
diff options
| author | Daniel Baumann <daniel.baumann@progress-linux.org> | 2024-08-26 08:15:20 +0000 |
|---|---|---|
| committer | Daniel Baumann <daniel.baumann@progress-linux.org> | 2024-08-26 08:15:20 +0000 |
| commit | 87d772a7d708fec12f48cd8adc0dedff6e1025da (patch) | |
| tree | 1fee344c64cc3f43074a01981e21126c8482a522 /doc | |
| parent | Adding upstream version 1.46.3. (diff) | |
| download | netdata-87d772a7d708fec12f48cd8adc0dedff6e1025da.tar.xz netdata-87d772a7d708fec12f48cd8adc0dedff6e1025da.zip | |
Adding upstream version 1.47.0.upstream/1.47.0
Signed-off-by: Daniel Baumann <daniel.baumann@progress-linux.org>
Diffstat (limited to '')
15 files changed, 81 insertions, 160 deletions
diff --git a/docs/alerts-and-notifications/notifications/centralized-cloud-notifications/manage-notification-methods.md b/docs/alerts-and-notifications/notifications/centralized-cloud-notifications/manage-notification-methods.md index 6a432ded3..463b10101 100644 --- a/docs/alerts-and-notifications/notifications/centralized-cloud-notifications/manage-notification-methods.md +++ b/docs/alerts-and-notifications/notifications/centralized-cloud-notifications/manage-notification-methods.md @@ -63,7 +63,6 @@ Note: If an administrator has disabled a Personal [service level](/docs/alerts-a 2. You are presented with: - The Personal [service level](/docs/alerts-and-notifications/notifications/centralized-cloud-notifications/centralized-cloud-notifications-reference.md#service-level) notification methods you can manage. - The list of Spaces and Rooms inside those where you have access to. - - If you're an Administrator, Manager, or Troubleshooter, you'll also see the Rooms from a Space you don't have access to on the **All Rooms** tab, and you can activate notifications for them by joining the Room. 3. On this modal you will be able to: 1. **Enable/Disable** the notification method for you; this applies across all Spaces and Rooms. - Use the toggle to enable or disable the notification method. diff --git a/docs/deployment-guides/deployment-strategies.md b/docs/deployment-guides/deployment-strategies.md index abdb36cdf..1a3c67164 100644 --- a/docs/deployment-guides/deployment-strategies.md +++ b/docs/deployment-guides/deployment-strategies.md @@ -16,7 +16,7 @@ The stand-alone setup is configured out of the box with reasonable defaults, but ### Parent – Child -For setups involving Parent and Child Agents, they need to be configured for [streaming](docs/observability-centralization-points/metrics-centralization-points/configuration.md), through the configuration file `stream.conf`. +For setups involving Parent and Child Agents, they need to be configured for [streaming](/docs/observability-centralization-points/metrics-centralization-points/configuration.md), through the configuration file `stream.conf`. This will instruct the Child to stream data to the Parent and the Parent to accept streaming connections for one or more Child Agents. To secure this connection, both need a shared API key (to replace the string `API_KEY` in the examples below). Additionally, the Child can be configured with one or more addresses of Parent Agents (`PARENT_IP_ADDRESS`). @@ -32,7 +32,7 @@ In this example, Machine Learning and Alerting are disabled for the Child, so th ##### netdata.conf -On the child node, edit `netdata.conf` by using the [edit-config](docs/netdata-agent/configuration/README.md#edit-netdataconf) script and set the following parameters: +On the child node, edit `netdata.conf` by using the [edit-config](/docs/netdata-agent/configuration/README.md#edit-netdataconf) script and set the following parameters: ```yaml [db] @@ -63,7 +63,7 @@ On the child node, edit `netdata.conf` by using the [edit-config](docs/netdata-a ##### stream.conf -To edit `stream.conf`, use again the [edit-config](docs/netdata-agent/configuration/README.md#edit-netdataconf) script and set the following parameters: +To edit `stream.conf`, use again the [edit-config](/docs/netdata-agent/configuration/README.md#edit-netdataconf) script and set the following parameters: ```yaml [stream] @@ -90,7 +90,7 @@ Requiring: ##### netdata.conf -On the Parent, edit `netdata.conf` by using the [edit-config](docs/netdata-agent/configuration/README.md#edit-netdataconf) script and set the following parameters: +On the Parent, edit `netdata.conf` by using the [edit-config](/docs/netdata-agent/configuration/README.md#edit-netdataconf) script and set the following parameters: ```yaml [db] @@ -125,7 +125,7 @@ On the Parent, edit `netdata.conf` by using the [edit-config](docs/netdata-agent ##### stream.conf -On the Parent node, edit `stream.conf` by using the [edit-config](docs/netdata-agent/configuration/README.md#edit-netdataconf) script and set the following parameters: +On the Parent node, edit `stream.conf` by using the [edit-config](/docs/netdata-agent/configuration/README.md#edit-netdataconf) script and set the following parameters: ```yaml [API_KEY] @@ -137,7 +137,7 @@ On the Parent node, edit `stream.conf` by using the [edit-config](docs/netdata-a In order to setup active–active streaming between Parent 1 and Parent 2, Parent 1 needs to be instructed to stream data to Parent 2 and Parent 2 to stream data to Parent 1. The Child Agents need to be configured with the addresses of both Parent Agents. An Agent will only connect to one Parent at a time, falling back to the next upon failure. These examples use the same API key between Parent Agents and for connections for Child Agents. -On both Netdata Parent and all Child Agents, edit `stream.conf` by using the [edit-config](docs/netdata-agent/configuration/README.md#edit-netdataconf) script: +On both Netdata Parent and all Child Agents, edit `stream.conf` by using the [edit-config](/docs/netdata-agent/configuration/README.md#edit-netdataconf) script: #### stream.conf on Parent 1 diff --git a/docs/developer-and-contributor-corner/collect-apache-nginx-web-logs.md b/docs/developer-and-contributor-corner/collect-apache-nginx-web-logs.md index 206c1e8ee..55af82fb7 100644 --- a/docs/developer-and-contributor-corner/collect-apache-nginx-web-logs.md +++ b/docs/developer-and-contributor-corner/collect-apache-nginx-web-logs.md @@ -8,7 +8,7 @@ You can use the [LTSV log format](http://ltsv.org/), track TLS and cipher usage, ever. In one test on a system with SSD storage, the collector consistently parsed the logs for 200,000 requests in 200ms, using ~30% of a single core. -The [web_log](/src/go/collectors/go.d.plugin/modules/weblog/README.md) collector is currently compatible +The [web_log](/src/go/plugin/go.d/modules/weblog/README.md) collector is currently compatible with [Nginx](https://nginx.org/en/) and [Apache](https://httpd.apache.org/). This guide will walk you through using the new Go-based web log collector to turn the logs these web servers @@ -91,7 +91,7 @@ The web log collector is capable of parsing custom Nginx and Apache log formats leave that topic for a separate guide. We do have [extensive -documentation](/src/go/collectors/go.d.plugin/modules/weblog/README.md#custom-log-format) on how +documentation](/src/go/plugin/go.d/modules/weblog/README.md#custom-log-format) on how to build custom parsing for Nginx and Apache logs. ## Tweak web log collector alerts diff --git a/docs/developer-and-contributor-corner/collect-unbound-metrics.md b/docs/developer-and-contributor-corner/collect-unbound-metrics.md index 0f80395fb..ac997b7f9 100644 --- a/docs/developer-and-contributor-corner/collect-unbound-metrics.md +++ b/docs/developer-and-contributor-corner/collect-unbound-metrics.md @@ -58,9 +58,7 @@ configuring the collector. You may not need to do any more configuration to have Netdata collect your Unbound metrics. If you followed the steps above to enable `remote-control` and make your Unbound files readable by Netdata, that should -be enough. Restart Netdata with `sudo systemctl restart netdata`, or the [appropriate -method](/packaging/installer/README.md#maintaining-a-netdata-agent-installation) for your system. You should see Unbound metrics in your Netdata -dashboard! +be enough. Restart Netdata with `sudo systemctl restart netdata`, or the appropriate method for your system. You should see Unbound metrics in your Netdata dashboard!  @@ -93,7 +91,7 @@ jobs: tls_skip_verify: yes tls_cert: /path/to/unbound_control.pem tls_key: /path/to/unbound_control.key - + - name: local address: 127.0.0.1:8953 cumulative: yes @@ -101,16 +99,15 @@ jobs: ``` Netdata will attempt to read `unbound.conf` to get the appropriate `address`, `cumulative`, `use_tls`, `tls_cert`, and -`tls_key` parameters. +`tls_key` parameters. -Restart Netdata with `sudo systemctl restart netdata`, or the [appropriate -method](/packaging/installer/README.md#maintaining-a-netdata-agent-installation) for your system. +Restart Netdata with `sudo systemctl restart netdata`, or the appropriate method for your system. ### Manual setup for a remote Unbound server Collecting metrics from remote Unbound servers requires manual configuration. There are too many possibilities to cover all remote connections here, but the [default `unbound.conf` -file](https://github.com/netdata/netdata/blob/master/src/go/collectors/go.d.plugin/config/go.d/unbound.conf) contains a few useful examples: +file](https://github.com/netdata/netdata/blob/master/src/go/plugin/go.d/config/go.d/unbound.conf) contains