# StatsD
[StatsD](https://github.com/statsd/statsd) is a system to collect data from any application. Applications send metrics to it,
usually via non-blocking UDP communication, and StatsD servers collect these metrics, perform a few simple calculations on
them and push them to backend time-series databases.
If you want to learn more about the StatsD protocol, we have written a
[blog post](https://blog.netdata.cloud/introduction-to-statsd/) about it!
Netdata is a fully featured statsd server. It can collect statsd formatted metrics, visualize
them on its dashboards and store them in it's database for long-term retention.
Netdata statsd is inside Netdata (an internal plugin, running inside the Netdata daemon), it is
configured via `netdata.conf` and by-default listens on standard statsd port 8125. Netdata supports
both TCP and UDP packets at the same time.
Since statsd is embedded in Netdata, it means you now have a statsd server embedded on all your servers.
Netdata statsd is fast. It can collect several millions of metrics per second on modern hardware, using
just 1 CPU core. The implementation uses two threads: one thread collects metrics, another thread updates
the charts from the collected data.
## Available StatsD synthetic application charts
Netdata ships with a few synthetic chart definitions to automatically present application metrics into a
more uniform way. These synthetic charts are configuration files (you can create your own) that re-arrange
statsd metrics into a more meaningful way.
On synthetic charts, we can have alerts as with any metric and chart.
- [K6 load testing tool](https://k6.io)
- **Description:** k6 is a developer-centric, free and open-source load testing tool built for making performance testing a productive and enjoyable experience.
- [Documentation](https://github.com/netdata/netdata/blob/master/collectors/statsd.plugin/k6.md)
- [Configuration](https://github.com/netdata/netdata/blob/master/collectors/statsd.plugin/k6.conf)
- [Asterisk](https://www.asterisk.org/)
- **Description:** Asterisk is an Open Source PBX and telephony toolkit.
- [Documentation](https://github.com/netdata/netdata/blob/master/collectors/statsd.plugin/asterisk.md)
- [Configuration](https://github.com/netdata/netdata/blob/master/collectors/statsd.plugin/asterisk.conf)
## Metrics supported by Netdata
Netdata fully supports the StatsD protocol and also extends it to support more advanced Netdata specific use cases.
All StatsD client libraries can be used with Netdata too.
- **Gauges**
The application sends `name:value|g`, where `value` is any **decimal/fractional** number, StatsD reports the
latest value collected and the number of times it was updated (events).
The application may increment or decrement a previous value, by setting the first character of the value to
`+` or `-` (so, the only way to set a gauge to an absolute negative value, is to first set it to zero).
[Sampling rate](#sampling-rates) is supported.
[Tags](#tags) are supported for changing chart units, family and dimension name.
When a gauge is not collected and the setting is not to show gaps on the charts (the default), the last value will be shown, until a data collection event changes it.
- **Counters** and **Meters**
The application sends `name:value|c`, `name:value|C` or `name:value|m`, where `value` is a positive or negative **integer** number of events occurred, StatsD reports the **rate** and the number of times it was updated (events).
`:value` can be omitted and StatsD will assume it is `1`. `|c`, `|C` and `|m` can be omitted and StatsD will assume it is `|m`. So, the application may send just `name` and StatsD will parse it as `name:1|m`.
- Counters use `|c` (etsy/StatsD compatible) or `|C` (brubeck compatible)
- Meters use `|m`
[Sampling rate](#sampling-rates) is supported.
[Tags](#tags) are supported for changing chart units, family and dimension name.
When a counter or meter is not collected, StatsD **defaults** to showing a zero value, until a data collection event changes the value.
- **Timers** and **Histograms**
The application sends `name:value|ms` or `name:value|h`, where `value` is any **decimal/fractional** number, StatsD reports **min**, **max**, **average**, **95th percentile**, **median** and **standard deviation** and the total number of times it was updated (events). Internally it also calculates the **sum**, which is available for synthetic charts.
- Timers use `|ms`
- Histograms use `|h`
The only difference between the two, is the `units` of the charts, as timers report *milliseconds*.
[Sampling rate](#sampling-rates) is supported.
[Tags](#tags) are supported for changing chart units and family.
When a counter or meter is not collected, StatsD **defaults** to showing a zero value, until a data collection event changes the value.
- **Sets**
The application sends `name:value|s`, where `value` is anything (**number or text**, leading and trailing spaces are removed), StatsD reports the number of unique values sent and the number of times it was updated (events).
Sampling rate is **not** supported for Sets. `value` is always considered text (so `01` and `1` are considered different).
[Tags](#tags) are supported for changing chart units and family.
When a set is not collected, Netdata **defaults** to showing a zero value, until a data collection event changes the value.
- **Dictionaries**
The application sends `name:value|d`, where `value` is anything (**number or text**, leading and trailing spaces are removed), StatsD reports the number of events sent for each `value` and the total times `name` was updated (events).
Sampling rate is **not** supported for Dictionaries. `value` is always considered text (so `01` and `1` are considered different).
[Tags](#tags) are supported for changing chart units and family.
When a set is not collected, Netdata **defaults** to showing a zero value, until a data collection event changes the value.
#### Sampling Rates
The application may append `|@sampling_rate`, where `sampling_rate` is a number from `0.0` to `1.0` in order for StatD to extrapolate the value and predict the total for the entire period. If the application reports to StatsD a value for 1/10th of the time, it can append `|@0.1` to the metrics it sends to statsd.
#### Tags
The application may append `|#tag1:value1,tag2:value2,tag3:value3` etc, where `tagX` and `valueX` are strings. `:valueX` can be omitted.
Currently, Netdata uses only 2 tags:
* `units=string` which sets the units of the chart that is automatically generated
* `family=string` which sets the family of the chart that is automatically generated (the family is the submenu of the dashboard)
* `name=string` which sets the name of the dimension of the chart that is automatically generated (only for counters, meters, gauges)
Other tags are parsed, but currently are ignored.
