
diff options
Diffstat (limited to 'docs')
{kind=link}
100 files changed, 11873 insertions, 0 deletions
diff --git a/docs/.templates/.page-level/_collector-page-template.mdx b/docs/.templates/.page-level/_collector-page-template.mdx new file mode 100644 index 00000000..fcbe7cec --- /dev/null +++ b/docs/.templates/.page-level/_collector-page-template.mdx @@ -0,0 +1,68 @@ +<!-- +title: $COLLECTOR_NAME monitoring with Netdata +description: Short summary (will be displayed in search engines) +custom_edit_url: Edit URL of the source file +keywords: [keywords, describing, the main topics] +--> + +# Title + +import { + EnableCollector, + CollectorDebug, +} from '@site/src/components/Collectors/_collector-components.jsx'; + +Short description of what the collector does on a high level. +Why should I use this collector? + +## Configuring $COLLECTOR_NAME + +#### Prerequisites + +List all needed prerequisites: + +- Prerequisite 1 +- Prerequisite 2 +- Prerequisite 3 + +<CollectorConfiguration configURL="" moduleName="PLUGIN/COLLECTOR.conf" /> + +### Example + +TODO: Check if we can automatically fetch the [JOBS] section of netdata.conf + +## Other configuration information + +Explain other configuration options, as needed. + +#### Prerequisites + +<!-- If there is only one requirement, use a paragraph instead of a single bullet item. Bullets are social animals and only appear in groups of 2 or more :) --> + +Optional. List all needed prerequisites: + +- Prerequisite 1 +- Prerequisite 2 +- Prerequisite 3 + +To do x: + +1. Step 1 written in active voice + ```bash + Code sample for step + ``` +2. Step 2 + Result of step 2, for example a system reaction; written in passive voice +3. Step 3 + +## Debugging $COLLECTOR_NAME (optional) + +<CollectorDebug pluginName="" collectorName="" /> + +## Metrics and Alerts produced by this collector + +| Chart | Metrics | Alert | +| ---------- | ----------- | ------------------------ | +| Chart Name | Metric name | [Alert 1](Link to alert) | +| Chart Name | Metric name | [Alert 2](Link to alert) | +| Chart Name | Metric name | [Alert 3](Link to alert) | diff --git a/docs/.templates/.page-level/_concept-page-template.md b/docs/.templates/.page-level/_concept-page-template.md new file mode 100644 index 00000000..685dd2ff --- /dev/null +++ b/docs/.templates/.page-level/_concept-page-template.md @@ -0,0 +1,30 @@ +<!-- +title: Noun that describes the concept +description: Short summary (will be displayed in search engines) +custom_edit_url: Edit URL of the source file +keywords: [keywords, describing, the main topics] +--> + +# Title + +Why should the reader care: “What’s in it for me?” + +## Subheading + +Ideally, try to explain one core idea per section. Questions that you could keep in mind while writing: + +- How does it work? +- What are the outcomes? +- What are the positive and negative effects of it? +- Are there alternatives that provide a similar result? + +## Subheading + +Add more subheadings and anything else that needs to be explained... +Remember, if you start to describe about another concept, stop yourself. +Each concept should be about one concept only. + +<!-- Optional --> +### Related links +<!-- Here, you could include links to task topic that describe how to implement the thing you discussed in this concept. --> +- Visit the [related thing documentation](www.related-thing.com) to learn more about related thing. diff --git a/docs/.templates/.page-level/_task-page-template.md b/docs/.templates/.page-level/_task-page-template.md new file mode 100644 index 00000000..0f49201e --- /dev/null +++ b/docs/.templates/.page-level/_task-page-template.md @@ -0,0 +1,41 @@ +<!-- +title: Starts with an active verb, like "Create a widget" or "Delete a widget" +description: Short summary (will be displayed in search engines) +custom_edit_url: Edit URL of the source file +keywords: [keywords, describing, the main topics] +--> +# Title + +Short description of why or when the procedure makes sense. + +## Subheading that describes the task +#### Prerequisites +<!-- If there is only one requirement, use a paragraph instead of a single bullet item. Bullets are social animals and only appear in groups of 2 or more :) --> +Optional. List all needed prerequisites: +- Prerequisite 1 +- Prerequisite 2 +- Prerequisite 3 + +To do x: + +1. Step 1 written in active voice + ```bash + Code sample for step + ``` +2. Step 2 + Result of step 2, for example a system reaction; written in passive voice +3. Step 3 + +## If needed, another task section + +See lines 11-24 + +<!-- Optional --> +## What's next? + +Optional section that explains the next logical steps. + +<!-- Optional --> +## Related links + +- Visit the [related thing documentation](www.related-thing.com) to learn more about related thing. diff --git a/docs/.templates/.page-level/_tutorial-page-template.mdx b/docs/.templates/.page-level/_tutorial-page-template.mdx new file mode 100644 index 00000000..9f64b5ec --- /dev/null +++ b/docs/.templates/.page-level/_tutorial-page-template.mdx @@ -0,0 +1,54 @@ +<!-- +title: Starts with an active verb, like "Create a widget" or "Delete a widget" +description: Short summary (will be displayed in search engines) +custom_edit_url: Edit URL of the source file +author: "Your Name" +author_title: "Your title at Netdata" +author_img: "/img/authors/YourFace.jpg" +keywords: [keywords, describing, the main topics] +--> + +A paragraph that explains what the tutorial does, why it matters, and the expected outcome. + +To achieve goal: + +1. [Do the first task](#first-task) +2. [Do the second task](#second-task) + +## Prerequisites + +<!-- If there is only one requirement, use a paragraph instead of a single bullet item. Bullets are social animals and only appear in groups of 2 or more :) --> + +Optional. List all needed prerequisites: + +- Prerequisite 1 +- Prerequisite 2 +- Prerequisite 3 + +## First task + +To do x: + +1. Step 1 written in active voice + ```bash + Code sample for step + ``` +2. Step 2 + Result of step 2, for example a system reaction; written in passive voice +3. Step 3 + +## Second task + +To do x: + +1. Step 1 written in active voice + ```bash + Code sample for step + ``` +2. Step 2 + Result of step 2, for example a system reaction; written in passive voice +3. Step 3 + +## What's next? + +Optional section that explains the next logical steps. diff --git a/docs/.templates/integration/schema.json b/docs/.templates/integration/schema.json new file mode 100644 index 00000000..5f2b2a85 --- /dev/null +++ b/docs/.templates/integration/schema.json @@ -0,0 +1,109 @@ +{ + "$schema": "http://json-schema.org/draft-07/schema#", + "type": "object", + "title": "Netdata Integrations file", + "properties": { + "categories": { + "type": "object", + "description": "A list defining all the available categories for the integrations.", + "properties": { + "list": { + "type": "array", + "items": { + "type": "object", + "description": "", + "properties": { + "id": { + "type": "string", + "description": "ID of the category, can be found in integrations/categories.yaml for every category." + }, + "description": { + "type": "string", + "description": "Text that will be presented below the category title, or that will be accompanying the category in the UI in any form." + }, + "priority": { + "type": "integer", + "description": "Priority of the category. A number expressing where the category should be in the menu. Currently, a static number gets assigned to all categories, with a higher priority one for the most-popular flagged categories." + }, + "children": { + "type": "array", + "description": "an array that recursively has the same elements as the parent.", + "items": { + "$ref": "#" + } + } + } + } + } + } + }, + "integrations": { + "type": "array", + "description": "A list of integration elements, combination of metadata.yaml and other sources.", + "items": { + "type": "object", + "properties": { + "id": { + "type": "string", + "description": "A unique string identifier for the integration." + }, + "name": { + "type": "string" + }, + "categories": { + "type": "array", + "description": "an array of categories that the integration belongs to", + "items": { + "type": "object", + "properties": { + "category_id": { + "type": "string", + "description": "The category_ID for this integration. This is the category ID mentioned inside integrations/category.yaml, for the respective category." + }, + "priority": { + "type": "integer", + "description": "Priority for this specific category. Will control where the integration will be positioned in this category" + } + } + } + }, + "icon": { + "type": "string", + "description": "path to the icon for this integration." + }, + "keywords": { + "type": "array", + "description": "An array of terms related to the integration.", + "items": { + "type": "string" + } + }, + "overview": { + "type": "string", + "description": "The text that will go in the top of the page, in markdown format." + }, + "metrics": { + "type": "string", + "description": "Metrics section rendered in markdown format." + }, + "alerts": { + "type": "string", + "description": "Alerts section rendered in markdown format." + }, + "setup": { + "type": "string", + "description": "Setup section rendered in markdown format." + }, + "troubleshooting": { + "type": "string", + "description": "troubleshooting section rendered in markdown format." + }, + "related_resources": { + "type": "string", + "description": "Related Resources section rendered in markdown format." + } + } + } + } + } +}
\ No newline at end of file diff --git a/docs/Demo-Sites.md b/docs/Demo-Sites.md new file mode 100644 index 00000000..177a37d1 --- /dev/null +++ b/docs/Demo-Sites.md @@ -0,0 +1,44 @@ +<!-- +title: "Live demos" +date: 2020-03-26 +custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/Demo-Sites.md +sidebar_label: "Live demos" +learn_status: "Published" +learn_topic_type: "Getting started" +learn_rel_path: "Getting started" +sidebar_position: "90" +--> + +# Live demos + +See the live Netdata Cloud demo with rooms (listed below) for specific use cases at **https://app.netdata.cloud/spaces/netdata-demo** + +| Location | Netdata Demo URL | 60 mins reqs | VM donated by | +| :------------------ | :-------------------------------------------------------------------------------------------------------------------------------------------- | :------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------| :------------------------------------------------- | +| Netdata Cloud | **[Netdata Demo - All nodes](https://app.netdata.cloud/spaces/netdata-demo/rooms/all-nodes/overview)** ||| +| Netdata Cloud | **[Netdata Demo - Active Directory](https://app.netdata.cloud/spaces/netdata-demo/rooms/active-directory/overview)** ||| +| Netdata Cloud | **[Netdata Demo - Apache](https://app.netdata.cloud/spaces/netdata-demo/rooms/apache/overview)** ||| +| Netdata Cloud | **[Netdata Demo - Cassandra](https://app.netdata.cloud/spaces/netdata-demo/rooms/cassandra/overview)** ||| +| Netdata Cloud | **[Netdata Demo - CoreDNS](https://app.netdata.cloud/spaces/netdata-demo/rooms/coredns/overview)** ||| +| Netdata Cloud | **[Netdata Demo - DNS Query](https://app.netdata.cloud/spaces/netdata-demo/rooms/dns-query/overview)** ||| +| Netdata Cloud | **[Netdata Demo - Docker](https://app.netdata.cloud/spaces/netdata-demo/rooms/docker/overview)** ||| +| Netdata Cloud | **[Netdata Demo - Host Reachability](https://app.netdata.cloud/spaces/netdata-demo/rooms/host-reachability/overview)** ||| +| Netdata Cloud | **[Netdata Demo - HTTP Endpoints](https://app.netdata.cloud/spaces/netdata-demo/rooms/http-endpoints/overview)** ||| +| Netdata Cloud | **[Netdata Demo - IIS](https://app.netdata.cloud/spaces/netdata-demo/rooms/iis/overview)** ||| +| Netdata Cloud | **[Netdata Demo - Kubernetes](https://app.netdata.cloud/spaces/netdata-demo/rooms/kubernetes/kubernetes)** ||| +| Netdata Cloud | **[Netdata Demo - Machine Learning](https://app.netdata.cloud/spaces/netdata-demo/rooms/machine-learning/overview)** ||| +| Netdata Cloud | **[Netdata Demo - MS Exchange](https://app.netdata.cloud/spaces/netdata-demo/rooms/ms-exchange/overview)** ||| +| Netdata Cloud | **[Netdata Demo - Nginx](https://app.netdata.cloud/spaces/netdata-demo/rooms/nginx/overview)** ||| +| Netdata Cloud | **[Netdata Demo - PostgreSQL](https://app.netdata.cloud/spaces/netdata-demo/rooms/postgresql/overview)** ||| +| Netdata Cloud | **[Netdata Demo - Redis](https://app.netdata.cloud/spaces/netdata-demo/rooms/redis/overview)** ||| +| Netdata Cloud | **[Netdata Demo - Windows](https://app.netdata.cloud/spaces/netdata-demo/rooms/windows/overview)** ||| +| London (UK) | **[london3.my-netdata.io](https://london3.my-netdata.io)**<br/>(this is the global Netdata **registry** and has **named** and **mysql** charts) | [](https://london3.my-netdata.io) | [DigitalOcean.com](https://m.do.co/c/83dc9f941745) | +| Atlanta (USA) | **[cdn77.my-netdata.io](https://cdn77.my-netdata.io)**<br/>(with **named** and **mysql** charts) | [](https://cdn77.my-netdata.io) | [CDN77.com](https://www.cdn77.com/) | +| Bangalore (India) | **[bangalore.my-netdata.io](https://bangalore.my-netdata.io)** | [](https://bangalore.my-netdata.io) | [DigitalOcean.com](https://m.do.co/c/83dc9f941745) | +| Frankfurt (Germany) | **[frankfurt.my-netdata.io](https://frankfurt.my-netdata.io)** | [](https://frankfurt.my-netdata.io) | [DigitalOcean.com](https://m.do.co/c/83dc9f941745) | +| New York (USA) | **[newyork.my-netdata.io](https://newyork.my-netdata.io)** | [](https://newyork.my-netdata.io) | [DigitalOcean.com](https://m.do.co/c/83dc9f941745) | +| San Francisco (USA) | **[sanfrancisco.my-netdata.io](https://sanfrancisco.my-netdata.io)** | [](https://sanfrancisco.my-netdata.io) | [DigitalOcean.com](https://m.do.co/c/83dc9f941745) | +| Singapore | **[singapore.my-netdata.io](https://singapore.my-netdata.io)** | [](https://singapore.my-netdata.io) | [DigitalOcean.com](https://m.do.co/c/83dc9f941745) | +| Toronto (Canada) | **[toronto.my-netdata.io](https://toronto.my-netdata.io)** | [](https://toronto.my-netdata.io) | [DigitalOcean.com](https://m.do.co/c/83dc9f941745) | + +Netdata dashboards are mobile- and touch-friendly. diff --git a/docs/Running-behind-apache.md b/docs/Running-behind-apache.md new file mode 100644 index 00000000..045bb676 --- /dev/null +++ b/docs/Running-behind-apache.md @@ -0,0 +1,363 @@ +# Netdata via Apache's mod_proxy + +Below you can find instructions for configuring an apache server to: + +1. Proxy a single Netdata via an HTTP and HTTPS virtual host. +2. Dynamically proxy any number of Netdata servers. +3. Add user authentication. +4. Adjust Netdata settings to get optimal results. + +## Requirements + +Make sure your apache has `mod_proxy` and `mod_proxy_http` installed and enabled. + +On Debian/Ubuntu systems, install apache, which already includes the two modules, using: + +```sh +sudo apt-get install apache2 +``` + +Enable them: + +```sh +sudo a2enmod proxy +sudo a2enmod proxy_http +``` + +Also, enable the rewrite module: + +```sh +sudo a2enmod rewrite +``` +## Netdata on an existing virtual host + +On any **existing** and already **working** apache virtual host, you can redirect requests for URL `/netdata/` to one or more Netdata servers. + +### Proxy one Netdata, running on the same server apache runs + +Add the following on top of any existing virtual host. It will allow you to access Netdata as `http://virtual.host/netdata/`. + +```conf +<VirtualHost *:80> + + RewriteEngine On + ProxyRequests Off + ProxyPreserveHost On + + <Proxy *> + Require all granted + </Proxy> + + # Local Netdata server accessed with '/netdata/', at localhost:19999 + ProxyPass "/netdata/" "http://localhost:19999/" connectiontimeout=5 timeout=30 keepalive=on + ProxyPassReverse "/netdata/" "http://localhost:19999/" + + # if the user did not give the trailing /, add it + # for HTTP (if the virtualhost is HTTP, use this) + RewriteRule ^/netdata$ http://%{HTTP_HOST}/netdata/ [L,R=301] + # for HTTPS (if the virtualhost is HTTPS, use this) + #RewriteRule ^/netdata$ https://%{HTTP_HOST}/netdata/ [L,R=301] + + # rest of virtual host config here + +</VirtualHost> +``` + +### Proxy multiple Netdata running on multiple servers + +Add the following on top of any existing virtual host. It will allow you to access multiple Netdata as `http://virtual.host/netdata/HOSTNAME/`, where `HOSTNAME` is the hostname of any other Netdata server you have (to access the `localhost` Netdata, use `http://virtual.host/netdata/localhost/`). + +```conf +<VirtualHost *:80> + + RewriteEngine On + ProxyRequests Off + ProxyPreserveHost On + + <Proxy *> + Require all granted + </Proxy> + + # proxy any host, on port 19999 + ProxyPassMatch "^/netdata/([A-Za-z0-9\._-]+)/(.*)" "http://$1:19999/$2" connectiontimeout=5 timeout=30 keepalive=on + + # make sure the user did not forget to add a trailing / + # for HTTP (if the virtualhost is HTTP, use this) + RewriteRule "^/netdata/([A-Za-z0-9\._-]+)$" http://%{HTTP_HOST}/netdata/$1/ [L,R=301] + # for HTTPS (if the virtualhost is HTTPS, use this) + RewriteRule "^/netdata/([A-Za-z0-9\._-]+)$" https://%{HTTP_HOST}/netdata/$1/ [L,R=301] + + # rest of virtual host config here + +</VirtualHost> +``` + +> IMPORTANT<br/> +> The above config allows your apache users to connect to port 19999 on any server on your network. + +If you want to control the servers your users can connect to, replace the `ProxyPassMatch` line with the following. This allows only `server1`, `server2`, `server3` and `server4`. + +``` + ProxyPassMatch "^/netdata/(server1|server2|server3|server4)/(.*)" "http://$1:19999/$2" connectiontimeout=5 timeout=30 keepalive=on +``` + +## Netdata on a dedicated virtual host + +You can proxy Netdata through apache, using a dedicated apache virtual host. + +Create a new apache site: + +```sh +nano /etc/apache2/sites-available/netdata.conf +``` + +with this content: + +```conf +<VirtualHost *:80> + ProxyRequests Off + ProxyPreserveHost On + + ServerName netdata.domain.tld + + <Proxy *> + Require all granted + </Proxy> + + ProxyPass "/" "http://localhost:19999/" connectiontimeout=5 timeout=30 keepalive=on + ProxyPassReverse "/" "http://localhost:19999/" + + ErrorLog ${APACHE_LOG_DIR}/netdata-error.log + CustomLog ${APACHE_LOG_DIR}/netdata-access.log combined +</VirtualHost> +``` + +Enable the VirtualHost: + +```sh +sudo a2ensite netdata.conf && service apache2 reload +``` + +## Netdata proxy in Plesk + +_Assuming the main goal is to make Netdata running in HTTPS._ + +1. Make a subdomain for Netdata on which you enable and force HTTPS - You can use a free Let's Encrypt certificate +2. Go to "Apache & nginx Settings", and in the following section, add: + +```conf +RewriteEngine on +RewriteRule (.*) http://localhost:19999/$1 [P,L] +``` + +3. Optional: If your server is remote, then just replace "localhost" with your actual hostname or IP, it just works. + +Repeat the operation for as many servers as you need. + +## Enable Basic Auth + +If you wish to add an authentication (user/password) to access your Netdata, do these: + +Install the package `apache2-utils`. On Debian/Ubuntu run `sudo apt-get install apache2-utils`. + +Then, generate password for user `netdata`, using `htpasswd -c /etc/apache2/.htpasswd netdata` + +**Apache 2.2 Example:**\ +Modify the virtual host with these: + +```conf + # replace the <Proxy *> section + <Proxy *> + Order deny,allow + Allow from all + </Proxy> + + # add a <Location /netdata/> section + <Location /netdata/> + AuthType Basic + AuthName "Protected site" + AuthUserFile /etc/apache2/.htpasswd + Require valid-user + Order deny,allow + Allow from all + </Location> +``` + +Specify `Location /` if Netdata is running on dedicated virtual host. + +**Apache 2.4 (dedicated virtual host) Example:** + +```conf +<VirtualHost *:80> + RewriteEngine On + ProxyRequests Off + ProxyPreserveHost On + + ServerName netdata.domain.tld + + <Proxy *> + AllowOverride None + AuthType Basic + AuthName "Protected site" + AuthUserFile /etc/apache2/.htpasswd + Require valid-user + </Proxy> + + ProxyPass "/" "http://localhost:19999/" connectiontimeout=5 timeout=30 keepalive=on + ProxyPassReverse "/" "http://localhost:19999/" + + ErrorLog ${APACHE_LOG_DIR}/netdata-error.log + CustomLog ${APACHE_LOG_DIR}/netdata-access.log combined +</VirtualHost> +``` + +Note: Changes are applied by reloading or restarting Apache. + +## Configuration of Content Security Policy + +If you want to enable CSP within your Apache, you should consider some special requirements of the headers. Modify your configuration like that: + +``` + Header always set Content-Security-Policy "default-src http: 'unsafe-inline' 'self' 'unsafe-eval'; script-src http: 'unsafe-inline' 'self' 'unsafe-eval'; style-src http: 'self' 'unsafe-inline'" +``` + +Note: Changes are applied by reloading or restarting Apache. + +## Using Netdata with Apache's `mod_evasive` module + +The `mod_evasive` Apache module helps system administrators protect their web server from brute force and distributed +denial of service attack (DDoS) attacks. + +Because Netdata sends a request to the web server for every chart update, it's normal to create 20-30 requests per +second, per client. If you're using `mod_evasive` on your Apache web server, this volume of requests will trigger the +module's protection, and your dashboard will become unresponsive. You may even begin to see 403 errors. + +To mitigate this issue, you will need to change the value of the `DOSPageCount` option in your `mod_evasive.conf` file, +which can typically be found at `/etc/httpd/conf.d/mod_evasive.conf` or `/etc/apache2/mods-enabled/evasive.conf`. + +The `DOSPageCount` option sets the limit of the number of requests from a single IP address for the same page per page +interval, which is usually 1 second. The default value is `2` requests per second. Clearly, Netdata's typical usage will +exceed that threshold, and `mod_evasive` will add your IP address to a blocklist. + +Our users have found success by setting `DOSPageCount` to `30`. Try this, and raise the value if you continue to see 403 +errors while accessing the dashboard. + +```conf +DOSPageCount 30 +``` + +Restart Apache with `sudo systemctl restart apache2`, or the appropriate method to restart services on your system, to +reload its configuration with your new values. + +### Virtual host + +To adjust the `DOSPageCount` for a specific virtual host, open your virtual host config, which can be found at +`/etc/httpd/conf/sites-available/my-domain.conf` or `/etc/apache2/sites-available/my-domain.conf` and add the +following: + +```conf +<VirtualHost *:80> + ... + # Increase the DOSPageCount to prevent 403 errors and IP addresses being blocked. + <IfModule mod_evasive20.c> + DOSPageCount 30 + </IfModule> +</VirtualHost> +``` + +See issues [#2011](https://github.com/netdata/netdata/issues/2011) and +[#7658](https://github.com/netdata/netdata/issues/7568) for more information. + +# Netdata configuration + +You might edit `/etc/netdata/netdata.conf` to optimize your setup a bit. For applying these changes you need to restart Netdata. + +## Response compression + +If you plan to use Netdata exclusively via apache, you can gain some performance by preventing double compression of its output (Netdata compresses its response, apache re-compresses it) by editing `/etc/netdata/netdata.conf` and setting: + +``` +[web] + enable gzip compression = no +``` + +Once you disable compression at Netdata (and restart it), please verify you receive compressed responses from apache (it is important to receive compressed responses - the charts will be more snappy). + +## Limit direct access to Netdata + +You would also need to instruct Netdata to listen only on `localhost`, `127.0.0.1` or `::1`. + +``` +[web] + bind to = localhost +``` + +or + +``` +[web] + bind to = 127.0.0.1 +``` + +or + +``` +[web] + bind to = ::1 +``` + + + +You can also use a unix domain socket. This will also provide a faster route between apache and Netdata: + +``` +[web] + bind to = unix:/tmp/netdata.sock +``` + +Apache 2.4.24+ can not read from `/tmp` so create your socket in `/var/run/netdata` + +``` +[web] + bind to = unix:/var/run/netdata/netdata.sock +``` + +_note: Netdata v1.8+ support unix domain sockets_ + +At the apache side, prepend the 2nd argument to `ProxyPass` with `unix:/tmp/netdata.sock|`, like this: + +``` +ProxyPass "/netdata/" "unix:/tmp/netdata.sock|http://localhost:19999/" connectiontimeout=5 timeout=30 keepalive=on +``` + + + +If your apache server is not on localhost, you can set: + +``` +[web] + bind to = * + allow connections from = IP_OF_APACHE_SERVER +``` + +*note: Netdata v1.9+ support `allow connections from`* + +`allow connections from` accepts [Netdata simple patterns](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md) to match against the connection IP address. + +## Prevent the double access.log + +apache logs accesses and Netdata logs them too. You can prevent Netdata from generating its access log, by setting this in `/etc/netdata/netdata.conf`: + +``` +[global] + access log = none +``` + +## Troubleshooting mod_proxy + +Make sure the requests reach Netdata, by examining `/var/log/netdata/access.log`. + +1. if the requests do not reach Netdata, your apache does not forward them. +2. if the requests reach Netdata but the URLs are wrong, you have not re-written them properly. + + diff --git a/docs/Running-behind-caddy.md b/docs/Running-behind-caddy.md new file mode 100644 index 00000000..b7608b30 --- /dev/null +++ b/docs/Running-behind-caddy.md @@ -0,0 +1,38 @@ +<!-- +title: "Netdata via Caddy" +custom_edit_url: "https://github.com/netdata/netdata/edit/master/docs/Running-behind-caddy.md" +sidebar_label: "Netdata via Caddy" +learn_status: "Published" +learn_topic_type: "Tasks" +learn_rel_path: "Configuration/Secure your nodes" +--> + +# Netdata via Caddy + +To run Netdata via [Caddy v2 proxying,](https://caddyserver.com/docs/caddyfile/directives/reverse_proxy) set your Caddyfile up like this: + +```caddyfile +netdata.domain.tld { + reverse_proxy localhost:19999 +} +``` + +Other directives can be added between the curly brackets as needed. + +To run Netdata in a subfolder: + +```caddyfile +netdata.domain.tld { + handle_path /netdata/* { + reverse_proxy localhost:19999 + } +} +``` + +## limit direct access to Netdata + +You would also need to instruct Netdata to listen only to `127.0.0.1` or `::1`. + +To limit access to Netdata only from localhost, set `bind socket to IP = 127.0.0.1` or `bind socket to IP = ::1` in `/etc/netdata/netdata.conf`. + + diff --git a/docs/Running-behind-h2o.md b/docs/Running-behind-h2o.md new file mode 100644 index 00000000..deadc91c --- /dev/null +++ b/docs/Running-behind-h2o.md @@ -0,0 +1,187 @@ +<!-- +title: "Running Netdata behind H2O" +custom_edit_url: "https://github.com/netdata/netdata/edit/master/docs/Running-behind-h2o.md" +sidebar_label: "Running Netdata behind H2O" +learn_status: "Published" +learn_topic_type: "Tasks" +learn_rel_path: "Configuration/Secure your nodes" +--> + +# Running Netdata behind H2O + +[H2O](https://h2o.examp1e.net/) is a new generation HTTP server that provides quicker response to users with less CPU utilization when compared to older generation of web servers. + +It is notable for having much simpler configuration than many popular HTTP servers, low resource requirements, and integrated native support for many things that other HTTP servers may need special setup to use. + +## Why H2O + +- Sane configuration defaults mean that typical configurations are very minimalistic and easy to work with. + +- Native support for HTTP/2 provides improved performance when accessing the Netdata dashboard remotely. + +- Password protect access to the Netdata dashboard without requiring Netdata Cloud. + +## H2O configuration file. + +On most systems, the H2O configuration is found under `/etc/h2o`. H2O uses [YAML 1.1](https://yaml.org/spec/1.1/), with a few special extensions, for it’s configuration files, with the main configuration file being `/etc/h2o/h2o.conf`. + +You can edit the H2O configuration file with Nano, Vim or any other text editors with which you are comfortable. + +After making changes to the configuration files, perform the following: + +- Test the configuration with `h2o -m test -c /etc/h2o/h2o.conf` + +- Restart H2O to apply tha changes with `/etc/init.d/h2o restart` or `service h2o restart` + +## Ways to access Netdata via H2O + +### As a virtual host + +With this method instead of `SERVER_IP_ADDRESS:19999`, the Netdata dashboard can be accessed via a human-readable URL such as `netdata.example.com` used in the configuration below. + +```yaml +hosts: + netdata.example.com: + listen: + port: 80 + paths: + /: + proxy.preserve-host: ON + proxy.reverse.url: http://127.0.0.1:19999 +``` + +### As a subfolder of an existing virtual host + +This method is recommended when Netdata is to be served from a subfolder (or directory). +In this case, the virtual host `netdata.example.com` already exists and Netdata has to be accessed via `netdata.example.com/netdata/`. + +```yaml +hosts: + netdata.example.com: + listen: + port: 80 + paths: + /netdata: + redirect: + status: 301 + url: /netdata/ + /netdata/: + proxy.preserve-host: ON + proxy.reverse.url: http://127.0.0.1:19999 +``` + +### As a subfolder for multiple Netdata servers, via one H2O instance + +This is the recommended configuration when one H2O instance will be used to manage multiple Netdata servers via subfolders. + +```yaml +hosts: + netdata.example.com: + listen: + port: 80 + paths: + /netdata/server1: + redirect: + status: 301 + url: /netdata/server1/ + /netdata/server1/: + proxy.preserve-host: ON + proxy.reverse.url: http://198.51.100.1:19999 + /netdata/server2: + redirect: + status: 301 + url: /netdata/server2/ + /netdata/server2/: + proxy.preserve-host: ON + proxy.reverse.url: http://198.51.100.2:19999 +``` + +Of course you can add as many backend servers as you like. + +Using the above, you access Netdata on the backend servers, like this: + +- `http://netdata.example.com/netdata/server1/` to reach Netdata on `198.51.100.1:19999` +- `http://netdata.example.com/netdata/server2/` to reach Netdata on `198.51.100.2:19999` + +### Encrypt the communication between H2O and Netdata + +In case Netdata's web server has been [configured to use TLS](https://github.com/netdata/netdata/blob/master/web/server/README.md#enabling-tls-support), it is +necessary to specify inside the H2O configuration that the final destination is using TLS. To do this, change the +`http://` on the `proxy.reverse.url` line in your H2O configuration with `https://` + +### Enable authentication + +Create an authentication file to enable basic authentication via H2O, this secures your Netdata dashboard. + +If you don't have an authentication file, you can use the following command: + +```sh +printf "yourusername:$(openssl passwd -apr1)" > /etc/h2o/passwords +``` + +And then add a basic authentication handler to each path definition: + +```yaml +hosts: + netdata.example.com: + listen: + port: 80 + paths: + /: + mruby.handler: | + require "htpasswd.rb" + Htpasswd.new("/etc/h2o/passwords", "netdata.example.com") + proxy.preserve-host: ON + proxy.reverse.url: http://127.0.0.1:19999 +``` + +For more information on using basic authentication with H2O, see [their official documentation](https://h2o.examp1e.net/configure/basic_auth.html). + +## Limit direct access to Netdata + +If your H2O server is on `localhost`, you can use this to ensure external access is only possible through H2O: + +``` +[web] + bind to = 127.0.0.1 ::1 +``` + + + +You can also use a unix domain socket. This will provide faster communication between H2O and Netdata as well: + +``` +[web] + bind to = unix:/run/netdata/netdata.sock +``` + +In the H2O configuration, use a line like the following to connect to Netdata via the unix socket: + +```yaml +proxy.reverse.url http://[unix:/run/netdata/netdata.sock] +``` + + + +If your H2O server is not on localhost, you can set: + +``` +[web] + bind to = * + allow connections from = IP_OF_H2O_SERVER +``` + +*note: Netdata v1.9+ support `allow connections from`* + +`allow connections from` accepts [Netdata simple patterns](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md) to match against +the connection IP address. + +## Prevent the double access.log + +H2O logs accesses and Netdata logs them too. You can prevent Netdata from generating its access log, by setting +this in `/etc/netdata/netdata.conf`: + +``` +[global] + access log = none +``` diff --git a/docs/Running-behind-haproxy.md b/docs/Running-behind-haproxy.md new file mode 100644 index 00000000..4c9c32cc --- /dev/null +++ b/docs/Running-behind-haproxy.md @@ -0,0 +1,297 @@ +<!-- +title: "Netdata via HAProxy" +custom_edit_url: "https://github.com/netdata/netdata/edit/master/docs/Running-behind-haproxy.md" +sidebar_label: "Netdata via HAProxy" +learn_status: "Published" +learn_topic_type: "Tasks" +learn_rel_path: "Configuration/Secure your nodes" +--> + +# Netdata via HAProxy + +> HAProxy is a free, very fast and reliable solution offering high availability, load balancing, +> and proxying for TCP and HTTP-based applications. It is particularly suited for very high traffic websites +> and powers quite a number of the world's most visited ones. + +If Netdata is running on a host running HAProxy, rather than connecting to Netdata from a port number, a domain name can +be pointed at HAProxy, and HAProxy can redirect connections to the Netdata port. This can make it possible to connect to +Netdata at `https://example.com` or `https://example.com/netdata/`, which is a much nicer experience then +`http://example.com:19999`. + +To proxy requests from [HAProxy](https://github.com/haproxy/haproxy) to Netdata, +the following configuration can be used: + +## Default Configuration + +For all examples, set the mode to `http` + +```conf +defaults + mode http +``` + +## Simple Configuration + +A simple example where the base URL, say `http://example.com`, is used with no subpath: + +### Frontend + +Create a frontend to receive the request. + +```conf +frontend http_frontend + ## HTTP ipv4 and ipv6 on all ips ## + bind :::80 v4v6 + + default_backend netdata_backend +``` + +### Backend + +Create the Netdata backend which will send requests to port `19999`. + +```conf +backend netdata_backend + option forwardfor + server netdata_local 127.0.0.1:19999 + + http-request set-header Host %[src] + http-request set-header X-Forwarded-For %[src] + http-request set-header X-Forwarded-Port %[dst_port] + http-request set-header Connection "keep-alive" +``` + +## Configuration with subpath + +An example where the base URL is used with a subpath `/netdata/`: + +### Frontend + +To use a subpath, create an ACL, which will set a variable based on the subpath. + +```conf +frontend http_frontend + ## HTTP ipv4 and ipv6 on all ips ## + bind :::80 v4v6 + + # URL begins with /netdata + acl is_netdata url_beg /netdata + + # if trailing slash is missing, redirect to /netdata/ + http-request redirect scheme https drop-query append-slash if is_netdata ! { path_beg /netdata/ } + + ## Backends ## + use_backend netdata_backend if is_netdata + + # Other requests go here (optional) + # put netdata_backend here if no others are used + default_backend www_backend +``` + +### Backend + +Same as simple example, except remove `/netdata/` with regex. + +```conf +backend netdata_backend + option forwardfor + server netdata_local 127.0.0.1:19999 + + http-request set-path %[path,regsub(^/netdata/,/)] + + http-request set-header Host %[src] + http-request set-header X-Forwarded-For %[src] + http-request set-header X-Forwarded-Port %[dst_port] + http-request set-header Connection "keep-alive" +``` + +## Using TLS communication + +TLS can be used by adding port `443` and a cert to the frontend. +This example will only use Netdata if host matches example.com (replace with your domain). + +### Frontend + +This frontend uses a certificate list. + +```conf +frontend https_frontend + ## HTTP ## + bind :::80 v4v6 + # Redirect all HTTP traffic to HTTPS with 301 redirect + redirect scheme https code 301 if !{ ssl_fc } + + ## HTTPS ## + # Bind to all v4/v6 addresses, use a list of certs in file + bind :::443 v4v6 ssl crt-list /etc/letsencrypt/certslist.txt + + ## ACL ## + # Optionally check host for Netdata + acl is_example_host hdr_sub(host) -i example.com + + ## Backends ## + use_backend netdata_backend if is_example_host + # Other requests go here (optional) + default_backend www_backend +``` + +In the cert list file place a mapping from a certificate file to the domain used: + +`/etc/letsencrypt/certslist.txt`: + +```txt +example.com /etc/letsencrypt/live/example.com/example.com.pem +``` + +The file `/etc/letsencrypt/live/example.com/example.com.pem` should contain the key and +certificate (in that order) concatenated into a `.pem` file.: + +```sh +cat /etc/letsencrypt/live/example.com/fullchain.pem \ + /etc/letsencrypt/live/example.com/privkey.pem > \ + /etc/letsencrypt/live/example.com/example.com.pem +``` + +### Backend + +Same as simple, except set protocol `https`. + +```conf +backend netdata_backend + option forwardfor + server netdata_local 127.0.0.1:19999 + + http-request add-header X-Forwarded-Proto https + http-request set-header Host %[src] + http-request set-header X-Forwarded-For %[src] + http-request set-header X-Forwarded-Port %[dst_port] + http-request set-header Connection "keep-alive" +``` + +## Enable authentication + +To use basic HTTP Authentication, create an authentication list: + +```conf +# HTTP Auth +userlist basic-auth-list + group is-admin + # Plaintext password + user admin password passwordhere groups is-admin +``` + +You can create a hashed password using the `mkpassword` utility. + +```sh + printf "passwordhere" | mkpasswd --stdin --method=sha-256 +$5$l7Gk0VPIpKO$f5iEcxvjfdF11khw.utzSKqP7W.0oq8wX9nJwPLwzy1 +``` + +Replace `passwordhere` with hash: + +```conf +user admin password $5$l7Gk0VPIpKO$f5iEcxvjfdF11khw.utzSKqP7W.0oq8wX9nJwPLwzy1 groups is-admin +``` + +Now add at the top of the backend: + +```conf +acl devops-auth http_auth_group(basic-auth-list) is-admin +http-request auth realm netdata_local unless devops-auth +``` + +## Full Example + +Full example configuration with HTTP auth over TLS with subpath: + +```conf +global + maxconn 20000 + + log /dev/log local0 + log /dev/log local1 notice + user haproxy + group haproxy + pidfile /run/haproxy.pid + + stats socket /run/haproxy/admin.sock mode 660 level admin expose-fd listeners + stats timeout 30s + daemon + + tune.ssl.default-dh-param 4096 # Max size of DHE key + + # Default ciphers to use on SSL-enabled listening sockets. + ssl-default-bind-ciphers ECDH+AESGCM:DH+AESGCM:ECDH+AES256:DH+AES256:ECDH+AES128:DH+AES:RSA+AESGCM:RSA+AES:!aNULL:!MD5:!DSS + ssl-default-bind-options no-sslv3 + +defaults + log global + mode http + option httplog + option dontlognull + timeout connect 5000 + timeout client 50000 + timeout server 50000 + errorfile 400 /etc/haproxy/errors/400.http + errorfile 403 /etc/haproxy/errors/403.http + errorfile 408 /etc/haproxy/errors/408.http + errorfile 500 /etc/haproxy/errors/500.http + errorfile 502 /etc/haproxy/errors/502.http + errorfile 503 /etc/haproxy/errors/503.http + errorfile 504 /etc/haproxy/errors/504.http + +frontend https_frontend + ## HTTP ## + bind :::80 v4v6 + # Redirect all HTTP traffic to HTTPS with 301 redirect + redirect scheme https code 301 if !{ ssl_fc } + + ## HTTPS ## + # Bind to all v4/v6 addresses, use a list of certs in file + bind :::443 v4v6 ssl crt-list /etc/letsencrypt/certslist.txt + + ## ACL ## + # Optionally check host for Netdata + acl is_example_host hdr_sub(host) -i example.com + acl is_netdata url_beg /netdata + + http-request redirect scheme https drop-query append-slash if is_netdata ! { path_beg /netdata/ } + + ## Backends ## + use_backend netdata_backend if is_example_host is_netdata + default_backend www_backend + +# HTTP Auth +userlist basic-auth-list + group is-admin + # Hashed password + user admin password $5$l7Gk0VPIpKO$f5iEcxvjfdF11khw.utzSKqP7W.0oq8wX9nJwPLwzy1 groups is-admin + +## Default server(s) (optional)## +backend www_backend + mode http + balance roundrobin + timeout connect 5s + timeout server 30s + timeout queue 30s + + http-request add-header 'X-Forwarded-Proto: https' + server other_server 111.111.111.111:80 check + +backend netdata_backend + acl devops-auth http_auth_group(basic-auth-list) is-admin + http-request auth realm netdata_local unless devops-auth + + option forwardfor + server netdata_local 127.0.0.1:19999 + + http-request set-path %[path,regsub(^/netdata/,/)] + + http-request add-header X-Forwarded-Proto https + http-request set-header Host %[src] + http-request set-header X-Forwarded-For %[src] + http-request set-header X-Forwarded-Port %[dst_port] + http-request set-header Connection "keep-alive" +``` + + diff --git a/docs/Running-behind-lighttpd.md b/docs/Running-behind-lighttpd.md new file mode 100644 index 00000000..d1d9acc3 --- /dev/null +++ b/docs/Running-behind-lighttpd.md @@ -0,0 +1,75 @@ +<!-- +title: "Netdata via lighttpd v1.4.x" +custom_edit_url: "https://github.com/netdata/netdata/edit/master/docs/Running-behind-lighttpd.md" +sidebar_label: "Netdata via lighttpd v1.4.x" +learn_status: "Published" +learn_topic_type: "Tasks" +learn_rel_path: "Configuration/Secure your nodes" +--> + +# Netdata via lighttpd v1.4.x + +Here is a config for accessing Netdata in a suburl via lighttpd 1.4.46 and newer: + +```txt +$HTTP["url"] =~ "^/netdata/" { + proxy.server = ( "" => ("netdata" => ( "host" => "127.0.0.1", "port" => 19999 ))) + proxy.header = ( "map-urlpath" => ( "/netdata/" => "/") ) +} +``` + +If you have older lighttpd you have to use a chain (such as below), as explained [at this stackoverflow answer](http://stackoverflow.com/questions/14536554/lighttpd-configuration-to-proxy-rewrite-from-one-domain-to-another). + +```txt +$HTTP["url"] =~ "^/netdata/" { + proxy.server = ( "" => ("" => ( "host" => "127.0.0.1", "port" => 19998 ))) +} + +$SERVER["socket"] == ":19998" { + url.rewrite-once = ( "^/netdata(.*)$" => "/$1" ) + proxy.server = ( "" => ( "" => ( "host" => "127.0.0.1", "port" => 19999 ))) +} +``` + + + +If the only thing the server is exposing via the web is Netdata (and thus no suburl rewriting required), +then you can get away with just + +``` +proxy.server = ( "" => ( ( "host" => "127.0.0.1", "port" => 19999 ))) +``` + +Though if it's public facing you might then want to put some authentication on it. htdigest support +looks like: + +``` +auth.backend = "htdigest" +auth.backend.htdigest.userfile = "/etc/lighttpd/lighttpd.htdigest" +auth.require = ( "" => ( "method" => "digest", + "realm" => "netdata", + "require" => "valid-user" + ) + ) +``` + +other auth methods, and more info on htdigest, can be found in lighttpd's [mod_auth docs](http://redmine.lighttpd.net/projects/lighttpd/wiki/Docs_ModAuth). + + + +It seems that lighttpd (or some versions of it), fail to proxy compressed web responses. +To solve this issue, disable web response compression in Netdata. + +Open `/etc/netdata/netdata.conf` and set in [global]\: + +``` +enable web responses gzip compression = no +``` + +## limit direct access to Netdata + +You would also need to instruct Netdata to listen only to `127.0.0.1` or `::1`. + +To limit access to Netdata only from localhost, set `bind socket to IP = 127.0.0.1` or `bind socket to IP = ::1` in `/etc/netdata/netdata.conf`. + + diff --git a/docs/Running-behind-nginx.md b/docs/Running-behind-nginx.md new file mode 100644 index 00000000..842a9c32 --- /dev/null +++ b/docs/Running-behind-nginx.md @@ -0,0 +1,282 @@ +# Running Netdata behind Nginx + +## Intro + +[Nginx](https://nginx.org/en/) is an HTTP and reverse proxy server, a mail proxy server, and a generic TCP/UDP proxy server used to host websites and applications of all sizes. + +The software is known for its low impact on memory resources, high scalability, and its modular, event-driven architecture which can offer secure, predictable performance. + +## Why Nginx + +- By default, Nginx is fast and lightweight out of the box. + +- Nginx is used and useful in cases when you want to access different instances of Netdata from a single server. + +- Password-protect access to Netdata, until distributed authentication is implemented via the Netdata cloud Sign In mechanism. + +- A proxy was necessary to encrypt the communication to Netdata, until v1.16.0, which provided TLS (HTTPS) support. + +## Nginx configuration file + +All Nginx configurations can be found in the `/etc/nginx/` directory. The main configuration file is `/etc/nginx/nginx.conf`. Website or app-specific configurations can be found in the `/etc/nginx/site-available/` directory. + +Configuration options in Nginx are known as directives. Directives are organized into groups known as blocks or contexts. The two terms can be used interchangeably. + +Depending on your installation source, you’ll find an example configuration file at `/etc/nginx/conf.d/default.conf` or `etc/nginx/sites-enabled/default`, in some cases you may have to manually create the `sites-available` and `sites-enabled` directories. + +You can edit the Nginx configuration file with Nano, Vim or any other text editors you are comfortable with. + +After making changes to the configuration files: + +- Test Nginx configuration with `nginx -t`. + +- Restart Nginx to effect the change with `/etc/init.d/nginx restart` or `service nginx restart`. + +## Ways to access Netdata via Nginx + +### As a virtual host + +With this method instead of `SERVER_IP_ADDRESS:19999`, the Netdata dashboard can be accessed via a human-readable URL such as `netdata.example.com` used in the configuration below. + +```conf +upstream backend { + # the Netdata server + server 127.0.0.1:19999; + keepalive 1024; +} + +server { + # nginx listens to this + listen 80; + # uncomment the line if you want nginx to listen on IPv6 address + #listen [::]:80; + + # the virtual host name of this + server_name netdata.example.com; + + location / { + proxy_set_header X-Forwarded-Host $host; + proxy_set_header X-Forwarded-Server $host; + proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; + proxy_pass http://backend; + proxy_http_version 1.1; + proxy_pass_request_headers on; + proxy_set_header Connection "keep-alive"; + proxy_store off; + } +} +``` + +### As a subfolder to an existing virtual host + +This method is recommended when Netdata is to be served from a subfolder (or directory). +In this case, the virtual host `netdata.example.com` already exists and Netdata has to be accessed via `netdata.example.com/netdata/`. + +```conf +upstream netdata { + server 127.0.0.1:19999; + keepalive 64; +} + +server { + listen 80; + # uncomment the line if you want nginx to listen on IPv6 address + #listen [::]:80; + + # the virtual host name of this subfolder should be exposed + #server_name netdata.example.com; + + location = /netdata { + return 301 /netdata/; + } + + location ~ /netdata/(?<ndpath>.*) { + proxy_redirect off; + proxy_set_header Host $host; + + proxy_set_header X-Forwarded-Host $host; + proxy_set_header X-Forwarded-Server $host; + proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; + proxy_http_version 1.1; + proxy_pass_request_headers on; + proxy_set_header Connection "keep-alive"; + proxy_store off; + proxy_pass http://netdata/$ndpath$is_args$args; + + gzip on; + gzip_proxied any; + gzip_types *; + } +} +``` + +### As a subfolder for multiple Netdata servers, via one Nginx + +This is the recommended configuration when one Nginx will be used to manage multiple Netdata servers via subfolders. + +```conf +upstream backend-server1 { + server 10.1.1.103:19999; + keepalive 64; +} +upstream backend-server2 { + server 10.1.1.104:19999; + keepalive 64; +} + +server { + listen 80; + # uncomment the line if you want nginx to listen on IPv6 address + #listen [::]:80; + + # the virtual host name of this subfolder should be exposed + #server_name netdata.example.com; + + location ~ /netdata/(?<behost>.*?)/(?<ndpath>.*) { + proxy_set_header X-Forwarded-Host $host; + proxy_set_header X-Forwarded-Server $host; + proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; + proxy_http_version 1.1; + proxy_pass_request_headers on; + proxy_set_header Connection "keep-alive"; + proxy_store off; + proxy_pass http://backend-$behost/$ndpath$is_args$args; + + gzip on; + gzip_proxied any; + gzip_types *; + } + + # make sure there is a trailing slash at the browser + # or the URLs will be wrong + location ~ /netdata/(?<behost>.*) { + return 301 /netdata/$behost/; + } +} +``` + +Of course you can add as many backend servers as you like. + +Using the above, you access Netdata on the backend servers, like this: + +- `http://netdata.example.com/netdata/server1/` to reach `backend-server1` +- `http://netdata.example.com/netdata/server2/` to reach `backend-server2` + +### Encrypt the communication between Nginx and Netdata + +In case Netdata's web server has been [configured to use TLS](https://github.com/netdata/netdata/blob/master/web/server/README.md#enabling-tls-support), it is +necessary to specify inside the Nginx configuration that the final destination is using TLS. To do this, please, append +the following parameters in your `nginx.conf` + +```conf +proxy_set_header X-Forwarded-Proto https; +proxy_pass https://localhost:19999; +``` + +Optionally it is also possible to [enable TLS/SSL on Nginx](http://nginx.org/en/docs/http/configuring_https_servers.html), this way the user will encrypt not only the communication between Nginx and Netdata but also between the user and Nginx. + +If Nginx is not configured as described here, you will probably receive the error `SSL_ERROR_RX_RECORD_TOO_LONG`. + +### Enable authentication + +Create an authentication file to enable basic authentication via Nginx, this secures your Netdata dashboard. + +If you don't have an authentication file, you can use the following command: + +```sh +printf "yourusername:$(openssl passwd -apr1)" > /etc/nginx/passwords +``` + +And then enable the authentication inside your server directive: + +```conf +server { + # ... + auth_basic "Protected"; + auth_basic_user_file passwords; + # ... +} +``` + +## Limit direct access to Netdata + +If your Nginx is on `localhost`, you can use this to protect your Netdata: + +``` +[web] + bind to = 127.0.0.1 ::1 +``` + +You can also use a unix domain socket. This will also provide a faster route between Nginx and Netdata: + +``` +[web] + bind to = unix:/var/run/netdata/netdata.sock +``` + +*note: Netdata v1.8+ support unix domain sockets* + +At the Nginx side, use something like this to use the same unix domain socket: + +```conf +upstream backend { + server unix:/var/run/netdata/netdata.sock; + keepalive 64; +} +``` + + +If your Nginx server is not on localhost, you can set: + +``` +[web] + bind to = * + allow connections from = IP_OF_NGINX_SERVER +``` + +*note: Netdata v1.9+ support `allow connections from`* + +`allow connections from` accepts [Netdata simple patterns](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md) to match against the +connection IP address. + +## Prevent the double access.log + +Nginx logs accesses and Netdata logs them too. You can prevent Netdata from generating its access log, by setting this in `/etc/netdata/netdata.conf`: + +``` +[global] + access log = none +``` + +## Use gzip compression + +By default, netdata compresses its responses. You can have nginx do that instead, with the following options in the `location /` block: + +```conf + location / { + ... + gzip on; + gzip_proxied any; + gzip_types *; + } +``` + +To disable Netdata's gzip compression, open `netdata.conf` and in the `[web]` section put: + +```conf +[web] + enable gzip compression = no +``` + +## SELinux + +If you get an 502 Bad Gateway error you might check your Nginx error log: + +```sh +# cat /var/log/nginx/error.log: +2016/09/09 12:34:05 [crit] 5731#5731: *1 connect() to 127.0.0.1:19999 failed (13: Permission denied) while connecting to upstream, client: 1.2.3.4, server: netdata.example.com, request: "GET / HTTP/2.0", upstream: "http://127.0.0.1:19999/", host: "netdata.example.com" +``` + +If you see something like the above, chances are high that SELinux prevents nginx from connecting to the backend server. To fix that, just use this policy: `setsebool -P httpd_can_network_connect true`. + + diff --git a/docs/anonymous-statistics.md b/docs/anonymous-statistics.md new file mode 100644 index 00000000..f84989e1 --- /dev/null +++ b/docs/anonymous-statistics.md @@ -0,0 +1,103 @@ +<!-- +title: "Anonymous telemetry events" +custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/anonymous-statistics.md +sidebar_label: "Anonymous telemetry events" +learn_status: "Published" +learn_rel_path: "Configuration" +--> + +# Anonymous telemetry events + +By default, Netdata collects anonymous usage information from the open-source monitoring agent. For agent events like start,stop,crash etc we use our own cloud function in GCP. For frontend telemetry (pageviews etc.) on the agent dashboard itself we use the open-source +product analytics platform [PostHog](https://github.com/PostHog/posthog). + +We are strongly committed to your [data privacy](https://netdata.cloud/privacy/). + +We use the statistics gathered from this information for two purposes: + +1. **Quality assurance**, to help us understand if Netdata behaves as expected, and to help us classify repeated + issues with certain distributions or environments. + +2. **Usage statistics**, to help us interpret how people use the Netdata agent in real-world environments, and to help + us identify how our development/design decisions influence the community. + +Netdata collects usage information via two different channels: + +- **Agent dashboard**: We use the [PostHog JavaScript integration](https://posthog.com/docs/integrations/js-integration) (with sensitive event attributes overwritten to be anonymized) to send product usage events when you access an [Agent's dashboard](https://github.com/netdata/netdata/blob/master/docs/category-overview-pages/accessing-netdata-dashboards.md). +- **Agent backend**: The `netdata` daemon executes the [`anonymous-statistics.sh`](https://github.com/netdata/netdata/blob/6469cf92724644f5facf343e4bdd76ac0551a418/daemon/anonymous-statistics.sh.in) script when Netdata starts, stops cleanly, or fails. + +You can opt-out from sending anonymous statistics to Netdata through three different [opt-out mechanisms](#opt-out). + +## Agent Dashboard - PostHog JavaScript + +When you kick off an Agent dashboard session by visiting `http://NODE:19999`, Netdata initializes a PostHog session and masks various event attributes. + +_Note_: You can see the relevant code in the [dashboard repository](https://github.com/netdata/dashboard/blob/master/src/domains/global/sagas.ts#L107) where the `window.posthog.register()` call is made. + +```JavaScript +window.posthog.register({ + distinct_id: machineGuid, + $ip: "127.0.0.1", + $current_url: "agent dashboard", + $pathname: "netdata-dashboard", + $host: "dashboard.netdata.io", +}) +``` + +In the above snippet a Netdata PostHog session is initialized and the `ip`, `current_url`, `pathname` and `host` attributes are set to constant values for all events that may be sent during the session. This way, information like the IP or hostname of the Agent will not be sent as part of the product usage event data. + +We have configured the dashboard to trigger the PostHog JavaScript code only when the variable `anonymous_statistics` is true. The value of this +variable is controlled via the [opt-out mechanism](#opt-out). + +## Agent Backend - Anonymous Statistics Script + +Every time the daemon is started or stopped and every time a fatal condition is encountered, Netdata uses the anonymous +statistics script to collect system information and send it to the Netdata telemetry cloud function via an http call. The information collected for all +events is: + +- Netdata version +- OS name, version, id, id_like +- Kernel name, version, architecture +- Virtualization technology +- Containerization technology + +Furthermore, the FATAL event sends the Netdata process & thread name, along with the source code function, source code +filename and source code line number of the fatal error. + +Starting with v1.21, we additionally collect information about: + +- Failures to build the dependencies required to use Cloud features. +- Unavailability of Cloud features in an agent. +- Failures to connect to the Cloud in case the [connection process](https://github.com/netdata/netdata/blob/master/claim/README.md) has been completed. This includes error codes + to inform the Netdata team about the reason why the connection failed. + +To see exactly what and how is collected, you can review the script template `daemon/anonymous-statistics.sh.in`. The +template is converted to a bash script called `anonymous-statistics.sh`, installed under the Netdata `plugins +directory`, which is usually `/usr/libexec/netdata/plugins.d`. + +## Opt-out + +You can opt-out from sending anonymous statistics to Netdata through three different opt-out mechanisms: + +**Create a file called `.opt-out-from-anonymous-statistics`.** This empty file, stored in your Netdata configuration +directory (usually `/etc/netdata`), immediately stops the statistics script from running, and works with any type of +installation, including manual, offline, and macOS installations. Create the file by running `touch +.opt-out-from-anonymous-statistics` from your Netdata configuration directory. + +**Pass the option `--disable-telemetry` to any of the installer scripts in the [installation +docs](https://github.com/netdata/netdata/blob/master/packaging/installer/README.md).** You can append this option during the initial installation or a manual +update. You can also export the environment variable `DISABLE_TELEMETRY` with a non-zero or non-empty value +(e.g: `export DISABLE_TELEMETRY=1`). + +When using Docker, **set your `DISABLE_TELEMETRY` environment variable to `1`.** You can set this variable with the following +command: `export DISABLE_TELEMETRY=1`. When creating a container using Netdata's [Docker +image](https://github.com/netdata/netdata/blob/master/packaging/docker/README.md#create-a-new-netdata-agent-container) for the first time, this variable will disable +the anonymous statistics script inside of the container. + +Each of these opt-out processes does the following: + +- Prevents the daemon from executing the anonymous statistics script. +- Forces the anonymous statistics script to exit immediately. +- Stops the PostHog JavaScript snippet, which remains on the dashboard, from firing and sending any data to the Netdata PostHog. + + diff --git a/docs/category-overview-pages/accessing-netdata-dashboards.md b/docs/category-overview-pages/accessing-netdata-dashboards.md new file mode 100644 index 00000000..97df8b83 --- /dev/null +++ b/docs/category-overview-pages/accessing-netdata-dashboards.md @@ -0,0 +1,38 @@ +# Accessing Netdata Dashboards + +This section contains documentation on how you can access the Netdata dashboard, which are the same both for the Agent and Cloud. + +A user accessing the Netdata dashboard **from the Cloud** will always be presented with the latest Netdata dashboard version. + +A user accessing the Netdata dashboard **from the Agent** will, by default, be presented with the latest Netdata dashboard version (the same as Netdata Cloud) except in the following scenarios: +* Agent doesn't have Internet access, and is unable to get the latest Netdata dashboards, as a result it falls back to the Netdata dashboard version that +was shipped with the agent. +* Users have defined, e.g. through URL bookmark, that they want to see the previous version of the dashboard (accessible `http://NODE:19999/v1`, replacing `NODE` with the IP address or hostname of your Agent). + +## Main sections + +The Netdata dashboard consists of the following main sections: +* [Netdata charts](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/interact-new-charts.md) +* [Infrastructure Overview](https://github.com/netdata/netdata/blob/master/docs/visualize/overview-infrastructure.md) +* [Nodes view](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/nodes.md) +* [Custom dashboards](https://learn.netdata.cloud/docs/visualizations/custom-dashboards) +* [Alerts](https://github.com/netdata/netdata/blob/master/docs/monitor/view-active-alerts.md) +* [Anomaly Advisor](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/anomaly-advisor.md) +* [Functions](https://github.com/netdata/netdata/blob/master/docs/cloud/netdata-functions.md) +* [Events feed](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/events-feed.md) + +> ⚠️ Some sections of the dashboard, when accessed through the agent, may require the user to be signed in to Netdata Cloud or having the Agent claimed to Netdata Cloud for their full functionality. Examples include saving visualization settings on charts or custom dashboards, claiming the node to Netdata Cloud, or executing functions on an Agent. + +## How to access the dashboards? + +### Netdata Cloud + +You can access the dashboard at https://app.netdata.cloud/ and [sign-in](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/sign-in.md) with an account or [sign-up](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/sign-in.md#dont-have-a-netdata-cloud-account-yet) if you don't have an account yet. + +### Netdata Agent + +Netdata starts a web server for its dashboard at port `19999`. Open up your web browser of choice and +navigate to `http://NODE:19999`, replacing `NODE` with the IP address or hostname of your Agent. If installed on localhost, you can access it through `http://localhost:19999`. + + +Documentation for previous Agent dashboard can still be found [here](https://github.com/netdata/netdata/blob/master/web/gui/README.md).
\ No newline at end of file diff --git a/docs/category-overview-pages/build-the-netdata-agent-yourself.md b/docs/category-overview-pages/build-the-netdata-agent-yourself.md new file mode 100644 index 00000000..99166ad9 --- /dev/null +++ b/docs/category-overview-pages/build-the-netdata-agent-yourself.md @@ -0,0 +1,3 @@ +# Build the Netdata Agent yourself + +This section contains documentation on all the ways that you can build the Netdata Agent.
\ No newline at end of file diff --git a/docs/category-overview-pages/deployment-strategies.md b/docs/category-overview-pages/deployment-strategies.md new file mode 100644 index 00000000..69daaf9f --- /dev/null +++ b/docs/category-overview-pages/deployment-strategies.md @@ -0,0 +1,268 @@ +# Deployment strategies + +Netdata can be used to monitor all kinds of infrastructure, from stand-alone tiny IoT devices to complex hybrid setups +combining on-premise and cloud infrastructure, mixing bare-metal servers, virtual machines and containers. + +There are 3 components to structure your Netdata ecosystem: + +1. **Netdata Agents** + To monitor the physical or virtual nodes of your infrastructure, including all applications and containers running on them. + + Netdata Agents are Open-Source, licensed under GPL v3+. + +2. **Netdata Parents** + To create data centralization points within your infrastructure, to offload Netdata Agents functions from your production + systems, to provide high-availability of your data, increased data retention and isolation of your nodes. + + Netdata Parents are implemented using the Netdata Agent software. Any Netdata Agent can be an Agent for a node and a Parent + for other Agents, at the same time. + + It is recommended to set up multiple Netdata Parents. They will all seamlessly be integrated by Netdata Cloud into one monitoring solution. + + +3. **Netdata Cloud** + Our SaaS, combining all your infrastructure, all your Netdata Agents and Parents, into one uniform, distributed, + scalable, monitoring database, offering advanced data slicing and dicing capabilities, custom dashboards, advanced troubleshooting + tools, user management, centralized management of alerts, and more. + + +The Netdata Agent is a highly modular software piece, providing data collection via numerous plugins, an in-house crafted time-series +database, a query engine, health monitoring and alerts, machine learning and anomaly detection, metrics exporting to third party systems. + + +## Deployment Options Overview + +This section provides a quick overview of a few common deployment options. The next sections go into configuration examples and further reading. + +### Stand-alone Deployment + +To help our users have a complete experience of Netdata when they install it for the first time, a Netdata Agent with default configuration +is a complete monitoring solution out of the box, having all these features enabled and available. + +The Agent will act as a _stand-alone_ Agent by default, and this is great to start out with for small setups and home labs. By [connecting each Agent to Cloud](https://github.com/netdata/netdata/blob/master/claim/README.md), you can see an overview of all your nodes, with aggregated charts and centralized alerting, without setting up a Parent. + + + +### Parent – Child Deployment + +An Agent connected to a Parent is called a _Child_. It will _stream_ metrics to its Parent. The Parent can then take care of storing metrics on behalf of that node (with longer retention), handle metrics queries for showing dashboards, and provide alerting. + +When using Cloud, it is recommended that just the Parent is connected to Cloud. Child Agents can then be configured to have short retention, in RAM instead of on Disk, and have alerting and other features disabled. Because they don't need to connect to Cloud themselves, those children can then be further secured by not allowing outbound traffic. + + + +This setup allows for leaner Child nodes and is good for setups with more than a handful of nodes. Metrics data remains accessible if the Child node is temporarily unavailable or decommissioned, although there is no failover in case the Parent becomes unavailable. + + +### Active–Active Parent Deployment + +For high availability, Parents can be configured to stream data for their children between them, and keep the data sets in sync. Child Agents are configured with the addresses of both Parent Agents, but will only stream to one of them at a time. When that Parent becomes unavailable, it reconnects to another. When the first Parent becomes available again, that Parent will catch up by receiving the backlog from the second. + +With both Parent Agents connected to Cloud, Cloud will route queries to either Parent transparently, depending on their availability. Alerts trigger on either Parent will stream to Cloud, and Cloud will deduplicate and debounce state changes to prevent spurious notifications. + + + + +## Configuration Details + +### Stand-alone Deployment + +The stand-alone setup is configured out of the box with reasonable defaults, but please consult our [configuration documentation](https://github.com/netdata/netdata/blob/master/docs/cloud/cheatsheet.md) for details, including the overview of [common configuration changes](https://github.com/netdata/netdata/blob/master/docs/configure/common-changes.md). + +### Parent – Child Deployment + +For setups involving Child and Parent Agents, the Agents need to be configured for [_streaming_](https://github.com/netdata/netdata/blob/master/streaming/README.md), through the configuration file `stream.conf`. This will instruct the Child to stream data to the Parent and the Parent to accept streaming connections for one or more Child Agents. To secure this connection, both need set up a shared API key (to replace the string `API_KEY` in the examples below). Additionally, the Child is configured with one or more addresses of Parent Agents (`PARENT_IP_ADDRESS`). + +An API key is a key created with `uuidgen` and is used for authentication and/or customization in the Parent side. I.e. a Child will stream using the API key, and a Parent is configured to accept connections from Child, but can also apply different options for children by using multiple different API keys. The easiest setup uses just one API key for all Child Agents. + +#### Child config + +As mentioned above, the recommendation is to not claim the Child to Cloud directly during your setup, avoiding establishing an [ACLK](https://github.com/netdata/netdata/blob/master/aclk/README.md) connection. + +To reduce the footprint of the Netdata Agent on your production system, some capabilities can be switched OFF on the Child and kept ON on the Parent. In this example, Machine Learning and Alerting are disabled in the Child, so that the Parent can take the load. We also use RAM instead of disk to store metrics with limited retention, covering temporary network issues. + +##### netdata.conf + +On the child node, edit `netdata.conf` by using the edit-config script: `/etc/netdata/edit-config netdata.conf` set the following parameters: + +```yaml +[db] + # https://learn.netdata.cloud/docs/agent/database + # none = no retention, ram = some retention in ram + mode = ram + # The retention in seconds. + # This provides some tolerance to the time the child has to find a parent in + # order to transfer the data. For IoT this can be lowered to 120. + retention = 1200 + # The granularity of metrics, in seconds. + # You may increase this to lower CPU resources. + update every = 1 +[ml] + # Disable Machine Learning + enabled = no +[health] + # Disable Health Checks (Alerting) + enabled = no +[web] + # Disable remote access to the local dashboard + bind to = lo +[plugins] + # Uncomment the following line to disable all external plugins on extreme + # IoT cases by default. + # enable running new plugins = no +``` + +##### stream.conf + +To edit `stream.conf`, again use the edit-config script: `/etc/netdata/edit-config stream.conf`. + +Set the following parameters: + +```yaml +[stream] + # Stream metrics to another Netdata + enabled = yes + # The IP and PORT of the parent + destination = PARENT_IP_ADDRESS:19999 + # The shared API key, generated by uuidgen + api key = API_KEY +``` + +#### Parent config + +For the Parent, besides setting up streaming, the example will also provide an example configuration of multiple [tiers](https://github.com/netdata/netdata/blob/master/database/engine/README.md#tiering) of metrics [storage](https://github.com/netdata/netdata/blob/master/docs/store/change-metrics-storage.md), for 10 children, with about 2k metrics each. + +- 1s granularity at tier 0 for 1 week +- 1m granularity at tier 1 for 1 month +- 1h granularity at tier 2 for 1 year + +Requiring: + +- 25GB of disk +- 3.5GB of RAM (2.5GB under pressure) + +##### netdata.conf + +On the Parent, edit `netdata.conf` with `/etc/netdata/edit-config netdata.conf` and set the following parameters: + +```yaml +[db] + mode = dbengine + storage tiers = 3 + # To allow memory pressure to offload index from ram + dbengine page descriptors in file mapped memory = yes + # storage tier 0 + update every = 1 + dbengine multihost disk space MB = 12000 + dbengine page cache size MB = 1400 + # storage tier 1 + dbengine tier 1 page cache size MB = 512 + dbengine tier 1 multihost disk space MB = 4096 + dbengine tier 1 update every iterations = 60 + dbengine tier 1 backfill = new + # storage tier 2 + dbengine tier 2 page cache size MB = 128 + dbengine tier 2 multihost disk space MB = 2048 + dbengine tier 2 update every iterations = 60 + dbengine tier 2 backfill = new +[ml] + # Enabled by default + # enabled = yes +[health] + # Enabled by default + # enabled = yes +[web] + # Enabled by default + # bind to = * +``` + +##### stream.conf + +On the Parent node, edit `stream.conf` with `/etc/netdata/edit-config stream.conf`, and then set the following parameters: + +```yaml +[API_KEY] + # Accept metrics streaming from other Agents with the specified API key + enabled = yes +``` + +### Active–Active Parent Deployment + +In order to setup active–active streaming between Parent 1 and Parent 2, Parent 1 needs to be instructed to stream data to Parent 2 and Parent 2 to stream data to Parent 1. The Child Agents need to be configured with the addresses of both Parent Agents. The Agent will only connect to one Parent at a time, falling back to the next if the previous failed. These examples use the same API key between Parent Agents as for connections from Child Agents. + +On both Netdata Parent and all Child Agents, edit `stream.conf` with `/etc/netdata/edit-config stream.conf`: + +##### stream.conf on Parent 1 + +```yaml +[stream] + # Stream metrics to another Netdata + enabled = yes + # The IP and PORT of Parent 2 + destination = PARENT_2_IP_ADDRESS:19999 + # This is the API key for the outgoing connection to Parent 2 + api key = API_KEY +[API_KEY] + # Accept metrics streams from Parent 2 and Child Agents + enabled = yes +``` + +##### stream.conf on Parent 2 + +```yaml +[stream] + # Stream metrics to another Netdata + enabled = yes + # The IP and PORT of Parent 1 + destination = PARENT_1_IP_ADDRESS:19999 + api key = API_KEY +[API_KEY] + # Accept metrics streams from Parent 1 and Child Agents + enabled = yes +``` + +##### stream.conf on Child Agents + +```yaml +[stream] + # Stream metrics to another Netdata + enabled = yes + # The IP and PORT of the parent + destination = PARENT_1_IP_ADDRESS:19999 PARENT_2_IP_ADDRESS:19999 + # The shared API key, generated by uuidgen + api key = API_KEY +``` + +## Further Reading + +We strongly recommend the following configuration changes for production deployments: + +1. Understand Netdata's [security and privacy design](https://github.com/netdata/netdata/blob/master/docs/netdata-security.md) and + [secure your nodes](https://github.com/netdata/netdata/blob/master/docs/category-overview-pages/secure-nodes.md) + + To safeguard your infrastructure and comply with your organization's security policies. + +2. Set up [streaming and replication](https://github.com/netdata/netdata/blob/master/streaming/README.md) to: + + - Offload Netdata Agents running on production systems and free system resources for the production applications running on them. + - Isolate production systems from the rest of the world and improve security. + - Increase data retention. + - Make your data highly available. + +3. [Optimize the Netdata Agents system utilization and performance](https://github.com/netdata/netdata/blob/master/docs/guides/configure/performance.md) + + To save valuable system resources, especially when running on weak IoT devices. + +We also suggest that you: + +1. [Use Netdata Cloud to access the dashboards](https://github.com/netdata/netdata/blob/master/docs/quickstart/infrastructure.md) + + For increased security, user management and access to our latest tools for advanced dashboarding and troubleshooting. + +2. [Change how long Netdata stores metrics](https://github.com/netdata/netdata/blob/master/docs/store/change-metrics-storage.md) + + To control Netdata's memory use, when you have a lot of ephemeral metrics. + +3. [Use host labels](https://github.com/netdata/netdata/blob/master/docs/guides/using-host-labels.md) + + To organize systems, metrics, and alerts. diff --git a/docs/category-overview-pages/install-netdata-on-embedded-systems.md b/docs/category-overview-pages/install-netdata-on-embedded-systems.md new file mode 100644 index 00000000..dfaa4482 --- /dev/null +++ b/docs/category-overview-pages/install-netdata-on-embedded-systems.md @@ -0,0 +1,3 @@ +# Install Netdata on Embedded Systems Overview + +This section contains documentation for installation methods when it comes to Embedded Systems.
\ No newline at end of file diff --git a/docs/category-overview-pages/install-with-a-cicd-provisioning-system.md b/docs/category-overview-pages/install-with-a-cicd-provisioning-system.md new file mode 100644 index 00000000..30a5a706 --- /dev/null +++ b/docs/category-overview-pages/install-with-a-cicd-provisioning-system.md @@ -0,0 +1,3 @@ +# Install with a CI/CD Provisioning System Overview + +This section contains documentation on all the installation methods through a CI/CD system.
\ No newline at end of file diff --git a/docs/category-overview-pages/installation-overview.md b/docs/category-overview-pages/installation-overview.md new file mode 100644 index 00000000..e60dd442 --- /dev/null +++ b/docs/category-overview-pages/installation-overview.md @@ -0,0 +1,10 @@ +# Installation + +In this category you can find instructions on all the possible ways you can install Netdata on the +[supported platforms](https://github.com/netdata/netdata/blob/master/packaging/PLATFORM_SUPPORT.md). + +If this is your first time using Netdata, we recommend that you first start with the +[quick installation guide](https://github.com/netdata/netdata/edit/master/packaging/installer/README.md) and then +go into the more advanced options available to you. + + diff --git a/docs/category-overview-pages/integrations-overview.md b/docs/category-overview-pages/integrations-overview.md new file mode 100644 index 00000000..6fa2f50a --- /dev/null +++ b/docs/category-overview-pages/integrations-overview.md @@ -0,0 +1,31 @@ +<!-- +title: "Integrations" +sidebar_label: "Integrations" +custom_edit_url: "https://github.com/netdata/netdata/edit/master/docs/category-overview-pages/integrations-overview.md" +description: "Available integrations in Netdata" +learn_status: "Published" +learn_rel_path: "Integrations" +sidebar_position: 60 +--> + +# Integrations + +Netdata's ability to monitor out of the box every potentially useful aspect of a node's operation is unparalleled. +But Netdata also provides out of the box, meaningful charts and alerts for hundreds of applications, with the ability +to be easily extended to monitor anything. See the full list of Netdata's capabilities and how you can extend them in the +[supported collectors list](https://github.com/netdata/netdata/blob/master/collectors/COLLECTORS.md). + +Our out of the box alerts were created by expert professionals and have been validated on the field, countless times. +Use them to trigger [alert notifications](https://github.com/netdata/netdata/blob/master/docs/monitor/enable-notifications.md) +either centrally, via the +[Cloud alert notifications](https://github.com/netdata/netdata/blob/master/docs/cloud/alerts-notifications/notifications.md) +, or by configuring individual +[agent notifications](https://github.com/netdata/netdata/blob/master/health/notifications/README.md). + +We designed Netdata with interoperability in mind. The Agent collects thousands of metrics every second, and then what +you do with them is up to you. You can +[store metrics in the database engine](https://github.com/netdata/netdata/blob/master/database/README.md), +or send them to another time series database for long-term storage or further analysis using +Netdata's [exporting engine](https://github.com/netdata/netdata/edit/master/exporting/README.md). + + diff --git a/docs/category-overview-pages/logs.md b/docs/category-overview-pages/logs.md new file mode 100644 index 00000000..fbaf8563 --- /dev/null +++ b/docs/category-overview-pages/logs.md @@ -0,0 +1,3 @@ +# Logs + +This section talks about ways Netdata collects and visualizes logs, while also providing useful guides on log centralization setups that can be used with Netdata. diff --git a/docs/category-overview-pages/machine-learning-and-assisted-troubleshooting.md b/docs/category-overview-pages/machine-learning-and-assisted-troubleshooting.md new file mode 100644 index 00000000..074051e3 --- /dev/null +++ b/docs/category-overview-pages/machine-learning-and-assisted-troubleshooting.md @@ -0,0 +1,3 @@ +# Machine Learning and Assisted Troubleshooting Overview + +This section contains documentation regarding Netdata's troubleshooting and machine learning features.
\ No newline at end of file diff --git a/docs/category-overview-pages/maintenance-operations-on-netdata-agents.md b/docs/category-overview-pages/maintenance-operations-on-netdata-agents.md new file mode 100644 index 00000000..207a0bd3 --- /dev/null +++ b/docs/category-overview-pages/maintenance-operations-on-netdata-agents.md @@ -0,0 +1,3 @@ +# Maintenance operations on Netdata Agents Overview + +This section provides information on various actions you can take when maintaining a Netdata Agent.