a few useful examples: ```yaml jobs: @@ -132,7 +129,7 @@ jobs: ``` To see all the available options, see the default [unbound.conf -file](https://github.com/netdata/netdata/blob/master/src/go/collectors/go.d.plugin/config/go.d/unbound.conf). +file](https://github.com/netdata/netdata/blob/master/src/go/plugin/go.d/config/go.d/unbound.conf). ## What's next? diff --git a/docs/developer-and-contributor-corner/kubernetes-k8s-netdata.md b/docs/developer-and-contributor-corner/kubernetes-k8s-netdata.md index 11982a5b4..011aac8da 100644 --- a/docs/developer-and-contributor-corner/kubernetes-k8s-netdata.md +++ b/docs/developer-and-contributor-corner/kubernetes-k8s-netdata.md @@ -137,7 +137,7 @@ Let's explore the most colorful box by hovering over it. container](https://user-images.githubusercontent.com/1153921/109049544-a8417980-7695-11eb-80a7-109b4a645a27.png) The **Context** tab shows `rabbitmq-5bb66bb6c9-6xr5b` as the container's image name, which means this container is -running a [RabbitMQ](/src/go/collectors/go.d.plugin/modules/rabbitmq/README.md) workload. +running a [RabbitMQ](/src/go/plugin/go.d/modules/rabbitmq/README.md) workload. Click the **Metrics** tab to see real-time metrics from that container. Unsurprisingly, it shows a spike in CPU utilization at regular intervals. @@ -166,13 +166,13 @@ for complete customization. For example, grouping the top chart by `k8s_containe Netdata has a [service discovery plugin](https://github.com/netdata/agent-service-discovery), which discovers and creates configuration files for [compatible services](https://github.com/netdata/helmchart#service-discovery-and-supported-services) and any endpoints covered by -our [generic Prometheus collector](/src/go/collectors/go.d.plugin/modules/prometheus/README.md). +our [generic Prometheus collector](/src/go/plugin/go.d/modules/prometheus/README.md). Netdata uses these files to collect metrics from any compatible application as they run _inside_ of a pod. Service discovery happens without manual intervention as pods are created, destroyed, or moved between nodes. Service metrics show up on the Overview as well, beneath the **Kubernetes** section, and are labeled according to the service in question. For example, the **RabbitMQ** section has numerous charts from the [`rabbitmq` -collector](/src/go/collectors/go.d.plugin/modules/rabbitmq/README.md): +collector](/src/go/plugin/go.d/modules/rabbitmq/README.md): 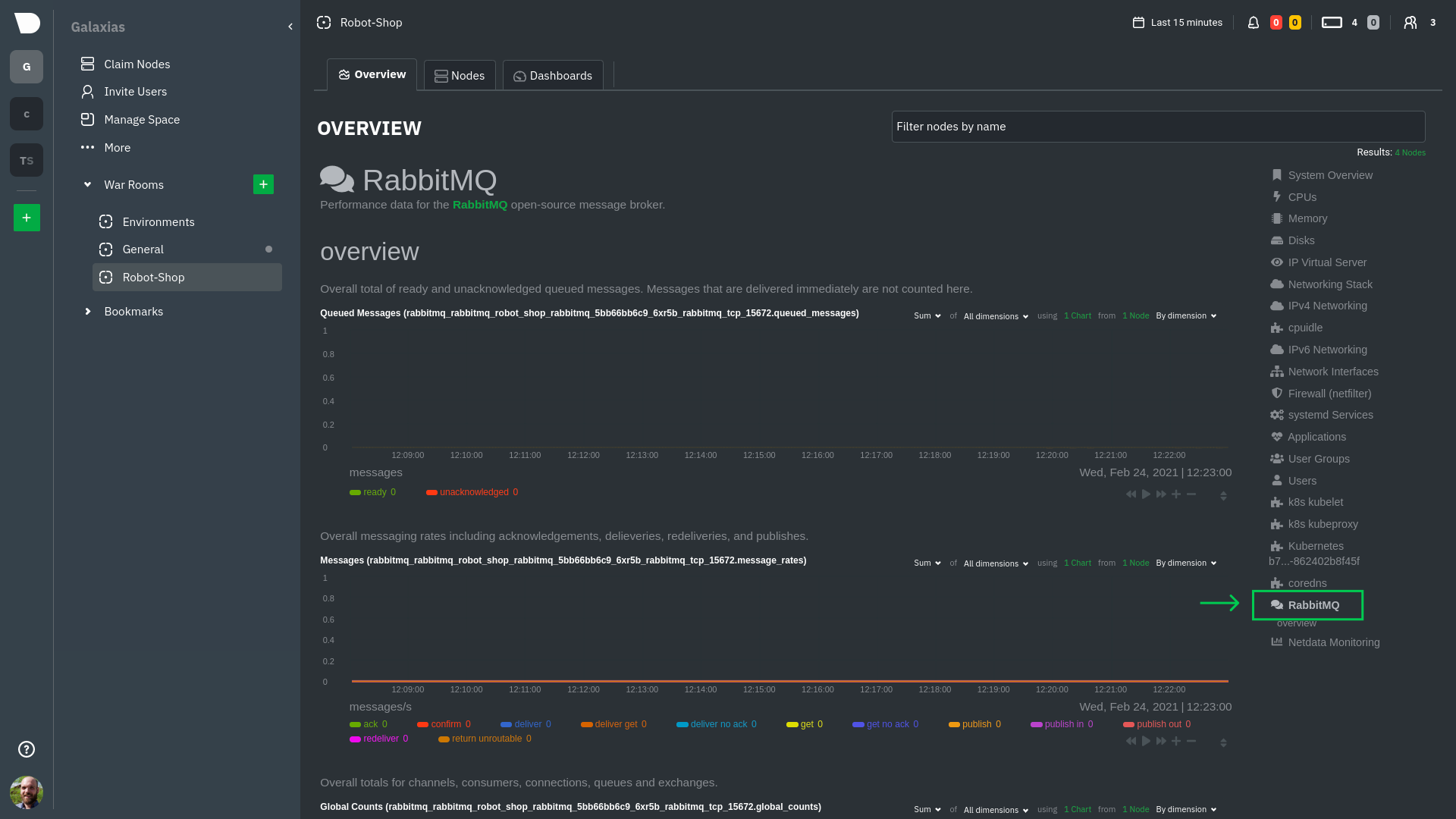 @@ -193,7 +193,7 @@ Netdata also automatically collects metrics from two essential Kubernetes proces The **k8s kubelet** section visualizes metrics from the Kubernetes agent responsible for managing every pod on a given node. This also happens without any configuration thanks to the [kubelet -collector](/src/go/collectors/go.d.plugin/modules/k8s_kubelet/README.md). +collector](/src/go/plugin/go.d/modules/k8s_kubelet/README.md). Monitoring each node's kubelet can be invaluable when diagnosing issues with your Kubernetes cluster. For example, you can see if the number of running containers/pods has dropped, which could signal a fault or crash in a particular @@ -209,7 +209,7 @@ configuration-related errors, and the actual vs. desired numbers of volumes, plu The **k8s kube-proxy** section displays metrics about the network proxy that runs on each node in your Kubernetes cluster. kube-proxy lets pods communicate with each other and accept sessions from outside your cluster. Its metrics are collected by the [kube-proxy -collector](/src/go/collectors/go.d.plugin/modules/k8s_kubeproxy/README.md). +collector](/src/go/plugin/go.d/modules/k8s_kubeproxy/README.md). With Netdata, you can monitor how often your k8s proxies are syncing proxy rules between nodes. Dramatic changes in these figures could indicate an anomaly in your cluster that's worthy of further investigation. @@ -229,9 +229,9 @@ clusters of all sizes. - [Netdata Helm chart](https://github.com/netdata/helmchart) - [Netdata service discovery](https://github.com/netdata/agent-service-discovery) - [Netdata Agent · `kubelet` - collector](/src/go/collectors/go.d.plugin/modules/k8s_kubelet/README.md) + collector](/src/go/plugin/go.d/modules/k8s_kubelet/README.md) - [Netdata Agent · `kube-proxy` - collector](/src/go/collectors/go.d.plugin/modules/k8s_kubeproxy/README.md) + collector](/src/go/plugin/go.d/modules/k8s_kubeproxy/README.md) - [Netdata Agent · `cgroups.plugin`](/src/collectors/cgroups.plugin/README.md) diff --git a/docs/developer-and-contributor-corner/lamp-stack.md b/docs/developer-and-contributor-corner/lamp-stack.md index bdec9e750..2df5a7167 100644 --- a/docs/developer-and-contributor-corner/lamp-stack.md +++ b/docs/developer-and-contributor-corner/lamp-stack.md @@ -69,7 +69,7 @@ metrics from each using the [cgroups data collector](/src/collectors/cgroups.plu ## Enable Apache monitoring Let's begin by configuring Apache to work with Netdata's [Apache data -collector](/src/go/collectors/go.d.plugin/modules/apache/README.md). +collector](/src/go/plugin/go.d/modules/apache/README.md). Actually, there's nothing for you to do to enable Apache monitoring with Netdata. @@ -80,7 +80,7 @@ metrics](https://httpd.apache.org/docs/2.4/mod/mod_status.html), which is just _ ## Enable web log monitoring The Netdata Agent also comes with a [web log -collector](/src/go/collectors/go.d.plugin/modules/weblog/README.md), which reads Apache's access +collector](/src/go/plugin/go.d/modules/weblog/README.md), which reads Apache's access log file, processes each line, and converts them into per-second metrics. On Debian systems, it reads the file at `/var/log/apache2/access.log`. @@ -93,7 +93,7 @@ monitoring. Because your MySQL database is password-protected, you do need to tell MySQL to allow the `netdata` user to connect to without a password. Netdata's [MySQL data -collector](/src/go/collectors/go.d.plugin/modules/mysql/README.md) collects metrics in _read-only_ +collector](/src/go/plugin/go.d/modules/mysql/README.md) collects metrics in _read-only_ mode, without being able to alter or affect operations in any way. First, log into the MySQL shell. Then, run the following three commands, one at a time: @@ -113,7 +113,7 @@ Unlike Apache or MySQL, PHP isn't a service that you can monitor directly, unles with [StatsD](/src/collectors/statsd.plugin/README.md). However, if you use [PHP-FPM](https://php-fpm.org/) in your LAMP stack, you can monitor that process with our [PHP-FPM -data collector](/src/go/collectors/go.d.plugin/modules/phpfpm/README.md). +data collector](/src/go/plugin/go.d/modules/phpfpm/README.md). Open your PHP-FPM configuration for editing, replacing `7.4` with your version of PHP: @@ -215,7 +215,7 @@ services. The per-second metrics granularity means you have the most accurate in any LAMP-related issues. Another powerful way to monitor the availability of a LAMP stack is the [`httpcheck` -collector](/src/go/collectors/go.d.plugin/modules/httpcheck/README.md), which pings a web server at +collector](/src/go/plugin/go.d/modules/httpcheck/README.md), which pings a web server at a regular interval and tells you whether if and how quickly it's responding. The `response_match` option also lets you monitor when the web server's response isn't what you expect it to be, which might happen if PHP-FPM crashes, for example. @@ -231,8 +231,8 @@ source of issues faster with [Metric Correlations](/docs/metric-correlations.md) ### Related reference documentation - [Netdata Agent · Get started](/packaging/installer/README.md) -- [Netdata Agent · Apache data collector](/src/go/collectors/go.d.plugin/modules/apache/README.md) -- [Netdata Agent · Web log collector](/src/go/collectors/go.d.plugin/modules/weblog/README.md) -- [Netdata Agent · MySQL data collector](/src/go/collectors/go.d.plugin/modules/mysql/README.md) -- [Netdata Agent · PHP-FPM data collector](/src/go/collectors/go.d.plugin/modules/phpfpm/README.md) +- [Netdata Agent · Apache data collector](/src/go/plugin/go.d/modules/apache/README.md) +- [Netdata Agent · Web log collector](/src/go/plugin/go.d/modules/weblog/README.md) +- [Netdata Agent · MySQL data collector](/src/go/plugin/go.d/modules/mysql/README.md) +- [Netdata Agent · PHP-FPM data collector](/src/go/plugin/go.d/modules/phpfpm/README.md) diff --git a/docs/developer-and-contributor-corner/monitor-cockroachdb.md b/docs/developer-and-contributor-corner/monitor-cockroachdb.md index 303c00f62..f0db12cc4 100644 --- a/docs/developer-and-contributor-corner/monitor-cockroachdb.md +++ b/docs/developer-and-contributor-corner/monitor-cockroachdb.md @@ -11,7 +11,7 @@ learn_rel_path: "Miscellaneous" [CockroachDB](https://github.com/cockroachdb/cockroach) is an open-source project that brings SQL databases into scalable, disaster-resilient cloud deployments. Thanks to -a [new CockroachDB collector](/src/go/collectors/go.d.plugin/modules/cockroachdb/README.md) +a [new CockroachDB collector](/src/go/plugin/go.d/modules/cockroachdb/README.md) released in [v1.20](https://blog.netdata.cloud/posts/release-1.20/), you can now monitor any number of CockroachDB databases with maximum granularity using Netdata. Collect more than 50 unique metrics and put them on interactive visualizations diff --git a/docs/developer-and-contributor-corner/monitor-hadoop-cluster.md b/docs/developer-and-contributor-corner/monitor-hadoop-cluster.md index 8ccaa935e..98bf3d21f 