Charts are not updated to change units or dimension names once they are created. So, either send the tags on every event, or use the special `zinit` value to initiaze the charts at the beginning. `zinit` is a special value that can be used on any chart, to have netdata initialize the charts, without actually setting any values to them. So, instead of sending `my.metric:VALUE|c|#units=bytes,name=size` every time, the application can send at the beginning `my.metric:zinit|c|#units=bytes,name=size` and then `my.metric:VALUE|c`.
#### Overlapping metrics
Netdata's StatsD server maintains different indexes for each of the metric types supported. This means the same metric `name` may exist under different types concurrently.
#### How to name your metrics
A good practice is to name your metrics like `application.operation.metric`, where:
- `application` is the application name - Netdata will automatically create a dashboard section based on the first keyword of the metrics, so you can have all your applications in different sections.
- `operation` is the operation your application is executing, like `dbquery`, `request`, `response`, etc.
- `metric` is anything you want to name your metric as. Netdata will automatically append the metric type (meter, counter, gauge, set, dictionary, timer, histogram) to the generated chart.
Using [Tags](#tags) you can also change the submenus of the dashboard, the units of the charts and for meters, counters and gauges, the name of dimension. So, you can have a usable default view without using [Synthetic StatsD charts](#synthetic-statsd-charts)
#### Multiple metrics per packet
Netdata accepts multiple metrics per packet if each is terminated with a newline (`\n`) at the end.
#### TCP packets
Netdata listens for both TCP and UDP packets. For TCP, is it important to always append `\n` on each metric, as Netdata will use the newline character to detect if a metric is split into multiple TCP packets.
#### UDP packets
When sending multiple metrics over a single UDP message, it is important not to exceed the network MTU, which is usually 1500 bytes.
Netdata will accept UDP packets up to 9000 bytes, but the underlying network will not exceed MTU.
> You can read more about the network maximum transmission unit(MTU) in this cloudflare [article](https://www.cloudflare.com/en-gb/learning/network-layer/what-is-mtu/).
## Configuration
You can find the configuration at `/etc/netdata/netdata.conf`:
```
[statsd]
# enabled = yes
# decimal detail = 1000
# update every (flushInterval) = 1
# udp messages to process at once = 10
# create private charts for metrics matching = *
# max private charts hard limit = 1000
# cleanup obsolete charts after secs = 0
# private charts memory mode = save
# private charts history = 3996
# histograms and timers percentile (percentThreshold) = 95.00000
# add dimension for number of events received = no
# gaps on gauges (deleteGauges) = no
# gaps on counters (deleteCounters) = no
# gaps on meters (deleteMeters) = no
# gaps on sets (deleteSets) = no
# gaps on histograms (deleteHistograms) = no
# gaps on timers (deleteTimers) = no
# listen backlog = 4096
# default port = 8125
# bind to = udp:localhost:8125 tcp:localhost:8125
```
### StatsD main config options
- `enabled = yes|no`
controls if StatsD will be enabled for this Netdata. The default is enabled.
- `default port = 8125`
controls the default port StatsD will use if no port is defined in the following setting.
- `bind to = udp:localhost tcp:localhost`
is a space separated list of IPs and ports to listen to. The format is `PROTOCOL:IP:PORT` - if `PORT` is omitted, the `default port` will be used. If `IP` is IPv6, it needs to be enclosed in `[]`. `IP` can also be `*` (to listen on all IPs) or even a hostname.
- `update every (flushInterval) = 1` seconds, controls the frequency StatsD will push the collected metrics to Netdata charts.
- `decimal detail = 1000` controls the number of fractional digits in gauges and histograms. Netdata collects metrics using signed 64-bit integers and their fractional detail is controlled using multipliers and divisors. This setting is used to multiply all collected values to convert them to integers and is also set as the divisors, so that the final data will be a floating point number with this fractional detail (1000 = X.0 - X.999, 10000 = X.0 - X.9999, etc).
The rest of the settings are discussed below.
## StatsD charts
Netdata can visualize StatsD collected metrics in 2 ways:
1. Each metric gets its own **private chart**. This is the default and does not require any configuration. You can adjust the default parameters.
2. **Synthetic charts** can be created, combining multiple metrics, independently of their metric types. For this type of charts, special configuration is required, to define the chart title, type, units, its dimensions, etc.
### Private metric charts
Private charts are controlled with `create private charts for metrics matching = *`. This setting accepts a space-separated list of [simple patterns](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md). Netdata will create private charts for all metrics **by default**.
For example, to render charts for all `myapp.*` metrics, except `myapp.*.badmetric`, use:
```
create private charts for metrics matching = !myapp.*.badmetric myapp.*
```
You can specify Netdata StatsD to have a different `memory mode` than the rest of the Netdata Agent. You can read more about `memory mode` in the [documentation](https://github.com/netdata/netdata/blob/master/database/README.md).
The default behavior is to use the same settings as the rest of the Netdata Agent. If you wish to change them, edit the following settings:
- `private charts memory mode`
- `private charts history`
### Optimize private metric charts storage
For optimization reasons, Netdata imposes a hard limit on private metric charts. The limit is set via the `max private charts hard limit` setting (which defaults to 1000 charts). Metrics above this hard limit are still collected, but they can only be used in synthetic charts (once a metric is added to chart, it will be sent to backend servers too).
If you have many ephemeral metrics collected (i.e. that you collect values for a certain amount of time), you can set the configuration option `set charts as obsolete after secs`. Setting a value in seconds here, means that Netdata will mark those metrics (and their private charts) as obsolete after the specified time has passed since the last sent metric value. Those charts will later be deleted according to the setting in `cleanup obsolete charts after secs`. Setting `set charts as obsolete after secs` to 0 (which is also the default value) will disable this functionality.
Example private charts (automatically generated without any configuration):
#### Counters
- Scope: **count the events of something** (e.g. number of file downloads)
- Format: `name:INTEGER|c` or `name:INTEGER|C` or `name|c`
- StatsD increments the counter by the `INTEGER` number supplied (positive, or negative).