\ No newline at end of file diff --git a/docs/category-overview-pages/metrics-streaming-and-replication.md b/docs/category-overview-pages/metrics-streaming-and-replication.md new file mode 100644 index 00000000..f473105f --- /dev/null +++ b/docs/category-overview-pages/metrics-streaming-and-replication.md @@ -0,0 +1,175 @@ +# Netdata Parents (Streaming and Replication) + +## What are they and why do we need them? + +A “Parent” is a Netdata Agent, like the ones we install on all our systems, but is configured as a central node that receives, stores and processes metrics data from other Netdata “Child” nodes in our infrastructure. + +Netdata Parents are flexible. You can have one big active-active cluster of Netdata Parents, or you can spread a lot of independent Parents across the infrastructure. + +This “distributed still centralized” setup provides a lot of benefits. Let’s see them: + +## Infrastructure-Level Dashboards: All Nodes in One Dashboard + +A Parent node receives and aggregates metrics data from all child nodes that push metrics to it, presenting all of them on a single, centralized dashboard. + +Metrics streaming between Netdata nodes is real-time and low-latency, so that the Parent can provide the same resolution and detail its children provide. + +Each chart on the Parent’s dashboard is automatically turned into a multi-node chart, allowing instant aggregation of the data across the entire dashboard. This is transparent and automatic for all kinds of charts, even application-specific ones. For example, when you have 2 PostgreSQL servers in your infrastructure, the parent will present one set of charts for PostgreSQL and these charts will include data from both servers. + +## Increased Data Retention: Store More, Learn More + +Netdata’s database (`dbengine`), supports multiple tiers of variable resolution for storing metrics’ samples. Tier 0 is the high-resolution one and usually stores per second data. Tier 1 is the middle resolution one, downsampling data to per minute. Tier 2 is the low-resolution one, downsampling data to per hour. With this setup, a default Netdata setup is usually able to maintain 2-3 days of high resolution and up to a year of low-resolution data, all in less than 1 GB of disk space. + +In many cases, however, organizations require a lot more retention than this. A Netdata Parent can be configured to have weeks or even months of high-resolution data and several years of low-resolution data for all its Child nodes, by allowing the Netdata database to grow to hundreds of GiBs or even several TiBs. + +## Monitoring Ephemeral Nodes: No Node Left Behind + +Production systems are often ephemeral by nature. In containerized and orchestrated environments, like Kubernetes, nodes may come and go due to scaling policies, maintenance tasks, or as part of regular operations. + +Netdata Parents come to the rescue in such scenarios. They can continuously receive metrics from ephemeral nodes during their lifecycle. As these nodes are removed or replaced, the Parent retains their performance history, essentially archiving the life of each node. + +The Netdata dashboards on the Parents automatically bring into the charts data from archived nodes when users pan the dashboard to the time-window these nodes were alive. This means that no data is lost and visibility is maintained across the entire lifespan of every node, regardless of its ephemeral nature. + +## Unified Alerts Management: Silence the Noise + +Each Netdata Agent is able to run health checks, trigger alerts and send notifications on its own. However, in a large-scale infrastructure with numerous nodes, each capable of generating alerts, managing these notifications can quickly become a challenge. Duplicate alerts and non-centralized management can lead to unnecessary noise, causing alert fatigue and possibly overlooking critical warnings. + +Netdata Parents provide a solution to this problem. By configuring a Parent node to handle all alerts and health checks, and disabling health monitoring on the Child nodes, you centralize your alerts management, meaning that all alerts are now generated from a single place, reducing noise and ensuring that each unique issue only triggers a single notification. + +In addition to making alert management more straightforward, this setup also allows for more refined control over your alert configurations. Instead of managing alert settings across multiple nodes, you can handle all configurations in one place, ensuring consistency and ease of management. + +## Offloading Production Systems: Prioritize Performance + +In a production environment, every bit of system resources is crucial. Minimizing the overhead due to monitoring and observability is vital to ensure optimal system performance. Although the Netdata Agent is designed to be lightweight and efficient, using a Netdata Parent can allow the Netdata Agents on your production systems to focus on the absolutely necessary for collecting metrics and pushing them to their Parent. + +On your production systems, by configuring the Netdata Agents to use the `alloc` database mode with 5-10 minutes of retention time and disabling health monitoring and Machine Learning (ML) processing, you significantly reduce the system resources consumed by the monitoring system. + +Netdata, with the `alloc` database mode, doesn't touch the disk at all (apart from logging - which can also be disabled). This approach eliminates any potential disk I/O impact from Netdata on your production applications, which could be particularly beneficial in I/O-sensitive environments. + +## Fault Tolerance and Redundancy: Ensure Continuous Monitoring + +Netdata Agents stream metrics to one Netdata Parent at a time. But more than one Parent can be configured on each child. The first available at any given time is used. + +Similarly, Netdata Parents can be configured to stream/proxy the data they receive to another Netdata Parent. And they can support multiple Parents too, one of which will be used at any given time. + +Configuration allows setting up a circular streaming setup. Parent A streams to Parent B and Parent B streams to Parent A. Child nodes are configured to stream to any of Parents A and B and they will automatically fall back and switch parents as necessary. + +With the replication feature (enabled by default), all nodes replicate missing data on their Parent, before streaming live metrics, filling up any gap the Parent may have. + +The same setup can work for 2 or even more parents, to form an active-active multi-node cluster. Child nodes can connect to any of the parent nodes available and the parent nodes will automatically replicate and stream metrics to each other. + +The setup is optimized even for wide-area connections between child nodes and parents, or for cases where the bandwidth between child nodes and parents has a cost associated with it. At any given time each child node sends its data only once. The parents then replicate and stream this data to each other. + +## Security and Isolation: Protect Your Production Systems + +Parent nodes can be set up in your organization's Demilitarized Zone (DMZ), acting as a protective barrier or application firewall, shielding your production Netdata agents from the outside world. + +With Netdata Parents configured, the Netdata Agents running on your production systems need only one connection to these parents. They don’t need to run data queries, they will never send alert notifications, or even connect to Netdata Cloud. + +Especially for Netdata Cloud, when the Parent node is connected to Netdata Cloud, it registers its Child nodes to it and can serve all functions required by the Cloud on behalf of the Child nodes. So, although only the parent is connected to Netdata Cloud, there is no difference in the user features you enjoy on Netdata Cloud in regard to your production systems. They will all be there. + +## FAQ about Netdata Parents + +### How much can a Parent node scale? + +For about 1 million real-time metrics, with a default configuration: + +- collected and streamed to it per second, +- stored in 3 database tiers (high, mid, low resolution), +- with ML training and anomaly detection running, +- health for alerts and notifications + +And about 2 TiB of storage for metrics, you will need about 5-8 CPU cores and 32GiB of RAM. On such a setup you can have: + +- 15 days of high resolution metrics +- 3 months of mid resolution metrics +- 1 year of low resolution metrics + +For such a setup, we recommend a 16 CPU cores system so that there is spare capacity for queries. More RAM and faster disks will give faster queries. + +So, depending on the number of metrics per node you have and the size of your Parents, you may be able to aggregate 200 to 500 nodes per Parent. + +### If I set up 2 active-active parents, will I be able to have more Child nodes stream to them? + +No. When you set up an active-active cluster, even if child nodes connect randomly to one or the other, all the parent nodes receive all the metrics of all the child nodes. So, all of them do all the work. + +There is a feature we currently work on, to allow Parent nodes to detect that they receive ML information with the streamed metric data (they receive it already but they ignore it), to prevent them from training their own ML models and running anomaly detection again for the child node. But this is not ready yet. + +### How much retention do the child nodes need? + +Child nodes need to have only the retention required in order to connect to another Parent if one fails or stops for maintenance. + +- If you have an active-active cluster of parents, 5 to 10 minutes in `alloc` mode is enough. +- If you have only 1 parent, it would be better to run the child nodes with `dbengine` so that they will have enough retention to backfill the parent nodes if it stops for a few hours for maintenance. + +### Does streaming between child nodes and parents support encryption? + +Yes. You can configure your parent nodes to enable TLS and configure the child nodes to connect with TLS to it. The streaming connection is also compressed with LZ4 and this works even on top of TLS. + +### Can I have an HTTP proxy between parent and child nodes? + +No. The streaming protocol works on the same port as the internal web server of Netdata Agents, but the protocol is not HTTP-friendly and cannot be understood by HTTP proxy servers. + +### Should I load balance the parents with a TCP load balancer? + +Although this can be done and for streaming between child and parent nodes it could work, we recommend not doing it. It can lead to several kinds of problems. + +It is better to configure all the parent nodes directly in the child nodes `stream.conf`. The child nodes will do everything in their power to find a parent node to connect and they will never give up. + +### When I have an active-active cluster of parents, will I receive alert notifications from both of them? + +If both are configured to run health checks and trigger alerts, yes. + +We recommend using Netdata Cloud to avoid receiving duplicate alert notifications. Netdata Cloud deduplicates alert notifications so that you will receive them only once. On top of that, you can control silencing and routing directly from the Netdata Cloud UI. + +### When I have only Parents connected to Netdata Cloud, will I be able to use the Functions feature on my child nodes? + +Yes. + +Functions is a feature of data collection plugins to expose functions that can be run from the dashboard to view more detailed information about a data collection. For example, apps.plugin exposes the processes function that returns a list of all the processes running, together with information about their CPU utilization, memory consumption, disk I/O operations, bandwidth, and a lot more. + +When a parent receives a Function request, it forwards it to the plugin that exposes it. If the plugin is available over a streaming connection, the parent will forward the request to the socket it receives metrics from. This process will be repeated even if many parents are chained in order to reach the child. + +### If I have a set of 2 active-active parents and get one out for maintenance for a few hours, will it have missing data when it returns back online? + +There are 2 reasons you may have gaps in your data after you bring it back online: + +1. Replication does not replicate metrics that are not actively collected. So, when the parent comes back, if there are samples that this parent does not have, for metrics that are not currently being collected, these samples will not be propagated to that parent. [We are working to fix this issue](https://github.com/netdata/netdata/issues/15198). +2. If the parent has been offline for a long time and the child nodes run in db mode `alloc`, you need to plan how you will bring this parent back online. Child nodes in this mode do not have enough retention to backfill the parent and if they connect to it before the other parent, you will end up with missing information on that parent. + +The simplest way to solve this is to block at the firewall all connections to port 19999 from child nodes, but allow connections from the other parent nodes. Once replication finishes for all nodes, you can unblock the connections from child nodes to it. + +### I got a parent out of maintenance but it replicates (backfills) missing data slowly. Can I speed it up? + +Yes, there is a setting on `netdata.conf` under section `[db]` called `replication threads`. The default value is 1. + +Usually, each thread is able to replicate about 2-5 million samples per second. We suggest setting this to 5 threads for all parents. Generally do not use too many threads because you are risking congesting the disks and/or the CPU cores available. Keep in mind that the sending parent needs this setting. + +There is no need to increase this number on child nodes. Each node has one replication sender, so when hundreds of nodes are replicating to a parent, there are already a lot of senders pushing metrics to it. + +### I have multiple active-active parents. Which one is used by Netdata Cloud for queries? + +When you have multiple parents available, the one that is further away from the child node is used by Netdata Cloud, unless it does not have the data required. + +This works like this: The child has `hops = 0`. Each parent receiving metrics for this child increases the `hops` by 1. So the first parent will have `hops = 1`, the second parent will have `hops = 2` and so on. + +Netdata Cloud knows the retention of each parent. So, when it needs data from this child, it first checks the available retention each parent has for it and then it uses the parent with the higher `hops`. If no parent is available and the child node is directly connected to Netdata Cloud, it uses the child. + +### Is there a way to balance child nodes to the parent nodes of an active-active cluster? + +If you have 2 parent nodes A and B, you can configure them on half the child nodes as A, B, and the other half as B, A. The child nodes will connect to the first available (left to right). If both A and B are online, half of the child nodes will connect to A and the other half to B. + +Keep in mind, however, that if you restart a parent, all the child nodes that were connected to it will automatically reconnect to the other parent. Once this happens, the child nodes will stay connected to it. + +### Is there a way to get notified when a child gets disconnected? + +There are 2 kinds of production nodes: +1. **Permanent nodes** + These are nodes that should be available permanently and if they disconnect an alert should be triggered to notify you. + By default, all nodes are considered permanent (not ephemeral). +2. **Ephemeral nodes** + These are nodes that are ephemeral by nature and they may shutdown at any point in time without any impact on the services you run. + +To set the ephemeral flag on a node, edit its `netdata.conf` and in the `[health]` section set is `ephemeral = yes`. This setting is propagated to parent nodes and Netdata Cloud. + +When using Netdata Cloud (via a parent or directly) and a permanent node gets disconnected, Netdata Cloud sends node disconnection notifications. diff --git a/docs/category-overview-pages/misc-overview.md b/docs/category-overview-pages/misc-overview.md new file mode 100644 index 00000000..dbb11e9b --- /dev/null +++ b/docs/category-overview-pages/misc-overview.md @@ -0,0 +1,3 @@ +# Miscellaneous material + +This section contains material that will be moved to new locations as we see fit. We keep it here to make it accessible while we make these changes.
\ No newline at end of file diff --git a/docs/category-overview-pages/monitor-your-infrastructure.md b/docs/category-overview-pages/monitor-your-infrastructure.md new file mode 100644 index 00000000..3582e88a --- /dev/null +++ b/docs/category-overview-pages/monitor-your-infrastructure.md @@ -0,0 +1,3 @@ +# Monitor your Infrastructure Overview + +This section contains documentation on how you can use Netdata Cloud and it's features to monitor your entire infrastructure.
\ No newline at end of file diff --git a/docs/category-overview-pages/netdata-apis.md b/docs/category-overview-pages/netdata-apis.md new file mode 100644 index 00000000..82d1c175 --- /dev/null +++ b/docs/category-overview-pages/netdata-apis.md @@ -0,0 +1,5 @@ +# Netdata APIs Overview + +This section contains information about Netdata's APIs. + +You can access the Netdata Agent's API through swagger UI [here](/api).
\ No newline at end of file diff --git a/docs/category-overview-pages/netdata-architecture.md b/docs/category-overview-pages/netdata-architecture.md new file mode 100644 index 00000000..70f12659 --- /dev/null +++ b/docs/category-overview-pages/netdata-architecture.md @@ -0,0 +1,3 @@ +# Netdata Architecture Overview + +This section's purpose is to explain the architecture of Netdata, the role of the Agent and the Cloud, and more.
\ No newline at end of file diff --git a/docs/category-overview-pages/netdata-dashboards-and-visualizations.md b/docs/category-overview-pages/netdata-dashboards-and-visualizations.md new file mode 100644 index 00000000..cc930436 --- /dev/null +++ b/docs/category-overview-pages/netdata-dashboards-and-visualizations.md @@ -0,0 +1,3 @@ +# Netdata Dashboards and Visualizations Overview + +This section provides documentation about all the visualization operations, features and insights that Netdata provides.
\ No newline at end of file diff --git a/docs/category-overview-pages/optimizing-metrics-database.md b/docs/category-overview-pages/optimizing-metrics-database.md new file mode 100644 index 00000000..fdbd3b69 --- /dev/null +++ b/docs/category-overview-pages/optimizing-metrics-database.md @@ -0,0 +1,3 @@ +# Optimizing Metrics Database Overview + +This section contains documentation to help you understand how the metrics DB works, understand the key features and configure them to suit your needs.
\ No newline at end of file diff --git a/docs/category-overview-pages/reverse-proxies.md b/docs/category-overview-pages/reverse-proxies.md new file mode 100644 index 00000000..07c8b9bd --- /dev/null +++ b/docs/category-overview-pages/reverse-proxies.md @@ -0,0 +1,34 @@ +# Running Netdata behind a reverse proxy + +If you need to access a Netdata agent's user interface or API in a production environment we recommend you put Netdata behind +another web server and secure access to the dashboard via SSL, user authentication and firewall rules. + +A dedicated web server also provides more robustness and capabilities than the Agent's [internal web server](https://github.com/netdata/netdata/blob/master/web/README.md). + +We have documented running behind +[nginx](https://github.com/netdata/netdata/blob/master/docs/Running-behind-nginx.md), +[Apache](https://github.com/netdata/netdata/blob/master/docs/Running-behind-apache.md), +[HAProxy](https://github.com/netdata/netdata/blob/master/docs/Running-behind-haproxy.md), +[Lighttpd](https://github.com/netdata/netdata/blob/master/docs/Running-behind-lighttpd.md), +[Caddy](https://github.com/netdata/netdata/blob/master/docs/Running-behind-caddy.md), +and [H2O](https://github.com/netdata/netdata/blob/master/docs/Running-behind-h2o.md). +If you prefer a different web server, we suggest you follow the documentation for nginx and tell us how you did it + by adding your own "Running behind webserverX" document. + +When you run Netdata behind a reverse proxy, we recommend you firewall protect all your Netdata servers, so that only the web server IP will be allowed to directly access Netdata. To do this, run this on each of your servers (or use your firewall manager): + +```sh +PROXY_IP="1.2.3.4" +iptables -t filter -I INPUT -p tcp --dport 19999 \! -s ${PROXY_IP} -m conntrack --ctstate NEW -j DROP +``` + +The above will prevent anyone except your web server to access a Netdata dashboard running on the host. + +You can also use `netdata.conf`: + +``` +[web] + allow connections from = localhost 1.2.3.4 +``` + +Of course, you can add more IPs. diff --git a/docs/category-overview-pages/secure-nodes.md b/docs/category-overview-pages/secure-nodes.md new file mode 100644 index 00000000..33e205f0 --- /dev/null +++ b/docs/category-overview-pages/secure-nodes.md @@ -0,0 +1,177 @@ +# Secure your nodes
+
+Netdata is a monitoring system. It should be protected, the same way you protect all your admin apps. We assume Netdata
+will be installed privately, for your eyes only.
+
+Upon installation, the Netdata Agent serves the **local dashboard** at port `19999`. If the node is accessible to the
+internet at large, anyone can access the dashboard and your node's metrics at `http://NODE:19999`. We made this decision
+so that the local dashboard was immediately accessible to users, and so that we don't dictate how professionals set up
+and secure their infrastructures.
+
+Viewers will be able to get some information about the system Netdata is running. This information is everything the dashboard
+provides. The dashboard includes a list of the services each system runs (the legends of the charts under the `Systemd Services`
+section), the applications running (the legends of the charts under the `Applications` section), the disks of the system and
+their names, the user accounts of the system that are running processes (the `Users` and `User Groups` section of the dashboard),
+the network interfaces and their names (not the IPs) and detailed information about the performance of the system and its applications.
+
+This information is not sensitive (meaning that it is not your business data), but **it is important for possible attackers**.
+It will give them clues on what to check, what to try and in the case of DDoS against your applications, they will know if they
+are doing it right or not.
+
+Also, viewers could use Netdata itself to stress your servers. Although the Netdata daemon runs unprivileged, with the minimum
+process priority (scheduling priority `idle` - lower than nice 19) and adjusts its OutOfMemory (OOM) score to 1000 (so that it
+will be first to be killed by the kernel if the system starves for memory), some pressure can be applied on your systems if
+someone attempts a DDoS against Netdata.
+
+Instead of dictating how to secure your infrastructure, we give you many options to establish security best practices
+that align with your goals and your organization's standards.
+
+- [Disable the local dashboard](#disable-the-local-dashboard): **Simplest and recommended method** for those who have
+ added nodes to Netdata Cloud and view dashboards and metrics there.
+
+- [Expose Netdata only in a private LAN](#expose-netdata-only-in-a-private-lan). Simplest and recommended method for those who do not use Netdata Cloud.
+
+- [Fine-grained access control](#fine-grained-access-control): Allow local dashboard access from
+ only certain IP addresses, such as a trusted static IP or connections from behind a management LAN. Full support for Netdata Cloud.
+
+- [Use a reverse proxy (authenticating web server in proxy mode)](#use-an-authenticating-web-server-in-proxy-mode): Password-protect
+ a local dashboard and enable TLS to secure it. Full support for Netdata Cloud.
+
+- [Use Netdata parents as Web Application Firewalls](#use-netdata-parents-as-web-application-firewalls)
+
+- [Other methods](#other-methods) list some less common methods of protecting Netdata.
+
+## Disable the local dashboard
+
+This is the _recommended method for those who have connected their nodes to Netdata Cloud_ and prefer viewing real-time
+metrics using the War Room Overview, Nodes tab, and Cloud dashboards.
+
+You can disable the local dashboard (and API) but retain the encrypted Agent-Cloud link
+([ACLK](https://github.com/netdata/netdata/blob/master/aclk/README.md)) that
+allows you to stream metrics on demand from your nodes via the Netdata Cloud interface. This change mitigates all
+concerns about revealing metrics and system design to the internet at large, while keeping all the functionality you
+need to view metrics and troubleshoot issues with Netdata Cloud.
+
+Open `netdata.conf` with `./edit-config netdata.conf`. Scroll down to the `[web]` section, and find the `mode =
+static-threaded` setting, and change it to `none`.
+
+```conf
+[web]
+ mode = none
+```
+
+Save and close the editor, then [restart your Agent](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md)
+using `sudo systemctl
+restart netdata`. If you try to visit the local dashboard to `http://NODE:19999` again, the connection will fail because
+that node no longer serves its local dashboard.
+
+> See the [configuration basics doc](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md) for details on how to find
+`netdata.conf` and use
+> `edit-config`.
+
+## Expose Netdata only in a private LAN
+
+If your organisation has a private administration and management LAN, you can bind Netdata on this network interface on all your servers.
+This is done in `Netdata.conf` with these settings:
+
+```
+[web]
+ bind to = 10.1.1.1:19999 localhost:19999
+```
+
+You can bind Netdata to multiple IPs and ports. If you use hostnames, Netdata will resolve them and use all the IPs
+(in the above example `localhost` usually resolves to both `127.0.0.1` and `::1`).
+
+**This is the best and the suggested way to protect Netdata**. Your systems **should** have a private administration and management
+LAN, so that all management tasks are performed without any possibility of them being exposed on the internet.
+
+For cloud based installations, if your cloud provider does not provide such a private LAN (or if you use multiple providers),
+you can create a virtual management and administration LAN with tools like `tincd` or `gvpe`. These tools create a mesh VPN
+allowing all servers to communicate securely and privately. Your administration stations join this mesh VPN to get access to
+management and administration tasks on all your cloud servers.
+
+For `gvpe` we have developed a [simple provisioning tool](https://github.com/netdata/netdata-demo-site/tree/master/gvpe) you
+may find handy (it includes statically compiled `gvpe` binaries for Linux and FreeBSD, and also a script to compile `gvpe`
+on your macOS system). We use this to create a management and administration LAN for all Netdata demo sites (spread all over
+the internet using multiple hosting providers).
+
+## Fine-grained access control
+
+If you want to keep using the local dashboard, but don't want it exposed to the internet, you can restrict access with
+[access lists](https://github.com/netdata/netdata/blob/master/web/server/README.md#access-lists). This method also fully
+retains the ability to stream metrics
+on-demand through Netdata Cloud.
+
+The `allow connections from` setting helps you allow only certain IP addresses or FQDN/hostnames, such as a trusted
+static IP, only `localhost`, or connections from behind a management LAN.
+
+By default, this setting is `localhost *`. This setting allows connections from `localhost` in addition to _all_
+connections, using the `*` wildcard. You can change this setting using Netdata's [simple
+patterns](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md).
+
+```conf
+[web]
+ # Allow only localhost connections
+ allow connections from = localhost
+
+ # Allow only from management LAN running on `10.X.X.X`
+ allow connections from = 10.*
+
+ # Allow connections only from a specific FQDN/hostname
+ allow connections from = example*
+```
+
+The `allow connections from` setting is global and restricts access to the dashboard, badges, streaming, API, and
+`netdata.conf`, but you can also set each of those access lists more granularly if you choose:
+
+```conf
+[web]
+ allow connections from = localhost *
+ allow dashboard from = localhost *
+ allow badges from = *
+ allow streaming from = *
+ allow netdata.conf from = localhost fd* 10.* 192.168.* 172.16.* 172.17.* 172.18.* 172.19.* 172.20.* 172.21.* 172.22.* 172.23.* 172.24.* 172.25.* 172.26.* 172.27.* 172.28.* 172.29.* 172.30.* 172.31.*
+ allow management from = localhost
+```
+
+See the [web server](https://github.com/netdata/netdata/blob/master/web/server/README.md#access-lists) docs for additional details
+about access lists. You can take
+access lists one step further by [enabling SSL](https://github.com/netdata/netdata/blob/master/web/server/README.md#enabling-tls-support) to encrypt data from local
+dashboard in transit. The connection to Netdata Cloud is always secured with TLS.
+
+## Use an authenticating web server in proxy mode
+
+Use one web server to provide authentication in front of **all your Netdata servers**. So, you will be accessing all your Netdata with
+URLs like `http://{HOST}/netdata/{NETDATA_HOSTNAME}/` and authentication will be shared among all of them (you will sign-in once for all your servers).
+Instructions are provided on how to set the proxy configuration to have Netdata run behind
+[nginx](https://github.com/netdata/netdata/blob/master/docs/Running-behind-nginx.md),
+[HAproxy](https://github.com/netdata/netdata/blob/master/docs/Running-behind-haproxy.md),
+[Apache](https://github.com/netdata/netdata/blob/master/docs/Running-behind-apache.md),
+[lighthttpd](https://github.com/netdata/netdata/blob/master/docs/Running-behind-lighttpd.md),
+[caddy](https://github.com/netdata/netdata/blob/master/docs/Running-behind-caddy.md), and
+[H2O](https://github.com/netdata/netdata/blob/master/docs/Running-behind-h2o.md).
+
+## Use Netdata parents as Web Application Firewalls
+
+The Netdata Agents you install on your production systems do not need direct access to the Internet. Even when you use
+Netdata Cloud, you can appoint one or more Netdata Parents to act as border gateways or application firewalls, isolating
+your production systems from the rest of the world. Netdata
+Parents receive metric data from Netdata Agents or other Netdata Parents on one side, and serve most queries using their own
+copy of the data to satisfy dashboard requests on the other side.
+
+For more information see [Streaming and replication](https://github.com/netdata/netdata/blob/master/docs/metrics-storage-management/enable-streaming.md).
+
+## Other methods
+
+Of course, there are many more methods you could use to protect Netdata:
+
+- Bind Netdata to localhost and use `ssh -L 19998:127.0.0.1:19999 remote.netdata.ip` to forward connections of local port 19998 to remote port 19999.
+This way you can ssh to a Netdata server and then use `http://127.0.0.1:19998/` on your computer to access the remote Netdata dashboard.
+
+- If you are always under a static IP, you can use the script given above to allow direct access to your Netdata servers without authentication,
+from all your static IPs.
+
+- Install all your Netdata in **headless data collector** mode, forwarding all metrics in real-time to a parent
+ Netdata server, which will be protected with authentication using an nginx server running locally at the parent
+ Netdata server. This requires more resources (you will need a bigger parent Netdata server), but does not require
+ any firewall changes, since all the child Netdata servers will not be listening for incoming connections.
diff --git a/docs/category-overview-pages/troubleshooting-overview.md b/docs/category-overview-pages/troubleshooting-overview.md new file mode 100644 index 00000000..60406edd --- /dev/null +++ b/docs/category-overview-pages/troubleshooting-overview.md @@ -0,0 +1,5 @@ +# Troubleshooting and machine learning + +In this section you can learn about Netdata's advanced tools that can assist you in troubleshooting issues with +your infrastructure, to facilitate the identification of a root cause. + diff --git a/docs/category-overview-pages/visualizations-overview.md b/docs/category-overview-pages/visualizations-overview.md new file mode 100644 index 00000000..d07af062 --- /dev/null +++ b/docs/category-overview-pages/visualizations-overview.md @@ -0,0 +1,4 @@ +# Visualizations, charts and dashboards + +In this section you can learn about the various ways Netdata visualizes the collected metrics at an infrastructure level with Netdata Cloud +and at a single node level, with the Netdata Agent Dashboard. diff --git a/docs/cloud/alerts-notifications/manage-alert-notification-silencing-rules.md b/docs/cloud/alerts-notifications/manage-alert-notification-silencing-rules.md new file mode 100644 index 00000000..b9806c6f --- /dev/null +++ b/docs/cloud/alerts-notifications/manage-alert-notification-silencing-rules.md @@ -0,0 +1,58 @@ +# Manage alert notification silencing rules + +From the Cloud interface, you can manage your space's alert notification silencing rules settings as well as allow users to define their personal ones. + +## Prerequisites + +To manage **space's alert notification silencing rule settings**, you will need the following: + +- A Netdata Cloud account +- Access to the space as an **administrator** or **manager** (**troubleshooters** can only view space rules) + + +To manage your **personal alert notification silencing rule settings**, you will need the following: + +- A Netdata Cloud account +- Access to the space with any roles except **billing** + +### Steps + +1. Click on the **Space settings** cog (located above your profile icon) +1. Click on the **Alert & Notification** tab on the left hand-side +1. Click on the **Notification Silencing Rules** tab +1. You will be presented with a table of the configured alert notification silencing rules for: + * the space (if aren't an **observer**) + * yourself + + You will be able to: + 1. **Add a new** alert notification silencing rule configuration. + - Choose if it applies to **All users** or **Myself** (All users is only available for **administrators** and **managers**) + - You need to provide a name for the configuration so you can easily refer to it + - Define criteria for Nodes: To which Rooms will this apply? What Nodes? Does it apply to host labels key-value pairs? + - Define criteria for Alerts: Which alert name is being targeted? What alert context? Will it apply to a specific alert role? + - Define when it will be applied: + - Immediately, from now till until it is turned off or until a specific duration (start and end date automatically set) + - Scheduled, you specify the start and end time for when the rule becomes active and then inactive (time is set according to your browser local timezone) + Note: You are only able to add a rule if your space is on a [paid plan](https://github.com/netdata/netdata/edit/master/docs/cloud/manage/plans.md). + 1. **Edit an existing** alert notification silencing rule configurations. You will be able to change: + - The name provided for it + - Who it applies to + - Selection criteria for Nodes and Alert + - When it will be applied + 1. **Enable/Disable** a given alert notification silencing rule configuration. + - Use the toggle to enable or disable + 1. **Delete an existing** alert notification silencing rule. + - Use the trash icon to delete your configuration + +## Silencing rules examples + +| Rule name | War Rooms | Nodes | Host Label | Alert name | Alert context | Alert role | Description | +| :-- | :-- | :-- | :-- | :-- | :-- | :-- | :--| +| Space silencing | All Rooms | * | * | * | * | * | This rule silences the entire space, targets all nodes and for all users. E.g. infrastructure wide maintenance window. | +| DB Servers Rooms | PostgreSQL Servers | * | * | * | * | * | This rules silences the nodes in the room named PostgreSQL Servers, for example it doesn't silence the `All Nodes` room. E.g. My team with membership to this room doesn't want to receive notifications for these nodes. | +| Node child1 | All Rooms | `child1` | * | * | * | * | This rule silences all alert state transitions for node `child1` on all rooms and for all users. E.g. node could be going under maintenance. | +| Production nodes | All Rooms | * | `environment:production` | * | * | * | This rule silences all alert state transitions for nodes with the host label key-value pair `environment:production`. E.g. Maintenance window on nodes with specific host labels. | +| Third party maintenance | All Rooms | * | * | `httpcheck_posthog_netdata_cloud.request_status` | * | * | This rule silences this specific alert since third party partner will be undergoing maintenance. | +| Intended stress usage on CPU | All Rooms | * | * | * | `system.cpu` | * | This rule silences specific alerts across all nodes and their CPU cores. | +| Silence role webmaster | All Rooms | * | * | * | * | `webmaster` | This rule silences all alerts configured with the role `webmaster`. | +| Silence alert on node | All Rooms | `child1` | * | `httpcheck_posthog_netdata_cloud.request_status` | * | * | This rule silences the specific alert on the `child1` node. | diff --git a/docs/cloud/alerts-notifications/manage-notification-methods.md b/docs/cloud/alerts-notifications/manage-notification-methods.md new file mode 100644 index 00000000..f61b6bf6 --- /dev/null +++ b/docs/cloud/alerts-notifications/manage-notification-methods.md @@ -0,0 +1,73 @@ +# Manage notification methods + +From the Cloud interface, you can manage your space's notification settings as well as allow users to personalize their notifications setting + +## Manage space notification settings + +### Prerequisites + +To manage space notification settings, you will need the following: + +- A Netdata Cloud account +- Access to the space as an **administrator** + +### Available actions per notification methods based on service level + +| **Action** | **Personal service level** | **System service level** | +| :- | :-: | :-: | +| Enable / Disable | X | X | +| Edit | | X | | +| Delete | X | X | +| Add multiple configurations for same method | | X | + +Notes: +* For Netadata provided ones you can't delete the existing notification method configuration. +* Enable, Edit and Add actions over specific notification methods will only be allowed if your plan has access to those ([service classification](https://github.com/netdata/netdata/blob/master/docs/cloud/alerts-notifications/notifications.md#service-classification)) + +### Steps + +1. Click on the **Space settings** cog (located above your profile icon) +1. Click on the **Alerts & Notification** tab on the left hand-side +1. Click on the **Notification Methods** tab +1. You will be presented with a table of the configured notification methods for the space. You will be able to: + 1. **Add a new** notification method configuration. + - Choose the service from the list of the available ones, you'll may see a list of unavailable options if your plan doesn't allow some of them (you will see on the + card the plan level that allows a specific service) + - You can optionally provide a name for the configuration so you can easily refer to what it + - Define filtering criteria. To which Rooms will this apply? What notifications I want to receive? (All Alerts and unreachable, All Alerts, Critical only) + - Depending on the service different inputs will be present, please note that there are mandatory and optional inputs + - If you doubts on how to configure the service you can find a link at the top of the modal that takes you to the specific documentation page to help you + 1. **Edit an existing** notification method configuration. Personal level ones can't be edited here, see [Manage user notification settings](#manage-user-notification-settings). You will be able to change: + - The name provided for it + - Filtering criteria + - Service specific inputs + 1. **Enable/Disable** a given notification method configuration. + - Use the toggle to enable or disable the notification method configuration + 1. **Delete an existing** notification method configuration. Netdata provided ones can't be deleted, e.g. Email + - Use the trash icon to delete your configuration + +## Manage user notification settings + +### Prerequisites + +To manage user specific notification settings, you will need the following: + +- A Cloud account +- Have access to, at least, a space + +Note: If an administrator has disabled a Personal [service level](https://github.com/netdata/netdata/blob/master/docs/cloud/alerts-notifications/notifications.md#service-level) notification method this will override any user specific setting. + +### Steps + +1. Click on the **User notification settings** shortcut on top of the help button +1. You are presented with: + - The Personal [service level](https://github.com/netdata/netdata/blob/master/docs/cloud/alerts-notifications/notifications.md#service-level) notification methods you can manage + - The list spaces and rooms inside those where you have access to + - If you're an administrator, Manager or Troubleshooter you'll also see the Rooms from a space you don't have access to on **All Rooms** tab and you can activate notifications for them by joining the room +1. On this modal you will be able to: + 1. **Enable/Disable** the notification method for you, this applies accross all spaces and rooms + - Use the the toggle enable or disable the notification method + 1. **Define what notifications you want** to per space/room: All Alerts and unreachable, All Alerts, Critical only or No notifications + 1. **Activate notifications** for a room you aren't a member of + - From the **All Rooms** tab click on the Join button for the room(s) you want + diff --git a/docs/cloud/alerts-notifications/notifications.md b/docs/cloud/alerts-notifications/notifications.md new file mode 100644 index 00000000..cde30a2b --- /dev/null +++ b/docs/cloud/alerts-notifications/notifications.md @@ -0,0 +1,147 @@ +# Cloud alert notifications + +import Callout from '@site/src/components/Callout' + +Netdata Cloud can send centralized alert notifications to your team whenever a node enters a warning, critical, or +unreachable state. By enabling notifications, you ensure no alert, on any node in your infrastructure, goes unnoticed by +you or your team. + +Having this information centralized helps you: +* Have a clear view of the health across your infrastructure, seeing all alerts in one place. +* Easily [set up your alert notification process](https://github.com/netdata/netdata/blob/master/docs/cloud/alerts-notifications/manage-notification-methods.md): +methods to use and where to use them, filtering rules, etc. +* Quickly troubleshoot using [Metric Correlations](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/metric-correlations.md) +or [Anomaly Advisor](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/anomaly-advisor.md) + +If a node is getting disconnected often or has many alerts, we protect you and your team from alert fatigue by sending +you a flood protection notification. Getting one of these notifications is a good signal of health or performance issues +on that node. + +Admins must enable alert notifications for their [Space(s)](https://github.com/netdata/netdata/blob/master/docs/cloud/alerts-notifications/manage-notification-methods.md#manage-space-notification-settings). All users in a +Space can then personalize their notifications settings from within their [account +menu](https://github.com/netdata/netdata/blob/master/docs/cloud/alerts-notifications/#manage-user-notification-settings). + +<Callout type="notice"> + +Centralized alert notifications from Netdata Cloud is a independent process from [notifications from +Netdata](https://github.com/netdata/netdata/blob/master/docs/monitor/enable-notifications.md). You can enable one or the other, or both, based on your needs. However, +the alerts you see in Netdata Cloud are based on those streamed from your Netdata-monitoring nodes. If you want to tweak +or add new alert that you see in Netdata Cloud, and receive via centralized alert notifications, you must +[configure](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md) each node's alert watchdog. + +</Callout> + +## Alert notifications + +Netdata Cloud can send centralized alert notifications to your team whenever a node enters a warning, critical, or unreachable state. By enabling notifications, +you ensure no alert, on any node in your infrastructure, goes unnoticed by you or your team. + +If a node is getting disconnected often or has many alerts, we protect you and your team from alert fatigue by sending you a flood protection notification. +Getting one of these notifications is a good signal of health or performance issues on that node. + +Alert notifications can be delivered through different methods, these can go from an Email sent from Netdata to the use of a 3rd party tool like PagerDuty. + +Notification methods are classified on two main attributes: +* Service level: Personal or System +* Service classification: Community or Business + +Only administrators are able to manage the space's alert notification settings. +All users in a Space can personalize their notifications settings, for Personal service level notification methods, from within their profile menu. + +> ⚠️ Netdata Cloud supports different notification methods and their availability will depend on the plan you are at. +> For more details check [Service classification](#service-classification) or [netdata.cloud/pricing](https://www.netdata.cloud/pricing). + +### Service level + +#### Personal + +The notifications methods classified as **Personal** are what we consider generic, meaning that these can't have specific rules for them set by the administrators. + +These notifications are sent to the destination of the channel which is a user-specific attribute, e.g. user's e-mail, and the users are the ones that will then be able to +manage what specific configurations they want for the Space / Room(s) and the desired Notification level, they can achieve this from their User Profile page under +**Notifications**. + +One example of such a notification method is the E-mail. + +#### System + +For **System** notification methods, the destination of the channel will be a target that usually isn't specific to a single user, e.g. slack channel. + +These notification methods allow for fine-grain rule settings to be done by administrators and more than one configuration can exist for them since. You can specify +different targets depending on Rooms or Notification level settings. + +Some examples of such notification methods are: Webhook, PagerDuty, Slack. + +### Service classification + +#### Community + +Notification methods classified as Community can be used by everyone independent on the plan your space is at. +These are: Email and discord + +#### Pro + +Notification methods classified as Pro are only available for **Pro** and **Business** plans +These are: webhook + +#### Business + +Notification methods classified as Business are only available for **Business** plans +These are: PagerDuty, Slack, Opsgenie + +## Silencing Alert notifications + +Netdata Cloud provides you a Silencing Rule engine which allows you to mute alert notifications. This muting action is specific to alert state transition notifications, it doesn't include node unreachable state transitions. + +The Silencing Rule engine is flexible and allows you to enter silence rules for the two main entities involved on alert notifications and can be set using different attributes. The main entities you can enter are **Nodes** and **Alerts** which can be used in combination or isolation to target specific needs - see some examples [here](https://github.com/netdata/netdata/blob/master/docs/cloud/alerts-notifications/manage-alert-notification-silencing-rules.md#silencing-rules-examples). + +### Scope definition for Nodes +* **Space:** silencing the space, selecting `All Rooms`, silences all alert state transitions from any node claimed to the space. +* **War Room:** silencing a specific room will silence all alert state transitions from any node in that room. Please note if the node belongs to +another room which isn't silenced it can trigger alert notifications to the users with membership to that other room. +* **Node:** silencing a specific node can be done for the entire space, selecting `All Rooms`, or for specific war room(s). The main difference is +if the node should be silenced for the entire space or just for specific rooms (when specific rooms are selected only users with membership to that room won't receive notifications). + +### Scope definition for Alerts +* **Alert name:** silencing a specific alert name silences all alert state transitions for that specific alert. +* **Alert context:** silencing a specific alert context will silence all alert state transitions for alerts targeting that chart context, for more details check [alert configuration docs](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md#alert-line-on). +* **Alert role:** silencing a specific alert role will silence all the alert state transitions for alerts that are configured to be specific role recipients, for more details check [alert configuration docs](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md#alert-line-to). + +Beside the above two main entities there are another two important settings that you can define on a silencing rule: +* Who does the rule affect? **All user** in the space or **Myself** +* When does is to apply? **Immediately** or on a **Schedule** (when setting immediately you can set duration) + +For further help on setting alert notification silencing rules go to [Manage Alert Notification Silencing Rules](https://github.com/netdata/netdata/blob/master/docs/cloud/alerts-notifications/manage-alert-notification-silencing-rules.md). + +> ⚠️ This feature is only available for [Netdata paid plans](https://github.com/netdata/netdata/edit/master/docs/cloud/manage/plans.md). + +## Flood protection + +If a node has too many state changes like firing too many alerts or going from reachable to unreachable, Netdata Cloud +enables flood protection. As long as a node is in flood protection mode, Netdata Cloud does not send notifications about +this node. Even with flood protection active, it is possible to access the node directly, either via Netdata Cloud or +the local Agent dashboard at `http://NODE:19999`. + +## Anatomy of an alert notification + +Email alert notifications show the following information: + +- The Space's name +- The node's name +- Alert status: critical, warning, cleared +- Previous alert status +- Time at which the alert triggered +- Chart context that triggered the alert +- Name and information about the triggered alert +- Alert value +- Total number of warning and critical alerts on that node +- Threshold for triggering the given alert state +- Calculation or database lookups that Netdata uses to compute the value +- Source of the alert, including which file you can edit to configure this alert on an individual node + +Email notifications also feature a **Go to Node** button, which takes you directly to the offending chart for that node +within Cloud's embedded dashboards. + +Here's an example email notification for the `ram_available` chart, which is in a critical state: + +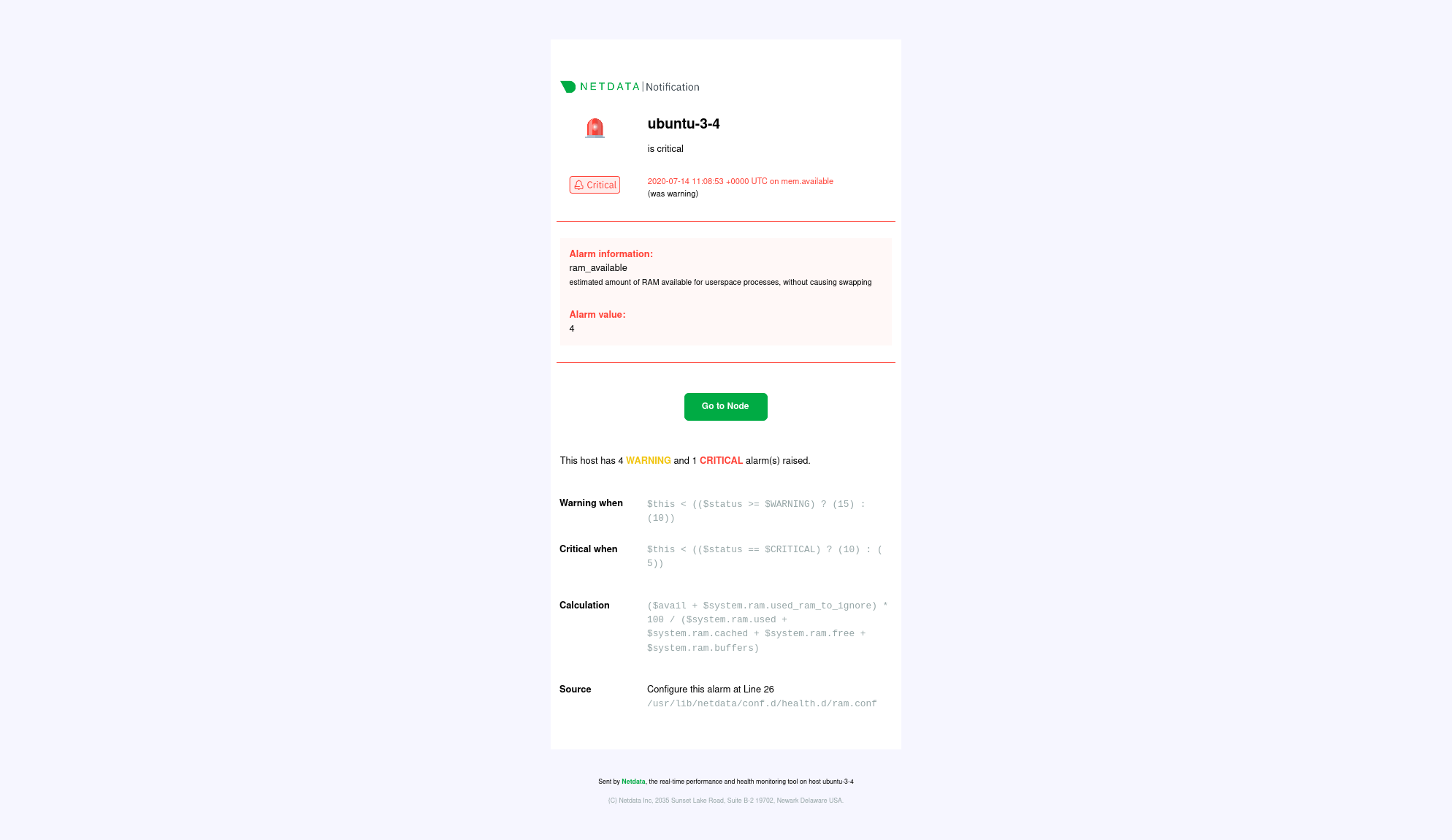 diff --git a/docs/cloud/cheatsheet.md b/docs/cloud/cheatsheet.md new file mode 100644 index 00000000..a3d2f028 --- /dev/null +++ b/docs/cloud/cheatsheet.md @@ -0,0 +1,215 @@ +# Useful management and configuration actions + +Below you will find some of the most common actions that one can take while using Netdata. You can use this page as a quick reference for installing Netdata, connecting a node to the Cloud, properly editing the configuration, accessing Netdata's API, and more! + +### Install Netdata + +```bash +wget -O /tmp/netdata-kickstart.sh https://my-netdata.io/kickstart.sh && sh /tmp/netdata-kickstart.sh + +# Or, if you have cURL but not wget (such as on macOS): +curl https://my-netdata.io/kickstart.sh > /tmp/netdata-kickstart.sh && sh /tmp/netdata-kickstart.sh +``` + +#### Connect a node to Netdata Cloud + +To do so, sign in to Netdata Cloud, on your Space under the Nodes tab, click `Add Nodes` and paste the provided command into your node’s terminal and run it. +You can also copy the Claim token and pass it to the installation script with `--claim-token` and re-run it. + +### Configuration + +**Netdata's config directory** is `/etc/netdata/` but in some operating systems it might be `/opt/netdata/etc/netdata/`. +Look for the `# config directory =` line over at `http://NODE_IP:19999/netdata.conf` to find your config directory. + +From within that directory you can run `sudo ./edit-config netdata.conf` **to edit Netdata's configuration.** +You can edit other config files too, by specifying their filename after `./edit-config`. +You are expected to use this method in all following configuration changes. + +<!-- #### Edit Netdata's other config files (examples): + +- `$ sudo ./edit-config apps_groups.conf` +- `$ sudo ./edit-config ebpf.conf` +- `$ sudo ./edit-config health.d/load.conf` +- `$ sudo ./edit-config go.d/prometheus.conf` + +#### View the running Netdata configuration: `http://NODE:19999/netdata.conf` + +> Replace `NODE` with the IP address or hostname of your node. Often `localhost`. + +## Metrics collection & retention + +You can tweak your settings in the netdata.conf file. +📄 [Find your netdata.conf file](https://github.com/netdata/netdata/blob/master/daemon/config/README.md) + +Open a new terminal and navigate to the netdata.conf file. Use the edit-config script to make changes: `sudo ./edit-config netdata.conf` + +The most popular settings to change are: + +#### Increase metrics retention (4GiB) + +``` +sudo ./edit-config netdata.conf +``` + +``` +[global] + dbengine multihost disk space = 4096 +``` + +#### Reduce the collection frequency (every 5 seconds) + +``` +sudo ./edit-config netdata.conf +``` + +``` +[global] + update every = 5 +``` --> + +--- + +#### Enable/disable plugins (groups of collectors) + +```bash +sudo ./edit-config netdata.conf +``` + +```conf +[plugins] + go.d = yes # enabled + node.d = no # disabled +``` + +#### Enable/disable specific collectors + +```bash +sudo ./edit-config go.d.conf # edit a plugin's config +``` + +```yaml +modules: + activemq: no # disabled + cockroachdb: yes # enabled +``` + +#### Edit a collector's config + +```bash +sudo ./edit-config go.d/mysql.conf +``` + +### Alerts & notifications + +<!-- #### Add a new alert + +``` +sudo touch health.d/example-alert.conf +sudo ./edit-config health.d/example-alert.conf +``` --> +After any change, reload the Netdata health configuration: + +```bash +netdatacli reload-health +#or if that command doesn't work on your installation, use: +killall -USR2 netdata +``` + +#### Configure a specific alert + +```bash +sudo ./edit-config health.d/example-alert.conf +``` + +#### Silence a specific alert + +```bash +sudo ./edit-config health.d/example-alert.conf +``` + +``` + to: silent +``` + +<!-- #### Disable alerts and notifications + +```conf +[health] + enabled = no +``` --> + +--- + +### Manage the daemon + +| Intent | Action | +|:----------------------------|------------------------------------------------------------:| +| Start Netdata | `$ sudo service netdata start` | +| Stop Netdata | `$ sudo service netdata stop` | +| Restart Netdata | `$ sudo service netdata restart` | +| Reload health configuration | `$ sudo netdatacli reload-health` `$ killall -USR2 netdata` | +| View error logs | `less /var/log/netdata/error.log` | +| View collectors logs | `less /var/log/netdata/collector.log` | + +#### Change the port Netdata listens to (example, set it to port 39999) + +```conf +[web] +default port = 39999 +``` + +### See metrics and dashboards + +#### Netdata Cloud: `https://app.netdata.cloud` + +#### Local dashboard: `https://NODE:19999` + +> Replace `NODE` with the IP address or hostname of your node. Often `localhost`. + +### Access the Netdata API + +You can access the API like this: `http://NODE:19999/api/VERSION/REQUEST`. +If you want to take a look at all the API requests, check our API page at <https://learn.netdata.cloud/api> +<!-- +## Interact with charts + +| Intent | Action | +| -------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: | +| Stop a chart from updating | `click` | +| Zoom | **Cloud** <br/> use the `zoom in` and `zoom out` buttons on any chart (upper right corner) <br/><br/> **Agent**<br/>`SHIFT` or `ALT` + `mouse scrollwheel` <br/> `SHIFT` or `ALT` + `two-finger pinch` (touchscreen) <br/> `SHIFT` or `ALT` + `two-finger scroll` (touchscreen) | +| Zoom to a specific timeframe | **Cloud**<br/>use the `select and zoom` button on any chart and then do a `mouse selection` <br/><br/> **Agent**<br/>`SHIFT` + `mouse selection` | +| Pan forward or back in time | `click` & `drag` <br/> `touch` & `drag` (touchpad/touchscreen) | +| Select a certain timeframe | `ALT` + `mouse selection` <br/> WIP need to evaluate this `command?` + `mouse selection` (macOS) | +| Reset to default auto refreshing state | `double click` | --> + +<!-- ## Dashboards + +#### Disable the local dashboard + +Use the `edit-config` script to edit the `netdata.conf` file. + +``` +[web] +mode = none +``` --> + +<!-- #### Opt out from anonymous statistics + +``` +sudo touch .opt-out-from-anonymous-statistics +``` --> + +<!-- ## Understanding the dashboard + +**Charts**: A visualization displaying one or more collected/calculated metrics in a time series. Charts are generated +by collectors. + +**Dimensions**: Any value shown on a chart, which can be raw or calculated values, such as percentages, averages, +minimums, maximums, and more. + +**Families**: One instance of a monitored hardware or software resource that needs to be monitored and displayed +separately from similar instances. Example, disks named +**sda**, **sdb**, **sdc**, and so on. + +**Contexts**: A grouping of charts based on the types of metrics collected and visualized. +**disk.io**, **disk.ops**, and **disk.backlog** are all contexts. --> diff --git a/docs/cloud/insights/anomaly-advisor.md b/docs/cloud/insights/anomaly-advisor.md new file mode 100644 index 00000000..4804dbc1 --- /dev/null +++ b/docs/cloud/insights/anomaly-advisor.md @@ -0,0 +1,87 @@ +<!-- +title: "Anomaly Advisor" +description: "Quickly find anomalous metrics anywhere in your infrastructure." +custom_edit_url: "https://github.com/netdata/netdata/blob/master/docs/cloud/insights/anomaly-advisor.md" +sidebar_label: "Anomaly Advisor" +learn_status: "Published" +learn_topic_type: "Tasks" +learn_rel_path: "Operations" +--> + +# Anomaly Advisor + +import ReactPlayer from 'react-player' + +The Anomaly Advisor feature lets you quickly surface potentially anomalous metrics and charts related to a particular highlight window of +interest. + +<ReactPlayer playing true controls true url='https://user-images.githubusercontent.com/24860547/165943403-1acb9759-7446-4704-8955-c566d04ad7ab.mp4' /> + +## Getting Started + +If you are running a Netdata version higher than `v1.35.0-29-nightly` you will be able to use the Anomaly Advisor out of the box with zero configuration. If you are on an earlier Netdata version you will need to first enable ML on your nodes by following the steps below. + +To enable the Anomaly Advisor you must first enable ML on your nodes via a small config change in `netdata.conf`. Once the anomaly detection models have trained on the Agent (with default settings this takes a couple of hours until enough data has been seen to train the models) you will then be able to enable the Anomaly Advisor feature in Netdata Cloud. + +### Enable ML on Netdata Agent + +To enable ML on your Netdata Agent, you need to edit the `[ml]` section in your `netdata.conf` to look something like the following example. + +```bash +[ml] + enabled = yes +``` + +At a minimum you just need to set `enabled = yes` to enable ML with default params. More details about configuration can be found in the [Netdata Agent ML docs](https://github.com/netdata/netdata/blob/master/ml/README.md#configuration). + +When you have finished your configuration, restart Netdata with a command like `sudo systemctl restart netdata` for the config changes to take effect. You can find more info on restarting Netdata [here](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md). + +After a brief delay, you should see the number of `trained` dimensions start to increase on the "dimensions" chart of the "Anomaly Detection" menu on the Overview page. By default the `minimum num samples to train = 3600` parameter means at least 1 hour of data is required to train initial models, but you could set this to `900` if you want to train initial models quicker but on less data. Over time, they will retrain on up to `maximum num samples to train = 14400` (4 hours by default), but you could increase this is you wanted to train on more data. + +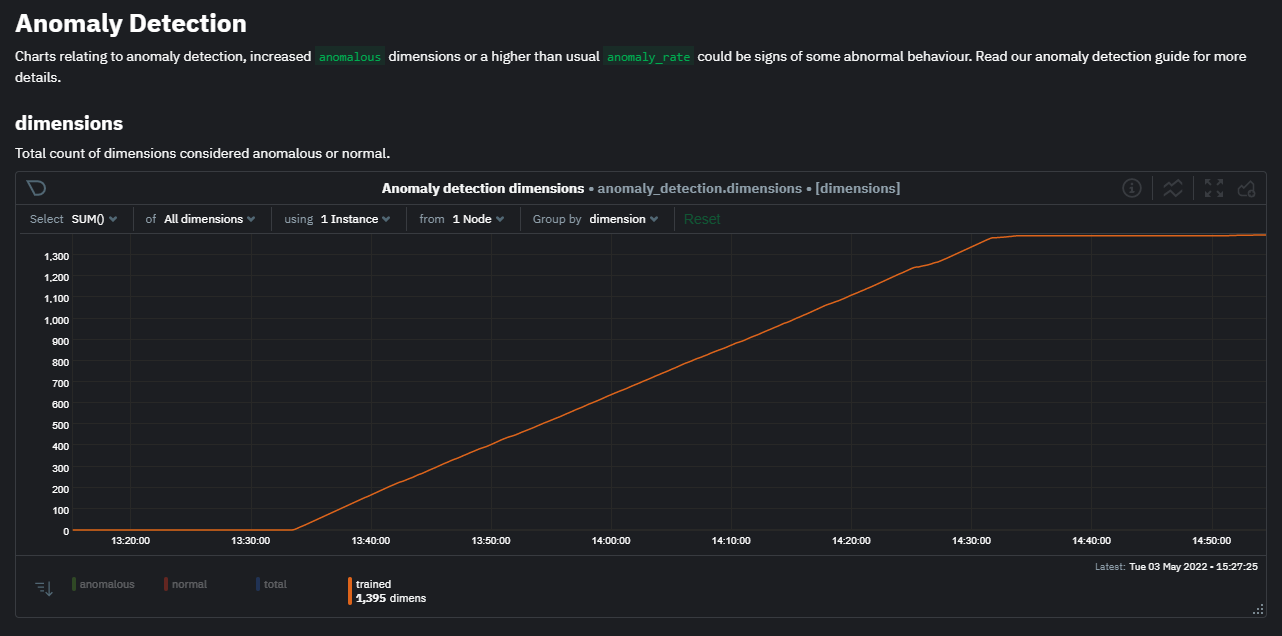 + +Once this line flattens out all configured metrics should have models trained and predicting anomaly scores each second, ready to be used by the new "anomalies" tab of the Anomaly Advisor. + +## Using Anomaly Advisor + +To use the Anomaly Advisor, go to the "anomalies" tab. Once you highlight a particular timeframe of interest, a selection of the most anomalous dimensions will appear below. + +The aim here is to surface the most anomalous metrics in the space or room for the highlighted window to try and cut down on the amount of manual searching required to get to the root cause of your issues. + +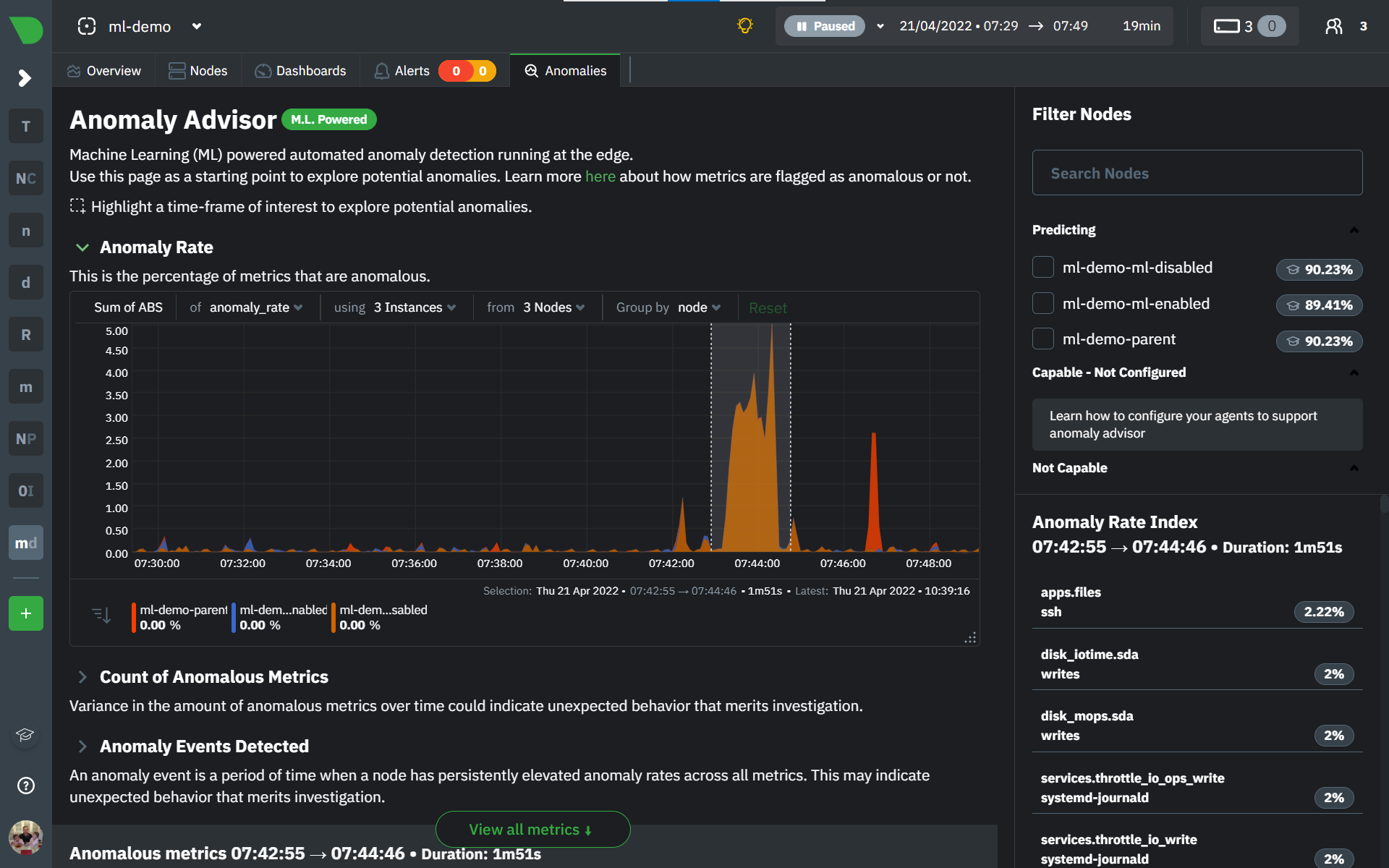 + +The "Anomaly Rate" chart shows the percentage of anomalous metrics over time per node. For example, in the following image, 3.21% of the metrics on the "ml-demo-ml-disabled" node were considered anomalous. This elevated anomaly rate could be a sign of something worth investigating. + +**Note**: in this example the anomaly rates for this node are actually being calculated on the parent it streams to, you can run ml on the Agent itselt or on a parent the Agent stream to. Read more about the various configuration options in the [Agent docs](https://github.com/netdata/netdata/blob/master/ml/README.md). + +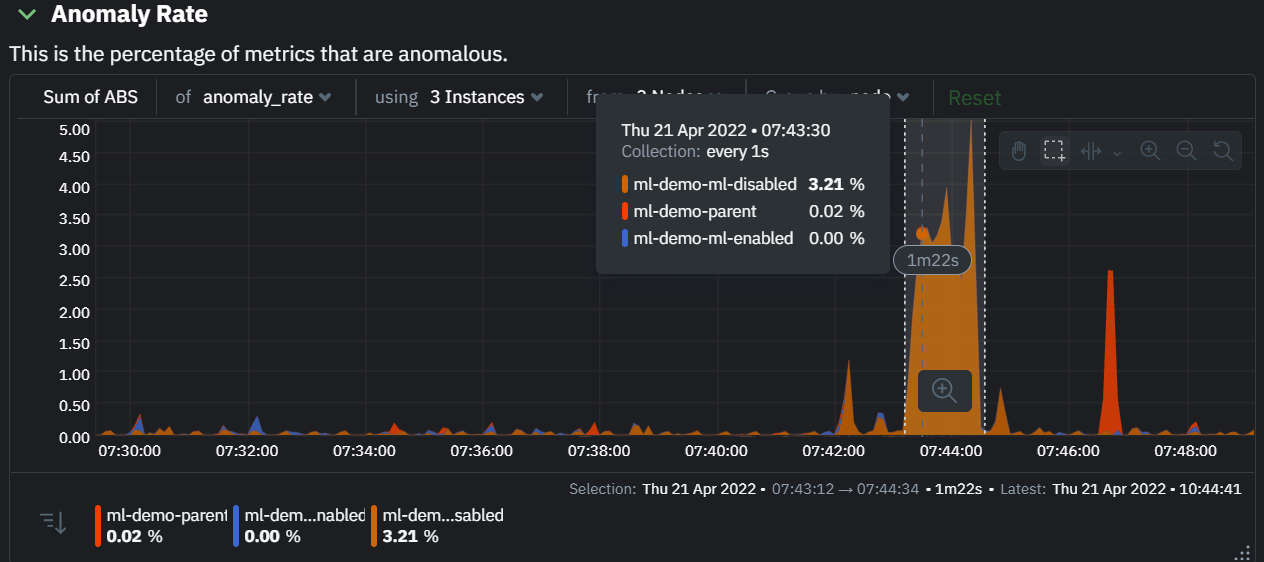 + +The "Count of Anomalous Metrics" chart (collapsed by default) shows raw counts of anomalous metrics per node so may often be similar to the anomaly rate chart, apart from where nodes may have different numbers of metrics. + +The "Anomaly Events Detected" chart (collapsed by default) shows if the anomaly rate per node was sufficiently elevated to trigger a node level anomaly. Anomaly events will appear slightly after the anomaly rate starts to increase in the timeline, this is because a significant number of metrics in the node need to be anomalous before an anomaly event is triggered. + +Once you have highlighted a window of interest, you should see an ordered list of anomaly rate sparklines in the "Anomalous metrics" section like below. + +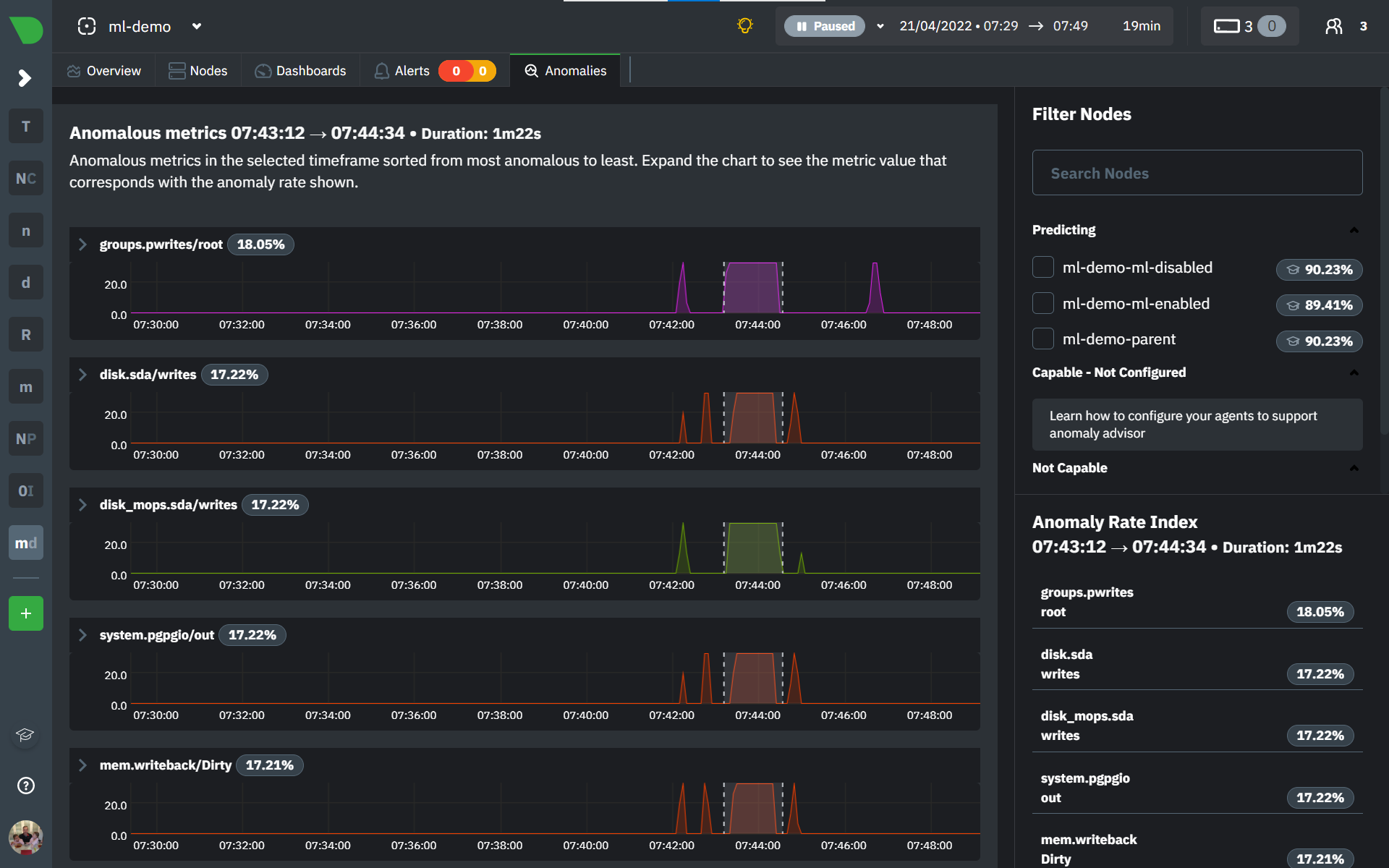 + +You can expand any sparkline chart to see the underlying raw data to see how it relates to the corresponding anomaly rate. + +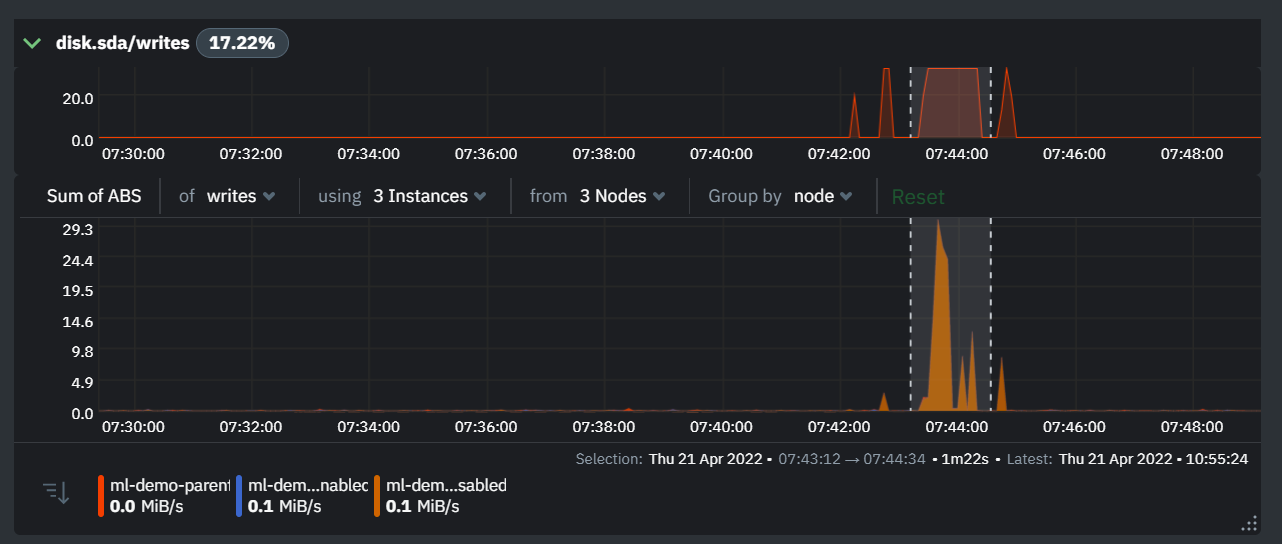 + +On the upper right hand side of the page you can select which nodes to filter on if you wish to do so. The ML training status of each node is also displayed. + +On the lower right hand side of the page an index of anomaly rates is displayed for the highlighted timeline of interest. The index is sorted from most anomalous metric (highest anomaly rate) to least (lowest anomaly rate). Clicking on an entry in the index will scroll the rest of the page to the corresponding anomaly rate sparkline for that metric. + +### Usage Tips + +- If you are interested in a subset of specific nodes then filtering to just those nodes before highlighting tends to give better results. This is because when you highlight a region, Netdata Cloud will ask the Agents for a ranking over all metrics so if you can filter this early to just the subset of nodes you are interested in, less 'averaging' will occur and so you might be a less noisy ranking. +- Ideally try and highlight close to a spike or window of interest so that the resulting ranking can narrow in more easily on the timeline you are interested in. + +You can read more detail on how anomaly detection in the Netdata Agent works in our [Agent docs](https://github.com/netdata/netdata/blob/master/ml/README.md). + +🚧 **Note**: This functionality is still **under active development** and considered experimental. We dogfood it internally and among early adopters within the Netdata community to build the feature. If you would like to get involved and help us with feedback, you can reach us through any of the following channels: + +- Email us at analytics-ml-team@netdata.cloud +- Comment on the [beta launch post](https://community.netdata.cloud/t/anomaly-advisor-beta-launch/2717) in the Netdata community +- Join us in the [🤖-ml-powered-monitoring](https://discord.gg/4eRSEUpJnc) channel of the Netdata discord. +- Or open a discussion in GitHub if that's more your thing diff --git a/docs/cloud/insights/events-feed.md b/docs/cloud/insights/events-feed.md new file mode 100644 index 00000000..a56877ab --- /dev/null +++ b/docs/cloud/insights/events-feed.md @@ -0,0 +1,99 @@ +<!-- +title: "Events feed" +sidebar_label: "Events feed" +custom_edit_url: "https://github.com/netdata/netdata/blob/master/docs/cloud/insights/events-feed.md" +sidebar_position: "2800" +learn_status: "Published" +learn_topic_type: "Concepts" +learn_rel_path: "Concepts" +learn_docs_purpose: "Present the Netdata Events feed." +--> + +# Events feed + +Netdata Cloud provides the Events feed which is a powerful feature that tracks events that happen on your infrastructure, or in your Space. The feed lets you investigate events that occurred in the past, which is invaluable for troubleshooting. Common use cases are ones like when a node goes offline, and you want to understand what events happened before that. A detailed event history can also assist in attributing sudden pattern changes in a time series to specific changes in your environment. + +## What are the available events? + +At a high-level view, these are the domains from which the Events feed will provide visibility into. + +> ⚠️ Based on your space's plan, different allowances are defined to query past data. + +| **Domains of events** | **Community** | **Pro** | **Business** | +| :-- | :-- | :-- | :-- | +| **[Auditing events](#auditing-events)** - <br/>Events related to actions done on your Space, e.g. invite user, change user role or change plan.| 4 hours | 7 days | 90 days | +| **[Topology events](#topology-events)**<br/>Node state transition events, e.g. live or offline.| 4 hours | 7 days | 14 days | +| **[Alert events](#alert-events)**<br/>Alert state transition events, can be seen as an alert history log.| 4 hours | 7 days | 90 days | + +### Auditing events + +| **Event name** | **Description** | **Example** | +| :-- | :-- | :-- | +| Space Created | The space was created.| Space `Acme Space` was **created** | +| Room Created | A room was created on the Space.| Room `DB Servers` was **created** by `John Doe` | +| Room Deleted | A room was deleted from the Space. | Room `DB servers` was **deleted** by `John Doe` | +| User Invited to Space | A user was invited to join the Space.| User `John Smith` was **invited** to this space by `Alan Doe` | +| User Uninvited from Space | An invitation for a user to join the space was revoked.| User `John Smith` was **uninvited** from this space | +| User Added to Space | A user was added to the Space from an invitation (user accepted the invitation).| User `John Smith` was **added** to this space by invite of `Alan Doe` | +| User Removed from Space | A user was added to the Space from an invitation. | User `John Smith` was **removed** from this space by `Alan Doe` | +| User Added to Room | A user was added to a room on the Space. | User `John Smith` was **added** to room `DB servers` | +| User Removed from Room | A user was removed from a room on the Space. | User `John Smith` was **removed** from room `DB Servers` by `Alan Doe` | +| User Space Properties Changed | The properties of a user on the Space have changed, e.g. change user role | User role for `John Smith` was **changed** to `troubleshooter` by `Alan Doe` | +| Node Added To Room | The node was added to a room on the Space. | Node `ip-xyz.ec2.internal` was **added** to room `DB Servers` by `John Doe` | +| Node Removed To Room | The node was removed from a room on the Space. | Node `ip-xyz.ec2.internal` was **removed** from room `DB Servers` by `John Doe` | +| Silencing Rule Created | A new alert notification silencing rule was created on the Space. | Silencing rule `DB Servers schedule silencing` on rooms `All nodes` and `DB Servers` was **created** by `John Smith` | +| Silencing Rule Changed | An existing alert notification silencing rule was modified on the Space. | Silencing rule `DB Servers schedule silencing` on rooms `All nodes` and `DB Servers` was **changed** by `John Doe` | +| Silencing Rule Deleted | An existing alert notifications silencing rule was removed from the Space. | Silencing rule `DB Servers schedule silencing` on rooms `All nodes` and `DB Servers` was **changed** by `Alan Smith` | + +### Topology events + +| **Event name** | **Description** | **Example** | +| :-- | :-- | :-- | +| Node Became Live | The node is collecting and streaming metrics to Cloud.| Node `netdata-k8s-state-xyz` was **live** | +| Node Became Stale | The node is offline and not streaming metrics to Cloud. It can show historical data from a parent node. | Node `ip-xyz.ec2.internal` was **stale** | +| Node Became Offline | The node is offline, not streaming metrics to Cloud and not available in any parent node.| Node `ip-xyz.ec2.internal` was **offline** | +| Node Created | The node is created but it is still `Unseen` on Cloud, didn't establish a successful connection yet.| Node `ip-xyz.ec2.internal` was **created** | +| Node Removed |The node was removed from the Space, for example by using the `Delete` action on the node. This is a soft delete in that the node gets marked as deleted, but retains the association with this space. If it becomes live again, it will be restored (see `Node Restored` below) and reappear in this space as before. | Node `ip-xyz.ec2.internal` was **deleted (soft)** | +| Node Restored | The node was restored. See `Node Removed` above. | Node `ip-xyz.ec2.internal` was **restored** | +| Node Deleted | The node was deleted from the Space. This is a hard delete and no information on the node is retained. | Node `ip-xyz.ec2.internal` was **deleted (hard)** | +| Agent Connected | The agent connected to the Cloud MQTT server (Agent-Cloud Link established).<br/>These events can only be seen on _All nodes_ War Room. | Agent with claim ID `7d87bqs9-cv42-4823-8sd4-3614548850c7` has connected to Cloud. | +| Agent Disconnected | The agent disconnected from the Cloud MQTT server (Agent-Cloud Link severed).<br/>These events can only be seen on _All nodes_ War Room. | Agent with claim ID `7d87bqs9-cv42-4823-8sd4-3614548850c7` has disconnected from Cloud: **Connection Timeout**. | +| Space Statistics | Daily snapshot of space node statistics.<br/>These events can only be seen on _All nodes_ War Room. | Space statistics. Nodes: **22 live**, **21 stale**, **18 removed**, **61 total**. | + + +### Alert events + +| **Event name** | **Description** | **Example** | +| :-- | :-- | :-- | +| Node Alert State Changed | These are node alert state transition events and can be seen as an alert history log. You will be able to see transitions to or from any of these states: Cleared, Warning, Critical, Removed, Error or Unknown | Transition to Cleared:<br/>`httpcheck_web_service_bad_status` for `httpcheck_netdata_cloud.request_status` on `netdata-parent-xyz` recovered with value **8.33%**<br/><br/>Transition from Cleared to Warning or Critical:<br/>`httpcheck_web_service_bad_status` for `httpcheck_netdata_cloud.request_status` on `netdata-parent-xyz` was raised to **WARNING** with value **10%**<br/><br/>Transition from Warning to Critical:<br/>`httpcheck_web_service_bad_status` for `httpcheck_netdata_cloud.request_status` on `netdata-parent-xyz` escalated to **CRITICAL** with value **25%**<br/><br/>Transition from Critical to Warning:<br/>`httpcheck_web_service_bad_status` for `httpcheck_netdata_cloud.request_status` on `netdata-parent-xyz` was demoted to **WARNING** with value **10%**<br/><br/>Transition to Removed:<br/>Alert `httpcheck_web_service_bad_status` for `httpcheck_netdata_cloud.request_status` on `netdata-parent-xyz` is no longer available, state can't be assessed.<br/><br/>Transition to Error:<br/>For this alert `httpcheck_web_service_bad_status` related to `httpcheck_netdata_cloud.request_status` on `netdata-parent-xyz` we couldn't calculate the current value ⓘ| + +## Who can access the events? + +All users will be able to see events from the Topology and Alerts domain but Auditing events, once these are added, only be accessible to administrators. For more details checkout [Netdata Role-Based Access model](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/role-based-access.md). + +## How to use the events feed + +1. Click on the **Events** tab (located near the top of your screen) +1. You will be presented with a table listing the events that occurred from the timeframe defined on the date time picker +1. You can use the filtering capabilities available on right-hand bar to slice through the results provided. See more details on event types and filters + +Note: When you try to query a longer period than what your space allows you will see an error message highlighting that you are querying data outside of your plan. + +### Event types and filters + +| Event type | Tags | Nodes | Alert Status | Alert Names | Chart Names | +| :-- | :-- | :-- | :-- | :-- | :-- | +| Node Became Live | node, lifecycle | Node name | - | - | - | +| Node Became Stale | node, lifecycle | Node name | - | - | - | +| Node Became Offline | node, lifecycle | Node name | - | - | - | +| Node Created | node, lifecycle | Node name | - | - | - | +| Node Removed | node, lifecycle | Node name | - | - | - | +| Node Restored | node, lifecycle | Node name | - | - | - | +| Node Deleted | node, lifecycle | Node name | - | - | - | +| Agent Claimed | agent | - | - | - | - | +| Agent Connected | agent | - | - | - | - | +| Agent Disconnected | agent | - | - | - | - | +| Agent Authenticated | agent | - | - | - | - | +| Agent Authentication Failed | agent | - | - | - | - | +| Space Statistics | space, node, statistics | Node name | - | - | - | +| Node Alert State Changed | alert, node | Node name | Cleared, Warning, Critical, Removed, Error or Unknown | Alert name | Chart name | diff --git a/docs/cloud/insights/metric-correlations.md b/docs/cloud/insights/metric-correlations.md new file mode 100644 index 00000000..c8ead9be --- /dev/null +++ b/docs/cloud/insights/metric-correlations.md @@ -0,0 +1,85 @@ +<!-- +title: "Metric Correlations" +description: "Quickly find metrics and charts closely related to a particular timeframe of interest anywhere in your infrastructure to discover the root cause faster." +custom_edit_url: "https://github.com/netdata/netdata/blob/master/docs/cloud/insights/metric-correlations.md" +sidebar_label: "Metric Correlations" +learn_status: "Published" +learn_topic_type: "Tasks" +learn_rel_path: "Operations" +--> + +# Metric Correlations + +The Metric Correlations (MC) feature lets you quickly find metrics and charts related to a particular window of interest that you want to explore further. By displaying the standard Netdata dashboard, filtered to show only charts that are relevant to the window of interest, you can get to the root cause sooner. + +Because Metric Correlations uses every available metric from your infrastructure, with as high as 1-second granularity, you get the most accurate insights using every possible metric. + +## Using Metric Correlations + +When viewing the overview or a single-node dashboard, the **Metric Correlations** button appears in the top right corner of the page. + +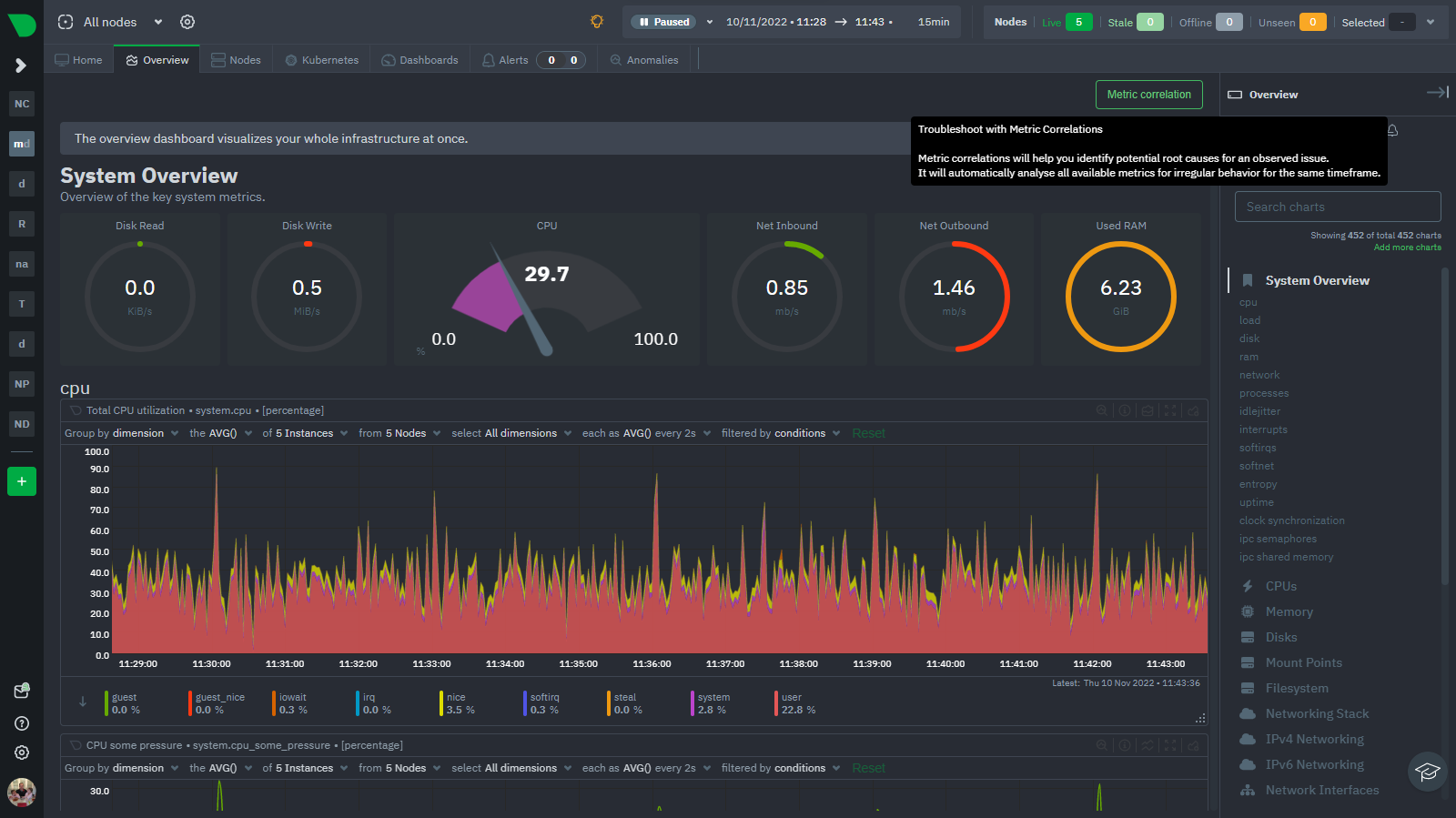 + +To start correlating metrics, click the **Metric Correlations** button, then hold the `Alt` key (or `⌘` on macOS) and click-and-drag a selection of metrics on a single chart. The selected timeframe needs to be at least 15 seconds for Metric Correlation to work. + +The menu then displays information about the selected area and reference baseline. Metric Correlations uses the reference baseline to discover which additional metrics are most closely connected to the selected metrics. The reference baseline is based upon the period immediately preceding the highlighted window and is the length of 4 times the highlighted window. This is to ensure that the reference baseline is always immediately before the highlighted window of interest and a bit longer so as to ensure it's a more representative short term baseline. + +Press the **Find Correlations** button to start up the correlations process, the button is only enabled when a valid timeframe is selected (at least 15 seconds). Once pressed, the process will score all available metrics on your nodes and return a filtered version of the Netdata dashboard. Now, you'll see only those metrics that have changed the most between a baseline window and the highlighted window you have selected. + +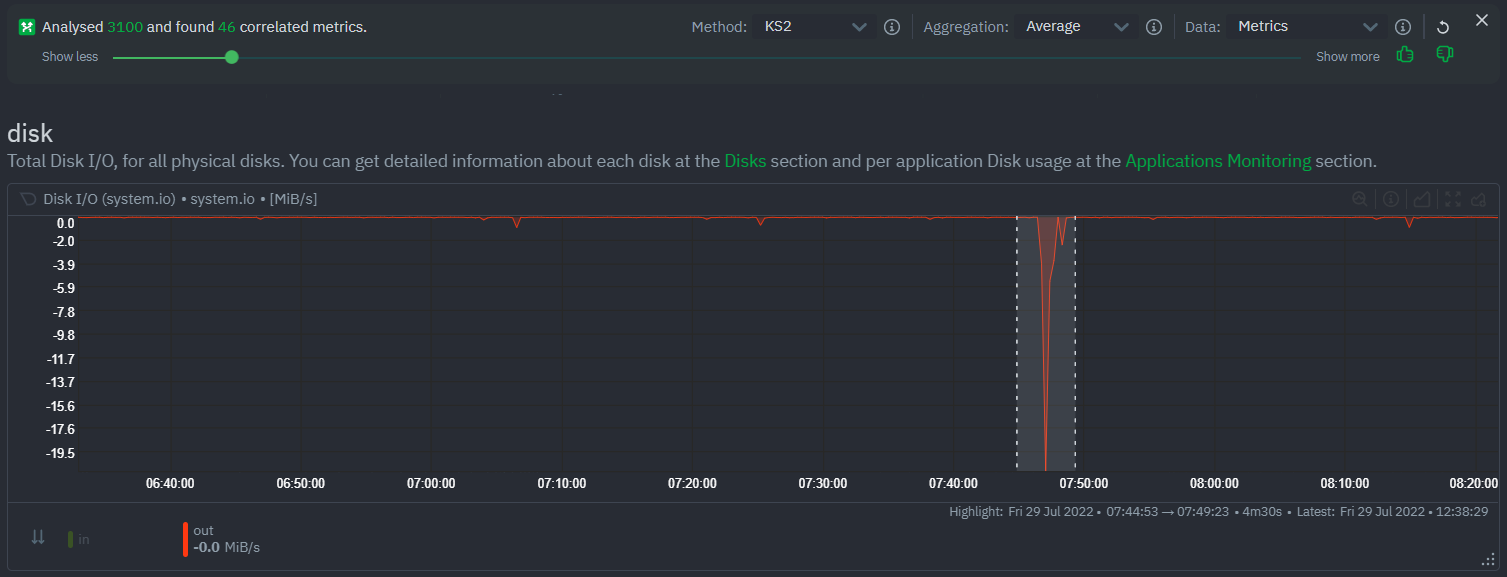 + +These charts are fully interactive, and whenever possible, will only show the _dimensions_ related to the timeline you selected. + +You can interact with all the scored metrics via the slider. Slide toward **show less** for more nuanced and significant results, or toward **show more** to "loosen" the threshold to explore other charts that may have changed too, but in a less significant manner. + +If you find something else interesting in the results, you can select another window and press **Find Correlations** again to kick the process off again. + +## Metric Correlations options + +MC enables a few input parameters that users can define to iteratively explore their data in different ways. As is usually the case in Machine Learning (ML), there is no "one size fits all" algorithm, what approach works best will typically depend on the type of data (which can be very different from one metric to the next) and even the nature of the event or incident you might be exploring in Netdata. + +So when you first run MC it will use the most sensible and general defaults. But you can also then vary any of the below options to explore further. + +### Method + +There are two algorithms available that aim to score metrics based on how much they have changed between the baseline and highlight windows. + +- `KS2` - A statistical test ([Two-sample Kolmogorov Smirnov](https://en.wikipedia.org/wiki/Kolmogorov%E2%80%93Smirnov_test#Two-sample_Kolmogorov%E2%80%93Smirnov_test)) comparing the distribution of the highlighted window to the baseline to try and quantify which metrics have most evidence of a significant change. You can explore our implementation [here](https://github.com/netdata/netdata/blob/d917f9831c0a1638ef4a56580f321eb6c9a88037/database/metric_correlations.c#L212). +- `Volume` - A heuristic measure based on the percentage change in averages between highlighted window and baseline, with various edge cases sensibly controlled for. You can explore our implementation [here](https://github.com/netdata/netdata/blob/d917f9831c0a1638ef4a56580f321eb6c9a88037/database/metric_correlations.c#L516). + +### Aggregation + +Behind the scenes, Netdata will aggregate the raw data as needed such that arbitrary window lengths can be selected for MC. By default, Netdata will just `Average` raw data when needed as part of pre-processing. However other aggregations like `Median`, `Min`, `Max`, `Stddev` are also possible. + +### Data + +Netdata is different from typical observability agents since, in addition to just collecting raw metric values, it will by default also assign an "[Anomaly Bit](https://github.com/netdata/netdata/tree/master/ml#anomaly-bit---100--anomalous-0--normal)" related to each collected metric each second. This bit will be 0 for "normal" and 1 for "anomalous". This means that each metric also natively has an "[Anomaly Rate](https://github.com/netdata/netdata/tree/master/ml#anomaly-rate---averageanomaly-bit)" associated with it and, as such, MC can be run against the raw metric values or their corresponding anomaly rates. + +**Note**: Read more [here](https://github.com/netdata/netdata/blob/master/ml/README.md) to learn more about the native anomaly detection features within netdata. + +- `Metrics` - Run MC on the raw metric values. +- `Anomaly Rate` - Run MC on the corresponding anomaly rate for each metric. + +## Metric Correlations on the agent + +As of `v1.35.0` Netdata is able to run the Metric Correlations algorithm ([Two Sample Kolmogorov-Smirnov test](https://en.wikipedia.org/wiki/Kolmogorov%E2%80%93Smirnov_test#Two-sample_Kolmogorov%E2%80%93Smirnov_test)) on the agent itself. This avoids sending the underlying raw data to the original Netdata Cloud based microservice and so typically will be much much faster as no data moves around and the computation happens instead on the agent. + +When a Metric Correlations request is made to Netdata Cloud, if any node instances have MC enabled then the request will be routed to the node instance with the highest hops (e.g. a parent node if one is found or the node itself if not). If no node instances have MC enabled then the request will be routed to the original Netdata Cloud based service which will request input data from the nodes and run the computation within the Netdata Cloud backend. + +#### Enabling/Disabling Metric Correlations on the agent + +As of `v1.35.0-22-nightly` Metric Correlation has been enabled by default on all agents. After further optimizations to the implementation, the impact of running the metric correlations algorithm on the agent was less than the impact of preparing all the data to send to cloud for MC to run in the cloud, as such running MC on the agent is less impactful on local resources than running via cloud. + +Should you still want to, disabling nodes for Metric Correlation on the agent is a simple one line config change. Just set `enable metric correlations = no` in the `[global]` section of `netdata.conf` + +## Usage tips! + +- When running Metric Correlations from the [Overview tab](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/overview.md#overview-and-single-node-view) across multiple nodes, you might find better results if you iterate on the initial results by grouping by node to then filter to nodes of interest and run the Metric Correlations again. So a typical workflow in this case would be to: + - If unsure which nodes you are interested in then run MC on all nodes. + - Within the initial results returned group the most interesting chart by node to see if the changes are across all nodes or a subset of nodes. + - If you see a subset of nodes clearly jump out when you group by node, then filter for just those nodes of interest and run the MC again. This will result in less aggregation needing to be done by Netdata and so should help give clearer results as you interact with the slider. +- Use the `Volume` algorithm for metrics with a lot of gaps (e.g. request latency when there are few requests), otherwise stick with `KS2` + - By default, Netdata uses the `KS2` algorithm which is a tried and tested method for change detection in a lot of domains. The [Wikipedia](https://en.wikipedia.org/wiki/Kolmogorov%E2%80%93Smirnov_test) article gives a good overview of how this works. Basically, it is comparing, for each metric, its cumulative distribution in the highlight window with its cumulative distribution in the baseline window. The statistical test then seeks to quantify the extent to which we can say these two distributions look similar enough to be considered the same or not. The `Volume` algorithm is a bit more simple than `KS2` in that it basically compares (with some edge cases sensibly handled) the average value of the metric across baseline and highlight and looks at the percentage change. Often both `KS2` and `Volume` will have significant agreement and return similar metrics. + - `Volume` might favour picking up more sparse metrics that were relatively flat and then came to life with some spikes (or vice versa). This is because for such metrics that just don't have that many different values in them, it is impossible to construct a cumulative distribution that can then be compared. So `Volume` might be useful in spotting examples of metrics turning on or off. 