
diff options
| author | Daniel Baumann <daniel.baumann@progress-linux.org> | 2021-12-14 16:28:27 +0000 |
|---|---|---|
| committer | Daniel Baumann <daniel.baumann@progress-linux.org> | 2021-12-14 16:28:34 +0000 |
| commit | 6abff7058da6b5bd0d8be156362a42ea458d6246 (patch) | |
| tree | 0bc2b2bb2dc1595e0bc281b58de3e2b0161bc9ca /docs/guides | |
| parent | Releasing debian version 1.32.0-1. (diff) | |
| download | netdata-6abff7058da6b5bd0d8be156362a42ea458d6246.tar.xz netdata-6abff7058da6b5bd0d8be156362a42ea458d6246.zip | |
Merging upstream version 1.32.1.
Signed-off-by: Daniel Baumann <daniel.baumann@progress-linux.org>
Diffstat (limited to 'docs/guides')
| -rw-r--r-- | docs/guides/monitor/anomaly-detection-python.md | 189 | ||||
| -rw-r--r-- | docs/guides/monitor/anomaly-detection.md | 363 | ||||
| -rw-r--r-- | docs/guides/monitor/raspberry-pi-anomaly-detection.md | 8 | ||||
| -rw-r--r-- | docs/guides/monitor/visualize-monitor-anomalies.md | 18 |
4 files changed, 423 insertions, 155 deletions
diff --git a/docs/guides/monitor/anomaly-detection-python.md b/docs/guides/monitor/anomaly-detection-python.md new file mode 100644 index 000000000..d10e9da4f --- /dev/null +++ b/docs/guides/monitor/anomaly-detection-python.md @@ -0,0 +1,189 @@ +<!-- +title: "Detect anomalies in systems and applications" +description: "Detect anomalies in any system, container, or application in your infrastructure with machine learning and the open-source Netdata Agent." +image: /img/seo/guides/monitor/anomaly-detection.png +author: "Joel Hans" +author_title: "Editorial Director, Technical & Educational Resources" +author_img: "/img/authors/joel-hans.jpg" +custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/guides/monitor/anomaly-detection-python.md +--> + +# Detect anomalies in systems and applications + +Beginning with v1.27, the [open-source Netdata Agent](https://github.com/netdata/netdata) is capable of unsupervised +[anomaly detection](https://en.wikipedia.org/wiki/Anomaly_detection) with machine learning (ML). As with all things +Netdata, the anomalies collector comes with preconfigured alarms and instant visualizations that require no query +languages or organizing metrics. You configure the collector to look at specific charts, and it handles the rest. + +Netdata's implementation uses a handful of functions in the [Python Outlier Detection (PyOD) +library](https://github.com/yzhao062/pyod/tree/master), which periodically runs a `train` function that learns what +"normal" looks like on your node and creates an ML model for each chart, then utilizes the +[`predict_proba()`](https://pyod.readthedocs.io/en/latest/api_cc.html#pyod.models.base.BaseDetector.predict_proba) and +[`predict()`](https://pyod.readthedocs.io/en/latest/api_cc.html#pyod.models.base.BaseDetector.predict) PyOD functions to +quantify how anomalous certain charts are. + +All these metrics and alarms are available for centralized monitoring in [Netdata Cloud](https://app.netdata.cloud). If +you choose to sign up for Netdata Cloud and [coonect your nodes](/claim/README.md), you will have the ability to run +tailored anomaly detection on every node in your infrastructure, regardless of its purpose or workload. + +In this guide, you'll learn how to set up the anomalies collector to instantly detect anomalies in an Nginx web server +and/or the node that hosts it, which will give you the tools to configure parallel unsupervised monitors for any +application in your infrastructure. Let's get started. + +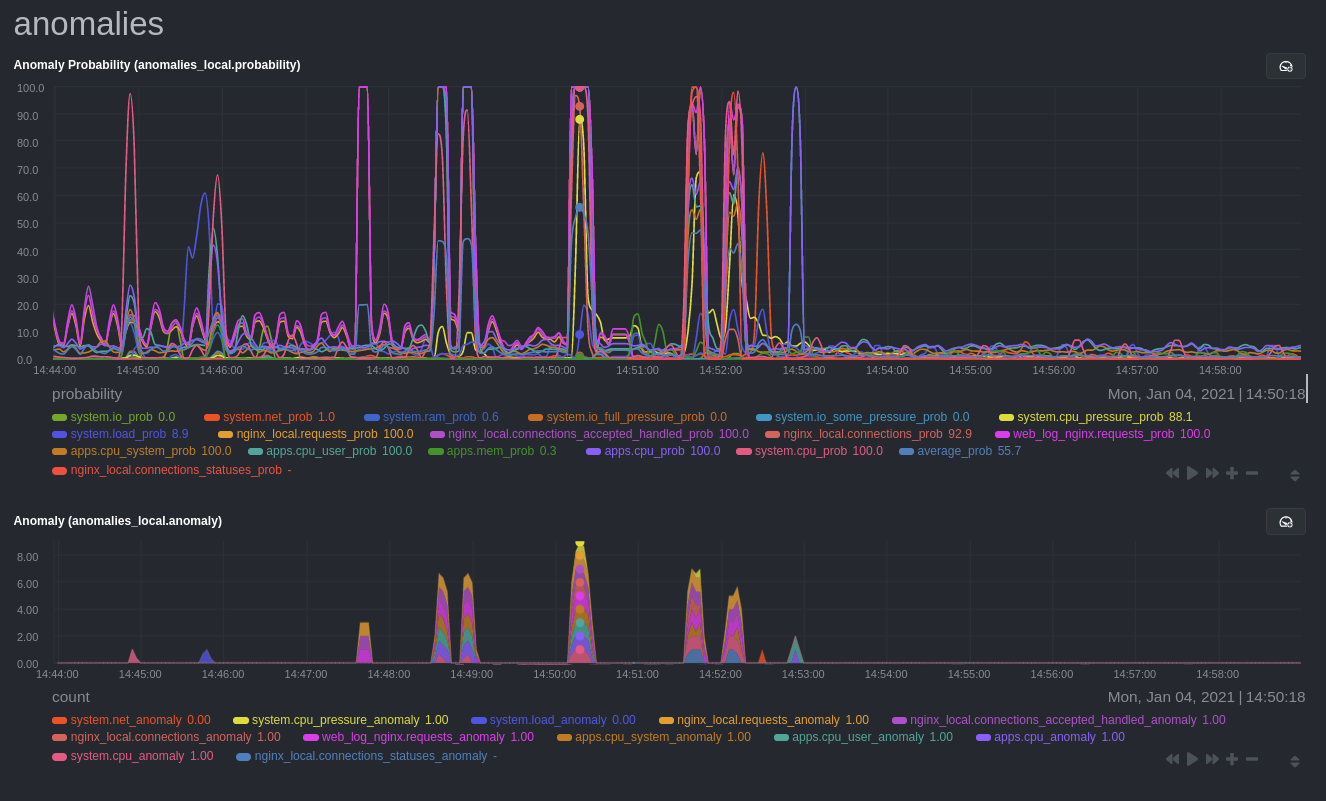 + +## Prerequisites + +- A node running the Netdata Agent. If you don't yet have that, [get Netdata](/docs/get-started.mdx). +- A Netdata Cloud account. [Sign up](https://app.netdata.cloud) if you don't have one already. +- Familiarity with configuring the Netdata Agent with [`edit-config`](/docs/configure/nodes.md). +- _Optional_: An Nginx web server running on the same node to follow the example configuration steps. + +## Install required Python packages + +The anomalies collector uses a few Python packages, available with `pip3`, to run ML training. It requires +[`numba`](http://numba.pydata.org/), [`scikit-learn`](https://scikit-learn.org/stable/), +[`pyod`](https://pyod.readthedocs.io/en/latest/), in addition to +[`netdata-pandas`](https://github.com/netdata/netdata-pandas), which is a package built by the Netdata team to pull data +from a Netdata Agent's API into a [Pandas](https://pandas.pydata.org/). Read more about `netdata-pandas` on its [package +repo](https://github.com/netdata/netdata-pandas) or in Netdata's [community +repo](https://github.com/netdata/community/tree/main/netdata-agent-api/netdata-pandas). + +```bash +# Become the netdata user +sudo su -s /bin/bash netdata + +# Install required packages for the netdata user +pip3 install --user netdata-pandas==0.0.38 numba==0.50.1 scikit-learn==0.23.2 pyod==0.8.3 +``` + +> If the `pip3` command fails, you need to install it. For example, on an Ubuntu system, use `sudo apt install +> python3-pip`. + +Use `exit` to become your normal user again. + +## Enable the anomalies collector + +Navigate to your [Netdata config directory](/docs/configure/nodes.md#the-netdata-config-directory) and use `edit-config` +to open the `python.d.conf` file. + +```bash +sudo ./edit-config python.d.conf +``` + +In `python.d.conf` file, search for the `anomalies` line. If the line exists, set the value to `yes`. Add the line +yourself if it doesn't already exist. Either way, the final result should look like: + +```conf +anomalies: yes +``` + +[Restart the Agent](/docs/configure/start-stop-restart.md) with `sudo systemctl restart netdata`, or the [appropriate +method](/docs/configure/start-stop-restart.md) for your system, to start up the anomalies collector. By default, the +model training process runs every 30 minutes, and uses the previous 4 hours of metrics to establish a baseline for +health and performance across the default included charts. + +> 💡 The anomaly collector may need 30-60 seconds to finish its initial training and have enough data to start +> generating anomaly scores. You may need to refresh your browser tab for the **Anomalies** section to appear in menus +> on both the local Agent dashboard or Netdata Cloud. + +## Configure the anomalies collector + +Open `python.d/anomalies.conf` with `edit-conf`. + +```bash +sudo ./edit-config python.d/anomalies.conf +``` + +The file contains many user-configurable settings with sane