#### Gauges
- Scope: **report the value of something** (e.g. cache memory used by the application server)
- Format: `name:FLOAT|g`
- StatsD remembers the last value supplied, and can increment or decrement the latest value if `FLOAT` begins with `+` or `-`.

#### histograms
- Scope: **statistics on a size of events** (e.g. statistics on the sizes of files downloaded)
- Format: `name:FLOAT|h`
- StatsD maintains a list of all the values supplied and provides statistics on them.

The same chart with `sum` unselected, to show the detail of the dimensions supported:

#### Meters
This is identical to `counter`.
- Scope: **count the events of something** (e.g. number of file downloads)
- Format: `name:INTEGER|m` or `name|m` or just `name`
- StatsD increments the counter by the `INTEGER` number supplied (positive, or negative).

#### Sets
- Scope: **count the unique occurrences of something** (e.g. unique filenames downloaded, or unique users that downloaded files)
- Format: `name:TEXT|s`
- StatsD maintains a unique index of all values supplied, and reports the unique entries in it.

#### Timers
- Scope: **statistics on the duration of events** (e.g. statistics for the duration of file downloads)
- Format: `name:FLOAT|ms`
- StatsD maintains a list of all the values supplied and provides statistics on them.

### Synthetic StatsD charts
Use synthetic charts to create dedicated sections on the dashboard to render your StatsD charts.
Synthetic charts are organized in
- **application** aka section in Netdata Dashboard.
- **charts for each application** aka family in Netdata Dashboard.
- **StatsD metrics for each chart** /aka charts and context Netdata Dashboard.
> You can read more about how the Netdata Agent organizes information in the relevant [documentation](https://github.com/netdata/netdata/blob/master/web/README.md)
For each application you need to create a `.conf` file in `/etc/netdata/statsd.d`.
For example, if you want to monitor the application `myapp` using StatsD and Netdata, create the file `/etc/netdata/statsd.d/myapp.conf`, with this content:
```
[app]
name = myapp
metrics = myapp.*
private charts = no
gaps when not collected = no
history = 60
[dictionary]
m1 = metric1
m2 = metric2
# replace 'mychart' with the chart id
# the chart will be named: myapp.mychart
[mychart]
name = mychart
title = my chart title
family = my family
context = chart.context
units = tests/s
priority = 91000
type = area
dimension = myapp.metric1 m1
dimension = myapp.metric2 m2
```
Using the above configuration `myapp` should get its own section on the dashboard, having one chart with 2 dimensions.
`[app]` starts a new application definition. The supported settings in this section are:
- `name` defines the name of the app.
- `metrics` is a Netdata [simple pattern](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md). This pattern should match all the possible StatsD metrics that will be participating in the application `myapp`.
- `private charts = yes|no`, enables or disables private charts for the metrics matched.
- `gaps when not collected = yes|no`, enables or disables gaps on the charts of the application in case that no metrics are collected.
- `memory mode` sets the memory mode for all charts of the application. The default is the global default for Netdata (not the global default for StatsD private charts). We suggest not to use this (we have commented it out in the example) and let your app use the global default for Netdata, which is our dbengine.
- `history` sets the size of the round-robin database for this application. The default is the global default for Netdata (not the global default for StatsD private charts). This is only relevant if you use `memory mode = save`. Read more on our [metrics storage(]/docs/store/change-metrics-storage.md) doc.
`[dictionary]` defines name-value associations. These are used to renaming metrics, when added to synthetic charts. Metric names are also defined at each `dimension` line. However, using the dictionary dimension names can be declared globally, for each app and is the only way to rename dimensions when using patterns. Of course the dictionary can be empty or missing.
Then, add any number of charts. Each chart should start with `[id]`. The chart will be called `app_name.id`. `family` controls the submenu on the dashboard. `context` controls the alert templates. `priority` controls the ordering of the charts on the dashboard. The rest of the settings are informational.
Add any number of metrics to a chart, using `dimension` lines. These lines accept 5 space separated parameters:
1. the metric name, as it is collected (it has to be matched by the `metrics =` pattern of the app)
2. the dimension name, as it should be shown on the chart
3. an optional selector (type) of the value to shown (see below)
4. an optional multiplier
5. an optional divider
6. optional flags, space separated and enclosed in quotes. All the external plugins `DIMENSION` flags can be used. Currently, the only usable flag is `hidden`, to add the dimension, but not show it on the dashboard. This is usually needed to have the values available for percentage calculation, or use them in alerts.
So, the format is this:
```
dimension = [pattern] METRIC NAME TYPE MULTIPLIER DIVIDER OPTIONS
```
`pattern` is a keyword. When set, `METRIC` is expected to be a Netdata [simple pattern](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md) that will be used to match all the StatsD metrics to be added to the chart. So, `pattern` automatically matches any number of StatsD metrics, all of which will be added as separate chart dimensions.
`TYPE`, `MULTIPLIER`, `DIVIDER` and `OPTIONS` are optional.