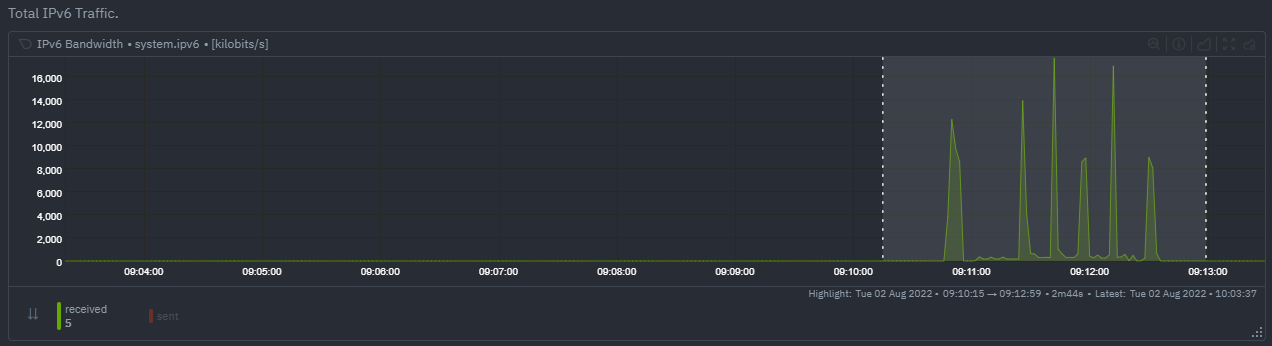 + - `KS2` since it relies on the full distribution might be better at highlighting more complex changes that `Volume` is unable to capture. For example a change in the variation of a metric might be picked up easily by `KS2` but missed (or just much lower scored) by `Volume` since the averages might remain not all that different between baseline and highlight even if their variance has changed a lot. 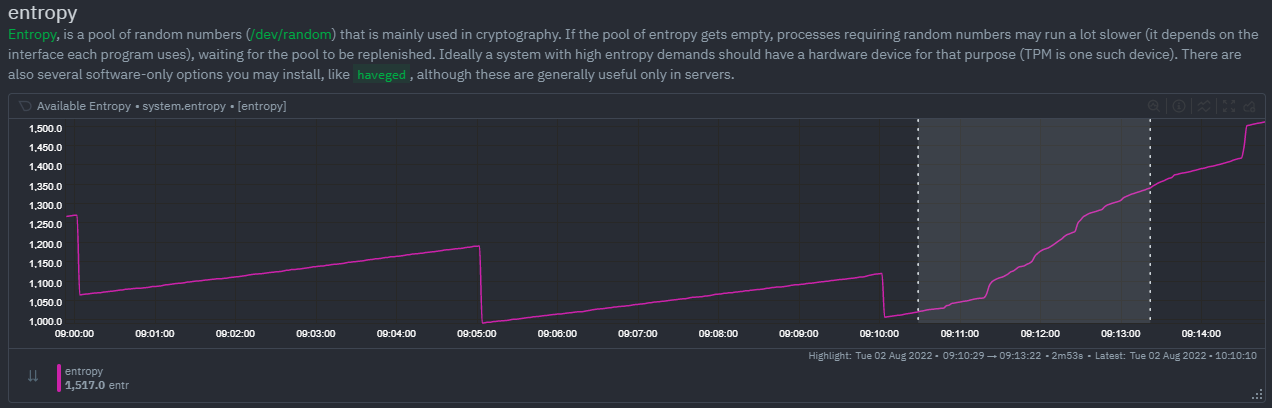 +- Use `Volume` and `Anomaly Rate` together to ask what metrics have turned most anomalous from baseline to highlighted window. You can expand the embedded anomaly rate chart once you have results to see this more clearly. 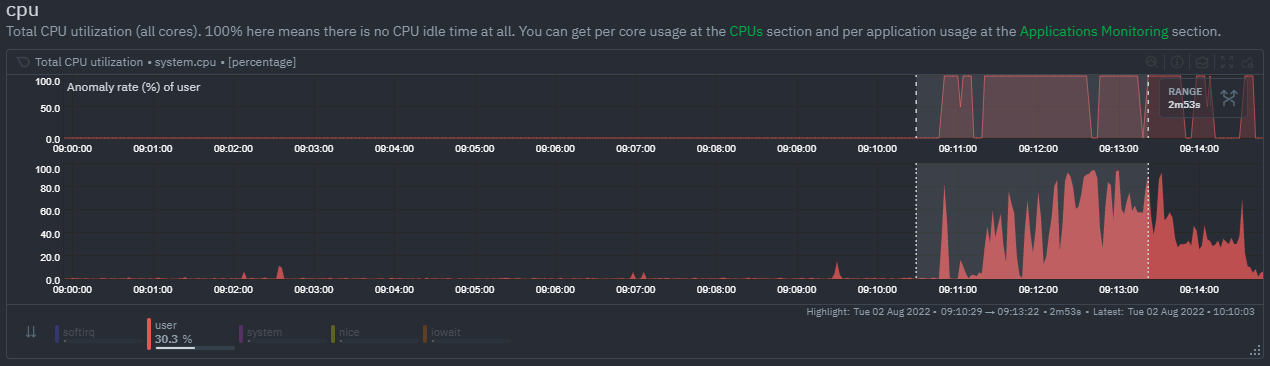 diff --git a/docs/cloud/manage/organize-your-infrastrucutre-invite-your-team.md b/docs/cloud/manage/organize-your-infrastrucutre-invite-your-team.md new file mode 100644 index 00000000..b36e0806 --- /dev/null +++ b/docs/cloud/manage/organize-your-infrastrucutre-invite-your-team.md @@ -0,0 +1,169 @@ +# Organize Your Infrastructure and Invite your Team + +Netdata Cloud provides you with features such as [Spaces](#netdata-cloud-spaces) and [War Rooms](#netdata-cloud-war-rooms) that allow you to better organize your infrastructure and ensure your team can also have access to it through invites. + +## Netdata Cloud Spaces + +Organize your multi-organization infrastructure monitoring on Netdata Cloud by creating Spaces to completely isolate access to your Agent-monitored nodes. + +A Space is a high-level container. It's a collaboration space where you can organize team members, access levels and the +nodes you want to monitor. + +Let's talk through some strategies for creating the most intuitive Cloud experience for your team. + +### How to organize your Netdata Cloud + +You can use any number of Spaces you want, but as you organize your Cloud experience, keep in mind that _you can only +add any given node to a single Space_. This 1:1 relationship between node and Space may dictate whether you use one +encompassing Space for your entire team and separate them by War Rooms, or use different Spaces for teams monitoring +discrete parts of your infrastructure. + +If you have been invited to Netdata Cloud by another user by default you will able to see that space. If you are a new +user the first space is already created. + +The other consideration for the number of Spaces you use to organize your Netdata Cloud experience is the size and +complexity of your organization. + +For smaller teams and infrastructures, we recommend sticking to a single Space so that you can keep all your nodes and their +respective metrics in one place. You can then use +multiple [War Rooms](#netdata-cloud-war-rooms) +to further organize your infrastructure monitoring. + +Enterprises may want to create multiple Spaces for each of their larger teams, particularly if those teams have +different responsibilities or parts of the overall infrastructure to monitor. For example, you might have one SRE team +for your user-facing SaaS application and a second team for infrastructure tooling. If they don't need to monitor the +same nodes, you can create separate Spaces for each team. + +### Navigate between spaces + +Click on any of the boxes to switch between available Spaces. + +Netdata Cloud abbreviates each Space to the first letter of the name, or the first two letters if the name is two words +or more. Hover over each icon to see the full name in a tooltip. + +To add a new Space click on the green **+** button. Enter the name of the Space and click **Save**. + + + +### Manage Spaces + +Manage your spaces by selecting a particular space and clicking on the small gear icon in the lower left corner. This +will open a side tab in which you can: + +1. _Configure this Space*_, in the first tab (**Space**) you can change the name, description or/and some privilege + options of this space + +2. _Edit the War Rooms*_, click on the **War rooms** tab to add or remove War Rooms. + +3. _Connect nodes*_, click on **Nodes** tab. Copy the claiming script to your node and run it. See the + [connect to Cloud doc](https://github.com/netdata/netdata/blob/master/claim/README.md) for details. + +4. _Manage the users*_, click on **Users**. + The [invitation doc](#invite-your-team) + details the invitation process. + +5. _Manage notification setting*_, click on **Notifications** tab to turn off/on notification methods. + +6. _Manage your bookmarks*_, click on the **Bookmarks** tab to add or remove bookmarks that you need. + +> #### Note +> +> \* This action requires admin rights for this space + +### Obsoleting offline nodes from a Space + +Netdata admin users now have the ability to remove obsolete nodes from a space. + +- Only admin users have the ability to obsolete nodes +- Only offline nodes can be marked obsolete (Live nodes and stale nodes cannot be obsoleted) +- Node obsoletion works across the entire space, so the obsoleted node will be removed from all rooms belonging to the + space +- If the obsoleted nodes eventually become live or online once more they will be automatically re-added to the space + +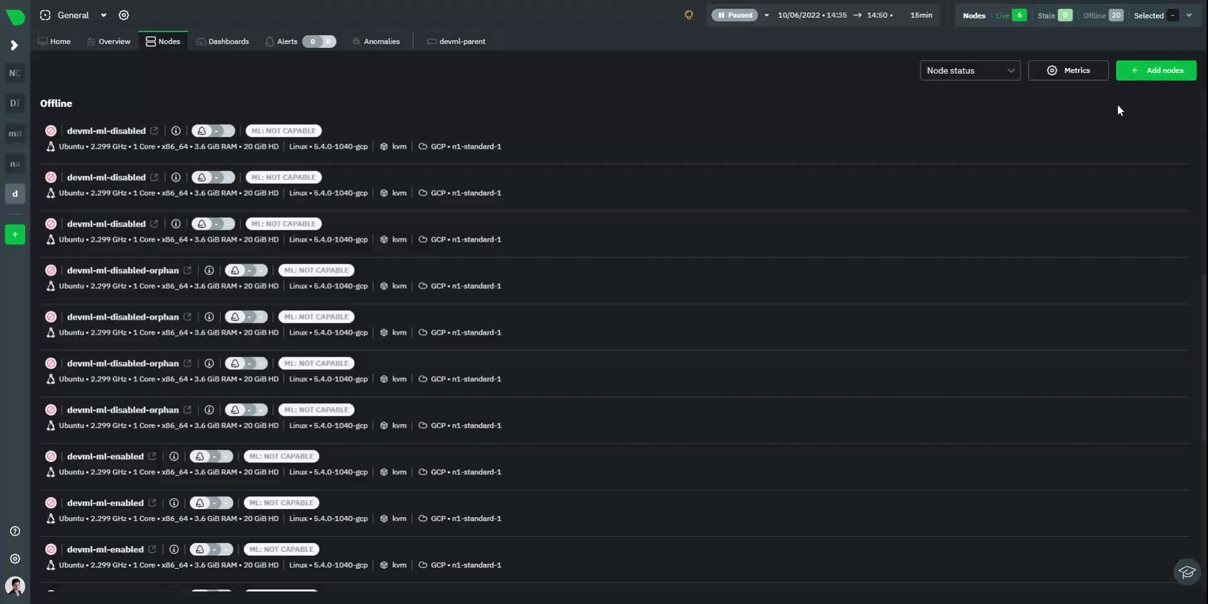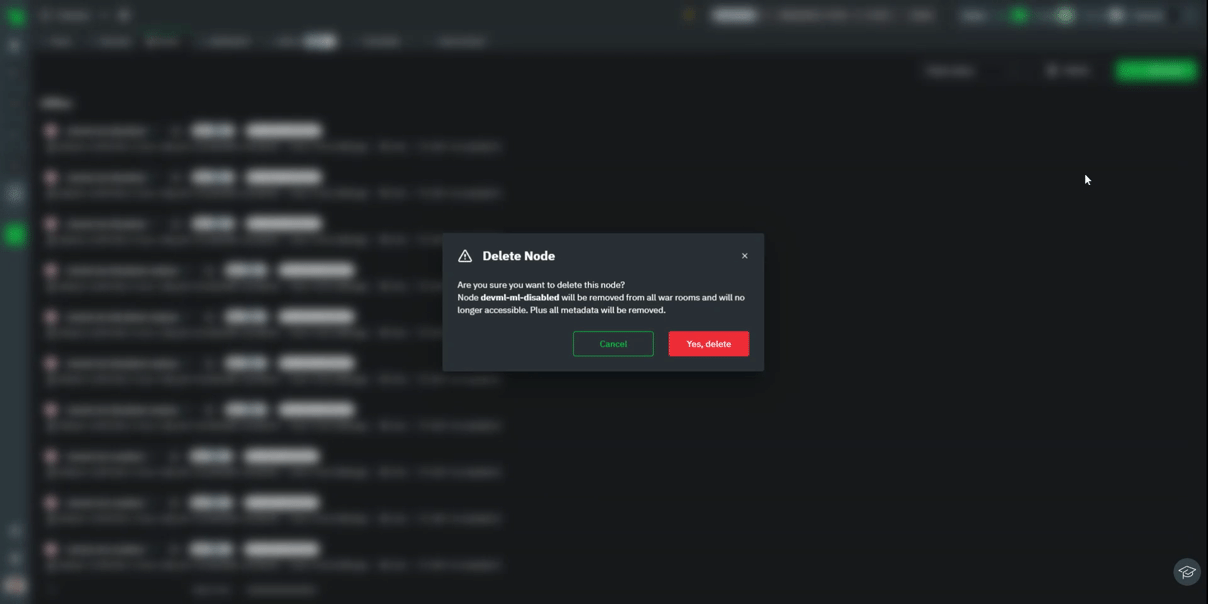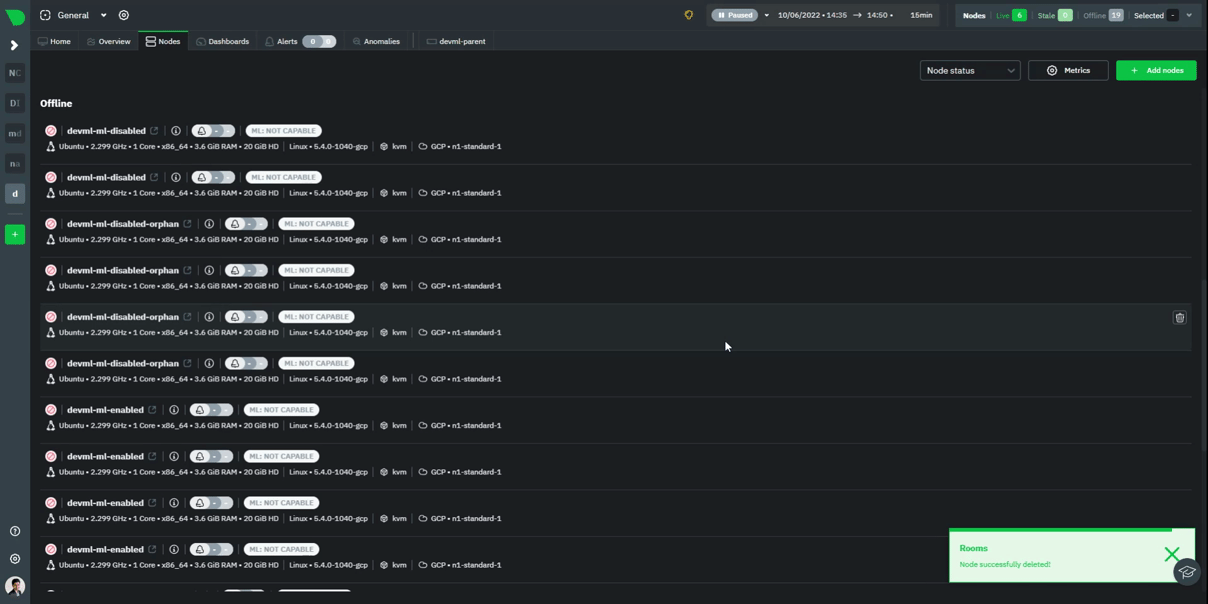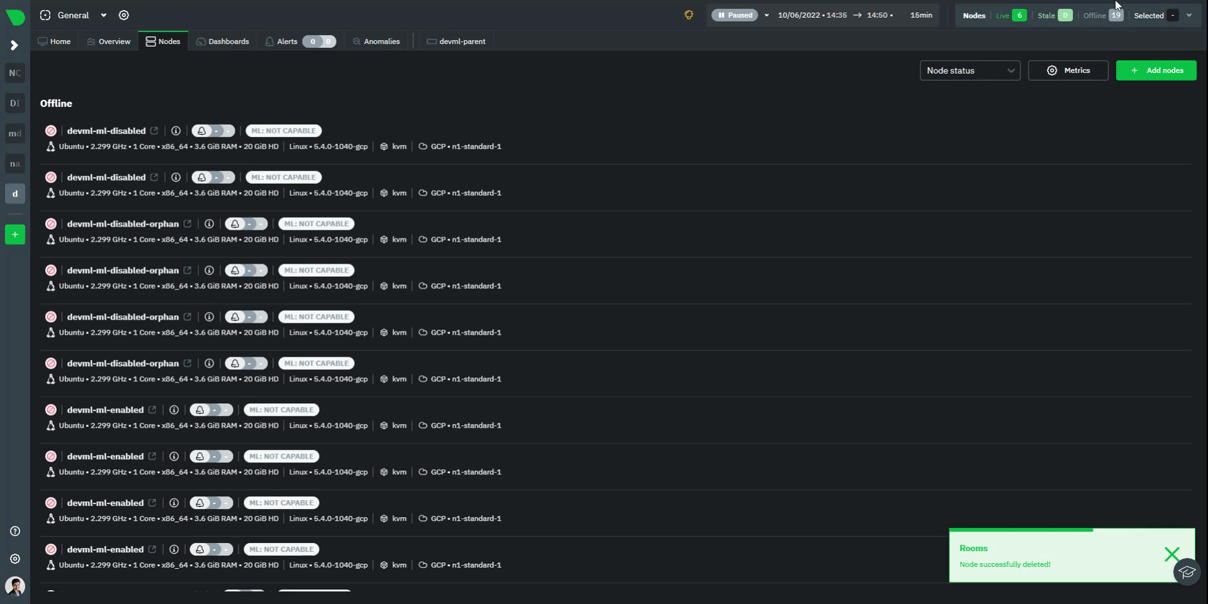 + +## Netdata Cloud War rooms + +Netdata Cloud uses War Rooms to organize your connected nodes and provide infrastructure-wide dashboards using real-time metrics and visualizations. + +Once you add nodes to a Space, all of your nodes will be visible in the **All nodes** War Room. This is a special War Room +which gives you an overview of all of your nodes in this particular Space. Then you can create functional separations of +your nodes into more War Rooms. Every War Room has its own dashboards, navigation, indicators, and management tools. + + + +### War Room organization + +We recommend a few strategies for organizing your War Rooms. + +- **Service, purpose, location, etc.** + You can group War Rooms by a service (Nginx, MySQL, Pulsar, and so on), their purpose (webserver, database, application), their physical location, whether they're "bare metal" or a Docker container, the PaaS/cloud provider it runs on, and much more. + This allows you to see entire slices of your infrastructure by moving from one War Room to another. + +- **End-to-end apps/services** + If you have a user-facing SaaS product, or an internal service that this said product relies on, you may want to monitor that entire stack in a single War Room. This might include Kubernetes clusters, Docker containers, proxies, databases, web servers, brokers, and more. + End-to-end War Rooms are valuable tools for ensuring the health and performance of your organization's essential services. + +- **Incident response** + You can also create new War Rooms as one of the first steps in your incident response process. + For example, you have a user-facing web app that relies on Apache Pulsar for a message queue, and one of your nodes using the [Pulsar collector](https://github.com/netdata/go.d.plugin/blob/master/modules/pulsar/README.md) begins reporting a suspiciously low messages rate. + You can create a War Room called `$year-$month-$day-pulsar-rate`, add all your Pulsar nodes in addition to nodes they connect to, and begin diagnosing the root cause in a War Room optimized for getting to resolution as fast as possible. + +### Add War Rooms + +To add new War Rooms to any Space, click on the green plus icon **+** next to the **War Rooms** heading on the left (Space's) sidebar. + +In the panel, give the War Room a name and description, and choose whether it's public or private. +Anyone in your Space can join public War Rooms, but can only join private War Rooms with an invitation. + +### Manage War Rooms + +All the users and nodes involved in a particular Space can be part of a War Room. + +Any user can change simple settings of a War room, like the name or the users participating in it. +Click on the gear icon of the War Room's name in the top of the page to do that. A sidebar will open with options for this War Room: + +1. To **change a War Room's name, description, or public/private status**, click on **War Room** tab. + +2. To **include an existing node** to a War Room or **connect a new node\*** click on **Nodes** tab. Choose any connected node you want to add to this War Room by clicking on the checkbox next to its hostname, then click **+ Add** at the top of the panel. + +3. To **add existing users to a War Room**, click on **Add Users**. + See our [invite section](#invite-your-team) for details on inviting new users to your Space in Netdata Cloud. + +> #### Note +> +>\* This action requires **admin** rights for this Space + +#### More actions + +To **view or remove nodes** in a War Room, click on the **Nodes tab**. To remove a node from the current War Room, click on +the **🗑** icon. + +> #### Info +> +> Removing a node from a War Room does not remove it from your Space. + +## Invite your team + +Invite your entire SRE, DevOPs, or ITOps team to Netdata Cloud, to give everyone insights into your infrastructure from a single pane of glass. + +Invite new users to your Space by clicking on **Invite Users** in +the [Space](#netdata-cloud-spaces) management area. + + + + +You will be prompted to enter the email addresses of the users you want to invite to your Space. You can enter any number of email addresses, separated by a comma, to send multiple invitations at once. + +Next, choose the War Rooms you want to invite these users to. Once logged in, these users are not restricted only to +these War Rooms. They can be invited to others, or join any that are public. + +Next, pick a role for the invited user. You can read more about [which roles are available](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/role-based-access.md#what-roles-are-available) based on your [subscription plan](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/plans.md). + +Click the **Send** button to send an email invitation, which will prompt them +to [sign up](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/sign-in.md) and join your Space. + +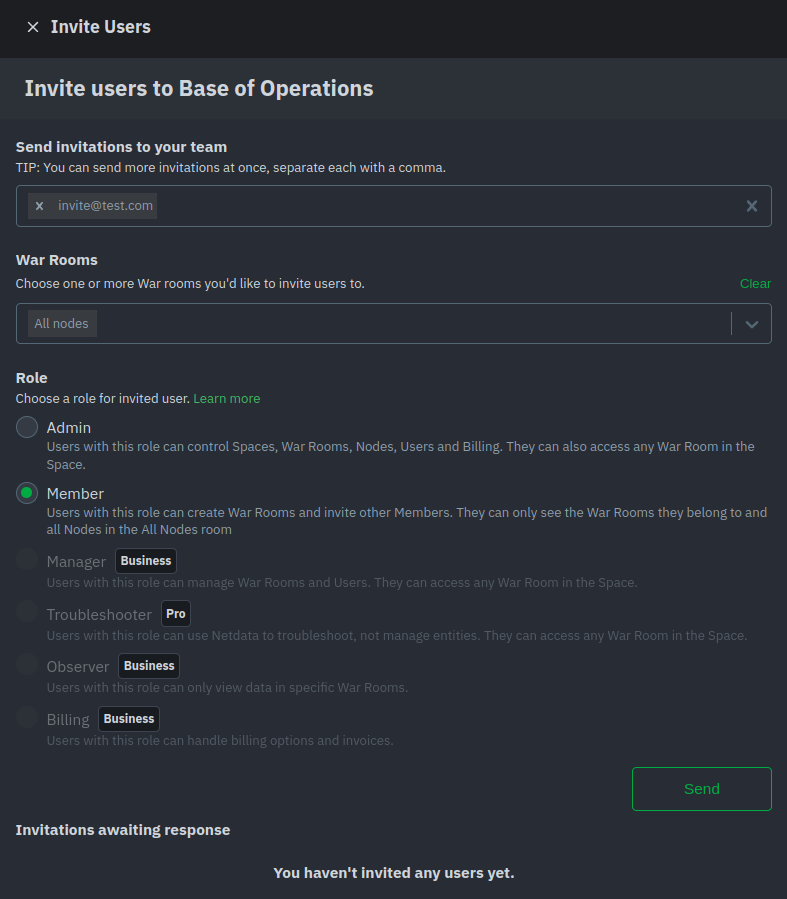 + +Any unaccepted invitations remain under **Invitations awaiting response**. These invitations can be rescinded at any +time by clicking the trash can icon. diff --git a/docs/cloud/manage/plans.md b/docs/cloud/manage/plans.md new file mode 100644 index 00000000..f84adaa8 --- /dev/null +++ b/docs/cloud/manage/plans.md @@ -0,0 +1,123 @@ +# Netdata Plans + +This page will guide you through the differences between the Community, Pro, Business and Enterprise plans. + +At Netdata, we believe in providing free and unrestricted access to high-quality monitoring solutions, and our commitment to this principle will not change. We offer our free SaaS offering - what we call **Community plan** - and Open Source Agent, which features unlimited nodes and users, unlimited metrics, and retention, providing real-time, high-fidelity, out-of-the-box infrastructure monitoring for packaged applications, containers, and operating systems. + +We also provide paid subscriptions that designed to provide additional features and capabilities for businesses that need tighter and customizable integration of the free monitoring solution to their processes. These are divided into three different plans: **Pro**, **Business**, and **Enterprise**. Each plan will offers a different set of features and capabilities to meet the needs of businesses of different sizes and with different monitoring requirements. + +> ### Note +> To not disrupt the existing space user's access rights we will keep them in the **Early Bird** plan. The reason for this is to allow users to +> keep using the legacy **Member** role with the exact same permissions as it has currently. +> +> If you move from the **Early Bird** plan to a paid plan, you will not be able to return to the **Early Bird** plan again. The **Community** free plan will always be available to you, but it does not allow +> you to invite or change users using the Member role. See more details on our [roles and plans](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/role-based-access.md#what-roles-are-available) documentation. + +### Plans + +The plan is an attribute that is directly attached to your space(s) and that dictates what capabilities and customizations you have on your space. If you have different spaces you can have different Netdata plans on them. This gives you flexibility to chose what is more adequate for your needs on each of your spaces. + +Netdata Cloud plans, with the exception of Community, work as subscriptions and overall consist of two pricing components: + +* A flat fee component, that is applied on yearly subscriptions for the [comitted-nodes](#committed-nodes) charte (space subscription fee has been waived off) +* An on-demand metered component, that is related to your usage of Netdata which directly links to the [number of nodes you have running](#running-nodes-and-billing) + +Netdata provides two billing frequency options: + +* Monthly - Pay as you go, where we charge both the flat fee and the on-demand component every month +* Yearly - Annual prepayment, where we charge upfront the flat fee and committed amount related to your estimated usage of Netdata (more details [here](#committed-nodes)) + +For more details on the plans and subscription conditions please check <https://netdata.cloud/pricing>. + +#### Running nodes and billing + +The only dynamic variable we consider for billing is the number of concurrently running nodes or agents. We only charge you for your active running nodes, so we don't count: + +* offline nodes +* stale nodes, nodes that are available to query through a Netdata parent agent but are not actively connecting metrics at the moment + +To ensure we don't overcharge you due to sporadic spikes throughout a month or even at a certain point in a day we are: + +* Calculate a daily P90 figure for your running nodes. To achieve that, we take a daily snapshot of your running nodes, and using the node state change events (live, offline) we guarantee that a daily P90 figure is calculated to remove any daily spikes +* On top of the above, we do a running P90 calculation from the start to the end of your billing cycle. Even if you have an yearly billing frequency we keep a monthly subscription linked to that to identify any potential overage over your [committed nodes](#committed-nodes). + +#### Committed nodes + +When you subscribe to an Yearly plan you will need to specify the number of nodes that you will commit to. On these nodes, a discounted price of less 25% than the original cost per node of the plan is applied. This amount will be part of your annual prepayment. + +``` +Node plan discounted price x committed nodes x 12 months +``` + +If, for a given month, your usage is over these committed nodes we will charge the original cost per node for the nodes above the committed number. + +#### Plan changes and credit balance + +It is ok to change your mind. We allow to change your plan, billing frequency or adjust the committed nodes, on yearly plans, at any time. + +To achieve this you can check the [Update plan](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/view-plan-billing.md#update-plan) section. + +> ⚠️ On a downgrade (going to a new plan with less benefits) or cancellation of an active subscription, please note that you will have all your notification methods configurations active **for a period of 24 hours**. +> After that, any notification methods unavailable in your new plan at that time will be automatically disabled. You can always re-enable them once you move to a paid plan that includes them. + +> ⚠️ Downgrade or cancellation may affect users in your Space. Please check what roles are available on the [each plans](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/plans.md#areas-impacted-by-plans). Users with unavailable roles on the new plan will immediately have restricted access to the Space. + +> ⚠️ Any credit given to you will be available to use on future paid subscriptions with us. It will be available until the the **end of the following year**. + +### Areas impacted by plans + +##### Role-Based Access model + +Depending on the plan associated to your space you will have different roles available: + +| **Role** | **Community** | **Pro** | **Business** | **Early Bird** | +| :-- | :--: | :--: | :--: | :--: | +| **Administrators**<p>Users with this role can control Spaces, War Rooms, Nodes, Users and Billing.</p><p>They can also access any War Room in the Space.</p> | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | +| **Managers**<p>Users with this role can manage War Rooms and Users.</p><p>They can access any War Room in the Space.</p> | - | - | :heavy_check_mark: | - | +| **Troubleshooters**<p>Users with this role can use Netdata to troubleshoot, not manage entities.</p><p>They can access any War Room in the Space.</p> | - | :heavy_check_mark: | :heavy_check_mark: | - | +| **Observers**<p>Users with this role can only view data in specific War Rooms.</p>💡 Ideal for restricting your customer's access to their own dedicated rooms.<p></p> | - | - | :heavy_check_mark: | - | +| **Billing**<p>Users with this role can handle billing options and invoices.</p> | - | - | :heavy_check_mark: | - | +| **Member** ⚠️ Legacy role<p>Users with this role can create War Rooms and invite other Members.</p><p>They can only see the War Rooms they belong to and all Nodes in the All Nodes room.</p>| - | - | - | :heavy_check_mark: | + +For more details check the documentation under [Role-Based Access model](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/role-based-access.md). + +##### Events feed + +The plan you have subscribed on your space will determine the amount of historical data you will be able to query: + +| **Type of events** | **Community** | **Pro** | **Business** | +| :-- | :-- | :-- | :-- | +| **Auditing events** - COMING SOON<p>Events related to actions done on your Space, e.g. invite user, change user role or create room.</p>| 4 hours | 7 days | 90 days | +| **Topology events**<p>Node state transition events, e.g. live or offline.</p>| 4 hours | 7 days | 14 days | +| **Alert events**<p>Alert state transition events, can be seen as an alert history log.</p>| 4 hours | 7 days | 90 days | + +For more details check the documentation under [Events feed](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/events-feed.md). + +##### Notification integrations + +The plan on your space will determine what type of notifications methods will be available to you: + +* **Community** - Email and Discord +* **Pro** - Email, Discord and webhook +* **Business** - Unlimited, this includes Slack, PagerDuty, Opsgenie etc. + +For more details check the documentation under [Alert Notifications](https://github.com/netdata/netdata/blob/master/docs/cloud/alerts-notifications/notifications.md#alert-notifications). + +##### Alert notification silencing rules + +The plan on your space will determine if you are able to add alert notification silencing rules since this feature will only be available for paid plans: **Pro** or **Business**. + +For more details check the documentation under [Alert Notifications](https://github.com/netdata/netdata/blob/master/docs/cloud/alerts-notifications/notifications.md#silencing-alert-notifications). + +### Related Topics + +#### **Related Concepts** + +* [Spaces](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/organize-your-infrastrucutre-invite-your-team.md#netdata-cloud-spaces) +* [Alert Notifications](https://github.com/netdata/netdata/blob/master/docs/cloud/alerts-notifications/notifications.md) +* [Events feed](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/events-feed.md) +* [Role-Based Access model](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/role-based-access.md) + +#### Related Tasks + +* [View Plan & Billing](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/view-plan-billing.md) diff --git a/docs/cloud/manage/role-based-access.md b/docs/cloud/manage/role-based-access.md new file mode 100644 index 00000000..a0b38774 --- /dev/null +++ b/docs/cloud/manage/role-based-access.md @@ -0,0 +1,143 @@ +# Role-Based Access model + +Netdata Cloud's role-based-access mechanism allows you to control what functionalities in the app users can access. Each user can be assigned only one role, which fully specifies all the capabilities they are afforded. + +## What roles are available? + +With the advent of the paid plans we revamped the roles to cover needs expressed by Netdata users, like providing more limited access to their customers, or +being able to join any room. We also aligned the offered roles to the target audience of each plan. The end result is the following: + +| **Role** | **Community** | **Pro** | **Business** | **Early Bird** | +| :-- | :--: | :--: | :--: | :--: | +| **Administrators**<p>Users with this role can control Spaces, War Rooms, Nodes, Users and Billing.</p><p>They can also access any War Room in the Space.</p> | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | +| **Managers**<p>Users with this role can manage War Rooms and Users.</p><p>They can access any War Room in the Space.</p> | - | - | :heavy_check_mark: | - | +| **Troubleshooters**<p>Users with this role can use Netdata to troubleshoot, not manage entities.</p><p>They can access any War Room in the Space.</p> | - | :heavy_check_mark: | :heavy_check_mark: | - | +| **Observers**<p>Users with this role can only view data in specific War Rooms.</p>💡 Ideal for restricting your customer's access to their own dedicated rooms.<p></p> | - | - | :heavy_check_mark: | - | +| **Billing**<p>Users with this role can handle billing options and invoices.</p> | - | - | :heavy_check_mark: | - | +| **Member** ⚠️ Legacy role<p>Users with this role can create War Rooms and invite other Members.</p><p>They can only see the War Rooms they belong to and all Nodes in the All Nodes room.</p>| - | - | - | :heavy_check_mark: | + +## What happens to the previous Member role? + +We will maintain a Early Bird plan for existing users, which will continue to provide access to the Member role. + +## Which functionalities are available for each role? + +In more detail, you can find on the following tables which functionalities are available for each role on each domain. + +### Space Management + +| **Functionality** | **Administrator** | **Manager** | **Troubleshooter** | **Observer** | **Billing** | **Member** | +| :-- | :--: | :--: | :--: | :--: | :--: | :--: | +| See Space | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | +| Leave Space | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | +| Delete Space | :heavy_check_mark: | - | - | - | - | - | +| Change name | :heavy_check_mark: | - | - | - | - | - | +| Change description | :heavy_check_mark: | - | - | - | - | - | + +### Node Management + +| **Functionality** | **Administrator** | **Manager** | **Troubleshooter** | **Observer** | **Billing** | **Member** | Notes | +| :-- | :--: | :--: | :--: | :--: | :--: | :--: | :-- | +| See all Nodes in Space (_All Nodes_ room) | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | - | - | :heavy_check_mark: | Members are always on the _All Nodes_ room | +| Connect Node to Space | :heavy_check_mark: | - | - | - | - | - | - | +| Delete Node from Space | :heavy_check_mark: | - | - | - | - | - | - | + +### User Management + +| **Functionality** | **Administrator** | **Manager** | **Troubleshooter** | **Observer** | **Billing** | **Member** | Notes | +| :-- | :--: | :--: | :--: | :--: | :--: | :--: | :-- | +| See all Users in Space | :heavy_check_mark: | :heavy_check_mark: | - | - | - | :heavy_check_mark: | | +| Invite new User to Space | :heavy_check_mark: | :heavy_check_mark: | - | - | - | :heavy_check_mark: | You can't invite a user with a role you don't have permissions to appoint to (see below) | +| Delete Pending Invitation to Space | :heavy_check_mark: | :heavy_check_mark: | - | - | - | :heavy_check_mark: | | +| Delete User from Space | :heavy_check_mark: | :heavy_check_mark: | - | - | - | - | You can't delete a user if he has a role you don't have permissions to appoint to (see below) | +| Appoint Administrators | :heavy_check_mark: | - | - | - | - | - | | +| Appoint Billing user | :heavy_check_mark: | - | - | - | - | - | | +| Appoint Managers | :heavy_check_mark: | :heavy_check_mark: | - | - | - | - | | +| Appoint Troubleshooters | :heavy_check_mark: | :heavy_check_mark: | - | - | - | - | | +| Appoint Observer | :heavy_check_mark: | :heavy_check_mark: | - | - | - | - | | +| Appoint Member | :heavy_check_mark: | - | - | - | - | :heavy_check_mark: | Only available on Early Bird plans | +| See all Users in a Room | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | - | :heavy_check_mark: | | +| Invite existing user to Room | :heavy_check_mark: | :heavy_check_mark: | - | - | - | :heavy_check_mark: | User already invited to the Space | +| Remove user from Room | :heavy_check_mark: | :heavy_check_mark: | - | - | - | - | | + +### Room Management + +| **Functionality** | **Administrator** | **Manager** | **Troubleshooter** | **Observer** | **Billing** | **Member** | Notes | +| :-- | :--: | :--: | :--: | :--: | :--: | :--: | :-- | +| See all Rooms in a Space | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | - | - | - | | +| Join any Room in a Space | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | - | - | - | By joining a room you will be enabled to get notifications from nodes on that room | +| Leave Room | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | - | :heavy_check_mark: | | +| Create a new Room in a Space | :heavy_check_mark: | :heavy_check_mark: | - | - | - | :heavy_check_mark: | | +| Delete Room | :heavy_check_mark: | :heavy_check_mark: | - | - | - | - | | +| Change Room name | :heavy_check_mark: | :heavy_check_mark: | - | - | - | :heavy_check_mark: | If not the _All Nodes_ room | +| Change Room description | :heavy_check_mark: | :heavy_check_mark: | - | - | - | :heavy_check_mark: | | +| Add existing Nodes to Room | :heavy_check_mark: | :heavy_check_mark: | - | - | - | :heavy_check_mark: | Node already connected to the Space | +| Remove Nodes from Room | :heavy_check_mark: | :heavy_check_mark: | - | - | - | :heavy_check_mark: | | + +### Notifications Management + +| **Functionality** | **Administrator** | **Manager** | **Troubleshooter** | **Observer** | **Billing** | **Member** | Notes | +| :-- | :--: | :--: | :--: | :--: | :--: | :--: | :-- | +| See all configured notifications on a Space | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | - | :heavy_check_mark: | | +| Add new configuration | :heavy_check_mark: | - | - | - | - | - | | +| Enable/Disable configuration | :heavy_check_mark: | - | - | - | - | - | | +| Edit configuration | :heavy_check_mark: | - | - | - | - | - | Some exceptions apply depending on [service level](https://github.com/netdata/netdata/blob/master/docs/cloud/alerts-notifications/manage-notification-methods.md#available-actions-per-notification-methods-based-on-service-level) | +| Delete configuration | :heavy_check_mark: | - | - | - | - | - | | +| Edit personal level notification settings | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | [Manage user notification settings](https://github.com/netdata/netdata/blob/master/docs/cloud/alerts-notifications/manage-notification-methods.md#manage-user-notification-settings) | +| See space alert notification silencing rules | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | - | - | - | | +| Add new space alert notification silencing rule | :heavy_check_mark: | :heavy_check_mark: | - | - | - | - | | +| Enable/Disable space alert notification silencing rule | :heavy_check_mark: | :heavy_check_mark: | - | - | - | - | | +| Edit space alert notification silencing rule | :heavy_check_mark: | :heavy_check_mark: | - | - | - | - | | +| Delete space alert notification silencing rule | :heavy_check_mark: | :heavy_check_mark: | - | - | - | - | | +| See, add, edit or delete personal level alert notification silencing rule | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | - | - | | + + +Notes: +* Enable, Edit and Add actions over specific notification methods will only be allowed if your plan has access to those ([service classification](https://github.com/netdata/netdata/blob/master/docs/cloud/alerts-notifications/notifications.md#service-classification)) + +### Dashboards + +| **Functionality** | **Administrator** | **Manager** | **Troubleshooter** | **Observer** | **Billing** | **Member** | +| :-- | :--: | :--: | :--: | :--: | :--: | :--: | +| See all dashboards in Room | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | - | :heavy_check_mark: | +| Add new dashboard to Room | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | - | :heavy_check_mark: | +| Edit any dashboard in Room | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | - | - | :heavy_check_mark: | +| Edit own dashboard in Room | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | - | :heavy_check_mark: | +| Delete any dashboard in Room | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | - | - | :heavy_check_mark: | +| Delete own dashboard in Room | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | - | :heavy_check_mark: | + +### Functions + +| **Functionality** | **Administrator** | **Manager** | **Troubleshooter** | **Observer** | **Billing** | **Member** | Notes | +| :-- | :--: | :--: | :--: | :--: | :--: | :--: | :-- | +| See all functions in Room | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | - | :heavy_check_mark: | +| Run any function in Room | :heavy_check_mark: | :heavy_check_mark: | - | - | - | - | +| Run read-only function in Room | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | - | :heavy_check_mark: | | +| Run sensitive function in Room | :heavy_check_mark: | :heavy_check_mark: | - | - | - | - | There isn't any function on this category yet, so subject to change. | + +### Events feed + +| **Functionality** | **Administrator** | **Manager** | **Troubleshooter** | **Observer** | **Billing** | **Member** | Notes | +| :-- | :--: | :--: | :--: | :--: | :--: | :--: | :-- | +| See Alert or Topology events | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | - | :heavy_check_mark: | | +| See Auditing events | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | - | - | These are coming soon, not currently available | + +### Billing + +| **Functionality** | **Administrator** | **Manager** | **Troubleshooter** | **Observer** | **Billing** | **Member** | Notes | +| :-- | :--: | :--: | :--: | :--: | :--: | :--: | :-- | +| See Plan & Billing details | :heavy_check_mark: | - | - | - | :heavy_check_mark: | - | Current plan and usage figures | +| Update plans | :heavy_check_mark: | - | - | - | - | - | This includes cancelling current plan (going to Community plan) | +| See invoices | :heavy_check_mark: | - | - | - | :heavy_check_mark: | - | | +| Manage payment methods | :heavy_check_mark: | - | - | - | :heavy_check_mark: | - | | +| Update billing email | :heavy_check_mark: | - | - | - | :heavy_check_mark: | - | | + +### Other permissions + +| **Functionality** | **Administrator** | **Manager** | **Troubleshooter** | **Observer** | **Billing** | **Member** | +| :-- | :--: | :--: | :--: | :--: | :--: | :--: | +| See Bookmarks in Space | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | - | :heavy_check_mark: | +| Add Bookmark to Space | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | - | - | :heavy_check_mark: | +| Delete Bookmark from Space | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | - | - | :heavy_check_mark: | +| See Visited Nodes | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | - | :heavy_check_mark: | +| Update Visited Nodes | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: | - | :heavy_check_mark: | diff --git a/docs/cloud/manage/sign-in.md b/docs/cloud/manage/sign-in.md new file mode 100644 index 00000000..53ea3a22 --- /dev/null +++ b/docs/cloud/manage/sign-in.md @@ -0,0 +1,81 @@ +# Sign in to Netdata + +This page explains how to sign in to Netdata with your email, Google account, or GitHub account, and provides some tips if you're having trouble signing in. + +You can [sign in to Netdata](https://app.netdata.cloud/sign-in?cloudRoute=spaces?utm_source=docs&utm_content=sign_in_button_first_section) through one of three methods: email, Google, or GitHub. Email uses a +time-sensitive link that authenticates your browser, and Google/GitHub both use OAuth to associate your email address +with a Netdata Cloud account. + +No matter the method, your Netdata Cloud account is based around your email address. Netdata Cloud does not store +passwords. + +## Email + +To sign in with email, visit [Netdata Cloud](https://app.netdata.cloud/sign-in?cloudRoute=spaces?utm_source=docs&utm_content=sign_in_button_email_section), enter your email address, and click +the **Sign in by email** button. + + + +Click the **Verify** button in the email to begin using Netdata Cloud. + +To use this same Netdata Cloud account on additional devices, request another sign in email, open the email on that +device, and sign in. + +### Don't have a Netdata Cloud account yet? + +If you don't already have a Netdata Cloud account, you don't need to worry about this. During the sign-in process we will create one for you and make the process seamless to you. + +After your account is created and you sign in to Netdata, you first are asked to agree to Netdata Cloud's [Privacy +Policy](https://www.netdata.cloud/privacy/) and [Terms of Use](https://www.netdata.cloud/terms/). Once you agree with these you are directed +through the Netdata Cloud onboarding process, which is explained in the [Netdata Cloud +quickstart](https://github.com/netdata/netdata/blob/master/packaging/installer/README.md). + +### Troubleshooting + +You should receive your sign in email in less than a minute. The subject is **Verify your email!** for new sign-ups, **Sign in to Netdata** for sign ins. +The sender is `no-reply@netdata.cloud` via `sendgrid.net`. + +If you don't see the email, try the following: + +- Check your spam folder. +- In Gmail, check the **Updates** category. +- Check [Netdata Cloud status](https://status.netdata.cloud) for ongoing issues with our infrastructure. +- Request another sign in email via the [sign-in page](https://app.netdata.cloud/sign-in?cloudRoute=spaces?utm_source=docs&utm_content=sign_in_button_troubleshooting_section). + +You may also want to add `no-reply@netdata.cloud` to your address book or contacts list, especially if you're using +a public email service, such as Gmail. You may also want to whitelist/allowlist either the specific email or the entire +`netdata.cloud` domain. + +In some cases, temporary issues with your mail server or email account may result in your email address being added to a Bounce list by Sendgrid. +If you are added to that list, no Netdata cloud email can reach you, including alert notifications. Let us know in Discord that you have trouble receiving +any email from us and someone will ask you to provide your email address privately, so we can check if you are on the Bounce list. + +## Google and GitHub OAuth + +When you use Google/GitHub OAuth, your Netdata Cloud account is associated with the email address that Netdata Cloud +receives via OAuth. + +To sign in with Google or GitHub OAuth, visit [Netdata Cloud](https://app.netdata.cloud/sign-in?cloudRoute=spaces?utm_source=docs&utm_content=sign_in_button_google_github_section) and click the +**Continue with Google/GitHub** or button. Enter your Google/GitHub username and your password. Complete two-factor +authentication if you or your organization has it enabled. + +You are then signed in to Netdata Cloud or directed to the new-user onboarding if you have not signed up previously. + +## Reset a password + +Netdata Cloud does not store passwords and does not support password resets. All of our sign in methods do not +require passwords, and use either links in emails or Google/GitHub OAuth for authentication. + +## Switch between sign in methods + +You can switch between sign in methods if the email account associated with each method is the same. + +For example, you first sign in via your email account, `user@example.com`, and later sign out. You later attempt to sign +in via a GitHub account associated with `user@example.com`. Netdata Cloud recognizes that the two are the same and signs +you in to your original account. + +However, if you first sign in via your `user@example.com` email account and then sign in via a Google account associated +with `user2@example.com`, Netdata Cloud creates a new account and begins the onboarding process. + +It is not currently possible to link an account created with `user@example.com` to a Google account associated with +`user2@example.com`. diff --git a/docs/cloud/manage/themes.md b/docs/cloud/manage/themes.md new file mode 100644 index 00000000..aaf193a8 --- /dev/null +++ b/docs/cloud/manage/themes.md @@ -0,0 +1,14 @@ +# Choose your Netdata Cloud theme + +The Dark theme is the default for all new Netdata Cloud accounts. + +To change your theme across Netdata Cloud, click on your profile picture, then **Profile**. Click on the **Settings** +tab, then choose your preferred theme: Light or Dark. + +**Light**: + + + +**Dark (default)**: + +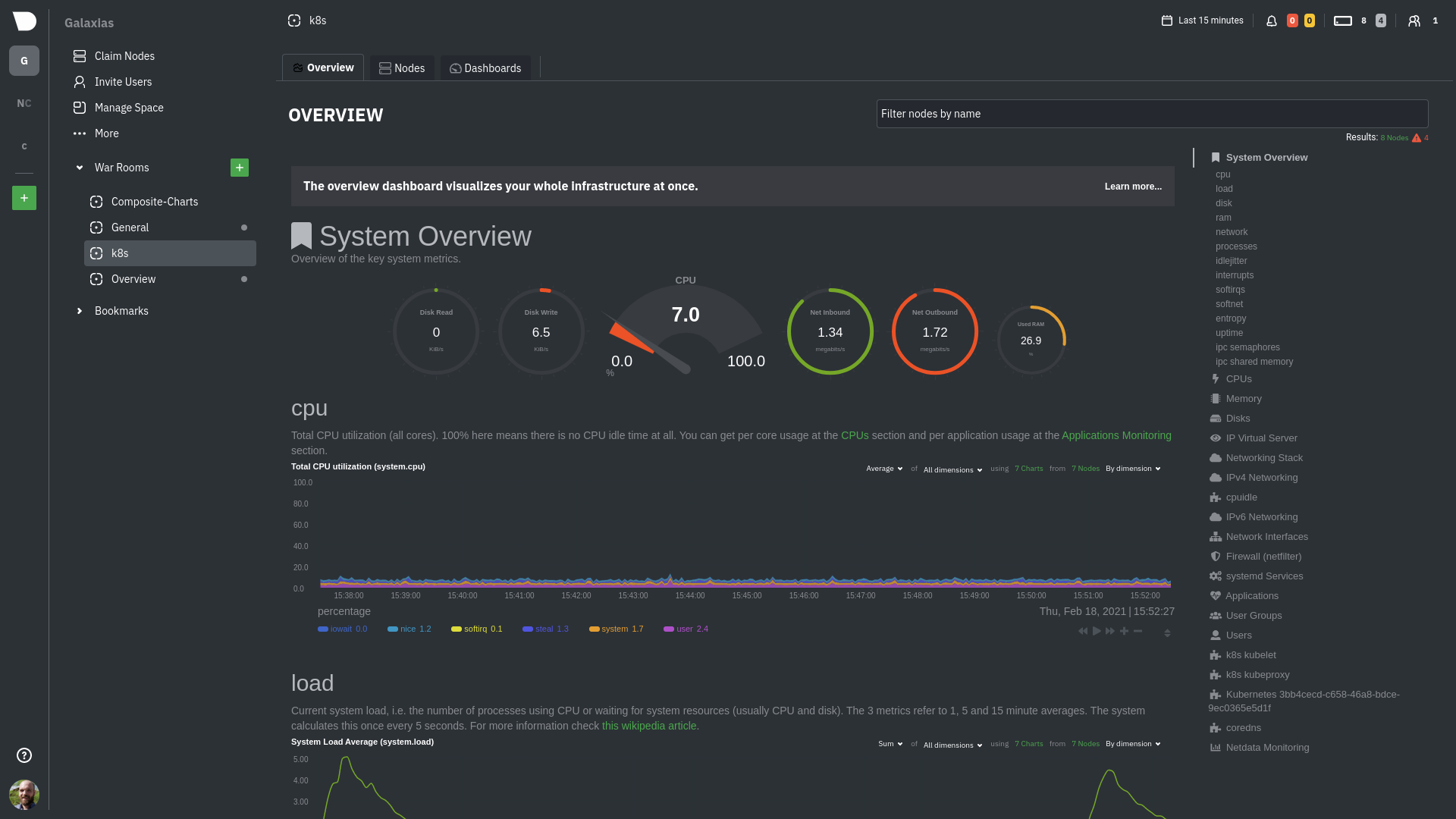 diff --git a/docs/cloud/manage/view-plan-billing.md b/docs/cloud/manage/view-plan-billing.md new file mode 100644 index 00000000..5d381f95 --- /dev/null +++ b/docs/cloud/manage/view-plan-billing.md @@ -0,0 +1,141 @@ +# View Plan & Billing + +From the Cloud interface, you can view and manage your space's plan and billing settings, and see the space's usage in terms of running nodes. + +To view and manage some specific settings, related to billing options and invoices, you'll be redirected to our billing provider Customer Portal. + +## Prerequisites + +To see your plan and billing setting you need: + +- A Cloud account +- Access to the space as an Administrator or Billing user + +## Steps + +### View current plan and Billing options and Invoices + +1. Click on the **Space settings** cog (located above your profile icon) +1. Click on the **Plan & Billing** tab +1. On this page you will be presented with information on your current plan, billing settings, and usage information: + 1. At the top of the page you will see: + - **Credit** amount which refers to any amount you have available to use on future invoices or subscription changes ([Plan changes and credit balance](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/plans.md#plan-changes-and-credit-balance)) - this is displayed once you have had an active paid subscription with us + - **Billing email** the email that was specified to be linked to tha plan subscription. This is where invoices, payment, and subscription-related notifications will be sent. + - **Billing options and Invoices** is the link to our billing provider Customer Portal where you will be able to: + - See the current subscription. There will always be 2 subscriptions active for the two pricing components mentioned on [Netdata Plans documentation page](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/plans.md#plans) + - Change directly the payment method associated to current subscriptions + - View, add, delete or change your default payment methods + - View or change or Billing information: + - Billing email + - Address + - Phone number + - Tax ID + - View your invoice history + 1. At the middle, you'll see details on your current plan as well as means to: + - Upgrade or cancel your plan + - View **All Plans** details page + 1. At the bottom, you will find your Usage chart that displays: + - Daily count - The weighted 90th percentile of the live node count during the day, taking time as the weight. If you have 30 live nodes throughout the day + except for a two hour peak of 44 live nodes, the daily value is 31. + - Period count: The 90th percentile of the daily counts for this period up to the date. The last value for the period is used as the number of nodes for the bill for that period. See more details in [running nodes and billing](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/plans.md#running-nodes-and-billing) (only applicable if you are on a paid plan subscription) + - Committed nodes: The number of nodes committed to in the yearly plan. In case the period count is higher than the number of committed nodes, the difference is billed as overage. + + +### Update plan + +1. Click on the **Space settings** cog (located above your profile icon) +1. Click on the **Plan & Billing** tab +1. On this page you will be presented with information on your current plan, billing settings, and usage information + 1. Depending on your plan there could be shortcuts to immediately take you to change, for example, the billing frequency to **Yearly** + 1. Most actions will be available under the **Change plan** link that take you to the **All plans** details page where you can + 1. Downgrade or upgrade your plan + 1. Change the billing frequency + 1. Change committed nodes, in case you are on a Yearly plan + 1. Once you chose an action to update your plan a modal will pop-up on the right with + 1. Billing frequency displayed on the top right-corner + 1. Committed Nodes, when applicable + 1. Current billing information: + - Billing email + - Default payment method + - Business name and VAT number, when these are applicable + - Billing Address + Note: Any changes to these need to done through our billing provider Customer Portal prior to confirm the checkout. You can click on the link **Change billing info and payment method** to access it. + 1. Promotion code, so you can review any applied promotion or enter one you may have + 1. Detailed view on Node and Space charges + 1. Breakdown of: + - Subscription Total + - Discount from promotion codes, if applicable + - credit value for Unused time from current plan, if applicable + - Credit amount used from balance, if applicable + - Total Before Tax + - VAT rate and amount, if applicable + 1. Summary of: + - Total payable amount + - credit adjustment value for any Remaining Unused time from current plan, if applicable + - Final credit balance + +Notes: +* Since there is an active plan you won't be redirected to our billing provider, the checkout if performed as soon as you click on **Checkout** +* The change to your plan will be applied as soon as the checkout process is completed successfully +* Downgrade or cancellations may have impacts on some of notification method settings or user accesses to your space, for more details please check [Plan changes and credit balance](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/plans.md#plan-changes-and-credit-balance) + +## FAQ + +### 1. What Payment Methods are accepted? + +You can easily pay online via most major Credit/Debit Cards. More payment options are expected to become available in the near future. + +### 2. What happens if a renewal payment fails? + +After an initial failed payment, we will attempt to process your payment every week for the next 15 days. After three failed attempts your Space will be moved to the **Community** plan (free forever). + +For the next 24 hours, you will be able to use all your current notification method configurations. After 24 hours, any of the notification method configurations that aren't available on your space's plan will be automatically disabled. + +Cancellation might affect users in your Space. Please check what roles are available on the [Community plan](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/plans.md#areas-impacted-by-plans). Users with unavailable roles on the Community plan will immediately have restricted access to the Space. + +### 3. Which currencies do you support? + +We currently accept payments only in US Dollars (USD). We currently have plans to also accept payments in Euros (EUR), but do not currently have an estimate for when such support will be available. + +### 4. Can I get a refund? How? + +Payments for Netdata subscriptions are refundable **only** if you cancel your subscription within 14 days of purchase. The refund will be credited to the Credit/Debit Card used for making the purchase. To request a refund, please email us at [billing@netdata.cloud](mailto:billing@netdata.cloud). + +### 5. How do I cancel my paid Plan? + +Your annual or monthly Netdata Subscription plan will automatically renew until you cancel it. You can cancel your paid plan at any time by clicking ‘Cancel Plan’ from the **Plan & Billing** section under settings. You can also cancel your paid Plan by clicking the _Select_ button under **Community** plan in the **Plan & Billing** Section under Settings. + +### 6. How can I access my Invoices/Receipts after I paid for a Plan? + +You can visit the _Billing Options & Invoices_ in the **Plan & Billing** section under settings in your Netdata Space where you can find all your Invoicing history. + +### 7. Why do I see two separate Invoices? + +Every time you purchase or renew a Plan, two separate Invoices are generated: + +- One Invoice includes the recurring fees of the Plan you have chosen + + We have waived off the space subscription free ($0.00), so the only recurring fee will be on annual plans for the committed nodes. + +- The other Invoice includes your monthly “On Demand - Usage”. + + Right after the activation of your subscription, you will receive a zero value Invoice since you had no usage when you subscribed. + + On the following month you will receive an Invoice based on your monthly usage. + +You can find some further details on the [Netdata Plans page](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/plans.md#plans). + +> ⚠️ We expect this to change to a single invoice in the future, but currently do not have a concrete timeline for when this change will happen. + +### 8. How is the **Total Before Tax** value calculated on plan changes? + +When you change your plan we will be calculating the residual before tax value you have from the _Unused time on your current plan_ in order to credit you with this value. + +After that, we will be performing the following calculations: + +1. Get the **Subscription total** (total amount to be paid for Nodes and Space) +2. Deduct any Discount applicable from promotion codes +3. If an amount remains, then we deduct the sum of the _Unused time on current plan_ then and the Credit amount from any existing credit balance. +4. The result, if positive, is the Total Before Tax, if applicable, any sales tax (VAT or other) will apply. + +If the calculation of step 3 returns a negative amount then this amount will be your new customer credit balance. diff --git a/docs/cloud/netdata-assistant.md b/docs/cloud/netdata-assistant.md new file mode 100644 index 00000000..afa13f6e --- /dev/null +++ b/docs/cloud/netdata-assistant.md @@ -0,0 +1,20 @@ +# Alert troubleshooting with Netdata Assistant + +The Netdata Assistant is a feature that uses large language models and the Netdata community's collective knowledge to guide you during troubleshooting. It is designed to make understanding and root causing alerts simpler and faster. + +## Using Netdata Assistant + +- Navigate to the alerts tab +- If there are active alerts, the `Actions` column will have an Assistant button + + 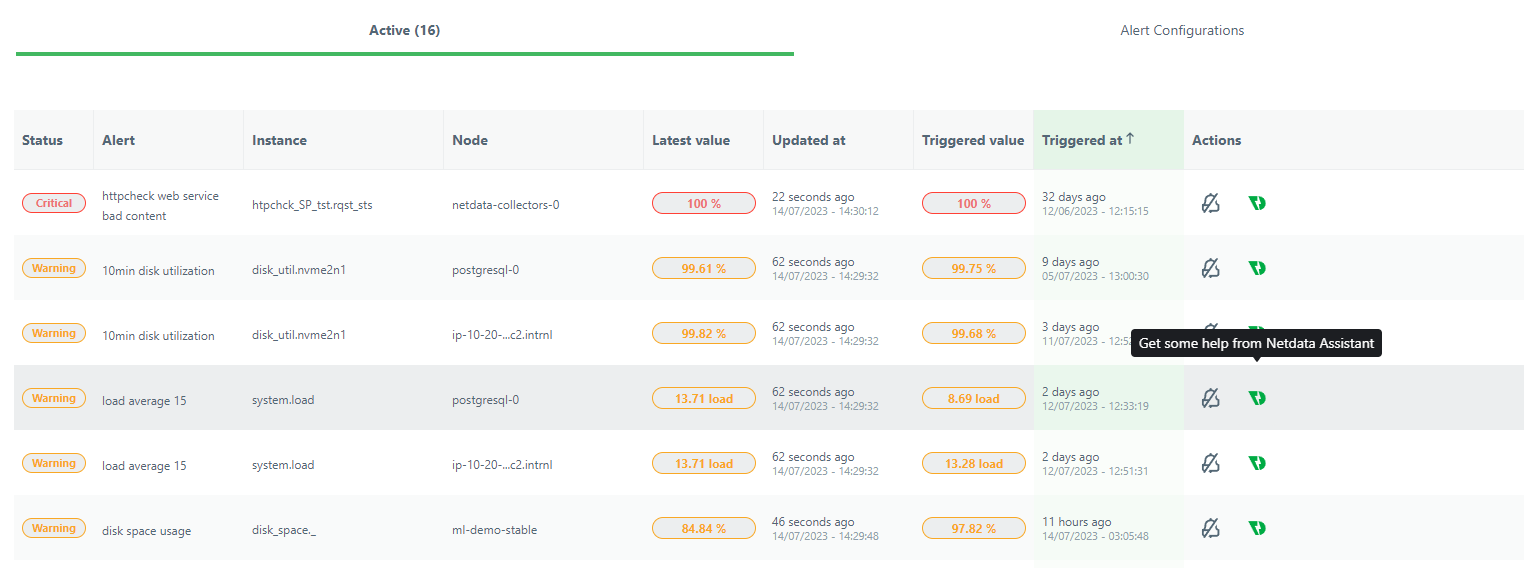 + +- Clicking on the Assistant button opens up as a floating window with customized information and troubleshooting tips for this alert (note that the window can follow you through your troubleshooting journey on Netdata dashboards) + +  + +- In case you need more information, or want to understand deeper, Netdata Assistant also provides useful web links to resources that can help. + +  + +- If there are no active alerts, you can still use Netdata Assistant by clicking the Assistant button on the Alert Configuration view. diff --git a/docs/cloud/netdata-functions.md b/docs/cloud/netdata-functions.md new file mode 100644 index 00000000..caff9b35 --- /dev/null +++ b/docs/cloud/netdata-functions.md @@ -0,0 +1,79 @@ +<!-- +title: "Netdata Functions" +sidebar_label: "Netdata Functions" +custom_edit_url: "https://github.com/netdata/netdata/blob/master/docs/cloud/netdata-functions.md" +sidebar_position: "2800" +learn_status: "Published" +learn_topic_type: "Concepts" +learn_rel_path: "Concepts" +learn_docs_purpose: "Present the Netdata Functions what these are and why they should be used." +--> + +# Netdata Functions + +Netdata Agent collectors are able to expose functions that can be executed in run-time and on-demand. These will be +executed on the node - host where the function is made +available. + +#### What is a function? + +Collectors besides the metric collection, storing, and/or streaming work are capable of executing specific routines on +request. These routines will bring additional information +to help you troubleshoot or even trigger some action to happen on the node itself. + +A function is a `key` - `value` pair. The `key` uniquely identifies the function within a node. The `value` is a +function (i.e. code) to be run by a data collector when +the function is invoked. + +For more details please check out documentation on how we use our internal collector to get this from the first collector that exposes +functions - [plugins.d](https://github.com/netdata/netdata/blob/master/collectors/plugins.d/README.md#function). + +#### What functions are currently available? + +| Function | Description | Alternative to CLI tools | plugin - module | +|:-------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------|---------------------------------|:-----------------------------------------------------------------------------------------------------------| +| block-devices | Disk I/O activity for all block devices, offering insights into both data transfer volume and operation performance. | `iostat` | [proc](https://github.com/netdata/netdata/tree/master/collectors/proc.plugin#readme) | +| containers-vms | Insights into the resource utilization of containers and QEMU virtual machines: CPU usage, memory consumption, disk I/O, and network traffic. | `docker stats`, `systemd-cgtop` | [cgroups](https://github.com/netdata/netdata/tree/master/collectors/cgroups.plugin#readme) | +| ipmi-sensors | Readings and status of IPMI sensors. | `ipmi-sensors` | [freeipmi](https://github.com/netdata/netdata/tree/master/collectors/freeipmi.plugin#readme) | +| mount-points | Disk usage for each mount point, including used and available space, both in terms of percentage and actual bytes, as well as used and available inode counts. | `df` | [diskspace](https://github.com/netdata/netdata/tree/master/collectors/diskspace.plugin#readme) | +| network interfaces | Network traffic, packet drop rates, interface states, MTU, speed, and duplex mode for all network interfaces. | `bmon`, `bwm-ng` | [proc](https://github.com/netdata/netdata/tree/master/collectors/proc.plugin#readme) | +| processes | Real-time information about the system's resource usage, including CPU utilization, memory consumption, and disk IO for every running process. | `top`, `htop` | [apps](https://github.com/netdata/netdata/blob/master/collectors/apps.plugin/README.md) | +| systemd-journal | Viewing, exploring and analyzing systemd journal logs. | `journalctl` | [systemd-journal](https://github.com/netdata/netdata/tree/master/collectors/systemd-journal.plugin#readme) | +| systemd-list-units | Information about all systemd units, including their active state, description, whether or not they are enabled, and more. | `systemctl list-units` | [systemd-journal](https://github.com/netdata/netdata/tree/master/collectors/systemd-journal.plugin#readme) | +| systemd-services | System resource utilization for all running systemd services: CPU, memory, and disk IO. | `systemd-cgtop` | [cgroups](https://github.com/netdata/netdata/tree/master/collectors/cgroups.plugin#readme) | +| streaming | Comprehensive overview of all Netdata children instances, offering detailed information about their status, replication completion time, and many more. | | | + + +If you have ideas or requests for other functions: +* Participate in the relevant [GitHub discussion](https://github.com/netdata/netdata/discussions/14412) +* Open a [feature request](https://github.com/netdata/netdata-cloud/issues/new?assignees=&labels=feature+request%2Cneeds+triage&template=FEAT_REQUEST.yml&title=%5BFeat%5D%3A+) on Netdata Cloud repo +* Join the Netdata community on [Discord](https://discord.com/invite/mPZ6WZKKG2) and let us know. + +#### How do functions work with streaming? + +Via streaming, the definitions of functions are transmitted to a parent node, so it knows all the functions available on +any children connected to it. + +If the parent node is the one connected to Netdata Cloud it is capable of triggering the call to the respective children +node to run the function. + +#### Why are they available only on Netdata Cloud? + +Since these functions are able to execute routines on the node and due to the potential use cases that they can cover, our +concern is to ensure no sensitive +information or disruptive actions are exposed through the Agent's API. + +With the communication between the Netdata Agent and Netdata Cloud being +through [ACLK](https://github.com/netdata/netdata/blob/master/aclk/README.md) this +concern is addressed. + +## Related Topics + +### **Related Concepts** + +- [ACLK](https://github.com/netdata/netdata/blob/master/aclk/README.md) +- [plugins.d](https://github.com/netdata/netdata/blob/master/collectors/plugins.d/README.md) + +### Related Tasks + +- [Run-time troubleshooting with Functions](https://github.com/netdata/netdata/blob/master/docs/cloud/runtime-troubleshooting-with-functions.md) diff --git a/docs/cloud/runtime-troubleshooting-with-functions.md b/docs/cloud/runtime-troubleshooting-with-functions.md new file mode 100644 index 00000000..839b8c9e --- /dev/null +++ b/docs/cloud/runtime-troubleshooting-with-functions.md @@ -0,0 +1,34 @@ +# Run-time troubleshooting with Functions + +Netdata Functions feature allows you to execute on-demand a pre-defined routine on a node where a Netdata Agent is running. These routines are exposed by a given collector. +These routines can be used to retrieve additional information to help you troubleshoot or to trigger some action to happen on the node itself. + + +### Prerequisites + +The following is required to be able to run Functions from Netdata Cloud. +* At least one of the nodes claimed to your Space should be on a Netdata agent version higher than `v1.37.1` +* Ensure that the node has the collector that exposes the function you want enabled ([see current available functions](https://github.com/netdata/netdata/blob/master/docs/cloud/netdata-functions.md#what-functions-are-currently-available)) + +### Execute a function (from the Functions tab) + +1. From the right-hand bar select the **Function** you want to run +2. Still on the right-hand bar select the **Node** where you want to run it +3. Results will be displayed in the central area for you to interact with +4. Additional filtering capabilities, depending on the function, should be available on right-hand bar + +### Execute a function (from the Nodes tab) + +1. Click on the functions icon for a node that has this active +2. You are directed to the **Functions** tab +3. Follow the above instructions from step 3. + +> ⚠️ If you get an error saying that your node can't execute Functions please check the [prerequisites](#prerequisites). + +## Related Topics + +### **Related Concepts** +- [Netdata Functions](https://github.com/netdata/netdata/blob/master/docs/cloud/netdata-functions.md) + +#### Related References documentation +- [External plugins overview](https://github.com/netdata/netdata/blob/master/collectors/plugins.d/README.md#function) diff --git a/docs/cloud/visualize/dashboards.md b/docs/cloud/visualize/dashboards.md new file mode 100644 index 00000000..4b4baf42 --- /dev/null +++ b/docs/cloud/visualize/dashboards.md @@ -0,0 +1,101 @@ +# Build new dashboards + +With Netdata Cloud, you can build new dashboards that target your infrastructure's unique needs. Put key metrics from +any number of distributed systems in one place for a bird's eye view of your infrastructure. + +Click on the **Dashboards** tab in any War Room to get started. + +## Create your first dashboard + +From the Dashboards tab, click on the **+** button. + +<img width="98" alt=" Green plus button " src="https://github.com/netdata/netdata/assets/73346910/511e2b38-e751-4a88-bc7d-bcd49764b7f6"/> + + +In the modal, give your new dashboard a name, and click **+ Add**. + +- The **Add Chart** button on the top right of the interface adds your first chart card. From the dropdown, select either **All Nodes** or a specific +node. Next, select the context. You'll see a preview of the chart before you finish adding it. In this modal you can also [interact with the chart](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/interact-new-charts.md), meaning you can configure all the aspects of the [NIDL framework](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/interact-new-charts.md#nidl-framework) of the chart and more in detail, you can: + - define which `group by` method to use + - select the aggregation function over the data source + - select nodes + - select instances + - select dimensions + - select labels + - select the aggregation function over time + + After you are done configuring the chart, you can also change the type of the chart from the right hand side of the [Title bar](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/interact-new-charts.md#title-bar), and select which of the final dimensions you want to be visible and in what order, from the [Dimensions bar](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/interact-new-charts.md#dimensions-bar). + +- The **Add Text** button on the top right of the interface creates a new card with user-defined text, which you can use to describe or document a +particular dashboard's meaning and purpose. + +> ### Important +> +> Be sure to click the **Save** button any time you make changes to your dashboard. + + +## Using your dashboard + +Dashboards are designed to be interactive and flexible so you can design them to your exact needs. Dashboards are made +of any number of **cards**, which can contain charts or text. + +### Chart cards + +The charts you add to any dashboard are [fully interactive](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/interact-new-charts.md), just like any other Netdata chart. You can zoom in and out, highlight timeframes, and more. + +Charts also synchronize as you interact with them, even across contexts _or_ nodes. + +### Text cards + +You can use text cards as notes to explain to other members of the [War Room](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/organize-your-infrastrucutre-invite-your-team.md#netdata-cloud-war-rooms) the purpose of the dashboard's arrangement. + +### Move cards + +To move any card, click and hold on **Drag & rearrange** at the top right of the card and drag it to a new location. A red placeholder indicates the +new location. Once you release your mouse, other charts re-sort to the grid system automatically. + +### Resize cards + +To resize any card on a dashboard, click on the bottom-right corner and drag to the card's new size. Other cards re-sort +to the grid system automatically. + +## Go to chart + +Quickly jump to the location of the chart in either the Overview tab or if the card refers to a single node, its single node dashboard by clicking the 3-dot icon in the corner of any card to open a menu. Hit the **Go to Chart** item. + +You'll land directly on that chart of interest, but you can now scroll up and down to correlate your findings with other +charts. Of course, you can continue to zoom, highlight, and pan through time just as you're used to with Netdata Charts. + +## Managing your dashboard + +To see dashboards associated with the current War Room, click the **Dashboards** tab in any War Room. You can select +dashboards and delete them using the 🗑️ icon. + +### Update/save a dashboard + +If you've made changes to a dashboard, such as adding or moving cards, the **Save** button is enabled. Click it to save +your most recent changes. Any other members of the War Room will be able to see these changes the next time they load +this dashboard. + +If multiple users attempt to make concurrent changes to the same dashboard, the second user who hits Save will be +prompted to either overwrite the dashboard or reload to see the most recent changes. + +### Remove an individual card + +Click on the 3-dot icon in the corner of any card to open a menu. Click the **Remove** item to remove the card. + +### Delete a dashboard + +Delete any dashboard by navigating to it and clicking the **Delete** button. This will remove this entry from the +dropdown for every member of this War Room. + +### Minimum browser viewport + +Because of the visual complexity of individual charts, dashboards require a minimum browser viewport of 800px. + +## What's next? + +Once you've designed a dashboard or two, make sure +to [invite your team](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/organize-your-infrastrucutre-invite-your-team.md#invite-your-team) if +you haven't already. You can add these new users to the same War Room to let them see the same dashboards without any +effort. diff --git a/docs/cloud/visualize/interact-new-charts.md b/docs/cloud/visualize/interact-new-charts.md new file mode 100644 index 00000000..16db927a --- /dev/null +++ b/docs/cloud/visualize/interact-new-charts.md @@ -0,0 +1,416 @@ +# Netdata Charts + +Learn how to use Netdata's powerful charts to troubleshoot with real-time, per-second metric data. + +Netdata excels in collecting, storing, and organizing metrics in out-of-the-box dashboards. +To make sense of all the metrics, Netdata offers an enhanced version of charts that update every second. + +These charts provide a lot of useful information, so that you can: + +- Enjoy the high-resolution, granular metrics collected by Netdata +- Examine all the metrics by hovering over them with your cursor +- Filter the metrics in any way you want using the [Definition bar](#definition-bar) +- View the combined anomaly rate of all underlying data with the [Anomaly Rate ribbon](#anomaly-rate-ribbon) +- Explore even more details about a chart's metrics through [hovering over certain elements of it](#hover-over-the-chart) +- Use intuitive tooling and shortcuts to pan, zoom or highlight areas of interest in your charts +- On highlight, get easy access to [Metric Correlations](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/metric-correlations.md) to see other metrics with similar patterns +- Have the dimensions sorted based on name or value +- View information about the chart, its plugin, context, and type +- View individual metric collection status about a chart + +These charts are available on Netdata Cloud's +[Overview tab](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/overview.md), Single Node tab and +on your [Custom Dashboards](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/dashboards.md). + +## Overview + +A Netdata chart looks like this: + +<img src="https://user-images.githubusercontent.com/70198089/236133212-353c102f-a6ed-45b7-9251-34e004c7a10a.png" width="900"/> + +With a quick glance you have immediate information available at your disposal: + +- [Chart title and units](#title-bar) +- [Anomaly Rate ribbon](#anomaly-rate-ribbon) +- [Definition bar](#definition-bar) +- [Tool bar](#tool-bar) +- [Chart area](#hover-over-the-chart) +- [Legend with dimensions](#dimensions-bar) + +## Fundemental elements + +While Netdata's charts require no configuration and are easy to interact with, they have a lot of underlying complexity. To meaningfully organize charts out of the box based on what's happening in your nodes, Netdata uses the concepts of [dimensions](#dimensions), [contexts](#contexts), and [families](#families). + +Understanding how these work will help you more easily navigate the dashboard, +[write new alerts](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md), or play around +with the [API](https://github.com/netdata/netdata/blob/master/web/api/README.md). + +### Dimensions + +A **dimension** is a value that gets shown on a chart. The value can be raw data or calculated values, such as the +average (the default), minimum, or maximum. These values can then be given any type of unit. For example, CPU +utilization is represented as a percentage, disk I/O as `MiB/s`, and available RAM as an absolute value in `MiB` or +`GiB`. + +Beneath every chart (or on the right-side if you configure the dashboard) is a legend of dimensions. When there are +multiple dimensions, you'll see a different entry in the legend for each dimension. + +The **Apps CPU Time** chart (with the [context](#contexts) `apps.cpu`), which visualizes CPU utilization of +different types of processes/services/applications on your node, always provides a vibrant example of a chart with +multiple dimensions. + +Dimensions can be [hidden](#show-and-hide-dimensions) to help you focus your attention. + +### Contexts + +A **context** is a way of grouping charts by the types of metrics collected and dimensions displayed. It's like a machine-readable naming and organization scheme. + +For example, the **Apps CPU Time** has the context `apps.cpu`. A little further down on the dashboard is a similar +chart, **Apps Real Memory (w/o shared)** with the context `apps.mem`. The `apps` portion of the context is the **type**, +whereas anything after the `.` is specified either by the chart's developer or by the [family](#families). + +By default, a chart's type affects where it fits in the menu, while its family creates submenus. + +Netdata also relies on contexts for [alert configuration](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md) (the [`on` line](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md#alert-line-on)). + +### Families + +**Families** are a _single instance_ of a hardware or software resource that needs to be displayed separately from +similar instances. + +For example, let's look at the **Disks** section, which contains a number of charts with contexts like `disk.io`, +`disk.ops`, `disk.backlog`, and `disk.util`. If your node has multiple disk drives at `sda` and `sdb`, Netdata creates +a separate family for each. + +Netdata now merges the contexts and families to create charts that are grouped by family, following a +`[context].[family]` naming scheme, so that you can see the `disk.io` and `disk.ops` charts for `sda` right next to each +other. + +Given the four example contexts, and two families of `sda` and `sdb`, Netdata will create the following charts and their +names: + +| Context | `sda` family | `sdb` family | +|:---------------|--------------------|--------------------| +| `disk.io` | `disk_io.sda` | `disk_io.sdb` | +| `disk.ops` | `disk_ops.sda` | `disk_ops.sdb` | +| `disk.backlog` | `disk_backlog.sda` | `disk_backlog.sdb` | +| `disk.util` | `disk_util.sda` | `disk_util.sdb` | + +## Title bar + +When you start interacting with a chart, you'll notice valuable information on the top bar: + +<img src="https://user-images.githubusercontent.com/70198089/236133832-fad45e65-5bd6-4fd1-8d68-33acf69fff5c.png" width="900"/> + +The elements that you can find on this top bar are: + +- **Netdata icon**: this indicates that data is continuously being updated, this happens if [Time controls](https://github.com/netdata/netdata/blob/master/docs/dashboard/visualization-date-and-time-controls.md#time-controls) are in Play or Force Play mode. +- **Chart title**: on the chart title you can see the title together with the metric being displayed, as well as the unit of measurement. +- **Chart status icon**: possible values are: Loading, Timeout, Error or No data, otherwise this icon is not shown. + +Along with viewing chart type, context and units, on this bar you have access to immediate actions over the chart: + +<img src="https://user-images.githubusercontent.com/70198089/236134195-ecb08f79-1355-4bce-8449-e829f4a6b1c0.png" width="200" /> + +- **Chart info**: get more information relevant to the chart you are interacting with. +- **Chart type**: change the chart type from **line**, **stacked**, **area**, **stacked bar** and **multi bar**. +- **Enter fullscreen mode**: expand the current chart to the full size of your screen. +- **Add chart to dashboard**: add the chart to an existing custom dashboard or directly create a new one that includes the chart. + +## Definition bar + +Each composite chart has a definition bar to provide information and options about the following: + +<img src="https://user-images.githubusercontent.com/70198089/236134615-e53a1d68-8a0f-466b-b2ef-1974085f0e8d.png" width="900"/> + +- Group by option +- Aggregate function to be applied in case multiple data sources exist +- Nodes filter +- Instances filter +- Dimensions filter +- Labels filter +- The aggregate function over time to be applied if one point in the chart consists of multiple data points aggregated +- Resetting the Definition bar + +### NIDL framework + +To help users instantly understand and validate the data they see on charts, we developed the NIDL (Nodes, Instances, Dimensions, Labels) framework. This information is visualized on all charts. + +> You can explore the in-depth infographic, by clicking on this image and opening it in a new tab, +> allowing you to zoom in to the different parts of it. +> +> <a href="https://user-images.githubusercontent.com/2662304/235475061-44628011-3b1f-4c44-9528-34452018eb89.png" target="_blank"> +> <img src="https://user-images.githubusercontent.com/2662304/235475061-44628011-3b1f-4c44-9528-34452018eb89.png" width="400" border="0" align="center"/> +> </a> + +You can rapidly access condensed information for collected metrics, grouped by node, monitored instances, dimension, or any key/value label pair. + +At the Definition bar of each chart, there are a few dropdown menus: + +<img src="https://user-images.githubusercontent.com/43294513/235470150-62a3b9ac-51ca-4c0d-81de-8804e3d733eb.png" width="900"/> + +These dropdown menus have 2 functions: + +1. Provide additional information about the visualized chart, to help with understanding the data that is presented. +2. Provide filtering and grouping capabilities, altering the query on the fly, to help get different views of the dataset. + +The NIDL framework attaches metadata to every metric that is collected to provide for each of them the following consolidated data for the visible time frame: + +1. The volume contribution of each metric into the final query. So even if a query comes from 1000 nodes, the contribution of each node in the result can instantly be visualized. The same goes for instances, dimensions and labels. Especially for labels, Netdata also provides the volume contribution of each label `key:value` pair to the final query, so that you can immediately see how much every label value involved in the query affected the chart. +2. The anomaly rate of each of them for the time-frame of the query. This is used to quickly spot which of the nodes, instances, dimensions or labels have anomalies in the requested time-frame. +3. The minimum, average and maximum values of all the points used for the query. This is used to quickly spot which of the nodes, instances, dimensions or labels are responsible for a spike or a dive in the chart. + +All of these dropdown menus can be used for instantly filtering the information shown, by including or excluding specific nodes, instances, dimensions or labels. Directly from the dropdown menu, without the need to edit a query string and without any additional knowledge of the underlying data. + +### Group by dropdown + +The "Group by" dropdown menu allows selecting 1 or more groupings to be applied at once on the same dataset. + +<img src="https://user-images.githubusercontent.com/43294513/235468819-3af5a1d3-8619-48fb-a8b7-8e8b4cf6a8ff.png" width="900"/> + +It supports: + +1. **Group by Node**, to summarize the data of each node, and provide one dimension on the chart for each of the nodes involved. Filtering nodes is supported at the same time, using the nodes dropdown menu. +2. **Group by Instance**, to summarize the data of each instance and provide one dimension on the chart for each of the instances involved. Filtering instances is supported at the same time, using the instances dropdown menu. +3. **Group by Dimension**, so that each metric in the visualization is the aggregation of a single dimension. This provides a per dimension view of the data from all the nodes in the War Room, taking into account filtering criteria if defined. +4. **Group by Label**, to summarize the data for each label value. Multiple label keys can be selected at the same time. + +Using this menu, you can slice and dice the data in any possible way, to quickly get different views of it, without the need to edit a query string and without any need to better understand the format of the underlying data. + +> ### Tip +> +> A very pertinent example is composite charts over contexts related to cgroups (VMs and containers). +> You have the means to change the default group by or apply filtering to get a better view into what data your are trying to analyze. +> For example, if you change the group by to _instance_ you get a view with the data of all the instances (cgroups) that contribute to that chart. +> Then you can use further filtering tools to focus the data that is important to you and even save the result to your own dashboards. + +> ### Tip +> +> Group by instance, dimension to see the time series of every individual collected metric participating in the chart. + +### Aggregate functions over data sources dropdown + +Each chart uses an opinionated-but-valuable default aggregate function over the data sources. + +<img src="https://user-images.githubusercontent.com/70198089/236136725-778670b4-7e81-44a8-8d3d-f38ded823c94.png" width="500"/> + +For example, the `system.cpu` chart shows the average for each dimension from every contributing chart, while the `net.net` chart shows the sum for each dimension from every contributing chart, which can also come from multiple networking interfaces. + +The following aggregate functions are available for each selected dimension: + +- **Average**: Displays the average value from contributing nodes. If a composite chart has 5 nodes with the following + values for the `out` dimension—`-2.1`, `-5.5`, `-10.2`, `-15`, `-0.1`—the composite chart displays a + value of `−6.58`. +- **Sum**: Displays the sum of contributed values. Using the same nodes, dimension, and values as above, the composite + chart displays a metric value of `-32.9`. +- **Min**: Displays a minimum value. For dimensions with positive values, the min is the value closest to zero. For + charts with negative values, the min is the value with the largest magnitude. +- **Max**: Displays a maximum value. For dimensions with positive values, the max is the value with the largest + magnitude. For charts with negative values, the max is the value closet to zero. + +### Nodes dropdown + +In this dropdown, you can view or filter the nodes contributing time-series metrics to the chart. +This menu also provides the contribution of each node to the volume of the chart, and a break down of the anomaly rate of the queried data per node. + +<img src="https://user-images.githubusercontent.com/70198089/236137765-b57d5443-3d4b-42f4-9e3d-db1eb606626f.png" width="900"/> + +If one or more nodes can't contribute to a given chart, the definition bar shows a warning symbol plus the number of +affected nodes, then lists them in the dropdown along with the associated error. Nodes might return errors because of +networking issues, a stopped `netdata` service, or because that node does not have any metrics for that context. + +### Instances dropdown + +In this dropdown, you can view or filter the instances contributing time-series metrics to the chart. +This menu also provides the contribution of each instance to the volume of the chart, and a break down of the anomaly rate of the queried data per instance. + +<img src="https://user-images.githubusercontent.com/70198089/236138302-4dd4072e-3a0d-43bb-a9d8-4dde79c65e92.png" width="900"/> + +### Dimensions dropdown + +In this dropdown, you can view or filter the original dimensions contributing time-series metrics to the chart. +This menu also presents the contribution of each original dimensions on the chart, and a break down of the anomaly rate of the data per dimension. + +<img src="https://user-images.githubusercontent.com/70198089/236138796-08dc6ac6-9a50-4913-a46d-d9bbcedd48f6.png" width="900"/> + +### Labels dropdown + +In this dropdown, you can view or filter the contributing time-series labels of the chart. +This menu also presents the contribution of each label on the chart,and a break down of the anomaly rate of the data per label. + +<img src="https://user-images.githubusercontent.com/70198089/236139027-8a51a958-2074-4675-a41b-efff30d8f51a.png" width="900"/> + +### Aggregate functions over time + +When the granularity of the data collected is higher than the plotted points on the chart an aggregation function over +time is applied. + +<img src="https://user-images.githubusercontent.com/70198089/236411297-e123db06-0117-4e24-a5ac-955b980a8f55.png" width="400"/> + +By default the aggregation applied is _average_ but the user can choose different options from the following: + +- Min, Max, Average or Sum +- Percentile + - you can specify the percentile you want to focus on: 25th, 50th, 75th, 80th, 90th, 95th, 97th, 98th and 99th. + <img src="https://user-images.githubusercontent.com/70198089/236410299-de5f3367-f3b0-4beb-a73f-a49007c543d4.png" width="250"/> +- Trimmed Mean or Trimmed Median + - you can choose the percentage of data tha you want to focus on: 1%, 2%, 3%, 5%, 10%, 15%, 20% and 25%. + <img src="https://user-images.githubusercontent.com/70198089/236410858-74b46af9-280a-4ab2-ad26-5a6aa9403aa8.png" width="250"/> +- Median +- Standard deviation +- Coefficient of variation +- Delta +- Single or Double exponential smoothing + +For more details on each, you can refer to our Agent's HTTP API details on [Data Queries - Data Grouping](https://github.com/netdata/netdata/blob/master/web/api/queries/README.md#data-grouping). + +### Reset to defaults + +Finally, you can reset everything to its defaults by clicking the green "Reset" prompt at the end of the definition bar. + +## Anomaly Rate ribbon + +Netdata's unsupervised machine learning algorithm creates a unique model for each metric collected by your agents, using exclusively the metric's past data. +It then uses these unique models during data collection to predict the value that should be collected and check if the collected value is within the range of acceptable values based on past patterns and behavior. + +If the value collected is an outlier, it is marked as anomalous. + +<img src="https://user-images.githubusercontent.com/70198089/236139886-79d63cf6-61ed-4aa7-842c-b5a1728c870d.png" width="900"/> + +This unmatched capability of real-time predictions as data is collected allows you to **detect anomalies for potentially millions of metrics across your entire infrastructure within a second of occurrence**. + +The Anomaly Rate ribbon on top of each chart visualizes the combined anomaly rate of all the underlying data, highlighting areas of interest that may not be easily visible to the naked eye. + +Hovering over the Anomaly Rate ribbon provides a histogram of the anomaly rates per presented dimension, for the specific point in time. + +Anomaly Rate visualization does not make Netdata slower. Anomaly rate is saved in the the Netdata database, together with metric values, and due to the smart design of Netdata, it does not even incur a disk footprint penalty. + +## Hover over the chart + +Hovering over any point in the chart will reveal a more informative overlay. +It includes a bar indicating the volume percentage of each time series compared to the total, the anomaly rate, and a notification on if there are data collection issues. + +This overlay sorts all dimensions by value, makes bold the closest dimension to the mouse and presents a histogram based on the values of the dimensions. + +<img src="https://user-images.githubusercontent.com/70198089/236141460-bfa66b99-d63c-4a2c-84b1-2509ed94857f.png" width="500"/> + +When hovering the anomaly ribbon, the overlay sorts all dimensions by anomaly rate, and presents a histogram of these anomaly rates. + +#### Info column + +Additionally, when hovering over the chart, the overlay may display an indication in the "Info" column. + +Currently, this column is used to inform users of any data collection issues that might affect the chart. +Below each chart, there is an information ribbon. This ribbon currently shows 3 states related to the points presented in the chart: + +1. **[P]: Partial Data** + At least one of the dimensions in the chart has partial data, meaning that not all instances available contributed data to this point. This can happen when a container is stopped, or when a node is restarted. This indicator helps to gain confidence of the dataset, in situations when unusual spikes or dives appear due to infrastructure maintenance, or due to failures to part of the infrastructure. + +2. **[O]: Overflown** + At least one of the data sources included in the chart has a counter that has overflowed at this point. + +3. **[E]: Empty Data** + At least one of the dimensions included in the chart has no data at all for the given points. + +All these indicators are also visualized per dimension, in the pop-over that appears when hovering the chart. + +<img src="https://user-images.githubusercontent.com/70198089/236145768-8ffadd02-93a4-4e9e-b4ae-c1367f614a7e.png" width="700"/> + +## Play, Pause and Reset + +Your charts are controlled using the available [Time controls](https://github.com/netdata/netdata/blob/master/docs/dashboard/visualization-date-and-time-controls.md#time-controls). +Besides these, when interacting with the chart you can also activate these controls by: + +- Hovering over any chart to temporarily pause it - this momentarily switches time control to Pause, so that you can + hover over a specific timeframe. When moving out of the chart time control will go back to Play (if it was it's + previous state) +- Clicking on the chart to lock it - this enables the Pause option on the time controls, to the current timeframe. This + is if you want to jump to a different chart to look for possible correlations. +- Double clicking to release a previously locked chart - move the time control back to Play + +| Interaction | Keyboard/mouse | Touchpad/touchscreen | Time control | +|:------------------|:---------------|:---------------------|:----------------------| +| **Pause** a chart | `hover` | `n/a` | Temporarily **Pause** | +| **Stop** a chart | `click` | `tap` | **Pause** | +| **Reset** a chart | `double click` | `n/a` | **Play** | + +Note: These interactions are available when the default "Pan" action is used from the [Tool Bar](#tool-bar). + +## Tool bar + +While exploring the chart, a tool bar will appear. This tool bar is there to support you on this task. +The available manipulation tools you can select are: + +<img src="https://user-images.githubusercontent.com/70198089/236143292-c1d75528-263d-4ddd-9db8-b8d6a31cb83e.png" width="400" /> + +- Pan +- Highlight +- Select and zoom +- Chart zoom +- Reset zoom + +### Pan + +Drag your mouse/finger to the right to pan backward through time, or drag to the left to pan forward in time. Think of +it like pushing the current timeframe off the screen to see what came before or after. + +| Interaction | Keyboard | Mouse | Touchpad/touchscreen | +|:------------|:---------|:---------------|:---------------------| +| **Pan** | `n/a` | `click + drag` | `touch drag` | + +### Highlight + +Selecting timeframes is useful when you see an interesting spike or change in a chart and want to investigate further by: + +- Looking at the same period of time on other charts/sections +- Running [metric correlations](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/metric-correlations.md) to filter metrics that also show something different in the selected period, vs the previous one + +| Interaction | Keyboard/mouse | Touchpad/touchscreen | +|:-----------------------------------|:---------------------------------------------------------|:---------------------| +| **Highlight** a specific timeframe | `Alt + mouse selection` or `⌘ + mouse selection` (macOS) | `n/a` | + +### Select and zoom + +You can zoom to a specific timeframe, either horizontally of vertically, by selecting a timeframe. + +| Interaction | Keyboard/mouse | Touchpad/touchscreen | +|:-------------------------------------------|:-------------------------------------|:-----------------------------------------------------| +| **Zoom** to a specific timeframe | `Shift + mouse vertical selection` | `n/a` | +| **Horizontal Zoom** a specific Y-axis area | `Shift + mouse horizontal selection` | `n/a` | + +### Chart zoom + +Zooming in helps you see metrics with maximum granularity, which is useful when you're trying to diagnose the root cause +of an anomaly or outage. + +Zooming out lets you see metrics within the larger context, such as the last hour, day, or week, which is useful in understanding what "normal" looks like, or to identify long-term trends, like a slow creep in memory usage. + +| Interaction | Keyboard/mouse | Touchpad/touchscreen | +|:-------------------------------------------|:-------------------------------------|:-----------------------------------------------------| +| **Zoom** in or out | `Shift + mouse scrollwheel` | `two-finger pinch` <br />`Shift + two-finger scroll` | + +## Dimensions bar + +### Order dimensions legend + +The bottom legend where you can see the dimensions of the chart can be ordered by: + +<img src="https://user-images.githubusercontent.com/70198089/236144658-6c3d0e31-9bcb-45f3-bb95-4eafdcbb0a58.png" width="300" /> + +- Dimension name (Ascending or Descending) +- Dimension value (Ascending or Descending) +- Dimension Anomaly Rate (Ascending or Descending) + +### Show and hide dimensions + +Hiding dimensions simplifies the chart and can help you better discover exactly which aspect of your system might be +behaving strangely. + +| Interaction | Keyboard/mouse | Touchpad/touchscreen | +|:---------------------------------------|:----------------|:---------------------| +| **Show one** dimension and hide others | `click` | `tap` | +| **Toggle (show/hide)** one dimension | `Shift + click` | `n/a` | + +## Resize a chart + +To resize the chart, click-and-drag the icon on the bottom-right corner of any chart. To restore the chart to its original height, double-click the same icon. diff --git a/docs/cloud/visualize/kubernetes.md b/docs/cloud/visualize/kubernetes.md new file mode 100644 index 00000000..82c33fd3 --- /dev/null +++ b/docs/cloud/visualize/kubernetes.md @@ -0,0 +1,142 @@ +<!