defaults. Here are some important settings that don't +involve tweaking the behavior of the ML training itself. + +- `charts_regex`: Which charts to train models for and run anomaly detection on, with each chart getting a separate + model. +- `charts_to_exclude`: Specific charts, selected by the regex in `charts_regex`, to exclude. +- `train_every_n`: How often to train the ML models. +- `train_n_secs`: The number of historical observations to train each model on. The default is 4 hours, but if your node + doesn't have historical metrics going back that far, consider [changing the metrics retention + policy](/docs/store/change-metrics-storage.md) or reducing this window. +- `custom_models`: A way to define custom models that you want anomaly probabilities for, including multi-node or + streaming setups. + +> ⚠️ Setting `charts_regex` with many charts or `train_n_secs` to a very large number will have an impact on the +> resources and time required to train a model for every chart. The actual performance implications depend on the +> resources available on your node. If you plan on changing these settings beyond the default, or what's mentioned in +> this guide, make incremental changes to observe the performance impact. Considering `train_max_n` to cap the number of +> observations actually used to train on. + +### Run anomaly detection on Nginx and log file metrics + +As mentioned above, this guide uses an Nginx web server to demonstrate how the anomalies collector works. You must +configure the collector to monitor charts from the +[Nginx](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/nginx) and [web +log](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/weblog) collectors. + +`charts_regex` allows for some basic regex, such as wildcards (`*`) to match all contexts with a certain pattern. For +example, `system\..*` matches with any chart with a context that begins with `system.`, and ends in any number of other +characters (`.*`). Note the escape character (`\`) around the first period to capture a period character exactly, and +not any character. + +Change `charts_regex` in `anomalies.conf` to the following: + +```conf + charts_regex: 'system\..*|nginx_local\..*|web_log_nginx\..*|apps.cpu|apps.mem' +``` + +This value tells the anomaly collector to train against every `system.` chart, every `nginx_local` chart, every +`web_log_nginx` chart, and specifically the `apps.cpu` and `apps.mem` charts. + +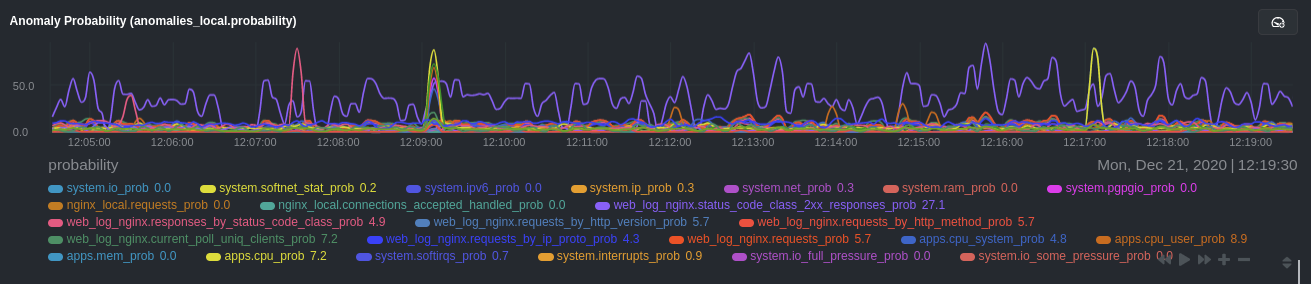 + +### Remove some metrics from anomaly detection + +As you can see in the above screenshot, this node is now looking for anomalies in many places. The result is a single +`anomalies_local.probability` chart with more than twenty dimensions, some of which the dashboard hides at the bottom of +a scroll-able area. In addition, training and analyzing the anomaly collector on many charts might require more CPU +utilization that you're willing to give. + +First, explicitly declare which `system.` charts to monitor rather than of all of them using regex (`system\..*`). + +```conf + charts_regex: 'system\.cpu|system\.load|system\.io|system\.net|system\.ram|nginx_local\..*|web_log_nginx\..*|apps.cpu|apps.mem' +``` + +Next, remove some charts with the `charts_to_exclude` setting. For this example, using an Nginx web server, focus on the +volume of requests/responses, not, for example, which type of 4xx response a user might receive. + +```conf + charts_to_exclude: 'web_log_nginx.excluded_requests,web_log_nginx.responses_by_status_code_class,web_log_nginx.status_code_class_2xx_responses,web_log_nginx.status_code_class_4xx_responses,web_log_nginx.current_poll_uniq_clients,web_log_nginx.requests_by_http_method,web_log_nginx.requests_by_http_version,web_log_nginx.requests_by_ip_proto' +``` + +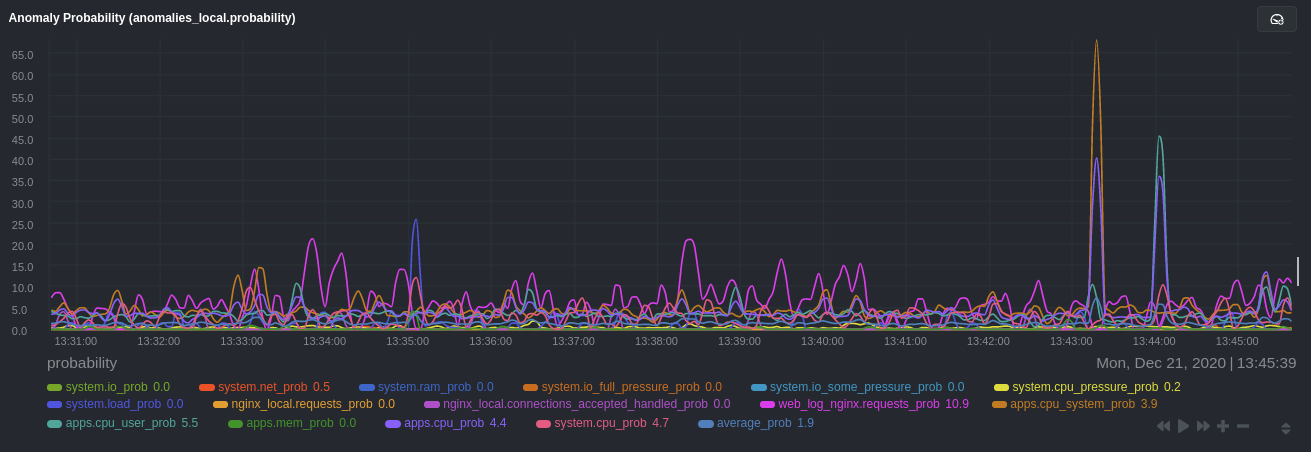 + +Apply the ideas behind the collector's regex and exclude settings to any other +[system](/docs/collect/system-metrics.md), [container](/docs/collect/container-metrics.md), or +[application](/docs/collect/application-metrics.md) metrics you want to detect anomalies for. + +## What's next? + +Now that you know how to set up unsupervised anomaly detection in the Netdata Agent, using an Nginx web server as an +example, it's time to apply that knowledge to other mission-critical parts of your infrastructure. If you're not sure +what to monitor next, check out our list of [collectors](/collectors/COLLECTORS.md) to see what kind of metrics Netdata +can collect from your systems, containers, and applications. + +Keep on moving to [part 2](/docs/guides/monitor/visualize-monitor-anomalies.md), which covers the charts and alarms +Netdata creates for unsupervised anomaly detection. + +For a different troubleshooting experience, try out the [Metric +Correlations](https://learn.netdata.cloud/docs/cloud/insights/metric-correlations) feature in Netdata Cloud. Metric +Correlations helps you perform faster root cause analysis by narrowing a dashboard to only the charts most likely to be +related to an anomaly. + +### Related reference documentation + +- [Netdata Agent · Anomalies collector](/collectors/python.d.plugin/anomalies/README.md) +- [Netdata Agent · Nginx collector](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/nginx) +- [Netdata Agent · web log collector](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/weblog) +- [Netdata Cloud · Metric Correlations](https://learn.netdata.cloud/docs/cloud/insights/metric-correlations) diff --git a/docs/guides/monitor/anomaly-detection.md b/docs/guides/monitor/anomaly-detection.md index 2d8b6d1d6..7b4388a05 100644 --- a/docs/guides/monitor/anomaly-detection.md +++ b/docs/guides/monitor/anomaly-detection.md @@ -1,191 +1,274 @@ <!