1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
497
498
499
500
501
502
503
504
505
506
507
508
509
510
511
512
513
514
515
516
517
518
519
520
521
522
523
524
525
526
527
528
529
530
531
532
533
534
535
536
537
538
539
540
541
542
543
544
545
546
547
548
549
550
551
552
553
554
555
556
557
558
559
560
561
562
563
564
565
566
567
568
569
570
571
572
573
574
575
576
577
578
579
580
581
582
583
584
585
586
587
588
589
590
591
592
593
594
595
596
597
598
599
600
601
602
603
604
605
606
607
608
609
610
611
612
613
614
615
616
617
618
619
620
621
622
623
624
625
626
627
628
629
630
631
632
633
634
635
636
637
638
639
640
641
642
643
644
645
646
647
648
649
650
651
652
653
654
655
656
657
658
659
660
661
662
663
664
665
666
667
668
669
670
671
672
673
674
675
676
677
678
679
680
681
682
683
684
685
686
687
688
689
690
691
692
693
694
695
696
697
698
699
700
701
702
703
704
705
706
707
708
709
710
711
712
713
714
715
716
717
718
719
720
721
722
723
724
725
726
727
728
729
730
731
732
733
734
735
736
737
738
739
740
741
742
743
744
745
746
747
748
749
750
751
752
753
754
755
756
757
758
759
760
761
762
763
764
765
766
767
768
769
770
771
772
773
774
775
776
777
778
779
780
781
782
783
784
785
786
787
788
789
790
791
792
793
794
795
796
797
798
799
800
801
802
803
804
805
806
807
808
809
810
811
812
813
814
815
816
817
818
819
820
821
822
823
824
825
826
827
828
829
830
831
832
833
834
835
836
837
838
839
840
841
842
843
844
845
846
847
848
849
850
851
852
853
854
855
856
857
858
859
860
861
862
863
864
865
866
867
868
869
870
871
872
873
874
875
876
|
<!--
title: "Health configuration reference"
custom_edit_url: https://github.com/netdata/netdata/edit/master/health/REFERENCE.md
-->
# Health configuration reference
Welcome to the health configuration reference.
This guide contains information about editing health configuration files to tweak existing alarms or create new health
entities that are customized to the needs of your infrastructure.
To learn the basics of locating and editing health configuration files, see the [health
quickstart](/health/QUICKSTART.md).
## Health configuration files
You can configure the Agent's health watchdog service by editing files in two locations:
- The `[health]` section in `netdata.conf`. By editing the daemon's behavior, you can disable health monitoring
altogether, run health checks more or less often, and more. See [daemon
configuration](/daemon/config/README.md#health-section-options) for a table of all the available settings, their
default values, and what they control.
- The individual `.conf` files in `health.d/`. These health entity files are organized by the type of metric they are
performing calculations on or their associated collector. You should edit these files using the `edit-config`
script. For example: `sudo ./edit-config health.d/cpu.conf`.
## Health entity reference
The following reference contains information about the syntax and options of _health entities_, which Netdata attaches
to charts in order to trigger alarms.
### Entity types
There are two entity types: **alarms** and **templates**. They have the same format and feature set—the only difference
is their label.
**Alarms** are attached to specific charts and use the `alarm` label.
**Templates** define rules that apply to all charts of a specific context, and use the `template` label. Templates help
you apply one entity to all disks, all network interfaces, all MySQL databases, and so on.
Alarms have higher precedence and will override templates. If an alarm and template entity have the same name and attach
to the same chart, Netdata will use the alarm.
### Entity format
Netdata parses the following lines. Beneath the table is an in-depth explanation of each line's purpose and syntax.
- The `alarm` or `template` line must be the first line of any entity.
- The `on` line is **always required**.
- The `every` line is **required** if not using `lookup`.
- Each entity **must** have at least one of the following lines: `lookup`, `calc`, `warn`, or `crit`.