`TYPE` can be:
- `events` to show the number of events received by StatsD for this metric
- `last` to show the last value, as calculated at the flush interval of the metric (the default)
Then for histograms and timers the following types are also supported:
- `min`, show the minimum value
- `max`, show the maximum value
- `sum`, show the sum of all values
- `average` (same as `last`)
- `percentile`, show the 95th percentile (or any other percentile, as configured at StatsD global config)
- `median`, show the median of all values (i.e. sort all values and get the middle value)
- `stddev`, show the standard deviation of the values
#### Example synthetic charts
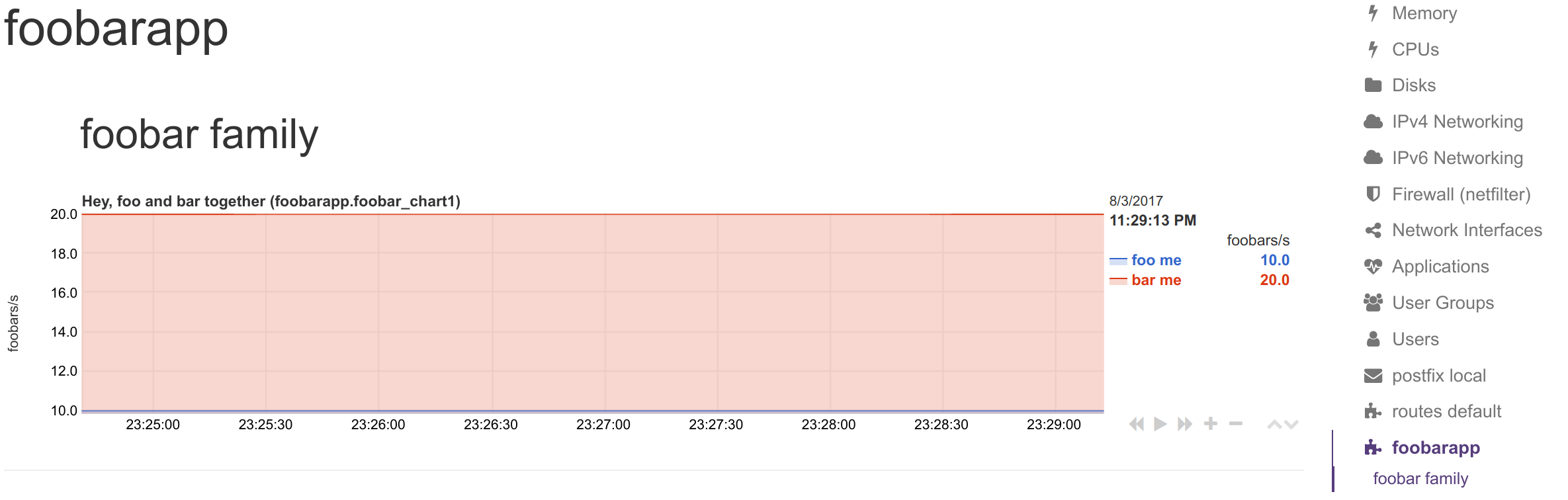
StatsD metrics: `foo` and `bar`.
Contents of file `/etc/netdata/stats.d/foobar.conf`:
```
[app]
name = foobarapp
metrics = foo bar
private charts = yes
[foobar_chart1]
title = Hey, foo and bar together
family = foobar_family
context = foobarapp.foobars
units = foobars
type = area
dimension = foo 'foo me' last 1 1
dimension = bar 'bar me' last 1 1
```
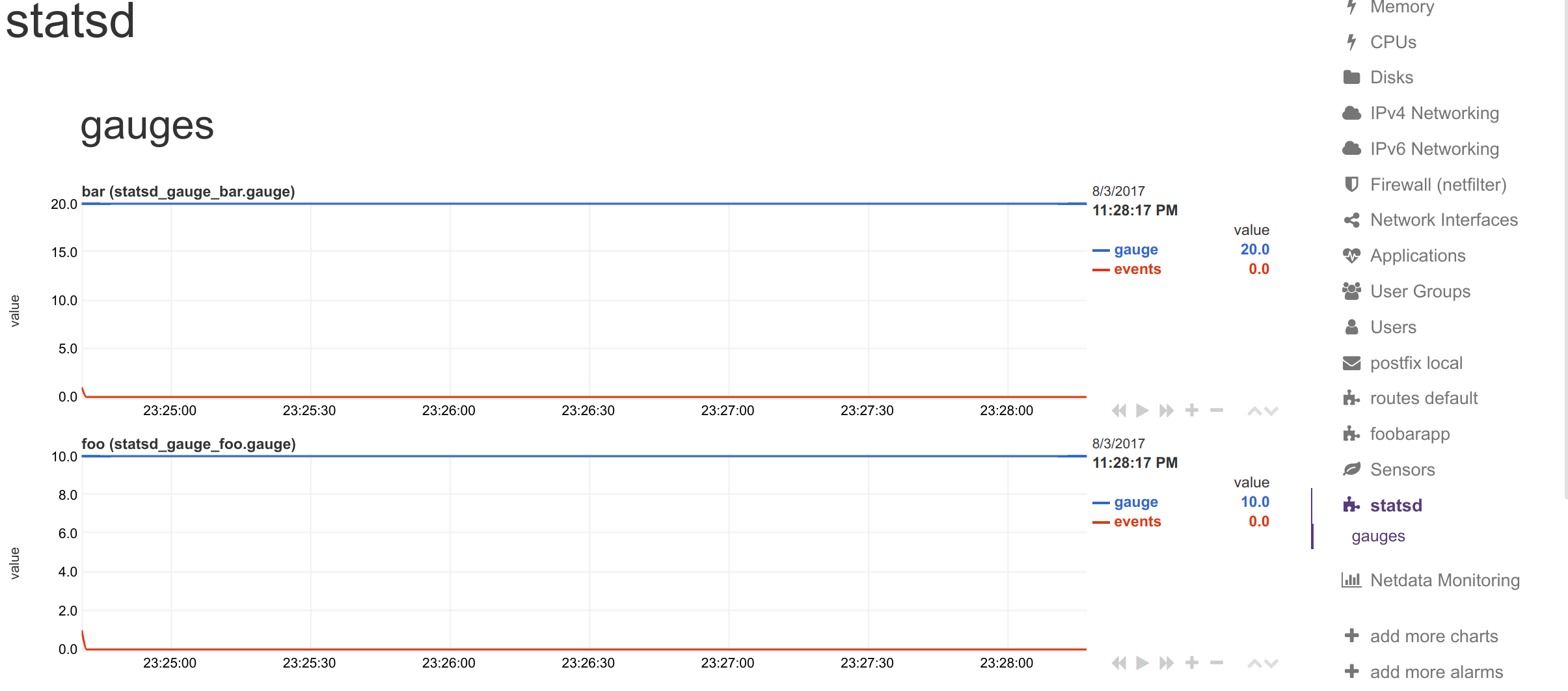
Metrics sent to statsd: `foo:10|g` and `bar:20|g`.