-- +title: "Kubernetes visualizations" +description: "Netdata Cloud features rich, zero-configuration Kubernetes monitoring for the resource utilization and application metrics of Kubernetes (k8s) clusters." +custom_edit_url: "https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/kubernetes.md" +sidebar_label: "Kubernetes visualizations" +learn_status: "Published" +learn_topic_type: "Concepts" +learn_rel_path: "Operations/Visualizations" +--> + +# Kubernetes visualizations + +Netdata Cloud features enhanced visualizations for the resource utilization of Kubernetes (k8s) clusters, embedded in +the default [Overview](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/overview.md) dashboard. + +These visualizations include a health map for viewing the status of k8s pods/containers, in addition to composite charts +for viewing per-second CPU, memory, disk, and networking metrics from k8s nodes. + +See our [Kubernetes deployment instructions](https://github.com/netdata/netdata/blob/master/packaging/installer/methods/kubernetes.md) for details on +installation and connecting to Netdata Cloud. + +## Available Kubernetes metrics + +Netdata Cloud organizes and visualizes the following metrics from your Kubernetes cluster from every container: + +- `cpu_limit`: CPU utilization as a percentage of the limit defined by the [pod specification + `spec.containers[].resources.limits.cpu`](https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/#resource-requests-and-limits-of-pod-and-container) + or a [`LimitRange` + object](https://kubernetes.io/docs/tasks/administer-cluster/manage-resources/cpu-default-namespace/#create-a-limitrange-and-a-pod). +- `cpu`: CPU utilization of the pod/container. 100% usage equals 1 fully-utilized core, 200% equals 2 fully-utilized + cores, and so on. +- `cpu_per_core`: CPU utilization averaged across available cores. +- `mem_usage_limit`: Memory utilization, without cache, as a percentage of the limit defined by the [pod specification + `spec.containers[].resources.limits.memory`](https://kubernetes.io/docs/concepts/configuration/manage-resources-containers/#resource-requests-and-limits-of-pod-and-container) + or a [`LimitRange` + object](https://kubernetes.io/docs/tasks/administer-cluster/manage-resources/cpu-default-namespace/#create-a-limitrange-and-a-pod). +- `mem_usage`: Used memory, without cache. +- `mem`: The sum of `cache` and `rss` (resident set size) memory usage. +- `writeback`: The size of `dirty` and `writeback` cache. +- `mem_activity`: Sum of `in` and `out` bandwidth. +- `pgfaults`: Sum of page fault bandwidth, which are raised when the Kubernetes cluster tries accessing a memory page + that is mapped into the virtual address space, but not actually loaded into main memory. +- `throttle_io`: Sum of `read` and `write` per second across all PVs/PVCs attached to the container. +- `throttle_serviced_ops`: Sum of the `read` and `write` operations per second across all PVs/PVCs attached to the + container. +- `net.net`: Sum of `received` and `sent` bandwidth per second. +- `net.packets`: Sum of `multicast`, `received`, and `sent` packets. + +When viewing the [health map](#health-map), Netdata Cloud shows the above metrics per container, or aggregated based on +their associated pods. + +When viewing the [composite charts](#composite-charts), Netdata Cloud aggregates metrics from multiple nodes, pods, or +containers, depending on the grouping chosen. For example, if you group the `cpu_limit` composite chart by +`k8s_namespace`, the metrics shown will be the average of `cpu_limit` metrics from all nodes/pods/containers that are +part of that namespace. + +## Health map + +The health map places each container or pod as a single box, then varies the intensity of its color to visualize the +resource utilization of specific k8s pods/containers. + + + +Change the health map's coloring, grouping, and displayed nodes to customize your experience and learn more about the +status of your k8s cluster. + +### Color by + +Color the health map by choosing an aggregate function to apply to an [available Kubernetes +metric](#available-kubernetes-metrics), then whether you to display boxes for individual pods or containers. + +The default is the _average, of CPU within the configured limit, organized by container_. + +### Group by + +Group the health map by the `k8s_cluster_id`, `k8s_controller_kind`, `k8s_controller_name`, `k8s_kind`, `k8s_namespace`, +and `k8s_node_name`. The default is `k8s_controller_name`. + +### Filtering + +Filtering behaves identically to the [node filter in War Rooms](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/node-filter.md), with the ability to +filter pods/containers by `container_id` and `namespace`. + +### Detailed information + +Hover over any of the pods/containers in the map to display a modal window, which contains contextual information +and real-time metrics from that resource. + +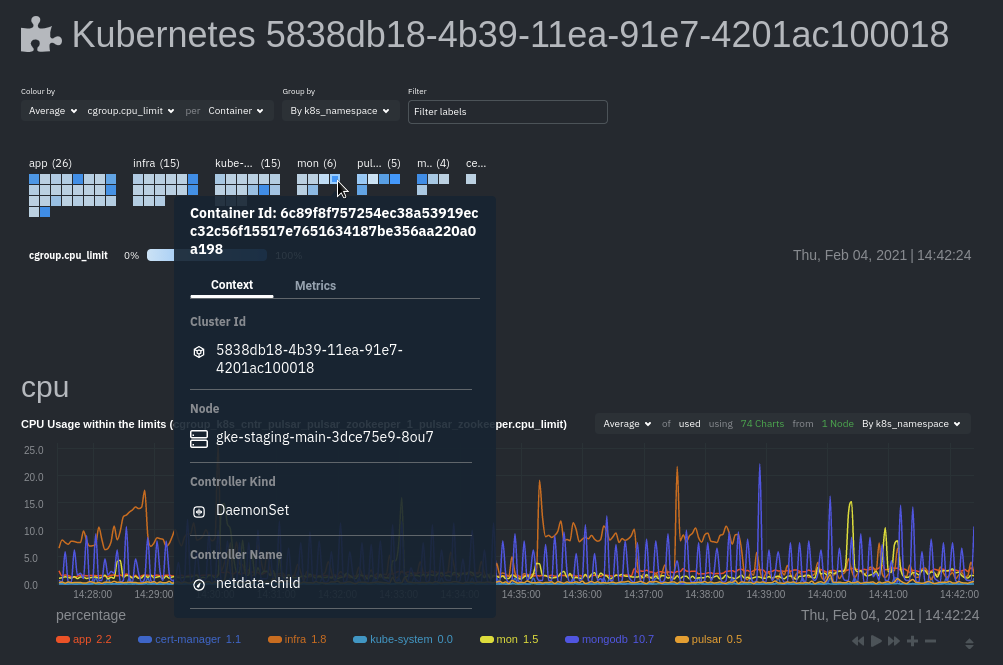 + +The **context** tab provides the following details about a container or pod: + +- Cluster ID +- Node +- Controller Kind +- Controller Name +- Pod Name +- Container +- Kind +- Pod UID + +This information helps orient you as to where the container/pod operates inside your cluster. + +The **Metrics** tab contains charts visualizing the last 15 minutes of the same metrics available in the [color by +option](#color-by). Use these metrics along with the context, to identify which containers or pods are experiencing +problematic behavior to investigate further, troubleshoot, and remediate with `kubectl` or another tool. + +## Composite charts + +The Kubernetes composite charts show real-time and historical resource utilization metrics from nodes, pods, or +containers within your Kubernetes deployment. + +See the [Overview](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/overview.md#definition-bar) doc for details on how composite charts work. These +work similarly, but in addition to visualizing _by dimension_ and _by node_, Kubernetes composite charts can also be +grouped by the following labels: + +- `k8s_cluster_id` +- `k8s_container_id` +- `k8s_container_name` +- `k8s_controller_kind` +- `k8s_kind` +- `k8s_namespace` +- `k8s_node_name` +- `k8s_pod_name` +- `k8s_pod_uid` + +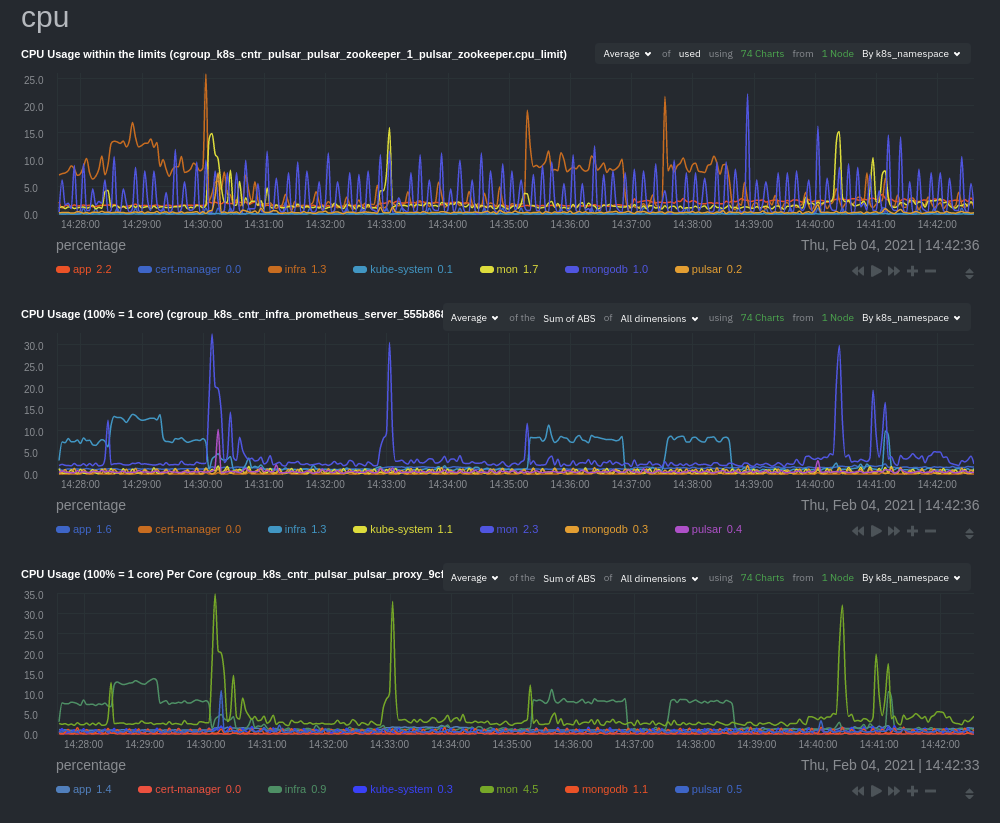 + +In addition, when you hover over a composite chart, the colors in the heat map changes as well, so you can see how +certain pod/container-level metrics change over time. + +## Caveats + +There are some caveats and known issues with Kubernetes monitoring with Netdata Cloud. + +- **No way to remove any nodes** you might have + [drained](https://kubernetes.io/docs/tasks/administer-cluster/safely-drain-node/) from your Kubernetes cluster. These + drained nodes will be marked "unreachable" and will show up in War Room management screens/dropdowns. The same applies + for any ephemeral nodes created and destroyed during horizontal scaling. diff --git a/docs/cloud/visualize/node-filter.md b/docs/cloud/visualize/node-filter.md new file mode 100644 index 00000000..0dd0ef5a --- /dev/null +++ b/docs/cloud/visualize/node-filter.md @@ -0,0 +1,17 @@ +# Node filter + +The node filter allows you to quickly filter the nodes visualized in a War Room's views. It appears on all views, except on single-node dashboards. + +Inside the filter, the nodes get categorized into three groups: + +| Group | Description | +|---------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------| +| Live | Nodes that are currently online, collecting and streaming metrics to Cloud. Live nodes display raised [Alert](https://github.com/netdata/netdata/blob/master/docs/monitor/view-active-alerts.md) counters, [Machine Learning](https://github.com/netdata/netdata/blob/master/ml/README.md) availability, and [Functions](https://github.com/netdata/netdata/blob/master/docs/cloud/netdata-functions.md) availability | +| Stale | Nodes that are offline and not streaming metrics to Cloud. Only historical data can be presented from a parent node. For these nodes you can only see their ML status, as they are not online to provide more information | +| Offline | Nodes that are offline, not streaming metrics to Cloud and not available in any parent node. Offline nodes are automatically deleted after 30 days and can also be deleted manually. | + +By using the search bar, you can narrow down to specific nodes based on their name. + +When you select one or more nodes, the total selected number will appear in the **Nodes** bar on the **Selected** field. + + diff --git a/docs/cloud/visualize/nodes.md b/docs/cloud/visualize/nodes.md new file mode 100644 index 00000000..3ecf76ca --- /dev/null +++ b/docs/cloud/visualize/nodes.md @@ -0,0 +1,39 @@ +# Nodes tab + +The Nodes tab lets you see and customize key metrics from any number of Agent-monitored nodes and seamlessly navigate +to any node's dashboard for troubleshooting performance issues or anomalies using Netdata's highly-granular metrics. + + + +Each War Room's Nodes tab is populated based on the nodes you added to that specific War Room. Each node occupies a +single row, first featuring that node's alert status (yellow for warnings, red for critical alerts) and operating +system, some essential information about the node, followed by columns of user-defined key metrics represented in +real-time charts. + +Use the [Overview](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/overview.md) for monitoring an infrastructure in real time using +composite charts and Netdata's familiar dashboard UI. + +Check the [node +filter](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/node-filter.md) and the [Visualization date time controls +selector](https://github.com/netdata/netdata/blob/master/docs/dashboard/visualization-date-and-time-controls.md) for tools available on the utility bar. + +## Add and customize metrics columns + +Add more metrics columns by clicking the gear icon. Choose the context you'd like to add, give it a relevant name, and +select whether you want to see all dimensions (the default), or only the specific dimensions your team is interested in. + +Click the gear icon and hover over any existing charts, then click the pencil icon. This opens a panel to +edit that chart. Edit the context, its title, add or remove dimensions, or delete the chart altogether. + +These customizations appear for anyone else with access to that War Room. + +## See more metrics in Netdata Cloud + +If you want to add more metrics to your War Rooms and they don't show up when you add new metrics to Nodes, you likely +need to configure those nodes to collect from additional data sources. See our [collectors configuration reference](https://github.com/netdata/netdata/blob/master/collectors/REFERENCE.md) +to learn how to use dozens of pre-installed collectors that can instantly collect from your favorite services and applications. + +If you want to see up to 30 days of historical metrics in Cloud (and more on individual node dashboards), read about [changing how long Netdata stores metrics](https://github.com/netdata/netdata/blob/master/docs/store/change-metrics-storage.md). Also, see our +[calculator](https://github.com/netdata/netdata/blob/master/docs/store/change-metrics-storage.md#calculate-the-system-resources-ram-disk-space-needed-to-store-metrics) +for finding the disk and RAM you need to store metrics for a certain period of time. diff --git a/docs/cloud/visualize/overview.md b/docs/cloud/visualize/overview.md new file mode 100644 index 00000000..84638f05 --- /dev/null +++ b/docs/cloud/visualize/overview.md @@ -0,0 +1,48 @@ +# Home, overview and single node tabs + +Learn how to use the Home, Overview, and Single Node tabs in Netdata Cloud, to explore your infrastructure and troubleshoot issues. + +## Home + +The Home tab provides a predefined dashboard of relevant information about entities in the War Room. + +This tab will automatically present summarized information in an easily digestible display. You can see information about your +nodes, data collection and retention stats, alerts, users and dashboards. + +## Overview and single node tab + +The Overview tab is another great way to monitor infrastructure using Netdata Cloud. While the interface might look +similar to local dashboards served by an Agent Overview uses **composite charts**. +These charts display real-time aggregated metrics from all the nodes (or a filtered selection) in a given War Room. + +When you [interact with composite charts](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/interact-new-charts.md) +you can see your infrastructure from a single pane of glass, discover trends or anomalies, and perform root cause analysis. + +The Single Node tab dashboard is exactly the same as the Overview, but with a hard-coded filter to only show a single node. + +### Chart navigation Menu + +Netdata Cloud uses a similar menu to local Agent dashboards, with sections +and sub-menus aggregated from every contributing node. For example, even if only two nodes actively collect from and +monitor an Apache web server, the **Apache** section still appears and displays composite charts from those two nodes. + + + +One difference between the Netdata Cloud menu and those found in local Agent dashboards is that +the Overview condenses multiple services, families, or instances into single sections, sub-menus, and associated charts. + +For services, let's say you have two concurrent jobs with the [web_log collector](https://github.com/netdata/go.d.plugin/blob/master/modules/weblog/README.md), one for Apache and another for Nginx. +A single-node or local dashboard shows two section, **web_log apache** and **web_log nginx**, whereas the Overview condenses these into a +single **web_log** section containing composite charts from both jobs. + +The Cloud also condenses multiple families or multiple instances into a single **all** sub-menu and associated charts. +For example, if Node A has 5 disks, and Node B has 3, each disk contributes to a single `disk.io` composite chart. +The utility bar should show that there are 8 charts from 2 nodes contributing to that chart. +The aggregation applies to disks, network devices, and other metric types that involve multiple instances of a piece of hardware or software. + +## Persistence of composite chart settings + +Of course you can [change the filtering or grouping](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/interact-new-charts.md) of metrics in the composite charts that aggregate all these instances, to see only the information you are interested in, and save that tab in a custom dashboard. + +When you change a composite chart via its definition bar, Netdata Cloud persists these settings in a query string attached to the URL in your browser. +You can "save" these settings by bookmarking this particular URL, or share it with colleagues by having them copy-paste it into their browser. diff --git a/docs/collect/application-metrics.md b/docs/collect/application-metrics.md new file mode 100644 index 00000000..ec73cefe --- /dev/null +++ b/docs/collect/application-metrics.md @@ -0,0 +1,83 @@ +<!-- +title: "Collect application metrics with Netdata" +sidebar_label: "Application metrics" +description: "Monitor and troubleshoot every application on your infrastructure with per-second metrics, zero configuration, and meaningful charts." +custom_edit_url: "https://github.com/netdata/netdata/edit/master/docs/collect/application-metrics.md" +learn_status: "Published" +learn_topic_type: "Concepts" +learn_rel_path: "Concepts" +--> + +# Collect application metrics with Netdata + +Netdata instantly collects per-second metrics from many different types of applications running on your systems, such as +web servers, databases, message brokers, email servers, search platforms, and much more. Metrics collectors are +pre-installed with every Netdata Agent and usually require zero configuration. Netdata also collects and visualizes +resource utilization per application on Linux systems using `apps.plugin`. + +[**apps.plugin**](https://github.com/netdata/netdata/blob/master/collectors/apps.plugin/README.md) looks at the Linux process tree every second, much like `top` or +`ps fax`, and collects resource utilization information on every running process. By reading the process tree, Netdata +shows CPU, disk, networking, processes, and eBPF for every application or Linux user. Unlike `top` or `ps fax`, Netdata +adds a layer of meaningful visualization on top of the process tree metrics, such as grouping applications into useful +dimensions, and then creates per-application charts under the **Applications** section of a Netdata dashboard, per-user +charts under **Users**, and per-user group charts under **User Groups**. + +Our most popular application collectors: + +- [Prometheus endpoints](https://github.com/netdata/go.d.plugin/blob/master/modules/prometheus/README.md): Gathers + metrics from one or more Prometheus endpoints that use the OpenMetrics exposition format. Auto-detects more than 600 + endpoints. +- [Web server logs (Apache, NGINX)](https://github.com/netdata/go.d.plugin/blob/master/modules/weblog/README.md): + Tail access logs and provide very detailed web server performance statistics. This module is able to parse 200k+ + rows in less than half a second. +- [MySQL](https://github.com/netdata/go.d.plugin/blob/master/modules/mysql/README.md): Collect database global, + replication, and per-user statistics. +- [Redis](https://github.com/netdata/go.d.plugin/blob/master/modules/redis/README.md): Monitor database status by + reading the server's response to the `INFO` command. +- [Apache](https://github.com/netdata/go.d.plugin/blob/master/modules/apache/README.md): Collect Apache web server + performance metrics via the `server-status?auto` endpoint. +- [Nginx](https://github.com/netdata/go.d.plugin/blob/master/modules/nginx/README.md): Monitor web server status + information by gathering metrics via `ngx_http_stub_status_module`. +- [Postgres](https://github.com/netdata/go.d.plugin/blob/master/modules/postgres/README.md): Collect database health + and performance metrics. +- [ElasticSearch](https://github.com/netdata/go.d.plugin/blob/master/modules/elasticsearch/README.md): Collect search + engine performance and health statistics. Optionally collects per-index metrics. +- [PHP-FPM](https://github.com/netdata/go.d.plugin/blob/master/modules/phpfpm/README.md): Collect application summary + and processes health metrics by scraping the status page (`/status?full`). + +Our [supported collectors list](https://github.com/netdata/netdata/blob/master/collectors/COLLECTORS.md#service-and-application-collectors) shows all Netdata's +application metrics collectors, including those for containers/k8s clusters. + +## Collect metrics from applications running on Windows + +Netdata is fully capable of collecting and visualizing metrics from applications running on Windows systems. The only +caveat is that you must [install Netdata](https://github.com/netdata/netdata/blob/master/packaging/installer/README.md) on a separate system or a compatible VM because there +is no native Windows version of the Netdata Agent. + +Once you have Netdata running on that separate system, you can follow the [collectors configuration reference](https://github.com/netdata/netdata/blob/master/collectors/REFERENCE.md) documentation to tell the collector to look for exposed metrics on the Windows system's IP +address or hostname, plus the applicable port. + +For example, you have a MySQL database with a root password of `my-secret-pw` running on a Windows system with the IP +address 203.0.113.0. you can configure the [MySQL +collector](https://github.com/netdata/go.d.plugin/blob/master/modules/mysql/README.md) to look at `203.0.113.0:3306`: + +```yml +jobs: + - name: local + dsn: root:my-secret-pw@tcp(203.0.113.0:3306)/ +``` + +This same logic applies to any application in our [supported collectors +list](https://github.com/netdata/netdata/blob/master/collectors/COLLECTORS.md#service-and-application-collectors) that can run on Windows. + +## What's next? + +If you haven't yet seen the [supported collectors list](https://github.com/netdata/netdata/blob/master/collectors/COLLECTORS.md) give it a once-over for any +additional applications you may want to monitor using Netdata's native collectors, or the [generic Prometheus +collector](https://github.com/netdata/go.d.plugin/blob/master/modules/prometheus/README.md). + +Collecting all the available metrics on your nodes, and across your entire infrastructure, is just one piece of the +puzzle. Next, learn more about Netdata's famous real-time visualizations by [seeing an overview of your +infrastructure](https://github.com/netdata/netdata/blob/master/docs/visualize/overview-infrastructure.md) using Netdata Cloud. + + diff --git a/docs/collect/container-metrics.md b/docs/collect/container-metrics.md new file mode 100644 index 00000000..b5ccca5a --- /dev/null +++ b/docs/collect/container-metrics.md @@ -0,0 +1,101 @@ +<!-- +title: "Collect container metrics with Netdata" +sidebar_label: "Container metrics" +description: "Use Netdata to collect per-second utilization and application-level metrics from Linux/Docker containers and Kubernetes clusters." +custom_edit_url: "https://github.com/netdata/netdata/edit/master/docs/collect/container-metrics.md" +learn_status: "Published" +learn_topic_type: "Concepts" +learn_rel_path: "Concepts" +--> + +# Collect container metrics with Netdata + +Thanks to close integration with Linux cgroups and the virtual files it maintains under `/sys/fs/cgroup`, Netdata can +monitor the health, status, and resource utilization of many different types of Linux containers. + +Netdata uses [cgroups.plugin](https://github.com/netdata/netdata/blob/master/collectors/cgroups.plugin/README.md) to poll `/sys/fs/cgroup` and convert the raw data +into human-readable metrics and meaningful visualizations. Through cgroups, Netdata is compatible with **all Linux +containers**, such as Docker, LXC, LXD, Libvirt, systemd-nspawn, and more. Read more about [Docker-specific +monitoring](#collect-docker-metrics) below. + +Netdata also has robust **Kubernetes monitoring** support thanks to a +[Helmchart](https://github.com/netdata/netdata/blob/master/packaging/installer/methods/kubernetes.md) to automate deployment, collectors for k8s agent services, and +robust [service discovery](https://github.com/netdata/agent-service-discovery/#service-discovery) to monitor the +services running inside of pods in your k8s cluster. Read more about [Kubernetes +monitoring](#collect-kubernetes-metrics) below. + +A handful of additional collectors gather metrics from container-related services, such as +[dockerd](https://github.com/netdata/go.d.plugin/blob/master/modules/docker/README.md) or [Docker +Engine](https://github.com/netdata/go.d.plugin/blob/master/modules/docker_engine/README.md). You can find all +container collectors in our supported collectors list under the +[containers/VMs](https://github.com/netdata/netdata/blob/master/collectors/COLLECTORS.md#containers-and-vms) and +[Kubernetes](https://github.com/netdata/netdata/blob/master/collectors/COLLECTORS.md#containers-and-vms) headings. + +## Collect Docker metrics + +Netdata has robust Docker monitoring thanks to the aforementioned +[cgroups.plugin](https://github.com/netdata/netdata/blob/master/collectors/cgroups.plugin/README.md). By polling cgroups every second, Netdata can produce meaningful +visualizations about the CPU, memory, disk, and network utilization of all running containers on the host system with +zero configuration. + +Netdata also collects metrics from applications running inside of Docker containers. For example, if you create a MySQL +database container using `docker run --name some-mysql -e MYSQL_ROOT_PASSWORD=my-secret-pw -d mysql:tag`, it exposes +metrics on port 3306. You can configure the [MySQL +collector](https://github.com/netdata/go.d.plugin/blob/master/modules/mysql/README.md) to look at `127.0.0.0:3306` for +MySQL metrics: + +```yml +jobs: + - name: local + dsn: root:my-secret-pw@tcp(127.0.0.1:3306)/ +``` + +Netdata then collects metrics from the container itself, but also dozens [MySQL-specific +metrics](https://github.com/netdata/go.d.plugin/blob/master/modules/mysql/README.md#charts) as well. + +### Collect metrics from applications running in Docker containers + +You could use this technique to monitor an entire infrastructure of Docker containers. The same [enable and configure](https://github.com/netdata/netdata/blob/master/collectors/REFERENCE.md) procedures apply whether an application runs on the host system or inside +a container. You may need to configure the target endpoint if it's not the application's default. + +Netdata can even [run in a Docker container](https://github.com/netdata/netdata/blob/master/packaging/docker/README.md) itself, and then collect metrics about the +host system, its own container with cgroups, and any applications you want to monitor. + +See our [application metrics doc](https://github.com/netdata/netdata/blob/master/docs/collect/application-metrics.md) for details about Netdata's application metrics +collection capabilities. + +## Collect Kubernetes metrics + +We already have a few complementary tools and collectors for monitoring the many layers of a Kubernetes cluster, +_entirely for free_. These methods work together to help you troubleshoot performance or availability issues across +your k8s infrastructure. + +- A [Helm chart](https://github.com/netdata/helmchart), which bootstraps a Netdata Agent pod on every node in your + cluster, plus an additional parent pod for storing metrics and managing alert notifications. +- A [service discovery plugin](https://github.com/netdata/agent-service-discovery), which discovers and creates + configuration files for [compatible + applications](https://github.com/netdata/helmchart#service-discovery-and-supported-services) and any endpoints + covered by our [generic Prometheus + collector](https://github.com/netdata/go.d.plugin/blob/master/modules/prometheus/README.md). With these + configuration files, Netdata collects metrics from any compatible applications as they run _inside_ a pod. + Service discovery happens without manual intervention as pods are created, destroyed, or moved between nodes. +- A [Kubelet collector](https://github.com/netdata/go.d.plugin/blob/master/modules/k8s_kubelet/README.md), which runs + on each node in a k8s cluster to monitor the number of pods/containers, the volume of operations on each container, + and more. +- A [kube-proxy collector](https://github.com/netdata/go.d.plugin/blob/master/modules/k8s_kubeproxy/README.md), which + also runs on each node and monitors latency and the volume of HTTP requests to the proxy. +- A [cgroups collector](https://github.com/netdata/netdata/blob/master/collectors/cgroups.plugin/README.md), which collects CPU, memory, and bandwidth metrics for + each container running on your k8s cluster. + +For a holistic view of Netdata's Kubernetes monitoring capabilities, see our guide: [_Monitor a Kubernetes (k8s) cluster +with Netdata_](https://github.com/netdata/netdata/blob/master/docs/guides/monitor/kubernetes-k8s-netdata.md). + +## What's next? + +Netdata is capable of collecting metrics from hundreds of applications, such as web servers, databases, messaging +brokers, and more. See more in the [application metrics doc](https://github.com/netdata/netdata/blob/master/docs/collect/application-metrics.md). + +If you already have all the information you need about collecting metrics, move into Netdata's meaningful visualizations +with [seeing an overview of your infrastructure](https://github.com/netdata/netdata/blob/master/docs/visualize/overview-infrastructure.md) using Netdata Cloud. + + diff --git a/docs/collect/system-metrics.md b/docs/collect/system-metrics.md new file mode 100644 index 00000000..daaf61d7 --- /dev/null +++ b/docs/collect/system-metrics.md @@ -0,0 +1,62 @@ +<!-- +title: "Collect system metrics with Netdata" +sidebar_label: "System metrics" +description: "Netdata collects thousands of metrics from physical and virtual systems, IoT/edge devices, and containers with zero configuration." +custom_edit_url: "https://github.com/netdata/netdata/edit/master/docs/collect/system-metrics.md" +learn_status: "Published" +learn_topic_type: "Concepts" +learn_rel_path: "Concepts" +--> + +# Collect system metrics with Netdata + +Netdata collects thousands of metrics directly from the operating systems of physical and virtual systems, IoT/edge +devices, and [containers](https://github.com/netdata/netdata/blob/master/docs/collect/container-metrics.md) with zero configuration. + +To gather system metrics, Netdata uses roughly a dozen plugins, each of which has one or more collectors for very +specific metrics exposed by the host. The system metrics Netdata users interact with most for health monitoring and +performance troubleshooting are collected and visualized by `proc.plugin`, `cgroups.plugin`, and `ebpf.plugin`. + +[**proc.plugin**](https://github.com/netdata/netdata/blob/master/collectors/proc.plugin/README.md) gathers metrics from the `/proc` and `/sys` folders in Linux +systems, along with a few other endpoints, and is responsible for the bulk of the system metrics collected and +visualized by Netdata. It collects CPU, memory, disks, load, networking, mount points, and more with zero configuration. +It even allows Netdata to monitor its own resource utilization! + +[**cgroups.plugin**](https://github.com/netdata/netdata/blob/master/collectors/cgroups.plugin/README.md) collects rich metrics about containers and virtual machines +using the virtual files under `/sys/fs/cgroup`. By reading cgroups, Netdata can instantly collect resource utilization +metrics for systemd services, all containers (Docker, LXC, LXD, Libvirt, systemd-nspawn), and more. Learn more in the +[collecting container metrics](https://github.com/netdata/netdata/blob/master/docs/collect/container-metrics.md) doc. + +[**ebpf.plugin**](https://github.com/netdata/netdata/blob/master/collectors/ebpf.plugin/README.md): Netdata's extended Berkeley Packet Filter (eBPF) collector +monitors Linux kernel-level metrics for file descriptors, virtual filesystem IO, and process management. You can use our +eBPF collector to analyze how and when a process accesses files, when it makes system calls, whether it leaks memory or +creating zombie processes, and more. + +While the above plugins and associated collectors are the most important for system metrics, there are many others. You +can find all system collectors in our [supported collectors list](https://github.com/netdata/netdata/blob/master/collectors/COLLECTORS.md#system-collectors). + +## Collect Windows system metrics + +Netdata is also capable of monitoring Windows systems. The [Windows +collector](https://github.com/netdata/go.d.plugin/blob/master/modules/windows/README.md) integrates with +[windows_exporter](https://github.com/prometheus-community/windows_exporter), a small Go-based binary that you can run +on Windows systems. The Windows collector then gathers metrics from an endpoint created by windows_exporter, for more +details see [the requirements](https://github.com/netdata/go.d.plugin/blob/master/modules/windows/README.md#requirements). + +Next, [configure](https://github.com/netdata/go.d.plugin/blob/master/modules/windows/README.md#configuration) the Windows +collector to point to the URL and port of your exposed endpoint. Restart Netdata with `sudo systemctl restart netdata`, or the [appropriate +method](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md) for your system. You'll start seeing Windows system metrics, such as CPU +utilization, memory, bandwidth per NIC, number of processes, and much more. + +For information about collecting metrics from applications _running on Windows systems_, see the [application metrics +doc](https://github.com/netdata/netdata/blob/master/docs/collect/application-metrics.md#collect-metrics-from-applications-running-on-windows). + +## What's next? + +Because there's some overlap between system metrics and [container metrics](https://github.com/netdata/netdata/blob/master/docs/collect/container-metrics.md), you +should investigate Netdata's container compatibility if you use them heavily in your infrastructure. + +If you don't use containers, skip ahead to collecting [application metrics](https://github.com/netdata/netdata/blob/master/docs/collect/application-metrics.md) with +Netdata. + + diff --git a/docs/configure/common-changes.md b/docs/configure/common-changes.md new file mode 100644 index 00000000..1c6f6f5a --- /dev/null +++ b/docs/configure/common-changes.md @@ -0,0 +1,159 @@ +<!-- +title: "Common configuration changes" +description: "See the most popular configuration changes to make to the Netdata Agent, including longer metrics retention, reduce sampling, and more." +custom_edit_url: "https://github.com/netdata/netdata/edit/master/docs/configure/common-changes.md" +sidebar_label: "Common configuration changes" +learn_status: "Published" +learn_topic_type: "Tasks" +learn_rel_path: "Configuration" +--> + +# Common configuration changes + +The Netdata Agent requires no configuration upon installation to collect thousands of per-second metrics from most +systems, containers, and applications, but there are hundreds of settings to tweak if you want to exercise more control +over your monitoring platform. + +This document assumes familiarity with +using [`edit-config`](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md) from the Netdata config +directory. + +## Change dashboards and visualizations + +The Netdata Agent's [local dashboard](https://github.com/netdata/netdata/blob/master/docs/category-overview-pages/accessing-netdata-dashboards.md), accessible +at `http://NODE:19999` is highly configurable. If +you use Netdata Cloud +for [infrastructure monitoring](https://github.com/netdata/netdata/blob/master/docs/quickstart/infrastructure.md), you +will see many of these +changes reflected in those visualizations due to the way Netdata Cloud proxies metric data and metadata to your browser. + +### Increase the long-term metrics retention period + +Read our doc +on [increasing long-term metrics storage](https://github.com/netdata/netdata/blob/master/docs/store/change-metrics-storage.md) +for details, including a +[calculator](https://github.com/netdata/netdata/blob/master/docs/store/change-metrics-storage.md#calculate-the-system-resources-ram-disk-space-needed-to-store-metrics) +to help you determine the exact settings for your desired retention period. + +### Reduce the data collection frequency + +Change `update every` in +the [`[global]` section](https://github.com/netdata/netdata/blob/master/daemon/config/README.md#global-section-options) +of `netdata.conf` so +that it is greater than `1`. An `update every` of `5` means the Netdata Agent enforces a _minimum_ collection frequency +of 5 seconds. + +```conf +[global] + update every = 5 +``` + +Every collector and plugin has its own `update every` setting, which you can also change in the `go.d.conf`, +`python.d.conf` or `charts.d.conf` files, or in individual collector configuration files. If the `update +every` for an individual collector is less than the global, the Netdata Agent uses the global setting. See +the [enable or configure a collector](https://github.com/netdata/netdata/blob/master/collectors/REFERENCE.md#enable-and-disable-a-specific-collection-module) +doc for details. + +### Disable a collector or plugin + +Turn off entire plugins in +the [`[plugins]` section](https://github.com/netdata/netdata/blob/master/daemon/config/README.md#plugins-section-options) +of +`netdata.conf`. + +To disable specific collectors, open `go.d.conf`, `python.d.conf` or `charts.d.conf` and find the line +for that specific module. Uncomment the line and change its value to `no`. + +## Modify alerts and notifications + +Netdata's health monitoring watchdog uses hundreds of preconfigured health entities, with intelligent thresholds, to +generate warning and critical alerts for most production systems and their applications without configuration. However, +each alert and notification method is completely customizable. + +### Add a new alert + +To create a new alert configuration file, initiate an empty file, with a filename that ends in `.conf`, in the +`health.d/` directory. The Netdata Agent loads any valid alert configuration file ending in `.conf` in that directory. +Next, edit the new file with `edit-config`. For example, with a file called `example-alert.conf`. + +```bash +sudo touch health.d/example-alert.conf +sudo ./edit-config health.d/example-alert.conf +``` + +Or, append your new alert to an existing file by editing a relevant existing file in the `health.d/` directory. + +Read more about [configuring alerts](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md) to +get started, and see +the [health monitoring reference](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md) for a full listing +of options available in health entities. + +### Configure a specific alert + +Tweak existing alerts by editing files in the `health.d/` directory. For example, edit `health.d/cpu.conf` to change how +the Agent responds to anomalies related to CPU utilization. + +To see which configuration file you need to edit to configure a specific +alert, [view your active alerts](https://github.com/netdata/netdata/blob/master/docs/monitor/view-active-alerts.md) in +Netdata Cloud or the local Agent dashboard and look for the **source** line. For example, it might +read `source 4@/usr/lib/netdata/conf.d/health.d/cpu.conf`. + +Because the source path contains `health.d/cpu.conf`, run `sudo edit-config health.d/cpu.conf` to configure that alert. + +### Disable a specific alert + +Open the configuration file for that alert and set the `to` line to `silent`. + +```conf +template: disk_fill_rate + on: disk.space + lookup: max -1s at -30m unaligned of avail + calc: ($this - $avail) / (30 * 60) + every: 15s + to: silent +``` + +### Turn of all alerts and notifications + +Set `enabled` to `no` in +the [`[health]`](https://github.com/netdata/netdata/blob/master/daemon/config/README.md#health-section-options) +section of `netdata.conf`. + +### Enable alert notifications + +Open `health_alarm_notify.conf` for editing. First, read the [enabling +notifications](https://github.com/netdata/netdata/blob/master/docs/monitor/enable-notifications.md#netdata-agent) doc +for an example of the process using Slack, then +click on the link to your preferred notification method to find documentation for that specific endpoint. + +## Improve node security + +While the Netdata Agent is both [open and secure by design](https://www.netdata.cloud/blog/netdata-agent-dashboard/), we +recommend every user take some action to administer and secure their nodes. + +Learn more about the available options in the [security design documentation](https://github.com/netdata/netdata/blob/master/docs/netdata-security.md). + +## Reduce resource usage + +Read +our [performance optimization guide](https://github.com/netdata/netdata/blob/master/docs/guides/configure/performance.md) +for a long list of specific changes +that can reduce the Netdata Agent's CPU/memory footprint and IO requirements. + +## Organize nodes with host labels + +Beginning with v1.20, Netdata accepts user-defined **host labels**. These labels are sent during streaming, exporting, +and as metadata to Netdata Cloud, and help you organize the metrics coming from complex infrastructure. Host labels are +defined in the section `[host labels]`. + +For a quick introduction, read +the [host label guide](https://github.com/netdata/netdata/blob/master/docs/guides/using-host-labels.md). + +The following restrictions apply to host label names: + +- Names cannot start with `_`, but it can be present in other parts of the name. +- Names only accept alphabet letters, numbers, dots, and dashes. + +The policy for values is more flexible, but you can not use exclamation marks (`!`), whitespaces (` `), single quotes +(`'`), double quotes (`"`), or asterisks (`*`), because they are used to compare label values in health alerts and +templates. diff --git a/docs/configure/nodes.md b/docs/configure/nodes.md new file mode 100644 index 00000000..8fdd1070 --- /dev/null +++ b/docs/configure/nodes.md @@ -0,0 +1,139 @@ +# Configure the Netdata Agent + +Netdata's zero-configuration collection, storage, and visualization features work for many users, infrastructures, and +use cases, but there are some situations where you might want to configure the Netdata Agent running on your node(s), +which can be a physical or virtual machine (VM), container, cloud deployment, or edge/IoT device. + +For example, you might want to increase metrics retention, configure a collector based on your infrastructure's unique +setup, or secure the local dashboard by restricting it to only connections from `localhost`. + +Whatever the reason, Netdata users should know how to configure individual nodes to act decisively if an incident, +anomaly, or change in infrastructure affects how their Agents should perform. + +## The Netdata config directory + +On most Linux systems, using our [recommended one-line +installation](https://github.com/netdata/netdata/blob/master/packaging/installer/README.md#install-on-linux-with-one-line-installer), the **Netdata config +directory** is `/etc/netdata/`. The config directory contains several configuration files with the `.conf` extension, a +few directories, and a shell script named `edit-config`. + +> Some operating systems will use `/opt/netdata/etc/netdata/` as the config directory. If you're not sure where yours +> is, navigate to `http://NODE:19999/netdata.conf` in your browser, replacing `NODE` with the IP address or hostname of +> your node, and find the `# config directory = ` setting. The value listed is the config directory for your system. + +All of Netdata's documentation assumes that your config directory is at `/etc/netdata`, and that you're running any +scripts from inside that directory. + +## Netdata's configuration files + +Upon installation, the Netdata config directory contains a few files and directories. It's okay if you don't see all +these files in your own Netdata config directory, as the next section describes how to edit any that might not already +exist. + +- `netdata.conf` is the main configuration file. This is where you'll find most configuration options. Read descriptions + for each in the [daemon config](https://github.com/netdata/netdata/blob/master/daemon/config/README.md) doc. +- `edit-config` is a shell script used for [editing configuration files](#use-edit-config-to-edit-configuration-files). +- Various configuration files ending in `.conf` for [configuring plugins or + collectors](https://github.com/netdata/netdata/blob/master/collectors/REFERENCE.md) behave. Examples: `go.d.conf`, + `python.d.conf`, and `ebpf.d.conf`. +- Various directories ending in `.d`, which contain other configuration files, each ending in `.conf`, for [configuring + specific collectors](https://github.com/netdata/netdata/blob/master/collectors/REFERENCE.md). +- `apps_groups.conf` is a configuration file for changing how applications/processes are grouped when viewing the + **Application** charts from [`apps.plugin`](https://github.com/netdata/netdata/blob/master/collectors/apps.plugin/README.md) or + [`ebpf.plugin`](https://github.com/netdata/netdata/blob/master/collectors/ebpf.plugin/README.md). +- `health.d/` is a directory that contains [health configuration files](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md). +- `health_alarm_notify.conf` enables and configures [alert notifications](https://github.com/netdata/netdata/blob/master/docs/monitor/enable-notifications.md). +- `statsd.d/` is a directory for configuring Netdata's [statsd collector](https://github.com/netdata/netdata/blob/master/collectors/statsd.plugin/README.md). +- `stream.conf` configures [parent-child streaming](https://github.com/netdata/netdata/blob/master/streaming/README.md) between separate nodes running the Agent. +- `.environment` is a hidden file that describes the environment in which the Netdata Agent is installed, including the + `PATH` and any installation options. Useful for [reinstalling](https://github.com/netdata/netdata/blob/master/packaging/installer/REINSTALL.md) or + [uninstalling](https://github.com/netdata/netdata/blob/master/packaging/installer/UNINSTALL.md) the Agent. + +The Netdata config directory also contains one symlink: + +- `orig` is a symbolic link to the directory `/usr/lib/netdata/conf.d`, which contains stock configuration files. Stock + versions are copied into the config directory when opened with `edit-config`. _Do not edit the files in + `/usr/lib/netdata/conf.d`, as they are overwritten by updates to the Netdata Agent._ + +## Configure a Netdata docker container + +See [configure agent containers](https://github.com/netdata/netdata/blob/master/packaging/docker/README.md#configure-agent-containers). + +## Use `edit-config` to edit configuration files + +The **recommended way to easily and safely edit Netdata's configuration** is with the `edit-config` script. This script +opens existing Netdata configuration files using your system's `$EDITOR`. If the file doesn't yet exist in your config +directory, the script copies the stock version from `/usr/lib/netdata/conf.d` (or wherever the symlink `orig` under the config directory leads to) +to the proper place in the config directory and opens the copy for editing. + +If you have trouble running the script, you can manually copy the file and edit the copy. + +e.g. `cp /usr/lib/netdata/conf.d/go.d/bind.conf /etc/netdata/go.d/bind.conf; vi /etc/netdata/go.d/bind.conf` + +Run `edit-config` without options, to see details on its usage, or `edit-config --list` to see a list of all the configuration +files you can edit. + +```bash +USAGE: + ./edit-config [options] FILENAME + + Copy and edit the stock config file named: FILENAME + if FILENAME is already copied, it will be edited as-is. + + Stock config files at: '/etc/netdata/../../usr/lib/netdata/conf.d' + User config files at: '/etc/netdata' + + The editor to use can be specified either by setting the EDITOR + environment variable, or by using the --editor option. + + The file to edit can also be specified using the --file option. + + For a list of known config files, run './edit-config --list' +``` + +To edit `netdata.conf`, run `./edit-config netdata.conf`. You may need to elevate your privileges with `sudo` or another +method for `edit-config` to write into the config directory. Use your `$EDITOR`, make your changes, and save the file. + +> `edit-config` uses the `EDITOR` environment variable on your system to edit the file. On many systems, that is +> defaulted to `vim` or `nano`. Use `export EDITOR=` to change this temporarily, or edit your shell configuration file +> to change to permanently. + +After you make your changes, you need to [restart the Agent](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md) with `sudo systemctl +restart netdata` or the appropriate method for your system. + +Here's an example of editing the node's hostname, which appears in both the local dashboard and in Netdata Cloud. + + + +### Other configuration files + +You can edit any Netdata configuration file using `edit-config`. A few examples: + +```bash +./edit-config apps_groups.conf +./edit-config ebpf.d.conf +./edit-config health.d/load.conf +./edit-config go.d/prometheus.conf +``` + +The documentation for each of Netdata's components explains which file(s) to edit to achieve the desired behavior. + +## See an Agent's running configuration + +On start, the Netdata Agent daemon attempts to load `netdata.conf`. If that file is missing, incomplete, or contains +invalid settings, the daemon attempts to run sane defaults instead. In other words, the state of `netdata.conf` on your +filesystem may be different from the state of the Netdata Agent itself. + +To see the _running configuration_, navigate to `http://NODE:19999/netdata.conf` in your browser, replacing `NODE` with +the IP address or hostname of your node. The file displayed here is exactly the settings running live in the Netdata +Agent. + +If you're having issues with configuring the Agent, apply the running configuration to `netdata.conf` by downloading the +file to the Netdata config directory. Use `sudo` to elevate privileges. + +```bash +wget -O /etc/netdata/netdata.conf http://localhost:19999/netdata.conf +# or +curl -o /etc/netdata/netdata.conf http://NODE:19999/netdata.conf +``` diff --git a/docs/configure/start-stop-restart.md b/docs/configure/start-stop-restart.md new file mode 100644 index 00000000..45691bc9 --- /dev/null +++ b/docs/configure/start-stop-restart.md @@ -0,0 +1,154 @@ +# Start, stop, or restart the Netdata Agent + +When you install the Netdata Agent, the [daemon](https://github.com/netdata/netdata/blob/master/daemon/README.md) is +configured to start at boot and stop and restart/shutdown. + +You will most often need to _restart_ the Agent to load new or editing configuration files. +[Health configuration](#reload-health-configuration) files are the only exception, as they can be reloaded without restarting +the entire Agent. + +Stopping or restarting the Netdata Agent will cause gaps in stored metrics until the `netdata` process initiates +collectors and the database engine. + +## Using `systemctl`, `service`, or `init.d` + +This is the recommended way to start, stop, or restart the Netdata daemon. + +- To **start** Netdata, run `sudo systemctl start netdata`. +- To **stop** Netdata, run `sudo systemctl stop netdata`. +- To **restart** Netdata, run `sudo systemctl restart netdata`. + +If the above commands fail, or you know that you're using a non-systemd system, try using the `service` command: + +- **service**: `sudo service netdata start`, `sudo service netdata stop`, `sudo service netdata restart` + +## Using `netdata` + +Use the `netdata` command, typically located at `/usr/sbin/netdata`, to start the Netdata daemon. + +```bash +sudo netdata +``` + +If you start the daemon this way, close it with `sudo killall netdata`. + +## Using `netdatacli` + +The Netdata Agent also comes with a [CLI tool](https://github.com/netdata/netdata/blob/master/cli/README.md) capable of performing shutdowns. Start the Agent back up +using your preferred method listed above. + +```bash +sudo netdatacli shutdown-agent +``` + +## Netdata MSI installations + +Netdata provides an installer for Windows using WSL, on those installations by using a Windows terminal (e.g. the Command prompt or Windows Powershell) you can: + +- Start Netdata, by running `start-netdata` +- Stop Netdata, by running `stop-netdata` +- Restart Netdata, by running `restart-netdata` + +## Reload health configuration + +You do not need to restart the Netdata Agent between changes to health configuration files, such as specific health +entities. Instead, use [`netdatacli`](#using-netdatacli) and the `reload-health` option to prevent gaps in metrics +collection. + +```bash +sudo netdatacli reload-health +``` + +If `netdatacli` doesn't work on your system, send a `SIGUSR2` signal to the daemon, which reloads health configuration +without restarting the entire process. + +```bash +killall -USR2 netdata +``` + +## Force stop stalled or unresponsive `netdata` processes + +In rare cases, the Netdata Agent may stall or not properly close sockets, preventing a new process from starting. In +these cases, try the following three commands: + +```bash +sudo systemctl stop netdata +sudo killall netdata +ps aux| grep netdata +``` + +The output of `ps aux` should show no `netdata` or associated processes running. You can now start the Netdata Agent +again with `service netdata start`, or the appropriate method for your system. + +## Starting Netdata at boot + +In the `system` directory you can find scripts and configurations for the +various distros. + +### systemd + +The installer already installs `netdata.service` if it detects a systemd system. + +To install `netdata.service` by hand, run: + +```sh +# stop Netdata +killall netdata + +# copy netdata.service to systemd +cp system/netdata.service /etc/systemd/system/ + +# let systemd know there is a new service +systemctl daemon-reload + +# enable Netdata at boot +systemctl enable netdata + +# start Netdata +systemctl start netdata +``` + +### init.d + +In the system directory you can find `netdata-lsb`. Copy it to the proper place according to your distribution +documentation. For Ubuntu, this can be done via running the following commands as root. + +```sh +# copy the Netdata startup file to /etc/init.d +cp system/netdata-lsb /etc/init.d/netdata + +# make sure it is executable +chmod +x /etc/init.d/netdata + +# enable it +update-rc.d netdata defaults +``` + +### openrc (gentoo) + +In the `system` directory you can find `netdata-openrc`. Copy it to the proper +place according to your distribution documentation. + +### CentOS / Red Hat Enterprise Linux + +For older versions of RHEL/CentOS that don't have systemd, an init script is included in the system directory. This can +be installed by running the following commands as root. + +```sh +# copy the Netdata startup file to /etc/init.d +cp system/netdata-init-d /etc/init.d/netdata + +# make sure it is executable +chmod +x /etc/init.d/netdata + +# enable it +chkconfig --add netdata +``` + +_There have been some recent work on the init script, see PR +<https://github.com/netdata/netdata/pull/403>_ + +### other systems + +You can start Netdata by running it from `/etc/rc.local` or equivalent. + diff --git a/docs/contributing/style-guide.md b/docs/contributing/style-guide.md new file mode 100644 index 00000000..b9dd63b8 --- /dev/null +++ b/docs/contributing/style-guide.md @@ -0,0 +1,486 @@ +# Netdata style guide + +The _Netdata style guide_ establishes editorial guidelines for any writing produced by the Netdata team or the Netdata community, including documentation, articles, in-product UX copy, and more. + +> ### Note +> This document is meant to be accompanied by the [Documentation Guidelines](https://github.com/netdata/netdata/blob/master/docs/guidelines.md). If you want to contribute to Netdata's documentation, please read it too. + +Both internal Netdata teams and external contributors to any of Netdata's open-source projects should reference and adhere to this style guide as much as possible. + +Netdata's writing should **empower** and **educate**. You want to help people understand Netdata's value, encourage them to learn more, and ultimately use Netdata's products to democratize monitoring in their organizations. +To achieve these goals, your writing should be: + +- **Clear**. Use simple words and sentences. Use strong, direct, and active language that encourages readers to action. +- **Concise**. Provide solutions and answers as quickly as possible. Give users the information they need right now, + along with opportunities to learn more. +- **Universal**. Think of yourself as a guide giving a tour of Netdata's products, features, and capabilities to a + diverse group of users. Write to reach the widest possible audience. + +You can achieve these goals by reading and adhering to the principles outlined below. + +## Voice and tone + +One way we write empowering, educational content is by using a consistent voice and an appropriate tone. + +_Voice_ is like your personality, which doesn't really change day to day. + +_Tone_ is how you express your personality. Your expression changes based on your attitude or mood, or based on who +you're around. In writing, your reflect tone in your word choice, punctuation, sentence structure, or even the use of +emoji. + +The same idea about voice and tone applies to organizations, too. Our voice shouldn't change much between two pieces of +content, no matter who wrote each, but the tone might be quite different based on who we think is reading. + + +### Voice + +Netdata's voice is authentic, passionate, playful, and respectful. + +- **Authentic** writing is honest and fact-driven. Focus on Netdata's strength while accurately communicating what + Netdata can and cannot do, and emphasize technical accuracy over hard sells and marketing jargon. +- **Passionate** writing is strong and direct. Be a champion for the product or feature you're writing about, and let + your unique personality and writing style shine. +- **Playful** writing is friendly, thoughtful, and engaging. Don't take yourself too seriously, as long as it's not at + the expense of Netdata or any of its users. +- **Respectful** writing treats people the way you want to be treated. Prioritize giving solutions and answers as + quickly as possible. + +### Tone + +Netdata's tone is fun and playful, but clarity and conciseness comes first. We also tend to be informal, and aren't +afraid of a playful joke or two. + +While we have general standards for voice and tone, we do want every individual's unique writing style to reflect in +published content. + +## Universal communication + +Netdata is a global company in every sense, with employees, contributors, and users from around the world. We strive to +communicate in a way that is clear and easily understood by everyone. + +Here are some guidelines, pointers, and questions to be aware of as you write to ensure your writing is universal. Some +of these are expanded into individual sections in +the [language, grammar, and mechanics](#language-grammar-and-mechanics) section below. + +- Would this language make sense to someone who doesn't work here? +- Could someone quickly scan this document and understand the material? +- Create an information hierarchy with key information presented first and clearly called out to improve scannability. +- Avoid directional language like "sidebar on the right of the page" or "header at the top of the page" since + presentation elements may adapt for devices. +- Use descriptive links rather than "click here" or "learn more". +- Include alt text for images and image links. +- Ensure any information contained within a graphic element is also available as plain text. +- Avoid idioms that may not be familiar to the user or that may not make sense when translated. +- Avoid local, cultural, or historical references that may be unfamiliar to users. +- Prioritize active, direct language. +- Avoid referring to someone's age unless it is directly relevant; likewise, avoid referring to people with age-related + descriptors like "young" or "elderly." +- Avoid disability-related idioms like "lame" or "falling on deaf ears." Don't refer to a person's disability unless + it’s directly relevant to what you're writing. +- Don't call groups of people "guys." Don't call women "girls." +- Avoid gendered terms in favor of neutral alternatives, like "server" instead of "waitress" and "businessperson" + instead of "businessman." +- When writing about a person, use their communicated pronouns. When in doubt, just ask or use their name. It's OK to + use "they" as a singular pronoun. + +> Some of these guidelines were adapted from MailChimp under the Creative Commons license. + +## Language, grammar, and mechanics + +To ensure Netdata's writing is clear, concise, and universal, we have established standards for language, grammar, and +certain writing mechanics. However, if you're writing about Netdata for an external publication, such as a guest blog +post, follow that publication's style guide or standards, while keeping +the [preferred spelling of Netdata terms](#netdata-specific-terms) in mind. + +### Active voice + +Active voice is more concise and easier to understand compared to passive voice. When using active voice, the subject of +the sentence is action. In passive voice, the subject is acted upon. A famous example of passive voice is the phrase +"mistakes were made." + +| | | +|-----------------|-------------------------------------------------------------------------------------------| +| Not recommended | When an alert is triggered by a metric, a notification is sent by Netdata. | +| **Recommended** | When a metric triggers an alert, Netdata sends a notification to your preferred endpoint. | + +### Second person + +Use the second person ("you") to give instructions or "talk" directly to users. + +In these situations, avoid "we," "I," "let's," and "us," particularly in documentation. The "you" pronoun can also be +implied, depending on your sentence structure. + +One valid exception is when a member of the Netdata team or community wants to write about said team or community. + +| | | +|--------------------------------|--------------------------------------------------------------| +| Not recommended | To install Netdata, we should try the one-line installer... | +| **Recommended** | To install Netdata, you should try the one-line installer... | +| **Recommended**, implied "you" | To install Netdata, try the one-line installer... | + +### "Easy" or "simple" + +Using words that imply the complexity of a task or feature goes against our policy +of [universal communication](#universal-communication). If you claim that a task is easy and the reader struggles to +complete it, you +may inadvertently discourage them. + +However, if you give users two options and want to relay that one option is genuinely less complex than another, be +specific about how and why. + +For example, don't write, "Netdata's one-line installer is the easiest way to install Netdata." Instead, you might want +to say, "Netdata's one-line installer requires fewer steps than manually installing from source." + +### Slang, metaphors, and jargon + +A particular word, phrase, or metaphor you're familiar with might not translate well to the other cultures featured +among Netdata's global community. We recommended you avoid slang or colloquialisms in your writing. + +In addition, don't use abbreviations that have not yet been defined in the content. See our section on +[abbreviations](#abbreviations-acronyms-and-initialisms) for additional guidance. + +If you must use industry jargon, such as "mean time to resolution," define the term as clearly and concisely as you can. + +> Netdata helps you reduce your organization's mean time to resolution (MTTR), which is the average time the responsible +> team requires to repair a system and resolve an ongoing incident. + +### Spelling + +While the Netdata team is mostly _not_ American, we still aspire to use American spelling whenever possible, as it is +the standard for the monitoring industry. + +See the [word list](#word-list) for spellings of specific words. + +### Capitalization + +Follow the general [English standards](https://owl.purdue.edu/owl/general_writing/mechanics/help_with_capitals.html) for +capitalization. In summary: + +- Capitalize the first word of every new sentence. +- Don't use uppercase for emphasis. (Netdata is the BEST!) +- Capitalize the names of brands, software, products, and companies according to their official guidelines. (Netdata, + Docker, Apache, NGINX) +- Avoid camel case (NetData) or all caps (NETDATA). + +Whenever you refer to the company Netdata, Inc., or the open-source monitoring agent the company develops, capitalize +**Netdata**. + +However, if you are referring to a process, user, or group on a Linux system, use lowercase and fence the word in an +inline code block: `` `netdata` ``. + +| | | +|-----------------|------------------------------------------------------------------------------------------------| +| Not recommended | The netdata agent, which spawns the netdata process, is actively maintained by netdata, inc. | +| **Recommended** | The Netdata Agent, which spawns the `netdata` process, is actively maintained by Netdata, Inc. | + +#### Capitalization of document titles and page headings + +Document titles and page headings should use sentence case. That means you should only capitalize the first word. + +If you need to use the name of a brand, software, product, and company, capitalize it according to their official +guidelines. + +Also, don't put a period (`.`) or colon (`:`) at the end of a title or header. + +| | | +|-----------------|-----------------------------------------------------------------------------------------------------| +| Not recommended | Getting Started Guide <br />Service Discovery and Auto-Detection: <br />Install netdata with docker | +| **Recommended** | Getting started guide <br />Service discovery and auto-detection <br />Install Netdata with Docker | + +### Abbreviations (acronyms and initialisms) + +Use abbreviations (including [acronyms and initialisms](https://www.dictionary.com/e/acronym-vs-abbreviation/)) in +documentation when one exists, when it's widely accepted within the monitoring/sysadmin community, and when it improves +the readability of a document. + +When introducing an abbreviation to a document for the first time, give the reader both the spelled-out version and the +shortened version at the same time. For example: + +> Use Netdata to monitor Extended Berkeley Packet Filter (eBPF) metrics in real-time. + +After you define an abbreviation, don't switch back and forth. Use only the abbreviation for the rest of the document. + +You can also use abbreviations in a document's title to keep the title short and relevant. If you do this, you should +still introduce the spelled-out name alongside the abbreviation as soon as possible. + +### Clause order + +When instructing users to take action, give them the context first. By placing the context in an initial clause at the +beginning of the sentence, users can immediately know if they want to read more, follow a link, or skip ahead. + +| | | +|-----------------|--------------------------------------------------------------------------------| +| Not recommended | Read the reference guide if you'd like to learn more about custom dashboards. | +| **Recommended** | If you'd like to learn more about custom dashboards, read the reference guide. | + +### Oxford comma + +The Oxford comma is the comma used after the second-to-last item in a list of three or more items. It appears just +before "and" or "or." + +| | | +|-----------------|------------------------------------------------------------------------------| +| Not recommended | Netdata can monitor RAM, disk I/O, MySQL queries per second and lm-sensors. | +| **Recommended** | Netdata can monitor RAM, disk I/O, MySQL queries per second, and lm-sensors. | + +### Future releases or features + +Do not mention future releases or upcoming features in writing unless they have been previously communicated via a +public roadmap. + +In particular, documentation must describe, as accurately as possible, the Netdata Agent _as of the [latest +commit](https://github.com/netdata/netdata/commits/master) in the GitHub repository_. For Netdata Cloud, documentation +must reflect the _current state of [production](https://app.netdata.cloud). + +### Informational links + +Every link should clearly state its destination. Don't use words like "here" to describe where a link will take your +reader. + +| | | +|-----------------|-----------------------------------------------------------------------------------------------------------------------------------------| +| Not recommended | To install Netdata, click [here](https://github.com/netdata/netdata/blob/master/packaging/installer/README.md). | +| **Recommended** | To install Netdata, read the [installation instructions](https://github.com/netdata/netdata/blob/master/packaging/installer/README.md). | + +Use links as often as required to provide necessary context. Blog posts and guides require less hyperlinks than +documentation. See the section on [linking between documentation](#linking-between-documentation) for guidance on the +Markdown syntax and path structure of inter-documentation links. + +### Contractions + +Contractions like "you'll" or "they're" are acceptable in most Netdata writing. They're both authentic and playful, and +reinforce the idea that you, as a writer, are guiding users through a particular idea, process, or feature. + +Contractions are generally not used in press releases or other media engagements. + +### Emoji + +Emoji can add fun and character to your writing, but should be used sparingly and only if it matches the content's tone +and desired audience. + +## Technical/Linux standards + +Configuration or maintenance of the Netdata Agent requires some system administration skills, such as navigating +directories, editing files, or starting/stopping/restarting services. Certain processes + +### Switching Linux users + +Netdata documentation often suggests that users switch from their normal user to the `netdata` user to run specific +commands. Use the following command to instruct users to make the switch: + +```bash +sudo su -s /bin/bash netdata +``` + +### Hostname/IP address of a node + +Use `NODE` instead of an actual or example IP address/hostname when referencing the process of navigating to a dashboard +or API endpoint in a browser. + +| | | +|-----------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------| +| Not recommended | Navigate to `http://example.com:19999` in your browser to see Netdata's dashboard. <br />Navigate to `http://203.0.113.0:19999` in your browser to see Netdata's dashboard. | +| **Recommended** | Navigate to `http://NODE:19999` in your browser to see Netdata's dashboard. | + +If you worry that `NODE` doesn't provide enough context for the user, particularly in documentation or guides designed +for beginners, you can provide an explanation: + +> With the Netdata Agent running, visit `http://NODE:19999/api/v1/info` in your browser, replacing `NODE` with the IP +> address or hostname of your Agent. + +### Paths and running commands + +When instructing users to run a Netdata-specific command, don't assume the path to said command, because not every +Netdata Agent installation will have commands under the same paths. When applicable, help them navigate to the correct +path, providing a recommendation or instructions on how to view the running configuration, which includes the correct +paths. + +For example, the [configuration](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md) doc first +teaches users how to find the Netdata config +directory and navigate to it, then runs commands from the `/etc/netdata` path so that the instructions are more +universal. + +Don't include full paths, beginning from the system's root (`/`), as these might not work on certain systems. + +| | | +|-----------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------| +| Not recommended | Use `edit-config` to edit Netdata's configuration: `sudo /etc/netdata/edit-config netdata.conf`. | +| **Recommended** | Use `edit-config` to edit Netdata's configuration by first navigating to your [Netdata config directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md#the-netdata-config-directory), which is typically at `/etc/netdata`, then running `sudo edit-config netdata.conf`. | + +### `sudo` + +Include `sudo` before a command if you believe most Netdata users will need to elevate privileges to run it. This makes +our writing more universal, and users on `sudo`-less systems are generally already aware that they need to run commands +differently. + +For example, most users need to use `sudo` with the `edit-config` script, because the Netdata config directory is owned +by the `netdata` user. Same goes for restarting the Netdata Agent with `systemctl`. + +| | | +|-----------------|----------------------------------------------------------------------------------------------------------------------------------------------| +| Not recommended | Run `edit-config netdata.conf` to configure the Netdata Agent. <br />Run `systemctl restart netdata` to restart the Netdata Agent. | +| **Recommended** | Run `sudo edit-config netdata.conf` to configure the Netdata Agent. <br />Run `sudo systemctl restart netdata` to restart the Netdata Agent. | + +## Markdown syntax + +Netdata's documentation uses Markdown syntax. + +If you're not familiar with Markdown, read the [Mastering +Markdown](https://guides.github.com/features/mastering-markdown/) guide from GitHub for the basics on creating +paragraphs, styled text, lists, tables, and more. + +The following sections describe situations in which a specific syntax is required. + +### Syntax standards (`remark-lint`) + +The Netdata team uses [`remark-lint`](https://github.com/remarkjs/remark-lint) for Markdown code styling. + +- Use a maximum of 120 characters per line. +- Begin headings with hashes, such as `# H1 heading`, `## H2 heading`, and so on. +- Use `_` for italics/emphasis. +- Use `**` for bold. +- Use dashes `-` to begin an unordered list, and put a single space after the dash. +- Tables should be padded so that pipes line up vertically with added whitespace. + +If you want to see all the settings, open the +[`remarkrc.js`](https://github.com/netdata/netdata/blob/master/.remarkrc.js) file in the `netdata/netdata` repository. + +### References to UI elements + +When referencing a user interface (UI) element in Netdata, reference the label text of the link/button with Markdown's +(`**bold text**`) tag. + +```markdown +Click the **Sign in** button. +``` + +Avoid directional language whenever possible. Not every user can use instructions like "look at the top-left corner" to +find their way around an interface, and interfaces often change between devices. If you must use directional language, +try to supplement the text with an [image](#images). + +### Images + +Don't rely on images to convey features, ideas, or instructions. Accompany every image with descriptive alt text. + +In Markdown, use the standard image syntax, `![]()`, and place the alt text between the brackets `[]`. Here's an example +using our logo: + +```markdown + +``` + +Reference in-product text, code samples, and terminal output with actual text content, not screen captures or other +images. Place the text in an appropriate element, such as a blockquote or code block, so all users can parse the +information. + +### Syntax highlighting + +Our documentation site at [learn.netdata.cloud](https://learn.netdata.cloud) uses +[Prism](https://v2.docusaurus.io/docs/markdown-features#syntax-highlighting) for syntax highlighting. Netdata +documentation will use the following for the most part: `c`, `python`, `js`, `shell`, `markdown`, `bash`, `css`, `html`, +and `go`. If no language is specified, Prism tries to guess the language based on its content. + +Include the language directly after the three backticks (```` ``` ````) that start the code block. For highlighting C +code, for example: + +````c +```c +inline char *health_stock_config_dir(void) { + char buffer[FILENAME_MAX + 1]; + snprintfz(buffer, FILENAME_MAX, "%s/health.d", netdata_configured_stock_config_dir); + return config_get(CONFIG_SECTION_DIRECTORIES, "stock health config", buffer); +} +``` +```` + +And the prettified result: + +```c +inline char *health_stock_config_dir(void) { + char buffer[FILENAME_MAX + 1]; + snprintfz(buffer, FILENAME_MAX, "%s/health.d", netdata_configured_stock_config_dir); + return config_get(CONFIG_SECTION_DIRECTORIES, "stock health config", buffer); +} +``` + +Prism also supports titles and line highlighting. See +the [Docusaurus documentation](https://v2.docusaurus.io/docs/markdown-features#code-blocks) for more information. + +### Adding Notes + +Notes inside files should render properly both in GitHub and in Learn, to do that, it is best to use the format listed below: + +``` +> ### Note +> This is an info or a note block. + +> ### Tip, Best Practice +> This is a tip or a best practice block. + +> ### Warning, Caution +> This is a warning or a caution block. +``` + +Which renders into: + + +> ### Note +> This is an info or a note block. + +> ### Tip, Best Practice +> This is a tip or a best practice block. + +> ### Warning, Caution +> This is a warning or a caution block. + +### Tabs + +Docusaurus allows for Tabs to be used, but we have to ensure that a user accessing the file from GitHub doesn't notice any weird artifacts while reading. So, we use tabs only when necessary in this format: + +``` + +<Tabs> +<TabItem value="tab1" label="tab1"> + +<h3> Header for tab1 </h3> + +text for tab1, both visible in GitHub and Docusaurus + + +</TabItem> +<TabItem value="tab2" label="tab2"> + +<h3> Header for tab2 </h3> + +text for tab2, both visible in GitHub and Docusaurus + +</TabItem> +</Tabs> +``` + +## Word list + +The following tables describe the standard spelling, capitalization, and usage of words found in Netdata's writing. + +### Netdata-specific terms + +| Term | Definition | +|-----------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------| +| **claimed node** | A node that you've proved ownership of by completing the [connecting to Cloud process](https://github.com/netdata/netdata/blob/master/claim/README.md). The claimed node will then appear in your Space and any War Rooms you added it to. | +| **Netdata** | The company behind the open-source Netdata Agent and the Netdata Cloud web application. Never use _netdata_ or _NetData_. <br /><br />In general, focus on the user's goals, actions, and solutions rather than what the company provides. For example, write _Learn more about enabling alert notifications on your preferred platforms_ instead of _Netdata sends alert notifications to your preferred platforms_. | +| **Netdata Agent** | The free and open source [monitoring agent](https://github.com/netdata/netdata) that you can install on all of your distributed systems, whether they're physical, virtual, containerized, ephemeral, and more. The Agent monitors systems running Linux, Docker, Kubernetes, macOS, FreeBSD, and more, and collects metrics from hundreds of popular services and applications. | +| **Netdata Cloud** | The web application hosted at [https://app.netdata.cloud](https://app.netdata.cloud) that helps you monitor an entire infrastructure of distributed systems in real time. <br /><br />Never use _Cloud_ without the preceding _Netdata_ to avoid ambiguity. | +| **Netdata community forum** | The Discourse-powered forum for feature requests, Netdata Cloud technical support, and conversations about Netdata's monitoring and troubleshooting products. | +| **node** | A system on which the Netdata Agent is installed. The system can be physical, virtual, in a Docker container, and more. Depending on your infrastructure, you may have one, dozens, or hundreds of nodes. Some nodes are _ephemeral_, in that they're created/destroyed automatically by an orchestrator service. | +| **Space** | The highest level container within Netdata Cloud for a user to organize their team members and nodes within their infrastructure. A Space likely represents an entire organization or a large team. <br /><br />_Space_ is always capitalized. | +| **unreachable node** | A connected node with a disrupted [Agent-Cloud link](https://github.com/netdata/netdata/blob/master/aclk/README.md). Unreachable could mean the node no longer exists or is experiencing network connectivity issues with Cloud. | +| **visited node** | A node which has had its Agent dashboard directly visited by a user. A list of these is maintained on a per-user basis. | +| **War Room** | A smaller grouping of nodes where users can view key metrics in real-time and monitor the health of many nodes with their alert status. War Rooms can be used to organize nodes in any way that makes sense for your infrastructure, such as by a service, purpose, physical location, and more. <br /><br />_War Room_ is always capitalized. | + +### Other technical terms + +| Term | Definition | +|-----------------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------| +| **filesystem** | Use instead of _file system_. | +| **preconfigured** | The concept that many of Netdata's features come with sane defaults that users don't need to configure to find immediate value. | +| **real time**/**real-time** | Use _real time_ as a noun phrase, most often with _in_: _Netdata collects metrics in real time_. Use _real-time_ as an adjective: _Netdata collects real-time metrics from hundreds of supported applications and services. | diff --git a/docs/dashboard/customize.md b/docs/dashboard/customize.md new file mode 100644 index 00000000..301f0bd6 --- /dev/null +++ b/docs/dashboard/customize.md @@ -0,0 +1,76 @@ +# Customize the standard dashboard + +> ### Disclaimer +> +> This document is only applicable to the v1 version of the dashboard and doesn't affect the [Netdata Dashboard](https://github.com/netdata/netdata/blob/master/docs/category-overview-pages/accessing-netdata-dashboards.md). + +While the [Netdata dashboard](https://github.com/netdata/netdata/blob/master/web/gui/README.md) comes preconfigured with hundreds of charts and +thousands of metrics, you may want to alter your experience based on a particular use case or preferences. + +## Dashboard settings + +To change dashboard settings, click the on the **settings** icon + +in the top panel. + +These settings only affect how the dashboard behaves in your browser. They take effect immediately and are permanently +saved to browser local storage (except the refresh on focus / always option). Some settings are applied immediately, and +others are only reflected after the dashboard is refreshed, which happens automatically. + +Here are a few popular settings: + +### Change chart legend position + +Find this setting under the **Visual** tab. By default, Netdata places the +[legend of dimensions](https://github.com/netdata/netdata/blob/master/docs/dashboard/dimensions-contexts-families.md#dimension) _below_ charts. +Click this toggle to move the legend to the _right_ of charts. + + +### Change theme + +Find this setting under the **Visual** tab. Choose between Dark (the default) and White. + +## Customize the standard dashboard info + +Netdata stores information about individual charts in the `dashboard_info.js` file. This file includes section and +subsection headings, descriptions, colors, titles, tooltips, and other information for Netdata to render on the +dashboard. + +One common use case for customizing the standard dashboard is adding internal "documentation" a section or specific +chart that can then be read by anyone with access to that dashboard. + +For example, here is how `dashboard_info.js` defines the **System Overview** section. + +```javascript +netdataDashboard.menu = { + 'system': { + title: 'System Overview', + icon: '<i class="fas fa-bookmark"></i>', + info: 'Overview of the key system metrics.' + }, +``` + +If you want to customize this information, use the example `dashboard_info_custom_example.js` as a starting point. +First, navigate to the web server's directory. If you're on a Linux system, this should be at `/usr/share/netdata/web/`. +Copy the example file, then ensure that its permissions match the rest of the web server, which is `netdata:netdata` by +default. + +```bash +cd /usr/share/netdata/web/ +sudo cp dashboard_info_custom_example.js your_dashboard_info_file.js +sudo chown netdata:netdata your_dashboard_info_file.js +``` + +Edit the file with customizations to the `title`, `icon`, and `info` fields. Replace the string after `fas fa-` with any +icon from [Font Awesome](https://fontawesome.com/cheatsheet) to customize the icons that appear throughout the +dashboard. + +Save the file, then navigate to your [Netdata config directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md) to edit `netdata.conf`. Add +the following line to the `[web]` section to tell Netdata where to find your custom configuration. + +```conf +[web] + custom dashboard_info.js = your_dashboard_info_file.js +``` + +Reload your browser tab to see your custom configuration.