-- -title: "Detect anomalies in systems and applications" +title: "Machine learning (ML) powered anomaly detection" description: "Detect anomalies in any system, container, or application in your infrastructure with machine learning and the open-source Netdata Agent." image: /img/seo/guides/monitor/anomaly-detection.png -author: "Joel Hans" -author_title: "Editorial Director, Technical & Educational Resources" -author_img: "/img/authors/joel-hans.jpg" -custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/guides/monitor/anomaly-detection.md +author: "Andrew Maguire" +author_title: "Analytics & ML Lead" +author_img: "/img/authors/andy-maguire.jpg" +custom_edit_url: https://github.com/netdata/netdata/edit/master/ml/README.md --> -# Detect anomalies in systems and applications +# Machine learning (ML) powered anomaly detection -Beginning with v1.27, the [open-source Netdata Agent](https://github.com/netdata/netdata) is capable of unsupervised -[anomaly detection](https://en.wikipedia.org/wiki/Anomaly_detection) with machine learning (ML). As with all things -Netdata, the anomalies collector comes with preconfigured alarms and instant visualizations that require no query -languages or organizing metrics. You configure the collector to look at specific charts, and it handles the rest. +## Overview -Netdata's implementation uses a handful of functions in the [Python Outlier Detection (PyOD) -library](https://github.com/yzhao062/pyod/tree/master), which periodically runs a `train` function that learns what -"normal" looks like on your node and creates an ML model for each chart, then utilizes the -[`predict_proba()`](https://pyod.readthedocs.io/en/latest/api_cc.html#pyod.models.base.BaseDetector.predict_proba) and -[`predict()`](https://pyod.readthedocs.io/en/latest/api_cc.html#pyod.models.base.BaseDetector.predict) PyOD functions to -quantify how anomalous certain charts are. +As of [`v1.32.0`](https://github.com/netdata/netdata/releases/tag/v1.32.0), Netdata comes with some ML powered [anomaly detection](https://en.wikipedia.org/wiki/Anomaly_detection) capabilities built into it and available to use out of the box, with minimal configuration required. -All these metrics and alarms are available for centralized monitoring in [Netdata Cloud](https://app.netdata.cloud). If -you choose to sign up for Netdata Cloud and [coonect your nodes](/claim/README.md), you will have the ability to run -tailored anomaly detection on every node in your infrastructure, regardless of its purpose or workload. +🚧 **Note**: This functionality is still under active development and considered experimental. Changes might cause the feature to break. We dogfood it internally and among early adopters within the Netdata community to build the feature. If you would like to get involved and help us with some feedback, email us at analytics-ml-team@netdata.cloud or come join us in the [🤖-ml-powered-monitoring](https://discord.gg/4eRSEUpJnc) channel of the Netdata discord. -In this guide, you'll learn how to set up the anomalies collector to instantly detect anomalies in an Nginx web server -and/or the node that hosts it, which will give you the tools to configure parallel unsupervised monitors for any -application in your infrastructure. Let's get started. +Once ML is enabled, Netdata will begin training a model for each dimension. By default this model is a [k-means clustering](https://en.wikipedia.org/wiki/K-means_clustering) model trained on the most recent 4 hours of data. Rather than just using the most recent value of each raw metric, the model works on a preprocessed ["feature vector"](#feature-vector) of recent smoothed and differenced values. This should enable the model to detect a wider range of potentially anomalous patterns in recent observations as opposed to just point anomalies like big spikes or drops. ([This infographic](https://user-images.githubusercontent.com/2178292/144414415-275a3477-5b47-43d6-8959-509eb48ebb20.png) shows some different types of anomalies.) - +The sections below will introduce some of the main concepts: +- anomaly bit +- anomaly score +- anomaly rate +- anomaly detector -## Prerequisites +Additional explanations and details can be found in the [Glossary](#glossary) and [Notes](#notes) at the bottom of the page. -- A node running the Netdata Agent. If you don't yet have that, [get Netdata](/docs/get-started.mdx). -- A Netdata Cloud account. [Sign up](https://app.netdata.cloud) if you don't have one already. -- Familiarity with configuring the Netdata Agent with [`edit-config`](/docs/configure/nodes.md). -- _Optional_: An Nginx web server running on the same node to follow the example configuration steps. +### Anomaly Bit - (100 = Anomalous, 0 = Normal) -## Install required Python packages +Once each model is trained, Netdata will begin producing an ["anomaly score"](#anomaly-score) at each time step for each dimension. This ["anomaly score"](#anomaly-score) is essentially a distance measure to the trained cluster centers of the model (by default each model has k=2, so two cluster centers are learned). More anomalous looking data should be more distant to those cluster centers. If this ["anomaly score"](#anomaly-score) is sufficiently large, this is a sign that the recent raw values of the dimension could potentially be anomalous. By default, "sufficiently large" means that the distance is in the 99th percentile or above of all distances observed during training or, put another way, it has to be further away than the furthest 1% of the data used during training. Once this threshold is passed, the ["anomaly bit"](#anomaly-bit) corresponding to that dimension is set to 100 to flag it as anomalous, otherwise it would be left at 0 to signal normal data. -The anomalies collector uses a few Python packages, available with `pip3`, to run ML training. It requires -[`numba`](http://numba.pydata.org/), [`scikit-learn`](https://scikit-learn.org/stable/), -[`pyod`](https://pyod.readthedocs.io/en/latest/), in addition to -[`netdata-pandas`](https://github.com/netdata/netdata-pandas), which is a package built by the Netdata team to pull data -from a Netdata Agent's API into a [Pandas](https://pandas.pydata.org/). Read more about `netdata-pandas` on its [package -repo](https://github.com/netdata/netdata-pandas) or in Netdata's [community -repo](https://github.com/netdata/community/tree/main/netdata-agent-api/netdata-pandas). +What this means is that in addition to the raw value of each metric, Netdata now also stores an ["anomaly bit"](#anomaly-bit) that is either 100 (anomalous) or 0 (normal). Importantly, this is achieved without additional storage overhead due to how the anomaly bit has been implemented within the existing internal Netdata storage representation. -```bash -# Become the netdata user -sudo su -s /bin/bash netdata +This ["anomaly bit"](#anomaly-bit) is exposed via the `anomaly-bit` key that can be passed to the `options` param of the `/api/v1/data` REST API. -# Install required packages for the netdata user -pip3 install --user netdata-pandas==0.0.38 numba==0.50.1 scikit-learn==0.23.2 pyod==0.8.3 -``` +For example, here are some recent raw dimension values for `system.ip` on our [london](http://london.my-netdata.io/) demo server: -> If the `pip3` command fails, you need to install it. For example, on an Ubuntu system, use `sudo apt install -> python3-pip`. +[`https://london.my-netdata.io/api/v1/data?chart=system.ip`](https://london.my-netdata.io/api/v1/data?chart=system.ip) -Use `exit` to become your normal user again. +``` +{ + "labels": ["time", "received", "sent"], + "data": + [ + [ 1638365672, 54.84098, -76.70201], + [ 1638365671, 124.4328, -309.7543], + [ 1638365670, 123.73152, -167.9056], + ... + ] +} +``` -## Enable the anomalies collector +And if we add the `&options=anomaly-bit` params, we can see the "anomaly bit" value corresponding to each raw dimension value: -Navigate to your [Netdata config directory](/docs/configure/nodes.md#the-netdata-config-directory) and use `edit-config` -to open the `python.d.conf` file. +[`https://london.my-netdata.io/api/v1/data?chart=system.ip&options=anomaly-bit`](https://london.my-netdata.io/api/v1/data?chart=system.ip&options=anomaly-bit) -```bash -sudo ./edit-config python.d.conf ``` +{ + "labels": ["time", "received", "sent"], + "data": + [ + [ 1638365672, 0, 0], + [ 1638365671, 0, 0], + [ 1638365670, 0, 0], + ... + ] +} +``` +In this example, the dimensions "received" and "sent" didn't show any abnormal behavior, so the anomaly bit is zero. +Under normal circumstances, the anomaly bit will mostly be 0. However, there can be random fluctuations setting the anomaly to 100, although this very much depends on the nature of the dimension in question. + +### Anomaly Rate - average(anomaly bit) -In `python.d.conf` file, search for the `anomalies` line. If the line exists, set the value to `yes`. Add the line -yourself if it doesn't already exist. Either way, the final result should look like: +Once all models have been trained, we can think of the Netdata dashboard as essentially a big matrix or table of 0's and 100's. If we consider this "anomaly bit"-based representation of the state of the node, we can now think about how we might detect overall node level anomalies. The figure below illustrates the main ideas. -```conf -anomalies: yes ``` + dimensions +time d1 d2 d3 d4 d5 NAR + 1 0 0 0 0 0 0% + 2 0 0 0 0 100 20% + 3 0 0 0 0 0 0% + 4 0 100 0 0 0 20% + 5 100 0 0 0 0 20% + 6 0 100 100 0 100 60% + 7 0 100 0 100 0 40% + 8 0 0 0 0 100 20% + 9 0 0 100 100 0 40% + 10 0 0 0 0 0 0% + +DAR 10% 30% 20% 20% 30% 22% NAR_t1-t10 + +DAR = Dimension Anomaly Rate +NAR = Node Anomaly Rate +NAR_t1-t10 = Node Anomaly Rate over t1 to t10 +``` + +To work out an ["anomaly rate"](#anomaly-rate), we can just average a row or a column in any direction. For example, if we were to just average along a row then this would be the ["node anomaly rate"](#node-anomaly-rate) (all dimensions) at time t. Likewise if we averaged a column then we would have the ["dimension anomaly rate"](#dimension-anomaly-rate) for each dimension over the time window t=1-10. Extending this idea, we can work out an overall ["anomaly rate"](#anomaly-rate) for the whole matrix or any subset of it we might be interested in. + +### Anomaly Detector - Node level anomaly events + +An ["anomaly detector"](#anomaly-detector) looks at all anomaly bits of a node. Netdata's anomaly detector produces an ["anomaly event"](#anomaly-event) when a the percentage of anomaly bits is high enough for a persistent amount of time. This anomaly event signals that there was sufficient evidence among all the anomaly bits that some strange behavior might have been detected in a more global sense across the node. + +Essentially if the ["Node Anomaly Rate"](#node-anomaly-rate) (NAR) passes a defined threshold and stays above that threshold for a persistent amount of time, a "Node [Anomaly Event](#anomaly-event)" will be triggered. -[Restart the Agent](/docs/configure/start-stop-restart.md) with `sudo systemctl restart netdata`, or the [appropriate -method](/docs/configure/start-stop-restart.md) for your system, to start up the anomalies collector. By default, the -model training process runs every 30 minutes, and uses the previous 4 hours of metrics to establish a baseline for -health and performance across the default included charts. +These anomaly events are currently exposed via `/api/v1/anomaly_events` -> 💡 The anomaly collector may need 30-60 seconds to finish its initial training and have enough data to start -> generating anomaly scores. You may need to refresh your browser tab for the **Anomalies** section to appear in menus -> on both the local Agent dashboard or Netdata Cloud. +**Note**: Clicking the link below will likely return an empty list of `[]`. This is the response when no anomaly events exist in the specified range. The example response below is illustrative of what the response would be when one or more anomaly events exist within the range of `after` to `before`. -## Configure the anomalies collector +https://london.my-netdata.io/api/v1/anomaly_events?after=1638365182000&before=1638365602000 -Open `python.d/anomalies.conf` with `edit-conf`. +If an event exists within the window, the result would be a list of start and end times. -```bash -sudo ./edit-config python.d/anomalies.conf ``` +[ + [ + 1638367788, + 1638367851 + ] +] +``` + +Information about each anomaly event can then be found at the `/api/v1/anomaly_event_info` endpoint (making sure to pass the `after` and `before` params): + +**Note**: If you click the below url you will get a `null` since no such anomaly event exists as the response is just an illustrative example taken from a node that did have such an anomaly event. -The file contains many user-configurable settings with sane defaults. Here are some important settings that don't -involve tweaking the behavior of the ML training itself. - -- `charts_regex`: Which charts to train models for and run anomaly detection on, with each chart getting a separate - model. -- `charts_to_exclude`: Specific charts, selected by the regex in `charts_regex`, to exclude. -- `train_every_n`: How often to train the ML models. -- `train_n_secs`: The number of historical observations to train each model on. The default is 4 hours, but if your node - doesn't have historical metrics going back that far, consider [changing the metrics retention - policy](/docs/store/change-metrics-storage.md) or reducing this window. -- `custom_models`: A way to define custom models that you want anomaly probabilities for, including multi-node or - streaming setups. - -> ⚠️ Setting `charts_regex` with many