100644 --- a/docs/developer-and-contributor-corner/monitor-hadoop-cluster.md +++ b/docs/developer-and-contributor-corner/monitor-hadoop-cluster.md @@ -27,8 +27,8 @@ alternative, like the guide available from For more specifics on the collection modules used in this guide, read the respective pages in our documentation: -- [HDFS](/src/go/collectors/go.d.plugin/modules/hdfs/README.md) -- [Zookeeper](/src/go/collectors/go.d.plugin/modules/zookeeper/README.md) +- [HDFS](/src/go/plugin/go.d/modules/hdfs/README.md) +- [Zookeeper](/src/go/plugin/go.d/modules/zookeeper/README.md) ## Set up your HDFS and Zookeeper installations diff --git a/docs/developer-and-contributor-corner/pi-hole-raspberry-pi.md b/docs/developer-and-contributor-corner/pi-hole-raspberry-pi.md index 124b95421..df6bb0809 100644 --- a/docs/developer-and-contributor-corner/pi-hole-raspberry-pi.md +++ b/docs/developer-and-contributor-corner/pi-hole-raspberry-pi.md @@ -81,7 +81,7 @@ service](https://discourse.pi-hole.net/t/how-do-i-configure-my-devices-to-use-pi finished setting up Pi-hole at this point. As far as configuring Netdata to monitor Pi-hole metrics, there's nothing you actually need to do. Netdata's [Pi-hole -collector](/src/go/collectors/go.d.plugin/modules/pihole/README.md) will autodetect the new service +collector](/src/go/plugin/go.d/modules/pihole/README.md) will autodetect the new service running on your Raspberry Pi and immediately start collecting metrics every second. Restart Netdata with `sudo systemctl restart netdata`, which will then recognize that Pi-hole is running and start a diff --git a/docs/metric-correlations.md b/docs/metric-correlations.md index 46da43bc6..0467b8dd0 100644 --- a/docs/metric-correlations.md +++ b/docs/metric-correlations.md @@ -52,7 +52,7 @@ When a Metric Correlations request is made to Netdata Cloud, if any node instanc ## Usage tips -- When running Metric Correlations from the [Metrics tab](docs/dashboards-and-charts/metrics-tab-and-single-node-tabs.md) across multiple nodes, you might find better results if you iterate on the initial results by grouping by node to then filter to nodes of interest and rerun the Metric Correlations. So a typical workflow in this case would be to: +- When running Metric Correlations from the [Metrics tab](/docs/dashboards-and-charts/metrics-tab-and-single-node-tabs.md) across multiple nodes, you might find better results if you iterate on the initial results by grouping by node to then filter to nodes of interest and rerun the Metric Correlations. So a typical workflow in this case would be to: - If unsure which nodes you are interested in then run MC on all nodes. - Within the initial results returned group the most interesting chart by node to see if the changes are across all nodes or a subset of nodes. - If you see a subset of nodes clearly jump out when you group by node, then filter for just those nodes of interest and run the MC again. This will result in less aggregation needing to be done by Netdata and so should help give clearer results as you interact with the slider. diff --git a/docs/netdata-agent/configuration/optimizing-metrics-database/change-metrics-storage.md b/docs/netdata-agent/configuration/optimizing-metrics-database/change-metrics-storage.md index 8d940a730..8a8659eff 100644 --- a/docs/netdata-agent/configuration/optimizing-metrics-database/change-metrics-storage.md +++ b/docs/netdata-agent/configuration/optimizing-metrics-database/change-metrics-storage.md @@ -5,11 +5,13 @@ space**. This provides greater control and helps you optimize storage usage for **Default Retention Limits**: -| Tier | Resolution | Time Limit | Size Limit | -|:----:|:-------------------:|:----------:|:----------:| -| 0 | high (per second) | 14 days | 1 GiB | -| 1 | middle (per minute) | 3 months | 1 GiB | -| 2 | low (per hour) | 2 years | 1 GiB | +| Tier | Resolution | Time Limit | Size Limit (min 256 MB) | +|:----:|:-------------------:|:----------:|:-----------------------:| +| 0 | high (per second) | 14 days | 1 GiB | +| 1 | middle (per minute) | 3 months | 1 GiB | +| 2 | low (per hour) | 2 years | 1 GiB | + +> **Note**: If a user sets a disk space size less than 256 MB for a tier, Netdata will automatically adjust it to 256 MB. With these defaults, Netdata requires approximately 4 GiB of storage space (including metadata). diff --git a/docs/netdata-agent/securing-netdata-agents.md b/docs/netdata-agent/securing-netdata-agents.md index 4f6ff4094..5232173fb 100644 --- a/docs/netdata-agent/securing-netdata-agents.md +++ b/docs/netdata-agent/securing-netdata-agents.md @@ -69,6 +69,9 @@ that node no longer serves its local dashboard. `netdata.conf` and use
> `edit-config`.