Private charts:
Synthetic chart:
#### Renaming StatsD synthetic charts' metrics
You can define a dictionary to rename metrics sent by StatsD clients. This enables you to send response `"200"` and Netdata visualize it as `succesful connection`
The `[dictionary]` section accepts any number of `name = value` pairs.
Netdata uses this dictionary as follows:
1. When a `dimension` has a non-empty `NAME`, that name is looked up at the dictionary.
2. If the above lookup gives nothing, or the `dimension` has an empty `NAME`, the original StatsD metric name is looked up at the dictionary.
3. If any of the above succeeds, Netdata uses the `value` of the dictionary, to set the name of the dimension. The dimensions will have as ID the original StatsD metric name, and as name, the dictionary value.
Use the dictionary in 2 ways:
1. set `dimension = myapp.metric1 ''` and have at the dictionary `myapp.metric1 = metric1 name`
2. set `dimension = myapp.metric1 'm1'` and have at the dictionary `m1 = metric1 name`
In both cases, the dimension will be added with ID `myapp.metric1` and will be named `metric1 name`. So, in alerts use either of the 2 as `${myapp.metric1}` or `${metric1 name}`.
> keep in mind that if you add multiple times the same StatsD metric to a chart, Netdata will append `TYPE` to the dimension ID, so `myapp.metric1` will be added as `myapp.metric1_last` or `myapp.metric1_events`, etc. If you add multiple times the same metric with the same `TYPE` to a chart, Netdata will also append an incremental counter to the dimension ID, i.e. `myapp.metric1_last1`, `myapp.metric1_last2`, etc.
#### Dimension patterns
Netdata allows adding multiple dimensions to a chart, by matching the StatsD metrics with a Netdata simple pattern.
Assume we have an API that provides StatsD metrics for each response code per method it supports, like these:
```
myapp.api.get.200
myapp.api.get.400
myapp.api.get.500
myapp.api.del.200
myapp.api.del.400
myapp.api.del.500
myapp.api.post.200
myapp.api.post.400
myapp.api.post.500
myapp.api.all.200
myapp.api.all.400
myapp.api.all.500
```
In order to add all the response codes of `myapp.api.get` to a chart, we simply make the following configuration:
```
[api_get_responses]
...
dimension = pattern 'myapp.api.get.* '' last 1 1
```
The above will add dimension named `200`, `400` and `500`. Netdata extracts the wildcard part of the metric name - so the dimensions will be named with whatever the `*` matched.
You can rename the dimensions with this:
```
[dictionary]
get.200 = 200 ok
get.400 = 400 bad request
get.500 = 500 cannot connect to db
[api_get_responses]
...
dimension = pattern 'myapp.api.get.* 'get.' last 1 1
```
Note that we added a `NAME` to the dimension line with `get.`. This is prefixed to the wildcarded part of the metric name, to compose the key for looking up the dictionary. So `500` became `get.500` which was looked up to the dictionary to find value `500 cannot connect to db`. This way we can have different dimension names, for each of the API methods (i.e. `get.500 = 500 cannot connect to db` while `post.500 = 500 cannot write to disk`).
To add all 200s across all API methods to a chart, you can do this:
```
[ok_by_method]
...
dimension = pattern 'myapp.api.*.200 '' last 1 1
```
The above will add `get`, `post`, `del` and `all` to the chart.
If `all` is not wanted (a `stacked` chart does not need the `all` dimension, since the sum of the dimensions provides the total), the line should be:
```
[ok_by_method]
...
dimension = pattern '!myapp.api.all.* myapp.api.*.200 '' last 1 1
```
With the above, all methods except `all` will be added to the chart.
To automatically rename the methods, you can use this:
```
[dictionary]
method.get = GET
method.post = ADD
method.del = DELETE
[ok_by_method]
...
dimension = pattern '!myapp.api.all.* myapp.api.*.200 'method.' last 1 1
```
Using the above, the dimensions will be added as `GET`, `ADD` and `DELETE`.
## StatsD examples
### Python
It's really easy to instrument your python application with StatsD, for example using [jsocol/pystatsd](https://github.com/jsocol/pystatsd).
```python
import statsd
c = statsd.StatsClient('localhost', 8125)
c.incr('foo') # Increment the 'foo' counter.
for i in range(100000000):
c.incr('bar')
c.incr('foo')
if i % 3:
c.decr('bar')
c.timing('stats.timed', 320) # Record a 320ms 'stats.timed'.
```
You can find detailed documentation in their [documentation page](https://statsd.readthedocs.io/en/v3.3/).
### Javascript and Node.js
Using the client library by [sivy/node-statsd](https://github.com/sivy/node-statsd), you can easily embed StatsD into your Node.js project.
```javascript
var StatsD = require('node-statsd'),
client = new StatsD();
// Timing: sends a timing command with the specified milliseconds
client.timing('response_time', 42);
// Increment: Increments a stat by a value (default is 1)
client.increment('my_counter');
// Decrement: Decrements a stat by a value (default is -1)
client.decrement('my_counter');
// Using the callback
client.set(['foo', 'bar'], 42, function(error, bytes){
//this only gets called once after all messages have been sent
if(error){
console.error('Oh noes! There was an error:', error);
} else {
console.log('Successfully sent', bytes, 'bytes');
}
});
// Sampling, tags and callback are optional and could be used in any combination
client.histogram('my_histogram', 42, 0.25); // 25% Sample Rate
client.histogram('my_histogram', 42, ['tag']); // User-defined tag
client.histogram('my_histogram', 42, next); // Callback
client.histogram('my_histogram', 42, 0.25, ['tag']);
client.histogram('my_histogram', 42, 0.25, next);
client.histogram('my_histogram', 42, ['tag'], next);
client.histogram('my_histogram', 42, 0.25, ['tag'], next);
```
### Other languages
You can also use StatsD with:
- Golang, thanks to [alexcesaro/statsd](https://github.com/alexcesaro/statsd)
- Ruby, thanks to [reinh/statsd](https://github.com/reinh/statsd)
- Java, thanks to [DataDog/java-dogstatsd-client](https://github.com/DataDog/java-dogstatsd-client)
### Shell
Getting the proper support for a programming language is not always easy, but the Unix shell is available on most Unix systems. You can use shell and `nc` to instrument your systems and send metric data to Netdata's StatsD implementation.