charts or `train_n_secs` to a very large number will have an impact on the -> resources and time required to train a model for every chart. The actual performance implications depend on the -> resources available on your node. If you plan on changing these settings beyond the default, or what's mentioned in -> this guide, make incremental changes to observe the performance impact. Considering `train_max_n` to cap the number of -> observations actually used to train on. - -### Run anomaly detection on Nginx and log file metrics - -As mentioned above, this guide uses an Nginx web server to demonstrate how the anomalies collector works. You must -configure the collector to monitor charts from the -[Nginx](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/nginx) and [web -log](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/weblog) collectors. - -`charts_regex` allows for some basic regex, such as wildcards (`*`) to match all contexts with a certain pattern. For -example, `system\..*` matches with any chart with a context that begins with `system.`, and ends in any number of other -characters (`.*`). Note the escape character (`\`) around the first period to capture a period character exactly, and -not any character. - -Change `charts_regex` in `anomalies.conf` to the following: - -```conf - charts_regex: 'system\..*|nginx_local\..*|web_log_nginx\..*|apps.cpu|apps.mem' +https://london.my-netdata.io/api/v1/anomaly_event_info?after=1638367788&before=1638367851 + +``` +[ + [ + 0.66, + "netdata.response_time|max" + ], + [ + 0.63, + "netdata.response_time|average" + ], + [ + 0.54, + "netdata.requests|requests" + ], + ... ``` -This value tells the anomaly collector to train against every `system.` chart, every `nginx_local` chart, every -`web_log_nginx` chart, and specifically the `apps.cpu` and `apps.mem` charts. +The query returns a list of dimension anomaly rates for all dimensions that were considered part of the detected anomaly event. - +**Note**: We plan to build additional anomaly detection and exploration features into both Netdata Agent and Netdata Cloud. The current endpoints are still under active development to power the upcoming features. -### Remove some metrics from anomaly detection +## Configuration -As you can see in the above screenshot, this node is now looking for anomalies in many places. The result is a single -`anomalies_local.probability` chart with more than twenty dimensions, some of which the dashboard hides at the bottom of -a scroll-able area. In addition, training and analyzing the anomaly collector on many charts might require more CPU -utilization that you're willing to give. +To enable anomaly detection: +1. Find and open the Netdata configuration file `netdata.conf`. +2. In the `[ml]` section, set `enabled = yes`. +3. Restart netdata (typically `sudo systemctl restart netdata`). -First, explicitly declare which `system.` charts to monitor rather than of all of them using regex (`system\..*`). +**Note**: If you would like to learn more about configuring Netdata please see [the configuration guide](https://learn.netdata.cloud/guides/step-by-step/step-04). -```conf - charts_regex: 'system\.cpu|system\.load|system\.io|system\.net|system\.ram|nginx_local\..*|web_log_nginx\..*|apps.cpu|apps.mem' +Below is a list of all the available configuration params and their default values. + +``` +[ml] + # enabled = no + # maximum num samples to train = 14400 + # minimum num samples to train = 3600 + # train every = 3600 + # num samples to diff = 1 + # num samples to smooth = 3 + # num samples to lag = 5 + # maximum number of k-means iterations = 1000 + # dimension anomaly score threshold = 0.99 + # host anomaly rate threshold = 0.01000 + # minimum window size = 30.00000 + # maximum window size = 600.00000 + # idle window size = 30.00000 + # window minimum anomaly rate = 0.25000 + # anomaly event min dimension rate threshold = 0.05000 + # hosts to skip from training = !* + # charts to skip from training = !system.* !cpu.* !mem.* !disk.* !disk_* !ip.* !ipv4.* !ipv6.* !net.* !net_* !netfilter.* !services.* !apps.* !groups.* !user.* !ebpf.* !netdata.* * ``` -Next, remove some charts with the `charts_to_exclude` setting. For this example, using an Nginx web server, focus on the -volume of requests/responses, not, for example, which type of 4xx response a user might receive. +### Descriptions (min/max) -```conf - charts_to_exclude: 'web_log_nginx.excluded_requests,web_log_nginx.responses_by_status_code_class,web_log_nginx.status_code_class_2xx_responses,web_log_nginx.status_code_class_4xx_responses,web_log_nginx.current_poll_uniq_clients,web_log_nginx.requests_by_http_method,web_log_nginx.requests_by_http_version,web_log_nginx.requests_by_ip_proto' -``` +- `enabled`: `yes` to enable, `no` to disable. +- `maximum num samples to train`: (`3600`/`21600`) This is the maximum amount of time you would like to train each model on. For example, the default of `14400` trains on the preceding 4 hours of data, assuming an `update every` of 1 second. +- `minimum num samples to train`: (`900`/`21600`) This is the minimum amount of data required to be able to train a model. For example, the default of `3600` implies that once at least 1 hour of data is available for training, a model is trained, otherwise it is skipped and checked again at the next training run. +- `train every`: (`1800`/`21600`) This is how often each model will be retrained. For example, the default of `3600` means that each model is retrained every hour. Note: The training of all models is spread out across the `train every` period for efficiency, so in reality, it means that each model will be trained in a staggered manner within each `train every` period. +- `num samples to diff`: (`0`/`1`) This is a `0` or `1` to determine if you want the model to operate on differences of the raw data or just the raw data. For example, the default of `1` means that we take differences of the raw values. Using differences is more general and works on dimensions that might naturally tend to have some trends or cycles in them that is normal behavior to which we don't want to be too sensitive. +- `num samples to smooth`: (`0`/`5`) This is a small integer that controls the amount of smoothing applied as part of the feature processing used by the model. For example, the default of `3` means that the rolling average of the last 3 values is used. Smoothing like this helps the model be a little more robust to spiky