- A few lines use space-separated lists to define how the entity behaves. You can use `*` as a wildcard or prefix with
`!` for a negative match. Order is important, too! See our [simple patterns docs](../libnetdata/simple_pattern/) for
more examples.
| line | required | functionality |
| --------------------------------------------------- | --------------- | ------------------------------------------------------------------------------------- |
| [`alarm`/`template`](#alarm-line-alarm-or-template) | yes | Name of the alarm/template. |
| [`on`](#alarm-line-on) | yes | The chart this alarm should attach to. |
| [`class`](#alarm-line-class) | no | The general classification of the alarm. |
| [`component`](#alarm-line-component) | no | Specify the component of the class of the alarm. |
| [`type`](#alarm-line-type) | no | The type of error the alarm monitors. |
| [`os`](#alarm-line-os) | no | Which operating systems to run this chart. |
| [`hosts`](#alarm-line-hosts) | no | Which hostnames will run this alarm. |
| [`plugin`](#alarm-line-plugin) | no | Restrict an alarm or template to only a certain plugin. |
| [`module`](#alarm-line-module) | no | Restrict an alarm or template to only a certain module. |
| [`charts`](#alarm-line-charts) | no | Restrict an alarm or template to only certain charts. |
| [`families`](#alarm-line-families) | no | Restrict a template to only certain families. |
| [`lookup`](#alarm-line-lookup) | yes | The database lookup to find and process metrics for the chart specified through `on`. |
| [`calc`](#alarm-line-calc) | yes (see above) | A calculation to apply to the value found via `lookup` or another variable. |
| [`every`](#alarm-line-every) | no | The frequency of the alarm. |
| [`green`/`red`](#alarm-lines-green-and-red) | no | Set the green and red thresholds of a chart. |
| [`warn`/`crit`](#alarm-lines-warn-and-crit) | yes (see above) | Expressions evaluating to true or false, and when true, will trigger the alarm. |
| [`to`](#alarm-line-to) | no | A list of roles to send notifications to. |
| [`exec`](#alarm-line-exec) | no | The script to execute when the alarm changes status. |
| [`delay`](#alarm-line-delay) | no | Optional hysteresis settings to prevent floods of notifications. |
| [`repeat`](#alarm-line-repeat) | no | The interval for sending notifications when an alarm is in WARNING or CRITICAL mode. |
| [`options`](#alarm-line-options) | no | Add an option to not clear alarms. |
| [`host labels`](#alarm-line-host-labels) | no | List of labels present on a host. |
The `alarm` or `template` line must be the first line of any entity.
#### Alarm line `alarm` or `template`
This line starts an alarm or template based on the [entity type](#entity-types) you're interested in creating.
**Alarm:**
```yaml
alarm: NAME
```
**Template:**
```yaml
template: NAME
```
`NAME` can be any alpha character, with `.` (period) and `_` (underscore) as the only allowed symbols, but the names
cannot be `chart name`, `dimension name`, `family name`, or `chart variables names`.
#### Alarm line `on`
This line defines the chart this alarm should attach to.
**Alarms:**
```yaml
on: CHART
```
The value `CHART` should be the unique ID or name of the chart you're interested in, as shown on the dashboard. In the
image below, the unique ID is `system.cpu`.
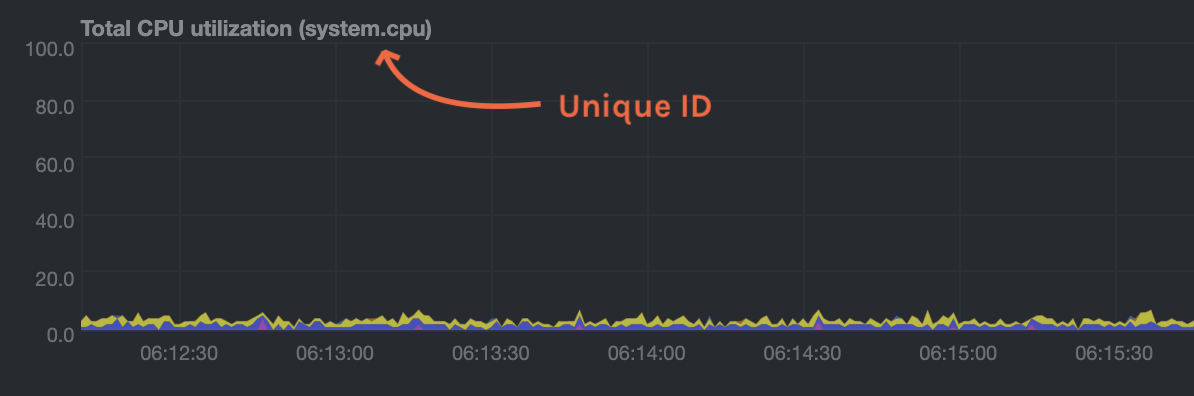
**Template:**
```yaml
on: CONTEXT
```
The value `CONTEXT` should be the context you want this template to attach to.