Using the method you can send metrics from any script. You can generate events like: backup.started, backup.ended, backup.time, or even tail logs and convert them to metrics.
> **IMPORTANT**:
>
> To send StatsD messages you need from the `netcat` package, the `nc` command.
> There are multiple versions of this package. Please try to experiment with the `nc` command you have available on your right system, to find the right parameters.
>
> In the examples below, we assume the `openbsd-netcat` is installed.
If you plan to send short StatsD events at sporadic occasions, use UDP. The messages should not be too long (remember, most networks support up to 1500 bytes MTU, which is also the limit for StatsD messages over UDP). The good thing is that using UDP will not block your script, even if the StatsD server is not there (UDP messages are "fire-and-forget").
For UDP use this:
```sh
echo "APPLICATION.METRIC:VALUE|TYPE" | nc -u -w 0 localhost 8125
```
`-u` turns on UDP, `-w 0` tells `nc` not to wait for a response from StatsD (idle time to close the connection).
where:
- `APPLICATION` is any name for your application
- `METRIC` is the name for the specific metric
- `VALUE` is the value for that metric (**meters**, **counters**, **gauges**, **timers** and **histograms** accept integer/decimal/fractional numbers, **sets** and **dictionaries** accept strings)
- `TYPE` is one of `m`, `c`, `g`, `ms`, `h`, `s`, `d` to define the metric type.
For tailing a log and converting it to metrics, do something like this:
```sh
tail -f some.log | awk 'awk commands to parse the log and format statsd metrics' | nc -N -w 120 localhost 8125
```
`-N` tells `nc` to close the socket once it receives EOF on its input. `-w 120` tells `nc` to stop if the connection is idle for 120 seconds. The timeout is needed to stop the `nc` command if you restart Netdata while `nc` is connected to it. Without it, `nc` will sit idle forever.
When you embed the above commands to a script, you may notice that all the metrics are sent to StatsD with a delay. They are buffered in the pipes `|`. You can turn them to real-time by prepending each command with `stdbuf -i0 -oL -eL command to be run`, like this:
```sh
stdbuf -i0 -oL -eL tail -f some.log |\
stdbuf -i0 -oL -eL awk 'awk commands to parse the log and format statsd metrics' |\
stdbuf -i0 -oL -eL nc -N -w 120 localhost 8125
```
If you use `mawk` you also need to run awk with `-W interactive`.
Examples:
To set `myapp.used_memory` as gauge to value `123456`, use:
```sh
echo "myapp.used_memory:123456|g|#units:bytes" | nc -u -w 0 localhost 8125
```
To increment `myapp.files_sent` by `10`, as a counter, use:
```sh
echo "myapp.files_sent:10|c|#units:files" | nc -u -w 0 localhost 8125
```
You can send multiple metrics like this:
```sh
# send multiple metrics via UDP
printf "myapp.used_memory:123456|g|#units:bytes\nmyapp.files_sent:10|c|#units:files\n" | nc -u -w 0 localhost 8125
```
Remember, for UDP communication each packet should not exceed the MTU. So, if you plan to push too many metrics at once, prefer TCP communication:
```sh
# send multiple metrics via TCP
cat /tmp/statsd.metrics.txt | nc -N -w 120 localhost 8125
```
You can also use this little function to take care of all the details:
```sh
#!/usr/bin/env bash
# we assume nc is from the openbsd-netcat package
STATSD_HOST="localhost"
STATSD_PORT="8125"
statsd() {
local options="-u -w 0" all="${*}"
# replace all spaces with newlines
all="${all// /\\n}"
# if the string length of all parameters given is above 1000, use TCP
[ "${#all}" -gt 1000 ] && options="-N -w 0"
# send the metrics to statsd
printf "${all}\n" | nc ${options} ${STATSD_HOST} ${STATSD_PORT} || return 1
return 0
}
if [ ! -z "${*}" ]
then
statsd "${@}"
fi
```
You can use it like this:
```sh
# first, source it in your script
source statsd.sh
# then, at any point:
statsd "myapp.used_memory:123456|g|#units:bytes" "myapp.files_sent:10|c|#units:files" ...
```
or even at a terminal prompt, like this:
```sh
./statsd.sh "myapp.used_memory:123456|g|#units:bytes" "myapp.files_sent:10|c|#units:files" ...
```
The function is smart enough to call `nc` just once and pass all the metrics to it. It will also automatically switch to TCP if the metrics to send are above 1000 bytes.
If you have gotten thus far, make sure to check out our [community forums](https://community.netdata.cloud) to share your experience using Netdata with StatsD.
## StatsD Step By Step Guide
In this guide, we'll go through a scenario of visualizing our data in Netdata in a matter of seconds using
[k6](https://k6.io), an open-source tool for automating load testing that outputs metrics to the StatsD format.
Although we'll use k6 as the use-case, the same principles can be applied to every application that supports
the StatsD protocol. Simply enable the StatsD output and point it to the node that runs Netdata, which is `localhost` in this case.
In general, the process for creating a StatsD collector can be summarized in 2 steps:
- Run an experiment by sending StatsD metrics to Netdata, without any prior configuration. This will create
a chart per metric (called private charts) and will help you verify that everything works as expected from the application side of things.
- Make sure to reload the dashboard tab **after** you start sending data to Netdata.
