
diff options
Diffstat (limited to 'docs/guides')
| -rw-r--r-- | docs/guides/collect-apache-nginx-web-logs.md | 8 | ||||
| -rw-r--r-- | docs/guides/monitor-cockroachdb.md | 8 | ||||
| -rw-r--r-- | docs/guides/monitor-hadoop-cluster.md | 10 | ||||
| -rw-r--r-- | docs/guides/monitor/anomaly-detection.md | 8 | ||||
| -rw-r--r-- | docs/guides/monitor/lamp-stack.md | 14 | ||||
| -rw-r--r-- | docs/guides/python-collector.md | 4 | ||||
| -rw-r--r-- | docs/guides/using-host-labels.md | 8 |
7 files changed, 30 insertions, 30 deletions
diff --git a/docs/guides/collect-apache-nginx-web-logs.md b/docs/guides/collect-apache-nginx-web-logs.md index e9b38c27e..f5e374429 100644 --- a/docs/guides/collect-apache-nginx-web-logs.md +++ b/docs/guides/collect-apache-nginx-web-logs.md @@ -94,13 +94,13 @@ We do have [extensive documentation](https://github.com/netdata/go.d.plugin/blob/master/modules/weblog/README.md#custom-log-format) on how to build custom parsing for Nginx and Apache logs. -## Tweak web log collector alarms +## Tweak web log collector alerts -Over time, we've created some default alarms for web log monitoring. These alarms are designed to work only when your +Over time, we've created some default alerts for web log monitoring. These alerts are designed to work only when your web server is receiving more than 120 requests per minute. Otherwise, there's simply not enough data to make conclusions about what is "too few" or "too many." -- [web log alarms](https://raw.githubusercontent.com/netdata/netdata/master/health/health.d/web_log.conf). +- [web log alerts](https://raw.githubusercontent.com/netdata/netdata/master/health/health.d/web_log.conf). You can also edit this file directly with `edit-config`: @@ -108,5 +108,5 @@ You can also edit this file directly with `edit-config`: ./edit-config health.d/weblog.conf ``` -For more information about editing the defaults or writing new alarm entities, see our +For more information about editing the defaults or writing new alert entities, see our [health monitoring documentation](https://github.com/netdata/netdata/blob/master/health/README.md). diff --git a/docs/guides/monitor-cockroachdb.md b/docs/guides/monitor-cockroachdb.md index ea94d7a02..d0db69ab5 100644 --- a/docs/guides/monitor-cockroachdb.md +++ b/docs/guides/monitor-cockroachdb.md @@ -28,7 +28,7 @@ Let's dive in and walk through the process of monitoring CockroachDB metrics wit - [What's in this guide](#whats-in-this-guide) - [Configure the CockroachDB collector](#configure-the-cockroachdb-collector) - [Manual setup for a local CockroachDB database](#manual-setup-for-a-local-cockroachdb-database) - - [Tweak CockroachDB alarms](#tweak-cockroachdb-alarms) + - [Tweak CockroachDB alerts](#tweak-cockroachdb-alerts) ## Configure the CockroachDB collector @@ -102,9 +102,9 @@ Netdata to see your new charts. <figcaption>Charts showing a node failure during a simulated test</figcaption> </figure> -## Tweak CockroachDB alarms +## Tweak CockroachDB alerts -This release also includes eight pre-configured alarms for live nodes, such as whether the node is live, storage +This release also includes eight pre-configured alerts for live nodes, such as whether the node is live, storage capacity, issues with replication, and the number of SQL connections/statements. See [health.d/cockroachdb.conf on GitHub](https://raw.githubusercontent.com/netdata/netdata/master/health/health.d/cockroachdb.conf) for details. @@ -115,4 +115,4 @@ cd /etc/netdata/ # Replace with your Netdata configuration directory, if not /et ./edit-config