Need to find the context? Hover over the date on any given chart and look at the tooltip. In the image below, which
shows a disk I/O chart, the tooltip reads: `proc:/proc/diskstats, disk.io`.
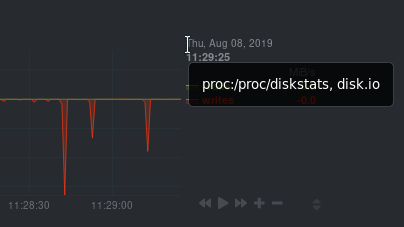
You're interested in what comes after the comma: `disk.io`. That's the name of the chart's context.
If you create a template using the `disk.io` context, it will apply an alarm to every disk available on your system.
#### Alarm line `class`
Specify the classification of the alarm or template.
Class can be used to indicate the broader area of the system that the alarm applies to. For example, under the general `Database` class, you can group together alarms that operate on various database systems, like `MySQL`, `CockroachDB`, `CouchDB` etc. Example:
```yaml
class: Database
```
<details>
<summary>Netdata's stock alarms use the following `class` attributes by default, but feel free to adjust for your own requirements.</summary>
| Class | Description |
| ------------------------ | ------------------------------------------------------------------------------------------------ |
| Ad Filtering | Services related to Ad Filtering (like pi-hole) |
| Certificates | Certificates monitoring related |
| Cgroups | Alerts for cpu and memory usage of control groups |
| Computing | Alerts for shared computing applications (e.g. boinc) |
| Containers | Container related alerts (e.g. docker instances) |
| Database | Database systems (e.g. MySQL, Postgress, etc) |
| Data Sharing | Used to group together alerts for data sharing applications |
| DHCP | Alerts for dhcp related services |
| DNS | Alerts for dns related services |
| Kubernetes | Alerts for kubernetes nodes monitoring |
| KV Storage | Key-Value pairs services alerts (e.g. memcached) |
| Linux | Services specific to Linux (e.g. systemd) |
| Messaging | Alerts for message passing services (e.g. vernemq) |
| Netdata | Internal Netdata components monitoring |
| Other | Use as a general class of alerts |
| Power Supply | Alerts from power supply related services (e.g. apcupsd) |
| Search engine | Alerts for search services (e.g. elasticsearch) |
| Storage | Class for alerts dealing with storage services (storage devices typically live under `System`) |
| System | General system alarms (e.g. cpu, network, etc.) |
| Virtual Machine | Virtual Machine software |
| Web Proxy | Web proxy software (e.g. squid) |
| Web Server | Web server software (e.g. Apache, ngnix, etc.) |
| Windows | Alerts for monitor of wmi services |
</details>
If an alarm configuration is missing the `class` line, its value will default to `Unknown`.
#### Alarm line `component`
Component can be used to narrow down what the previous `class` value specifies for each alarm or template. Continuing from the previous example, `component` might include `MySQL`, `CockroachDB`, `MongoDB`, all under the same `Database` classification. Example:
```yaml
component: MySQL
```
As with the `class` line, if `component` is missing from the configuration, its value will default to `Unknown`.
#### Alarm line `type`
This indicates the type of error (or general problem area) that the alarm or template applies to. For example, `Latency` can be used for alarms that trigger on latency issues in network interfaces, web servers, or database systems. Example:
```yaml
type: Latency
```
`type` will also (as with `class` and `component`) default to `Unknown` if the line is missing from the alarm configuration.
#### Alarm line `os`
The alarm or template will be used only if the operating system of the host matches this list specified in `os`. The
value is a space-separated list.
The following example enables the entity on Linux, FreeBSD, and macOS, but no other operating systems.
```yaml
os: linux freebsd macos
```
#### Alarm line `hosts`
The alarm or template will be used only if the hostname of the host matches this space-separated list.
The following example will load on systems with the hostnames `server` and `server2`, and any system with hostnames that
begin with `database`. It _will not load_ on the host `redis3`, but will load on any _other_ systems with hostnames that
begin with `redis`.
```yaml
hosts: server1 server2 database* !redis3 redis*
```
#### Alarm line `plugin`
The `plugin` line filters which plugin within the context this alarm should apply to. The value is a space-separated
list of [simple patterns](/libnetdata/simple_pattern/README.md). For example,
you can create a filter for an alarm that applies specifically to `python.d.plugin`:
```yaml
plugin: python.d.plugin
```
The `plugin` line is best used with other options like `module`. When used alone, the `plugin` line creates a very
inclusive filter that is unlikely to be of much use in production. See [`module`](#alarm-line-module) for a
comprehensive example using both.