- Create a configuration file for your app using [edit-config](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md): `sudo ./edit-config
statsd.d/myapp.conf`
- Each app will have it's own section in the right-hand menu.
Now, let's see the above process in detail.
### Prerequisites
- A node with the [Netdata](https://github.com/netdata/netdata/blob/master/packaging/installer/README.md) installed.
- An application to instrument. For this guide, that will be [k6](https://k6.io/docs/getting-started/installation).
### Understanding the metrics
The real in instrumenting an application with StatsD for you is to decide what metrics you
want to visualize and how you want them grouped. In other words, you need decide which metrics
will be grouped in the same charts and how the charts will be grouped on Netdata's dashboard.
Start with documentation for the particular application that you want to monitor (or the
technological stack that you are using). In our case, the
[k6 documentation](https://k6.io/docs/using-k6/metrics/) has a whole page dedicated to the
metrics output by k6, along with descriptions.
If you are using StatsD to monitor an existing application, you don't have much control over
these metrics. For example, k6 has a type called `trend`, which is identical to timers and histograms.
Thus, _k6 is clearly dictating_ which metrics can be used as histograms and simple gauges.
On the other hand, if you are instrumenting your own code, you will need to not only decide what are
the "things" that you want to measure, but also decide which StatsD metric type is the appropriate for each.
### Use private charts to see all available metrics
In Netdata, every metric will receive its own chart, called a `private chart`. Although in the
final implementation this is something that we will disable, since it can create considerable noise
(imagine having 100s of metrics), it’s very handy while building the configuration file.
You can get a quick visual representation of the metrics and their type (e.g it’s a gauge, a timer, etc.).
An important thing to notice is that StatsD has different types of metrics, as illustrated in the
[supported metrics](#metrics-supported-by-netdata). Histograms and timers support mathematical operations
to be performed on top of the baseline metric, like reporting the `average` of the value.
Here are some examples of default private charts. You can see that the histogram private charts will
visualize all the available operations.
**Gauge private chart**

**Histogram private chart**

### Create a new StatsD configuration file
Start by creating a new configuration file under the `statsd.d/` folder in the
[Netdata config directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md#the-netdata-config-directory).
Use [`edit-config`](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md#use-edit-config-to-edit-configuration-files)
to create a new file called `k6.conf`.
```bash=
sudo ./edit-config statsd.d/k6.conf
```
Copy the following configuration into your file as a starting point.
```conf
[app]
name = k6
metrics = k6*
private charts = yes
gaps when not collected = no
memory mode = dbengine
```
Next, you need is to understand how to organize metrics in Netdata’s StatsD.
#### Synthetic charts
Netdata lets you group the metrics exposed by your instrumented application with _synthetic charts_.
First, create a `[dictionary]` section to transform the names of the metrics into human-readable equivalents.
`http_req_blocked`, `http_req_connecting`, `http_req_receiving`, and `http_reqs` are all metrics exposed by k6.
```
[dictionary]
http_req_blocked = Blocked HTTP Requests
http_req_connecting = Connecting HTTP Requests
http_req_receiving = Receiving HTTP Requests
http_reqs = Total HTTP requests
```
Continue this dictionary process with any other metrics you want to collect with Netdata.
#### Families and context
Families and context are additional ways to group metrics. Families control the submenu at right-hand menu and
it's a subcategory of the section. Given the metrics given by K6, we are organizing them in 2 major groups,
or `families`: `k6 native metrics` and `http metrics`.
Context is a second way to group metrics, when the metrics are of the same nature but different origin. In
our case, if we ran several different load testing experiments side-by-side, we could define the same app,
but different context (e.g `http_requests.experiment1`, `http_requests.experiment2`).
Find more details about family and context in our [documentation](https://github.com/netdata/netdata/blob/master/web/README.md#families).
#### Dimensions
Now, having decided on how we are going to group the charts, we need to define how we are going to group
metrics into different charts. This is particularly important, since we decide:
- What metrics **not** to show, since they are not useful for our use-case.
- What metrics to consolidate into the same charts, so as to reduce noise and increase visual correlation.
The dimension option has this syntax: `dimension = [pattern] METRIC NAME TYPE MULTIPLIER DIVIDER OPTIONS`
- **pattern**: A keyword that tells the StatsD server the `METRIC` string is actually a
[simple pattern](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md).
We don't use simple patterns in the example, but if we wanted to visualize all the `http_req` metrics, we
could have a single dimension: `dimension = pattern 'k6.http_req*' last 1 1`. Find detailed examples with
patterns in [dimension patterns](https://github.com/netdata/netdata/blob/master/collectors/statsd.plugin/README.md#dimension-patterns).
- **METRIC** The id of the metric as it comes from the client. You can easily find this in the private charts above,
for example: `k6.http_req_connecting`.
- **NAME**: The name of the dimension. You can use the dictionary to expand this to something more human-readable.
- **TYPE**:
- For all charts:
- `events`: The number of events (data points) received by the StatsD server
- `last`: The last value that the server received
- For histograms and timers:
- `min`, `max`, `sum`, `average`, `percentile`, `median`, `stddev`: This is helpful if you want to see
different representations of the same value. You can find an example at the `[iteration_duration]`
above. Note that the baseline `metric` is the same, but the `name` of the dimension is different,
since we use the baseline, but we perform a computation on it, creating a different final metric for
visualization(dimension).
- **MULTIPLIER DIVIDER**: Handy if you want to convert Kilobytes to Megabytes or you want to give negative value.
The second is handy for better visualization of send/receive. You can find an example at the **packets** submenu of the **IPv4 Networking Section**.
If you define a chart, run Netdata to visualize metrics, and then add or remove a dimension from that chart,
this will result in a new chart with the same name, confusing Netdata. If you change the dimensions of the chart,
make sure to also change the `name` of that chart, since it serves as the `id` of that chart in Netdata's storage.
(e.g http_req --> http_req_1).