+If you are using Netdata with Docker, make sure to set the `NETDATA_HEALTHCHECK_TARGET` environment variable to `cli`.
+
+
## Expose Netdata only in a private LAN
If your organisation has a private administration and management LAN, you can bind Netdata on this network interface on all your servers.
diff --git a/docs/netdata-agent/sizing-netdata-agents/disk-requirements-and-retention.md b/docs/netdata-agent/sizing-netdata-agents/disk-requirements-and-retention.md index d9e879cb6..7cd9a527d 100644 --- a/docs/netdata-agent/sizing-netdata-agents/disk-requirements-and-retention.md +++ b/docs/netdata-agent/sizing-netdata-agents/disk-requirements-and-retention.md @@ -2,41 +2,17 @@ ## Database Modes and Tiers -Netdata comes with 3 database modes: +Netdata offers two database modes to suit your needs for performance and data persistence: -1. `dbengine`: the default high-performance multi-tier database of Netdata. Metric samples are cached in memory and are saved to disk in multiple tiers, with compression. -2. `ram`: metric samples are stored in ring buffers in memory, with increments of 1024 samples. Metric samples are not committed to disk. Kernel-Same-Page (KSM) can be used to deduplicate Netdata's memory. -3. `alloc`: metric samples are stored in ring buffers in memory, with flexible increments. Metric samples are not committed to disk. - -## `ram` and `alloc` - -Modes `ram` and `alloc` can help when Netdata should not introduce any disk I/O at all. In both of these modes, metric samples exist only in memory, and only while they are collected. - -When Netdata is configured to stream its metrics to a Metrics Observability Centralization Point (a Netdata Parent), metric samples are forwarded in real-time to that Netdata Parent. The ring buffers available in these modes is used to cache the collected samples for some time, in case there are network issues, or the Netdata Parent is restarted for maintenance. - -The memory required per sample in these modes, is 4 bytes: - -- `ram` mode uses `mmap()` behind the scene, and can be incremented in steps of 1024 samples (4KiB). Mode `ram` allows the use of the Linux kernel memory dedupper (Kernel-Same-Page or KSM) to deduplicate Netdata ring buffers and save memory. -- `alloc` mode can be sized for any number of samples per metric. KSM cannot be used in this mode. - -To configure database mode `ram` or `alloc`, in `netdata.conf`, set the following: - -- `[db].mode` to either `ram` or `alloc`. -- `[db].retention` to the number of samples the ring buffers should maintain. For `ram` if the value set is not a multiple of 1024, the next multiple of 1024 will be used. +| Mode | Description | +|:------------------:|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------| +| dbengine (default) | High-performance, multi-tier storage with compression. Metric samples are cached in memory and then written to disk in multiple tiers for efficient retrieval and long-term storage. | +| ram | In-memory storage. Metric samples are stored in memory only, and older data is overwritten as new data arrives. This mode prioritizes speed, making it ideal for Netdata Child instances that stream data to a central Netdata parent. | ## `dbengine` -`dbengine` supports up to 5 tiers. By default, 3 tiers are used, like this: - -| Tier | Resolution | Uncompressed Sample Size | Usually On Disk | -|:--------:|:--------------------------------------------------------------------------------------------:|:------------------------:|:---------------:| -| `tier0` | native resolution (metrics collected per-second as stored per-second) | 4 bytes | 0.6 bytes | -| `tier1` | 60 iterations of `tier0`, so when metrics are collected per-second, this tier is per-minute. | 16 bytes | 6 bytes | -| `tier2` | 60 iterations of `tier1`, so when metrics are collected per second, this tier is per-hour. | 16 bytes | 18 bytes | - -Data are saved to disk compressed, so the actual size on disk varies depending on compression efficiency. - -`dbegnine` tiers are overlapping, so higher tiers include a down-sampled version of the samples in lower tiers: +Netdata's `dbengine` mode efficiently stores data on disk using compression. The actual disk space used depends on how well the data compresses. +This mode utilizes a tiered storage approach: data is saved in multiple tiers on disk. Each tier retains data at a different resolution (detail level). Higher tiers store a down-sampled (less detailed) version of the data found in lower tiers. ```mermaid gantt @@ -49,83 +25,28 @@ gantt tier2, 365d :a3, 2023-11-02, 59d ``` -## Disk Space and Metrics Retention - -You can find information about the current disk utilization of a Netdata Parent, at <http://agent-ip:19999/api/v2/info>. The output of this endpoint is like this: - -```json -{ - // more information about the agent - // then, near the end: - "db_size": [ - { - "tier": 0, - "metrics": 43070, - "samples": 88078162001, - "disk_used": 41156409552, - "disk_max": 41943040000, - "disk_percent": 98.1245269, - "from": 1705033983, - "to": 1708856640, - "retention": 3822657, - "expected_retention": 3895720, - "currently_collected_metrics": 27424 - }, - { - "tier": 1, - "metrics": 72987, - "samples": 5155155269, - "disk_used": 20585157180, - "disk_max": 20971520000, - "disk_percent": 98.1576785, - "from": 1698287340, - "to": 1708856640, - "retention": 10569300, - "expected_retention": 10767675, - "currently_collected_metrics": 27424 - }, - { - "tier": 2, - "metrics": 148234, - "samples": 314919121, - "disk_used": 5957346684, - "disk_max": 