\ No newline at end of file diff --git a/docs/dashboard/import-export-print-snapshot.md b/docs/dashboard/import-export-print-snapshot.md new file mode 100644 index 00000000..5a05f51e --- /dev/null +++ b/docs/dashboard/import-export-print-snapshot.md @@ -0,0 +1,74 @@ +<!-- +title: "Import, export, and print a snapshot" +description: >- + "Snapshots can be incredibly useful for diagnosing anomalies after + they've already happened, and are interoperable with any other node + running Netdata." +type: "how-to" +custom_edit_url: "https://github.com/netdata/netdata/blob/master/docs/dashboard/import-export-print-snapshot.md" +sidebar_label: "Import, export, and print a snapshot" +learn_status: "Published" +learn_topic_type: "Tasks" +learn_rel_path: "Operations" +--> + +# Import, export, and print a snapshot + +Netdata can export snapshots of the contents of your dashboard at a given time, which you can then import into any other +node running Netdata. Or, you can create a print-ready version of your dashboard to save to PDF or actually print to +paper. + +Snapshots can be incredibly useful for diagnosing anomalies after they've already happened. Let's say Netdata triggered a warning alert while you were asleep. In the morning, you can [select the +timeframe](https://github.com/netdata/netdata/blob/master/docs/dashboard/visualization-date-and-time-controls.md) when the alert triggered, export a snapshot, and send it to a + +colleague for further analysis. + +Or, send the Netdata team a snapshot of your dashboard when [filing a bug +report](https://github.com/netdata/netdata/issues/new?assignees=&labels=bug%2Cneeds+triage&template=BUG_REPORT.yml) on +GitHub. + + + +## Import a snapshot + +To import a snapshot, click on the **import** icon  +in the top panel. + +Select the Netdata snapshot file to import. Once the file is loaded, the modal updates with information about the +snapshot and the system from which it was taken. Click **Import** to begin to process. + +Netdata takes the data embedded inside the snapshot and re-creates a static replica on your dashboard. When the import +finishes, you're free to move around and examine the charts. + +Some caveats and tips to keep in mind: + +- Only metrics in the export timeframe are available to you. If you zoom out or pan through time, you'll see the + beginning and end of the snapshot. +- Charts won't update with new information, as you're looking at a static replica, not the live dashboard. +- The import is only temporary. Reload your browser tab to return to your node's real-time dashboard. + +## Export a snapshot + +To export a snapshot, first pan/zoom any chart to an appropriate _visible timeframe_. The export snapshot will only +contain the metrics you see in charts, so choose the most relevant timeframe. + +Next, click on the **export** icon  +in the top panel. + +Select the metrics resolution to export. The default is 1-second, equal to how often Netdata collects and stores +metrics. Lowering the resolution will reduce the number of data points, and thus the snapshot's overall size. + +Edit the snapshot file name and select your desired compression method. Click on **Export**. When the export is +complete, your browser will prompt you to save the `.snapshot` file to your machine. + +## Print a snapshot + +To print a snapshot, click on the **print** icon  +in the top panel. + +When you click **Print**, Netdata opens a new window to render every chart. This might take some time. When finished, +Netdata opens a browser print dialog for you to save to PDF or print. diff --git a/docs/dashboard/visualization-date-and-time-controls.md b/docs/dashboard/visualization-date-and-time-controls.md new file mode 100644 index 00000000..99e4c308 --- /dev/null +++ b/docs/dashboard/visualization-date-and-time-controls.md @@ -0,0 +1,92 @@ +# Visualization date and time controls + +Netdata's dashboard features powerful date visualization controls that include a time control, a timezone selector and a rich date and timeframe selector. + +The controls come with useful defaults and rich customization, to help you narrow your focus when troubleshooting issues or anomalies. + +## Time controls + +The time control provides you the following options: **Play**, **Pause** and **Force Play**. + +- **Play** - the content of the page will be automatically refreshed while this is in the foreground +- **Pause** - the content of the page isn't refreshed due to a manual request to pause it or, for example, when your investigating data on a chart (cursor is on top of a chart) +- **Force Play** - the content of the page will be automatically refreshed even if this is in the background + +With this, we aim to bring more clarity and allow you to distinguish if the content you are looking at is live or historical and also allow you to always refresh the content of the page when the tabs are in the background. + +Main use cases for **Force Play**: + +- You use a terminal or deployment tools to do changes in your infra and want to see the effect immediately, Netdata is in the background, displaying the impact of these changes +- You want to have Netdata on the background, example displayed on a TV, to constantly see metrics through dashboards or to watch the alert status + + + +## Date and time selector + +The date and time selector allows you to change the visible timeframe and change the timezone used in the interface. + +### Pick timeframes to visualize + +While [panning through time and zooming in/out](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/interact-new-charts.md) from charts it is helpful when you're looking a recent history, or want to do granular troubleshooting, what if you want to see metrics from 6 hours ago? Or 6 days? + +Netdata's dashboard features a **timeframe selector** to help you visualize specific timeframes in a few helpful ways. +By default, it shows a certain number of minutes of historical metrics based on the your browser's viewport to ensure it's always showing per-second granularity. + +#### Open the timeframe selector + +To visualize a new timeframe, you need to open the picker, which appears just above the menu, near the top-right bar of the dashboard. + + + +The **Clear** button resets the dashboard back to its default state based on your browser viewport, and **Apply** closes +the picker and shifts all charts to the selected timeframe. + +#### Use the pre-defined timeframes + +Click any of the following options in the predefined timeframe column to choose between: + +- Last 5 minutes +- Last 15 minutes +- Last 30 minutes +- Last hour +- Last 2 hours +- Last 6 hours +- Last 12 hours +- Last day +- Last 2 days +- Last 7 days + +Click **Apply** to see metrics from your selected timeframe. + +#### Choose a specific interval + +Beneath the predefined timeframe columns is an input field and dropdown you use in combination to select a specific timeframe of +minutes, hours, days, or months. Enter a number and choose the appropriate unit of time, then click **Apply**. + +#### Choose multiple days via the calendar + +Use the calendar to select multiple days. Click on a date to begin the timeframe selection, then an ending date. The +timeframe begins at noon on the beginning and end dates. Click **Apply** to see your selected multi-day timeframe. + +#### Caveats and considerations + +**Longer timeframes will decrease metrics granularity**. At the default timeframe, based on your browser viewport, each +"tick" on charts represents one second. If you select a timeframe of 6 hours, each tick represents the _average_ value +across a larger period of time. + +**You can only see metrics as far back in history as your metrics retention policy allows**. Netdata uses an internal +time-series database (TSDB) to store as many metrics as it can within a specific amount of disk space. The default +storage is 256 MiB, which should be enough for 1-3 days of historical metrics. If you navigate back to a timeframe +beyond stored historical metrics, you'll see this message: + + + +At any time, [configure the internal TSDB's storage capacity](https://github.com/netdata/netdata/blob/master/docs/store/change-metrics-storage.md) to expand your +depth of historical metrics. + +### Timezone selector + +The default timezone used in all date and time fields in Netdata Cloud comes from your browser. To change it, open the +date and time selector and use the control displayed here: + + diff --git a/docs/export/enable-connector.md b/docs/export/enable-connector.md new file mode 100644 index 00000000..02e380e1 --- /dev/null +++ b/docs/export/enable-connector.md @@ -0,0 +1,105 @@ +<!-- +title: "Enable an exporting connector" +description: "Learn how to enable and configure any connector using examples to start exporting metrics to external time-series databases in minutes." +custom_edit_url: "https://github.com/netdata/netdata/edit/master/docs/export/enable-connector.md" +sidebar_label: "Enable an exporting connector" +learn_status: "Published" +learn_topic_type: "Tasks" +learn_rel_path: "Configuration" +--> + +# Enable an exporting connector + +Now that you found the right connector for your [external time-series +database](https://github.com/netdata/netdata/blob/master/docs/export/external-databases.md#supported-databases), you can now enable the exporting engine and the +connector itself. We'll walk through the process of enabling the exporting engine itself, followed by two examples using +the OpenTSDB and Graphite connectors. + +> When you enable the exporting engine and a connector, the Netdata Agent exports metrics _beginning from the time you +> restart its process_, not the entire +> [database of long-term metrics](https://github.com/netdata/netdata/blob/master/docs/store/change-metrics-storage.md). + +Once you understand the process of enabling a connector, you can translate that knowledge to any other connector. + +## Enable the exporting engine + +Use `edit-config` from your +[Netdata config directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md#the-netdata-config-directory) +to open `exporting.conf`: + +```bash +sudo ./edit-config exporting.conf +``` + +Enable the exporting engine itself by setting `enabled` to `yes`: + +```conf +[exporting:global] + enabled = yes +``` + +Save the file but keep it open, as you will edit it again to enable specific connectors. + +## Example: Enable the OpenTSDB connector + +Use the following configuration as a starting point. Copy and paste it into `exporting.conf`. + +```conf +[opentsdb:http:my_opentsdb_http_instance] + enabled = yes + destination = localhost:4242 +``` + +Replace `my_opentsdb_http_instance` with an instance name of your choice, and change the `destination` setting to the IP +address or hostname of your OpenTSDB database. + +Restart your Agent with `sudo systemctl restart netdata`, or +the [appropriate method](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md) for your system, to begin exporting to your OpenTSDB +database. The +Netdata Agent exports metrics _beginning from the time the process starts_, and because it exports as metrics are +collected, you should start seeing data in your external database after only a few seconds. + +Any further configuration is optional, based on your needs and the configuration of your OpenTSDB database. See the +[OpenTSDB connector doc](https://github.com/netdata/netdata/blob/master/exporting/opentsdb/README.md) +and [exporting engine reference](https://github.com/netdata/netdata/blob/master/exporting/README.md#configuration) for +details. + +## Example: Enable the Graphite connector + +Use the following configuration as a starting point. Copy and paste it into `exporting.conf`. + +```conf +[graphite:my_graphite_instance] + enabled = yes + destination = 203.0.113.0:2003 +``` + +Replace `my_graphite_instance` with an instance name of your choice, and change the `destination` setting to the IP +address or hostname of your Graphite-supported database. + +Restart your Agent with `sudo systemctl restart netdata`, or +the [appropriate method](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md) for your system, to begin exporting to your +Graphite-supported database. +Because the Agent exports metrics as they're collected, you should start seeing data in your external database after +only a few seconds. + +Any further configuration is optional, based on your needs and the configuration of your Graphite-supported database. +See [exporting engine reference](https://github.com/netdata/netdata/blob/master/exporting/README.md#configuration) for +details. + +## What's next? + +If you want to further configure your exporting connectors, see +the [exporting engine reference](https://github.com/netdata/netdata/blob/master/exporting/README.md#configuration). + +For a comprehensive example of using the Graphite connector, read our documentation on +[exporting metrics to Graphite providers](https://github.com/netdata/netdata/blob/master/exporting/graphite/README.md). Or, start +[using host labels](https://github.com/netdata/netdata/blob/master/docs/guides/using-host-labels.md) on exported metrics. + +### Related reference documentation + +- [Exporting engine reference](https://github.com/netdata/netdata/blob/master/exporting/README.md) +- [OpenTSDB connector](https://github.com/netdata/netdata/blob/master/exporting/opentsdb/README.md) +- [Graphite connector](https://github.com/netdata/netdata/blob/master/exporting/graphite/README.md) + + diff --git a/docs/export/external-databases.md b/docs/export/external-databases.md new file mode 100644 index 00000000..715e8660 --- /dev/null +++ b/docs/export/external-databases.md @@ -0,0 +1,77 @@ +<!-- +title: "Export metrics to external time-series databases" +description: "Use the exporting engine to send Netdata metrics to popular external time series databases for long-term storage or further analysis." +custom_edit_url: "https://github.com/netdata/netdata/edit/master/docs/export/external-databases.md" +sidebar_label: "Export metrics to external time-series databases" +learn_status: "Published" +learn_topic_type: "Concepts" +learn_rel_path: "Concepts" +--> + +# Export metrics to external time-series databases + +Netdata allows you to export metrics to external time-series databases with the [exporting +engine](https://github.com/netdata/netdata/blob/master/exporting/README.md). This system uses a number of **connectors** to initiate connections to [more than +thirty](#supported-databases) supported databases, including InfluxDB, Prometheus, Graphite, ElasticSearch, and much +more. + +The exporting engine resamples Netdata's thousands of per-second metrics at a user-configurable interval, and can export +metrics to multiple time-series databases simultaneously. + +Based on your needs and resources you allocated to your external time-series database, you can configure the interval +that metrics are exported or export only certain charts with filtering. You can also choose whether metrics are exported +as-collected, a normalized average, or the sum/volume of metrics values over the configured interval. + +Exporting is an important part of Netdata's effort to be interoperable +with other monitoring software. You can use an external time-series database for long-term metrics retention, further +analysis, or correlation with other tools, such as application tracing. + +## Supported databases + +Netdata supports exporting metrics to the following databases through several +[connectors](https://github.com/netdata/netdata/blob/master/exporting/README.md#features). Once you find the connector that works for your database, open its +documentation and the [enabling a connector](https://github.com/netdata/netdata/blob/master/docs/export/enable-connector.md) doc for details on enabling it. + +- **AppOptics**: [Prometheus remote write](https://github.com/netdata/netdata/blob/master/exporting/prometheus/remote_write/README.md) +- **AWS Kinesis**: [AWS Kinesis Data Streams](https://github.com/netdata/netdata/blob/master/exporting/aws_kinesis/README.md) +- **Azure Data Explorer**: [Prometheus remote write](https://github.com/netdata/netdata/blob/master/exporting/prometheus/remote_write/README.md) +- **Azure Event Hubs**: [Prometheus remote write](https://github.com/netdata/netdata/blob/master/exporting/prometheus/remote_write/README.md) +- **Blueflood**: [Graphite](https://github.com/netdata/netdata/blob/master/exporting/graphite/README.md) +- **Chronix**: [Prometheus remote write](https://github.com/netdata/netdata/blob/master/exporting/prometheus/remote_write/README.md) +- **Cortex**: [Prometheus remote write](https://github.com/netdata/netdata/blob/master/exporting/prometheus/remote_write/README.md) +- **CrateDB**: [Prometheus remote write](https://github.com/netdata/netdata/blob/master/exporting/prometheus/remote_write/README.md) +- **ElasticSearch**: [Graphite](https://github.com/netdata/netdata/blob/master/exporting/graphite/README.md), [Prometheus remote + write](https://github.com/netdata/netdata/blob/master/exporting/prometheus/remote_write/README.md) +- **Gnocchi**: [Prometheus remote write](https://github.com/netdata/netdata/blob/master/exporting/prometheus/remote_write/README.md) +- **Google BigQuery**: [Prometheus remote write](https://github.com/netdata/netdata/blob/master/exporting/prometheus/remote_write/README.md) +- **Google Cloud Pub/Sub**: [Google Cloud Pub/Sub Service](https://github.com/netdata/netdata/blob/master/exporting/pubsub/README.md) +- **Graphite**: [Graphite](https://github.com/netdata/netdata/blob/master/exporting/graphite/README.md), [Prometheus remote + write](https://github.com/netdata/netdata/blob/master/exporting/prometheus/remote_write/README.md) +- **InfluxDB**: [Graphite](https://github.com/netdata/netdata/blob/master/exporting/graphite/README.md), [Prometheus remote + write](https://github.com/netdata/netdata/blob/master/exporting/prometheus/remote_write/README.md) +- **IRONdb**: [Prometheus remote write](https://github.com/netdata/netdata/blob/master/exporting/prometheus/remote_write/README.md) +- **JSON**: [JSON document databases](https://github.com/netdata/netdata/blob/master/exporting/json/README.md) +- **Kafka**: [Prometheus remote write](https://github.com/netdata/netdata/blob/master/exporting/prometheus/remote_write/README.md) +- **KairosDB**: [Graphite](https://github.com/netdata/netdata/blob/master/exporting/graphite/README.md), [OpenTSDB](https://github.com/netdata/netdata/blob/master/exporting/opentsdb/README.md) +- **M3DB**: [Prometheus remote write](https://github.com/netdata/netdata/blob/master/exporting/prometheus/remote_write/README.md) +- **MetricFire**: [Prometheus remote write](https://github.com/netdata/netdata/blob/master/exporting/prometheus/remote_write/README.md) +- **MongoDB**: [MongoDB](https://github.com/netdata/netdata/blob/master/exporting/mongodb/README.md) +- **New Relic**: [Prometheus remote write](https://github.com/netdata/netdata/blob/master/exporting/prometheus/remote_write/README.md) +- **OpenTSDB**: [OpenTSDB](https://github.com/netdata/netdata/blob/master/exporting/opentsdb/README.md), [Prometheus remote + write](https://github.com/netdata/netdata/blob/master/exporting/prometheus/remote_write/README.md) +- **PostgreSQL**: [Prometheus remote write](https://github.com/netdata/netdata/blob/master/exporting/prometheus/remote_write/README.md) + via [PostgreSQL Prometheus Adapter](https://github.com/CrunchyData/postgresql-prometheus-adapter) +- **Prometheus**: [Prometheus scraper](https://github.com/netdata/netdata/blob/master/exporting/prometheus/README.md) +- **TimescaleDB**: [Prometheus remote write](https://github.com/netdata/netdata/blob/master/exporting/prometheus/remote_write/README.md), + [netdata-timescale-relay](https://github.com/netdata/netdata/blob/master/exporting/TIMESCALE.md) +- **QuasarDB**: [Prometheus remote write](https://github.com/netdata/netdata/blob/master/exporting/prometheus/remote_write/README.md) +- **SignalFx**: [Prometheus remote write](https://github.com/netdata/netdata/blob/master/exporting/prometheus/remote_write/README.md) +- **Splunk**: [Prometheus remote write](https://github.com/netdata/netdata/blob/master/exporting/prometheus/remote_write/README.md) +- **TiKV**: [Prometheus remote write](https://github.com/netdata/netdata/blob/master/exporting/prometheus/remote_write/README.md) +- **Thanos**: [Prometheus remote write](https://github.com/netdata/netdata/blob/master/exporting/prometheus/remote_write/README.md) +- **VictoriaMetrics**: [Prometheus remote write](https://github.com/netdata/netdata/blob/master/exporting/prometheus/remote_write/README.md) +- **Wavefront**: [Prometheus remote write](https://github.com/netdata/netdata/blob/master/exporting/prometheus/remote_write/README.md) + +Can't find your preferred external time-series database? Ask our [community](https://community.netdata.cloud/) for +solutions, or file an [issue on +GitHub](https://github.com/netdata/netdata/issues/new?assignees=&labels=bug%2Cneeds+triage&template=BUG_REPORT.yml). diff --git a/docs/getting-started/introduction.md b/docs/getting-started/introduction.md new file mode 100644 index 00000000..5586bff2 --- /dev/null +++ b/docs/getting-started/introduction.md @@ -0,0 +1,192 @@ +# Getting started with Netdata + +Learn how Netdata can get you monitoring your infrastructure in minutes. + +## What is Netdata ? + +Netdata is designed by system administrators, DevOps engineers, and developers to collect everything, help you visualize +metrics, troubleshoot complex performance problems, and make data interoperable with the rest of your monitoring stack. + +You can install Netdata on most Linux distributions (Ubuntu, Debian, CentOS, and more), container platforms (Kubernetes +clusters, Docker), and many other operating systems (FreeBSD). + +Netdata is: + +### Simple to deploy + +- **One-line deployment** for Linux distributions, plus support for Kubernetes/Docker infrastructures. +- **Zero configuration and maintenance** required to collect thousands of metrics, every second, from the underlying + OS and running applications. +- **Prebuilt charts and alerts** alert you to common anomalies and performance issues without manual configuration. +- **Distributed storage** to simplify the cost and complexity of storing metrics data from any number of nodes. + +### Powerful and scalable + +- **1% CPU utilization, a few MB of RAM, and minimal disk I/O** to run the monitoring Agent on bare metal, virtual + machines, containers, and even IoT devices. +- **Per-second granularity** for an unlimited number of metrics based on the hardware and applications you're running + on your nodes. +- **Interoperable exporters** let you connect Netdata's per-second metrics with an existing monitoring stack and other + time-series databases. + +### Optimized for troubleshooting + +- **Visual anomaly detection** with a UI/UX that emphasizes the relationships between charts. +- **Customizable dashboards** to pinpoint correlated metrics, respond to incidents, and help you streamline your + workflows. +- **Distributed metrics in a centralized interface** to assist users or teams trace complex issues between distributed + nodes. + +### Secure by design + +- **Distributed data architecture** so fast and efficient, there’s no limit to the number of metrics you can follow. +- Because your data is **stored at the edge**, security is ensured. + +### Comparison with other monitoring solutions + +Netdata offers many benefits over the existing monitoring landscape, whether they're expensive SaaS products or other +open-source tools. + +| Netdata | Others (open-source and commercial) | +|:----------------------------------------------------------------|:-----------------------------------------------------------------| +| **High resolution metrics** (1s granularity) | Low resolution metrics (10s granularity at best) | +| Collects **thousands of metrics per node** | Collects just a few metrics | +| Fast UI optimized for **anomaly detection** | UI is good for just an abstract view | +| **Long-term, autonomous storage** at one-second granularity | Centralized metrics in an expensive data lake at 10s granularity | +| **Meaningful presentation**, to help you understand the metrics | You have to know the metrics before you start | +| Install and get results **immediately** | Long sales process and complex installation process | +| Use it for **troubleshooting** performance problems | Only gathers _statistics of past performance_ | +| **Kills the console** for tracing performance issues | The console is always required for troubleshooting | +| Requires **zero dedicated resources** | Require large dedicated resources | + +Netdata works with tons of applications, notifications platforms, and other time-series databases: + +- **300+ system, container, and application endpoints**: Collectors autodetect metrics from default endpoints and + immediately visualize them into meaningful charts designed for troubleshooting. See [everything we + support](https://github.com/netdata/netdata/blob/master/collectors/COLLECTORS.md). +- **20+ notification platforms**: Netdata's health watchdog sends warning and critical alerts to your [favorite + platform](https://github.com/netdata/netdata/blob/master/docs/monitor/enable-notifications.md) to inform you of anomalies just seconds + after they affect your node. +- **30+ external time-series databases**: Export resampled metrics as they're collected to other [local- and + Cloud-based databases](https://github.com/netdata/netdata/blob/master/docs/export/external-databases.md) for best-in-class + interoperability. + +## How it works + +Netdata is a highly efficient, highly modular, metrics management engine. Its lockless design makes it ideal for concurrent operations on the metrics. + +You can see a high level representation in the following diagram. + + + +And a higher level diagram in this one. + + + +You can even visit this slightly dated [interactive infographic](https://my-netdata.io/infographic.html) and get lost in a rabbit hole. + +But the best way to get under the hood or in the steering wheel of our highly efficient, low-latency system (supporting multiple readers and one writer on each metric) is to read the rest of our docs, or just to jump in and [get started](https://github.com/netdata/netdata/blob/master/packaging/installer/README.md). But here's a good breakdown: + +### Netdata Agent + +Netdata's distributed monitoring Agent collects thousands of metrics from systems, hardware, and applications with zero configuration. It runs permanently on all your physical/virtual servers, containers, cloud deployments, and edge/IoT devices. + +You can install Netdata on most Linux distributions (Ubuntu, Debian, CentOS, and more), container/microservice platforms (Kubernetes clusters, Docker), and many other operating systems (FreeBSD, macOS), with no sudo required. + +### Netdata Cloud + +Netdata Cloud is a web application that gives you real-time visibility for your entire infrastructure. With Netdata Cloud, you can view key metrics, insightful charts, and active alerts from all your nodes in a single web interface. When an anomaly strikes, seamlessly navigate to any node to troubleshoot and discover the root cause with the familiar Netdata dashboard. + +Netdata Cloud is free! You can add an entire infrastructure of nodes, invite all your colleagues, and visualize any number of metrics, charts, and alerts entirely for free. + +While Netdata Cloud offers a centralized method of monitoring your Agents, your metrics data is not stored or centralized in any way. Metrics data remains with your nodes and is only streamed to your browser, through Cloud, when you're viewing the Netdata Cloud interface. + +## Use Netdata standalone or as part of your monitoring stack + +Netdata is an extremely powerful monitoring, visualization, and troubleshooting platform. While you can use it as an +effective standalone tool, we also designed it to be open and interoperable with other tools you might already be using. + +Netdata helps you collect everything and scales to infrastructure of any size, but it doesn't lock-in data or force you +to use specific tools or methodologies. Each feature is extensible and interoperable so they can work in parallel with +other tools. For example, you can use Netdata to collect metrics, visualize metrics with a second open-source program, +and centralize your metrics in a cloud-based time-series database solution for long-term storage or further analysis. + +You can build a new monitoring stack, including Netdata, or integrate Netdata's metrics with your existing monitoring +stack. No matter which route you take, Netdata helps you monitor infrastructure of any size. + +Here are a few ways to enrich your existing monitoring and troubleshooting stack with Netdata: + +### Collect metrics from Prometheus endpoints + +Netdata automatically detects 600 popular endpoints and collects per-second metrics from them via the [generic +Prometheus collector](https://github.com/netdata/go.d.plugin/blob/master/modules/prometheus/README.md). This even +includes support for Windows 10 via [`windows_exporter`](https://github.com/prometheus-community/windows_exporter). + +This collector is installed and enabled on all Agent installations by default, so you don't need to waste time +configuring Netdata. Netdata will detect these Prometheus metrics endpoints and collect even more granular metrics than +your existing solutions. You can now use all of Netdata's meaningfully-visualized charts to diagnose issues and +troubleshoot anomalies. + +### Export metrics to external time-series databases + +Netdata can send its per-second metrics to external time-series databases, such as InfluxDB, Prometheus, Graphite, +TimescaleDB, ElasticSearch, AWS Kinesis Data Streams, Google Cloud Pub/Sub Service, and many others. + +Once you have Netdata's metrics in a secondary time-series database, you can use them however you'd like, such as +additional visualization/dashboarding tools or aggregation of data from multiple sources. + +### Visualize metrics with Grafana + +One popular monitoring stack is Netdata, Prometheus, and Grafana. Netdata acts as the stack's metrics collection +powerhouse, Prometheus as the time-series database, and Grafana as the visualization platform. You can also use Grafite instead of Prometheus, +or directly use the [Netdata source plugin for Grafana](https://blog.netdata.cloud/introducing-netdata-source-plugin-for-grafana/) + +Of course, just because you export or visualize metrics elsewhere, it doesn't mean Netdata's equivalent features +disappear. You can always build new dashboards in Netdata Cloud, drill down into per-second metrics using Netdata's +charts, or use Netdata's health watchdog to send notifications whenever an anomaly strikes. + +## Community + +Netdata is an inclusive open-source project and community. Please read our [Code of Conduct](https://github.com/netdata/.github/blob/main/CODE_OF_CONDUCT.md). + +Find most of the Netdata team in our [community forums](https://community.netdata.cloud). It's the best place to +ask questions, find resources, and engage with passionate professionals. The team is also available and active in our [Discord](https://discord.com/invite/mPZ6WZKKG2) too. + +You can also find Netdata on: + +- [Twitter](https://twitter.com/netdatahq) +- [YouTube](https://www.youtube.com/c/Netdata) +- [Reddit](https://www.reddit.com/r/netdata/) +- [LinkedIn](https://www.linkedin.com/company/netdata-cloud/) +- [StackShare](https://stackshare.io/netdata) +- [Product Hunt](https://www.producthunt.com/posts/netdata-monitoring-agent/) +- [Repology](https://repology.org/metapackage/netdata/versions) +- [Facebook](https://www.facebook.com/linuxnetdata/) + +## Contribute + +Contributions are the lifeblood of open-source projects. While we continue to invest in and improve Netdata, we need help to democratize monitoring! + +- Check our [Security Policy](https://github.com/netdata/netdata/security/policy). +- Found a bug? Open a [GitHub issue](https://github.com/netdata/netdata/issues/new?assignees=&labels=bug%2Cneeds+triage&template=BUG_REPORT.yml&title=%5BBug%5D%3A+). +- Read our [Contributing Guide](https://github.com/netdata/.github/blob/main/CONTRIBUTING.md), which contains all the information you need to contribute to Netdata, such as improving our documentation, engaging in the community, and developing new features. We've made it as frictionless as possible, but if you need help, just ping us on our community forums! + +Package maintainers should read the guide on [building Netdata from source](https://github.com/netdata/netdata/blob/master/packaging/installer/methods/source.md) for +instructions on building each Netdata component from source and preparing a package. + +## License + +The Netdata Agent is an open source project distributed under [GPLv3+](https://github.com/netdata/netdata/blob/master/LICENSE). Netdata re-distributes other open-source tools and libraries. Please check the +[third party licenses](https://github.com/netdata/netdata/blob/master/REDISTRIBUTED.md). + +## Is it any good? + +Yes. + +_When people first hear about a new product, they frequently ask if it is any good. A Hacker News user +[remarked](https://news.ycombinator.com/item?id=3067434):_ + +> Note to self: Starting immediately, all raganwald projects will have a “Is it any good?” section in the readme, and +> the answer shall be "yes.". +******************************************************************************* diff --git a/docs/glossary.md b/docs/glossary.md new file mode 100644 index 00000000..26817d42 --- /dev/null +++ b/docs/glossary.md @@ -0,0 +1,180 @@ +# Glossary + +The Netdata community welcomes engineers, SREs, admins, etc. of all levels of expertise with engineering and the Netdata tool. And just as a journey of a thousand miles starts with one step, sometimes, the journey to mastery begins with understanding a single term. + +As such, we want to provide a little Glossary as a reference starting point for new users who might be confused about the Netdata vernacular that more familiar users might take for granted. + +If you're here looking for the definition of a term you heard elsewhere in our community or products, or if you just want to learn Netdata from the ground up, you've come to the right page. + +Use the alphabatized list below to find the answer to your single-term questions, and click the bolded list items to explore more on the topics! We'll be sure to keep constantly updating this list, so if you hear a word that you would like for us to cover, just let us know or submit a request! + +[A](#a) | [B](#b) | [C](#c) | [D](#d)| [E](#e) | [F](#f) | [G](#g) | [H](#h) | [I](#i) | [J](#j) | [K](#k) | [L](#l) | [M](#m) | [N](#n) | [O](#o) | [P](#p) +| [Q](#q) | [R](#r) | [S](#s) | [T](#t) | [U](#u) | [V](#v) | [W](#w) | [X](#x) | [Y](#y) | [Z](#z) + +## A + +- [**Agent** or **Netdata Agent**](https://github.com/netdata/netdata/blob/master/packaging/installer/README.md): Netdata's distributed monitoring Agent collects thousands of metrics from systems, hardware, and applications with zero configuration. It runs permanently on all your physical/virtual servers, containers, cloud deployments, and edge/IoT devices. + +- [**Agent-cloud link** or **ACLK**](https://github.com/netdata/netdata/blob/master/aclk/README.md): The Agent-Cloud link (ACLK) is the mechanism responsible for securely connecting a Netdata Agent to your web browser through Netdata Cloud. + +- [**Aggregate Function**](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/interact-new-charts.md#aggregate-functions-over-time): A function applied When the granularity of the data collected is higher than the plotted points on the chart. + +- [**Alerts** (formerly **Alarms**)](https://github.com/netdata/netdata/blob/master/docs/cloud/alerts-notifications/notifications.md): With the information that appears on Netdata Cloud and the local dashboard about active alerts, you can configure alerts to match your infrastructure's needs or your team's goals. + +- [**Alarm Entity Type**](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md#health-entity-reference): Entity types that are attached to specific charts and use the `alarm` label. + +- [**Anomaly Advisor**](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/anomaly-advisor.md): A Netdata feature that lets you quickly surface potentially anomalous metrics and charts related to a particular highlight window of interest. + +## B + +- [**Bookmarks**](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/organize-your-infrastrucutre-invite-your-team.md#manage-spaces): Netdata Cloud's bookmarks put your tools in one accessible place. Bookmarks are shared between all War Rooms in a Space, so any users in your Space will be able to see and use them. + +## C + +- [**Child**](https://github.com/netdata/netdata/blob/master/docs/metrics-storage-management/enable-streaming.md#streaming-basics): A node, running Netdata, that streams metric data to one or more parent. + +- [**Cloud** or **Netdata Cloud**](https://github.com/netdata/netdata/blob/master/docs/quickstart/infrastructure.md): Netdata Cloud is a web application that gives you real-time visibility for your entire infrastructure. With Netdata Cloud, you can view key metrics, insightful charts, and active alerts from all your nodes in a single web interface. + +- [**Collector**](https://github.com/netdata/netdata/blob/master/collectors/README.md#collector-architecture-and-terminology): A catch-all term for any Netdata process that gathers metrics from an endpoint. + +- [**Community**](https://community.netdata.cloud/): As a company with a passion and genesis in open-source, we are not just very proud of our community, but we consider our users, fans, and chatters to be an imperative part of the Netdata experience and culture. + +- [**Composite Charts**](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/overview.md#overview-and-single-node-view): Charts used by the **Overview** tab which aggregate metrics from all the nodes (or a filtered selection) in a given War Room. + +- [**Context**](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/interact-new-charts.md#contexts): A way of grouping charts by the types of metrics collected and dimensions displayed. It's kind of like a machine-readable naming and organization scheme. + +- [**Custom dashboards**](https://github.com/netdata/netdata/blob/master/web/gui/custom/README.md) A dashboard that you can create using simple HTML (no javascript is required for basic dashboards). + +## D + +- [**Dashboards**](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/dashboards.md): Out-of-the box visual presentation of metrics that allows you to make sense of your infrastructure and its health and performance. + +- [**Definition Bar**](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/interact-new-charts.md): Bar within a composite chart that provides important information and options about the metrics within the chart. + +- [**Dimension**](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/interact-new-charts.md#dimensions): A dimension is a value that gets shown on a chart. + +- [**Distributed Architecture**](https://github.com/netdata/netdata/blob/master/docs/store/distributed-data-architecture.md): The data architecture mindset with which Netdata was built, where all data are collected and stored on the edge, whenever it's possible, creating countless benefits. + +## E + +- [**External Plugins**](https://github.com/netdata/netdata/blob/master/collectors/plugins.d/README.md): These gather metrics from external processes, such as a webserver or database, and run as independent processes that communicate with the Netdata daemon via pipes. + +## F + +- [**Family**](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/interact-new-charts.md#families): 1. What we consider our Netdata community of users and engineers. 2. A single instance of a hardware or software resource that needs to be displayed separately from similar instances. + +- [**Flood Protection**](https://github.com/netdata/netdata/blob/master/docs/cloud/alerts-notifications/notifications.md#flood-protection): If a node has too many state changes like firing too many alerts or going from reachable to unreachable, Netdata Cloud enables flood protection. As long as a node is in flood protection mode, Netdata Cloud does not send notifications about this node + +- [**Functions** or **Netdata Functions**](https://github.com/netdata/netdata/blob/master/docs/cloud/netdata-functions.md): Routines exposed by a collector on the Netdata Agent that can bring additional information to support troubleshooting or trigger some action to happen on the node itself. + +## G + +- [**Guided Troubleshooting**](https://github.com/netdata/netdata/blob/master/docs/category-overview-pages/troubleshooting-overview.md): Troubleshooting with our Machine-Learning-powered tools designed to give you a cutting edge advantage in your troubleshooting battles. + +- [**Group by**](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/interact-new-charts.md#group-by-dimension-node-or-chart): The drop-down on the dimension bar of a composite chart that allows you to group metrics by dimension, node, or chart. + +## H + +- [**Headless Collector Streaming**](https://github.com/netdata/netdata/blob/master/docs/metrics-storage-management/enable-streaming.md#supported-streaming-configurations): Streaming configuration where child `A`, _without_ a database or web dashboard, streams metrics to parent `B`. + +- [**Health Configuration Files**](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md#edit-health-configuration-files): Files that you can edit to configure your Agent's health watchdog service. + +- [**Health Entity Reference**](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md#health-entity-reference): + +- [**Home** tab](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/overview.md#home): Tab in Netdata Cloud that provides a predefined dashboard of relevant information about entities in the War Room. + +## I + +- [**Internal plugins**](https://github.com/netdata/netdata/blob/master/collectors/README.md#collector-architecture-and-terminology): These gather metrics from `/proc`, `/sys`, and other Linux kernel sources. They are written in `C` and run as threads within the Netdata daemon. + +## K + +- [**Kickstart** or **Kickstart Script**](https://github.com/netdata/netdata/blob/master/packaging/installer/methods/kickstart.md): An automatic one-line installation script named 'kickstart.sh' that works on all Linux distributions and macOS. + +- [**Kubernetes Dashboard** or **Kubernetes Tab**](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/kubernetes.md): Netdata Cloud features enhanced visualizations for the resource utilization of Kubernetes (k8s) clusters, embedded in the default Overview dashboard. + +## M + +- [**Metrics Collection**](https://github.com/netdata/netdata/blob/master/collectors/README.md): With zero configuration, Netdata auto-detects thousands of data sources upon starting and immediately collects per-second metrics. Netdata can immediately collect metrics from these endpoints thanks to 300+ collectors, which all come pre-installed when you install Netdata. + +- [**Metric Correlations**](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/metric-correlations.md): A Netdata feature that lets you quickly find metrics and charts related to a particular window of interest that you want to explore further. + +- [**Metrics Exporting**](https://github.com/netdata/netdata/blob/master/docs/export/external-databases.md): Netdata allows you to export metrics to external time-series databases with the exporting engine. This system uses a number of connectors to initiate connections to more than thirty supported databases, including InfluxDB, Prometheus, Graphite, ElasticSearch, and much more. + +- [**Metrics Storage**](https://github.com/netdata/netdata/blob/master/docs/store/change-metrics-storage.md): Upon collection the collected metrics need to be either forwarded, exported or just stored for further treatment. The Agent is capable to store metrics both short and long-term, with or without the usage of non-volatile storage. + +- [**Metrics Streaming Replication**](https://github.com/netdata/netdata/blob/master/docs/metrics-storage-management/enable-streaming.md): Each node running Netdata can stream the metrics it collects, in real time, to another node. Metric streaming allows you to replicate metrics data across multiple nodes, or centralize all your metrics data into a single time-series database (TSDB). + +- [**Module**](https://github.com/netdata/netdata/blob/master/collectors/REFERENCE.md#enable-and-disable-a-specific-collection-module): A type of collector. + +## N + +- [**Netdata**](https://github.com/netdata/netdata/blob/master/docs/getting-started/introduction.md): Netdata is a monitoring tool designed by system administrators, DevOps engineers, and developers to collect everything, help you visualize +metrics, troubleshoot complex performance problems, and make data interoperable with the rest of your monitoring stack. + +- [**Netdata Agent** or **Agent**](https://github.com/netdata/netdata/blob/master/packaging/installer/README.md): Netdata's distributed monitoring Agent collects thousands of metrics from systems, hardware, and applications with zero configuration. It runs permanently on all your physical/virtual servers, containers, cloud deployments, and edge/IoT devices. + +- [**Netdata Cloud** or **Cloud**](https://github.com/netdata/netdata/blob/master/docs/quickstart/infrastructure.md): Netdata Cloud is a web application that gives you real-time visibility for your entire infrastructure. With Netdata Cloud, you can view key metrics, insightful charts, and active alerts from all your nodes in a single web interface. + +- [**Netdata Functions** or **Functions**](https://github.com/netdata/netdata/blob/master/docs/cloud/netdata-functions.md): Routines exposed by a collector on the Netdata Agent that can bring additional information to support troubleshooting or trigger some action to happen on the node itself. + +<!-- No link for this keyword - **Netdata Logs** https://github.com/netdata/netdata/blob/master/docs/tasks/miscellaneous/check-netdata-logs.md: The three log files - `error.log`, `access.log` and `debug.log` - used by Netdata --> + +<!-- Here we need to explain Agent notifications and Cloud notifications, not just "notifications" + +- **Notifications** https://github.com/netdata/netdata/blob/master/docs/concepts/health-monitoring/notifications.md: Netdata can send centralized alert notifications to your team whenever a node enters a warning, critical, or unreachable state. By enabling notifications, you ensure no alert, on any node in your infrastructure, goes unnoticed by you or your team. --> + +## O + +- [**Obsoletion**(of nodes)](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/organize-your-infrastrucutre-invite-your-team.md#obsoleting-offline-nodes-from-a-space): Removing nodes from a space. + +- [**Orchestrators**](https://github.com/netdata/netdata/blob/master/collectors/README.md#collector-architecture-and-terminology): External plugins that run and manage one or more modules. They run as independent processes. + +- [**Overview** tab](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/overview.md#overview-and-single-node-view): Tab in Netdata Cloud that uses composite charts. These charts display real-time aggregated metrics from all the nodes (or a filtered selection) in a given War Room. + +## P + +- [**Parent**](https://github.com/netdata/netdata/blob/master/docs/metrics-storage-management/enable-streaming.md#streaming-basics): A node, running Netdata, that receives streamed metric data. + +- [**Proxy**](https://github.com/netdata/netdata/blob/master/docs/metrics-storage-management/enable-streaming.md#streaming-basics): A node, running Netdata, that receives metric data from a child and "forwards" them on to a separate parent node. + +- [**Proxy Streaming**](https://github.com/netdata/netdata/blob/master/docs/metrics-storage-management/enable-streaming.md#supported-streaming-configurations): Streaming configuration where child `A`, _with or without_ a database, sends metrics to proxy `C`, also _with or without_ a database. `C` sends metrics to parent `B` + +## R + +- [**Registry**](https://github.com/netdata/netdata/blob/master/registry/README.md): Registry that allows Netdata to provide unified cross-server dashboards. + +- [**Replication Streaming**](https://github.com/netdata/netdata/blob/master/streaming/README.md): Streaming configuration where child `A`, _with_ a database and web dashboard, streams metrics to parent `B`. + +- [**Room** or **War Room**](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/organize-your-infrastrucutre-invite-your-team.md#netdata-cloud-war-rooms): War Rooms organize your connected nodes and provide infrastructure-wide dashboards using real-time metrics and visualizations. + +## S + +- [**Single Node Dashboard**](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/overview.md#overview-and-single-node-view): A dashboard pre-configured with every installation of the Netdata agent, with thousand of metrics and hundreds of interactive charts that requires no set up. + +<!-- No link for this file in current structure. - **Snapshots** https://github.com/netdata/netdata/blob/master/docs/tasks/miscellaneous/snapshot-data.md: An image of your dashboard at any given time, whicn can be imiported into any other node running Netdata or used to genereated a PDF file for your records. --> + +- [**Space**](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/organize-your-infrastrucutre-invite-your-team.md#netdata-cloud-spaces): A high-level container and virtual collaboration area where you can organize team members, access levels,and the nodes you want to monitor. + +## T + +- [**Template Entity Type**](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md#entity-types): Entity type that defines rules that apply to all charts of a specific context, and use the template label. Templates help you apply one entity to all disks, all network interfaces, all MySQL databases, and so on. + +- [**Tiers**](https://github.com/netdata/netdata/blob/master/database/engine/README.md#tiers): Tiering is a mechanism of providing multiple tiers of data with different granularity of metrics (the frequency they are collected and stored, i.e. their resolution). + +## U + +- [**Unlimited Scalability**](https://www.netdata.cloud/#:~:text=love%20community%20contributions!-,Infinite%20Scalability,-By%20storing%20data): With Netdata's distributed architecture, you can seamless observe a couple, hundreds or +even thousands of nodes. There are no actual bottlenecks especially if you retain metrics locally in the Agents. + +## V + +- [**Visualizations**](https://github.com/netdata/netdata/blob/master/docs/category-overview-pages/visualizations-overview.md): Netdata uses dimensions, contexts, and families to sort your metric data into graphs, charts, and alerts that maximize your understand of your infrastructure and your ability to troubleshoot it, along or on a team. + +## W + +- [**War Room** or **Room**](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/organize-your-infrastrucutre-invite-your-team.md#netdata-cloud-war-rooms): War Rooms organize your connected nodes and provide infrastructure-wide dashboards using real-time metrics and visualizations. + +## Z + +- [**Zero Configuration**](https://github.com/netdata/netdata/blob/master/docs/getting-started/introduction.md#simple-to-deploy): Netdata is preconfigured and capable to autodetect and monitor any well known application that runs on your system. You just deploy and claim Netdata Agents in your Netdata space, and monitor them in seconds. diff --git a/docs/guidelines.md b/docs/guidelines.md new file mode 100644 index 00000000..e8ff98e4 --- /dev/null +++ b/docs/guidelines.md @@ -0,0 +1,71 @@ +# Contribute to the documentation + +Welcome to our docs developer guidelines! + +This document will guide you to the process of contributing to our docs (**learn.netdata.cloud**) + +## Documentation architecture + +Our documentation in <https://learn.netdata.cloud> is generated by markdown documents in the public Github repositories of the "netdata" organization. + +The structure of the documentation is handled by a [map](https://github.com/netdata/learn/blob/master/map.tsv) file, that contains metadata for every markdown files in the repos we ingest from. + +Then the ingest script parses that map and organizes the markdown files accordingly. + +### Improve existing documentation + +The easiest way to contribute to Netdata's documentation is to edit a file directly on GitHub. This is perfect for small fixes to a single document, such as fixing a typo or clarifying a confusing sentence. + +Each published document on [Netdata Learn](https://learn.netdata.cloud) includes at the bottom a link to **Edit this page**. +Clicking on that link is the recommended way to improve our documentation, as it leads you directly to GitHub's code editor. +Make your suggested changes, and use the ***Preview changes*** button to ensure your Markdown syntax works as expected. + +Under the **Commit changes** header, write descriptive title for your requested change. Click the **Commit changes** button to initiate your pull request (PR). + +Jump down to our instructions on [PRs](#making-a-pull-request) for your next steps. + +### Create a new document + +You can create a pull request to add a completely new markdown document in any of our public repositories. +After the Github pull request is merged, our documentation team will decide where in the documentation hierarchy to publish that document. + +If you wish to contribute documentation that is tailored to your specific infrastructure monitoring/troubleshooting experience, please consider submitting a blog post about your experience. + +Check out our [blog](https://github.com/netdata/blog#readme) repo! Any blog submissions that have widespread or universal application will be integrated into our permanent documentation. + +#### Before you get started + +Anyone interested in contributing significantly to documentation should first read the [Netdata style guide](https://github.com/netdata/netdata/blob/master/docs/contributing/style-guide.md) and the [Netdata Community Code of Conduct](https://github.com/netdata/.github/blob/main/CODE_OF_CONDUCT.md). + +Netdata's documentation uses Markdown syntax. If you're not familiar with Markdown, read the [Mastering Markdown](https://guides.github.com/features/mastering-markdown/) guide from GitHub for the basics on creating paragraphs, styled text, lists, tables, and more. + +#### Edit locally + +Editing documentation locally is the preferred method for completely new documents, or complex changes that span multiple documents. Clone the repository where you wish to make your changes, work on a new branch and create a pull request with that branch. + +### Links to other documents + +Please ensure that any links to a different documentation resource are fully expanded URLs to the relevant markdown document, not links to "learn.netdata.cloud". + +e.g. + +``` +[Correct link to this document](https://github.com/netdata/netdata/blob/master/docs/guidelines.md) +vs +[Incorrect link to this document](https://learn.netdata.cloud/XYZ) +``` + +This permalink ensures that the link will not be broken by any future restructuring in learn.netdata.cloud. + +You can see the URL to the source of any published documentation page in the **Edit this page** link at the bottom. +If you just replace `edit` with `blob` in that URL, you have the permalink to the original markdown document. + +### Making a pull request + +Pull requests (PRs) should be concise and informative. +See our [PR guidelines](https://github.com/netdata/.github/blob/main/CONTRIBUTING.md#pr-guidelines) for specifics. + +The Netdata team will review your PR and assesses it for correctness, conciseness, and overall quality. +We may point to specific sections and ask for additional information or other fixes. + +After merging your PR, the Netdata team rebuilds the [documentation site](https://learn.netdata.cloud) to publish the changed documentation. diff --git a/docs/guides/collect-apache-nginx-web-logs.md b/docs/guides/collect-apache-nginx-web-logs.md new file mode 100644 index 00000000..f5e37442 --- /dev/null +++ b/docs/guides/collect-apache-nginx-web-logs.md @@ -0,0 +1,112 @@ +# Monitor Nginx or Apache web server log files + +Parsing web server log files with Netdata, revealing the volume of redirects, requests and other metrics, can give you a better overview of your infrastructure. + +Too many bad requests? Maybe a recent deploy missed a few small SVG icons. Too many requests? Time to batten down the hatches—it's a DDoS. + +You can use the [LTSV log format](http://ltsv.org/), track TLS and cipher usage, and the whole parser is faster than +ever. In one test on a system with SSD storage, the collector consistently parsed the logs for 200,000 requests in +200ms, using ~30% of a single core. + +The [web_log](https://github.com/netdata/go.d.plugin/blob/master/modules/weblog/README.md) collector is currently compatible +with [Nginx](https://nginx.org/en/) and [Apache](https://httpd.apache.org/). + +This guide will walk you through using the new Go-based web log collector to turn the logs these web servers +constantly write to into real-time insights into your infrastructure. + +## Set up your web servers + +As with all data sources, Netdata can auto-detect Nginx or Apache servers if you installed them using their standard +installation procedures. + +Almost all web server installations will need _no_ configuration to start collecting metrics. As long as your web server +has readable access log file, you can configure the web log plugin to access and parse it. + +## Custom configuration of the web log collector + +The web log collector's default configuration comes with a few example jobs that should cover most Linux distributions +and their default locations for log files: + +```yaml +# [ JOBS ] +jobs: +# NGINX +# debian, arch + - name: nginx + path: /var/log/nginx/access.log + +# gentoo + - name: nginx + path: /var/log/nginx/localhost.access_log + +# APACHE +# debian + - name: apache + path: /var/log/apache2/access.log + +# gentoo + - name: apache + path: /var/log/apache2/access_log + +# arch + - name: apache + path: /var/log/httpd/access_log + +# debian + - name: apache_vhosts + path: /var/log/apache2/other_vhosts_access.log + +# GUNICORN + - name: gunicorn + path: /var/log/gunicorn/access.log + + - name: gunicorn + path: /var/log/gunicorn/gunicorn-access.log +``` + +However, if your log files were not auto-detected, it might be because they are in a different location. Try the default +`web_log.conf` file. + +```bash +./edit-config go.d/web_log.conf +``` + +To create a new custom configuration, you need to set the `path` parameter to point to your web server's access log +file. You can give it a `name` as well, and set the `log_type` to `auto`. + +```yaml +jobs: + - name: example + path: /path/to/file.log + log_type: auto +``` + +Restart Netdata with `sudo systemctl restart netdata`, or the [appropriate +method](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md) for your system. Netdata should pick up your web server's access log and +begin showing real-time charts! + +### Custom log formats and fields + +The web log collector is capable of parsing custom Nginx and Apache log formats and presenting them as charts, but we'll +leave that topic for a separate guide. + +We do have [extensive +documentation](https://github.com/netdata/go.d.plugin/blob/master/modules/weblog/README.md#custom-log-format) on how +to build custom parsing for Nginx and Apache logs. + +## Tweak web log collector alerts + +Over time, we've created some default alerts for web log monitoring. These alerts are designed to work only when your +web server is receiving more than 120 requests per minute. Otherwise, there's simply not enough data to make conclusions +about what is "too few" or "too many." + +- [web log alerts](https://raw.githubusercontent.com/netdata/netdata/master/health/health.d/web_log.conf). + +You can also edit this file directly with `edit-config`: + +```bash +./edit-config health.d/weblog.conf +``` + +For more information about editing the defaults or writing new alert entities, see our +[health monitoring documentation](https://github.com/netdata/netdata/blob/master/health/README.md). diff --git a/docs/guides/collect-unbound-metrics.md b/docs/guides/collect-unbound-metrics.md new file mode 100644 index 00000000..c5f4deb5 --- /dev/null +++ b/docs/guides/collect-unbound-metrics.md @@ -0,0 +1,144 @@ +<!-- +title: "Monitor Unbound DNS servers with Netdata" +sidebar_label: "Monitor Unbound DNS servers with Netdata" +date: 2020-03-31 +custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/guides/collect-unbound-metrics.md +learn_status: "Published" +learn_topic_type: "Tasks" +learn_rel_path: "Miscellaneous" +--> + +# Monitor Unbound DNS servers with Netdata + +[Unbound](https://nlnetlabs.nl/projects/unbound/about/) is a "validating, recursive, caching DNS resolver" from NLNet +Labs. In v1.19 of Netdata, we release a completely refactored collector for collecting real-time metrics from Unbound +servers and displaying them in Netdata dashboards. + +Unbound runs on FreeBSD, OpenBSD, NetBSD, macOS, Linux, and Windows, and supports DNS-over-TLS, which ensures that DNS +queries and answers are all encrypted with TLS. In theory, that should reduce the risk of eavesdropping or +man-in-the-middle attacks when communicating to DNS servers. + +This guide will show you how to collect dozens of essential metrics from your Unbound servers with minimal +configuration. + +## Set up your Unbound installation + +As with all data sources, Netdata can auto-detect Unbound servers if you installed them using the standard installation +procedure. + +Regardless of whether you're connecting to a local or remote Unbound server, you need to be able to access the server's +`remote-control` interface via an IP address, FQDN, or Unix socket. + +To set up the `remote-control` interface, you can use `unbound-control`. First, run `unbound-control-setup` to generate +the TLS key files that will encrypt connections to the remote interface. Then add the following to the end of your +`unbound.conf` configuration file. See the [Unbound +documentation](https://nlnetlabs.nl/documentation/unbound/howto-setup/#setup-remote-control) for more details on using +`unbound-control`, such as how to handle situations when Unbound is run under a unique user. + +```conf +# enable remote-control +remote-control: + control-enable: yes +``` + +Next, make your `unbound.conf`, `unbound_control.key`, and `unbound_control.pem` files readable by Netdata using [access +control lists](https://wiki.archlinux.org/index.php/Access_Control_Lists) (ACL). + +```bash +sudo setfacl -m user:netdata:r unbound.conf +sudo setfacl -m user:netdata:r unbound_control.key +sudo setfacl -m user:netdata:r unbound_control.pem +``` + +Finally, take note whether you're using Unbound in _cumulative_ or _non-cumulative_ mode. This will become relevant when +configuring the collector. + +## Configure the Unbound collector + +You may not need to do any more configuration to have Netdata collect your Unbound metrics. + +If you followed the steps above to enable `remote-control` and make your Unbound files readable by Netdata, that should +be enough. Restart Netdata with `sudo systemctl restart netdata`, or the [appropriate +method](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md) for your system. You should see Unbound metrics in your Netdata +dashboard! + + + +If that failed, you will need to manually configure `unbound.conf`. See the next section for details. + +### Manual setup for a local Unbound server + +To configure Netdata's Unbound collector module, navigate to your Netdata configuration directory (typically at +`/etc/netdata/`) and use `edit-config` to initialize and edit your Unbound configuration file. + +```bash +cd /etc/netdata/ # Replace with your Netdata configuration directory, if not /etc/netdata/ +sudo ./edit-config go.d/unbound.conf +``` + +The file contains all the global and job-related parameters. The `name` setting is required, and two Unbound servers +can't have the same name. + +> It is important you know whether your Unbound server is running in cumulative or non-cumulative mode, as a conflict +> between modes will create incorrect charts. + +Here are two examples for local Unbound servers, which may work based on your unique setup: + +```yaml +jobs: + - name: local + address: 127.0.0.1:8953 + cumulative: no + use_tls: yes + tls_skip_verify: yes + tls_cert: /path/to/unbound_control.pem + tls_key: /path/to/unbound_control.key + + - name: local + address: 127.0.0.1:8953 + cumulative: yes + use_tls: no +``` + +Netdata will attempt to read `unbound.conf` to get the appropriate `address`, `cumulative`, `use_tls`, `tls_cert`, and +`tls_key` parameters. + +Restart Netdata with `sudo systemctl restart netdata`, or the [appropriate +method](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md) for your system. + +### Manual setup for a remote Unbound server + +Collecting metrics from remote Unbound servers requires manual configuration. There are too many possibilities to cover +all remote connections here, but the [default `unbound.conf` +file](https://github.com/netdata/go.d.plugin/blob/master/config/go.d/unbound.conf) contains a few useful examples: + +```yaml +jobs: + - name: remote + address: 203.0.113.10:8953 + use_tls: no + + - name: remote_cumulative + address: 203.0.113.11:8953 + use_tls: no + cumulative: yes + + - name: remote + address: 203.0.113.10:8953 + cumulative: yes + use_tls: yes + tls_cert: /etc/unbound/unbound_control.pem + tls_key: /etc/unbound/unbound_control.key +``` + +To see all the available options, see the default [unbound.conf +file](https://github.com/netdata/go.d.plugin/blob/master/config/go.d/unbound.conf). + +## What's next? + +Now that you're collecting metrics from your Unbound servers, let us know how it's working for you! There's always room +for improvement or refinement based on real-world use cases. Feel free to [file an +issue](https://github.com/netdata/netdata/issues/new?assignees=&labels=bug%2Cneeds+triage&template=BUG_REPORT.yml) with your +thoughts. + + diff --git a/docs/guides/configure/performance.md b/docs/guides/configure/performance.md new file mode 100644 index 00000000..2e5e105f --- /dev/null +++ b/docs/guides/configure/performance.md @@ -0,0 +1,224 @@ +# How to optimize the Netdata Agent's performance + +We designed the Netdata Agent to be incredibly lightweight, even when it's collecting a few thousand dimensions every +second and visualizing that data into hundreds of charts. However, the default settings of the Netdata Agent are not +optimized for performance, but for a simple, standalone setup. We want the first install to give you something you can +run without any configuration. Most of the settings and options are enabled, since we want you to experience the full thing. + +By default, Netdata will automatically detect applications running on the node it is installed to start collecting metrics in +real-time, has health monitoring enabled to evaluate alerts and trains Machine Learning (ML) models for each metric, to detect anomalies. + +This document describes the resources required for the various default capabilities and the strategies to optimize Netdata for production use. + +## Summary of performance optimizations + +The following table summarizes the effect of each optimization on the CPU, RAM and Disk IO utilization in production. + +Optimization | CPU | RAM | Disk IO +-- | -- | -- |-- +[Use streaming and replication](#use-streaming-and-replication) | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: +[Disable unneeded plugins or collectors](#disable-unneeded-plugins-or-collectors) | :heavy_check_mark: | :heavy_check_mark: | :heavy_check_mark: +[Reduce data collection frequency](#reduce-collection-frequency) | :heavy_check_mark: | | :heavy_check_mark: +[Change how long Netdata stores metrics](https://github.com/netdata/netdata/blob/master/docs/store/change-metrics-storage.md) | | :heavy_check_mark: | :heavy_check_mark: +[Use a different metric storage database](https://github.com/netdata/netdata/blob/master/database/README.md) | | :heavy_check_mark: | :heavy_check_mark: +[Disable machine learning](#disable-machine-learning) | :heavy_check_mark: | | +[Use a reverse proxy](#run-netdata-behind-a-proxy) | :heavy_check_mark: | | +[Disable/lower gzip compression for the agent dashboard](#disablelower-gzip-compression-for-the-dashboard) | :heavy_check_mark: | | + +## Resources required by a default Netdata installation + +Netdata's performance is primarily affected by **data collection/retention** and **clients accessing data**. + +You can configure almost all aspects of data collection/retention, and certain aspects of clients accessing data. + +### CPU consumption + +Expect about: + - 1-3% of a single core for the netdata core + - 1-3% of a single core for the various collectors (e.g. go.d.plugin, apps.plugin) + - 5-10% of a single core, when ML training runs + +Your experience may vary depending on the number of metrics collected, the collectors enabled and the specific environment they +run on, i.e. the work they have to do to collect these metrics. + +As a general rule, for modern hardware and VMs, the total CPU consumption of a standalone Netdata installation, including all its components, +should be below 5 - 15% of a single core. For example, on 8 core server it will use only 0.6% - 1.8% of a total CPU capacity, depending on +the CPU characteristics. + +The Netdata Agent runs with the lowest possible [process scheduling policy](https://github.com/netdata/netdata/blob/master/daemon/README.md#netdata-process-scheduling-policy), which is `nice 19`, and uses the `idle` process scheduler. +Together, these settings ensure that the Agent only gets CPU resources when the node has CPU resources to space. If the +node reaches 100% CPU utilization, the Agent is stopped first to ensure your applications get any available resources. + +To reduce CPU usage you can [disable machine learning](#disable-machine-learning), +[use streaming and replication](#use-streaming-and-replication), +[reduce the data collection frequency](#reduce-collection-frequency), [disable unneeded plugins or collectors](#disable-unneeded-plugins-or-collectors), [use a reverse proxy](#run-netdata-behind-a-proxy), and [disable/lower gzip compression for the agent dashboard](#disablelower-gzip-compression-for-the-dashboard). + +### Memory consumption + +The memory footprint of Netdata is mainly influenced by the number of metrics concurrently being collected. Expect about 150MB of RAM for a typical 64-bit server collecting about 2000 to 3000 metrics. + +To estimate and control memory consumption, you can [disable unneeded plugins or collectors](#disable-unneeded-plugins-or-collectors), [change how long Netdata stores metrics](https://github.com/netdata/netdata/blob/master/docs/store/change-metrics-storage.md), or [use a different metric storage database](https://github.com/netdata/netdata/blob/master/database/README.md). + + +### Disk footprint and I/O + +By default, Netdata should not use more than 1GB of disk space, most of which is dedicated for storing metric data and metadata. For typical installations collecting 2000 - 3000 metrics, this storage should provide a few days of high-resolution retention (per second), about a month of mid-resolution retention (per minute) and more than a year of low-resolution retention (per hour). + +Netdata spreads I/O operations across time. For typical standalone installations there should be a few write operations every 5-10 seconds of a few kilobytes each, occasionally up to 1MB. In addition, under heavy load, collectors that require disk I/O may stop and show gaps in charts. + +To configure retention, you can [change how long Netdata stores metrics](https://github.com/netdata/netdata/blob/master/docs/store/change-metrics-storage.md). +To control disk I/O [use a different metric storage database](https://github.com/netdata/netdata/blob/master/database/README.md), avoid querying the +production system [using streaming and replication](#use-streaming-and-replication), [reduce the data collection frequency](#reduce-collection-frequency), and [disable unneeded plugins or collectors](#disable-unneeded-plugins-or-collectors). + +## Use streaming and replication + +For all production environments, parent Netdata nodes outside the production infrastructure should be receiving all +collected data from children Netdata nodes running on the production infrastructure, using [streaming and replication](https://github.com/netdata/netdata/blob/master/docs/metrics-storage-management/enable-streaming.md). + +### Disable health checks on the child nodes + +When you set up streaming, we recommend you run your health checks on the parent. This saves resources on the children +and makes it easier to configure or disable alerts and agent notifications. + +The parents by default run health checks for each child, as long as the child is connected (the details are in `stream.conf`). +On the child nodes you should add to `netdata.conf` the following: + +```conf +[health] + enabled = no +``` + +### Use memory mode ram or save for the child nodes + +See [using a different metric storage database](https://github.com/netdata/netdata/blob/master/database/README.md). + +## Disable unneeded plugins or collectors + +If you know that you don't need an [entire plugin or a specific +collector](https://github.com/netdata/netdata/blob/master/collectors/README.md#collector-architecture-and-terminology), you can disable any of them. +Keep in mind that if a plugin/collector has nothing to do, it simply shuts down and does not consume system resources. +You will only improve the Agent's performance by disabling plugins/collectors that are actively collecting metrics. + +Open `netdata.conf` and scroll down to the `[plugins]` section. To disable any plugin, uncomment it and set the value to +`no`. For example, to explicitly keep the `proc` and `go.d` plugins enabled while disabling `python.d` and `charts.d`. + +```conf +[plugins] + proc = yes + python.d = no + charts.d = no + go.d = yes +``` + +Disable specific collectors by opening their respective plugin configuration files, uncommenting the line for the +collector, and setting its value to `no`. + +```bash +sudo ./edit-config go.d.conf +sudo ./edit-config python.d.conf +sudo ./edit-config charts.d.conf +``` + +For example, to disable a few Python collectors: + +```conf +modules: + apache: no + dockerd: no + fail2ban: no +``` + +## Reduce collection frequency + +The fastest way to improve the Agent's resource utilization is to reduce how often it collects metrics. + +### Global + +If you don't need per-second metrics, or if the Netdata Agent uses a lot of CPU even when no one is viewing that node's +dashboard, [configure the Agent](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md) to collect metrics less often. + +Open `netdata.conf` and edit the `update every` setting. The default is `1`, meaning that the Agent collects metrics +every second. + +If you change this to `2`, Netdata enforces a minimum `update every` setting of 2 seconds, and collects metrics every +other second, which will effectively halve CPU utilization. Set this to `5` or `10` to collect metrics every 5 or 10 +seconds, respectively. + +```conf +[global] + update every = 5 +``` + +### Specific plugin or collector + +Every collector and plugin has its own `update every` setting, which you can also change in the `go.d.conf`, +`python.d.conf`, or `charts.d.conf` files, or in individual collector configuration files. If the `update +every` for an individual collector is less than the global, the Netdata Agent uses the global setting. See the [collectors configuration reference](https://github.com/netdata/netdata/blob/master/collectors/REFERENCE.md) for details. + +To reduce the frequency of an [internal +plugin/collector](https://github.com/netdata/netdata/blob/master/collectors/README.md#collector-architecture-and-terminology), open `netdata.conf` and +find the appropriate section. For example, to reduce the frequency of the `apps` plugin, which collects and visualizes +metrics on application resource utilization: + +```conf +[plugin:apps] + update every = 5 +``` + +To [configure an individual collector](https://github.com/netdata/netdata/blob/master/collectors/REFERENCE.md#configure-a-collector), open its specific configuration file with +`edit-config` and look for the `update_every` setting. For example, to reduce the frequency of the `nginx` collector, +run `sudo ./edit-config go.d/nginx.conf`: + +```conf +# [ GLOBAL ] +update_every: 10 +``` + +## Lower memory usage for metrics retention + +See how to [change how long Netdata stores metrics](https://github.com/netdata/netdata/blob/master/docs/store/change-metrics-storage.md). + +## Use a different metric storage database + +Consider [using a different metric storage database](https://github.com/netdata/netdata/blob/master/database/README.md) when running Netdata on IoT devices, +and for children in a parent-child set up based on [streaming and replication](https://github.com/netdata/netdata/blob/master/docs/metrics-storage-management/enable-streaming.md). + +## Disable machine learning + +Automated anomaly detection may be a powerful tool, but we recommend it to only be enabled on Netdata parents +that sit outside your production infrastructure, or if you have cpu and memory to spare. You can disable ML +with the following: + +```conf +[ml] + enabled = no +``` + +## Run Netdata behind a proxy + +A dedicated web server like nginx provides more robustness than the Agent's internal [web server](https://github.com/netdata/netdata/blob/master/web/README.md). +Nginx can handle more concurrent connections, reuse idle connections, and use fast gzip compression to reduce payloads. + +For details on installing another web server as a proxy for the local Agent dashboard, see [reverse proxies](https://github.com/netdata/netdata/blob/master/docs/category-overview-pages/reverse-proxies.md). + +## Disable/lower gzip compression for the dashboard + +If you choose not to run the Agent behind Nginx, you can disable or lower the Agent's web server's gzip compression. +While gzip compression does reduce the size of the HTML/CSS/JS payload, it does use additional CPU while a user is +looking at the local Agent dashboard. + +To disable gzip compression, open `netdata.conf` and find the `[web]` section: + +```conf +[web] + enable gzip compression = no +``` + +Or to lower the default compression level: + +```conf +[web] + enable gzip compression = yes + gzip compression level = 1 +``` + diff --git a/docs/guides/monitor-cockroachdb.md b/docs/guides/monitor-cockroachdb.md new file mode 100644 index 00000000..d0db69ab --- /dev/null +++ b/docs/guides/monitor-cockroachdb.md @@ -0,0 +1,118 @@ +<!