
diff options
Diffstat (limited to '')
| -rw-r--r-- | ml/README.md | 51 |
1 files changed, 48 insertions, 3 deletions
diff --git a/ml/README.md b/ml/README.md index 06979ea15..cb8384a66 100644 --- a/ml/README.md +++ b/ml/README.md @@ -10,7 +10,7 @@ keywords: [machine learning, anomaly detection, Netdata ML] As of [`v1.32.0`](https://github.com/netdata/netdata/releases/tag/v1.32.0), Netdata comes with some ML powered [anomaly detection](https://en.wikipedia.org/wiki/Anomaly_detection) capabilities built into it and available to use out of the box, with minimal configuration required. -🚧 **Note**: This functionality is still under active development and considered experimental. Changes might cause the feature to break. We dogfood it internally and among early adopters within the Netdata community to build the feature. If you would like to get involved and help us with some feedback, email us at analytics-ml-team@netdata.cloud or come join us in the [🤖-ml-powered-monitoring](https://discord.gg/4eRSEUpJnc) channel of the Netdata discord. +🚧 **Note**: This functionality is still under active development and considered experimental. Changes might cause the feature to break. We dogfood it internally and among early adopters within the Netdata community to build the feature. If you would like to get involved and help us with some feedback, email us at analytics-ml-team@netdata.cloud, comment on the [beta launch post](https://community.netdata.cloud/t/anomaly-advisor-beta-launch/2717) in the Netdata community, or come join us in the [🤖-ml-powered-monitoring](https://discord.gg/4eRSEUpJnc) channel of the Netdata discord. Once ML is enabled, Netdata will begin training a model for each dimension. By default this model is a [k-means clustering](https://en.wikipedia.org/wiki/K-means_clustering) model trained on the most recent 4 hours of data. Rather than just using the most recent value of each raw metric, the model works on a preprocessed ["feature vector"](#feature-vector) of recent smoothed and differenced values. This should enable the model to detect a wider range of potentially anomalous patterns in recent observations as opposed to just point anomalies like big spikes or drops. ([This infographic](https://user-images.githubusercontent.com/2178292/144414415-275a3477-5b47-43d6-8959-509eb48ebb20.png) shows some different types of anomalies.) @@ -160,7 +160,7 @@ Below is a list of all the available configuration params and their default valu # maximum num samples to train = 14400 # minimum num samples to train = 3600 # train every = 3600 - # dbengine anomaly rate every = 60 + # dbengine anomaly rate every = 30 # num samples to diff = 1 # num samples to smooth = 3 # num samples to lag = 5 @@ -177,10 +177,55 @@ Below is a list of all the available configuration params and their default valu # charts to skip from training = netdata.* ``` +### Configuration Examples + +If you would like to run ML on a parent instead of at the edge, some configuration options are illustrated below. + +This example assumes 3 child nodes [streaming](https://learn.netdata.cloud/docs/agent/streaming) to 1 parent node and illustrates the main ways you might want to configure running ml for the children on the parent, running ML on the children themselves, or even a mix of approaches. + +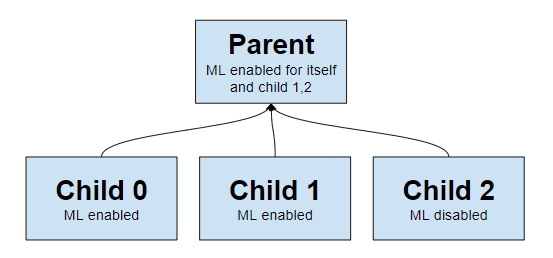 + +``` +# parent will run ml for itself and child 1,2. +# child 0 will run its own ml at the edge and just stream its ml charts to parent. +# child 1 will run its own ml at the edge, even though parent will also run ml for it, a bit wasteful potentially to run ml in both places but is possible. +# child 2 will not run ml at the edge, it will be run in the parent only. + +# parent-ml-ml-stress-0 +# run ml on all hosts apart from child-ml-ml-stress-0 +[ml] + enabled = yes + minimum num samples to train = 900 + train every = 900 + charts to skip from training = !* + hosts to skip from training = child-ml-ml-stress-0 + +# child-ml-ml-stress-0 +# run ml on child-ml-ml-stress-0 and stream ml charts to parent +[ml] + enabled = yes + minimum num samples to train = 900 + train every = 900 + stream anomaly detection charts = yes + +# child-ml-ml-stress-1 +# run ml on child-ml-ml-stress-1 and stream ml charts to parent +[ml] + enabled = yes + minimum num samples to train = 900 + train every = 900 + stream anomaly detection charts = yes + +# child-ml-ml-stress-2 +# don't run ml on child-ml-ml-stress-2, it will instead run on parent-ml-ml-stress-0 +[ml] + enabled = no +``` + ### Descriptions (min/max) - `enabled`: `yes` to enable, `no` to disable. -- `maximum num samples to train`: (`3600`/`21600`) This is the maximum amount of time you would like to train each model on. For example, the default of `14400` trains on the preceding 4 hours of data, assuming an `update every` of 1 second. +- `maximum num samples to train`: (`3600`/`86400`) This is the maximum amount of time you would like to train each model on. For example, the default of `14400` trains on the preceding 4 hours of data, assuming an `update every` of 1 second. - `minimum num samples to train`: (`900`/`21600`) This is the minimum amount of data required to be able to train a model. For example, the default of `3600` implies that once at least 1 hour of data is available for training, a model is trained, otherwise it is skipped and checked again at the next training run. - `train every`: (`1800`/`21600`) This is how often each model will be retrained. For example, the default of `3600` means that each model is retrained every hour. Note: The training of all models is spread out across the `train every` period for efficiency, so in reality, it means that each model will be trained in a staggered manner within each `train every` period. - `dbengine anomaly rate every`: (`30`/`900`) This is how often netdata will aggregate all the anomaly bits into a single chart (`anomaly_detection.anomaly_rates`). The aggregation into a single chart allows enabling anomaly rate ranking over _all_ metrics with one API call as opposed to a call per chart. |