types of dimensions that naturally "jump" up or down as part of their normal behavior. +- `num samples to lag`: (`0`/`5`) This is a small integer that determines how many lagged values of the dimension to include in the feature vector. For example, the default of `5` means that in addition to the most recent (by default, differenced and smoothed) value of the dimension, the feature vector will also include the 5 previous values too. Using lagged values in our feature representation allows the model to work over strange patterns over recent values of a dimension as opposed to just focusing on if the most recent value itself is big or small enough to be anomalous. +- `maximum number of k-means iterations`: This is a parameter that can be passed to the model to limit the number of iterations in training the k-means model. Vast majority of cases can ignore and leave as default. +- `dimension anomaly score threshold`: (`0.01`/`5.00`) This is the threshold at which an individual dimension at a specific timestep is considered anomalous or not. For example, the default of `0.99` means that a dimension with an anomaly score of 99% or higher is flagged as anomalous. This is a normalized probability based on the training data, so the default of 99% means that anything that is as strange (based on distance measure) or more strange as the most strange 1% of data observed during training will be flagged as anomalous. If you wanted to make the anomaly detection on individual dimensions more sensitive you could try a value like `0.90` (90%) or to make it less sensitive you could try `1.5` (150%). +- `host anomaly rate threshold`: (`0.0`/`1.0`) This is the percentage of dimensions (based on all those enabled for anomaly detection) that need to be considered anomalous at specific timestep for the host itself to be considered anomalous. For example, the default value of `0.01` means that if more than 1% of dimensions are anomalous at the same time then the host itself is considered in an anomalous state. +- `minimum window size`: The Netdata "Anomaly Detector" logic works over a rolling window of data. This parameter defines the minimum length of window to consider. If over this window the host is in an anomalous state then an anomaly detection event will be triggered. For example, the default of `30` means that the detector will initially work over a rolling window of 30 seconds. Note: The length of this window will be dynamic once an anomaly event has been triggered such that it will expand as needed until either the max length of an anomaly event is hit or the host settles back into a normal state with sufficiently decreased host level anomaly states in the rolling window. Note: If you wanted to adjust the higher level anomaly detector behavior then this is one parameter you might adjust to see the impact of on anomaly detection events. +- `maximum window size`: This parameter defines the maximum length of window to consider. If an anomaly event reaches this size, it will be closed. This is to provide an upper bound on the length of an anomaly event and cost of the anomaly detector logic for that event. +- `window minimum anomaly rate`: (`0.0`/`1.0`) This parameter corresponds to a threshold on the percentage of time in the rolling window that the host was considered in an anomalous state. For example, the default of `0.25` means that if the host is in an anomalous state for 25% of more of the rolling window then and anomaly event will be triggered or extended if one is already active. Note: If you want to make the anomaly detector itself less sensitive, you can adjust this value to something like `0.75` which would mean the host needs to be much more consistently in an anomalous state to trigger an anomaly detection event. Likewise, a lower value like `0.1` would make the anomaly detector more sensitive. +- `anomaly event min dimension rate threshold`: (`0.0`/`1.0`) This is a parameter that helps filter out irrelevant dimensions from anomaly events. For example, the default of `0.05` means that only dimensions that were considered anomalous for at least 5% of the anomaly event itself will be included in that anomaly event. The idea here is to just include dimensions that were consistently anomalous as opposed to those that may have just randomly happened to be anomalous at the same time. +- `hosts to skip from training`: This parameter allows you to turn off anomaly detection for any child hosts on a parent host by defining those you would like to skip from training here. For example, a value like `dev-*` skips all hosts on a parent that begin with the "dev-" prefix. The default value of `!*` means "don't skip any". +- `charts to skip from training`: This parameter allows you to exclude certain charts from anomaly detection by defining them here. By default, all charts, apart from a specific allow list of the typical basic Netdata charts, are excluded. If you have additional charts you would like to include for anomaly detection, you can add them here. **Note**: It is recommended to add charts in small groups and then measure any impact on performance before adding additional ones. + +## Charts + +Once enabled, the "Anomaly Detection" menu and charts will be available on the dashboard. + + + +In terms of anomaly detection, the most interesting charts would be the `anomaly_detection.dimensions` and `anomaly_detection.anomaly_rate` ones, which hold the `anomalous` and `anomaly_rate` dimensions that show the overall number of dimensions considered anomalous at any time and the corresponding anomaly rate. + +- `anomaly_detection.dimensions`: Total count of dimensions considered anomalous or normal. +- `anomaly_detection.dimensions`: Percentage of anomalous dimensions. +- `anomaly_detection.detector_window`: The length of the active window used by the detector. +- `anomaly_detection.detector_events`: Flags (0 or 1) to show when an anomaly event has been triggered by the detector. +- `anomaly_detection.prediction_stats`: Diagnostic metrics relating to prediction time of anomaly detection. +- `anomaly_detection.training_stats`: Diagnostic metrics relating to training time of anomaly detection. + +Below is an example of how these charts may look in the presence of an anomaly event. + +Initially we see a jump in `anomalous` dimensions: + +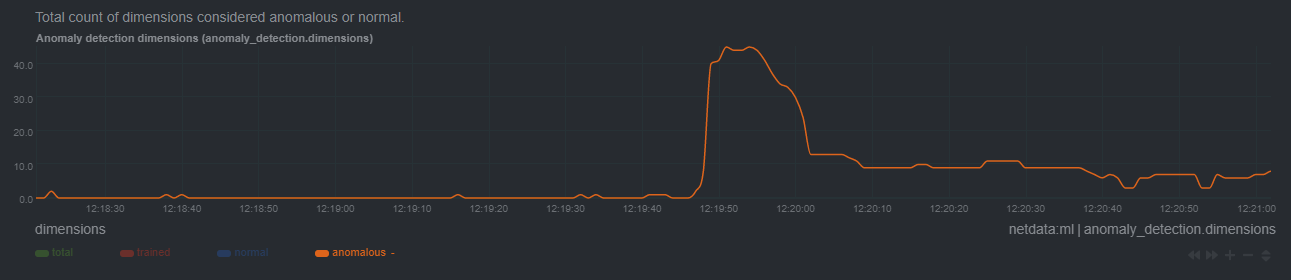 + +And a corresponding jump in the `anomaly_rate`: + +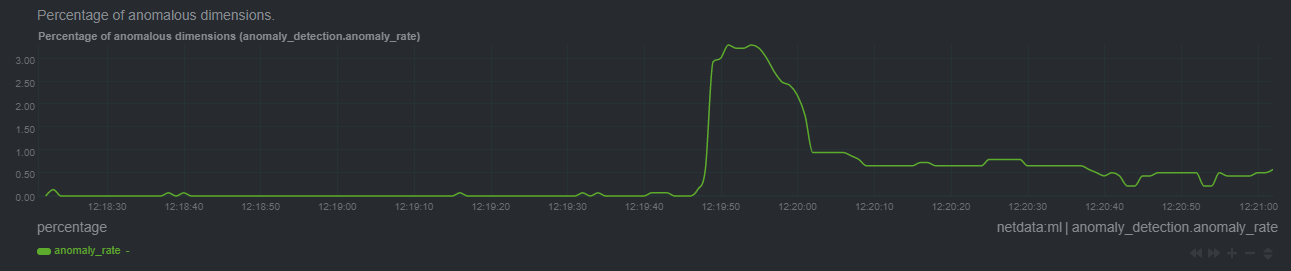 + +After a short