-- +title: "Monitor CockroachDB metrics with Netdata" +sidebar_label: "Monitor CockroachDB metrics with Netdata" +custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/guides/monitor-cockroachdb.md +learn_status: "Published" +learn_topic_type: "Tasks" +learn_rel_path: "Miscellaneous" +--> + +# Monitor CockroachDB metrics with Netdata + +[CockroachDB](https://github.com/cockroachdb/cockroach) is an open-source project that brings SQL databases into +scalable, disaster-resilient cloud deployments. Thanks to +a [new CockroachDB collector](https://github.com/netdata/go.d.plugin/blob/master/modules/cockroachdb/README.md) +released in +[v1.20](https://blog.netdata.cloud/posts/release-1.20/), you can now monitor any number of CockroachDB databases with +maximum granularity using Netdata. Collect more than 50 unique metrics and put them on interactive visualizations +designed for better visual anomaly detection. + +Netdata itself uses CockroachDB as part of its Netdata Cloud infrastructure, so we're happy to introduce this new +collector and help others get started with it straight away. + +Let's dive in and walk through the process of monitoring CockroachDB metrics with Netdata. + +## What's in this guide + +- [Monitor CockroachDB metrics with Netdata](#monitor-cockroachdb-metrics-with-netdata) + - [What's in this guide](#whats-in-this-guide) + - [Configure the CockroachDB collector](#configure-the-cockroachdb-collector) + - [Manual setup for a local CockroachDB database](#manual-setup-for-a-local-cockroachdb-database) + - [Tweak CockroachDB alerts](#tweak-cockroachdb-alerts) + +## Configure the CockroachDB collector + +Because _all_ of Netdata's collectors can auto-detect the services they monitor, you _shouldn't_ need to worry about +configuring CockroachDB. Netdata only needs to regularly query the database's `_status/vars` page to gather metrics and +display them on the dashboard. + +If your CockroachDB instance is accessible through `http://localhost:8080/` or `http://127.0.0.1:8080`, your setup is +complete. Restart Netdata with `sudo systemctl restart netdata`, or the [appropriate +method](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md) for your system, and refresh your browser. You should see CockroachDB +metrics in your Netdata dashboard! + +<figure> + <img src="https://user-images.githubusercontent.com/1153921/73564467-d7e36b00-441c-11ea-9ec9-b5d5ea7277d4.png" alt="CPU utilization charts from a CockroachDB database monitored by Netdata" /> + <figcaption>CPU utilization charts from a CockroachDB database monitored by Netdata</figcaption> +</figure> + +> Note: Netdata collects metrics from CockroachDB every 10 seconds, instead of our usual 1 second, because CockroachDB +> only updates `_status/vars` every 10 seconds. You can't change this setting in CockroachDB. + +If you don't see CockroachDB charts, you may need to configure the collector manually. + +### Manual setup for a local CockroachDB database + +To configure Netdata's CockroachDB collector, navigate to your Netdata configuration directory (typically at +`/etc/netdata/`) and use `edit-config` to initialize and edit your CockroachDB configuration file. + +```bash +cd /etc/netdata/ # Replace with your Netdata configuration directory, if not /etc/netdata/ +./edit-config go.d/cockroachdb.conf +``` + +Scroll down to the `[JOBS]` section at the bottom of the file. You will see the two default jobs there, which you can +edit, or create a new job with any of the parameters listed above in the file. Both the `name` and `url` values are +required, and everything else is optional. + +For a production cluster, you'll use either an IP address or the system's hostname. Be sure that your remote system +allows TCP communication on port 8080, or whichever port you have configured CockroachDB's +[Admin UI](https://www.cockroachlabs.com/docs/stable/monitoring-and-alerting.html#prometheus-endpoint) to listen on. + +```yaml +# [ JOBS ] +jobs: + - name: remote + url: http://203.0.113.0:8080/_status/vars + + - name: remote_hostname + url: http://cockroachdb.example.com:8080/_status/vars +``` + +For a secure cluster, use `https` in the `url` field instead. + +```yaml +# [ JOBS ] +jobs: + - name: remote + url: https://203.0.113.0:8080/_status/vars + tls_skip_verify: yes # If your certificate is self-signed + + - name: remote_hostname + url: https://cockroachdb.example.com:8080/_status/vars + tls_skip_verify: yes # If your certificate is self-signed +``` + +You can add as many jobs as you'd like based on how many CockroachDB databases you have—Netdata will create separate +charts for each job. Once you've edited `cockroachdb.conf` according to the needs of your infrastructure, restart +Netdata to see your new charts. + +<figure> + <img src="https://user-images.githubusercontent.com/1153921/73564469-d7e36b00-441c-11ea-8333-02ba0e1c294c.png" alt="Charts showing a node failure during a simulated test" /> + <figcaption>Charts showing a node failure during a simulated test</figcaption> +</figure> + +## Tweak CockroachDB alerts + +This release also includes eight pre-configured alerts for live nodes, such as whether the node is live, storage +capacity, issues with replication, and the number of SQL connections/statements. See [health.d/cockroachdb.conf on +GitHub](https://raw.githubusercontent.com/netdata/netdata/master/health/health.d/cockroachdb.conf) for details. + +You can also edit these files directly with `edit-config`: + +```bash +cd /etc/netdata/ # Replace with your Netdata configuration directory, if not /etc/netdata/ +./edit-config health.d/cockroachdb.conf # You may need to use `sudo` for write privileges +``` + +For more information about editing the defaults or writing new alert entities, see our documentation on [configuring health alerts](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md). diff --git a/docs/guides/monitor-hadoop-cluster.md b/docs/guides/monitor-hadoop-cluster.md new file mode 100644 index 00000000..1ddac85e --- /dev/null +++ b/docs/guides/monitor-hadoop-cluster.md @@ -0,0 +1,191 @@ +<!-- +title: "Monitor a Hadoop cluster with Netdata" +sidebar_label: "Monitor a Hadoop cluster with Netdata" +custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/guides/monitor-hadoop-cluster.md +learn_status: "Published" +learn_topic_type: "Tasks" +learn_rel_path: "Miscellaneous" +--> + +# Monitor a Hadoop cluster with Netdata + +Hadoop is an [Apache project](https://hadoop.apache.org/) is a framework for processing large sets of data across a +distributed cluster of systems. + +And while Hadoop is designed to be a highly-available and fault-tolerant service, those who operate a Hadoop cluster +will want to monitor the health and performance of their [Hadoop Distributed File System +(HDFS)](https://hadoop.apache.org/docs/r1.2.1/hdfs_design.html) and [Zookeeper](https://zookeeper.apache.org/) +implementations. + +Netdata comes with built-in and pre-configured support for monitoring both HDFS and Zookeeper. + +This guide assumes you have a Hadoop cluster, with HDFS and Zookeeper, running already. If you don't, please follow +the [official Hadoop +instructions](http://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/SingleCluster.html) or an +alternative, like the guide available from +[DigitalOcean](https://www.digitalocean.com/community/tutorials/how-to-install-hadoop-in-stand-alone-mode-on-ubuntu-18-04). + +For more specifics on the collection modules used in this guide, read the respective pages in our documentation: + +- [HDFS](https://github.com/netdata/go.d.plugin/blob/master/modules/hdfs/README.md) +- [Zookeeper](https://github.com/netdata/go.d.plugin/blob/master/modules/zookeeper/README.md) + +## Set up your HDFS and Zookeeper installations + +As with all data sources, Netdata can auto-detect HDFS and Zookeeper nodes if you installed them using the standard +installation procedure. + +For Netdata to collect HDFS metrics, it needs to be able to access the node's `/jmx` endpoint. You can test whether an +JMX endpoint is accessible by using `curl HDFS-IP:PORT/jmx`. For a NameNode, you should see output similar to the +following: + +```json +{ + "beans" : [ { + "name" : "Hadoop:service=NameNode,name=JvmMetrics", + "modelerType" : "JvmMetrics", + "MemNonHeapUsedM" : 65.67851, + "MemNonHeapCommittedM" : 67.3125, + "MemNonHeapMaxM" : -1.0, + "MemHeapUsedM" : 154.46341, + "MemHeapCommittedM" : 215.0, + "MemHeapMaxM" : 843.0, + "MemMaxM" : 843.0, + "GcCount" : 15, + "GcTimeMillis" : 305, + "GcNumWarnThresholdExceeded" : 0, + "GcNumInfoThresholdExceeded" : 0, + "GcTotalExtraSleepTime" : 92, + "ThreadsNew" : 0, + "ThreadsRunnable" : 6, + "ThreadsBlocked" : 0, + "ThreadsWaiting" : 7, + "ThreadsTimedWaiting" : 34, + "ThreadsTerminated" : 0, + "LogFatal" : 0, + "LogError" : 0, + "LogWarn" : 2, + "LogInfo" : 348 + }, + { ... } + ] +} +``` + +The JSON result for a DataNode's `/jmx` endpoint is slightly different: + +```json +{ + "beans" : [ { + "name" : "Hadoop:service=DataNode,name=DataNodeActivity-dev-slave-01.dev.local-9866", + "modelerType" : "DataNodeActivity-dev-slave-01.dev.local-9866", + "tag.SessionId" : null, + "tag.Context" : "dfs", + "tag.Hostname" : "dev-slave-01.dev.local", + "BytesWritten" : 500960407, + "TotalWriteTime" : 463, + "BytesRead" : 80689178, + "TotalReadTime" : 41203, + "BlocksWritten" : 16, + "BlocksRead" : 16, + "BlocksReplicated" : 4, + ... + }, + { ... } + ] +} +``` + +If Netdata can't access the `/jmx` endpoint for either a NameNode or DataNode, it will not be able to auto-detect and +collect metrics from your HDFS implementation. + +Zookeeper auto-detection relies on an accessible client port and a allow-listed `mntr` command. For more details on +`mntr`, see Zookeeper's documentation on [cluster +options](https://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_clusterOptions) and [Zookeeper +commands](https://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_zkCommands). + +## Configure the HDFS and Zookeeper modules + +To configure Netdata's HDFS module, navigate to your Netdata directory (typically at `/etc/netdata/`) and use +`edit-config` to initialize and edit your HDFS configuration file. + +```bash +cd /etc/netdata/ +sudo ./edit-config go.d/hdfs.conf +``` + +At the bottom of the file, you will see two example jobs, both of which are commented out: + +```yaml +# [ JOBS ] +#jobs: +# - name: namenode +# url: http://127.0.0.1:9870/jmx +# +# - name: datanode +# url: http://127.0.0.1:9864/jmx +``` + +Uncomment these lines and edit the `url` value(s) according to your setup. Now's the time to add any other configuration +details, which you can find inside of the `hdfs.conf` file itself. Most production implementations will require TLS +certificates. + +The result for a simple HDFS setup, running entirely on `localhost` and without certificate authentication, might look +like this: + +```yaml +# [ JOBS ] +jobs: + - name: namenode + url: http://127.0.0.1:9870/jmx + + - name: datanode + url: http://127.0.0.1:9864/jmx +``` + +At this point, Netdata should be configured to collect metrics from your HDFS servers. Let's move on to Zookeeper. + +Next, use `edit-config` again to initialize/edit your `zookeeper.conf` file. + +```bash +cd /etc/netdata/ +sudo ./edit-config go.d/zookeeper.conf +``` + +As with the `hdfs.conf` file, head to the bottom, uncomment the example jobs, and tweak the `address` values according +to your setup. Again, you may need to add additional configuration options, like TLS certificates. + +```yaml +jobs: + - name : local + address : 127.0.0.1:2181 + + - name : remote + address : 203.0.113.10:2182 +``` + +Finally, [restart Netdata](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md). + +```sh +sudo systemctl restart netdata +``` + +Upon restart, Netdata should recognize your HDFS/Zookeeper servers, enable the HDFS and Zookeeper modules, and begin +showing real-time metrics for both in your Netdata dashboard. 🎉 + +## Configuring HDFS and Zookeeper alerts + +The Netdata community helped us create sane defaults for alerts related to both HDFS and Zookeeper. You may want to +investigate these to ensure they work well with your Hadoop implementation. + +- [HDFS alerts](https://raw.githubusercontent.com/netdata/netdata/master/health/health.d/hdfs.conf) + +You can also access/edit these files directly with `edit-config`: + +```bash +sudo /etc/netdata/edit-config health.d/hdfs.conf +sudo /etc/netdata/edit-config health.d/zookeeper.conf +``` + +For more information about editing the defaults or writing new alert entities, see our +[health monitoring documentation](https://github.com/netdata/netdata/blob/master/health/README.md). diff --git a/docs/guides/monitor/anomaly-detection.md b/docs/guides/monitor/anomaly-detection.md new file mode 100644 index 00000000..c0a00ef3 --- /dev/null +++ b/docs/guides/monitor/anomaly-detection.md @@ -0,0 +1,76 @@ +<!-- +title: "Machine learning (ML) powered anomaly detection" +sidebar_label: "Machine learning (ML) powered anomaly detection" +description: "Detect anomalies in any system, container, or application in your infrastructure with machine learning and the open-source Netdata Agent." +image: /img/seo/guides/monitor/anomaly-detection.png +custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/guides/monitor/anomaly-detection.md +learn_status: "Published" +learn_rel_path: "Operations" +--> + +# Machine learning (ML) powered anomaly detection + + +## Overview + +As of [`v1.32.0`](https://github.com/netdata/netdata/releases/tag/v1.32.0), Netdata comes with some ML powered [anomaly detection](https://en.wikipedia.org/wiki/Anomaly_detection) capabilities built into it and available to use out of the box, with zero configuration required (ML was enabled by default in `v1.35.0-29-nightly` in [this PR](https://github.com/netdata/netdata/pull/13158), previously it required a one line config change). + +This means that in addition to collecting raw value metrics, the Netdata agent will also produce an [`anomaly-bit`](https://github.com/netdata/netdata/blob/master/ml/README.md#anomaly-bit---100--anomalous-0--normal) every second which will be `100` when recent raw metric values are considered anomalous by Netdata and `0` when they look normal. Once we aggregate beyond one second intervals this aggregated `anomaly-bit` becomes an ["anomaly rate"](https://github.com/netdata/netdata/blob/master/ml/README.md#anomaly-rate---averageanomaly-bit). + +To be as concrete as possible, the below api call shows how to access the raw anomaly bit of the `system.cpu` chart from the [london.my-netdata.io](https://london.my-netdata.io) Netdata demo server. Passing `options=anomaly-bit` returns the anomaly bit instead of the raw metric value. + +``` +https://london.my-netdata.io/api/v1/data?chart=system.cpu&options=anomaly-bit +``` + +If we aggregate the above to just 1 point by adding `points=1` we get an "[Anomaly Rate](https://github.com/netdata/netdata/blob/master/ml/README.md#anomaly-rate---averageanomaly-bit)": + +``` +https://london.my-netdata.io/api/v1/data?chart=system.cpu&options=anomaly-bit&points=1 +``` + +The fundamentals of Netdata's anomaly detection approach and implementation are covered in lots more detail in the [agent ML documentation](https://github.com/netdata/netdata/blob/master/ml/README.md). + +This guide will explain how to get started using these ML based anomaly detection capabilities within Netdata. + +## Anomaly Advisor + +The [Anomaly Advisor](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/anomaly-advisor.md) is the flagship anomaly detection feature within Netdata. In the "Anomalies" tab of Netdata you will see an overall "Anomaly Rate" chart that aggregates node level anomaly rate for all nodes in a space. The aim of this chart is to make it easy to quickly spot periods of time where the overall "[node anomaly rate](https://github.com/netdata/netdata/blob/master/ml/README.md#node-anomaly-rate)" is elevated in some unusual way and for what node or nodes this relates to. + + + +Once an area on the Anomaly Rate chart is highlighted netdata will append a "heatmap" to the bottom of the screen that shows which metrics were more anomalous in the highlighted timeframe. Each row in the heatmap consists of an anomaly rate sparkline graph that can be expanded to reveal the raw underlying metric chart for that dimension. + +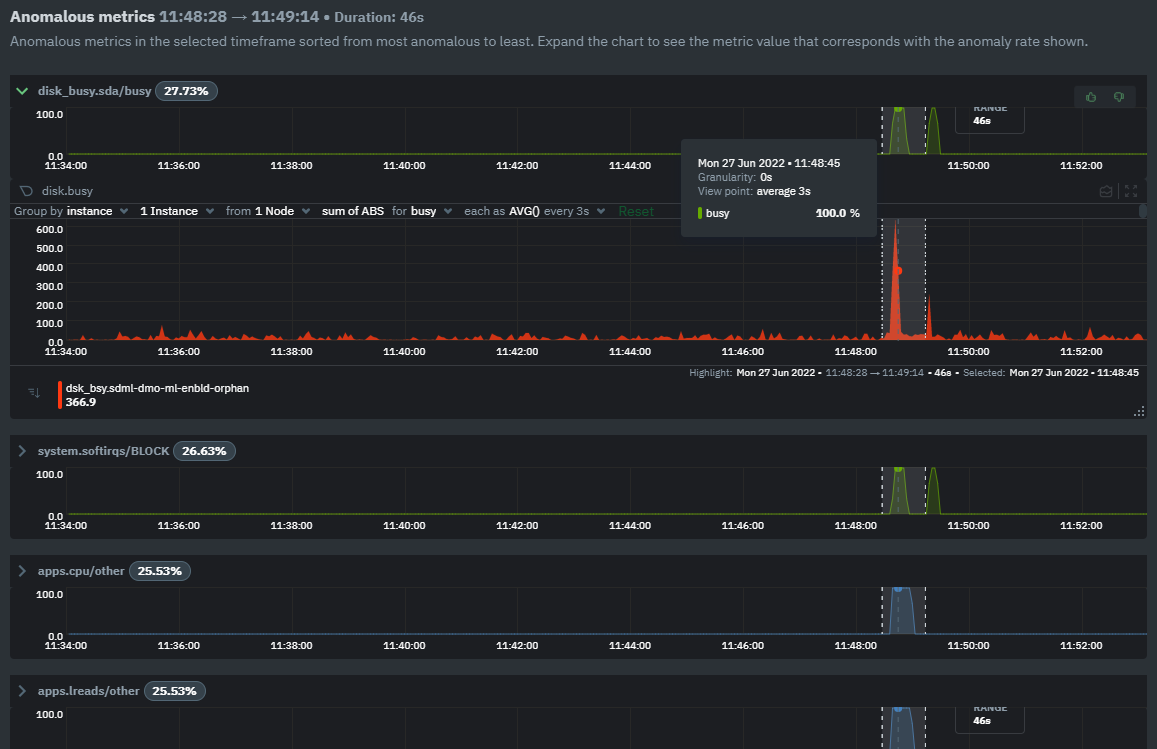 + +## Embedded Anomaly Rate Charts + +Charts in both the [Overview](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/overview.md) and [single node dashboard](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/overview.md#jump-to-single-node-dashboards) tabs also expose the underlying anomaly rates for each dimension so users can easily see if the raw metrics are considered anomalous or not by Netdata. + +Pressing the anomalies icon (next to the information icon in the chart header) will expand the anomaly rate chart to make it easy to see how the anomaly rate for any individual dimension corresponds to the raw underlying data. In the example below we can see that the spike in `system.pgpgio|in` corresponded in the anomaly rate for that dimension jumping to 100% for a small period of time until the spike passed. + +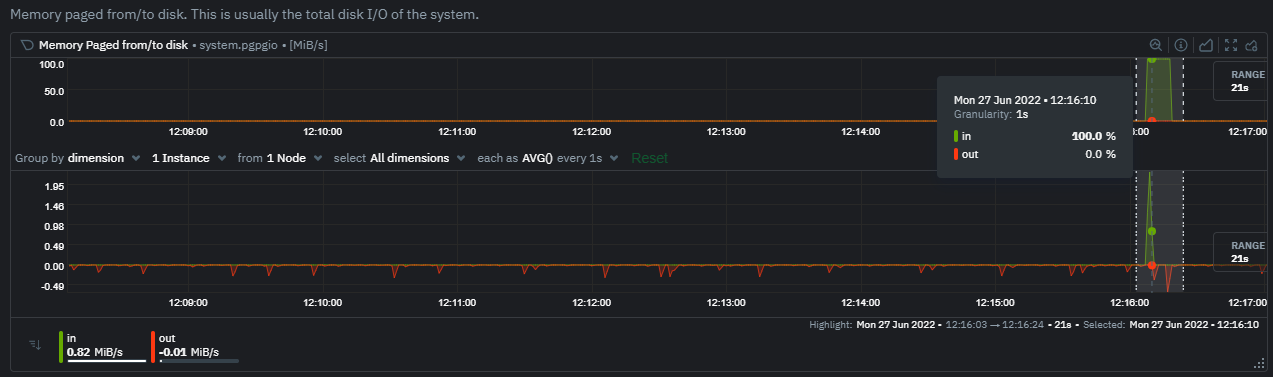 + +## Anomaly Rate Based Alerts + +It is possible to use the `anomaly-bit` when defining traditional Alerts within netdata. The `anomaly-bit` is just another `options` parameter that can be passed as part of an [alert line lookup](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md#alert-line-lookup). + +You can see some example ML based alert configurations below: + +- [Anomaly rate based CPU dimensions alert](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md#example-8---anomaly-rate-based-cpu-dimensions-alert) +- [Anomaly rate based CPU chart alert](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md#example-9---anomaly-rate-based-cpu-chart-alert) +- [Anomaly rate based node level alert](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md#example-10---anomaly-rate-based-node-level-alert) +- More examples in the [`/health/health.d/ml.conf`](https://github.com/netdata/netdata/blob/master/health/health.d/ml.conf) file that ships with the agent. + +## Learn More + +Check out the resources below to learn more about how Netdata is approaching ML: + +- [Agent ML documentation](https://github.com/netdata/netdata/blob/master/ml/README.md). +- [Anomaly Advisor documentation](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/anomaly-advisor.md). +- [Metric Correlations documentation](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/metric-correlations.md). +- Anomaly Advisor [launch blog post](https://www.netdata.cloud/blog/introducing-anomaly-advisor-unsupervised-anomaly-detection-in-netdata/). +- Netdata Approach to ML [blog post](https://www.netdata.cloud/blog/our-approach-to-machine-learning/). +- `areal/ml` related [GitHub Discussions](https://github.com/netdata/netdata/discussions?discussions_q=label%3Aarea%2Fml). +- Netdata Machine Learning Meetup [deck](https://docs.google.com/presentation/d/1rfSxktg2av2k-eMwMbjN0tXeo76KC33iBaxerYinovs/edit?usp=sharing) and [YouTube recording](https://www.youtube.com/watch?v=eJGWZHVQdNU). +- Netdata Anomaly Advisor [YouTube Playlist](https://youtube.com/playlist?list=PL-P-gAHfL2KPeUcCKmNHXC-LX-FfdO43j). diff --git a/docs/guides/monitor/kubernetes-k8s-netdata.md b/docs/guides/monitor/kubernetes-k8s-netdata.md new file mode 100644 index 00000000..96d79935 --- /dev/null +++ b/docs/guides/monitor/kubernetes-k8s-netdata.md @@ -0,0 +1,246 @@ +# Kubernetes monitoring with Netdata + +This document gives an overview of what visualizations Netdata provides on Kubernetes deployments. + +At Netdata, we've built Kubernetes monitoring tools that add visibility without complexity while also helping you +actively troubleshoot anomalies or outages. This guide walks you through each of the visualizations and offers best +practices on how to use them to start Kubernetes monitoring in a matter of minutes, not hours or days. + +Netdata's Kubernetes monitoring solution uses a handful of [complementary tools and +collectors](#related-reference-documentation) for peeling back the many complex layers of a Kubernetes cluster, +_entirely for free_. These methods work together to give you every metric you need to troubleshoot performance or +availability issues across your Kubernetes infrastructure. + +## Challenge + +While Kubernetes (k8s) might simplify the way you deploy, scale, and load-balance your applications, not all clusters +come with "batteries included" when it comes to monitoring. Doubly so for a monitoring stack that helps you actively +troubleshoot issues with your cluster. + +Some k8s providers, like GKE (Google Kubernetes Engine), do deploy clusters bundled with monitoring capabilities, such +as Google Stackdriver Monitoring. However, these pre-configured solutions might not offer the depth of metrics, +customization, or integration with your preferred alerting methods. + +Without this visibility, it's like you built an entire house and _then_ smashed your way through the finished walls to +add windows. + +## Solution + +In this tutorial, you'll learn how to navigate Netdata's Kubernetes monitoring features, using +[robot-shop](https://github.com/instana/robot-shop) as an example deployment. Deploying robot-shop is purely optional. +You can also follow along with your own Kubernetes deployment if you choose. While the metrics might be different, the +navigation and best practices are the same for every cluster. + +## What you need to get started + +To follow this tutorial, you need: + +- A free Netdata Cloud account. [Sign up](https://app.netdata.cloud/sign-up?cloudRoute=/spaces) if you don't have one + already. +- A working cluster running Kubernetes v1.9 or newer, with a Netdata deployment and connected parent/child nodes. See + our [Kubernetes deployment process](https://github.com/netdata/netdata/blob/master/packaging/installer/methods/kubernetes.md) for details on deployment and + conneting to Cloud. +- The [`kubectl`](https://kubernetes.io/docs/reference/kubectl/overview/) command line tool, within [one minor version + difference](https://kubernetes.io/docs/tasks/tools/install-kubectl/#before-you-begin) of your cluster, on an + administrative system. +- The [Helm package manager](https://helm.sh/) v3.0.0 or newer on the same administrative system. + +### Install the `robot-shop` demo (optional) + +Begin by downloading the robot-shop code and using `helm` to create a new deployment. + +```bash +git clone git@github.com:instana/robot-shop.git +cd robot-shop/K8s/helm +kubectl create ns robot-shop +helm install robot-shop --namespace robot-shop . +``` + +Running `kubectl get pods` shows both the Netdata and robot-shop deployments. + +```bash +kubectl get pods --all-namespaces +NAMESPACE NAME READY STATUS RESTARTS AGE +default netdata-child-29f9c 2/2 Running 0 10m +default netdata-child-8xphf 2/2 Running 0 10m +default netdata-child-jdvds 2/2 Running 0 11m +default netdata-parent-554c755b7d-qzrx4 1/1 Running 0 11m +kube-system aws-node-jnjv8 1/1 Running 0 17m +kube-system aws-node-svzdb 1/1 Running 0 17m +kube-system aws-node-ts6n2 1/1 Running 0 17m +kube-system coredns-559b5db75d-f58hp 1/1 Running 0 22h +kube-system coredns-559b5db75d-tkzj2 1/1 Running 0 22h +kube-system kube-proxy-9p9cd 1/1 Running 0 17m +kube-system kube-proxy-lt9ss 1/1 Running 0 17m +kube-system kube-proxy-n75t9 1/1 Running 0 17m +robot-shop cart-b4bbc8fff-t57js 1/1 Running 0 14m +robot-shop catalogue-8b5f66c98-mr85z 1/1 Running 0 14m +robot-shop dispatch-67d955c7d8-lnr44 1/1 Running 0 14m +robot-shop mongodb-7f65d86c-dsslc 1/1 Running 0 14m +robot-shop mysql-764c4c5fc7-kkbnf 1/1 Running 0 14m +robot-shop payment-67c87cb7d-5krxv 1/1 Running 0 14m +robot-shop rabbitmq-5bb66bb6c9-6xr5b 1/1 Running 0 14m +robot-shop ratings-94fd9c75b-42wvh 1/1 Running 0 14m +robot-shop redis-0 0/1 Pending 0 14m +robot-shop shipping-7d69cb88b-w7hpj 1/1 Running 0 14m +robot-shop user-79c445b44b-hwnm9 1/1 Running 0 14m +robot-shop web-8bb887476-lkcjx 1/1 Running 0 14m +``` + +## Explore Netdata's Kubernetes monitoring charts + +The Netdata Helm chart deploys and enables everything you need for monitoring Kubernetes on every layer. Once you deploy +Netdata and connect your cluster's nodes, you're ready to check out the visualizations **with zero configuration**. + +To get started, [sign in](https://app.netdata.cloud/sign-in?cloudRoute=/spaces) to your Netdata Cloud account. Head over +to the War Room you connected your cluster to, if not **General**. + +Netdata Cloud is already visualizing your Kubernetes metrics, streamed in real-time from each node, in the +[Overview](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/overview.md): + +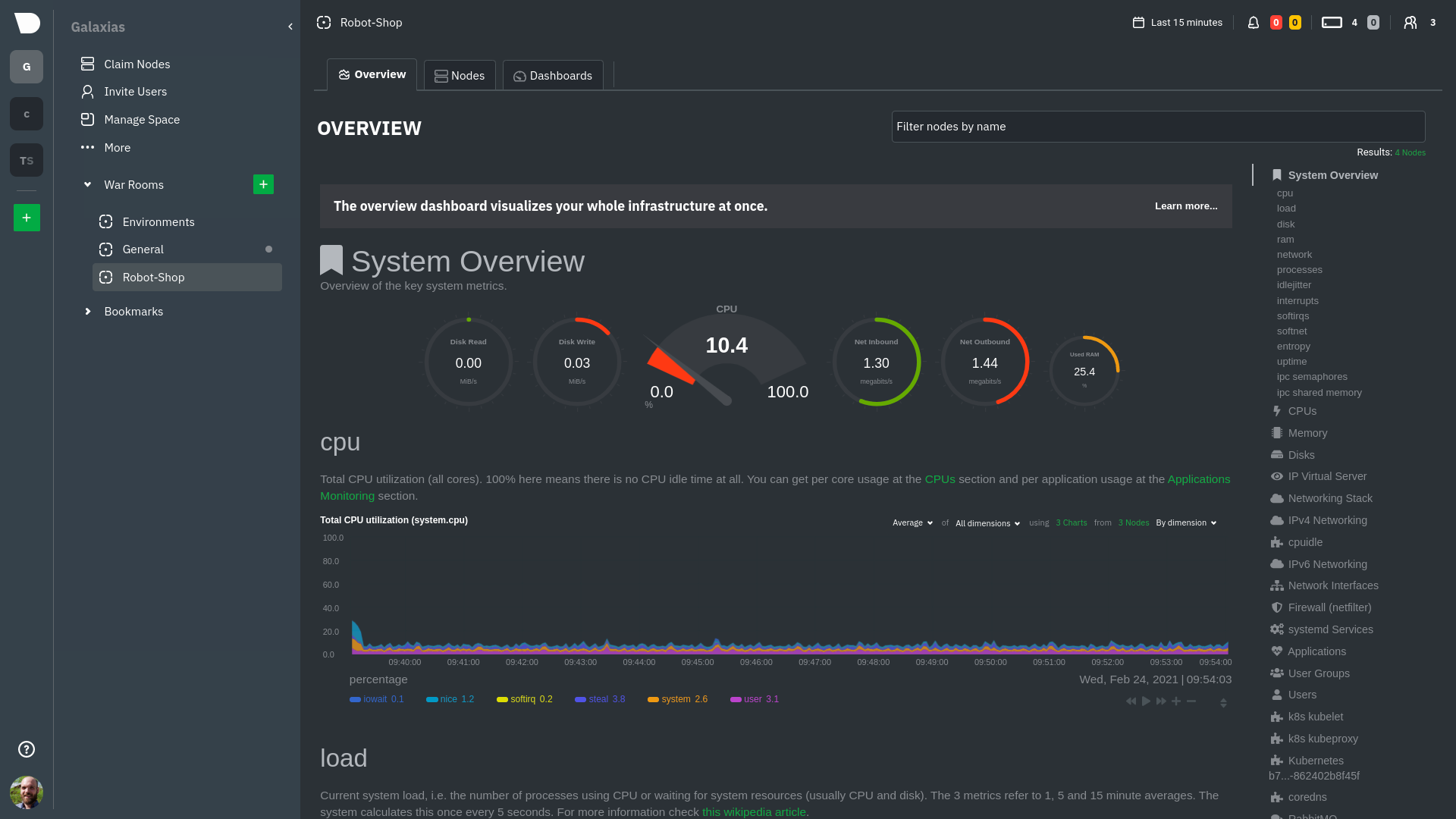 + +Let's walk through monitoring each layer of a Kubernetes cluster using the Overview as our framework. + +## Cluster and node metrics + +The gauges and time-series charts you see right away in the Overview show aggregated metrics from every node in your +cluster. + +For example, the `apps.cpu` chart (in the **Applications** menu item), visualizes the CPU utilization of various +applications/services running on each of the nodes in your cluster. The **X Nodes** dropdown shows which nodes +contribute to the chart and links to jump a single-node dashboard for further investigation. + +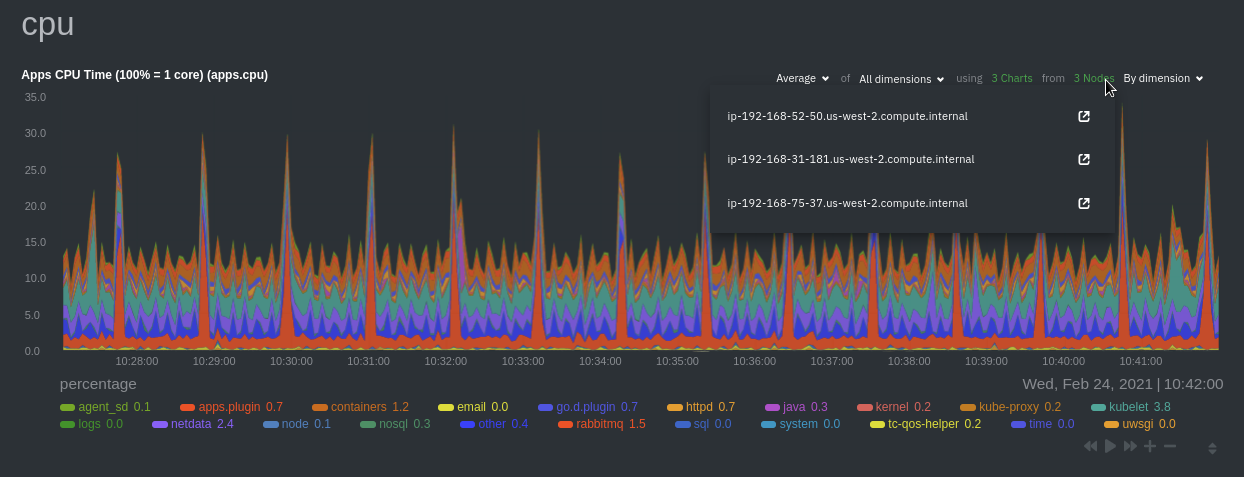 + +For example, the chart above shows a spike in the CPU utilization from `rabbitmq` every minute or so, along with a +baseline CPU utilization of 10-15% across the cluster. + +Read about the [Overview](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/overview.md) and some best practices on [viewing +an overview of your infrastructure](https://github.com/netdata/netdata/blob/master/docs/visualize/overview-infrastructure.md) for details on using composite charts to +drill down into per-node performance metrics. + +## Pod and container metrics + +Click on the **Kubernetes xxxxxxx...** section to jump down to Netdata Cloud's unique Kubernetes visualizations for view +real-time resource utilization metrics from your Kubernetes pods and containers. + + + +### Health map + +The first visualization is the [health map](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/kubernetes.md#health-map), +which places each container into its own box, then varies the intensity of their color to visualize the resource +utilization. By default, the health map shows the **average CPU utilization as a percentage of the configured limit** +for every container in your cluster. + + + +Let's explore the most colorful box by hovering over it. + + + +The **Context** tab shows `rabbitmq-5bb66bb6c9-6xr5b` as the container's image name, which means this container is +running a [RabbitMQ](https://github.com/netdata/go.d.plugin/blob/master/modules/rabbitmq/README.md) workload. + +Click the **Metrics** tab to see real-time metrics from that container. Unsurprisingly, it shows a spike in CPU +utilization at regular intervals. + + + +### Time-series charts + +Beneath the health map is a variety of time-series charts that help you visualize resource utilization over time, which +is useful for targeted troubleshooting. + +The default is to display metrics grouped by the `k8s_namespace` label, which shows resource utilization based on your +different namespaces. + +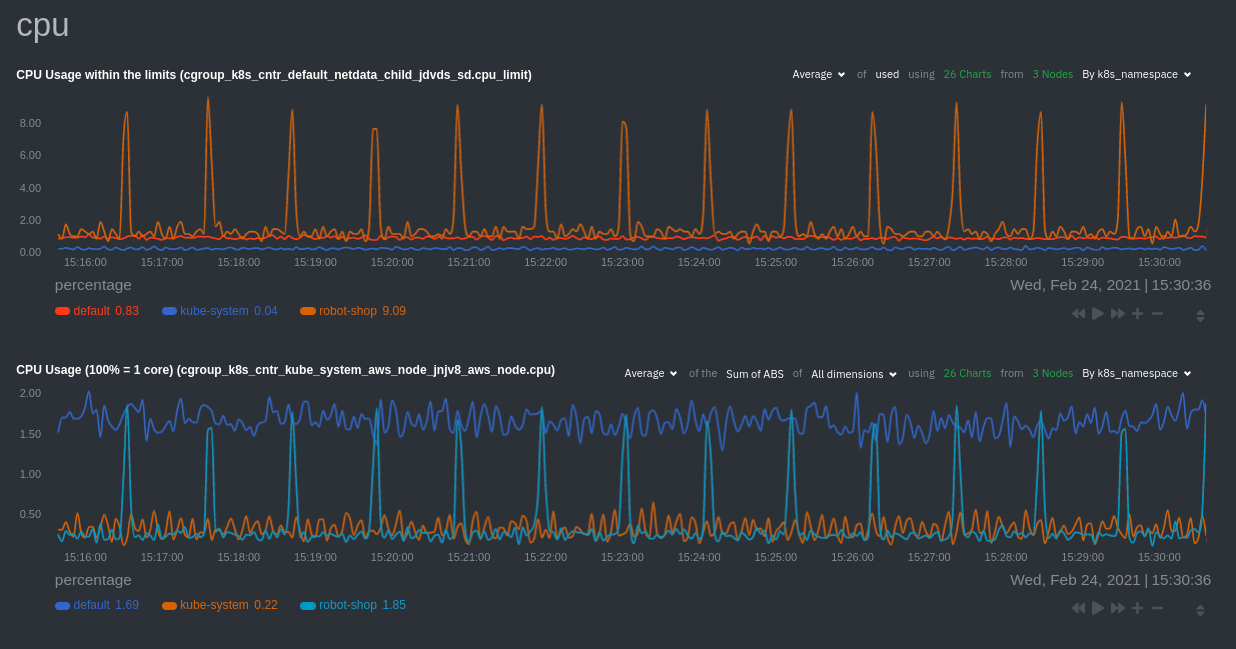 + +Each composite chart has a [definition bar](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/overview.md#definition-bar) +for complete customization. For example, grouping the top chart by `k8s_container_name` reveals new information. + +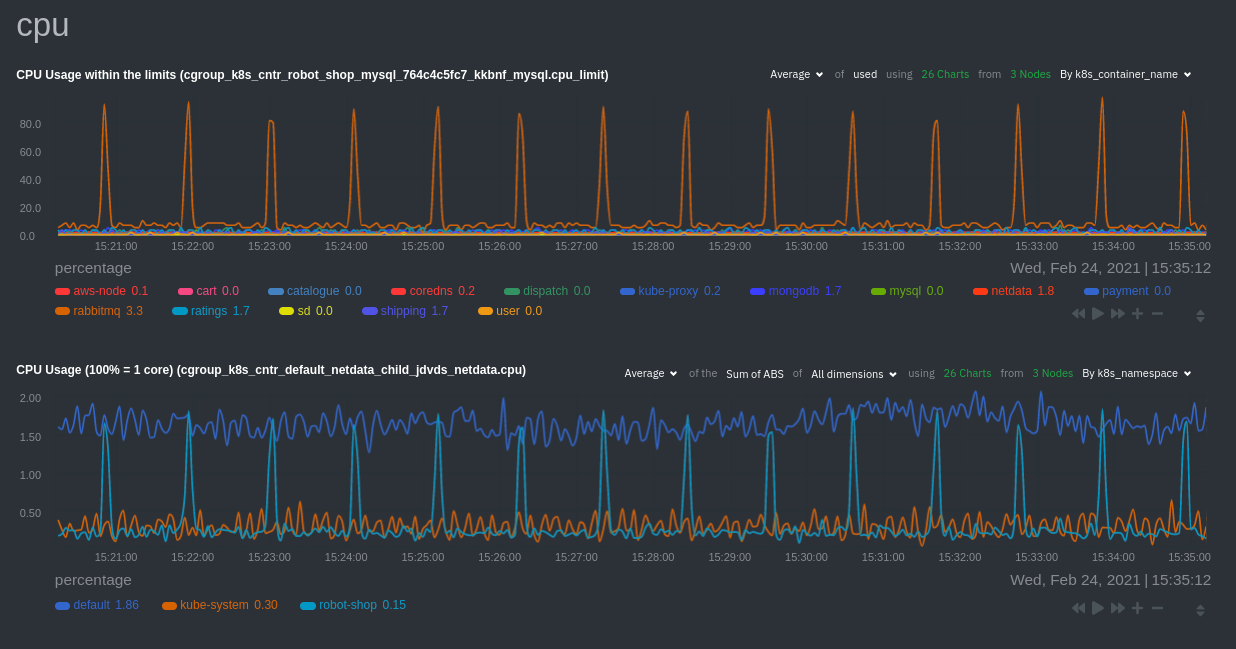 + +## Service metrics + +Netdata has a [service discovery plugin](https://github.com/netdata/agent-service-discovery), which discovers and +creates configuration files for [compatible +services](https://github.com/netdata/helmchart#service-discovery-and-supported-services) and any endpoints covered by +our [generic Prometheus collector](https://github.com/netdata/go.d.plugin/blob/master/modules/prometheus/README.md). +Netdata uses these files to collect metrics from any compatible application as they run _inside_ of a pod. Service +discovery happens without manual intervention as pods are created, destroyed, or moved between nodes. + +Service metrics show up on the Overview as well, beneath the **Kubernetes** section, and are labeled according to the +service in question. For example, the **RabbitMQ** section has numerous charts from the [`rabbitmq` +collector](https://github.com/netdata/go.d.plugin/blob/master/modules/rabbitmq/README.md): + + + +> The robot-shop cluster has more supported services, such as MySQL, which are not visible with zero configuration. This +> is usually because of services running on non-default ports, using non-default names, or required passwords. Read up +> on [configuring service discovery](https://github.com/netdata/netdata/blob/master/packaging/installer/methods/kubernetes.md#configure-service-discovery) to collect +> more service metrics. + +Service metrics are essential to infrastructure monitoring, as they're the best indicator of the end-user experience, +and key signals for troubleshooting anomalies or issues. + +## Kubernetes components + +Netdata also automatically collects metrics from two essential Kubernetes processes. + +### kubelet + +The **k8s kubelet** section visualizes metrics from the Kubernetes agent responsible for managing every pod on a given +node. This also happens without any configuration thanks to the [kubelet +collector](https://github.com/netdata/go.d.plugin/blob/master/modules/k8s_kubelet/README.md). + +Monitoring each node's kubelet can be invaluable when diagnosing issues with your Kubernetes cluster. For example, you +can see if the number of running containers/pods has dropped, which could signal a fault or crash in a particular +Kubernetes service or deployment (see `kubectl get services` or `kubectl get deployments` for more details). If the +number of pods increases, it may be because of something more benign, like another team member scaling up a +service with `kubectl scale`. + +You can also view charts for the Kubelet API server, the volume of runtime/Docker operations by type, +configuration-related errors, and the actual vs. desired numbers of volumes, plus a lot more. + +### kube-proxy + +The **k8s kube-proxy** section displays metrics about the network proxy that runs on each node in your Kubernetes +cluster. kube-proxy lets pods communicate with each other and accept sessions from outside your cluster. Its metrics are +collected by the [kube-proxy +collector](https://github.com/netdata/go.d.plugin/blob/master/modules/k8s_kubeproxy/README.md). + +With Netdata, you can monitor how often your k8s proxies are syncing proxy rules between nodes. Dramatic changes in +these figures could indicate an anomaly in your cluster that's worthy of further investigation. + +## What's next? + +After reading this guide, you should now be able to monitor any Kubernetes cluster with Netdata, including nodes, pods, +containers, services, and more. + +With the health map, time-series charts, and the ability to drill down into individual nodes, you can see hundreds of +per-second metrics with zero configuration and less time remembering all the `kubectl` options. Netdata moves with your +cluster, automatically picking up new nodes or services as your infrastructure scales. And it's entirely free for +clusters of all sizes. + +### Related reference documentation + +- [Netdata Helm chart](https://github.com/netdata/helmchart) +- [Netdata service discovery](https://github.com/netdata/agent-service-discovery) +- [Netdata Agent · `kubelet` + collector](https://github.com/netdata/go.d.plugin/blob/master/modules/k8s_kubelet/README.md) +- [Netdata Agent · `kube-proxy` + collector](https://github.com/netdata/go.d.plugin/blob/master/modules/k8s_kubeproxy/README.md) +- [Netdata Agent · `cgroups.plugin`](https://github.com/netdata/netdata/blob/master/collectors/cgroups.plugin/README.md) + + diff --git a/docs/guides/monitor/lamp-stack.md b/docs/guides/monitor/lamp-stack.md new file mode 100644 index 00000000..2289c71c --- /dev/null +++ b/docs/guides/monitor/lamp-stack.md @@ -0,0 +1,238 @@ +import { OneLineInstallWget } from '@site/src/components/OneLineInstall/' + +# LAMP stack monitoring with Netdata + +Set up robust LAMP stack monitoring (Linux, Apache, MySQL, PHP) in a few minutes using Netdata. + +The LAMP stack is the "hello world" for deploying dynamic web applications. It's fast, flexible, and reliable, which +means a developer or sysadmin won't go far in their career without interacting with the stack and its services. + +_LAMP_ is an acronym of the core services that make up the web application: **L**inux, **A**pache, **M**ySQL, and +**P**HP. + +- [Linux](https://en.wikipedia.org/wiki/Linux) is the operating system running the whole stack. +- [Apache](https://httpd.apache.org/) is a web server that responds to HTTP requests from users and returns web pages. +- [MySQL](https://www.mysql.com/) is a database that stores and returns information based on queries from the web + application. +- [PHP](https://www.php.net/) is a scripting language used to query the MySQL database and build new pages. + +LAMP stacks are the foundation for tons of end-user applications, with [Wordpress](https://wordpress.org/) being the +most popular. + +## Challenge + +You've already deployed a LAMP stack, either in testing or production. You want to monitor every service's performance +and availability to ensure the best possible experience for your end-users. You might also be particularly interested in +using a free, open-source monitoring tool. + +Depending on your monitoring experience, you may not even know what metrics you're looking for, much less how to build +dashboards using a query language. You need a robust monitoring experience that has the metrics you need without a ton +of required setup. + +## Solution + +In this tutorial, you'll set up robust LAMP stack monitoring with Netdata in just a few minutes. When you're done, +you'll have one dashboard to monitor every part of your web application, including each essential LAMP stack service. + +This dashboard updates every second with new metrics, and pairs those metrics up with preconfigured alerts to keep you +informed of any errors or odd behavior. + +## What you need to get started + +To follow this tutorial, you need: + +- A physical or virtual Linux system, which we'll call a _node_. +- A functional LAMP stack. There's plenty of tutorials for installing a LAMP stack, like [this + one](https://www.digitalocean.com/community/tutorials/how-to-install-linux-apache-mysql-php-lamp-stack-ubuntu-18-04) + from Digital Ocean. +- Optionally, a [Netdata Cloud](https://app.netdata.cloud/sign-up?cloudRoute=/spaces) account, which you can use to view + metrics from multiple nodes in one dashboard, and a whole lot more, for free. + +## Install the Netdata Agent + +If you don't have the free, open-source Netdata monitoring agent installed on your node yet, get started with a [single +kickstart command](https://github.com/netdata/netdata/blob/master/packaging/installer/README.md): + +<OneLineInstallWget/> + +The Netdata Agent is now collecting metrics from your node every second. You don't need to jump into the dashboard yet, +but if you're curious, open your favorite browser and navigate to `http://localhost:19999` or `http://NODE:19999`, +replacing `NODE` with the hostname or IP address of your system. + +## Enable hardware and Linux system monitoring + +There's nothing you need to do to enable [system monitoring](https://github.com/netdata/netdata/blob/master/docs/collect/system-metrics.md) and Linux monitoring with +the Netdata Agent, which autodetects metrics from CPUs, memory, disks, networking devices, and Linux processes like +systemd without any configuration. If you're using containers, Netdata automatically collects resource utilization +metrics from each using the [cgroups data collector](https://github.com/netdata/netdata/blob/master/collectors/cgroups.plugin/README.md). + +## Enable Apache monitoring + +Let's begin by configuring Apache to work with Netdata's [Apache data +collector](https://github.com/netdata/go.d.plugin/blob/master/modules/apache/README.md). + +Actually, there's nothing for you to do to enable Apache monitoring with Netdata. + +Apache comes with `mod_status` enabled by default these days, and Netdata is smart enough to look for metrics at that +endpoint without you configuring it. Netdata is already collecting [`mod_status` +metrics](https://httpd.apache.org/docs/2.4/mod/mod_status.html), which is just _part_ of your web server monitoring. + +## Enable web log monitoring + +The Netdata Agent also comes with a [web log +collector](https://github.com/netdata/go.d.plugin/blob/master/modules/weblog/README.md), which reads Apache's access +log file, processes each line, and converts them into per-second metrics. On Debian systems, it reads the file at +`/var/log/apache2/access.log`. + +At installation, the Netdata Agent adds itself to the [`adm` +group](https://wiki.debian.org/SystemGroups#Groups_without_an_associated_user), which gives the `netdata` process the +right privileges to read Apache's log files. In other words, you don't need to do anything to enable Apache web log +monitoring. + +## Enable MySQL monitoring + +Because your MySQL database is password-protected, you do need to tell MySQL to allow the `netdata` user to connect to +without a password. Netdata's [MySQL data +collector](https://github.com/netdata/go.d.plugin/blob/master/modules/mysql/README.md) collects metrics in _read-only_ +mode, without being able to alter or affect operations in any way. + +First, log into the MySQL shell. Then, run the following three commands, one at a time: + +```mysql +CREATE USER 'netdata'@'localhost'; +GRANT USAGE, REPLICATION CLIENT, PROCESS ON *.* TO 'netdata'@'localhost'; +FLUSH PRIVILEGES; +``` + +Run `sudo systemctl restart netdata`, or the [appropriate alternative for your +system](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md), to collect dozens of metrics every second for robust MySQL monitoring. + +## Enable PHP monitoring + +Unlike Apache or MySQL, PHP isn't a service that you can monitor directly, unless you instrument a PHP-based application +with [StatsD](https://github.com/netdata/netdata/blob/master/collectors/statsd.plugin/README.md). + +However, if you use [PHP-FPM](https://php-fpm.org/) in your LAMP stack, you can monitor that process with our [PHP-FPM +data collector](https://github.com/netdata/go.d.plugin/blob/master/modules/phpfpm/README.md). + +Open your PHP-FPM configuration for editing, replacing `7.4` with your version of PHP: + +```bash +sudo nano /etc/php/7.4/fpm/pool.d/www.conf +``` + +> Not sure what version of PHP you're using? Run `php -v`. + +Find the line that reads `;pm.status_path = /status` and remove the `;` so it looks like this: + +```conf +pm.status_path = /status +``` + +Next, add a new `/status` endpoint to Apache. Open the Apache configuration file you're using for your LAMP stack. + +```bash +sudo nano /etc/apache2/sites-available/your_lamp_stack.conf +``` + +Add the following to the end of the file, again replacing `7.4` with your version of PHP: + +```apache +ProxyPass "/status" "unix:/run/php/php7.4-fpm.sock|fcgi://localhost" +``` + +Save and close the file. Finally, restart the PHP-FPM, Apache, and Netdata processes. + +```bash +sudo systemctl restart php7.4-fpm.service +sudo systemctl restart apache2 +sudo systemctl restart netdata +``` + +As the Netdata Agent starts up again, it automatically connects to the new `127.0.0.1/status` page and collects +per-second PHP-FPM metrics to get you started with PHP monitoring. + +## View LAMP stack metrics + +If the Netdata Agent isn't already open in your browser, open a new tab and navigate to `http://localhost:19999` or +`http://NODE:19999`, replacing `NODE` with the hostname or IP address of your system. + +> If you [signed up](https://app.netdata.cloud/sign-up?cloudRoute=/spaces) for Netdata Cloud earlier, you can also view +> the exact same LAMP stack metrics there, plus additional features, like drag-and-drop custom dashboards. Be sure to +> [connecting your node](https://github.com/netdata/netdata/blob/master/claim/README.md) to start streaming metrics to your browser through Netdata Cloud. + +Netdata automatically organizes all metrics and charts onto a single page for easy navigation. Peek at gauges to see +overall system performance, then scroll down to see more. Click-and-drag with your mouse to pan _all_ charts back and +forth through different time intervals, or hold `SHIFT` and use the scrollwheel (or two-finger scroll) to zoom in and +out. Check out our doc on [interacting with charts](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/interact-new-charts.md) for all the details. + +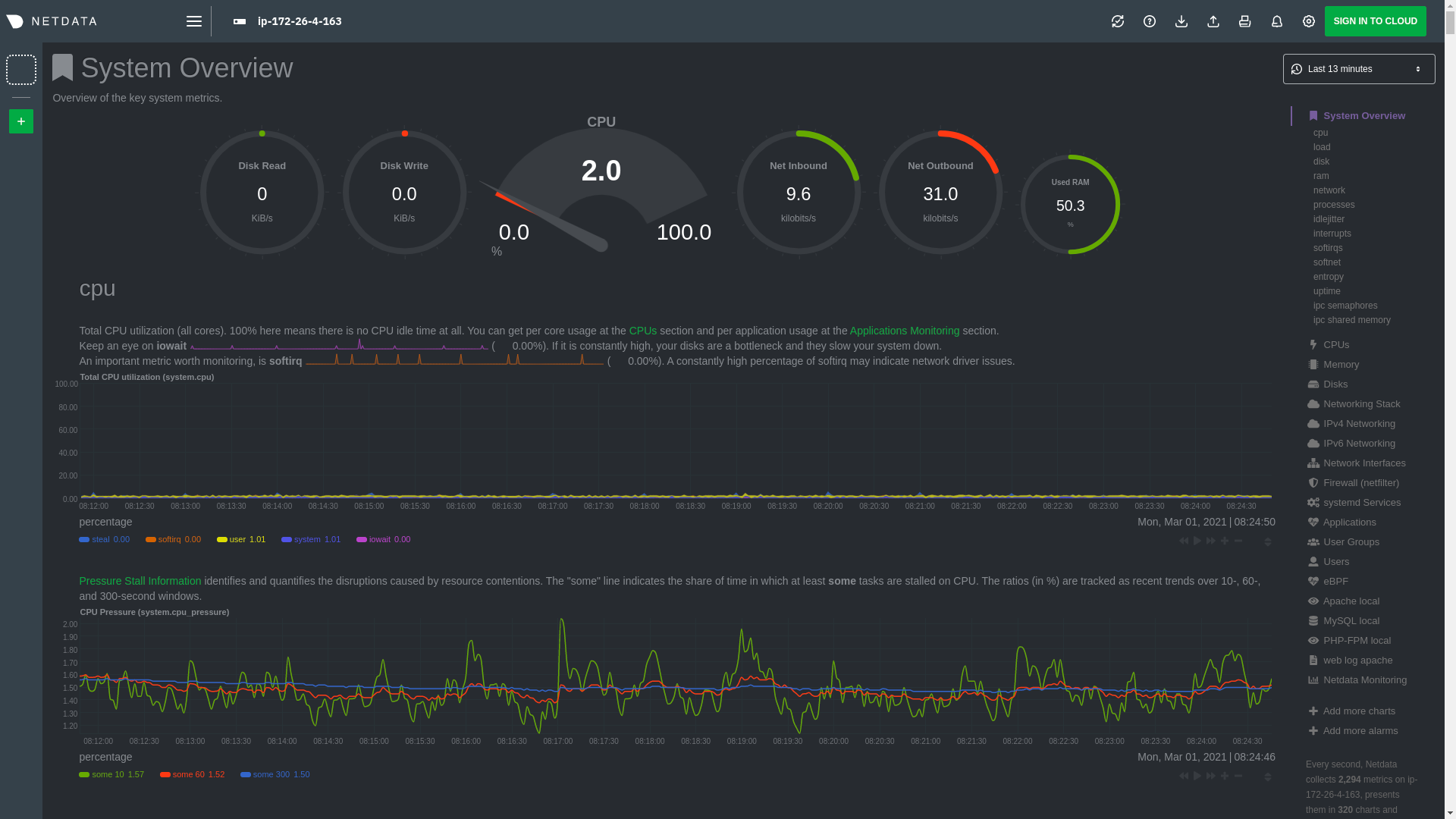 + +The **System Overview** section, which you can also see in the right-hand menu, contains key hardware monitoring charts, +including CPU utilization, memory page faults, network monitoring, and much more. The **Applications** section shows you +exactly which Linux processes are using the most system resources. + +Next, let's check out LAMP-specific metrics. You should see four relevant sections: **Apache local**, **MySQL local**, +**PHP-FPM local**, and **web log apache**. Click on any of these to see metrics from each service in your LAMP stack. + + + +### Key LAMP stack monitoring charts + +Here's a quick reference for what charts you might want to focus on after setting up Netdata. + +| Chart name / context | Type | Why? | +|-------------------------------------------------------|---------------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------| +| System Load Average (`system.load`) | Hardware monitoring | A good baseline load average is `0.7`, while `1` (on a 1-core system, `2` on a 2-core system, and so on) means resources are "perfectly" utilized. Higher load indicates a bottleneck somewhere in your system. | +| System RAM (`system.ram`) | Hardware monitoring | Look at the `free` dimension. If that drops to `0`, your system will use swap memory and slow down. | +| Uptime (`apache_local.uptime`) | Apache monitoring | This chart should always be "climbing," indicating a continuous uptime. Investigate any drops back to `0`. | +| Requests By Type (`web_log_apache.requests_by_type`) | Apache monitoring | Check for increases in the `error` or `bad` dimensions, which could indicate users arriving at broken pages or PHP returning errors. | +| Queries (`mysql_local.queries`) | MySQL monitoring | Queries is the total number of queries (queries per second, QPS). Check this chart for sudden spikes or drops, which indicate either increases in traffic/demand or bottlenecks in hardware performance. | +| Active Connections (`mysql_local.connections_active`) | MySQL monitoring | If the `active` dimension nears the `limit`, your MySQL database will bottleneck responses. | +| Performance (phpfpm_local.performance) | PHP monitoring | The `slow requests` dimension lets you know if any requests exceed the configured `request_slowlog_timeout`. If so, users might be having a less-than-ideal experience. | + +## Get alerts for LAMP stack errors + +The Netdata Agent comes with hundreds of pre-configured alerts to help you keep tabs on your system, including 19 alerts +designed for smarter LAMP stack monitoring. + +Click the 🔔 icon in the top navigation to [see active alerts](https://github.com/netdata/netdata/blob/master/docs/monitor/view-active-alerts.md). The **Active** tabs +shows any alerts currently triggered, while the **All** tab displays a list of _every_ pre-configured alert. The + + + +[Tweak alerts](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md) based on your infrastructure monitoring needs, and to see these alerts +in other places, like your inbox or a Slack channel, [enable a notification +method](https://github.com/netdata/netdata/blob/master/docs/monitor/enable-notifications.md). + +## What's next? + +You've now set up robust monitoring for your entire LAMP stack: Linux, Apache, MySQL, and PHP (-FPM, to be exact). These +metrics will help you keep tabs on the performance and availability of your web application and all its essential +services. The per-second metrics granularity means you have the most accurate information possible for troubleshooting +any LAMP-related issues. + +Another powerful way to monitor the availability of a LAMP stack is the [`httpcheck` +collector](https://github.com/netdata/go.d.plugin/blob/master/modules/httpcheck/README.md), which pings a web server at +a regular interval and tells you whether if and how quickly it's responding. The `response_match` option also lets you +monitor when the web server's response isn't what you expect it to be, which might happen if PHP-FPM crashes, for +example. + +The best way to use the `httpcheck` collector is from a separate node from the one running your LAMP stack, which is why +we're not covering it here, but it _does_ work in a single-node setup. Just don't expect it to tell you if your whole +node crashed. + +If you're planning on managing more than one node, or want to take advantage of advanced features, like finding the +source of issues faster with [Metric Correlations](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/metric-correlations.md), +[sign up](https://app.netdata.cloud/sign-up?cloudRoute=/spaces) for a free Netdata Cloud account. + +### Related reference documentation + +- [Netdata Agent · Get started](https://github.com/netdata/netdata/blob/master/packaging/installer/README.md) +- [Netdata Agent · Apache data collector](https://github.com/netdata/go.d.plugin/blob/master/modules/apache/README.md) +- [Netdata Agent · Web log collector](https://github.com/netdata/go.d.plugin/blob/master/modules/weblog/README.md) +- [Netdata Agent · MySQL data collector](https://github.com/netdata/go.d.plugin/blob/master/modules/mysql/README.md) +- [Netdata Agent · PHP-FPM data collector](https://github.com/netdata/go.d.plugin/blob/master/modules/phpfpm/README.md) + diff --git a/docs/guides/monitor/pi-hole-raspberry-pi.md b/docs/guides/monitor/pi-hole-raspberry-pi.md new file mode 100644 index 00000000..4f0ff4cd --- /dev/null +++ b/docs/guides/monitor/pi-hole-raspberry-pi.md @@ -0,0 +1,142 @@ +<!-- +title: "Monitor Pi-hole (and a Raspberry Pi) with Netdata" +sidebar_label: "Monitor Pi-hole (and a Raspberry Pi) with Netdata" +description: "Monitor Pi-hole metrics, plus Raspberry Pi system metrics, in minutes and completely for free with Netdata's open-source monitoring agent." +image: /img/seo/guides/monitor/netdata-pi-hole-raspberry-pi.png +custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/guides/monitor/pi-hole-raspberry-pi.md +learn_status: "Published" +learn_rel_path: "Miscellaneous" +--> + +# Monitor Pi-hole (and a Raspberry Pi) with Netdata + +import { OneLineInstallWget } from '@site/src/components/OneLineInstall/' + +Between intrusive ads, invasive trackers, and vicious malware, many techies and homelab enthusiasts are advancing their +networks' security and speed with a tiny computer and a powerful piece of software: [Pi-hole](https://pi-hole.net/). + +Pi-hole is a DNS sinkhole that prevents unwanted content from even reaching devices on your home network. It blocks ads +and malware at the network, instead of using extensions/add-ons for individual browsers, so you'll stop seeing ads in +some of the most intrusive places, like your smart TV. Pi-hole can even [improve your network's speed and reduce +bandwidth](https://discourse.pi-hole.net/t/will-pi-hole-slow-down-my-network/2048). + +Most Pi-hole users run it on a [Raspberry Pi](https://www.raspberrypi.org/products/raspberry-pi-4-model-b/) (hence the +name), a credit card-sized, super-capable computer that costs about $35. + +And to keep tabs on how both Pi-hole and the Raspberry Pi are working to protect your network, you can use the +open-source [Netdata monitoring agent](https://github.com/netdata/netdata). + +To get started, all you need is a [Raspberry Pi](https://www.raspberrypi.org/products/raspberry-pi-4-model-b/) with +Raspbian installed. This guide uses a Raspberry Pi 4 Model B and Raspbian GNU/Linux 10 (buster). This guide assumes +you're connecting to a Raspberry Pi remotely over SSH, but you could also complete all these steps on the system +directly using a keyboard, mouse, and monitor. + +## Why monitor Pi-hole and a Raspberry Pi with Netdata? + +Netdata helps you monitor and troubleshoot all kinds of devices and the applications they run, including IoT devices +like the Raspberry Pi and applications like Pi-hole. + +After a two-minute installation and with zero configuration, you'll be able to see all of Pi-hole's metrics, including +the volume of queries, connected clients, DNS queries per type, top clients, top blocked domains, and more. + +With Netdata installed, you can also monitor system metrics and any other applications you might be running. By default, +Netdata collects metrics on CPU usage, disk IO, bandwidth, per-application resource usage, and a ton more. With the +Raspberry Pi used for this guide, Netdata automatically collects about 1,500 metrics every second! + + + +## Install Netdata + +Let's start by installing Netdata first so that it can start collecting system metrics as soon as possible for the most +possible historic data. + +> ⚠️ Don't install Netdata using `apt` and the default package available in Raspbian. The Netdata team does not maintain +> this package, and can't guarantee it works properly. + +On Raspberry Pis running Raspbian, the best way to install Netdata is our one-line kickstart script. This script asks +you to install dependencies, then compiles Netdata from source via [GitHub](https://github.com/netdata/netdata). + +<OneLineInstallWget/> + +Once installed on a Raspberry Pi 4 with no accessories, Netdata starts collecting roughly 1,500 metrics every second and +populates its dashboard with more than 250 charts. + +Open your browser of choice and navigate to `http://NODE:19999/`, replacing `NODE` with the IP address of your Raspberry +Pi. Not sure what that IP is? Try running `hostname -I | awk '{print $1}'` from the Pi itself. + +You'll see Netdata's dashboard and a few hundred real-time, interactive charts. Feel free to explore, but let's turn our attention to installing Pi-hole. + +## Install Pi-Hole + +Like Netdata, Pi-hole has a one-line script for simple installation. From your Raspberry Pi, run the following: + +```bash +curl -sSL https://install.pi-hole.net | bash +``` + +The installer will help you set up Pi-hole based on the topology of your network. Once finished, you should set up your +devices—or your router for system-wide sinkhole protection—to [use Pi-hole as their DNS +service](https://discourse.pi-hole.net/t/how-do-i-configure-my-devices-to-use-pi-hole-as-their-dns-server/245). You've +finished setting up Pi-hole at this point. + +As far as configuring Netdata to monitor Pi-hole metrics, there's nothing you actually need to do. Netdata's [Pi-hole +collector](https://github.com/netdata/go.d.plugin/blob/master/modules/pihole/README.md) will autodetect the new service +running on your Raspberry Pi and immediately start collecting metrics every second. + +Restart Netdata with `sudo systemctl restart netdata`, which will then recognize that Pi-hole is running and start a +per-second collection job. When you refresh your Netdata dashboard or load it up again in a new tab, you'll see a new +entry in the menu for **Pi-hole** metrics. + +## Use Netdata to explore and monitor your Raspberry Pi and Pi-hole + +By the time you've reached this point in the guide, Netdata has already collected a ton of valuable data about your +Raspberry Pi, Pi-hole, and any other apps/services you might be running. Even a few minutes of collecting 1,500 metrics +per second adds up quickly. + +You can now use Netdata's synchronized charts to zoom, highlight, scrub through time, and discern how an anomaly in one +part of your system might affect another. + + + +If you're completely new to Netdata, look at the [Introduction](https://github.com/netdata/netdata/blob/master/docs/getting-started/introduction.md) section for a walkthrough of all its features. For a more expedited tour, see the [get started documentation](https://github.com/netdata/netdata/blob/master/packaging/installer/README.md). + +### Enable temperature sensor monitoring + +You need to manually enable Netdata's built-in [temperature sensor +collector](https://github.com/netdata/netdata/blob/master/collectors/charts.d.plugin/sensors/README.md) to start collecting metrics. + +> Netdata uses a few plugins to manage its [collectors](https://github.com/netdata/netdata/blob/master/collectors/REFERENCE.md), each using a different language: Go, +> Python, Node.js, and Bash. While our Go collectors are undergoing the most active development, we still support the +> other languages. In this case, you need to enable a temperature sensor collector that's written in Bash. + +First, open the `charts.d.conf` file for editing. You should always use the `edit-config` script to edit Netdata's +configuration files, as it ensures your settings persist across updates to the Netdata Agent. + +```bash +cd /etc/netdata +sudo ./edit-config charts.d.conf +``` + +Uncomment the `sensors=force` line and save the file. Restart Netdata with `sudo systemctl restart netdata` to enable +Raspberry Pi temperature sensor monitoring. + +### Storing historical metrics on your Raspberry Pi + +By default, Netdata allocates 256 MiB in disk space to store historical metrics inside the [database +engine](https://github.com/netdata/netdata/blob/master/database/engine/README.md). On the Raspberry Pi used for this guide, Netdata collects 1,500 metrics every +second, which equates to storing 3.5 days worth of historical metrics. + +You can increase this allocation by editing `netdata.conf` and increasing the `dbengine multihost disk space` setting to +more than 256. + +```yaml +[global] + dbengine multihost disk space = 512 +``` + +Use our [database sizing +calculator](https://github.com/netdata/netdata/blob/master/docs/store/change-metrics-storage.md#calculate-the-system-resources-ram-disk-space-needed-to-store-metrics) +and the [Database configuration documentation](https://github.com/netdata/netdata/blob/master/database/README.md) to help you determine the right +setting for your Raspberry Pi. diff --git a/docs/guides/monitor/process.md b/docs/guides/monitor/process.md new file mode 100644 index 00000000..9aa6911f --- /dev/null +++ b/docs/guides/monitor/process.md @@ -0,0 +1,270 @@ +<!-- +title: Monitor any process in real-time with Netdata +sidebar_label: Monitor any process in real-time with Netdata +description: "Tap into Netdata's powerful collectors, with per-second utilization metrics for every process, to troubleshoot faster and make data-informed decisions." +image: /img/seo/guides/monitor/process.png +custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/guides/monitor/process.md +learn_status: "Published" +learn_rel_path: "Operations" +--> + +# Monitor any process in real-time with Netdata + +Netdata is more than a multitude of generic system-level metrics and visualizations. Instead of providing only a bird's +eye view of your system, leaving you to wonder exactly _what_ is taking up 99% CPU, Netdata also gives you visibility +into _every layer_ of your node. These additional layers give you context, and meaningful insights, into the true health +and performance of your infrastructure. + +One of these layers is the _process_. Every time a Linux system runs a program, it creates an independent process that +executes the program's instructions in parallel with anything else happening on the system. Linux systems track the +state and resource utilization of processes using the [`/proc` filesystem](https://en.wikipedia.org/wiki/Procfs), and +Netdata is designed to hook into those metrics to create meaningful visualizations out of the box. + +While there are a lot of existing command-line tools for tracking processes on Linux systems, such as `ps` or `top`, +only Netdata provides dozens of real-time charts, at both per-second and event frequency, without you having to write +SQL queries or know a bunch of arbitrary command-line flags. + +With Netdata's process monitoring, you can: + +- Benchmark/optimize performance of standard applications, like web servers or databases +- Benchmark/optimize performance of custom applications +- Troubleshoot CPU/memory/disk utilization issues (why is my system's CPU spiking right now?) +- Perform granular capacity planning based on the specific needs of your infrastructure +- Search for leaking file descriptors +- Investigate zombie processes + +... and much more. Let's get started. + +## Prerequisites + +- One or more Linux nodes running [Netdata](https://github.com/netdata/netdata/blob/master/packaging/installer/README.md) +- A general understanding of how + to [configure the Netdata Agent](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md) + using `edit-config`. +- A Netdata Cloud account. [Sign up](https://app.netdata.cloud) if you don't have one already. + +## How does Netdata do process monitoring? + +The Netdata Agent already knows to look for hundreds +of [standard applications that we support via collectors](https://github.com/netdata/netdata/blob/master/collectors/COLLECTORS.md), +and groups them based on their +purpose. Let's say you want to monitor a MySQL +database using its process. The Netdata Agent already knows to look for processes with the string `mysqld` in their +name, along with a few others, and puts them into the `sql` group. This `sql` group then becomes a dimension in all +process-specific charts. + +The process and groups settings are used by two unique and powerful collectors. + +[**`apps.plugin`**](https://github.com/netdata/netdata/blob/master/collectors/apps.plugin/README.md) looks at the Linux +process tree every second, much like `top` or +`ps fax`, and collects resource utilization information on every running process. It then automatically adds a layer of +meaningful visualization on top of these metrics, and creates per-process/application charts. + +[**`ebpf.plugin`**](https://github.com/netdata/netdata/blob/master/collectors/ebpf.plugin/README.md): Netdata's extended +Berkeley Packet Filter (eBPF) collector +monitors Linux kernel-level metrics for file descriptors, virtual filesystem IO, and process management, and then hands +process-specific metrics over to `apps.plugin` for visualization. The eBPF collector also collects and visualizes +metrics on an _event frequency_, which means it captures every kernel interaction, and not just the volume of +interaction at every second in time. That's even more precise than Netdata's standard per-second granularity. + +### Per-process metrics and charts in Netdata + +With these collectors working in parallel, Netdata visualizes the following per-second metrics for _any_ process on your +Linux systems: + +- CPU utilization (`apps.cpu`) + - Total CPU usage + - User/system CPU usage (`apps.cpu_user`/`apps.cpu_system`) +- Disk I/O + - Physical reads/writes (`apps.preads`/`apps.pwrites`) + - Logical reads/writes (`apps.lreads`/`apps.lwrites`) + - Open unique files (if a file is found open multiple times, it is counted just once, `apps.files`) +- Memory + - Real Memory Used (non-shared, `apps.mem`) + - Virtual Memory Allocated (`apps.vmem`) + - Minor page faults (i.e. memory activity, `apps.minor_faults`) +- Processes + - Threads running (`apps.threads`) + - Processes running (`apps.processes`) + - Carried over uptime (since the last Netdata Agent restart, `apps.uptime`) + - Minimum uptime (`apps.uptime_min`) + - Average uptime (`apps.uptime_average`) + - Maximum uptime (`apps.uptime_max`) + - Pipes open (`apps.pipes`) +- Swap memory + - Swap memory used (`apps.swap`) + - Major page faults (i.e. swap activity, `apps.major_faults`) +- Network + - Sockets open (`apps.sockets`) +- eBPF file + - Number of calls to open files. (`apps.file_open`) + - Number of files closed. (`apps.file_closed`) + - Number of calls to open files that returned errors. + - Number of calls to close files that returned errors. +- eBPF syscall + - Number of calls to delete files. (`apps.file_deleted`) + - Number of calls to `vfs_write`. (`apps.vfs_write_call`) + - Number of calls to `vfs_read`. (`apps.vfs_read_call`) + - Number of bytes written with `vfs_write`. (`apps.vfs_write_bytes`) + - Number of bytes read with `vfs_read`. (`apps.vfs_read_bytes`) + - Number of calls to write a file that returned errors. + - Number of calls to read a file that returned errors. +- eBPF process + - Number of process created with `do_fork`. (`apps.process_create`) + - Number of threads created with `do_fork` or `__x86_64_sys_clone`, depending on your system's kernel + version. (`apps.thread_create`) + - Number of times that a process called `do_exit`. (`apps.task_close`) +- eBPF net + - Number of bytes sent. (`apps.bandwidth_sent`) + - Number of bytes received. (`apps.bandwidth_recv`) + +As an example, here's the per-process CPU utilization chart, including a `sql` group/dimension. + + + +## Configure the Netdata Agent to recognize a specific process + +To monitor any process, you need to make sure the Netdata Agent is aware of it. As mentioned above, the Agent is already +aware of hundreds of processes, and collects metrics from them automatically. + +But, if you want to change the grouping behavior, add an application that isn't yet supported in the Netdata Agent, or +monitor a custom application, you need to edit the `apps_groups.conf` configuration file. + +Navigate to your [Netdata config directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md) and +use `edit-config` to edit the file. + +```bash +cd /etc/netdata # Replace this with your Netdata config directory if not at /etc/netdata. +sudo ./edit-config apps_groups.conf +``` + +Inside the file are lists of process names, oftentimes using wildcards (`*`), that the Netdata Agent looks for and +groups together. For example, the Netdata Agent looks for processes starting with `mysqld`, `mariad`, `postgres`, and +others, and groups them into `sql`. That makes sense, since all these processes are for SQL databases. + +```conf +sql: mysqld* mariad* postgres* postmaster* oracle_* ora_* sqlservr +``` + +These groups are then reflected as [dimensions](https://github.com/netdata/netdata/blob/master/web/README.md#dimensions) +within Netdata's charts. + + + +See the following two sections for details based on your needs. If you don't need to configure `apps_groups.conf`, jump +down to [visualizing process metrics](#visualize-process-metrics). + +### Standard applications (web servers, databases, containers, and more) + +As explained above, the Netdata Agent is already aware of most standard applications you run on Linux nodes, and you +shouldn't need to configure it to discover them. + +However, if you're using multiple applications that the Netdata Agent groups together you may want to separate them for +more precise monitoring. If you're not running any other types of SQL databases on that node, you don't need to change +the grouping, since you know that any MySQL is the only process contributing to the `sql` group. + +Let's say you're using both MySQL and PostgreSQL databases on a single node, and want to monitor their processes +independently. Open the `apps_groups.conf` file as explained in +the [section above](#configure-the-netdata-agent-to-recognize-a-specific-process) and scroll down until you find +the `database servers` section. Create new groups for MySQL and PostgreSQL, and move their process queries into the +unique groups. + +```conf +# ----------------------------------------------------------------------------- +# database servers + +mysql: mysqld* +postgres: postgres* +sql: mariad* postmaster* oracle_* ora_* sqlservr +``` + +Restart Netdata with `sudo systemctl restart netdata`, or +the [appropriate method](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md) for your system, to start collecting utilization metrics +from your application. Time to [visualize your process metrics](#visualize-process-metrics). + +### Custom applications + +Let's assume you have an application that runs on the process `custom-app`. To monitor eBPF metrics for that application +separate from any others, you need to create a new group in `apps_groups.conf` and associate that process name with it. + +Open the `apps_groups.conf` file as explained in +the [section above](#configure-the-netdata-agent-to-recognize-a-specific-process). Scroll down +to `# NETDATA processes accounting`. +Above that, paste in the following text, which creates a new `custom-app` group with the `custom-app` process. Replace +`custom-app` with the name of your application's Linux process. `apps_groups.conf` should now look like this: + +```conf +... +# ----------------------------------------------------------------------------- +# Custom applications to monitor with apps.plugin and ebpf.plugin + +custom-app: custom-app + +# ----------------------------------------------------------------------------- +# NETDATA processes accounting +... +``` + +Restart Netdata with `sudo systemctl restart netdata`, or +the [appropriate method](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md) for your system, to start collecting utilization metrics +from your application. + +## Visualize process metrics + +Now that you're collecting metrics for your process, you'll want to visualize them using Netdata's real-time, +interactive charts. Find these visualizations in the same section regardless of whether you +use [Netdata Cloud](https://app.netdata.cloud) for infrastructure monitoring, or single-node monitoring with the local +Agent's dashboard at `http://localhost:19999`. + +If you need a refresher on all the available per-process charts, see +the [above list](#per-process-metrics-and-charts-in-netdata). + +### Using Netdata's application collector (`apps.plugin`) + +`apps.plugin` puts all of its charts under the **Applications** section of any Netdata dashboard. + + + +Let's continue with the MySQL example. We can create a [test +database](https://www.digitalocean.com/community/tutorials/how-to-measure-mysql-query-performance-with-mysqlslap) in +MySQL to generate load on the `mysql` process. + +`apps.plugin` immediately collects and visualizes this activity `apps.cpu` chart, which shows an increase in CPU +utilization from the `sql` group. There is a parallel increase in `apps.pwrites`, which visualizes writes to disk. + + + + + +Next, the `mysqlslap` utility queries the database to provide some benchmarking load on the MySQL database. It won't +look exactly like a production database executing lots of user queries, but it gives you an idea into the possibility of +these visualizations. + +```bash +sudo mysqlslap --user=sysadmin --password --host=localhost --concurrency=50 --iterations=10 --create-schema=employees --query="SELECT * FROM dept_emp;" --verbose +``` + +The following per-process disk utilization charts show spikes under the `sql` group at the same time `mysqlslap` was run +numerous times, with slightly different concurrency and query options. + + + +> 💡 Click on any dimension below a chart in Netdata Cloud (or to the right of a chart on a local Agent dashboard), to +> visualize only that dimension. This can be particularly useful in process monitoring to separate one process' +> utilization from the rest of the system. + +### Using Netdata's eBPF collector (`ebpf.plugin`) + +Netdata's eBPF collector puts its charts in two places. Of most importance to process monitoring are the **ebpf file**, +**ebpf syscall**, **ebpf process**, and **ebpf net** sub-sections under **Applications**, shown in the above screenshot. + +For example, running the above workload shows the entire "story" how MySQL interacts with the Linux kernel to open +processes/threads to handle a large number of SQL queries, then subsequently close the tasks as each query returns the +relevant data. + + + +`ebpf.plugin` visualizes additional eBPF metrics, which are system-wide and not per-process, under the **eBPF** section. + + diff --git a/docs/guides/monitor/raspberry-pi-anomaly-detection.md b/docs/guides/monitor/raspberry-pi-anomaly-detection.md new file mode 100644 index 00000000..935d0f6c --- /dev/null +++ b/docs/guides/monitor/raspberry-pi-anomaly-detection.md @@ -0,0 +1,96 @@ +# Anomaly detection for RPi monitoring + +Learn how to use a low-overhead machine learning algorithm alongside Netdata to detect anomalous metrics on a Raspberry Pi. + +We love IoT and edge at Netdata, we also love machine learning. Even better if we can combine the two to ease the pain +of monitoring increasingly complex systems. + +We recently explored what might be involved in enabling our Python-based [anomalies +collector](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/anomalies/README.md) on a Raspberry Pi. To our delight, it's actually quite +straightforward! + +Read on to learn all the steps and enable unsupervised anomaly detection on your on Raspberry Pi(s). + +> Spoiler: It's just a couple of extra commands that will make you feel like a pro. + +## What you need to get started + +- A Raspberry Pi running Raspbian, which we'll call a _node_. +- The [open-source Netdata](https://github.com/netdata/netdata) monitoring agent. If you don't have it installed on your + node yet, [get started now](https://github.com/netdata/netdata/blob/master/packaging/installer/README.md). + +## Install dependencies + +First make sure Netdata is using Python 3 when it runs Python-based data collectors. + +Next, open `netdata.conf` using [`edit-config`](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md#use-edit-config-to-edit-configuration-files) +from within the [Netdata config directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md#the-netdata-config-directory). Scroll down to the +`[plugin:python.d]` section to pass in the `-ppython3` command option. + +```conf +[plugin:python.d] + # update every = 1 + command options = -ppython3 +``` + +Next, install some of the underlying libraries used by the Python packages the collector depends upon. + +```bash +sudo apt install llvm-9 libatlas3-base libgfortran5 libatlas-base-dev +``` + +Now you're ready to install the Python packages used by the collector itself. First, become the `netdata` user. + +```bash +sudo su -s /bin/bash netdata +``` + +Then pass in the location to find `llvm` as an environment variable for `pip3`. + +```bash +LLVM_CONFIG=llvm-config-9 pip3 install --user llvmlite numpy==1.20.1 netdata-pandas==0.0.38 numba==0.50.1 scikit-learn==0.23.2 pyod==0.8.3 +``` + +## Enable the anomalies collector + +Now you're ready to enable the collector and [restart Netdata](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md). + +```bash +sudo ./edit-config python.d.conf + +# restart netdata +sudo systemctl restart netdata +``` + +And that should be it! Wait a minute or two, refresh your Netdata dashboard, you should see the default anomalies +charts under the **Anomalies** section in the dashboard's menu. + + + +## Overhead on system + +Of course one of the most important considerations when trying to do anomaly detection at the edge (as opposed to in a +centralized cloud somewhere) is the resource utilization impact of running a monitoring tool. + +With the default configuration, the anomalies collector uses about 6.5% of CPU at each run. During the retraining step, +CPU utilization jumps to between 20-30% for a few seconds, but you can [configure +retraining](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/anomalies/README.md#configuration) to happen less often if you wish. + +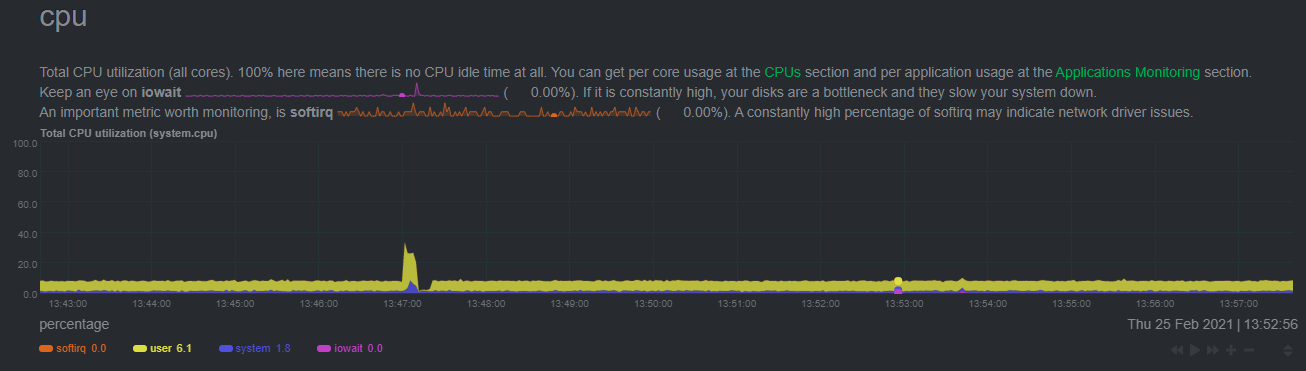 + +In terms of the runtime of the collector, it was averaging around 250ms during each prediction step, jumping to about +8-10 seconds during a retraining step. This jump equates only to a small gap in the anomaly charts for a few seconds. + + + +The last consideration then is the amount of RAM the collector needs to store both the models and some of the data +during training. By default, the anomalies collector, along with all other running Python-based collectors, uses about +100MB of system memory. + + + + diff --git a/docs/guides/python-collector.md b/docs/guides/python-collector.md new file mode 100644 index 00000000..d89eb25e --- /dev/null +++ b/docs/guides/python-collector.md @@ -0,0 +1,626 @@ +# Develop a custom data collector in Python + +The Netdata Agent uses [data collectors](https://github.com/netdata/netdata/blob/master/collectors/README.md) to +fetch metrics from hundreds of system, container, and service endpoints. While the Netdata team and community has built +[powerful collectors](https://github.com/netdata/netdata/blob/master/collectors/COLLECTORS.md) for most system, container, +and service/application endpoints, some custom applications can't be monitored by default. + +In this tutorial, you'll learn how to leverage the [Python programming language](https://www.python.org/) to build a +custom data collector for the Netdata Agent. Follow along with your own dataset, using the techniques and best practices +covered here, or use the included examples for collecting and organizing either random or weather data. + +## Disclaimer + +If you're comfortable with Golang, consider instead writing a module for the [go.d.plugin](https://github.com/netdata/go.d.plugin). +Golang is more performant, easier to maintain, and simpler for users since it doesn't require a particular runtime on the node to +execute. Python plugins require Python on the machine to be executed. Netdata uses Go as the platform of choice for +production-grade collectors. + +We generally do not accept contributions of Python modules to the GitHub project netdata/netdata. If you write a Python collector and +want to make it available for other users, you should create the pull request in https://github.com/netdata/community. + +## What you need to get started + + - A physical or virtual Linux system, which we'll call a _node_. + - A working [installation of Netdata](https://github.com/netdata/netdata/blob/master/packaging/installer/README.md) monitoring agent. + +### Quick start + +For a quick start, you can look at the +[example plugin](https://raw.githubusercontent.com/netdata/netdata/master/collectors/python.d.plugin/example/example.chart.py). + +**Note**: If you are working 'locally' on a new collector and would like to run it in an already installed and running +Netdata (as opposed to having to install Netdata from source again with your new changes) you can copy over the relevant +file to where Netdata expects it and then either `sudo systemctl restart netdata` to have it be picked up and used by +Netdata or you can just run the updated collector in debug mode by following a process like below (this assumes you have +[installed Netdata from a GitHub fork](https://github.com/netdata/netdata/blob/master/packaging/installer/methods/manual.md) you +have made to do your development on). + +```bash +# clone your fork (done once at the start but shown here for clarity) +#git clone --branch my-example-collector https://github.com/mygithubusername/netdata.git --depth=100 --recursive +# go into your netdata source folder +cd netdata +# git pull your latest changes (assuming you built from a fork you are using to develop on) +git pull +# instead of running the installer we can just copy over the updated collector files +#sudo ./netdata-installer.sh --dont-wait +# copy over the file you have updated locally (pretending we are working on the 'example' collector) +sudo cp collectors/python.d.plugin/example/example.chart.py /usr/libexec/netdata/python.d/ +# become user netdata +sudo su -s /bin/bash netdata +# run your updated collector in debug mode to see if it works without having to reinstall netdata +/usr/libexec/netdata/plugins.d/python.d.plugin example debug trace nolock +``` + +## Jobs and elements of a Python collector + +A Python collector for Netdata is a Python script that gathers data from an external source and transforms these data +into charts to be displayed by Netdata dashboard. The basic jobs of the plugin are: + +- Gather the data from the service/application. +- Create the required charts. +- Parse the data to extract or create the actual data to be represented. +- Assign the correct values to the charts +- Set the order for the charts to be displayed. +- Give the charts data to Netdata for visualization. + +The basic elements of a Netdata collector are: + +- `ORDER[]`: A list containing the charts to be displayed. +- `CHARTS{}`: A dictionary containing the details for the charts to be displayed. +- `data{}`: A dictionary containing the values to be displayed. +- `get_data()`: The basic function of the plugin which will return to Netdata the correct values. + +**Note**: All names are better explained in the +[External Plugins Documentation](https://github.com/netdata/netdata/blob/master/collectors/plugins.d/README.md). +Parameters like `priority` and `update_every` mentioned in that documentation are handled by the `python.d.plugin`, +not by each collection module. + +Let's walk through these jobs and elements as independent elements first, then apply them to example Python code. + +### Determine how to gather metrics data + +Netdata can collect data from any program that can print to stdout. Common input sources for collectors can be logfiles, +HTTP requests, executables, and more. While this tutorial will offer some example inputs, your custom application will +have different inputs and metrics. + +A great deal of the work in developing a Netdata collector is investigating the target application and understanding +which metrics it exposes and how to + +### Create charts + +For the data to be represented in the Netdata dashboard, you need to create charts. Charts (in general) are defined by +several characteristics: title, legend, units, type, and presented values. Each chart is represented as a dictionary +entry: + +```python +chart= { + "chart_name": + { + "options": [option_list], + "lines": [ + [dimension_list] + ] + } + } +``` + +Use the `options` field to set the chart's options, which is a list in the form `options: [name, title, units, family, +context, charttype]`, where: + +- `name`: The name of the chart. +- `title` : The title to be displayed in the chart. +- `units` : The units for this chart. +- `family`: An identifier used to group charts together (can be null). +- `context`: An identifier used to group contextually similar charts together. The best practice is to provide a context + that is `A.B`, with `A` being the name of the collector, and `B` being the name of the specific metric. +- `charttype`: Either `line`, `area`, or `stacked`. If null line is the default value. + +You can read more about `family` and `context` in the [web dashboard](https://github.com/netdata/netdata/blob/master/web/README.md#families) doc. + +Once the chart has been defined, you should define the dimensions of the chart. Dimensions are basically the metrics to +be represented in this chart and each chart can have more than one dimension. In order to define the dimensions, the +"lines" list should be filled in with the required dimensions. Each dimension is a list: + +`dimension: [id, name, algorithm, multiplier, divisor]` +- `id` : The id of the dimension. Mandatory unique field (string) required in order to set a value. +- `name`: The name to be presented in the chart. If null id will be used. +- `algorithm`: Can be absolute or incremental. If null absolute is used. Incremental shows the difference from the + previous value. +- `multiplier`: an integer value to divide the collected value, if null, 1 is used +- `divisor`: an integer value to divide the collected value, if null, 1 is used + +The multiplier/divisor fields are used in cases where the value to be displayed should be decimal since Netdata only +gathers integer values. + +### Parse the data to extract or create the actual data to be represented + +Once the data is received, your collector should process it in order to get the values required. If, for example, the +received data is a JSON string, you should parse the data to get the required data to be used for the charts. + +### Assign the correct values to the charts + +Once you have process your data and get the required values, you need to assign those values to the charts you created. +This is done using the `data` dictionary, which is in the form: + +`"data": {dimension_id: value }`, where: +- `dimension_id`: The id of a defined dimension in a created chart. +- `value`: The numerical value to associate with this dimension. + +### Set the order for the charts to be displayed + +Next, set the order of chart appearance with the `ORDER` list, which is in the form: + +`"ORDER": [chart_name_1,chart_name_2, …., chart_name_X]`, where: +- `chart_name_x`: is the chart name to be shown in X order. + +### Give the charts data to Netdata for visualization + +Our plugin should just rerun the data dictionary. If everything is set correctly the charts should be updated with the +correct values. + +## Framework classes + +Every module needs to implement its own `Service` class. This class should inherit from one of the framework classes: + +- `SimpleService` +- `UrlService` +- `SocketService` +- `LogService` +- `ExecutableService` + +Also it needs to invoke the parent class constructor in a specific way as well as assign global variables to class variables. + +For example, the snippet below is from the +[RabbitMQ collector](https://github.com/netdata/netdata/blob/91f3268e9615edd393bd43de4ad8068111024cc9/collectors/python.d.plugin/rabbitmq/rabbitmq.chart.py#L273). +This collector uses an HTTP endpoint and uses the `UrlService` framework class, which only needs to define an HTTP +endpoint for data collection. + +```python +class Service(UrlService): + def __init__(self, configuration=None, name=None): + UrlService.