10485760000, - "disk_percent": 56.8136853, - "from": 1667808000, - "to": 1708856640, - "retention": 41048640, - "expected_retention": 72251324, - "currently_collected_metrics": 27424 - } - ] -} -``` +`dbengine` supports up to 5 tiers. By default, 3 tiers are used: + +| Tier | Resolution | Uncompressed Sample Size | Usually On Disk | +|:-------:|:--------------------------------------------------------------------------------------------:|:------------------------:|:---------------:| +| `tier0` | native resolution (metrics collected per-second as stored per-second) | 4 bytes | 0.6 bytes | +| `tier1` | 60 iterations of `tier0`, so when metrics are collected per-second, this tier is per-minute. | 16 bytes | 6 bytes | +| `tier2` | 60 iterations of `tier1`, so when metrics are collected per second, this tier is per-hour. | 16 bytes | 18 bytes | + +**Configuring dbengine mode and retention**: + +- Enable dbengine mode: The dbengine mode is already the default, so no configuration change is necessary. For reference, the dbengine mode can be configured by setting `[db].mode` to `dbengine` in `netdata.conf`. +- Adjust retention (optional): see [Change how long Netdata stores metrics](/docs/netdata-agent/configuration/optimizing-metrics-database/change-metrics-storage.md). + +## `ram` + +`ram` mode can help when Netdata should not introduce any disk I/O at all. In both of these modes, metric samples exist only in memory, and only while they are collected. + +When Netdata is configured to stream its metrics to a Metrics Observability Centralization Point (a Netdata Parent), metric samples are forwarded in real-time to that Netdata Parent. The ring buffers available in these modes is used to cache the collected samples for some time, in case there are network issues, or the Netdata Parent is restarted for maintenance. + +The memory required per sample in these modes, is 4 bytes: `ram` mode uses `mmap()` behind the scene, and can be incremented in steps of 1024 samples (4KiB). Mode `ram` allows the use of the Linux kernel memory dedupper (Kernel-Same-Page or KSM) to deduplicate Netdata ring buffers and save memory. + +**Configuring ram mode and retention**: -In this example: - -- `tier` is the database tier. -- `metrics` is the number of unique time-series in the database. -- `samples` is the number of samples in the database. -- `disk_used` is the currently used disk space in bytes. -- `disk_max` is the configured max disk space in bytes. -- `disk_percent` is the current disk space utilization for this tier. -- `from` is the first (oldest) timestamp in the database for this tier. -- `to` is the latest (newest) timestamp in the database for this tier. -- `retention` is the current retention of the database for this tier, in seconds (divide by 3600 for hours, divide by 86400 for days). -- `expected_retention` is the expected retention in seconds when `disk_percent` will be 100 (divide by 3600 for hours, divide by 86400 for days). -- `currently_collected_metrics` is the number of unique time-series currently being collected for this tier. - -So, for our example above: - -| Tier | # Of Metrics | # Of Samples | Disk Used | Disk Free | Current Retention | Expected Retention | Sample Size | -|-----:|-------------:|--------------:|----------:|----------:|------------------:|-------------------:|------------:| -| 0 | 43.1K | 88.1 billion | 38.4Gi | 1.88% | 44.2 days | 45.0 days | 0.46 B | -| 1 | 73.0K | 5.2 billion | 19.2Gi | 1.84% | 122.3 days | 124.6 days | 3.99 B | -| 2 | 148.3K | 315.0 million | 5.6Gi | 43.19% | 475.1 days | 836.2 days | 18.91 B | - -To configure retention, in `netdata.conf`, set the following: - -- `[db].mode` to `dbengine`. -- `[db].dbengine multihost disk space MB`, this is the max disk size for `tier0`. The default is 256MiB. -- `[db].dbengine tier 1 multihost disk space MB`, this is the max disk space for `tier1`. The default is 50% of `tier0`. -- `[db].dbengine tier 2 multihost disk space MB`, this is the max disk space for `tier2`. The default is 50% of `tier1`. +- Enable ram mode: To use in-memory storage, set `[db].mode` to ram in your `netdata.conf` file. Remember, this mode won't retain historical data after restarts. +- Adjust retention (optional): While ram mode focuses on real-time data, you can optionally control the number of samples stored in memory. Set `[db].retention` in `netdata.conf` to the desired number in seconds. Note: If the value you choose isn't a multiple of 1024, Netdata will automatically round it up to the nearest multiple. diff --git a/docs/netdata-cloud/authentication-and-authorization/role-based-access-model.md b/docs/netdata-cloud/authentication-and-authorization/role-based-access-model.md index fec33ca22..d2a3ea4f2 100644 --- a/docs/netdata-cloud/authentication-and-authorization/role-based-access-model.md +++ b/docs/netdata-cloud/authentication-and-authorization/role-based-access-model.md @@ -11,7 +11,7 @@ being able to join any Room. We also aligned the offered roles to the target aud |:------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:-------------------|:-------------------|:-------------------|:--------------------------| | **Admins**<p>Users with this role can control Spaces, Rooms, Nodes, Users and Billing.</p><p>They can also access any Room in the Space.</p> | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | | **Managers**<p>Users with this role can manage Rooms and Users.</p><p>They can access any Room in the Space.