health.d/cockroachdb.conf # You may need to use `sudo` for write privileges ``` -For more information about editing the defaults or writing new alarm entities, see our documentation on [configuring health alarms](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md). +For more information about editing the defaults or writing new alert entities, see our documentation on [configuring health alerts](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md). diff --git a/docs/guides/monitor-hadoop-cluster.md b/docs/guides/monitor-hadoop-cluster.md index 91282b955..41bf891f6 100644 --- a/docs/guides/monitor-hadoop-cluster.md +++ b/docs/guides/monitor-hadoop-cluster.md @@ -173,13 +173,13 @@ sudo systemctl restart netdata Upon restart, Netdata should recognize your HDFS/Zookeeper servers, enable the HDFS and Zookeeper modules, and begin showing real-time metrics for both in your Netdata dashboard. 🎉 -## Configuring HDFS and Zookeeper alarms +## Configuring HDFS and Zookeeper alerts -The Netdata community helped us create sane defaults for alarms related to both HDFS and Zookeeper. You may want to +The Netdata community helped us create sane defaults for alerts related to both HDFS and Zookeeper. You may want to investigate these to ensure they work well with your Hadoop implementation. -- [HDFS alarms](https://raw.githubusercontent.com/netdata/netdata/master/health/health.d/hdfs.conf) -- [Zookeeper alarms](https://raw.githubusercontent.com/netdata/netdata/master/health/health.d/zookeeper.conf) +- [HDFS alerts](https://raw.githubusercontent.com/netdata/netdata/master/health/health.d/hdfs.conf) +- [Zookeeper alerts](https://raw.githubusercontent.com/netdata/netdata/master/health/health.d/zookeeper.conf) You can also access/edit these files directly with `edit-config`: @@ -188,5 +188,5 @@ sudo /etc/netdata/edit-config health.d/hdfs.conf sudo /etc/netdata/edit-config health.d/zookeeper.conf ``` -For more information about editing the defaults or writing new alarm entities, see our +For more information about editing the defaults or writing new alert entities, see our [health monitoring documentation](https://github.com/netdata/netdata/blob/master/health/README.md). diff --git a/docs/guides/monitor/anomaly-detection.md b/docs/guides/monitor/anomaly-detection.md index 4552e7a72..c0a00ef34 100644 --- a/docs/guides/monitor/anomaly-detection.md +++ b/docs/guides/monitor/anomaly-detection.md @@ -53,13 +53,13 @@ Pressing the anomalies icon (next to the information icon in the chart header) w ## Anomaly Rate Based Alerts -It is possible to use the `anomaly-bit` when defining traditional Alerts within netdata. The `anomaly-bit` is just another `options` parameter that can be passed as part of an [alarm line lookup](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md#alarm-line-lookup). +It is possible to use the `anomaly-bit` when defining traditional Alerts within netdata. The `anomaly-bit` is just another `options` parameter that can be passed as part of an [alert line lookup](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md#alert-line-lookup). You can see some example ML based alert configurations below: -- [Anomaly rate based CPU dimensions alarm](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md#example-8---anomaly-rate-based-cpu-dimensions-alarm) -- [Anomaly rate based CPU chart alarm](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md#example-9---anomaly-rate-based-cpu-chart-alarm) -- [Anomaly rate based node level alarm](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md#example-10---anomaly-rate-based-node-level-alarm) +- [Anomaly