#### Alarm line `module`
The `module` line filters which module within the context this alarm should apply to. The value is a space-separated
list of [simple patterns](/libnetdata/simple_pattern/README.md). For
example, you can create an alarm that applies only on the `isc_dhcpd` module started by `python.d.plugin`:
```yaml
plugin: python.d.plugin
module: isc_dhcpd
```
#### Alarm line `charts`
The `charts` line filters which chart this alarm should apply to. It is only available on entities using the
[`template`](#alarm-line-alarm-or-template) line.
The value is a space-separated list of [simple patterns](/libnetdata/simple_pattern/README.md). For
example, a template that applies to `disk.svctm` (Average Service Time) context, but excludes the disk `sdb` from alarms:
```yaml
template: disk_svctm_alarm
on: disk.svctm
charts: !*sdb* *
```
#### Alarm line `families`
The `families` line, used only alongside templates, filters which families within the context this alarm should apply
to. The value is a space-separated list.
The value is a space-separate list of simple patterns. See our [simple patterns docs](../libnetdata/simple_pattern/) for
some examples.
For example, you can create a template on the `disk.io` context, but filter it to only the `sda` and `sdb` families:
```yaml
families: sda sdb
```
#### Alarm line `lookup`
This line makes a database lookup to find a value. This result of this lookup is available as `$this`.
The format is:
```yaml
lookup: METHOD AFTER [at BEFORE] [every DURATION] [OPTIONS] [of DIMENSIONS] [foreach DIMENSIONS]
```
Everything is the same with [badges](../web/api/badges/). In short:
- `METHOD` is one of `average`, `min`, `max`, `sum`, `incremental-sum`.
This is required.
- `AFTER` is a relative number of seconds, but it also accepts a single letter for changing
the units, like `-1s` = 1 second in the past, `-1m` = 1 minute in the past, `-1h` = 1 hour
in the past, `-1d` = 1 day in the past. You need a negative number (i.e. how far in the past
to look for the value). **This is required**.
- `at BEFORE` is by default 0 and is not required. Using this you can define the end of the
lookup. So data will be evaluated between `AFTER` and `BEFORE`.
- `every DURATION` sets the updated frequency of the lookup (supports single letter units as
above too).
- `OPTIONS` is a space separated list of `percentage`, `absolute`, `min2max`, `unaligned`,
`match-ids`, `match-names`. Check the badges documentation for more info.
- `of DIMENSIONS` is optional and has to be the last parameter. Dimensions have to be separated
by `,` or `|`. The space characters found in dimensions will be kept as-is (a few dimensions
have spaces in their names). This accepts Netdata simple patterns _(with `words` separated by
`,` or `|` instead of spaces)_ and the `match-ids` and `match-names` options affect the searches
for dimensions.
- `foreach DIMENSIONS` is optional, will always be the last parameter, and uses the same `,`/`|`
rules as the `of` parameter. Each dimension you specify in `foreach` will use the same rule
to trigger an alarm. If you set both `of` and `foreach`, Netdata will ignore the `of` parameter
and replace it with one of the dimensions you gave to `foreach`.
The result of the lookup will be available as `$this` and `$NAME` in expressions.
The timestamps of the timeframe evaluated by the database lookup is available as variables
`$after` and `$before` (both are unix timestamps).
#### Alarm line `calc`
A `calc` is designed to apply some calculation to the values or variables available to the entity. The result of the
calculation will be made available at the `$this` variable, overwriting the value from your `lookup`, to use in warning
and critical expressions.
When paired with `lookup`, `calc` will perform the calculation just after `lookup` has retrieved a value from Netdata's
database.
You can use `calc` without `lookup` if you are using [other available variables](#variables).
The `calc` line uses [expressions](#expressions) for its syntax.
```yaml
calc: EXPRESSION
```
#### Alarm line `every`
Sets the update frequency of this alarm. This is the same to the `every DURATION` given
in the `lookup` lines.
Format:
```yaml
every: DURATION
```
`DURATION` accepts `s` for seconds, `m` is minutes, `h` for hours, `d` for days.
#### Alarm lines `green` and `red`
Set the green and red thresholds of a chart. Both are available as `$green` and `$red` in expressions. If multiple
alarms define different thresholds, the ones defined by the first alarm will be used. These will eventually visualized
on the dashboard, so only one set of them is allowed. If you need multiple sets of them in different alarms, use
absolute numbers instead of `$red` and `$green`.