while the rolling node anomaly rate goes `above_threshold`, and once it stays above threshold for long enough a `new_anomaly_event` is created: + +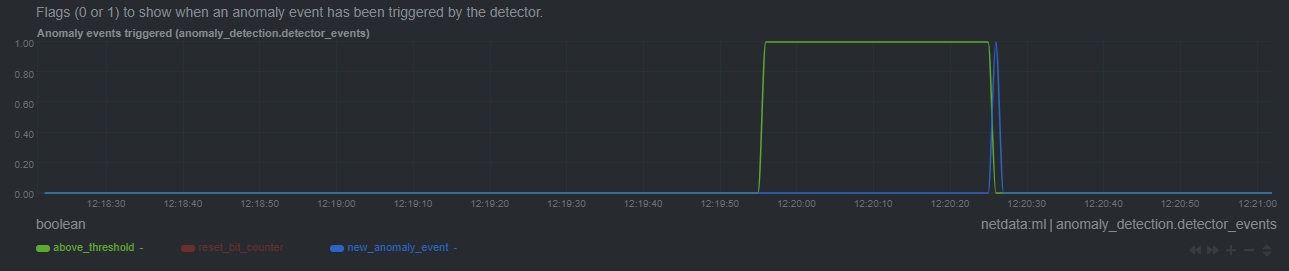 + +## Glossary + +#### _feature vector_ + +A [feature vector](https://en.wikipedia.org/wiki/Feature_(machine_learning)) is what the ML model is trained on and uses for prediction. The most simple feature vector would be just the latest raw dimension value itself [x]. By default Netdata will use a feature vector consisting of the 6 latest differences and smoothed values of the dimension so conceptually something like `[avg3(diff1(x-5)), avg3(diff1(x-4)), avg3(diff1(x-3)), avg3(diff1(x-2)), avg3(diff1(x-1)), avg3(diff1(x))]` which ends up being just 6 floating point numbers that try and represent the "shape" of recent data. + +#### _anomaly score_ + +At prediction time the anomaly score is just the distance of the most recent feature vector to the trained cluster centers of the model, which are themselves just feature vectors, albeit supposedly the best most representative feature vectors that could be "learned" from the training data. So if the most recent feature vector is very far away in terms of [euclidean distance](https://en.wikipedia.org/wiki/Euclidean_distance#:~:text=In%20mathematics%2C%20the%20Euclidean%20distance,being%20called%20the%20Pythagorean%20distance.) it's more likely that the recent data it represents consists of some strange pattern not commonly found in the training data. + +#### _anomaly bit_ + +If the anomaly score is greater than a specified threshold then the most recent feature vector, and hence most recent raw data, is considered anomalous. Since storing the raw anomaly score would essentially double amount of storage space Netdata would need, we instead efficiently store just the anomaly bit in the existing internal Netdata data representation without any additional storage overhead. + +#### _anomaly rate_ + +An anomaly rate is really just an average over one or more anomaly bits. An anomaly rate can be calculated over time for one or more dimensions or at a point in time across multiple dimensions, or some combination of the two. Its just an average of some collection of anomaly bits. + +#### _anomaly detector_ - +The is essentially business logic that just tries to process a collection of anomaly bits to determine if there is enough active anomaly bits to merit investigation or declaration of a node level anomaly event. -Apply the ideas behind the collector's regex and exclude settings to any other -[system](/docs/collect/system-metrics.md), [container](/docs/collect/container-metrics.md), or -[application](/docs/collect/application-metrics.md) metrics you want to detect anomalies for. +#### _anomaly event_ -## What's next? +Anomaly events are triggered by the anomaly detector and represent a window of time on the node with sufficiently elevated anomaly rates across all dimensions. -Now that you know how to set up unsupervised anomaly detection in the Netdata Agent, using an Nginx web server as an -example, it's time to apply that knowledge to other mission-critical parts of your infrastructure. If you're not sure -what to monitor next, check out our list of [collectors](/collectors/COLLECTORS.md) to see what kind of metrics Netdata -can collect from your systems, containers, and applications. +#### _dimension anomaly rate_ -Keep on moving to [part 2](/docs/guides/monitor/visualize-monitor-anomalies.md), which covers the charts and alarms -Netdata creates for unsupervised anomaly detection. +The anomaly rate of a specific dimension over some window of time. -For a different troubleshooting experience, try out the [Metric -Correlations](https://learn.netdata.cloud/docs/cloud/insights/metric-correlations) feature in Netdata Cloud. Metric -Correlations helps you perform faster root cause analysis by narrowing a dashboard to only the charts most likely to be -related to an anomaly. +#### _node anomaly rate_ -### Related reference documentation +The anomaly rate across all dimensions of a node. -- [Netdata Agent · Anomalies collector](/collectors/python.d.plugin/anomalies/README.md) -- [Netdata Agent · Nginx collector](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/nginx) -- [Netdata Agent · web log collector](https://learn.netdata.cloud/docs/agent/collectors/go.d.plugin/modules/weblog) -- [Netdata Cloud · Metric Correlations](https://learn.netdata.cloud/docs/cloud/insights/metric-correlations) +## Notes -[](<>) +- We would love to hear any feedback relating to this functionality, please email us at analytics-ml-team@netdata.cloud or come join us in the [🤖-ml-powered-monitoring](https://discord.gg/4eRSEUpJnc) channel of the Netdata discord. +- We are working on additional UI/UX based features that build on these core components to make them as useful as possible out of the box. +- Although not yet a core focus of this work, users could leverage the `anomaly_detection` chart dimensions and/or `anomaly-bit` options in defining alarms based on ML driven anomaly detection models. +- [This presentation](https://docs.google.com/presentation/d/18zkCvU3nKP-Bw_nQZuXTEa4PIVM6wppH3VUnAauq-RU/edit?usp=sharing) walks through some of the main concepts covered above in a more informal way. +- After restart Netdata will wait until `minimum num samples to train` observations of data are available before starting training and prediction. +- Netdata uses [dlib](https://github.com/davisking/dlib) under the hood for its core ML features. +- You should benchmark Netdata resource usage before and after enabling ML. Typical overhead ranges from 1-2% additional CPU at most. +- The "anomaly bit" has been implemented to be a building block to underpin many more ML based use cases that we plan to deliver soon. +- At its core Netdata uses an approach and problem formulation very similar to the Netdata python [anomalies collector](https://learn.netdata.cloud/docs/agent/collectors/python.d.plugin/anomalies), just implemented in a much much more efficient and scalable way in the agent in c++. So if you would like to learn more about the approach and are familiar with Python that is a useful resource to explore, as is the corresponding [deep dive tutorial](https://nbviewer.org/github/netdata/community/blob/main/netdata-agent-api/netdata-pandas/anomalies_collector_deepdive.ipynb) where the default model used is PCA instead of K-Means but the overall approach and formulation is similar.