__init__(self, configuration=configuration, name=name) + self.order = ORDER + self.definitions = CHARTS + self.url = '{0}://{1}:{2}'.format( + configuration.get('scheme', 'http'), + configuration.get('host', '127.0.0.1'), + configuration.get('port', 15672), + ) + self.node_name = str() + self.vhost = VhostStatsBuilder() + self.collected_vhosts = set() + self.collect_queues_metrics = configuration.get('collect_queues_metrics', False) + self.debug("collect_queues_metrics is {0}".format("enabled" if self.collect_queues_metrics else "disabled")) + if self.collect_queues_metrics: + self.queue = QueueStatsBuilder() + self.collected_queues = set() +``` + +In our use-case, we use the `SimpleService` framework, since there is no framework class that suits our needs. + +You can find below the [framework class reference](#framework-class-reference). + +## An example collector using weather station data + +Let's build a custom Python collector for visualizing data from a weather monitoring station. + +### Determine how to gather metrics data + +This example assumes you can gather metrics data through HTTP requests to a web server, and that the data provided are +numeric values for temperature, humidity and pressure. It also assumes you can get the `min`, `max`, and `average` +values for these metrics. + +### Chart creation + +First, create a single chart that shows the latest temperature metric: + +```python +CHARTS = { + "temp_current": { + "options": ["my_temp", "Temperature", "Celsius", "TEMP", "weather_station.temperature", "line"], + "lines": [ + ["current_temp_id","current_temperature"] + ] + } +} +``` + +## Parse the data to extract or create the actual data to be represented + +Every collector must implement `_get_data`. This method should grab raw data from `_get_raw_data`, +parse it, and return a dictionary where keys are unique dimension names, or `None` if no data is collected. + +For example: +```py +def _get_data(self): + try: + raw = self._get_raw_data().split(" ") + return {'active': int(raw[2])} + except (ValueError, AttributeError): + return None +``` + +In our weather data collector we declare `_get_data` as follows: + +```python + def get_data(self): + #The data dict is basically all the values to be represented + # The entries are in the format: { "dimension": value} + #And each "dimension" should belong to a chart. + data = dict() + + self.populate_data() + + data['current_temperature'] = self.weather_data["temp"] + + return data +``` + +A standard practice would be to either get the data on JSON format or transform them to JSON format. We use a dictionary +to give this format and issue random values to simulate received data. + +The following code iterates through the names of the expected values and creates a dictionary with the name of the value +as `key`, and a random value as `value`. + +```python + weather_data=dict() + weather_metrics=[ + "temp","av_temp","min_temp","max_temp", + "humid","av_humid","min_humid","max_humid", + "pressure","av_pressure","min_pressure","max_pressure", + ] + + def populate_data(self): + for metric in self.weather_metrics: + self.weather_data[metric]=random.randint(0,100) +``` + +### Assign the correct values to the charts + +Our chart has a dimension called `current_temp_id`, which should have the temperature value received. + +```python +data['current_temp_id'] = self.weather_data["temp"] +``` + +### Set the order for the charts to be displayed + +```python +ORDER = [ + "temp_current" +] +``` + +### Give the charts data to Netdata for visualization + +```python +return data +``` + +A snapshot of the chart created by this plugin: + + + +Here's the current source code for the data collector: + +```python +# -*- coding: utf-8 -*- +# Description: howto weather station netdata python.d module +# Author: Panagiotis Papaioannou (papajohn-uop) +# SPDX-License-Identifier: GPL-3.0-or-later + +from bases.FrameworkServices.SimpleService import SimpleService + +import random + +NETDATA_UPDATE_EVERY=1 +priority = 90000 + +ORDER = [ + "temp_current" +] + +CHARTS = { + "temp_current": { + "options": ["my_temp", "Temperature", "Celsius", "TEMP", "weather_station.temperature", "line"], + "lines": [ + ["current_temperature"] + ] + } +} + +class Service(SimpleService): + def __init__(self, configuration=None, name=None): + SimpleService.__init__(self, configuration=configuration, name=name) + self.order = ORDER + self.definitions = CHARTS + #values to show at graphs + self.values=dict() + + @staticmethod + def check(): + return True + + weather_data=dict() + weather_metrics=[ + "temp","av_temp","min_temp","max_temp", + "humid","av_humid","min_humid","max_humid", + "pressure","av_pressure","min_pressure","max_pressure", + ] + + def logMe(self,msg): + self.debug(msg) + + def populate_data(self): + for metric in self.weather_metrics: + self.weather_data[metric]=random.randint(0,100) + + def get_data(self): + #The data dict is basically all the values to be represented + # The entries are in the format: { "dimension": value} + #And each "dimension" should belong to a chart. + data = dict() + + self.populate_data() + + data['current_temperature'] = self.weather_data["temp"] + + return data +``` + +## Add more charts to the existing weather station collector + +To enrich the example, add another chart the collector which to present the humidity metric. + +Add a new entry in the `CHARTS` dictionary with the definition for the new chart. + +```python +CHARTS = { + 'temp_current': { + 'options': ['my_temp', 'Temperature', 'Celsius', 'TEMP', 'weather_station.temperature', 'line'], + 'lines': [ + ['current_temperature'] + ] + }, + 'humid_current': { + 'options': ['my_humid', 'Humidity', '%', 'HUMIDITY', 'weather_station.humidity', 'line'], + 'lines': [ + ['current_humidity'] + ] + } +} +``` + +The data has already been created and parsed by the `weather_data=dict()` function, so you only need to populate the +`current_humidity` dimension `self.weather_data["humid"]`. + +```python + data['current_temperature'] = self.weather_data["temp"] + data['current_humidity'] = self.weather_data["humid"] +``` + +Next, put the new `humid_current` chart into the `ORDER` list: + +```python +ORDER = [ + 'temp_current', + 'humid_current' +] +``` + +[Restart Netdata](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md) with `sudo systemctl restart netdata` to see the new humidity +chart: + + + +Next, time to add one more chart that visualizes the average, minimum, and maximum temperature values. + +Add a new entry in the `CHARTS` dictionary with the definition for the new chart. Since you want three values +represented in this this chart, add three dimensions. You should also use the same `FAMILY` value in the charts (`TEMP`) +so that those two charts are grouped together. + +```python +CHARTS = { + 'temp_current': { + 'options': ['my_temp', 'Temperature', 'Celsius', 'TEMP', 'weather_station.temperature', 'line'], + 'lines': [ + ['current_temperature'] + ] + }, + 'temp_stats': { + 'options': ['stats_temp', 'Temperature', 'Celsius', 'TEMP', 'weather_station.temperature_stats', 'line'], + 'lines': [ + ['min_temperature'], + ['max_temperature'], + ['avg_temperature'] + ] + }, + 'humid_current': { + 'options': ['my_humid', 'Humidity', '%', 'HUMIDITY', 'weather_station.humidity', 'line'], + 'lines': [ + ['current_humidity'] + ] + } + +} +``` + +As before, initiate new dimensions and add data to them: + +```python + data['current_temperature'] = self.weather_data["temp"] + data['min_temperature'] = self.weather_data["min_temp"] + data['max_temperature'] = self.weather_data["max_temp"] + data['avg_temperature`'] = self.weather_data["av_temp"] + data['current_humidity'] = self.weather_data["humid"] +``` + +Finally, set the order for the `temp_stats` chart: + +```python +ORDER = [ + 'temp_current', + ‘temp_stats’ + 'humid_current' +] +``` + +[Restart Netdata](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md) with `sudo systemctl restart netdata` to see the new +min/max/average temperature chart with multiple dimensions: + + + +## Add a configuration file + +The last piece of the puzzle to create a fully robust Python collector is the configuration file. Python.d uses +configuration in [YAML](https://www.tutorialspoint.com/yaml/yaml_basics.htm) format and is used as follows: + +- Create a configuration file in the same directory as the `<plugin_name>.chart.py`. Name it `<plugin_name>.conf`. +- Define a `job`, which is an instance of the collector. It is useful when you want to collect data from different + sources with different attributes. For example, we could gather data from 2 different weather stations, which use + different temperature measures: Fahrenheit and Celsius. +- You can define many different jobs with the same name, but with different attributes. Netdata will try each job + serially and will stop at the first job that returns data. If multiple jobs have the same name, only one of them can + run. This enables you to define different "ways" to fetch data from a particular data source so that the collector has + more chances to work out-of-the-box. For example, if the data source supports both `HTTP` and `linux socket`, you can + define 2 jobs named `local`, with each using a different method. +- Check the `example` collector configuration file on + [GitHub](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/example/example.conf) to get a + sense of the structure. + +```yaml +weather_station_1: + name: 'Greece' + endpoint: 'https://endpoint_1.com' + port: 67 + type: 'celsius' +weather_station_2: + name: 'Florida USA' + endpoint: 'https://endpoint_2.com' + port: 67 + type: 'fahrenheit' +``` + +Next, access the above configuration variables in the `__init__` function: + +```python +def __init__(self, configuration=None, name=None): + SimpleService.__init__(self, configuration=configuration, name=name) + self.endpoint = self.configuration.get('endpoint', <default_endpoint>) +``` + +Because you initiate the `framework class` (e.g `SimpleService.__init__`), the configuration will be available +throughout the whole `Service` class of your module, as `self.configuration`. Finally, note that the `configuration.get` +function takes 2 arguments, one with the name of the configuration field and one with a default value in case it doesn't +find the configuration field. This allows you to define sane defaults for your collector. + +Moreover, when creating the configuration file, create a large comment section that describes the configuration +variables and inform the user about the defaults. For example, take a look at the `example` collector on +[GitHub](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/example/example.conf). + +You can read more about the configuration file on the [`python.d.plugin` +documentation](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/README.md). + +You can find the source code for the above examples on [GitHub](https://github.com/papajohn-uop/netdata). + +## Pull Request Checklist for Python Plugins + +Pull requests should be created in https://github.com/netdata/community. + +This is a generic checklist for submitting a new Python plugin for Netdata. It is by no means comprehensive. + +At minimum, to be buildable and testable, the PR needs to include: + +- The module itself, following proper naming conventions: `collectors/python.d.plugin/<module_dir>/<module_name>.chart.py` +- A README.md file for the plugin under `collectors/python.d.plugin/<module_dir>`. +- The configuration file for the module: `collectors/python.d.plugin/<module_dir>/<module_name>.conf`. Python config files are in YAML format, and should include comments describing what options are present. The instructions are also needed in the configuration section of the README.md +- A basic configuration for the plugin in the appropriate global config file: `collectors/python.d.plugin/python.d.conf`, which is also in YAML format. Either add a line that reads `# <module_name>: yes` if the module is to be enabled by default, or one that reads `<module_name>: no` if it is to be disabled by default. +- A makefile for the plugin at `collectors/python.d.plugin/<module_dir>/Makefile.inc`. Check an existing plugin for what this should look like. +- A line in `collectors/python.d.plugin/Makefile.am` including the above-mentioned makefile. Place it with the other plugin includes (please keep the includes sorted alphabetically). +- Optionally, chart information in `web/gui/dashboard_info.js`. This generally involves specifying a name and icon for the section, and may include descriptions for the section or individual charts. +- Optionally, some default alert configurations for your collector in `health/health.d/<module_name>.conf` and a line adding `<module_name>.conf` in `health/Makefile.am`. + +## Framework class reference + +Every framework class has some user-configurable variables which are specific to this particular class. Those variables should have default values initialized in the child class constructor. + +If module needs some additional user-configurable variable, it can be accessed from the `self.configuration` list and assigned in constructor or custom `check` method. Example: + +```py +def __init__(self, configuration=None, name=None): + UrlService.__init__(self, configuration=configuration, name=name) + try: + self.baseurl = str(self.configuration['baseurl']) + except (KeyError, TypeError): + self.baseurl = "http://localhost:5001" +``` + +Classes implement `_get_raw_data` which should be used to grab raw data. This method usually returns a list of strings. + +### `SimpleService` + +This is last resort class, if a new module cannot be written by using other framework class this one can be used. + +Example: `ceph`, `sensors` + +It is the lowest-level class which implements most of module logic, like: + +- threading +- handling run times +- chart formatting +- logging +- chart creation and updating + +### `LogService` + +Examples: `apache_cache`, `nginx_log`_ + +Variable from config file: `log_path`. + +Object created from this class reads new lines from file specified in `log_path` variable. It will check if file exists and is readable. Also `_get_raw_data` returns list of strings where each string is one line from file specified in `log_path`. + +### `ExecutableService` + +Examples: `exim`, `postfix`_ + +Variable from config file: `command`. + +This allows to execute a shell command in a secure way. It will check for invalid characters in `command` variable and won't proceed if there is one of: + +- '&' +- '|' +- ';' +- '>' +- '\<' + +For additional security it uses python `subprocess.Popen` (without `shell=True` option) to execute command. Command can be specified with absolute or relative name. When using relative name, it will try to find `command` in `PATH` environment variable as well as in `/sbin` and `/usr/sbin`. + +`_get_raw_data` returns list of decoded lines returned by `command`. + +### UrlService + +Examples: `apache`, `nginx`, `tomcat`_ + +Variables from config file: `url`, `user`, `pass`. + +If data is grabbed by accessing service via HTTP protocol, this class can be used. It can handle HTTP Basic Auth when specified with `user` and `pass` credentials. + +Please note that the config file can use different variables according to the specification of each module. + +`_get_raw_data` returns list of utf-8 decoded strings (lines). + +### SocketService + +Examples: `dovecot`, `redis` + +Variables from config file: `unix_socket`, `host`, `port`, `request`. + +Object will try execute `request` using either `unix_socket` or TCP/IP socket with combination of `host` and `port`. This can access unix sockets with SOCK_STREAM or SOCK_DGRAM protocols and TCP/IP sockets in version 4 and 6 with SOCK_STREAM setting. + +Sockets are accessed in non-blocking mode with 15 second timeout. + +After every execution of `_get_raw_data` socket is closed, to prevent this module needs to set `_keep_alive` variable to `True` and implement custom `_check_raw_data` method. + +`_check_raw_data` should take raw data and return `True` if all data is received otherwise it should return `False`. Also it should do it in fast and efficient way. diff --git a/docs/guides/troubleshoot/monitor-debug-applications-ebpf.md b/docs/guides/troubleshoot/monitor-debug-applications-ebpf.md new file mode 100644 index 00000000..f393e8e0 --- /dev/null +++ b/docs/guides/troubleshoot/monitor-debug-applications-ebpf.md @@ -0,0 +1,254 @@ +<!-- +title: "Monitor, troubleshoot, and debug applications with eBPF metrics" +sidebar_label: "Monitor, troubleshoot, and debug applications with eBPF metrics" +description: "Use Netdata's built-in eBPF metrics collector to monitor, troubleshoot, and debug your custom application using low-level kernel feedback." +image: /img/seo/guides/troubleshoot/monitor-debug-applications-ebpf.png +custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/guides/troubleshoot/monitor-debug-applications-ebpf.md +learn_status: "Published" +learn_rel_path: "Operations" +--> + +# Monitor, troubleshoot, and debug applications with eBPF metrics + +When trying to troubleshoot or debug a finicky application, there's no such thing as too much information. At Netdata, +we developed programs that connect to the [_extended Berkeley Packet Filter_ (eBPF) virtual +machine](https://github.com/netdata/netdata/blob/master/collectors/ebpf.plugin/README.md) to help you see exactly how specific applications are interacting with the +Linux kernel. With these charts, you can root out bugs, discover optimizations, diagnose memory leaks, and much more. + +This means you can see exactly how often, and in what volume, the application creates processes, opens files, writes to +filesystem using virtual filesystem (VFS) functions, and much more. Even better, the eBPF collector gathers metrics at +an _event frequency_, which is even faster than Netdata's beloved 1-second granularity. When you troubleshoot and debug +applications with eBPF, rest assured you miss not even the smallest meaningful event. + +Using this guide, you'll learn the fundamentals of setting up Netdata to give you kernel-level metrics from your +application so that you can monitor, troubleshoot, and debug to your heart's content. + +## Configure `apps.plugin` to recognize your custom application + +To start troubleshooting an application with eBPF metrics, you need to ensure your Netdata dashboard collects and +displays those metrics independent from any other process. + +You can use the `apps_groups.conf` file to configure which applications appear in charts generated by +[`apps.plugin`](https://github.com/netdata/netdata/blob/master/collectors/apps.plugin/README.md). Once you edit this file and create a new group for the application +you want to monitor, you can see how it's interacting with the Linux kernel via real-time eBPF metrics. + +Let's assume you have an application that runs on the process `custom-app`. To monitor eBPF metrics for that application +separate from any others, you need to create a new group in `apps_groups.conf` and associate that process name with it. + +Open the `apps_groups.conf` file in your Netdata configuration directory. + +```bash +cd /etc/netdata # Replace this path with your Netdata config directory +sudo ./edit-config apps_groups.conf +``` + +Scroll down past the explanatory comments and stop when you see `# NETDATA processes accounting`. Above that, paste in +the following text, which creates a new `dev` group with the `custom-app` process. Replace `custom-app` with the name of +your application's process name. + +Your file should now look like this: + +```conf +... +# ----------------------------------------------------------------------------- +# Custom applications to monitor with apps.plugin and ebpf.plugin + +dev: custom-app + +# ----------------------------------------------------------------------------- +# NETDATA processes accounting +... +``` + +Restart Netdata with `sudo systemctl restart netdata`, or the [appropriate +method](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md) for your system, to begin seeing metrics for this particular +group+process. You can also add additional processes to the same group. + +You can set up `apps_groups.conf` to more show more precise eBPF metrics for any application or service running on your +system, even if it's a standard package like Redis, Apache, or any other [application/service Netdata collects +from](https://github.com/netdata/netdata/blob/master/collectors/COLLECTORS.md). + +```conf +# ----------------------------------------------------------------------------- +# Custom applications to monitor with apps.plugin and ebpf.plugin + +dev: custom-app +database: *redis* +apache: *apache* + +# ----------------------------------------------------------------------------- +# NETDATA processes accounting +... +``` + +Now that you have `apps_groups.conf` set up to monitor your application/service, you can also set up the eBPF collector +to show other charts that will help you debug and troubleshoot how it interacts with the Linux kernel. + +## Configure the eBPF collector to monitor errors + +The eBPF collector has [two possible modes](https://github.com/netdata/netdata/blob/master/collectors/ebpf.plugin/README.md#ebpf-load-mode): `entry` and `return`. The default +is `entry`, and only monitors calls to kernel functions, but the `return` also monitors and charts _whether these calls +return in error_. + +Let's turn on the `return` mode for more granularity when debugging Firefox's behavior. + +```bash +cd /etc/netdata # Replace this path with your Netdata config directory +sudo ./edit-config ebpf.d.conf +``` + +Replace `entry` with `return`: + +```conf +[global] + ebpf load mode = return + disable apps = no + +[ebpf programs] + process = yes + network viewer = yes +``` + +Restart Netdata with `sudo systemctl restart netdata`, or the [appropriate +method](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md) for your system. + +## Get familiar with per-application eBPF metrics and charts + +Visit the Netdata dashboard at `http://NODE:19999`, replacing `NODE` with the hostname or IP of the system you're using +to monitor this application. Scroll down to the **Applications** section. These charts now feature a `firefox` dimension +with metrics specific to that process. + +Pay particular attention to the charts in the **ebpf file**, **ebpf syscall**, **ebpf process**, and **ebpf net** +sub-sections. These charts are populated by low-level Linux kernel metrics thanks to eBPF, and showcase the volume of +calls to open/close files, call functions like `do_fork`, IO activity on the VFS, and much more. + +See the [eBPF collector documentation](https://github.com/netdata/netdata/blob/master/collectors/ebpf.plugin/README.md#integration-with-appsplugin) for the full list +of per-application charts. + +Let's show some examples of how you can first identify normal eBPF patterns, then use that knowledge to identify +anomalies in a few simulated scenarios. + +For example, the following screenshot shows the number of open files, failures to open files, and closed files on a +Debian 10 system. The first spike is from configuring/compiling a small C program, then from running Apache's `ab` tool +to benchmark an Apache web server. + + + +In these charts, you can see first a spike in syscalls to open and close files from the configure/build process, +followed by a similar spike from the Apache benchmark. + +> 👋 Don't forget that you can view chart data directly via Netdata's API! +> +> For example, open your browser and navigate to `http://NODE:19999/api/v1/data?chart=apps.file_open`, replacing `NODE` +> with the IP address or hostname of your Agent. The API returns JSON of that chart's dimensions and metrics, which you +> can use in other operations. +> +> To see other charts, replace `apps.file_open` with the context of the chart you want to see data for. +> +> To see all the API options, visit our [Swagger +> documentation](https://editor.swagger.io/?url=https://raw.githubusercontent.com/netdata/netdata/master/web/api/netdata-swagger.yaml) +> and look under the **/data** section. + +## Troubleshoot and debug applications with eBPF + +The actual method of troubleshooting and debugging any application with Netdata's eBPF metrics depends on the +application, its place within your stack, and the type of issue you're trying to root cause. This guide won't be able to +explain how to troubleshoot _any_ application with eBPF metrics, but it should give you some ideas on how to start with +your own systems. + +The value of using Netdata to collect and visualize eBPF metrics is that you don't have to rely on existing (complex) +command line eBPF programs or, even worse, write your own eBPF program to get the information you need. + +Let's walk through some scenarios where you might find value in eBPF metrics. + +### Benchmark application performance + +You can use eBPF metrics to profile the performance of your applications, whether they're custom or a standard Linux +service, like a web server or database. + +For example, look at the charts below. The first spike represents running a Redis benchmark _without_ pipelining +(`redis-benchmark -n 1000000 -t set,get -q`). The second spike represents the same benchmark _with_ pipelining +(`redis-benchmark -n 1000000 -t set,get -q -P 16`). + + + +The performance optimization is clear from the speed at which the benchmark finished (the horizontal length of the +spike) and the reduced write/read syscalls and bytes written to disk. + +You can run similar performance benchmarks against any application, view the results on a Linux kernel level, and +continuously improve the performance of your infrastructure. + +### Inspect for leaking file descriptors + +If your application runs fine and then only crashes after a few hours, leaking file descriptors may be to blame. + +Check the **Number of open files (apps.file_open)** and **Files closed (apps.file_closed)** for discrepancies. These +metrics should be more or less equal. If they diverge, with more open files than closed, your application may not be +closing file descriptors properly. + +See, for example, the volume of files opened and closed by `apps.plugin` itself. Because the eBPF collector is +monitoring these syscalls at an event level, you can see at any given second that the open and closed numbers as equal. + +This isn't to say Netdata is _perfect_, but at least `apps.plugin` doesn't have a file descriptor problem. + + + +### Pin down syscall failures + +If you enabled the eBPF collector's `return` mode as mentioned [in a previous +step](#configure-the-ebpf-collector-to-monitor-errors), you can view charts related to how often a given application's +syscalls return in failure. + +By understanding when these failures happen, and when, you might be able to diagnose a bug in your application. + +To diagnose potential issues with an application, look at the **Fails to open files (apps.file_open_error)**, **Fails to +close files (apps.file_close_error)**, **Fails to write (apps.vfs_write_error)**, and **Fails to read +(apps.vfs_read_error)** charts for failed syscalls coming from your application. If you see any, look to the surrounding +charts for anomalies at the same time frame, or correlate with other activity in the application or on the system to get +closer to the root cause. + +### Investigate zombie processes + +Look for the trio of **Process started (apps.process_create)**, **Threads started (apps.thread_create)**, and **Tasks +closed (apps.task_close)** charts to investigate situations where an application inadvertently leaves [zombie +processes](https://en.wikipedia.org/wiki/Zombie_process). + +These processes, which are terminated and don't use up system resources, can still cause issues if your system runs out +of available PIDs to allocate. + +For example, the chart below demonstrates a [zombie factory +program](https://www.refining-linux.org/archives/7-Dr.-Frankenlinux-or-how-to-create-zombie-processes.html) in action. + + + +Starting at 14:51:49, Netdata sees the `zombie` group creating one new process every second, but no closed tasks. This +continues for roughly 30 seconds, at which point the factory program was killed with `SIGINT`, which results in the 31 +closed tasks in the subsequent second. + +Zombie processes may not be catastrophic, but if you're developing an application on Linux, you should eliminate them. +If a service in your stack creates them, you should consider filing a bug report. + +## View eBPF metrics in Netdata Cloud + +You can also show per-application eBPF metrics in Netdata Cloud. This could be particularly useful if you're running the +same application on multiple systems and want to correlate how it performs on each target, or if you want to share your +findings with someone else on your team. + +If you don't already have a Netdata Cloud account, go [sign in](https://app.netdata.cloud) and get started for free. +You can also read how to [monitor your infrastructure with Netdata Cloud](https://github.com/netdata/netdata/blob/master/docs/quickstart/infrastructure.md) to understand the key features that it has to offer. + +Once you've added one or more nodes to a Space in Netdata Cloud, you can see aggregated eBPF metrics in the [Overview +dashboard](https://github.com/netdata/netdata/blob/master/docs/visualize/overview-infrastructure.md) under the same **Applications** or **eBPF** sections that you +find on the local Agent dashboard. Or, [create new dashboards](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/dashboards.md) using eBPF metrics +from any number of distributed nodes to see how your application interacts with multiple Linux kernels on multiple Linux +systems. + +Now that you can see eBPF metrics in Netdata Cloud, you can [invite your +team](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/organize-your-infrastrucutre-invite-your-team.md#invite-your-team) and share your findings with others. + + + diff --git a/docs/guides/troubleshoot/troubleshooting-agent-with-cloud-connection.md b/docs/guides/troubleshoot/troubleshooting-agent-with-cloud-connection.md new file mode 100644 index 00000000..9c69ee91 --- /dev/null +++ b/docs/guides/troubleshoot/troubleshooting-agent-with-cloud-connection.md @@ -0,0 +1,147 @@ +# Troubleshoot Agent-Cloud connectivity issues + +Learn how to troubleshoot connectivity issues leading to agents not appearing at all in Netdata Cloud, or +appearing with a status other than `live`. + +After installing an agent with the claiming token provided by Netdata Cloud, you should see charts from that node on +Netdata Cloud within seconds. If you don't see charts, check if the node appears in the list of nodes +(Nodes tab, top right Node filter, or Manage Nodes screen). If your node does not appear in the list, or it does appear with a status other than "Live", this guide will help you troubleshoot what's happening. + + The most common explanation for connectivity issues usually falls into one of the following three categories: + +- If the node does not appear at all in Netdata Cloud, [the claiming process was unsuccessful](#the-claiming-process-was-unsuccessful). +- If the node appears as in Netdata Cloud, but is in the "Unseen" state, [the Agent was claimed but can not connect](#the-agent-was-claimed-but-can-not-connect). +- If the node appears as in Netdata Cloud as "Offline" or "Stale", it is a [previously connected agent that can no longer connect](#previously-connected-agent-that-can-no-longer-connect). + +## The claiming process was unsuccessful + +If the claiming process fails, the node will not appear at all in Netdata Cloud. + +First ensure that you: +- Use the newest possible stable or nightly version of the agent (at least v1.32). +- Your node can successfully issue an HTTPS request to https://app.netdata.cloud + +Other possible causes differ between kickstart installations and Docker installations. + +### Verify your node can access Netdata Cloud + +If you run either `curl` or `wget` to do an HTTPS request to https://app.netdata.cloud, you should get +back a 404 response. If you do not, check your network connectivity, domain resolution, +and firewall settings for outbound connections. + +If your firewall is configured to completely prevent outbound connections, you need to whitelist `app.netdata.cloud` and `mqtt.netdata.cloud`. If you can't whitelist domains in your firewall, you can whitelist the IPs that the hostnames resolve to, but keep in mind that they can change without any notice. + +If you use an outbound proxy, you need to [take some extra steps]( https://github.com/netdata/netdata/blob/master/claim/README.md#connect-through-a-proxy). + +### Troubleshoot claiming with kickstart.sh + +Claiming is done by executing `netdata-claim.sh`, a script that is usually located under `${INSTALL_PREFIX}/netdata/usr/sbin/netdata-claim.sh`. Possible error conditions we have identified are: +- No script found at all in any of our search paths. +- The path where the claiming script should be does not exist. +- The path exists, but is not a file. +- The path is a file, but is not executable. +Check the output of the kickstart script for any reported errors claiming and verify that the claiming script exists +and can be executed. + +### Troubleshoot claiming with Docker + +First verify that the NETDATA_CLAIM_TOKEN parameter is correctly configured and then check for any errors during +initialization of the container. + +The most common issue we have seen claiming nodes in Docker is [running on older hosts with seccomp enabled](https://github.com/netdata/netdata/blob/master/claim/README.md#known-issues-on-older-hosts-with-seccomp-enabled). + +## The Agent was claimed but can not connect + +Agents that appear on the cloud with state "Unseen" have successfully been claimed, but have never +been able to successfully establish an ACLK connection. + +Agents that appear with state "Offline" or "Stale" were able to connect at some point, but are currently not +connected. The difference between the two is that "Stale" nodes had some of their data replicated to a +parent node that is still connected. + +### Verify that the agent is running + +#### Troubleshoot connection establishment with kickstart.sh + +The kickstart script will install/update your Agent and then try to claim the node to the Cloud +(if tokens are provided). To complete the second part, the Agent must be running. In some platforms, +the Netdata service cannot be enabled by default and you must do it manually, using the following steps: + +1. Check if the Agent is running: + + ```bash + systemctl status netdata + ``` + + The expected output should contain info like this: + + ```bash + Active: active (running) since Wed 2022-07-06 12:25:02 EEST; 1h 40min ago + ``` + +2. Enable and start the Netdata Service. + + ```bash + systemctl enable netdata + systemctl start netdata + ``` + +3. Retry the kickstart claiming process. + +> ### Note +> +> In some cases a simple restart of the Agent can fix the issue. +> Read more about [Starting, Stopping and Restarting the Agent](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md). + +#### Troubleshoot connection establishment with Docker + +If a Netdata container exits or is killed before it properly starts, it may be able to complete the claiming +process, but not have enough time to establish the ACLK connection. + +### Verify that your firewall allows websockets + +The agent initiates an SSL connection to `app.netdata.cloud` and then upgrades that connection to use secure +websockets. Some firewalls completely prevent the use of websockets, even for outbound connections. + +## Previously connected agent that can no longer connect + +The states "Offline" and "Stale" suggest that the agent was able to connect at some point in the past, but +that it is currently not connected. + +### Verify that network connectivity is still possible + +Verify that you can still issue HTTPS requests to app.netdata.cloud and that no firewall or proxy changes were made. + +### Verify that the claiming info is persisted + +If you use Docker, verify that the contents of `/var/lib/netdata` are preserved across container restarts, using a persistent volume. + +### Verify that the claiming info is not cloned + +A relatively common case we have seen especially with VMs is two or more nodes sharing the same credentials. +This happens if you claim a node in a VM and then create an image based on that node. Netdata can't properly +work this way, as we have unique node identification information under `/var/lib/netdata`. + +### Verify that your IP is not blocked by Netdata Cloud + +Most of the nodes change IPs dynamically. It is possible that your current IP has been restricted from accessing `app.netdata.cloud` due to security concerns, usually because it was spamming Netdata Coud with too many +failed requests (old versions of the agent). + +To verify this: + +1. Check the Agent's `aclk-state`. + + ```bash + sudo netdatacli aclk-state | grep "Banned By Cloud" + ``` + + The output will contain a line indicating if the IP is banned from `app.netdata.cloud`: + + ```bash + Banned By Cloud: yes + ``` + +2. If your node's IP is banned, you can: + + - Contact our team to whitelist your IP by submitting a ticket in the [Netdata forum](https://community.netdata.cloud/) + - Change your node's IP diff --git a/docs/guides/using-host-labels.md b/docs/guides/using-host-labels.md new file mode 100644 index 00000000..5f3a467f --- /dev/null +++ b/docs/guides/using-host-labels.md @@ -0,0 +1,253 @@ +# Organize systems, metrics, and alerts + +When you use Netdata to monitor and troubleshoot an entire infrastructure, you need sophisticated ways of keeping everything organized. +Netdata allows to organize your observability infrastructure with spaces, war rooms, virtual nodes, host labels, and metric labels. + +## Spaces and war rooms + +[Spaces](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/organize-your-infrastrucutre-invite-your-team.md#netdata-cloud-spaces) are used for organization-level or infrastructure-level +grouping of nodes and people. A node can only appear in a single space, while people can have access to multiple spaces. + +The [war rooms](https://github.com/netdata/netdata/edit/master/docs/cloud/war-rooms.md) in a space bring together nodes and people in +collaboration areas. War rooms can also be used for fine-tuned +[role based access control](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/role-based-access.md). + +## Virtual nodes + +Netdata’s virtual nodes functionality allows you to define nodes in configuration files and have them be treated as regular nodes +in all of the UI, dashboards, tabs, filters etc. For example, you can create a virtual node each for all your Windows machines +and monitor them as discrete entities. Virtual nodes can help you simplify your infrastructure monitoring and focus on the +individual node that matters. + +To define your windows server as a virtual node you need to: + + * Define virtual nodes in `/etc/netdata/vnodes/vnodes.conf` + + ```yaml + - hostname: win_server1 + guid: <value> + ``` + Just remember to use a valid guid (On Linux you can use `uuidgen` command to generate one, on Windows just use the `[guid]::NewGuid()` command in PowerShell) + + * Add the vnode config to the data collection job. e.g. in `go.d/windows.conf`: + ```yaml + jobs: + - name: win_server1 + vnode: win_server1 + url: http://203.0.113.10:9182/metrics + ``` + +## Host labels + +Host labels can be extremely useful when: + +- You need alerts that adapt to the system's purpose +- You need properly-labeled metrics archiving so you can sort, correlate, and mash-up your data to your heart's content. +- You need to keep tabs on ephemeral Docker containers in a Kubernetes cluster. + +Let's take a peek into how to create host labels and apply them across a few of Netdata's features to give you more +organization power over your infrastructure. + +### Default labels + +When Netdata starts, it captures relevant information about the system and converts them into automatically generated +host labels. You can use these to logically organize your systems via health entities, exporting metrics, +parent-child status, and more. + +They capture the following: + +- Kernel version +- Operating system name and version +- CPU architecture, system cores, CPU frequency, RAM, and disk space +- Whether Netdata is running inside of a container, and if so, the OS and hardware details about the container's host +- Whether Netdata is running inside K8s node +- What virtualization layer the system runs on top of, if any +- Whether the system is a streaming parent or child + +If you want to organize your systems without manually creating host labels, try the automatic labels in some of the +features below. You can see them under `http://HOST-IP:19999/api/v1/info`, beginning with an underscore `_`. +```json +{ + ... + "host_labels": { + "_is_k8s_node": "false", + "_is_parent": "false", + ... +``` + +### Custom labels + +Host labels are defined in `netdata.conf`. To create host labels, open that file using `edit-config`. + +```bash +cd /etc/netdata # Replace this path with your Netdata config directory, if different +sudo ./edit-config netdata.conf +``` + +Create a new `[host labels]` section defining a new host label and its value for the system in question. Make sure not +to violate any of the [host label naming rules](https://github.com/netdata/netdata/blob/master/docs/configure/common-changes.md#organize-nodes-with-host-labels). + +```conf +[host labels] + type = webserver + location = us-seattle + installed = 20200218 +``` + +Once you've written a few host labels, you need to enable them. Instead of restarting the entire Netdata service, you +can reload labels using the helpful `netdatacli` tool: + +```bash +netdatacli reload-labels +``` + +Your host labels will now be enabled. You can double-check these by using `curl http://HOST-IP:19999/api/v1/info` to +read the status of your agent. For example, from a VPS system running Debian 10: + +```json +{ + ... + "host_labels": { + "_is_k8s_node": "false", + "_is_parent": "false", + "_virt_detection": "systemd-detect-virt", + "_container_detection": "none", + "_container": "unknown", + "_virtualization": "kvm", + "_architecture": "x86_64", + "_kernel_version": "4.19.0-6-amd64", + "_os_version": "10 (buster)", + "_os_name": "Debian GNU/Linux", + "type": "webserver", + "location": "seattle", + "installed": "20200218" + }, + ... +} +``` + + +### Host labels in streaming + +You may have noticed the `_is_parent` and `_is_child` automatic labels from above. Host labels are also now +streamed from a child to its parent node, which concentrates an entire infrastructure's OS, hardware, container, +and virtualization information in one place: the parent. + +Now, if you'd like to remind yourself of how much RAM a certain child node has, you can access +`http://localhost:19999/host/CHILD_HOSTNAME/api/v1/info` and reference the automatically-generated host labels from the +child system. It's a vastly simplified way of accessing critical information about your infrastructure. + +> ⚠️ Because automatic labels for child nodes are accessible via API calls, and contain sensitive information like +> kernel and operating system versions, you should secure streaming connections with SSL. See the [streaming +> documentation](https://github.com/netdata/netdata/blob/master/streaming/README.md#securing-streaming-communications) for details. You may also want to use +> [access lists](https://github.com/netdata/netdata/blob/master/web/server/README.md#access-lists) or [expose the API only to LAN/localhost +> connections](https://github.com/netdata/netdata/blob/master/docs/netdata-security.md#expose-netdata-only-in-a-private-lan). + +You can also use `_is_parent`, `_is_child`, and any other host labels in both health entities and metrics +exporting. Speaking of which... + +### Host labels in alerts + +You can use host labels to logically organize your systems by their type, purpose, or location, and then apply specific +alerts to them. + +For example, let's use configuration example from earlier: + +```conf +[host labels] + type = webserver + location = us-seattle + installed = 20200218 +``` + +You could now create a new health entity (checking if disk space will run out soon) that applies only to any host +labeled `webserver`: + +```yaml + template: disk_fill_rate + on: disk.space + lookup: max -1s at -30m unaligned of avail + calc: ($this - $avail) / (30 * 60) + every: 15s + host labels: type = webserver +``` + +Or, by using one of the automatic labels, for only webserver systems running a specific OS: + +```yaml + host labels: _os_name = Debian* +``` + +In a streaming configuration where a parent node is triggering alerts for its child nodes, you could create health +entities that apply only to child nodes: + +```yaml + host labels: _is_child = true +``` + +Or when ephemeral Docker nodes are involved: + +```yaml + host labels: _container = docker +``` + +Of course, there are many more possibilities for intuitively organizing your systems with host labels. See the [health +documentation](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md#alert-line-host-labels) for more details, and then get creative! + +### Host labels in metrics exporting + +If you have enabled any metrics exporting via our experimental [exporters](https://github.com/netdata/netdata/blob/master/exporting/README.md), any new host +labels you created manually are sent to the destination database alongside metrics. You can change this behavior by +editing `exporting.conf`, and you can even send automatically-generated labels on with exported metrics. + +```conf +[exporting:global] +enabled = yes +send configured labels = yes +send automatic labels = no +``` + +You can also change this behavior per exporting connection: + +```conf +[opentsdb:my_instance3] +enabled = yes +destination = localhost:4242 +data source = sum +update every = 10 +send charts matching = system.cpu +send configured labels = no +send automatic labels = yes +``` + +By applying labels to exported metrics, you can more easily parse historical metrics with the labels applied. To learn +more about exporting, read the [documentation](https://github.com/netdata/netdata/blob/master/exporting/README.md). + +## Metric labels + +The Netdata aggregate charts allow you to filter and group metrics based on label name-value pairs. + +All go.d plugin collectors support the specification of labels at the "collection job" level. Some collectors come with out of the box +labels (e.g. generic Prometheus collector, Kubernetes, Docker and more). But you can also add your own custom labels, by configuring +the data collection jobs. + +For example, suppose we have a single Netdata agent, collecting data from two remote Apache web servers, located in different data centers. +The web servers are load balanced and provide access to the service "Payments". + +You can define the following in `go.d.conf`, to be able to group the web requests by service or location: + +``` +jobs: + - name: mywebserver1 + url: http://host1/server-status?auto + labels: + service: "Payments" + location: "Atlanta" + - name: mywebserver2 + url: http://host2/server-status?auto + labels: + service: "Payments" + location: "New York" +``` + +Of course you may define as many custom label/value pairs as you like, in as many data collection jobs you need. diff --git a/docs/metrics-storage-management/enable-streaming.md b/docs/metrics-storage-management/enable-streaming.md new file mode 100644 index 00000000..fcbb16c8 --- /dev/null +++ b/docs/metrics-storage-management/enable-streaming.md @@ -0,0 +1,228 @@ +# How metrics streaming works + +Each node running Netdata can stream the metrics it collects, in real time, to another node. Streaming allows you to +replicate metrics data across multiple nodes, or centralize all your metrics data into a single time-series database +(TSDB). + +When one node streams metrics to another, the node receiving metrics can visualize them on the dashboard, run health checks to +[trigger alerts](https://github.com/netdata/netdata/blob/master/docs/monitor/view-active-alerts.md) and +[send notifications](https://github.com/netdata/netdata/blob/master/docs/monitor/enable-notifications.md), and +[export](https://github.com/netdata/netdata/blob/master/docs/export/external-databases.md) all metrics to an external TSDB. When Netdata streams metrics to another +Netdata, the receiving one is able to perform everything a Netdata instance is capable of. + +Streaming lets you decide exactly how you want to store and maintain metrics data. While we believe Netdata's +[distributed architecture](https://github.com/netdata/netdata/blob/master/docs/store/distributed-data-architecture.md) is +ideal for speed and scale, streaming provides centralization options and high data availability. + +This document will get you started quickly with streaming. More advanced concepts and suggested production deployments +can be found in the [streaming and replication reference](https://github.com/netdata/netdata/blob/master/streaming/README.md). + +## Streaming basics + +There are three types of nodes in Netdata's streaming ecosystem. + +- **Parent**: A node, running Netdata, that receives streamed metric data. +- **Child**: A node, running Netdata, that streams metric data to one or more parent. +- **Proxy**: A node, running Netdata, that receives metric data from a child and "forwards" them on to a + separate parent node. + +Netdata uses API keys, which are just random GUIDs, to authorize the communication between child and parent nodes. We +recommend using `uuidgen` for generating API keys, which can then be used across any number of streaming connections. +Or, you can generate unique API keys for each parent-child relationship. + +Once the parent node authorizes the child's API key, the child can start streaming metrics. + +It's important to note that the streaming connection uses TCP, UDP, or Unix sockets, _not HTTP_. To proxy streaming +metrics, you need to use a proxy that tunnels [OSI layer 4-7 +traffic](https://en.wikipedia.org/wiki/OSI_model#Layer_4:_Transport_Layer) without interfering with it, such as +[SOCKS](https://en.wikipedia.org/wiki/SOCKS) or Nginx's +[TCP/UDP load balancing](https://docs.nginx.com/nginx/admin-guide/load-balancer/tcp-udp-load-balancer/). + +## Supported streaming configurations + +Netdata supports any combination of parent, child, and proxy nodes that you can imagine. Any node can act as both a +parent, child, or proxy at the same time, sending or receiving streaming metrics from any number of other nodes. + +Here are a few example streaming configurations: + +- **Headless collector**: + - Child `A`, _without_ a database or web dashboard, streams metrics to parent `B`. + - `A` metrics are only available via the local Agent dashboard for `B`. + - `B` generates alerts for `A`. +- **Replication**: + - Child `A`, _with_ a database and web dashboard, streams metrics to parent `B`. + - `A` metrics are available on both local Agent dashboards, and can be stored with the same or different metrics + retention policies. + - Both `A` and `B` generate alerts. +- **Proxy**: + - Child `A`, _with or without_ a database, sends metrics to proxy `C`, also _with or without_ a database. `C` sends + metrics to parent `B`. + - Any node with a database can generate alerts. + + + +### A basic parent child setup + + + +For a predictable number of non-ephemeral nodes, install a Netdata agent on each node and replicate its data to a +Netdata parent, preferrably on a management/admin node outside your production infrastructure. +There are two variations of the basic setup: + +- When your nodes have sufficient RAM and disk IO the Netdata agents on each node can run with the default + settings for data collection and retention. + +- When your nodes have severe RAM and disk IO limitations (e.g. Raspberry Pis), you should + [optimize the Netdata agent's performance](https://github.com/netdata/netdata/blob/master/docs/guides/configure/performance.md). + +[Secure your nodes](https://github.com/netdata/netdata/blob/master/docs/category-overview-pages/secure-nodes.md) to +protect them from the internet by making their UI accessible only via an nginx proxy, with potentially different subdomains +for the parent and even each child, if necessary. + +Both children and the parent are connected to the cloud, to enable infrastructure observability, +[without transferring the collected data](https://github.com/netdata/netdata/blob/master/docs/netdata-security.md). +Requests for data are always serverd by a connected Netdata agent. When both a child and a parent are connected, +the cloud will always select the parent to query the user requested data. + +### An advanced setup + + + +When the nodes are ephemeral, we recommend using two parents in an active-active setup, and having the children not store data at all. + +Both parents are configured on each child, so that if one is not available, they connect to the other. + +The children in this set up are not connected to Netdata Cloud at all, as high availability is achieved with the second parent. + +## Enable streaming between nodes + +The simplest streaming configuration is **replication**, in which a child node streams its metrics in real time to a +parent node, and both nodes retain metrics in their own databases. + +To configure replication, you need two nodes, each running Netdata. First you'll first enable streaming on your parent +node, then enable streaming on your child node. When you're finished, you'll be able to see the child node's metrics in +the parent node's dashboard, quickly switch between the two dashboards, and be able to serve +[alert notifications](https://github.com/netdata/netdata/blob/master/docs/monitor/enable-notifications.md) from either or both nodes. + +### Enable streaming on the parent node + +First, log onto the node that will act as the parent. + +Run `uuidgen` to create a new API key, which is a randomly-generated machine GUID the Netdata Agent uses to identify +itself while initiating a streaming connection. Copy that into a separate text file for later use. + +> Find out how to [install `uuidgen`](https://command-not-found.com/uuidgen) on your node if you don't already have it. + +Next, open `stream.conf` using [`edit-config`](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md#use-edit-config-to-edit-configuration-files) +from within the [Netdata config directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md#the-netdata-config-directory). + +```bash +cd /etc/netdata +sudo ./edit-config stream.conf +``` + +Scroll down to the section beginning with `[API_KEY]`. Paste the API key you generated earlier between the brackets, so +that it looks like the following: + +```conf +[11111111-2222-3333-4444-555555555555] +``` + +Set `enabled` to `yes`, and `default memory mode` to `dbengine`. Leave all the other settings as their defaults. A +simplified version of the configuration, minus the commented lines, looks like the following: + +```conf +[11111111-2222-3333-4444-555555555555] + enabled = yes + default memory mode = dbengine +``` + +Save the file and close it, then restart Netdata with `sudo systemctl restart netdata`, or the [appropriate +method](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md) for your system. + +### Enable streaming on the child node + +Connect to your child node with SSH. + +Open `stream.conf` again. Scroll down to the `[stream]` section and set `enabled` to `yes`. Paste the IP address of your +parent node at the end of the `destination` line, and paste the API key generated on the parent node onto the `api key` +line. + +Leave all the other settings as their defaults. A simplified version of the configuration, minus the commented lines, +looks like the following: + +```conf +[stream] + enabled = yes + destination = 203.0.113.0 + api key = 11111111-2222-3333-4444-555555555555 +``` + +Save the file and close it, then restart Netdata with `sudo systemctl restart netdata`, or the [appropriate +method](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md) for your system. + +### Enable TLS/SSL on streaming (optional) + +While encrypting the connection between your parent and child nodes is recommended for security, it's not required to +get started. If you're not interested in encryption, skip ahead to [view streamed +metrics](#view-streamed-metrics-in-netdatas-dashboard). + +In this example, we'll use self-signed certificates. + +On the **parent** node, use OpenSSL to create the key and certificate, then use `chown` to make the new files readable +by the `netdata` user. + +```bash +sudo openssl req -newkey rsa:2048 -nodes -sha512 -x509 -days 365 -keyout /etc/netdata/ssl/key.pem -out /etc/netdata/ssl/cert.pem +sudo chown netdata:netdata /etc/netdata/ssl/cert.pem /etc/netdata/ssl/key.pem +``` + +Next, enforce TLS/SSL on the web server. Open `netdata.conf`, scroll down to the `[web]` section, and look for the `bind +to` setting. Add `^SSL=force` to turn on TLS/SSL. See the [web server +reference](https://github.com/netdata/netdata/blob/master/web/server/README.md#enabling-tls-support) for other TLS/SSL options. + +```conf +[web] + bind to = *=dashboard|registry|badges|management|streaming|netdata.conf^SSL=force +``` + +Next, connect to the **child** node and open `stream.conf`. Add `:SSL` to the end of the existing `destination` setting +to connect to the parent using TLS/SSL. Uncomment the `ssl skip certificate verification` line to allow the use of +self-signed certificates. + +```conf +[stream] + enabled = yes + destination = 203.0.113.0:SSL + ssl skip certificate verification = yes + api key = 11111111-2222-3333-4444-555555555555 +``` + +Restart both the parent and child nodes with `sudo systemctl restart netdata`, or the [appropriate +method](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md) for your system, to stream encrypted metrics using TLS/SSL. + +### View streamed metrics in Netdata Cloud + +In Netdata Cloud you should now be able to see a new parent showing up in the Home tab under "Nodes by data replication". +The replication factor for the child node has now increased to 2, meaning that its data is now highly available. + +You don't need to do anything else, as the cloud will automatically prefer to fetch data about the child from the parent +and switch to querying the child only when the parent is unavailable, or for some reason doesn't have the requested +data (e.g. the connection between parent and the child is broken). + +### View streamed metrics in Netdata's dashboard + +At this point, the child node is streaming its metrics in real time to its parent. Open the local Agent dashboard for +the parent by navigating to `http://PARENT-NODE:19999` in your browser, replacing `PARENT-NODE` with its IP address or +hostname. + +This dashboard shows parent metrics. To see child metrics, open the left-hand sidebar with the hamburger icon + +in the top panel. Both nodes appear under the **Replicated Nodes** menu. Click on either of the links to switch between +separate parent and child dashboards. + + + +The child dashboard is also available directly at `http://PARENT-NODE:19999/host/CHILD-HOSTNAME`, which in this example +is `http://203.0.113.0:19999/host/netdata-child`. + diff --git a/docs/monitor/enable-notifications.md b/docs/monitor/enable-notifications.md new file mode 100644 index 00000000..4bfebb4d --- /dev/null +++ b/docs/monitor/enable-notifications.md @@ -0,0 +1,90 @@ +<!-- +title: "Alert notifications" +description: "Send Netdata alerts from a centralized place with Netdata Cloud, or configure nodes individually, to enable incident response and faster resolution." +custom_edit_url: "https://github.com/netdata/netdata/edit/master/docs/monitor/enable-notifications.md" +sidebar_label: "Notify" +learn_status: "Published" +learn_rel_path: "Integrations/Notify" +--> + +# Alert notifications + +Netdata offers two ways to receive alert notifications on external platforms. These methods work independently _or_ in +parallel, which means you can enable both at the same time to send alert notifications to any number of endpoints. + +Both methods use a node's health alerts to generate the content of alert notifications. Read our documentation on [configuring alerts](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md) to change the preconfigured thresholds or to create tailored alerts for your +infrastructure. + +Netdata Cloud offers [centralized alert notifications](#netdata-cloud) via email, which leverages the health status +information already streamed to Netdata Cloud from connected nodes to send notifications to those who have enabled them. + +The Netdata Agent has a [notification system](#netdata-agent) that supports more than a dozen services, such as email, +Slack, PagerDuty, Twilio, Amazon SNS, Discord, and much more. + +For example, use centralized alert notifications in Netdata Cloud for immediate, zero-configuration alert notifications +for your team, then configure individual nodes send notifications to a PagerDuty endpoint for an automated incident +response process. + +## Netdata Cloud + +Netdata Cloud's [centralized alert +notifications](https://github.com/netdata/netdata/blob/master/docs/cloud/alerts-notifications/notifications.md) is a zero-configuration way to +get notified when an anomaly or incident strikes any node or application in your infrastructure. The advantage of using +centralized alert notifications from Netdata Cloud is that you don't have to worry about configuring each node in your +infrastructure. + +To enable centralized alert notifications for a Space, click on **Manage Space** in the left-hand menu, then click on +the **Notifications** tab. Click the toggle switch next to **E-mail** to enable this notification method. + +Next, enable notifications on a user level by clicking on your profile icon, then **Profile** in the dropdown. The +**Notifications** tab reveals rich management settings, including the ability to enable/disable methods entirely or +choose what types of notifications to receive from each War Room. + + + +See the [centralized alert notifications](https://github.com/netdata/netdata/blob/master/docs/cloud/alerts-notifications/notifications.md) +reference doc for further details about what information is conveyed in an email notification, flood protection, and +more. + +## Netdata Agent + +The Netdata Agent's [notification system](https://github.com/netdata/netdata/blob/master/health/notifications/README.md) runs on every node and dispatches +notifications based on configured endpoints and roles. You can enable multiple endpoints on any one node _and_ use Agent +notifications in parallel with centralized alert notifications in Netdata Cloud. + +> ❗ If you want to enable notifications from multiple nodes in your infrastructure, each running the Netdata Agent, you +> must configure each node individually. + +Below, we'll use [Slack notifications](#enable-slack-notifications) as an example of the process of enabling any +notification platform. + +### Supported notification endpoints + +- [**alerta.io**](https://github.com/netdata/netdata/blob/master/health/notifications/alerta/README.md) +- [**Amazon SNS**](https://github.com/netdata/netdata/blob/master/health/notifications/awssns/README.md) +- [**Custom endpoint**](https://github.com/netdata/netdata/blob/master/health/notifications/custom/README.md) +- [**Discord**](https://github.com/netdata/netdata/blob/master/health/notifications/discord/README.md) +- [**Dynatrace**](https://github.com/netdata/netdata/blob/master/health/notifications/dynatrace/README.md) +- [**Email**](https://github.com/netdata/netdata/blob/master/health/notifications/email/README.md) +- [**Flock**](https://github.com/netdata/netdata/blob/master/health/notifications/flock/README.md) +- [**Gotify**](https://github.com/netdata/netdata/blob/master/health/notifications/gotify/README.md) +- [**IRC**](https://github.com/netdata/netdata/blob/master/health/notifications/irc/README.md) +- [**Kavenegar**](https://github.com/netdata/netdata/blob/master/health/notifications/kavenegar/README.md) +- [**Matrix**](https://github.com/netdata/netdata/blob/master/health/notifications/matrix/README.md) +- [**Messagebird**](https://github.com/netdata/netdata/blob/master/health/notifications/messagebird/README.md) +- [**Microsoft Teams**](https://github.com/netdata/netdata/blob/master/health/notifications/msteams/README.md) +- [**Netdata Agent dashboard**](https://github.com/netdata/netdata/blob/master/health/notifications/web/README.md) +- [**Opsgenie**](https://github.com/netdata/netdata/blob/master/health/notifications/opsgenie/README.md) +- [**PagerDuty**](https://github.com/netdata/netdata/blob/master/health/notifications/pagerduty/README.md) +- [**Prowl**](https://github.com/netdata/netdata/blob/master/health/notifications/prowl/README.md) +- [**PushBullet**](https://github.com/netdata/netdata/blob/master/health/notifications/pushbullet/README.md) +- [**PushOver**](https://github.com/netdata/netdata/blob/master/health/notifications/pushover/README.md) +- [**Rocket.Chat**](https://github.com/netdata/netdata/blob/master/health/notifications/rocketchat/README.md) +- [**Slack**](https://github.com/netdata/netdata/blob/master/health/notifications/slack/README.md) +- [**SMS Server Tools 3**](https://github.com/netdata/netdata/blob/master/health/notifications/smstools3/README.md) +- [**Syslog**](https://github.com/netdata/netdata/blob/master/health/notifications/syslog/README.md) +- [**Telegram**](https://github.com/netdata/netdata/blob/master/health/notifications/telegram/README.md) +- [**Twilio**](https://github.com/netdata/netdata/blob/master/health/notifications/twilio/README.md) + + diff --git a/docs/monitor/view-active-alerts.md b/docs/monitor/view-active-alerts.md new file mode 100644 index 00000000..14b1663d --- /dev/null +++ b/docs/monitor/view-active-alerts.md @@ -0,0 +1,70 @@ +# View active alerts + +Netdata comes with hundreds of pre-configured health alerts designed to notify you when an anomaly or performance issue affects your node or its applications. + +From the Alerts tab you can see all the active alerts in your War Room. You will be presented with a table having information about each alert that is in warning and critical state. +You can always sort the table by a certain column by clicking on the name of that column, and use the gear icon on the top right to control which columns are visible at any given time. + + + +## Filter alerts + +From this tab, you can also filter alerts with the right hand bar. More specifically you can filter: + +- Alert status + - Filter based on the status of the alerts (e.g. Warning, Critical) +- Alert class + - Filter based on the class of the alert (e.g. Latency, Utilization, Workload etc.) +- Alert type & component + - Filter based on the alert's type (e.g. System, Web Server) and component (e.g. CPU, Disk, Load) +- Alert role + - Filter by the role that the alert is set to notify (e.g. Sysadmin, Webmaster etc.) +- Nodes + - Filter the alerts based on the nodes that are online, next to each node's name you can see how many alerts the node has, "critical" colored in red and "warning" colored in yellow + +## View alert details + +By clicking on the name of an entry of the table you can access that alert's details page, providing you with: + +- Latest and Triggered time values +- The alert's description +- A link to the Community forum's alert page +- The chart at the time frame that the alert was triggered +- The alert's information: Node name, chart ID, type, component and class +- Configuration section +- Instance values - Node Instances + + + +At the bottom of the panel you can click the green button "View dedicated alert page" to open a [dynamic tab](https://github.com/netdata/netdata/blob/master/docs/quickstart/infrastructure.md#dynamic-tabs) containing all the info for this alert in a tab format, where you can also run correlations and go to the node's chart that raised the particular alert. + +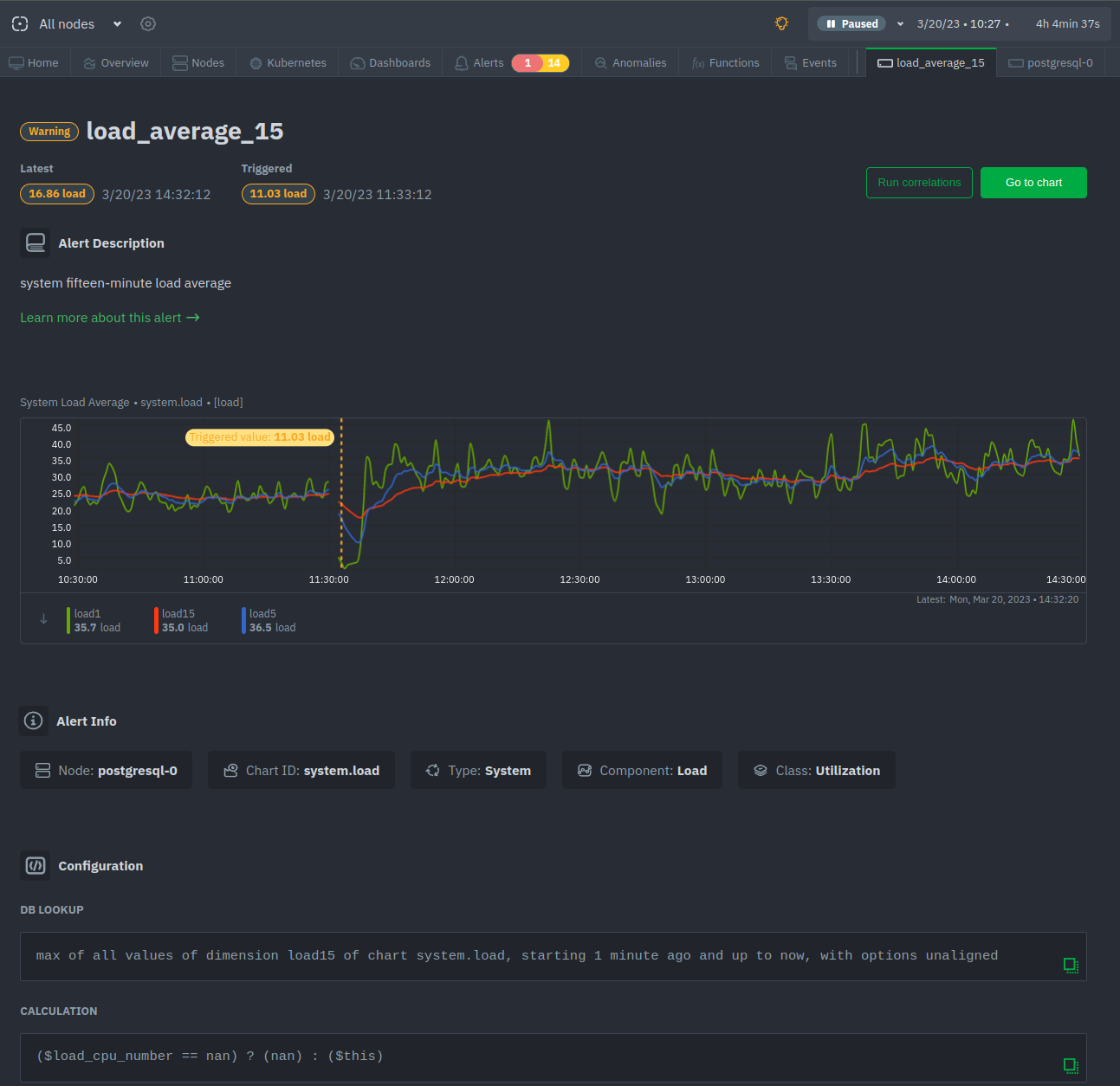 + +<!-- +## Local Netdata Agent dashboard + +Find the alerts icon  +in the top navigation to bring up a modal that shows currently raised alerts, all running alerts, and the alerts log. +Here is an example of a raised `system.cpu` alert, followed by the full list and alert log: + +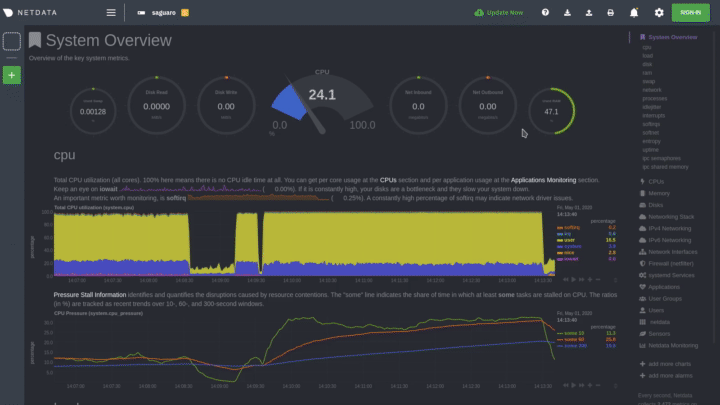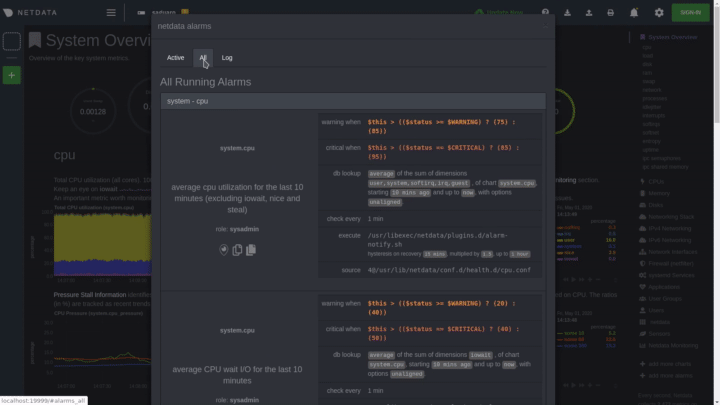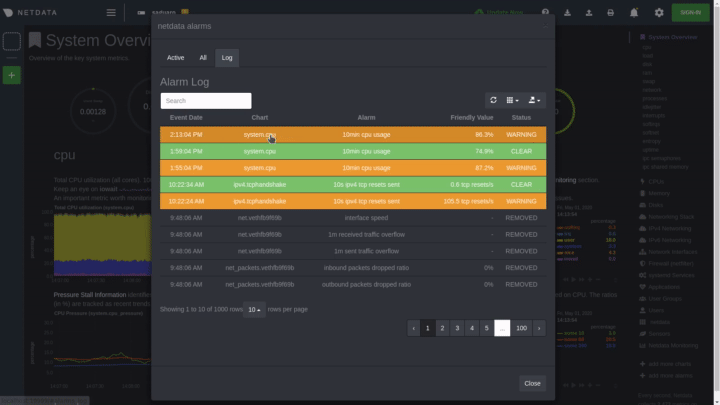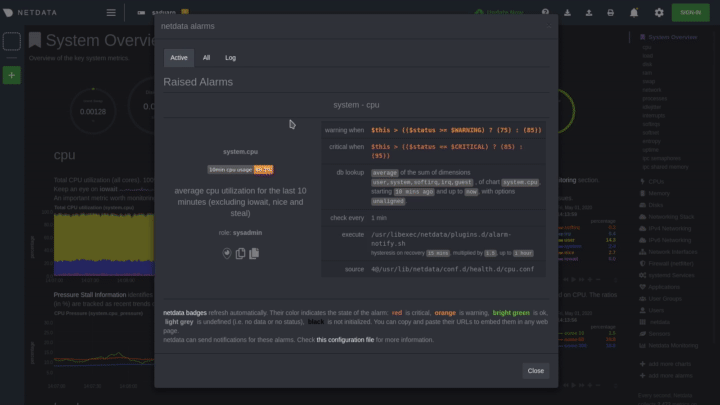 + +And a static screenshot of the raised CPU alert: + +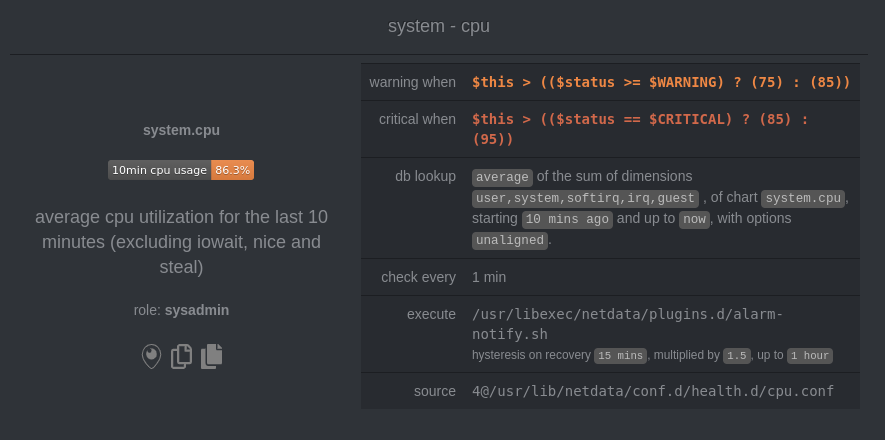 + +The alert itself is named **system - cpu**, and its context is `system.cpu`. Beneath that is an auto-updating badge that +shows the latest value of the chart that triggered the alert. + +With the three icons beneath that and the **role** designation, you can: + +1. Scroll to the chart associated with this raised alert. +2. Copy a link to the badge to your clipboard. +3. Copy the code to embed the badge onto another web page using an `<embed>` element. + +The table on the right-hand side displays information about the health entity that triggered the alert, which you can +use as a reference to [configure alerts](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md). + --> diff --git a/docs/netdata-cloud-onprem/getting-started-light-poc.md b/docs/netdata-cloud-onprem/getting-started-light-poc.md new file mode 100644 index 00000000..dfe0a0c8 --- /dev/null +++ b/docs/netdata-cloud-onprem/getting-started-light-poc.md @@ -0,0 +1,51 @@ +# Getting started with Netdata Cloud On-Prem Light PoC +Due to the high demand, we designed a very light and easy-to-install version of netdata for clients who do not have Kubernetes cluster installed. Please keep in mind that this is (for now) only designed to be used as a PoC with no built-in resiliency on failures of any kind. + +Requirements: + - Ubuntu 22.04 (clean installation will work best). + - 10 CPU Cores and 24 GiB of memory. + - Access to shell as a sudo. + - TLS certificate for Netdata Cloud On-Prem PoC. A single endpoint is required. The certificate must be trusted by all entities connecting to the On-Prem installation by any means. + - AWS ID and Key - contact Netdata Product Team - info@netdata.cloud + - License Key - contact Netdata Product Team - info@netdata.cloud + +To install the whole environment, log in to the designated host and run: +```shell +curl https://netdata-cloud-netdata-static-content.s3.amazonaws.com/provision.sh -o provision.sh +chmod +x provision.sh +sudo ./provision.sh --install +``` + +What does the script do during installation? +1. Prompts user to provide: + - ID and KEY for accessing the AWS (to pull helm charts and container images) + - License Key + - URL under which Netdata Cloud Onprem PoC is going to function (without protocol like `https://`) + - Path for certificate file (PEM format) + - Path for private key file (PEM format) +2. After getting all of the information installation is starting. The script will install: + - Helm + - Kubectl + - AWS CLI + - K3s cluster (single node) +3. When all the required software is installed script starts to provision the K3s cluster with gathered data. + +After cluster provisioning netdata is ready to be used. + +##### How to log in? +Because this is a PoC with 0 configurations required, only log in by mail can work. What's more every mail that Netdata Cloud On-Prem sends will appear on the mailcatcher, which acts as the SMTP server with a simple GUI to read the mails. Steps: +1. Open Netdata Cloud On-Prem PoC in the web browser on URL you specified +2. Provide email and use the button to confirm +3. Mailcatcher will catch all the emails so go to `<URL from point 1.>/mailcatcher`. Find yours and click the link. +4. You are now logged into the netdata. Add your first nodes! + +##### How to remove Netdata Cloud On-Prem PoC? +To uninstall the whole PoC, use the same script that installed it, with the `--uninstall` switch. + +```shell +cd <script dir> +sudo ./provision.sh --uninstall +``` + +#### WARNING +This script will automatically expose not only netdata but also a mailcatcher under `<URL from point 1.