Format:
```yaml
green: NUMBER
red: NUMBER
```
#### Alarm lines `warn` and `crit`
Define the expression that triggers either a warning or critical alarm. These are optional, and should evaluate to
either true or false (or zero/non-zero).
The format uses Netdata's [expressions syntax](#expressions).
```yaml
warn: EXPRESSION
crit: EXPRESSION
```
#### Alarm line `to`
This will be the first parameter of the script to be executed when the alarm switches status. Its meaning is left up to
the `exec` script.
The default `exec` script, `alarm-notify.sh`, uses this field as a space separated list of roles, which are then
consulted to find the exact recipients per notification method.
Format:
```yaml
to: ROLE1 ROLE2 ROLE3 ...
```
#### Alarm line `exec`
The script that will be executed when the alarm changes status.
Format:
```yaml
exec: SCRIPT
```
The default `SCRIPT` is Netdata's `alarm-notify.sh`, which supports all the notifications methods Netdata supports,
including custom hooks.
#### Alarm line `delay`
This is used to provide optional hysteresis settings for the notifications, to defend against notification floods. These
settings do not affect the actual alarm - only the time the `exec` script is executed.
Format:
```yaml
delay: [[[up U] [down D] multiplier M] max X]
```
- `up U` defines the delay to be applied to a notification for an alarm that raised its status
(i.e. CLEAR to WARNING, CLEAR to CRITICAL, WARNING to CRITICAL). For example, `up 10s`, the
notification for this event will be sent 10 seconds after the actual event. This is used in
hope the alarm will get back to its previous state within the duration given. The default `U`
is zero.
- `down D` defines the delay to be applied to a notification for an alarm that moves to lower
state (i.e. CRITICAL to WARNING, CRITICAL to CLEAR, WARNING to CLEAR). For example, `down 1m`
will delay the notification by 1 minute. This is used to prevent notifications for flapping
alarms. The default `D` is zero.
- `multiplier M` multiplies `U` and `D` when an alarm changes state, while a notification is
delayed. The default multiplier is `1.0`.
- `max X` defines the maximum absolute notification delay an alarm may get. The default `X`
is `max(U * M, D * M)` (i.e. the max duration of `U` or `D` multiplied once with `M`).
Example:
`delay: up 10s down 15m multiplier 2 max 1h`
The time is `00:00:00` and the status of the alarm is CLEAR.
| time of event | new status | delay | notification will be sent | why |
| ------------- | ---------- | --- | ------------------------- | --- |
| 00:00:01 | WARNING | `up 10s` | 00:00:11 | first state switch |
| 00:00:05 | CLEAR | `down 15m x2` | 00:30:05 | the alarm changes state while a notification is delayed, so it was multiplied |
| 00:00:06 | WARNING | `up 10s x2 x2` | 00:00:26 | multiplied twice |
| 00:00:07 | CLEAR | `down 15m x2 x2 x2` | 00:45:07 | multiplied 3 times. |
So:
- `U` and `D` are multiplied by `M` every time the alarm changes state (any state, not just
their matching one) and a delay is in place.
- All are reset to their defaults when the alarm switches state without a delay in place.
#### Alarm line `repeat`
Defines the interval between repeating notifications for the alarms in CRITICAL or WARNING mode. This will override the
default interval settings inherited from health settings in `netdata.conf`. The default settings for repeating
notifications are `default repeat warning = DURATION` and `default repeat critical = DURATION` which can be found in
health stock configuration, when one of these interval is bigger than 0, Netdata will activate the repeat notification
for `CRITICAL`, `CLEAR` and `WARNING` messages.
Format:
```yaml
repeat: [off] [warning DURATION] [critical DURATION]
```
- `off`: Turns off the repeating feature for the current alarm. This is effective when the default repeat settings has
been enabled in health configuration.
- `warning DURATION`: Defines the interval when the alarm is in WARNING state. Use `0s` to turn off the repeating
notification for WARNING mode.
- `critical DURATION`: Defines the interval when the alarm is in CRITICAL state. Use `0s` to turn off the repeating
notification for CRITICAL mode.