rate based CPU dimensions alert](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md#example-8---anomaly-rate-based-cpu-dimensions-alert) +- [Anomaly rate based CPU chart alert](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md#example-9---anomaly-rate-based-cpu-chart-alert) +- [Anomaly rate based node level alert](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md#example-10---anomaly-rate-based-node-level-alert) - More examples in the [`/health/health.d/ml.conf`](https://github.com/netdata/netdata/blob/master/health/health.d/ml.conf) file that ships with the agent. ## Learn More diff --git a/docs/guides/monitor/lamp-stack.md b/docs/guides/monitor/lamp-stack.md index 190ea87e8..2289c71c9 100644 --- a/docs/guides/monitor/lamp-stack.md +++ b/docs/guides/monitor/lamp-stack.md @@ -34,7 +34,7 @@ of required setup. In this tutorial, you'll set up robust LAMP stack monitoring with Netdata in just a few minutes. When you're done, you'll have one dashboard to monitor every part of your web application, including each essential LAMP stack service. -This dashboard updates every second with new metrics, and pairs those metrics up with preconfigured alarms to keep you +This dashboard updates every second with new metrics, and pairs those metrics up with preconfigured alerts to keep you informed of any errors or odd behavior. ## What you need to get started @@ -192,18 +192,18 @@ Here's a quick reference for what charts you might want to focus on after settin | Active Connections (`mysql_local.connections_active`) | MySQL monitoring | If the `active` dimension nears the `limit`, your MySQL database will bottleneck responses. | | Performance (phpfpm_local.performance) | PHP monitoring | The `slow requests` dimension lets you know if any requests exceed the configured `request_slowlog_timeout`. If so, users might be having a less-than-ideal experience. | -## Get alarms for LAMP stack errors +## Get alerts for LAMP stack errors -The Netdata Agent comes with hundreds of pre-configured alarms to help you keep tabs on your system, including 19 alarms +The Netdata Agent comes with hundreds of pre-configured alerts to help you keep tabs on your system, including 19 alerts designed for smarter LAMP stack monitoring. -Click the 🔔 icon in the top navigation to [see active alarms](https://github.com/netdata/netdata/blob/master/docs/monitor/view-active-alarms.md). The **Active** tabs -shows any alarms currently triggered, while the **All** tab displays a list of _every_ pre-configured alarm. The +Click the 🔔 icon in the top navigation to [see active alerts](https://github.com/netdata/netdata/blob/master/docs/monitor/view-active-alerts.md). The **Active** tabs +shows any alerts currently triggered, while the **All** tab displays a list of _every_ pre-configured alert. The 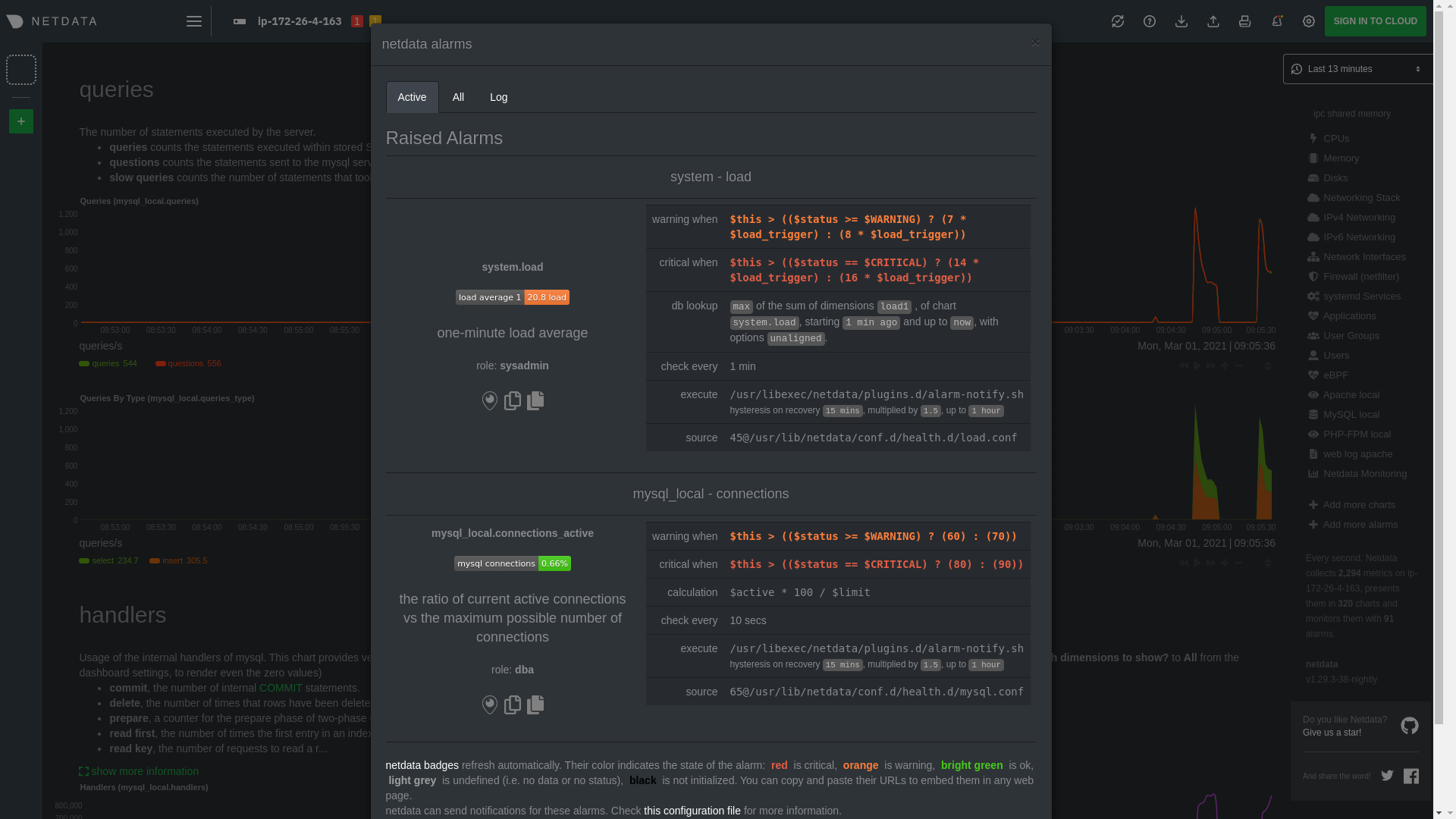 +alerts](https://user-images.githubusercontent.com/1153921/109524120-5883f900-7a6d-11eb-830e-0e7baaa28163.png) -[Tweak alarms](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md) based on your infrastructure monitoring needs, and to see these alarms +[Tweak alerts](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md) based on your infrastructure monitoring needs, and to see these alerts in other places, like your inbox or a Slack channel, [enable a notification method](https://github.com/netdata/netdata/blob/master/docs/monitor/enable-notifications.md). diff --git a/docs/guides/python-collector.md b/docs/guides/python-collector.md index f77699495..d89eb25e1 