#### Finalize your StatsD configuration file
It's time to assemble all the pieces together and create the synthetic charts that will consist our application
dashboard in Netdata. We can do it in a few simple steps:
- Decide which metrics we want to use (we have viewed all of them as private charts). For example, we want to use
`k6.http_requests`, `k6.vus`, etc.
- Decide how we want organize them in different synthetic charts. For example, we want `k6.http_requests`, `k6.vus`
on their own, but `k6.http_req_blocked` and `k6.http_req_connecting` on the same chart.
- For each synthetic chart, we define a **unique** name and a human readable title.
- We decide at which `family` (submenu section) we want each synthetic chart to belong to. For example, here we
have defined 2 families: `http requests`, `k6_metrics`.
- If we have multiple instances of the same metric, we can define different contexts, (Optional).
- We define a dimension according to the syntax we highlighted above.
- We define a type for each synthetic chart (line, area, stacked)
- We define the units for each synthetic chart.
Following the above steps, we append to the `k6.conf` that we defined above, the following configuration:
```
[http_req_total]
name = http_req_total
title = Total HTTP Requests
family = http requests
context = k6.http_requests
dimension = k6.http_reqs http_reqs last 1 1 sum
type = line
units = requests/s
[vus]
name = vus
title = Virtual Active Users
family = k6_metrics
dimension = k6.vus vus last 1 1
dimension = k6.vus_max vus_max last 1 1
type = line
unit = vus
[iteration_duration]
name = iteration_duration_2
title = Iteration duration
family = k6_metrics
dimension = k6.iteration_duration iteration_duration last 1 1
dimension = k6.iteration_duration iteration_duration_max max 1 1
dimension = k6.iteration_duration iteration_duration_min min 1 1
dimension = k6.iteration_duration iteration_duration_avg avg 1 1
type = line
unit = s
[dropped_iterations]
name = dropped_iterations
title = Dropped Iterations
family = k6_metrics
dimension = k6.dropped_iterations dropped_iterations last 1 1
units = iterations
type = line
[data]
name = data
title = K6 Data
family = k6_metrics
dimension = k6.data_received data_received last 1 1
dimension = k6.data_sent data_sent last -1 1
units = kb/s
type = area
[http_req_status]
name = http_req_status
title = HTTP Requests Status
family = http requests
dimension = k6.http_req_blocked http_req_blocked last 1 1
dimension = k6.http_req_connecting http_req_connecting last 1 1
units = ms
type = line
[http_req_duration]
name = http_req_duration
title = HTTP requests duration
family = http requests
dimension = k6.http_req_sending http_req_sending last 1 1
dimension = k6.http_req_waiting http_req_waiting last 1 1
dimension = k6.http_req_receiving http_req_receiving last 1 1
units = ms
type = stacked
```
Note that Netdata will report the rate for metrics and counters, even if k6 or another application
sends an _absolute_ number. For example, k6 sends absolute HTTP requests with `http_reqs`,
but Netdata visualizes that in `requests/second`.
To enable this StatsD configuration, [restart Netdata](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md).
### Final touches
At this point, you have used StatsD to gather metrics for k6, creating a whole new section in your
Netdata dashboard in the process. Moreover, you can further customize the icon of the particular section,
as well as the description for each chart.
To edit the section, please follow the Netdata [documentation](https://github.com/netdata/netdata/blob/master/web/gui/README.md#customizing-the-local-dashboard).
While the following configuration will be placed in a new file, as the documentation suggests, it is
instructing to use `dashboard_info.js` as a template. Open the file and see how the rest of sections and collectors have been defined.
```javascript=
netdataDashboard.menu = {
'k6': {
title: 'K6 Load Testing',
icon: '',
info: 'k6 is an open-source load testing tool and cloud service providing the best developer experience for API performance testing.'
},
.
.
.
```
We can then add a description for each chart. Simply find the following section in `dashboard_info.js` to understand how a chart definitions are used:
```javascript=
netdataDashboard.context = {
'system.cpu': {
info: function (os) {
void (os);
return 'Total CPU utilization (all cores). 100% here means there is no CPU idle time at all. You can get per core usage at the CPUs section and per application usage at the Applications Monitoring section.'
+ netdataDashboard.sparkline('
Keep an eye on iowait ', 'system.cpu', 'iowait', '%', '. If it is constantly high, your disks are a bottleneck and they slow your system down.')
+ netdataDashboard.sparkline('
An important metric worth monitoring, is softirq ', 'system.cpu', 'softirq', '%', '. A constantly high percentage of softirq may indicate network driver issues.');
},
valueRange: "[0, 100]"
},
```
Afterwards, you can open your `custom_dashboard_info.js`, as suggested in the documentation linked above,
and add something like the following example:
```javascript=
netdataDashboard.context = {
'k6.http_req_duration': {
info: "Total time for the request. It's equal to http_req_sending + http_req_waiting + http_req_receiving (i.e. how long did the remote server take to process the request and respond, without the initial DNS lookup/connection times)"
},
```
The chart is identified as ``.``.
These descriptions can greatly help the Netdata user who is monitoring your application in the midst of an incident.
The `info` field supports `html`, embedding useful links and instructions in the description.
### Vendoring a new collector
While we learned how to visualize any data source in Netdata using the StatsD protocol, we have also created a new collector.
As long as you use the same underlying collector, every new `myapp.conf` file will create a new data
source and dashboard section for Netdata. Netdata loads all the configuration files by default, but it will
**not** create dashboard sections or charts, unless it starts receiving data for that particular data source.
This means that we can now share our collector with the rest of the Netdata community.
- Make sure you follow the [contributing guide](https://github.com/netdata/.github/edit/main/CONTRIBUTING.md)
- Fork the netdata/netdata repository
- Place the configuration file inside `netdata/collectors/statsd.plugin`
- Add a reference in `netdata/collectors/statsd.plugin/Makefile.am`. For example, if we contribute the `k6.conf` file:
```Makefile
dist_statsdconfig_DATA = \
example.conf \
k6.conf \
$(NULL)
```