#### Alarm line `options`
The only possible value for the `options` line is
```yaml
options: no-clear-notification
```
For some alarms we need compare two time-frames, to detect anomalies. For example, `health.d/httpcheck.conf` has an
alarm template called `web_service_slow` that compares the average http call response time over the last 3 minutes,
compared to the average over the last hour. It triggers a warning alarm when the average of the last 3 minutes is twice
the average of the last hour. In such cases, it is easy to trigger the alarm, but difficult to tell when the alarm is
cleared. As time passes, the newest window moves into the older, so the average response time of the last hour will keep
increasing. Eventually, the comparison will find the averages in the two time-frames close enough to clear the alarm.
However, the issue was not resolved, it's just a matter of the newer data "polluting" the old. For such alarms, it's a
good idea to tell Netdata to not clear the notification, by using the `no-clear-notification` option.
#### Alarm line `host labels`
Defines the list of labels present on a host. See our [host labels guide](/docs/guides/using-host-labels.md) for
an explanation of host labels and how to implement them.
For example, let's suppose that `netdata.conf` is configured with the following labels:
```yaml
[host labels]
installed = 20191211
room = server
```
And more labels in `netdata.conf` for workstations:
```yaml
[host labels]
installed = 201705
room = workstation
```
By defining labels inside of `netdata.conf`, you can now apply labels to alarms. For example, you can add the following
line to any alarms you'd like to apply to hosts that have the label `room = server`.
```yaml
host labels: room = server
```
The `host labels` is a space-separated list that accepts simple patterns. For example, you can create an alarm
that will be applied to all hosts installed in the last decade with the following line:
```yaml
host labels: installed = 201*
```
See our [simple patterns docs](../libnetdata/simple_pattern/) for more examples.
## Expressions
Netdata has an internal [infix expression parser](../libnetdata/eval). This parses expressions and creates an internal
structure that allows fast execution of them.
These operators are supported `+`, `-`, `*`, `/`, `<`, `<=`, `<>`, `!=`, `>`, `>=`, `&&`, `||`, `!`, `AND`, `OR`, `NOT`.
Boolean operators result in either `1` (true) or `0` (false).
The conditional evaluation operator `?` is supported too. Using this operator IF-THEN-ELSE conditional statements can be
specified. The format is: `(condition) ? (true expression) : (false expression)`. So, Netdata will first evaluate the
`condition` and based on the result will either evaluate `true expression` or `false expression`.
Example: `($this > 0) ? ($avail * 2) : ($used / 2)`.
Nested such expressions are also supported (i.e. `true expression` and `false expression` can contain conditional
evaluations).
Expressions also support the `abs()` function.
Expressions can have variables. Variables start with `$`. Check below for more information.
There are two special values you can use:
- `nan`, for example `$this != nan` will check if the variable `this` is available. A variable can be `nan` if the
database lookup failed. All calculations (i.e. addition, multiplication, etc) with a `nan` result in a `nan`.
- `inf`, for example `$this != inf` will check if `this` is not infinite. A value or variable can be set to infinite
if divided by zero. All calculations (i.e. addition, multiplication, etc) with a `inf` result in a `inf`.
### Special use of the conditional operator
A common (but not necessarily obvious) use of the conditional evaluation operator is to provide
[hysteresis](https://en.wikipedia.org/wiki/Hysteresis) around the critical or warning thresholds. This usage helps to
avoid bogus messages resulting from small variations in the value when it is varying regularly but staying close to the
threshold value, without needing to delay sending messages at all.
An example of such usage from the default CPU usage alarms bundled with Netdata is:
```yaml
warn: $this > (($status >= $WARNING) ? (75) : (85))
crit: $this > (($status == $CRITICAL) ? (85) : (95))
```
The above say:
- If the alarm is currently a warning, then the threshold for being considered a warning is 75, otherwise it's 85.
- If the alarm is currently critical, then the threshold for being considered critical is 85, otherwise it's 95.
Which in turn, results in the following behavior:
- While the value is rising, it will trigger a warning when it exceeds 85, and a critical alert when it exceeds 95.
- While the value is falling, it will return to a warning state when it goes below 85, and a normal state when it goes
below 75.
- If the value is constantly varying between 80 and 90, then it will trigger a warning the first time it goes above
85, but will remain a warning until it goes below 75 (or goes above 85).
- If the value is constantly varying between 90 and 100, then it will trigger a critical alert the first time it goes
above 95, but will remain a critical alert goes below 85 (at which point it will return to being a warning).
## Variables
You can find all the variables that can be used for a given chart, using
`http://NODE:19999/api/v1/alarm_variables?chart=CHART_NAME`, replacing `NODE` with the IP address or hostname for your
Agent dashboard. For example, [variables for the `system.cpu` chart of the
registry](https://registry.my-netdata.io/api/v1/alarm_variables?chart=system.cpu).