100644 --- a/docs/guides/python-collector.md +++ b/docs/guides/python-collector.md @@ -16,7 +16,7 @@ Golang is more performant, easier to maintain, and simpler for users since it do execute. Python plugins require Python on the machine to be executed. Netdata uses Go as the platform of choice for production-grade collectors. -We generally do not accept contributions of Python modules to the Github project netdata/netdata. If you write a Python collector and +We generally do not accept contributions of Python modules to the GitHub project netdata/netdata. If you write a Python collector and want to make it available for other users, you should create the pull request in https://github.com/netdata/community. ## What you need to get started @@ -540,7 +540,7 @@ At minimum, to be buildable and testable, the PR needs to include: - A makefile for the plugin at `collectors/python.d.plugin/<module_dir>/Makefile.inc`. Check an existing plugin for what this should look like. - A line in `collectors/python.d.plugin/Makefile.am` including the above-mentioned makefile. Place it with the other plugin includes (please keep the includes sorted alphabetically). - Optionally, chart information in `web/gui/dashboard_info.js`. This generally involves specifying a name and icon for the section, and may include descriptions for the section or individual charts. -- Optionally, some default alarm configurations for your collector in `health/health.d/<module_name>.conf` and a line adding `<module_name>.conf` in `health/Makefile.am`. +- Optionally, some default alert configurations for your collector in `health/health.d/<module_name>.conf` and a line adding `<module_name>.conf` in `health/Makefile.am`. ## Framework class reference diff --git a/docs/guides/using-host-labels.md b/docs/guides/using-host-labels.md index 5b9ab2e87..5f3a467fc 100644 --- a/docs/guides/using-host-labels.md +++ b/docs/guides/using-host-labels.md @@ -41,7 +41,7 @@ To define your windows server as a virtual node you need to: Host labels can be extremely useful when: -- You need alarms that adapt to the system's purpose +- You need alerts that adapt to the system's purpose - You need properly-labeled metrics archiving so you can sort, correlate, and mash-up your data to your heart's content. - You need to keep tabs on ephemeral Docker containers in a Kubernetes cluster. @@ -149,7 +149,7 @@ exporting. Speaking of which... ### Host labels in alerts You can use host labels to logically organize your systems by their type, purpose, or location, and then apply specific -alarms to them. +alerts to them. For example, let's use configuration example from earlier: @@ -178,7 +178,7 @@ Or, by using one of the automatic labels, for only webserver systems running a s host labels: _os_name = Debian* ``` -In a streaming configuration where a parent node is triggering alarms for its child nodes, you could create health +In a streaming configuration where a parent node is triggering alerts for its child nodes, you could create health entities that apply only to child nodes: ```yaml @@ -192,7 +192,7 @@ Or when ephemeral Docker nodes are involved: ``` Of course, there are many more possibilities for intuitively organizing your systems with host labels. See the [health -documentation](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md#alarm-line-host-labels) for more details, and then get creative! +documentation](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md#alert-line-host-labels) for more details, and then get creative! ### Host labels in metrics exporting |