
diff options
Diffstat (limited to 'docs/guides/monitor/kubernetes-k8s-netdata.md')
| -rw-r--r-- | docs/guides/monitor/kubernetes-k8s-netdata.md | 16 |
1 files changed, 8 insertions, 8 deletions
diff --git a/docs/guides/monitor/kubernetes-k8s-netdata.md b/docs/guides/monitor/kubernetes-k8s-netdata.md index 96d79935b..982c35e79 100644 --- a/docs/guides/monitor/kubernetes-k8s-netdata.md +++ b/docs/guides/monitor/kubernetes-k8s-netdata.md @@ -146,7 +146,7 @@ Let's explore the most colorful box by hovering over it. container](https://user-images.githubusercontent.com/1153921/109049544-a8417980-7695-11eb-80a7-109b4a645a27.png) The **Context** tab shows `rabbitmq-5bb66bb6c9-6xr5b` as the container's image name, which means this container is -running a [RabbitMQ](https://github.com/netdata/go.d.plugin/blob/master/modules/rabbitmq/README.md) workload. +running a [RabbitMQ](https://github.com/netdata/netdata/blob/master/src/go/collectors/go.d.plugin/modules/rabbitmq/README.md) workload. Click the **Metrics** tab to see real-time metrics from that container. Unsurprisingly, it shows a spike in CPU utilization at regular intervals. @@ -175,13 +175,13 @@ for complete customization. For example, grouping the top chart by `k8s_containe Netdata has a [service discovery plugin](https://github.com/netdata/agent-service-discovery), which discovers and creates configuration files for [compatible services](https://github.com/netdata/helmchart#service-discovery-and-supported-services) and any endpoints covered by -our [generic Prometheus collector](https://github.com/netdata/go.d.plugin/blob/master/modules/prometheus/README.md). +our [generic Prometheus collector](https://github.com/netdata/netdata/blob/master/src/go/collectors/go.d.plugin/modules/prometheus/README.md). Netdata uses these files to collect metrics from any compatible application as they run _inside_ of a pod. Service discovery happens without manual intervention as pods are created, destroyed, or moved between nodes. Service metrics show up on the Overview as well, beneath the **Kubernetes** section, and are labeled according to the service in question. For example, the **RabbitMQ** section has numerous charts from the [`rabbitmq` -collector](https://github.com/netdata/go.d.plugin/blob/master/modules/rabbitmq/README.md): +collector](https://github.com/netdata/netdata/blob/master/src/go/collectors/go.d.plugin/modules/rabbitmq/README.md): 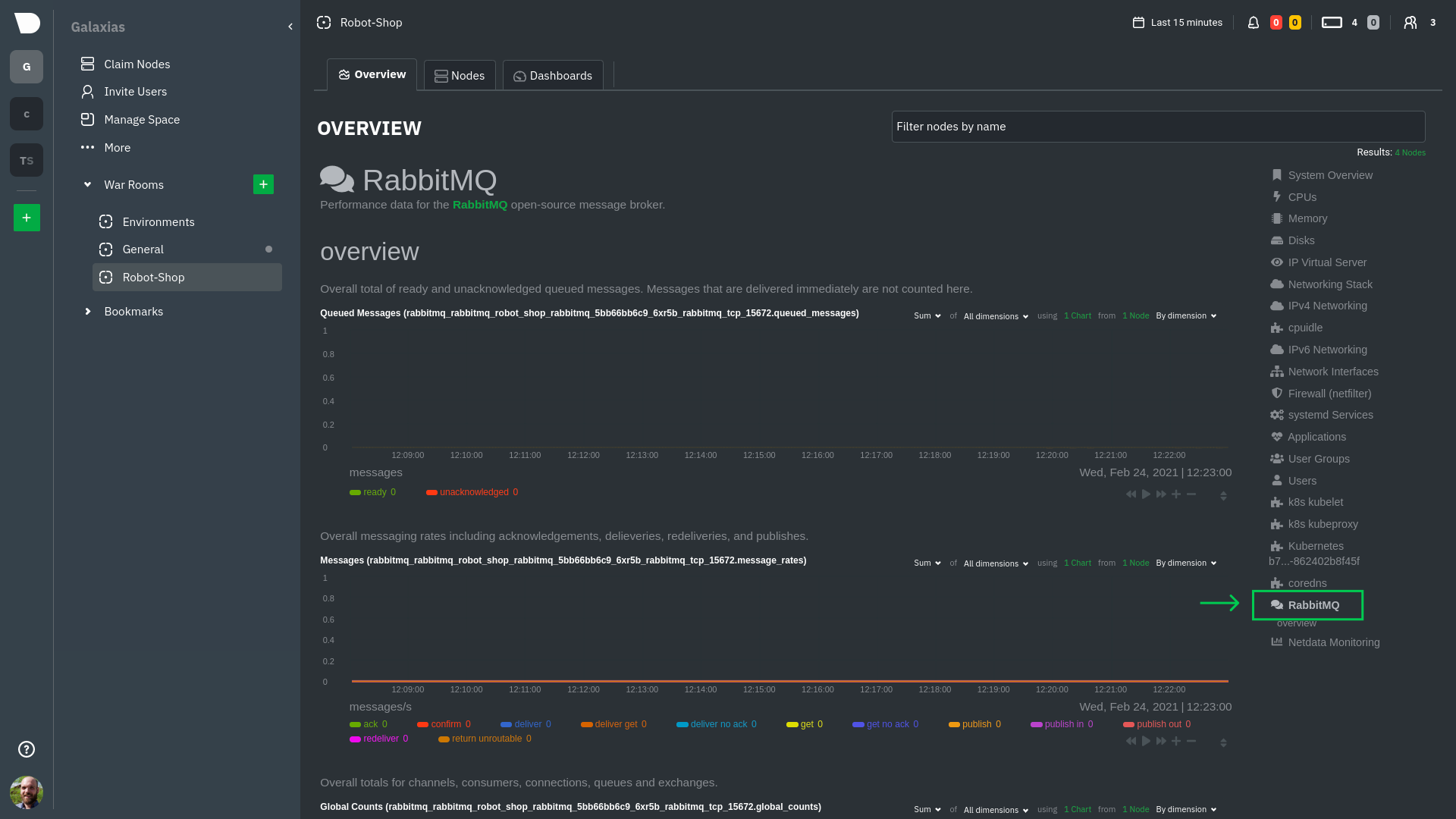 @@ -202,7 +202,7 @@ Netdata also automatically collects metrics from two essential Kubernetes proces The **k8s kubelet** section visualizes metrics from the Kubernetes agent responsible for managing every pod on a given node. This also happens without any configuration thanks to the [kubelet -collector](https://github.com/netdata/go.d.plugin/blob/master/modules/k8s_kubelet/README.md). +collector](https://github.com/netdata/netdata/blob/master/src/go/collectors/go.d.plugin/modules/k8s_kubelet/README.md). Monitoring each node's kubelet can be invaluable when diagnosing issues with your Kubernetes cluster. For example, you can see if the number of running containers/pods has dropped, which could signal a fault or crash in a particular @@ -218,7 +218,7 @@ configuration-related errors, and the actual vs. desired numbers of volumes, plu The **k8s kube-proxy** section displays metrics about the network proxy that runs on each node in your Kubernetes cluster. kube-proxy lets pods communicate with each other and accept sessions from outside your cluster. Its metrics are collected by the [kube-proxy -collector](https://github.com/netdata/go.d.plugin/blob/master/modules/k8s_kubeproxy/README.md). +collector](https://github.com/netdata/netdata/blob/master/src/go/collectors/go.d.plugin/modules/k8s_kubeproxy/README.md). With Netdata, you can monitor how often your k8s proxies are syncing proxy rules between nodes. Dramatic changes in these figures could indicate an anomaly in your cluster that's worthy of further investigation. @@ -238,9 +238,9 @@ clusters of all sizes. - [Netdata Helm chart](https://github.com/netdata/helmchart) - [Netdata service discovery](https://github.com/netdata/agent-service-discovery) - [Netdata Agent · `kubelet` - collector](https://github.com/netdata/go.d.plugin/blob/master/modules/k8s_kubelet/README.md) + collector](https://github.com/netdata/netdata/blob/master/src/go/collectors/go.d.plugin/modules/k8s_kubelet/README.md) - [Netdata Agent · `kube-proxy` - collector](https://github.com/netdata/go.d.plugin/blob/master/modules/k8s_kubeproxy/README.md) -- [Netdata Agent · `cgroups.plugin`](https://github.com/netdata/netdata/blob/master/collectors/cgroups.plugin/README.md) + collector](https://github.com/netdata/netdata/blob/master/src/go/collectors/go.d.plugin/modules/k8s_kubeproxy/README.md) +- [Netdata Agent · `cgroups.plugin`](https://github.com/netdata/netdata/blob/master/src/collectors/cgroups.plugin/README.md) |