> If you don't know how to find the CHART_NAME, you can read about it [here](../web/README.md#charts).
Netdata supports 3 internal indexes for variables that will be used in health monitoring.
<details markdown="1"><summary>The variables below can be used in both chart alarms and context templates.</summary>
Although the `alarm_variables` link shows you variables for a particular chart, the same variables can also be used in
templates for charts belonging to a given [context](../web/README.md#contexts). The reason is that all charts of a given
context are essentially identical, with the only difference being the [family](../web/README.md#families) that
identifies a particular hardware or software instance. Charts and templates do not apply to specific families anyway,
unless if you explicitly limit an alarm with the [alarm line `families`](#alarm-line-families).
</details>
- **chart local variables**. All the dimensions of the chart are exposed as local variables. The value of `$this` for
the other configured alarms of the chart also appears, under the name of each configured alarm.
Charts also define a few special variables:
- `$last_collected_t` is the unix timestamp of the last data collection
- `$collected_total_raw` is the sum of all the dimensions (their last collected values)
- `$update_every` is the update frequency of the chart
- `$green` and `$red` the threshold defined in alarms (these are per chart - the charts
inherits them from the the first alarm that defined them)
Chart dimensions define their last calculated (i.e. interpolated) value, exactly as
shown on the charts, but also a variable with their name and suffix `_raw` that resolves
to the last collected value - as collected and another with suffix `_last_collected_t`
that resolves to unix timestamp the dimension was last collected (there may be dimensions
that fail to be collected while others continue normally).
- **family variables**. Families are used to group charts together. For example all `eth0`
charts, have `family = eth0`. This index includes all local variables, but if there are
overlapping variables, only the first are exposed.
- **host variables**. All the dimensions of all charts, including all alarms, in fullname.
Fullname is `CHART.VARIABLE`, where `CHART` is either the chart id or the chart name (both
are supported).
- **special variables\*** are:
- `$this`, which is resolved to the value of the current alarm.
- `$status`, which is resolved to the current status of the alarm (the current = the last
status, i.e. before the current database lookup and the evaluation of the `calc` line).
This values can be compared with `$REMOVED`, `$UNINITIALIZED`, `$UNDEFINED`, `$CLEAR`,
`$WARNING`, `$CRITICAL`. These values are incremental, ie. `$status > $CLEAR` works as
expected.
- `$now`, which is resolved to current unix timestamp.
## Alarm statuses
Alarms can have the following statuses:
- `REMOVED` - the alarm has been deleted (this happens when a SIGUSR2 is sent to Netdata
to reload health configuration)
- `UNINITIALIZED` - the alarm is not initialized yet
- `UNDEFINED` - the alarm failed to be calculated (i.e. the database lookup failed,
a division by zero occurred, etc)
- `CLEAR` - the alarm is not armed / raised (i.e. is OK)
- `WARNING` - the warning expression resulted in true or non-zero
- `CRITICAL` - the critical expression resulted in true or non-zero
The external script will be called for all status changes.
## Example alarms
Check the `health/health.d/` directory for all alarms shipped with Netdata.
Here are a few examples:
### Example 1
A simple check if an apache server is alive:
```yaml
template: apache_last_collected_secs
on: apache.requests
calc: $now - $last_collected_t
every: 10s
warn: $this > ( 5 * $update_every)
crit: $this > (10 * $update_every)
```
The above checks that Netdata is able to collect data from apache. In detail:
```yaml
template: apache_last_collected_secs
```
The above defines a **template** named `apache_last_collected_secs`.
The name is important since `$apache_last_collected_secs` resolves to the `calc` line.
So, try to give something descriptive.
```yaml
on: apache.requests
```
The above applies the **template** to all charts that have `context = apache.requests`
(i.e. all your apache servers).
```yaml
calc: $now - $last_collected_t
```
- `$now` is a standard variable that resolves to the current timestamp.
- `$last_collected_t` is the last data collection timestamp of the chart.
So this calculation gives the number of seconds passed since the last data collection.
```yaml
every: 10s
```
The alarm will be evaluated every 10 seconds.
```yaml
warn: $this > ( 5 * $update_every)
crit: $this > (10 * $update_every)
```
If these result in non-zero or true, they trigger the alarm.
- `$this` refers to the value of this alarm (i.e. the result of the `calc` line.
We could also use `$apache_last_collected_secs`.