\ No newline at end of file diff --git a/docs/guides/monitor/raspberry-pi-anomaly-detection.md b/docs/guides/monitor/raspberry-pi-anomaly-detection.md index 90ad763b8..029dfcbc7 100644 --- a/docs/guides/monitor/raspberry-pi-anomaly-detection.md +++ b/docs/guides/monitor/raspberry-pi-anomaly-detection.md @@ -1,4 +1,4 @@ -<!-- +--- title: "Unsupervised anomaly detection for Raspberry Pi monitoring" description: "Use a low-overhead machine learning algorithm and an open-source monitoring tool to detect anomalous metrics on a Raspberry Pi." image: /img/seo/guides/monitor/raspberry-pi-anomaly-detection.png @@ -6,9 +6,7 @@ author: "Andy Maguire" author_title: "Senior Machine Learning Engineer" author_img: "/img/authors/andy-maguire.jpg" custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/guides/monitor/raspberry-pi-anomaly-detection.md ---> - -# Unsupervised anomaly detection for Raspberry Pi monitoring +--- We love IoT and edge at Netdata, we also love machine learning. Even better if we can combine the two to ease the pain of monitoring increasingly complex systems. @@ -110,7 +108,7 @@ looks like a potentially useful addition to enable unsupervised anomaly detectio See our two-part guide series for a more complete picture of configuring the anomalies collector, plus some best practices on using the charts it automatically generates: -- [_Detect anomalies in systems and applications_](/docs/guides/monitor/anomaly-detection.md) +- [_Detect anomalies in systems and applications_](/docs/guides/monitor/anomaly-detection-python.md) - [_Monitor and visualize anomalies with Netdata_](/docs/guides/monitor/visualize-monitor-anomalies.md) If you're using your Raspberry Pi for other purposes, like blocking ads/trackers with Pi-hole, check out our companions diff --git a/docs/guides/monitor/visualize-monitor-anomalies.md b/docs/guides/monitor/visualize-monitor-anomalies.md index 681ba8390..9eace5232 100644 --- a/docs/guides/monitor/visualize-monitor-anomalies.md +++ b/docs/guides/monitor/visualize-monitor-anomalies.md @@ -1,4 +1,4 @@ -<!-- +--- title: "Monitor and visualize anomalies with Netdata (part 2)" description: "Using unsupervised anomaly detection and machine learning, get notified " image: /img/seo/guides/monitor/visualize-monitor-anomalies.png @@ -6,13 +6,11 @@ author: "Joel Hans" author_title: "Editorial Director, Technical & Educational Resources" author_img: "/img/authors/joel-hans.jpg" custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/guides/monitor/visualize-monitor-anomalies.md ---> - -# Monitor and visualize anomalies with Netdata (part 2) +--- Welcome to part 2 of our series of guides on using _unsupervised anomaly detection_ to detect issues with your systems, containers, and applications using the open-source Netdata Agent. For an introduction to detecting anomalies and -monitoring associated metrics, see [part 1](/docs/guides/monitor/anomaly-detection.md), which covers prerequisites and +monitoring associated metrics, see [part 1](/docs/guides/monitor/anomaly-detection-python.md), which covers prerequisites and configuration basics. With anomaly detection in the Netdata Agent set up, you will now want to visualize and monitor which charts have @@ -50,8 +48,8 @@ analysis (RCA). The anomalies collector creates two "classes" of alarms for each chart captured by the `charts_regex` setting. All these alarms are preconfigured based on your [configuration in -`anomalies.conf`](/docs/guides/monitor/anomaly-detection.md#configure-the-anomalies-collector). With the `charts_regex` -and `charts_to_exclude` settings from [part 1](/docs/guides/monitor/anomaly-detection.md) of this guide series, the +`anomalies.conf`](/docs/guides/monitor/anomaly-detection-python.md#configure-the-anomalies-collector). With the `charts_regex` +and `charts_to_exclude` settings from [part 1](/docs/guides/monitor/anomaly-detection-python.md) of this guide series, the Netdata Agent creates 32 alarms driven by unsupervised anomaly detection. The first class triggers warning alarms when the average anomaly probability for a given chart has stayed above 50% for @@ -81,7 +79,7 @@ alarms for any dimension on the `anomalies_local.probability` and `anomalies_loc In either [Netdata Cloud](https://app.netdata.cloud) or the local Agent dashboard at `http://NODE:19999`, click on the **Anomalies** [section](/web/gui/README.md#sections) to see the pair of anomaly detection charts, which are preconfigured to visualize per-second anomaly metrics based on your [configuration in -`anomalies.conf`](/docs/guides/monitor/anomaly-detection.md#configure-the-anomalies-collector). +`anomalies.conf`](/docs/guides/monitor/anomaly-detection-python.md#configure-the-anomalies-collector). These charts have the contexts `anomalies.probability` and `anomalies.anomaly`. Together, these charts create meaningful visualizations for immediately recognizing not only that something is going wrong on your node, but @@ -90,7 +88,7 @@ give context as to where to look next. The `anomalies_local.probability` chart shows the probability that the latest observed data is anomalous, based on the trained model. The `anomalies_local.anomaly` chart visualizes 0→1 predictions based on whether the latest observed data is anomalous based on the trained model. Both charts share the same dimensions, which you configured via -`charts_regex` and `charts_to_exclude` in [part 1](/docs/guides/monitor/anomaly-detection.md). +`charts_regex` and `charts_to_exclude` in [part 1](/docs/guides/monitor/anomaly-detection-python.md). In other words, the `probability` chart shows the amplitude of the anomaly, whereas the `anomaly` chart provides quick yes/no context. @@ -126,7 +124,7 @@ the dashboard into only the charts relevant to what you're seeing from the anoma ## What's next? -Between this guide and [part 1](/docs/guides/monitor/anomaly-detection.md), which covered setup and configuration, you +Between this guide and [part 1](/docs/guides/monitor/anomaly-detection-python.md), which covered setup and configuration, you now have a fundamental understanding of how unsupervised anomaly detection in Netdata works, from root cause to alarms to preconfigured or custom dashboards. |