</p> | - | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | -| **Troubleshooters**<p>Users with this role can use Netdata to troubleshoot, not manage entities.</p><p>They can access any Room in the Space.</p> | - | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | +| **Troubleshooters**<p>Users with this role can use Netdata to troubleshoot, not manage entities.</p><p>They need to be assigned to Rooms in the Space.</p> | - | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | | **Observers**<p>Users with this role can only view data in specific Rooms.</p>💡 Ideal for restricting your customer's access to their own dedicated rooms.<p></p> | - | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | | **Billing**<p>Users with this role can handle billing options and invoices.</p> | - | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | | **Member** ⚠️ Legacy role<p>Users with this role you can create Rooms and invite other Members.</p><p>They can only see the Rooms they belong to and all Nodes in the All Nodes Room.</p> | - | - | - | - | @@ -36,7 +36,7 @@ In more detail, you can find on the following tables which functionalities are a | **Functionality** | **Admin** | **Manager** | **Troubleshooter** | **Observer** | **Billing** | **Member** | Notes | |:------------------------------------------|:------------------:|:------------------:|:------------------:|:------------:|:-----------:|:------------------:|:-------------------------------------------| -| See all Nodes in Space (_All Nodes_ Room) | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | - | - | :heavy_check_mark: | Members are always on the _All Nodes_ Room | +| See all Nodes in Space (_All Nodes_ Room) | :heavy_check_mark: | :heavy_check_mark: | - | - | - | :heavy_check_mark: | Members are always on the _All Nodes_ Room | | Connect Node to Space | :heavy_check_mark: | - | - | - | - | - | - | | Delete Node from Space | :heavy_check_mark: | - | - | - | - | - | - | @@ -62,8 +62,8 @@ In more detail, you can find on the following tables which functionalities are a | **Functionality** | **Admin** | **Manager** | **Troubleshooter** | **Observer** | **Billing** | **Member** | Notes | |:-----------------------------|:------------------:|:------------------:|:------------------:|:------------------:|:-----------:|:------------------:|:-----------------------------------------------------------------------------------| -| See all Rooms in a Space | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | - | - | - | | -| Join any Room in a Space | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | - | - | - | By joining a Room you will be enabled to get notifications from nodes on that Room | +| See all Rooms in a Space | :heavy_check_mark: | :heavy_check_mark: | - | - | - | - | | +| Join any Room in a Space | :heavy_check_mark: | :heavy_check_mark: | - | - | - | - | By joining a Room you will be enabled to get notifications from nodes on that Room | | Leave Room | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | - | :heavy_check_mark: | | | Create a new Room in a Space | :heavy_check_mark: | :heavy_check_mark: | - | - | - | :heavy_check_mark: | | | Delete Room | :heavy_check_mark: | :heavy_check_mark: | - | - | - | - | | @@ -145,7 +145,6 @@ Netdata Cloud paid subscription required for all action except "List All". | View | :heavy_check_mark: | :heavy_check_mark: | - | - | - | - | | View File Format | :heavy_check_mark: | :heavy_check_mark: | - | - | - | - | - ### Other permissions | **Functionality** | **Admin** | **Manager** | **Troubleshooter** | **Observer** | **Billing** | **Member** | diff --git a/docs/netdata-cloud/organize-your-infrastructure-invite-your-team.md b/docs/netdata-cloud/organize-your-infrastructure-invite-your-team.md index 1ca004d99..05538a916 100644 --- a/docs/netdata-cloud/organize-your-infrastructure-invite-your-team.md +++ b/docs/netdata-cloud/organize-your-infrastructure-invite-your-team.md @@ -41,7 +41,7 @@ We recommend a few strategies for organizing your Rooms. If you have a user-facing SaaS product, or an internal service that this said product relies on, you may want to monitor that entire stack in a single Room. This might include Kubernetes clusters, Docker containers, proxies, databases, web servers, brokers, and more. End-to-end Rooms are valuable tools for ensuring the health and performance of your organization's essential services. - **Incident response** - You can also create new Rooms as one of the first steps in your incident response process. For example, you have a user-facing web app that relies on Apache Pulsar for a message queue, and one of your nodes using the [Pulsar collector](/src/go/collectors/go.d.plugin/modules/pulsar/README.md) begins reporting a suspiciously low messages rate. You can create a Room called `$year-$month-$day-pulsar-rate`, add all your Pulsar nodes in addition to nodes they connect to, and begin diagnosing the root cause in a Room optimized for getting to resolution as fast as possible. + You can also create new Rooms as one of the first steps in your incident response process. For example, you have a user-facing web app that relies on Apache Pulsar for a message queue, and one of your nodes using the [Pulsar collector](/src/go/plugin/go.d/modules/pulsar/README.md) begins reporting a suspiciously low messages rate. You can create a Room called `$year-$month-$day-pulsar-rate`, add all your Pulsar nodes in addition to nodes they connect to, and begin diagnosing the root cause in a Room optimized for getting to resolution as fast as possible. ### Add Rooms |