`$update_every` is the update frequency of the chart, in seconds.
So, the warning condition checks if we have not collected data from apache for 5
iterations and the critical condition checks for 10 iterations.
### Example 2
Check if any of the disks is critically low on disk space:
```yaml
template: disk_full_percent
on: disk.space
calc: $used * 100 / ($avail + $used)
every: 1m
warn: $this > 80
crit: $this > 95
repeat: warning 120s critical 10s
```
`$used` and `$avail` are the `used` and `avail` chart dimensions as shown on the dashboard.
So, the `calc` line finds the percentage of used space. `$this` resolves to this percentage.
This is a repeating alarm and if the alarm becomes CRITICAL it repeats the notifications every 10 seconds. It also
repeats notifications every 2 minutes if the alarm goes into WARNING mode.
### Example 3
Predict if any disk will run out of space in the near future.
We do this in 2 steps:
Calculate the disk fill rate:
```yaml
template: disk_fill_rate
on: disk.space
lookup: max -1s at -30m unaligned of avail
calc: ($this - $avail) / (30 * 60)
every: 15s
```
In the `calc` line: `$this` is the result of the `lookup` line (i.e. the free space 30 minutes
ago) and `$avail` is the current disk free space. So the `calc` line will either have a positive
number of GB/second if the disk if filling up, or a negative number of GB/second if the disk is
freeing up space.
There is no `warn` or `crit` lines here. So, this template will just do the calculation and
nothing more.
Predict the hours after which the disk will run out of space:
```yaml
template: disk_full_after_hours
on: disk.space
calc: $avail / $disk_fill_rate / 3600
every: 10s
warn: $this > 0 and $this < 48
crit: $this > 0 and $this < 24
```
The `calc` line estimates the time in hours, we will run out of disk space. Of course, only
positive values are interesting for this check, so the warning and critical conditions check
for positive values and that we have enough free space for 48 and 24 hours respectively.
Once this alarm triggers we will receive an email like this:

### Example 4
Check if any network interface is dropping packets:
```yaml
template: 30min_packet_drops
on: net.drops
lookup: sum -30m unaligned absolute
every: 10s
crit: $this > 0
```
The `lookup` line will calculate the sum of the all dropped packets in the last 30 minutes.
The `crit` line will issue a critical alarm if even a single packet has been dropped.
Note that the drops chart does not exist if a network interface has never dropped a single packet.
When Netdata detects a dropped packet, it will add the chart and it will automatically attach this
alarm to it.
### Example 5
Check if user or system dimension is using more than 50% of cpu:
```yaml
alarm: dim_template
on: system.cpu
os: linux
lookup: average -3s percentage foreach system,user
units: %
every: 10s
warn: $this > 50
crit: $this > 80
```
The `lookup` line will calculate the average CPU usage from system and user in the last 3 seconds. Because we have
the foreach in the `lookup` line, Netdata will create two independent alarms called `dim_template_system`
and `dim_template_user` that will have all the other parameters shared among them.
### Example 6
Check if all dimensions are using more than 50% of cpu:
```yaml
alarm: dim_template
on: system.cpu
os: linux
lookup: average -3s percentage foreach *
units: %
every: 10s
warn: $this > 50
crit: $this > 80
```
The `lookup` line will calculate the average of CPU usage from system and user in the last 3 seconds. In this case
Netdata will create alarms for all dimensions of the chart.
## Troubleshooting
You can compile Netdata with [debugging](/daemon/README.md#debugging) and then set in `netdata.conf`:
```yaml
[global]
debug flags = 0x0000000000800000
```
Then check your `/var/log/netdata/debug.log`. It will show you how it works. Important: this will generate a lot of
output in debug.log.
You can find the context of charts by looking up the chart in either `http://NODE:19999/netdata.conf` or
`http://NODE:19999/api/v1/charts`, replacing `NODE` with the IP address or hostname for your Agent dashboard.
You can find how Netdata interpreted the expressions by examining the alarm at
`http://NODE:19999/api/v1/alarms?all`. For each expression, Netdata will return the expression as given in its
config file, and the same expression with additional parentheses added to indicate the evaluation flow of the
expression.
## Disabling health checks or silencing notifications at runtime
It's currently not possible to schedule notifications from within the alarm template. For those scenarios where you need
to temporary disable notifications (for instance when running backups triggers a disk alert) you can disable or silence
notifications are runtime. The health checks can be controlled at runtime via the [health management
api](/web/api/health/README.md).
[](<>)
|