>/mailcatcher`. diff --git a/docs/netdata-cloud-onprem/getting-started.md b/docs/netdata-cloud-onprem/getting-started.md new file mode 100644 index 00000000..9d2eea66 --- /dev/null +++ b/docs/netdata-cloud-onprem/getting-started.md @@ -0,0 +1,200 @@ +# Getting started with Netdata Cloud On-Prem +Helm charts are designed for Kubernetes to run as the local equivalent of the Netdata Cloud public offering. This means that no data is sent outside of your cluster. By default, On-Prem installation is trying to reach outside resources only when pulling the container images. +There are 2 helm charts in total: +- netdata-cloud-onprem - installs onprem itself. +- netdata-cloud-dependency - installs all necessary dependency applications. Not for production use, PoC only. + +## Requirements +#### Install host: +- [AWS CLI](https://docs.aws.amazon.com/cli/latest/userguide/getting-started-install.html) +- [Helm](https://helm.sh/docs/intro/install/) version 3.12+ with OCI Configuration (explained in the installation section) +- [Kubectl](https://kubernetes.io/docs/tasks/tools/) + +#### Kubernetes requirements: +- Kubernetes cluster version 1.23+ +- Kubernetes metrics server (For autoscaling) +- TLS certificate for Netdata Cloud On-Prem. A single endpoint is required but there is an option to split the frontend, api, and mqtt endpoints. The certificate must be trusted by all entities connecting to the On-Prem installation by any means. +- Ingress controller to support HTTPS `*` +- PostgreSQL version 13.7 `*` (Main persistent data app) +- EMQX version 5.11 `*` (MQTT Broker that allows Agents to send messages to the On-Prem Cloud) +- Apache Pulsar version 2.10+ `*` (Central communication hub. Applications exchange messages through Pulsar) +- Traefik version 2.7.x `*` (Internal communication - API Gateway) +- Elasticsearch version 8.8.x `*` (Holds Feed) +- Redis version 6.2 `*` (Cache) +- Some form of generating imagePullSecret `*` (Our ECR repos are secured) +- Default storage class configured and working (Persistent volumes based on SSDs are preferred) +`*` - available in dependencies helm chart for PoC applications. + +#### Hardware requirements: +##### How we tested it: +- Several VMs on the AWS EC2, the size of the instance was c6a.32xlarge (128CPUs / 256GiB memory). +- Host system - Ubuntu 22.04. +- Each VM hosts 200 Agent nodes as docker containers. +- Agents are connected directly to the Netdata Cloud On-Prem (no Parent-Child relationships). This is the worst option for the cloud. +- Cloud hosted on 1 Kubernetes node c6a.8xlarge (32CPUs / 64GiB memory). +- Dependencies were also installed on the same node. +The maximum of nodes connected was ~2000. + +##### Results +There was no point in trying to connect more nodes as we are covering the PoC purposes. +- In a peak connection phase - All nodes startup were triggered in ~15 minutes: + - Up to 60% (20 cores) CPU usage of the Kubernetes node. Top usage came from: + - Ingress controller (we used haproxy ingress controller) + - Postgres + - Pulsar + - EMQX + Combined they were responsible for ~30-35% of CPU usage of the node. +- When all nodes connected and synchronized their state CPU usage floated between 30% and 40% - depending on what we did on the Cloud. Here top offenders were: + - Pulsar + - Postgres + Combined they were responsible for ~15-20% of CPU usage of the node. +- Memory usage - 45GiB in a peak. Most of it (~20GiB) was consumed by: + - Postgres + - Elasticsearch + - Pulsar + +For a comparison - Netdata Cloud On-prem installation with just 100 nodes connected, without dependencies is going to consume ~2CPUs and ~2GiB of memory (REAL usage, not requests on a Kubernetes). + +## Pulling the helm chart +The helm chart for the Netdata Cloud On-Prem installation on Kubernetes is available in the ECR registry. +The ECR registry is private, so you need to log in first. Credentials are sent by our Product Team. If you do not have them, please contact our Product Team - info@netdata.cloud. + +#### Configure AWS CLI +The machine used for helm chart installation will also need [AWS CLI installed](https://docs.aws.amazon.com/cli/latest/userguide/getting-started-install.html). +There are 2 options for configuring `aws cli` to work with the provided credentials. The first one is to set the environment variables: +```bash +export AWS_ACCESS_KEY_ID=<your_secret_id> +export AWS_SECRET_ACCESS_KEY=<your_secret_key> +``` + +The second one is to use an interactive shell: +```bash +aws configure +``` + +#### Configure helm to use secured ECR repository +Using `aws` command we will generate a token for helm to access the secured ECR repository: +```bash +aws ecr get-login-password --region us-east-1 | helm registry login --username AWS --password-stdin 362923047827.dkr.ecr.us-east-1.amazonaws.com/netdata-cloud-onprem +``` + +After this step you should be able to add the repository to your helm or just pull the helm chart: +```bash +helm pull oci://362923047827.dkr.ecr.us-east-1.amazonaws.com/netdata-cloud-dependency --untar #optional +helm pull oci://362923047827.dkr.ecr.us-east-1.amazonaws.com/netdata-cloud-onprem --untar +``` + +Local folders with the newest versions of helm charts should appear on your working dir. + +## Installation + +Netdata provides access to two helm charts: +1. netdata-cloud-dependency - required applications for netdata-cloud-onprem. Not for production use. +2. netdata-cloud-onprem - the application itself + provisioning + +### netdata-cloud-dependency +The entire helm chart is designed around the idea that it allows the installation of the necessary applications: +- Redis +- Elasticsearch +- EMQX +- Apache Pulsar +- PostgreSQL +- Traefik +- Mailcatcher +- k8s-ecr-login-renew +- kubernetes-ingress + +Every configuration option is available through `values.yaml` in the folder that contains your netdata-cloud-dependency helm chart. All configuration options are described in README.md which is a part of the helm chart. It is enough to mention here that each component can be enabled/disabled individually. It is done by true/false switches in `values.yaml`. In this way, it is easier for the user to migrate to production-grade components gradually. + +Unless you prefer a different solution to the problem, `k8s-ecr-login-renew` is responsible for calling out the `AWS API` for token regeneration. This token is then injected into the secret that every node is using for authentication with secured ECR when pulling the images. +The default setting in `values.yaml` of `netdata-cloud-onprem` - `.global.imagePullSecrets` is configured to work out of the box with the dependency helm chart. + +For helm chart installation - save your changes in `values.yaml` and execute: +```shell +cd [your helm chart location] +helm upgrade --wait --install netdata-cloud-dependency -n netdata-cloud --create-namespace -f values.yaml . +``` + +### netdata-cloud-onprem + +Every configuration option is available through `values.yaml` in the folder that contains your netdata-cloud-onprem helm chart. All configuration options are described in README.md which is a part of the helm chart. + +#### Installing Netdata Cloud On-Prem +```shell +cd [your helm chart location] +helm upgrade --wait --install netdata-cloud-onprem -n netdata-cloud --create-namespace -f values.yaml . +``` + +##### Important notes +1. Installation takes care of provisioning the resources with migration services. +1. During the first installation, a secret called the `netdata-cloud-common` is created. It contains several randomly generated entries. Deleting helm chart is not going to delete this secret, nor reinstalling the whole On-Prem, unless manually deleted by kubernetes administrator. The content of this secret is extremely relevant - strings that are contained there are essential parts of encryption. Losing or changing the data that it contains will result in data loss. + +## Short description of services +#### cloud-accounts-service +Responsible for user registration & authentication. Manages user account information. +#### cloud-agent-data-ctrl-service +Forwards request from the cloud to the relevant agents. +The requests include: +* Fetching chart metadata from the agent +* Fetching chart data from the agent +* Fetching function data from the agent +#### cloud-agent-mqtt-input-service +Forwards MQTT messages emitted by the agent related to the agent entities to the internal Pulsar broker. These include agent connection state updates. +#### cloud-agent-mqtt-output-service +Forwards Pulsar messages emitted in the cloud related to the agent entities to the MQTT broker. From there, the messages reach the relevant agent. +#### cloud-alarm-config-mqtt-input-service +Forwards MQTT messages emitted by the agent related to the alarm-config entities to the internal Pulsar broker. These include the data for the alarm configuration as seen by the agent. +#### cloud-alarm-log-mqtt-input-service +Forwards MQTT messages emitted by the agent related to the alarm-log entities to the internal Pulsar broker. These contain data about the alarm transitions that occurred in an agent. +#### cloud-alarm-mqtt-output-service +Forwards Pulsar messages emitted in the cloud related to the alarm entities to the MQTT broker. From there, the messages reach the relevant agent. +#### cloud-alarm-processor-service +Persists latest alert statuses received from the agent in the cloud. +Aggregates alert statuses from relevant node instances. +Exposes API endpoints to fetch alert data for visualization on the cloud. +Determines if notifications need to be sent when alert statuses change and emits relevant messages to Pulsar. +Exposes API endpoints to store and return notification-silencing data. +#### cloud-alarm-streaming-service +Responsible for starting the alert stream between the agent and the cloud. +Ensures that messages are processed in the correct order, and starts a reconciliation process between the cloud and the agent if out-of-order processing occurs. +#### cloud-charts-mqtt-input-service +Forwards MQTT messages emitted by the agent related to the chart entities to the internal Pulsar broker. These include the chart metadata that is used to display relevant charts on the cloud. +#### cloud-charts-mqtt-output-service +Forwards Pulsar messages emitted in the cloud related to the charts entities to the MQTT broker. From there, the messages reach the relevant agent. +#### cloud-charts-service +Exposes API endpoints to fetch the chart metadata. +Forwards data requests via the `cloud-agent-data-ctrl-service` to the relevant agents to fetch chart data points. +Exposes API endpoints to call various other endpoints on the agent, for instance, functions. +#### cloud-custom-dashboard-service +Exposes API endpoints to fetch and store custom dashboard data. +#### cloud-environment-service +Serves as the first contact point between the agent and the cloud. +Returns authentication and MQTT endpoints to connecting agents. +#### cloud-feed-service +Processes incoming feed events and stores them in Elasticsearch. +Exposes API endpoints to fetch feed events from Elasticsearch. +#### cloud-frontend +Contains the on-prem cloud website. Serves static content. +#### cloud-iam-user-service +Acts as a middleware for authentication on most of the API endpoints. Validates incoming token headers, injects the relevant ones, and forwards the requests. +#### cloud-metrics-exporter +Exports various metrics from an On-Prem Cloud installation. Uses the Prometheus metric exposition format. +#### cloud-netdata-assistant +Exposes API endpoints to fetch a human-friendly explanation of various netdata configuration options, namely the alerts. +#### cloud-node-mqtt-input-service +Forwards MQTT messages emitted by the agent related to the node entities to the internal Pulsar broker. These include the node metadata as well as their connectivity state, either direct or via parents. +#### cloud-node-mqtt-output-service +Forwards Pulsar messages emitted in the cloud related to the charts entities to the MQTT broker. From there, the messages reach the relevant agent. +#### cloud-notifications-dispatcher-service +Exposes API endpoints to handle integrations. +Handles incoming notification messages and uses the relevant channels(email, slack...) to notify relevant users. +#### cloud-spaceroom-service +Exposes API endpoints to fetch and store relations between agents, nodes, spaces, users, and rooms. +Acts as a provider of authorization for other cloud endpoints. +Exposes API endpoints to authenticate agents connecting to the cloud. + +## Infrastructure Diagram + + + +### If you have any questions or suggestions please contact the Netdata team. diff --git a/docs/netdata-cloud-onprem/infrastructure.jpeg b/docs/netdata-cloud-onprem/infrastructure.jpeg Binary files differnew file mode 100644 index 00000000..a866e141 --- /dev/null +++ b/docs/netdata-cloud-onprem/infrastructure.jpeg diff --git a/docs/netdata-cloud-onprem/troubleshooting-onprem.md b/docs/netdata-cloud-onprem/troubleshooting-onprem.md new file mode 100644 index 00000000..4f449c96 --- /dev/null +++ b/docs/netdata-cloud-onprem/troubleshooting-onprem.md @@ -0,0 +1,21 @@ +# Basic troubleshooting +We cannot predict how your particular installation of Netdata Cloud On-prem is going to work. It is a mixture of underlying infrastructure, the number of agents, and their topology. +You can always contact the Netdata team for recommendations! + +#### Loading charts takes a long time or ends with an error +Charts service is trying to collect the data from all of the agents in question. If we are talking about the overview screen, all of the nodes in space are going to be queried (`All nodes` room). If it takes a long time, there are a few things that should be checked: +1. How many nodes are you querying directly? + There is a big difference between having 100 nodes connected directly to the cloud compared to them being connected through a few parents. Netdata always prioritizes querying nodes through parents. This way, we can reduce some of the load by pushing the responsibility to query the data to the parent. The parent is then responsible for passing accumulated data from nodes connected to it to the cloud. +1. If you are missing data from endpoints all the time. + Netdata Cloud always queries nodes themselves for the metrics. The cloud only holds information about metadata, such as information about what charts can be pulled from any node, but not the data points themselves for any metric. This means that if a node is throttled by the network connection or under high resource pressure, the information exchange between the agent and cloud through the MQTT broker might take a long time. In addition to checking resource usage and networking, we advise using a parent node for such endpoints. Parents can hold the data from nodes that are connected to the cloud through them, eliminating the need to query those endpoints. +1. Errors on the cloud when trying to load charts. + If the entire data query is crashing and no data is displayed on the UI, it could indicate problems with the `cloud-charts-service`. The query you are performing might simply exceed the CPU and/or memory limits set on the deployment. We advise increasing those resources. +It takes a long time to load anything on the Cloud UI +When experiencing sluggishness and slow responsiveness, the following factors should be checked regarding the Postgres database: + 1. CPU: Monitor the CPU usage to ensure it is not reaching its maximum capacity. High and sustained CPU usage can lead to sluggish performance. + 1. Memory: Check if the database server has sufficient memory allocated. Inadequate memory could cause excessive disk I/O and slow down the database. + 1. Disk Queue / IOPS: Analyze the disk queue length and disk I/O operations per second (IOPS). A high disk queue length or limited IOPS can indicate a bottleneck and negatively impact database performance. +By examining these factors and ensuring that CPU, memory, and disk IOPS are within acceptable ranges, you can mitigate potential performance issues with the Postgres database. + +#### Nodes are not updated quickly on the Cloud UI +If you're experiencing delays with information exchange between the Cloud UI and the Agent, and you've already checked the networking and resource usage on the agent side, the problem may be related to Apache Pulsar or the database. Slow alerts on node alerts or slow updates on node status (online/offline) could indicate issues with message processing or database performance. You may want to investigate the performance of Apache Pulsar, ensure it is properly configured, and consider scaling or optimizing the database to handle the volume of data being processed or written to it. diff --git a/docs/netdata-for-IoT.md b/docs/netdata-for-IoT.md new file mode 100644 index 00000000..8dfed21e --- /dev/null +++ b/docs/netdata-for-IoT.md @@ -0,0 +1,78 @@ +<!-- +title: "Netdata for IoT" +custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/netdata-for-IoT.md +sidebar_label: "Netdata for IoT" +learn_status: "Published" +learn_rel_path: "Miscellaneous" +--> + +# Netdata for IoT + + + +> New to Netdata? Check its demo: **<https://my-netdata.io/>** +> +>[](https://registry.my-netdata.io/#netdata_registry) +> [](https://registry.my-netdata.io/#netdata_registry) +> [](https://registry.my-netdata.io/#netdata_registry) +> +>[](https://registry.my-netdata.io/#netdata_registry) +> [](https://registry.my-netdata.io/#netdata_registry) +> [](https://registry.my-netdata.io/#netdata_registry) + +--- + +Netdata is a [very efficient](https://github.com/netdata/netdata/blob/master/docs/guides/configure/performance.md) +server performance monitoring solution. When running in server hardware, it can collect +thousands of system and application metrics **per second** with just 1% CPU utilization of a single core. Its web server +responds to most data requests in about **half a millisecond** making its web dashboards spontaneous, amazingly fast! + +Netdata can also be a very efficient real-time monitoring solution for **IoT devices** (RPIs, routers, media players, +wifi access points, industrial controllers and sensors of all kinds). Netdata will generally run everywhere a Linux +kernel runs (and it is glibc and [musl-libc](https://www.musl-libc.org/) friendly). + +You can use it as both a data collection agent (where you pull data using its API), for embedding its charts on other +web pages / consoles, but also for accessing it directly with your browser to view its dashboard. + +The Netdata web API already provides **reduce** functions allowing it to report **average** and **max** for any +timeframe. It can also respond in many formats including JSON, JSONP, CSV, HTML. Its API is also a **google charts** +provider so it can directly be used by google sheets, google charts, google widgets. + + + +Although Netdata has been significantly optimized to lower the CPU and RAM resources it consumes, the plethora of data +collection plugins may be inappropriate for weak IoT devices. Please follow +the [Netdata Agent performance guide](https://github.com/netdata/netdata/blob/master/docs/guides/configure/performance.md) + +## Monitoring RPi temperature + +The python version of the sensors plugin uses `lm-sensors`. Unfortunately the temperature reading of RPi are not +supported by `lm-sensors`. + +Netdata also has a bash version of the sensors plugin that can read RPi temperatures. It is disabled by default to avoid +the conflicts with the python version. + +To enable it, run: + +```bash +cd /etc/netdata # Replace this path with your Netdata config directory +sudo ./edit-config charts.d.conf +``` + +and uncomment this line: + +```sh +sensors=force +``` + +Then restart Netdata. You will get this: + + + + diff --git a/docs/netdata-security.md b/docs/netdata-security.md new file mode 100644 index 00000000..2716e08e --- /dev/null +++ b/docs/netdata-security.md @@ -0,0 +1,429 @@ +# Security and privacy design + +This document serves as the relevant Annex to the [Terms of Service](https://www.netdata.cloud/service-terms/), +the [Privacy Policy](https://www.netdata.cloud/privacy/) and +the Data Processing Addendum, when applicable. It provides more information regarding Netdata’s technical and +organizational security and privacy measures. + +We have given special attention to all aspects of Netdata, ensuring that everything throughout its operation is as +secure as possible. Netdata has been designed with security in mind. + +## Netdata's Security Principles + +### Security by Design + +Netdata, an open-source software widely installed across the globe, prioritizes security by design, showcasing our +commitment to safeguarding user data. The entire structure and internal architecture of the software is built to ensure +maximum security. We aim to provide a secure environment from the ground up, rather than as an afterthought. + +### Compliance with Open Source Security Foundation Best Practices + +Netdata is committed to adhering to the best practices laid out by the Open Source Security Foundation (OSSF). +Currently, the Netdata Agent follows the OSSF best practices at the passing level. Feel free to audit our approach to +the [OSSF guidelines](https://bestpractices.coreinfrastructure.org/en/projects/2231) + +Netdata Cloud boasts of comprehensive end-to-end automated testing, encompassing the UI, back-end, and agents, where +involved. In addition, the Netdata Agent uses an array of third-party services for static code analysis, static code +security analysis, and CI/CD integrations to ensure code quality on a per pull request basis. Tools like Github's +CodeQL, Github's Dependabot, our own unit tests, various types of linters, +and [Coverity](https://scan.coverity.com/projects/netdata-netdata?tab=overview) are utilized to this end. + +Moreover, each PR requires two code reviews from our senior engineers before being merged. We also maintain two +high-performance environments (a production-like kubernetes cluster and a highly demanding stress lab) for +stress-testing our entire solution. This robust pipeline ensures the delivery of high-quality software consistently. + +### Regular Third-Party Testing and Isolation + +While Netdata doesn't have a dedicated internal security team, the open-source Netdata Agent undergoes regular testing +by third parties. Any security reports received are addressed immediately. In contrast, Netdata Cloud operates in a +fully automated and isolated environment with Infrastructure as Code (IaC), ensuring no direct access to production +applications. Monitoring and reporting is also fully automated. + +### Security Vulnerability Response + +Netdata has a transparent and structured process for handling security vulnerabilities. We appreciate and value the +contributions of security researchers and users who report vulnerabilities to us. All reports are thoroughly +investigated, and any identified vulnerabilities trigger a Security Release Process. + +We aim to fully disclose any bugs as soon as a user mitigation is available, typically within a week of the report. In +case of security fixes, we promptly release a new version of the software. Users can subscribe to our releases on GitHub +to stay updated about all security incidents. More details about our vulnerability response process can be +found [here](https://github.com/netdata/netdata/security/policy). + +### Adherence to Open Source Security Foundation Best Practices + +In line with our commitment to security, we uphold the best practices as outlined by the Open Source Security +Foundation. This commitment reflects in every aspect of our operations, from the design phase to the release process, +ensuring the delivery of a secure and reliable product to our users. For more information +check [here](https://bestpractices.coreinfrastructure.org/en/projects/2231). + +## Netdata Agent Security + +### Security by Design + +Netdata Agent is designed with a security-first approach. Its structure ensures data safety by only exposing chart +metadata and metric values, not the raw data collected. This design principle allows Netdata to be used in environments +requiring the highest level of data isolation, such as PCI Level 1. Even though Netdata plugins connect to a user's +database server or read application log files to collect raw data, only the processed metrics are stored in Netdata +databases, sent to upstream Netdata servers, or archived to external time-series databases. + +### User Data Protection + +The Netdata Agent is programmed to safeguard user data. When collecting data, the raw data does not leave the host. All +plugins, even those running with escalated capabilities or privileges, perform a hard-coded data collection job. They do +not accept commands from Netdata, and the original application data collected do not leave the process they are +collected in, are not saved, and are not transferred to the Netdata daemon. For the “Functions” feature, the data +collection plugins offer Functions, and the user interface merely calls them back as defined by the data collector. The +Netdata Agent main process does not require any escalated capabilities or privileges from the operating system, and +neither do most of the data collecting plugins. + +### Communication and Data Encryption + +Data collection plugins communicate with the main Netdata process via ephemeral, in-memory, pipes that are inaccessible +to any other process. + +Streaming of metrics between Netdata agents requires an API key and can also be encrypted with TLS if the user +configures it. + +The Netdata agent's web API can also use TLS if configured. + +When Netdata agents are claimed to Netdata Cloud, the communication happens via MQTT over Web Sockets over TLS, and +public/private keys are used for authorizing access. These keys are exchanged during the claiming process (usually +during the provisioning of each agent). + +### Authentication + +Direct user access to the agent is not authenticated, considering that users should either use Netdata Cloud, or they +are already on the same LAN, or they have configured proper firewall policies. However, Netdata agents can be hidden +behind an authenticating web proxy if required. + +For other Netdata agents streaming metrics to an agent, authentication via API keys is required and TLS can be used if +configured. + +For Netdata Cloud accessing Netdata agents, public/private key cryptography is used and TLS is mandatory. + +### Security Vulnerability Response + +If a security vulnerability is found in the Netdata Agent, the Netdata team acknowledges and analyzes each report within +three working days, kicking off a Security Release Process. Any vulnerability information shared with the Netdata team +stays within the Netdata project and is not disseminated to other projects unless necessary for fixing the issue. The +reporter is kept updated as the security issue moves from triage to identified fix, to release planning. More +information can be found [here](https://github.com/netdata/netdata/security/policy). + +### Protection Against Common Security Threats + +The Netdata agent is resilient against common security threats such as DDoS attacks and SQL injections. For DDoS, +Netdata agent uses a fixed number of threads for processing requests, providing a cap on the resources that can be +consumed. It also automatically manages its memory to prevent overutilization. SQL injections are prevented as nothing +from the UI is passed back to the data collection plugins accessing databases. + +Additionally, the Netdata agent is running as a normal, unprivileged, operating system user (a few data collections +require escalated privileges, but these privileges are isolated to just them), every netdata process runs by default +with a nice priority to protect production applications in case the system is starving for CPU resources, and Netdata +agents are configured by default to be the first processes to be killed by the operating system in case the operating +system starves for memory resources (OS-OOM - Operating System Out Of Memory events). + +### User Customizable Security Settings + +Netdata provides users with the flexibility to customize agent security settings. Users can configure TLS across the +system, and the agent provides extensive access control lists on all its interfaces to limit access to its endpoints +based on IP. Additionally, users can configure the CPU and Memory priority of Netdata agents. + +## Netdata Cloud Security + +Netdata Cloud is designed with a security-first approach to ensure the highest level of protection for user data. When +using Netdata Cloud in environments that require compliance with standards like PCI DSS, SOC 2, or HIPAA, users can be +confident that all collected data is stored within their infrastructure. Data viewed on dashboards and alert +notifications travel over Netdata Cloud, but are not stored—instead, they're transformed in transit, aggregated from +multiple agents and parents (centralization points), to appear as one data source in the user's browser. + +### User Identification and Authorization + +Netdata Cloud requires only an email address to create an account and use the service. User identification and +authorization are conducted either via third-party integrations (Google, GitHub accounts) or through short-lived access +tokens sent to the user’s email account. Email addresses are stored securely in our production database on AWS and are +also used for product and marketing communications. Netdata Cloud does not store user credentials. + +### Data Storage and Transfer + +Although Netdata Cloud does not store metric data, it does keep some metadata for each node connected to user spaces. +This metadata includes the hostname, information from the `/api/v1/info` endpoint, metric metadata +from `/api/v1/contexts`, and alerts configurations from `/api/v1/alarms`. This data is securely stored in our production +database on AWS and copied to Google BigQuery for analytics purposes. + +All data visible on Netdata Cloud is transferred through the Agent-Cloud link (ACLK) mechanism, which securely connects +a Netdata Agent to Netdata Cloud. The ACLK is encrypted and safe, and is only established if the user connects/claims +their node. Data in transit between a user and Netdata Cloud is encrypted using TLS. + +### Data Retention and Erasure + +Netdata Cloud maintains backups of customer content for approximately 90 days following a deletion. Users have the +ability to access, retrieve, correct, and delete personal data stored in Netdata Cloud. In case a user is unable to +delete personal data via self-services functionality, Netdata will delete personal data upon the customer's written +request, in accordance with applicable data protection law. + +### Infrastructure and Authentication + +Netdata Cloud operates on an Infrastructure as Code (IaC) model. Its microservices environment is completely isolated, +and all changes occur through Terraform. At the edge of Netdata Cloud, there is a TLS termination and an Identity and +Access Management (IAM) service that validates JWT tokens included in request cookies. + +Netdata Cloud does not store user credentials. + +### Security Features and Response + +Netdata Cloud offers a variety of security features, including infrastructure-level dashboards, centralized alerts +notifications, auditing logs, and role-based access to different segments of the infrastructure. The cloud service +employs several protection mechanisms against DDoS attacks, such as rate-limiting and automated blacklisting. It also +uses static code analysers to prevent other types of attacks. + +In the event of potential security vulnerabilities or incidents, Netdata Cloud follows the same process as the Netdata +agent. Every report is acknowledged and analyzed by the Netdata team within three working days, and the team keeps the +reporter updated throughout the process. + +### User Customization + +Netdata Cloud uses the highest level of security. There is no user customization available out of the box. Its security +settings are designed to provide maximum protection for all users. We are offering customization (like custom SSO +integrations, custom data retention policies, advanced user access controls, tailored audit logs, integration with other +security tools, etc.) on a per contract basis. + +### Deleting Personal Data + +Users who wish to remove all personal data (including email and activities) can delete their cloud account by logging +into Netdata Cloud and accessing their profile. + +## User Privacy and Data Protection + +Netdata Cloud is built with an unwavering commitment to user privacy and data protection. We understand that our users' +data is both sensitive and valuable, and we have implemented stringent measures to ensure its safety. + +### Data Collection + +Netdata Cloud collects minimal personal information from its users. The only personal data required to create an account +and use the service is an email address. This email address is used for product and marketing communications. +Additionally, the IP address used to access Netdata Cloud is stored in web proxy access logs. + +### Data Usage + +The collected email addresses are stored in our production database on Amazon Web Services (AWS) and copied to Google +BigQuery, our data lake, for analytics purposes. These analytics are crucial for our product development process. If a +user accepts the use of analytical cookies, their email address and IP are stored in the systems we use to track +application usage (Google Analytics, Posthog, and Gainsight PX). Subscriptions and Payments data are handled by Stripe. + +### Data Sharing + +Netdata Cloud does not share any personal data with third parties, ensuring the privacy of our users' data, but Netdata +Cloud does use third parties for its services, including, but not limited to, Google Cloud and Amazon Web Services for +its infrastructure, Stripe for payment processing, Google Analytics, Posthog and Gainsight PX for analytics. + +### Data Protection + +We use state-of-the-art security measures to protect user data from unauthorized access, use, or disclosure. All +infrastructure data visible on Netdata Cloud passes through the Agent-Cloud Link (ACLK) mechanism, which securely +connects a Netdata Agent to Netdata Cloud. The ACLK is encrypted, safe, and is only established if the user connects +their node. All data in transit between a user and Netdata Cloud is encrypted using TLS. + +### User Control over Data + +Netdata provides its users with the ability to access, retrieve, correct, and delete their personal data stored in +Netdata Cloud. This ability may occasionally be limited due to temporary service outages for maintenance or other +updates to Netdata Cloud, or when it is technically not feasible. If a customer is unable to delete personal data via +the self-services functionality, Netdata deletes the data upon the customer's written request, within the timeframe +specified in the Data Protection Agreement (DPA), and in accordance with applicable data protection laws. + +### Compliance with Data Protection Laws + +Netdata Cloud is fully compliant with data protection laws like the General Data Protection Regulation (GDPR) and the +California Consumer Privacy Act (CCPA). + +### Data Transfer + +Data transfer within Netdata Cloud is secure and respects the privacy of the user data. The Netdata Agent establishes an +outgoing secure WebSocket (WSS) connection to Netdata Cloud, ensuring that the data is encrypted when in transit. + +### Use of Tracking Technologies + +Netdata Cloud uses analytical cookies if a user consents to their use. These cookies are used to track the usage of the +application and are stored in systems like Google Analytics, Posthog and Gainsight PX. + +### Data Breach Notification Process + +In the event of a data breach, Netdata has a well-defined process in place for notifying users. The details of this +process align with the standard procedures and timelines defined in the Data Protection Agreement (DPA). + +We continually review and update our privacy and data protection practices to ensure the highest level of data safety +and privacy for our users. + +## Compliance with Regulations + +Netdata is committed to ensuring the security, privacy, and integrity of user data. It complies with both the General +Data Protection Regulation (GDPR), a regulation in EU law on data protection and privacy, and the California Consumer +Privacy Act (CCPA), a state statute intended to enhance privacy rights and consumer protection for residents of +California. + +### Compliance with GDPR and CCPA + +Compliance with GDPR and CCPA are self-assessment processes, and Netdata has undertaken thorough internal audits and +controls to ensure it meets all requirements. + +As per request basis, any customer may enter with Netdata into a data processing addendum (DPA) governing customer’s +ability to load and permit Netdata to process any personal data or information regulated under applicable data +protection laws, including the GDPR and CCPA. + +### Data Transfers + +While Netdata Agent itself does not engage in any cross-border data transfers, certain personal and infrastructure data +is transferred to Netdata Cloud for the purpose of providing its services. The metric data collected and processed by +Netdata Agents, however, stays strictly within the user's infrastructure, eliminating any concerns about cross-border +data transfer issues. + +When users utilize Netdata Cloud, the metric data is streamed directly from the Netdata Agent to the users’ web browsers +via Netdata Cloud, without being stored on Netdata Cloud's servers. However, user identification data (such as email +addresses) and infrastructure metadata necessary for Netdata Cloud's operation are stored in data centers in the United +States, using compliant infrastructure providers such as Google Cloud and Amazon Web Services. These transfers and +storage are carried out in full compliance with applicable data protection laws, including GDPR and CCPA. + +### Privacy Rights + +Netdata ensures user privacy rights as mandated by the GDPR and CCPA. This includes the right to access, correct, and +delete personal data. These functions are all available online via the Netdata Cloud User Interface (UI). In case a user +wants to remove all personal information (email and activities), they can delete their cloud account by logging +into https://app.netdata.cloud and accessing their profile, at the bottom left of the screen. + +### Regular Review and Updates + +Netdata is dedicated to keeping its practices up-to-date with the latest developments in data protection regulations. +Therefore, as soon as updates or changes are made to these regulations, Netdata reviews and updates its policies and +practices accordingly to ensure continual compliance. + +While Netdata is confident in its compliance with GDPR and CCPA, users are encouraged to review Netdata's privacy policy +and reach out with any questions or concerns they may have about data protection and privacy. + +## Anonymous Statistics + +The anonymous statistics collected by the Netdata Agent are related to the installations and not to individual users. +This data includes community size, types of plugins used, possible crashes, operating systems installed, and the use of +the registry feature. No IP addresses are collected, but each Netdata installation has a unique ID. + +Netdata also collects anonymous telemetry events, which provide information on the usage of various features, errors, +and performance metrics. This data is used to understand how the software is being used and to identify areas for +improvement. + +The purpose of collecting these statistics and telemetry data is to guide the development of the open-source agent, +focusing on areas that are most beneficial to users. + +Users have the option to opt out of this data collection during the installation of the agent, or at any time by +removing a specific file from their system. + +Netdata retains this data indefinitely in order to track changes and trends within the community over time. + +Netdata does not share these anonymous statistics or telemetry data with any third parties. + +By collecting this data, Netdata is able to continuously improve their service and identify any issues or areas for +improvement, while respecting user privacy and maintaining transparency. + +## Internal Security Measures + +Internal Security Measures at Netdata are designed with an emphasis on data privacy and protection. The measures +include: + +1. **Infrastructure as Code (IaC)** : + Netdata Cloud follows the IaC model, which means it is a microservices environment that is completely isolated. All + changes are managed through Terraform, an open-source IaC software tool that provides a consistent CLI workflow for + managing cloud services. +2. **TLS Termination and IAM Service** : + At the edge of Netdata Cloud, there is a TLS termination, which provides the decryption point for incoming TLS + connections. Additionally, an Identity Access Management (IAM) service validates JWT tokens included in request + cookies or denies access to them. +3. **Session Identification** : + Once inside the microservices environment, all requests are associated with session IDs that identify the user making + the request. This approach provides additional layers of security and traceability. +4. **Data Storage** : + Data is stored in various NoSQL and SQL databases and message brokers. The entire environment is fully isolated, + providing a secure space for data management. +5. **Authentication** : + Netdata Cloud does not store credentials. It offers three types of authentication: GitHub Single Sign-On (SSO), + Google SSO, and email validation. +6. **DDoS Protection** : + Netdata Cloud has multiple protection mechanisms against Distributed Denial of Service (DDoS) attacks, including + rate-limiting and automated blacklisting. +7. **Security-Focused Development Process** : + To ensure a secure environment, Netdata employs a security-focused development process. This includes the use of + static code analysers to identify potential security vulnerabilities in the codebase. +8. **High Security Standards** : + Netdata Cloud maintains high security standards and can provide additional customization on a per contract basis. +9. **Employee Security Practices** : + Netdata ensures its employees follow security best practices, including role-based access, periodic access review, + and multi-factor authentication. This helps to minimize the risk of unauthorized access to sensitive data. +10. **Experienced Developers** : + Netdata hires senior developers with vast experience in security-related matters. It enforces two code reviews for + every Pull Request (PR), ensuring that any potential issues are identified and addressed promptly. +11. **DevOps Methodologies** : + Netdata's DevOps methodologies use the highest standards in access control in all places, utilizing the best + practices available. +12. **Risk-Based Security Program** : + Netdata has a risk-based security program that continually assesses and mitigates risks associated with data + security. This program helps maintain a secure environment for user data. + +These security measures ensure that Netdata Cloud is a secure environment for users to monitor and troubleshoot their +systems. The company remains committed to continuously improving its security practices to safeguard user data +effectively. + +## PCI DSS + +PCI DSS (Payment Card Industry Data Security Standard) is a set of security standards designed to ensure that all +companies that accept, process, store or transmit credit card information maintain a secure environment. + +Netdata is committed to providing secure and privacy-respecting services, and it aligns its practices with many of the +key principles of the PCI DSS. However, it's important to clarify that Netdata is not officially certified as PCI +DSS-compliant. While Netdata follows practices that align with PCI DSS's key principles, the company itself has not +undergone the formal certification process for PCI DSS compliance. + +PCI DSS compliance is not just about the technical controls but also involves a range of administrative and procedural +safeguards that go beyond the scope of Netdata's services. These include, among other things, maintaining a secure +network, implementing strong access control measures, regularly monitoring and testing networks, and maintaining an +information security policy. + +Therefore, while Netdata can support entities with their data security needs in relation to PCI DSS, it is ultimately +the responsibility of the entity to ensure full PCI DSS compliance across all of their operations. Entities should +always consult with a legal expert or a PCI DSS compliance consultant to ensure that their use of any product, including +Netdata, aligns with PCI DSS regulations. + +## HIPAA + +HIPAA stands for the Health Insurance Portability and Accountability Act, which is a United States federal law enacted +in 1996. HIPAA is primarily focused on protecting the privacy and security of individuals' health information. + +Netdata is committed to providing secure and privacy-respecting services, and it aligns its practices with many key +principles of HIPAA. However, it's important to clarify that Netdata is not officially certified as HIPAA-compliant. +While Netdata follows practices that align with HIPAA's key principles, the company itself has not undergone the formal +certification process for HIPAA compliance. + +HIPAA compliance is not just about technical controls but also involves a range of administrative and procedural +safeguards that go beyond the scope of Netdata's services. These include, among other things, employee training, +physical security, and contingency planning. + +Therefore, while Netdata can support HIPAA-regulated entities with their data security needs and is prepared to sign a +Business Associate Agreement (BAA), it is ultimately the responsibility of the healthcare entity to ensure full HIPAA +compliance across all of their operations. Entities should always consult with a legal expert or a HIPAA compliance +consultant to ensure that their use of any product, including Netdata, aligns with HIPAA regulations. + +## Conclusion + +In conclusion, Netdata Cloud's commitment to data security and user privacy is paramount. From the careful design of the +infrastructure and stringent internal security measures to compliance with international regulations and standards like +GDPR and CCPA, Netdata Cloud ensures a secure environment for users to monitor and troubleshoot their systems. + +The use of advanced encryption techniques, role-based access control, and robust authentication methods further +strengthen the security of user data. Netdata Cloud also maintains transparency in its data handling practices, giving +users control over their data and the ability to easily access, retrieve, correct, and delete their personal data. + +Netdata's approach to anonymous statistics collection respects user privacy while enabling the company to improve its +product based on real-world usage data. Even in such cases, users have the choice to opt-out, underlining Netdata's +respect for user autonomy. + +In summary, Netdata Cloud offers a highly secure, user-centric environment for system monitoring and troubleshooting. +The company's emphasis on continuous security improvement and commitment to user privacy make it a trusted choice in the +data monitoring landscape. + diff --git a/docs/quickstart/infrastructure.md b/docs/quickstart/infrastructure.md new file mode 100644 index 00000000..d2e7f2d8 --- /dev/null +++ b/docs/quickstart/infrastructure.md @@ -0,0 +1,226 @@ +import { Grid, Box, BoxList, BoxListItemRegexLink } from '@site/src/components/Grid/' +import { RiExternalLinkLine } from 'react-icons/ri' + +# Monitor your infrastructure + +Learn how to view key metrics, insightful charts, and active alerts from all your nodes, with Netdata Cloud's real-time infrastructure monitoring. + +[Netdata Cloud](https://app.netdata.cloud) provides scalable infrastructure monitoring for any number of distributed +nodes running the Netdata Agent. A node is any system in your infrastructure that you want to monitor, whether it's a +physical or virtual machine (VM), container, cloud deployment, or edge/IoT device. + +The Netdata Agent uses zero-configuration collectors to gather metrics from every application and container instantly, +and uses Netdata's [distributed data architecture](https://github.com/netdata/netdata/blob/master/docs/store/distributed-data-architecture.md) to store metrics +locally. Without a slow and troublesome centralized data lake for your infrastructure's metrics, you reduce the +resources you need to invest in, and the complexity of, monitoring your infrastructure. + +Netdata Cloud unifies infrastructure monitoring by _centralizing the interface_ you use to query and visualize your +nodes' metrics, not the data. By streaming metrics values to your browser, with Netdata Cloud acting as the secure proxy +between them, you can monitor your infrastructure using customizable, interactive, and real-time visualizations from any +number of distributed nodes. + +In this quickstart guide, you'll learn the basics of using Netdata Cloud to monitor an infrastructure with dashboards, +composite charts, and alert viewing. You'll then learn about the most critical ways to configure the Agent on each of +your nodes to maximize the value you get from Netdata. + +This quickstart assumes you've [installed Netdata](https://github.com/netdata/netdata/edit/master/packaging/installer/README.md) +on more than one node in your infrastructure, and connected those nodes to your Space in Netdata Cloud. + +## Set up your Netdata Cloud experience + +Start your infrastructure monitoring experience by setting up your Netdata Cloud account. + +### Organize Spaces and War Rooms + +Spaces are high-level containers to help you organize your team members and the nodes they can view in each War Room. +You already have at least one Space in your Netdata Cloud account. + +A single Space puts all your metrics in one easily-accessible place, while multiple Spaces creates logical division +between different users and different pieces of a large infrastructure. For example, a large organization might have one +SRE team for the user-facing SaaS application, and a second IT team for managing employees' hardware. Since these teams +don't monitor the same nodes, they can work in separate Spaces and then further organize their nodes into War Rooms. + +Next, set up War Rooms. Netdata Cloud creates dashboards and visualizations based on the nodes added to a given War +Room. You can [organize War Rooms](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/organize-your-infrastrucutre-invite-your-team.md#war-room-organization) in any way +you want, such as by the application type, for end-to-end application monitoring, or as an incident response tool. + +Learn more about [Spaces](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/organize-your-infrastrucutre-invite-your-team.md#netdata-cloud-spaces) and [War +Rooms](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/organize-your-infrastrucutre-invite-your-team.md#netdata-cloud-war-rooms), including how to manage each, in their respective reference +documentation. + +### Invite your team + +Netdata Cloud makes an infrastructure's real-time metrics available and actionable to all organization members. By +inviting others, you can better synchronize with your team or colleagues to understand your infrastructure's heartbeat. +When something goes wrong, you'll be ready to collaboratively troubleshoot complex performance problems from a single +pane of glass. + +To [invite new users](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/organize-your-infrastrucutre-invite-your-team.md#invite-your-team), click on **Invite Users** in the +Space management Area. Choose which War Rooms to add this user to, then click **Send**. + +If your team members have trouble signing in, direct them to the [Netdata Cloud sign +in](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/sign-in.md) doc. + +### See an overview of your infrastructure + +Netdata Cloud utilizes "tabs" in order to provide you with informative sections based on your infrastructure. +These tabs can be separated into "static", meaning they are by default presented, and "non-static" which are tabs that get presented by user action (e.g clicking on a custom dashboard) + +#### Static tabs + +- The default tab for any War Room is the [Home tab](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/overview.md#home), which gives you an overview of this Space. + Here you can see the number of Nodes claimed, data retention statics, users by role, alerts and more. + +- The second and most important tab is the [Overview tab](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/overview.md#overview-and-single-node-view) which uses composite charts to display real-time metrics from every available node in a given War Room. + +- The [Nodes tab](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/nodes.md) gives you the ability to see the status (offline or online), host details, alert status and also a short overview of some key metrics from all your nodes at a glance. + +- [Kubernetes tab](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/kubernetes.md) is a logical grouping of charts regarding your Kubernetes clusters. It contains a subset of the charts available in the **Overview tab**. + +- The [Dashboards tab](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/dashboards.md) gives you the ability to have tailored made views of specific/targeted interfaces for your infrastructure using any number of charts from any number of nodes. + +- The [Alerts tab](https://github.com/netdata/netdata/blob/master/docs/monitor/view-active-alerts.md) provides you with an overview for all the active alerts you receive for the nodes in this War Room, you can also see all the alerts that are configured to be triggered in any given moment. + +- The [Anomalies tab](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/anomaly-advisor.md) is dedicated to the Anomaly Advisor tool. + +- The [Functions tab](https://github.com/netdata/netdata/blob/master/docs/cloud/netdata-functions.md) gives you the ability to visualize functions that the Netdata Agent collectors are able to expose. + +- The [Feed & events](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/events-feed.md) tab lets you investigate events that occurred in the past, which is invaluable for troubleshooting. + +#### Dynamic tabs + +If you open a [new dashboard](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/dashboards.md), jump to a single-node dashboard, or navigate to a dedicated alert page, a new tab will open in War Room bar. + +Tabs can be rearranged with drag-and-drop or closed with the **X** button. Open tabs persist between sessions, so you can always come right back to your preferred setup. + +### Drill down to specific nodes + +Both the Overview and the Nodes tab offer easy access to **single-node dashboards** for targeted analysis. You can use +single-node dashboards in Netdata Cloud to drill down on specific issues, scrub backward in time to investigate +historical data, and see like metrics presented meaningfully to help you troubleshoot performance problems. + +Read about the process in the [infrastructure +overview](https://github.com/netdata/netdata/blob/master/docs/visualize/overview-infrastructure.md#drill-down-with-single-node-dashboards) doc, then learn about [interacting with +dashboards and charts](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/interact-new-charts.md) to get the most from all of Netdata's real-time +metrics. + +### Create new dashboards + +You can use Netdata Cloud to create new dashboards that match your infrastructure's topology or help you diagnose +complex issues by aggregating correlated charts from any number of nodes. For example, you could monitor the system CPU +from every node in your infrastructure on a single dashboard. + +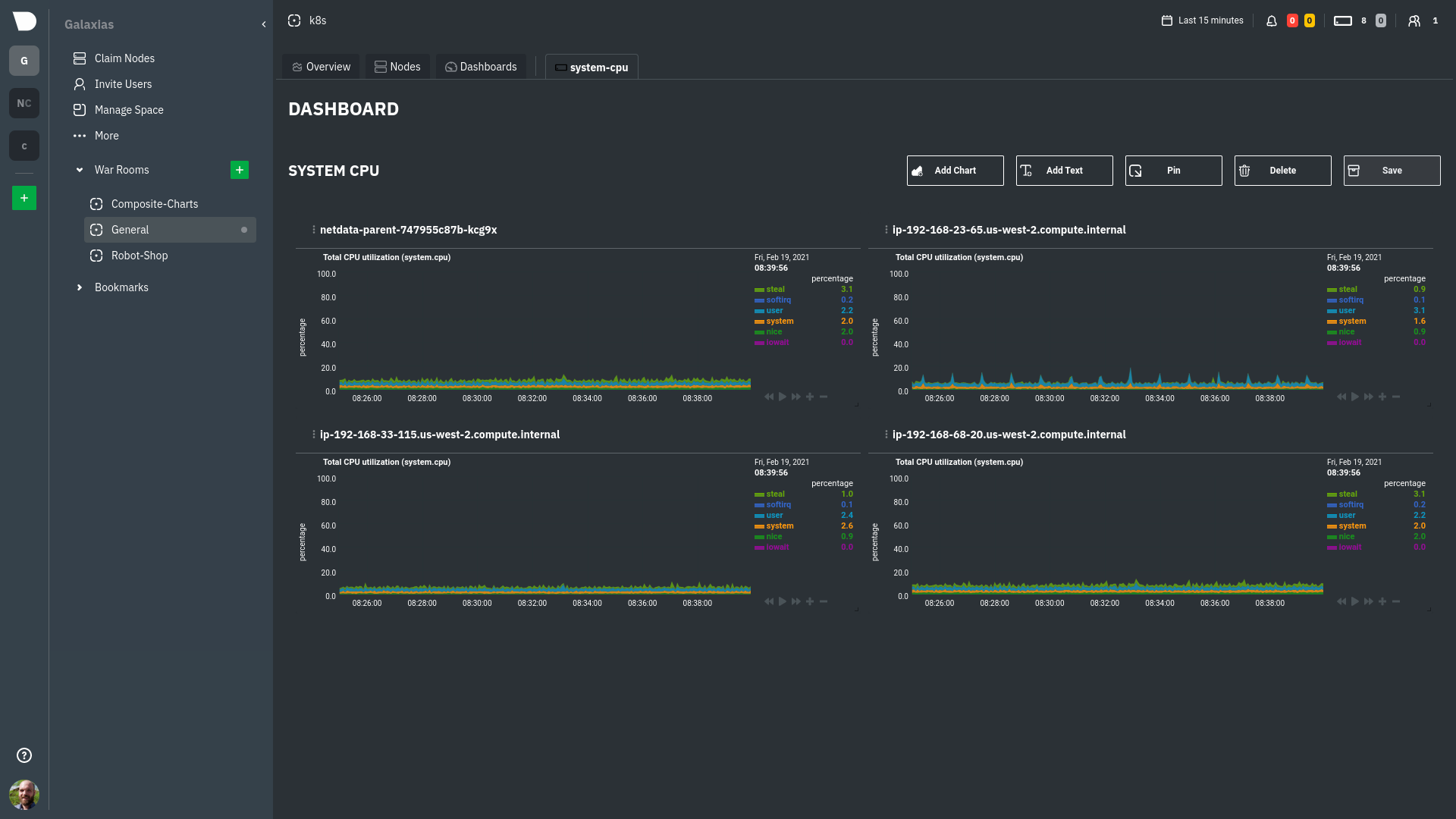 + +Read more about [creating new dashboards](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/dashboards.md) for more details about the process and +additional tips on best leveraging the feature to help you troubleshoot complex performance problems. + +## Set up your nodes + +You get the most value out of Netdata Cloud's infrastructure monitoring capabilities if each node collects every +possible metric. For example, if a node in your infrastructure is responsible for serving a MySQL database, you should +ensure that the Netdata Agent on that node is properly collecting and streaming all MySQL-related metrics. + +In most cases, collectors autodetect their data source and require no configuration, but you may need to configure +certain behaviors based on your infrastructure. Or, you may want to enable/configure advanced functionality, such as +longer metrics retention or streaming. + +### Configure the Netdata Agent on your nodes + +You can configure any node in your infrastructure if you need to, although most users will find the default settings +work extremely well for monitoring their infrastructures. + +Each node has a configuration file called `netdata.conf`, which is typically at `/etc/netdata/netdata.conf`. The best +way to edit this file is using the `edit-config` script, which ensures updates to the Netdata Agent do not overwrite +your changes. For example: + +```bash +cd /etc/netdata +sudo ./edit-config netdata.conf +``` + +Our [configuration basics doc](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md) contains more information about `netdata.conf`, `edit-config`, +along with simple examples to get you familiar with editing your node's configuration. + +After you've learned the basics, you should [secure your infrastructure's nodes](https://github.com/netdata/netdata/blob/master/docs/netdata-security.md) using +one of our recommended methods. These security best practices ensure no untrusted parties gain access to the metrics +collected on any of your nodes. + +### Collect metrics from systems and applications + +Netdata has [300+ pre-installed collectors](https://github.com/netdata/netdata/blob/master/collectors/COLLECTORS.md) that gather thousands of metrics with zero +configuration. Collectors search each of your nodes in default locations and ports to find running applications and +gather as many metrics as they can without you having to configure them individually. + +Most collectors work without configuration, should you want more info, you can read more on [how Netdata's metrics collectors work](https://github.com/netdata/netdata/blob/master/collectors/README.md) and the [Collectors configuration reference](https://github.com/netdata/netdata/blob/master/collectors/REFERENCE.md) documentation. + +In addition, find detailed information about which [system](https://github.com/netdata/netdata/blob/master/docs/collect/system-metrics.md), +[container](https://github.com/netdata/netdata/blob/master/docs/collect/container-metrics.md), and [application](https://github.com/netdata/netdata/blob/master/docs/collect/application-metrics.md) metrics you can +collect from across your infrastructure with Netdata. + +## Netdata Cloud features + +<Grid columns="2"> + <Box + title="Spaces and War Rooms"> + <BoxList> + <BoxListItemRegexLink to="[](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/organize-your-infrastrucutre-invite-your-team.md#netdata-cloud-spaces)" title="Spaces" /> + <BoxListItemRegexLink to="[](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/organize-your-infrastrucutre-invite-your-team.md#netdata-cloud-war-rooms)" title="War Rooms" /> + </BoxList> + </Box> + <Box + title="Dashboards"> + <BoxList> + <BoxListItemRegexLink to="[](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/overview.md)" title="Overview" /> + <BoxListItemRegexLink to="[](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/nodes.md)" title="Nodes tab" /> + <BoxListItemRegexLink to="[](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/kubernetes.md)" title="Kubernetes" /> + <BoxListItemRegexLink to="[](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/dashboards.md)" title="Create new dashboards" /> + </BoxList> + </Box> + <Box + title="Alerts and notifications"> + <BoxList> + <BoxListItemRegexLink to="[](https://github.com/netdata/netdata/blob/master/docs/monitor/view-active-alerts.md#netdata-cloud)" title="View active alerts" /> + <BoxListItemRegexLink to="[](https://github.com/netdata/netdata/blob/master/docs/cloud/alerts-notifications/notifications.md)" title="Alert notifications" /> + </BoxList> + </Box> + <Box + title="Troubleshooting with Netdata Cloud"> + <BoxListItemRegexLink to="[](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/metric-correlations.md)" title="Metric Correlations" /> + <BoxListItemRegexLink to="[](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/anomaly-advisor.md)" title="Anomaly Advisor" /> + <BoxListItemRegexLink to="[](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/events-feed.md)" title="Events Feed" /> + </Box> + <Box + title="Management and settings"> + <BoxList> + <BoxListItemRegexLink to="[](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/sign-in.md)" title="Sign in with email, Google, or GitHub" /> + <BoxListItemRegexLink to="[](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/organize-your-infrastrucutre-invite-your-team.md#invite-your-team)" title="Invite your team" /> + <BoxListItemRegexLink to="[](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/themes.md)" title="Choose your Netdata Cloud theme" /> + <BoxListItemRegexLink to="[](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/role-based-access.md)" title="Role-Based Access" /> + <BoxListItemRegexLink to="[](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/plans.md)" title="Paid Plans" /> + </BoxList> + </Box> +</Grid> + +- Spaces and War Rooms + - [Spaces](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/organize-your-infrastrucutre-invite-your-team.md#netdata-cloud-spaces) + - [War Rooms](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/organize-your-infrastrucutre-invite-your-team.md#netdata-cloud-war-rooms) +- Dashboards + - [Overview](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/overview.md) + - [Nodes tab](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/nodes.md) + - [Kubernetes](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/kubernetes.md) + - [Create new dashboards](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/dashboards.md) +- Alerts and notifications + - [View active alerts](https://github.com/netdata/netdata/blob/master/docs/monitor/view-active-alerts.md#netdata-cloud) + - [Alert notifications](https://github.com/netdata/netdata/blob/master/docs/cloud/alerts-notifications/notifications.md) +- Troubleshooting with Netdata Cloud + - [Metric Correlations](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/metric-correlations.md) + - [Anomaly Advisor](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/anomaly-advisor.md) + - [Events Feed](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/events-feed.md) +- Management and settings + - [Sign in with email, Google, or GitHub](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/sign-in.md) + - [Invite your team](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/organize-your-infrastrucutre-invite-your-team.md#invite-your-team) + - [Choose your Netdata Cloud theme](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/themes.md) + - [Role-Based Access](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/role-based-access.md) + - [Paid Plans](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/plans.md) diff --git a/docs/running-through-cf-tunnels.md b/docs/running-through-cf-tunnels.md new file mode 100644 index 00000000..9dc263b5 --- /dev/null +++ b/docs/running-through-cf-tunnels.md @@ -0,0 +1,113 @@ +# Running a Local Dashboard through Cloudflare Tunnels + +## Summary of tasks + +- Make a `netdata-web` HTTP tunnel on the parent node, so the web interface can be viewed publicly +- Make a `netdata-tcp` tcp tunnel on the parent node, so it can receive tcp streams from child nodes +- Provide access to the `netdata-tcp` tunnel on the child nodes, so you can send the tcp stream to the parent node +- Make sure the parent node uses port `19999` for both web and tcp streams +- Make sure that the child nodes have `mode = none` in the `[web]` section of the `netdata.conf` file, and `destination = tcp:127.0.0.1:19999` in the `[stream]` section of the `stream.conf` file + +## Detailed instructions with commands and service files + +- Install the `cloudflared` package on all your Netdata nodes, follow the repository instructions [here](https://pkg.cloudflare.com/index.html) + +- Login to cloudflare with `sudo cloudflared login` on all your Netdata nodes + +### Parent node: public web interface and receiving stats from Child nodes + +- Create the HTTP tunnel + `sudo cloudflared tunnel create netdata-web` +- Start routing traffic + `sudo cloudflared tunnel route dns netdata-web netdata-web.my.domain` +- Create a service by making a file called `/etc/systemd/system/cf-tun-netdata-web.service` and input: + +```ini +[Unit] +Description=cloudflare tunnel netdata-web +After=network-online.target + +[Service] +Type=simple +User=root +Group=root +ExecStart=/usr/bin/cloudflared --no-autoupdate tunnel run --url http://localhost:19999 netdata-web +Restart=on-failure +TimeoutStartSec=0 +RestartSec=5s + +[Install] +WantedBy=multi-user.target +``` + +- Create the TCP tunnel + `sudo cloudflared tunnel create netdata-tcp` +- Start routing traffic + `sudo cloudflared tunnel route dns netdata-tcp netdata-tcp.my.domain` +- Create a service by making a file called `/etc/systemd/system/cf-tun-netdata-tcp.service` and input: + +```ini +[Unit] +Description=cloudflare tunnel netdata-tcp +After=network-online.target + +[Service] +Type=simple +User=root +Group=root +ExecStart=/usr/bin/cloudflared --no-autoupdate tunnel run --url tcp://localhost:19999 netdata-tcp +Restart=on-failure +TimeoutStartSec=0 +RestartSec=5s + +[Install] +WantedBy=multi-user.target +``` + +### Child nodes: send stats to the Parent node + +- Create a service by making a file called `/etc/systemd/system/cf-acs-netdata-tcp.service` and input: + +```ini +[Unit] +Description=cloudflare access netdata-tcp +After=network-online.target + +[Service] +Type=simple +User=root +Group=root +ExecStart=/usr/bin/cloudflared --no-autoupdate access tcp --url localhost:19999 --tunnel-host netdata-tcp.my.domain +Restart=on-failure +TimeoutStartSec=0 +RestartSec=5s + +[Install] +WantedBy=multi-user.target +``` + +You can edit the configuration file using the `edit-config` script from the Netdata [config directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md#the-netdata-config-directory). + +- Edit `netdata.conf` and input: + +```ini +[web] + mode = none +``` + +- Edit `stream.conf` and input: + +```ini +[stream] + destination = tcp:127.0.0.1:19999 +``` + +[Restart the Agents](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md), and you are done! + +You should now be able to have a Local Dashboard that gets its metrics from Child instances, running through Cloudflare tunnels. + +> ### Note +> +> You can find the origin of this page in [this discussion](https://discord.com/channels/847502280503590932/1154164395799216189/1154556625944854618) in our Discord server. +> +> We thought it was going to be helpful to all users, so we included it in our docs. diff --git a/docs/store/change-metrics-storage.md b/docs/store/change-metrics-storage.md new file mode 100644 index 00000000..456ea6c2 --- /dev/null +++ b/docs/store/change-metrics-storage.md @@ -0,0 +1,207 @@ +# Change how long Netdata stores metrics + +The Netdata Agent uses a custom made time-series database (TSDB), named the +[`dbengine`](https://github.com/netdata/netdata/blob/master/database/engine/README.md), to store metrics. + +To see the number of metrics stored and the retention in days per tier, use the `/api/v1/dbengine_stats` endpoint. + +To increase or decrease the metric retention time, you just [configure](#configure-metric-retention) +the number of storage tiers and the space allocated to each one. The effect of these two parameters +on the maximum retention and the memory used by Netdata is described in detail, below. + +## Calculate the system resources (RAM, disk space) needed to store metrics + +### Effect of storage tiers and disk space on retention + +3 tiers are enabled by default in Netdata, with the following configuration: + +``` +[db] + mode = dbengine + + # per second data collection + update every = 1 + + # number of tiers used (1 to 5, 3 being default) + storage tiers = 3 + + # Tier 0, per second data + dbengine multihost disk space MB = 256 + + # Tier 1, per minute data + dbengine tier 1 multihost disk space MB = 128 + dbengine tier 1 update every iterations = 60 + + # Tier 2, per hour data + dbengine tier 2 multihost disk space MB = 64 + dbengine tier 2 update every iterations = 60 +``` + +The default "update every iterations" of 60 means that if a metric is collected per second in Tier 0, then +we will have a data point every minute in tier 1 and every hour in tier 2. + +Up to 5 tiers are supported. You may add, or remove tiers and/or modify these multipliers, as long as the +product of all the "update every iterations" does not exceed 65535 (number of points for each tier0 point). + +e.g. If you simply add a fourth tier by setting `storage tiers = 4` and define the disk space for the new tier, +the product of the "update every iterations" will be 60 \* 60 \* 60 = 216,000, which is > 65535. So you'd need to reduce +the `update every iterations` of the tiers, to stay under the limit. + +The exact retention that can be achieved by each tier depends on the number of metrics collected. The more +the metrics, the smaller the retention that will fit in a given size. The general rule is that Netdata needs +about **1 byte per data point on disk for tier 0**, and **4 bytes per data point on disk for tier 1 and above**. + +So, for 1000 metrics collected per second and 256 MB for tier 0, Netdata will store about: + +``` +256MB on disk / 1 byte per point / 1000 metrics => 256k points per metric / 86400 sec per day ~= 3 days +``` + +At tier 1 (per minute): + +``` +128MB on disk / 4 bytes per point / 1000 metrics => 32k points per metric / (24 hr * 60 min) ~= 22 days +``` + +At tier 2 (per hour): + +``` +64MB on disk / 4 bytes per point / 1000 metrics => 16k points per metric / 24 hr per day ~= 2 years +``` + +Of course double the metrics, half the retention. There are more factors that affect retention. The number +of ephemeral metrics (i.e. metrics that are collected for part of the time). The number of metrics that are +usually constant over time (affecting compression efficiency). The number of restarts a Netdata Agents gets +through time (because it has to break pages prematurely, increasing the metadata overhead). But the actual +numbers should not deviate significantly from the above. + +To see the number of metrics stored and the retention in days per tier, use the `/api/v1/dbengine_stats` endpoint. + +### Effect of storage tiers and retention on memory usage + +The total memory Netdata uses is heavily influenced by the memory consumed by the DBENGINE. +The DBENGINE memory is related to the number of metrics concurrently being collected, the retention of the metrics +on disk in relation with the queries running, and the number of metrics for which retention is maintained. + +The precise analysis of how much memory will be used by the DBENGINE itself is described in +[DBENGINE memory requirements](https://github.com/netdata/netdata/blob/master/database/engine/README.md#memory-requirements). + +In addition to the DBENGINE, Netdata uses memory for contexts, metric labels (e.g. in a Kubernetes setup), +other Netdata structures/processes (e.g. Health) and system overhead. + +The quick rule of thumb, for a high level estimation is + +``` +DBENGINE memory in MiB = METRICS x (TIERS - 1) x 8 / 1024 MiB +Total Netdata memory in MiB = Metric ephemerality factor x DBENGINE memory in MiB + "dbengine page cache size MB" from netdata.conf +``` + +You can get the currently collected **METRICS** from the "dbengine metrics" chart of the Netdata dashboard. You just need to divide the +value of the "collected" dimension with the number of tiers. For example, at the specific point highlighted in the chart below, 608k metrics +were being collected across all 3 tiers, which means that `METRICS = 608k / 3 = 203667`. + +<img width="988" alt="image" src="https://user-images.githubusercontent.com/43294513/225335899-a9216ba7-a09e-469e-89f6-4690aada69a4.png" /> + + +The **ephemerality factor** is usually between 3 or 4 and depends on how frequently the identifiers of the collected metrics change, increasing their +cardinality. The more ephemeral the infrastructure, the more short-lived metrics you have, increasing the ephemerality factor. If the metric cardinality is +extremely high due for example to a lot of extremely short lived containers (hundreds started every minute), the ephemerality factor can be much higher than 4. +In such cases, we recommend splitting the load across multiple Netdata parents, until we can provide a way to lower the metric cardinality, +by aggregating similar metrics. + +#### Small agent RAM usage + +For 2000 metrics (dimensions) in 3 storage tiers and the default cache size: + +``` +DBENGINE memory for 2k metrics = 2000 x (3 - 1) x 8 / 1024 MiB = 32 MiB +dbengine page cache size MB = 32 MiB +Total Netdata memory in MiB = 3*32 + 32 = 128 MiB (low ephemerality) +``` + +#### Large parent RAM usage + +The Netdata parent in our production infrastructure at the time of writing: + - Collects 206k metrics per second, most from children streaming data + - The metrics include moderately ephemeral Kubernetes containers, leading to an ephemerality factor of about 4 + - 3 tiers are used for retention + - The `dbengine page cache size MB` in `netdata.conf` is configured to be 4GB + +Netdata parents can end up collecting millions of metrics per second. See also [scaling dedicated parent nodes](#scaling-dedicated-parent-nodes). + +The rule of thumb calculation for this set up gives us +``` +DBENGINE memory = 206,000 x 16 / 1024 MiB = 3,217 MiB = about 3 GiB +Extra cache = 4 GiB +Metric ephemerality factor = 4 +Estimated total Netdata memory = 3 * 4 + 4 = 16 GiB +``` + +The actual measurement during a low usage time was the following: + +Purpose|RAM|Note +:--- | ---: | :--- +DBENGINE usage | 5.9 GiB | Out of 7GB max +Cardinality/ephemerality related memory (k8s contexts, labels, strings) | 3.4 GiB +Buffer for queries | 0 GiB | Out of 0.5 GiB max, when heavily queried +Other | 0.5 GiB | +System overhead | 4.4 GiB | Calculated by subtracting all of the above from the total +**Total Netdata memory usage** | 14.2 GiB | + +All the figures above except for the system memory management overhead were retrieved from Netdata itself. +The overhead can't be directly calculated, so we subtracted all the other figures from the total Netdata memory usage to get it. +This overhead is usually around 50% of the memory actually useable by Netdata, but could range from 20% in small +setups, all the way to 100% in some edge cases. + +## Configure metric retention + +Once you have decided how to size each tier, open `netdata.conf` with +[`edit-config`](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md#use-edit-config-to-edit-configuration-files) +and make your changes in the `[db]` subsection. + +Save the file and restart the Agent with `sudo systemctl restart netdata`, or +the [appropriate method](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md) +for your system, to change the database engine's size. + +## Scaling dedicated parent nodes + +When you use streaming in medium to large infrastructures, you can have potentially millions of metrics per second reaching each parent node. +In the lab we have reliably collected 1 million metrics/sec with 16cores and 32GB RAM. + +Our suggestion for scaling parents is to have them running on dedicated VMs, using a maximum of 50% of cpu, and ensuring you have enough RAM +for the desired retention. When your infrastructure can lead a parent to exceed these characteristics, split the load to multiple parents that +do not communicate with each other. With each child sending data to only one of the parents, you can still have replication, high availability, +and infrastructure level observability via the Netdata Cloud UI. + +## Legacy configuration + +### v1.35.1 and prior + +These versions of the Agent do not support tiers. You could change the metric retention for the parent and +all of its children only with the `dbengine multihost disk space MB` setting. This setting accounts the space allocation +for the parent node and all of its children. + +To configure the database engine, look for the `page cache size MB` and `dbengine multihost disk space MB` settings in +the `[db]` section of your `netdata.conf`. + +```conf +[db] + dbengine page cache size MB = 32 + dbengine multihost disk space MB = 256 +``` + +### v1.23.2 and prior + +_For Netdata Agents earlier than v1.23.2_, the Agent on the parent node uses one dbengine instance for itself, and another instance for every child node it receives metrics from. If you had four streaming nodes, you would have five instances in total (`1 parent + 4 child nodes = 5 instances`). + +The Agent allocates resources for each instance separately using the `dbengine disk space MB` (**deprecated**) setting. If `dbengine disk space MB`(**deprecated**) is set to the default `256`, each instance is given 256 MiB in disk space, which means the total disk space required to store all instances is, roughly, `256 MiB * 1 parent * 4 child nodes = 1280 MiB`. + +#### Backward compatibility + +All existing metrics belonging to child nodes are automatically converted to legacy dbengine instances and the localhost +metrics are transferred to the multihost dbengine instance. + +All new child nodes are automatically transferred to the multihost dbengine instance and share its page cache and disk +space. If you want to migrate a child node from its legacy dbengine instance to the multihost dbengine instance, you +must delete the instance's directory, which is located in `/var/cache/netdata/MACHINE_GUID/dbengine`, after stopping the +Agent. diff --git a/docs/store/distributed-data-architecture.md b/docs/store/distributed-data-architecture.md new file mode 100644 index 00000000..b5e6f376 --- /dev/null +++ b/docs/store/distributed-data-architecture.md @@ -0,0 +1,75 @@ +# Distributed data architecture + +Learn how Netdata's distributed data architecture enables us to store metrics on the edge nodes for security, high performance and scalability. + +This way, it helps you collect and store per-second metrics from any number of nodes. +Every node in your infrastructure, whether it's one or a thousand, stores the metrics it collects. + +Netdata Cloud bridges the gap between many distributed databases by _centralizing the interface_ you use to query and +visualize your nodes' metrics. When you [look at charts in Netdata Cloud](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/interact-new-charts.md) +, the metrics values are queried directly from that node's database and securely streamed to Netdata Cloud, which +proxies them to your browser. + +Netdata's distributed data architecture has a number of benefits: + +- **Performance**: Every query to a node's database takes only a few milliseconds to complete for responsiveness when + viewing dashboards or using features + like [Metric Correlations](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/metric-correlations.md). +- **Scalability**: As your infrastructure scales, install the Netdata Agent on every new node to immediately add it to + your monitoring solution without adding cost or complexity. +- **1-second granularity**: Without an expensive centralized data lake, you can store all of your nodes' per-second + metrics, for any period of time, while keeping costs down. +- **No filtering or selecting of metrics**: Because Netdata's distributed data architecture allows you to store all + metrics, you don't have to configure which metrics you retain. Keep everything for full visibility during + troubleshooting and root cause analysis. +- **Easy maintenance**: There is no centralized data lake to purchase, allocate, monitor, and update, removing + complexity from your monitoring infrastructure. + +## Ephemerality of metrics + +The ephemerality of metrics plays an important role in retention. In environments where metrics collection is dynamic and +new metrics are constantly being generated, we are interested about 2 parameters: + +1. The **expected concurrent number of metrics** as an average for the lifetime of the database. This affects mainly the + storage requirements. + +2. The **expected total number of unique metrics** for the lifetime of the database. This affects mainly the memory + requirements for having all these metrics indexed and available to be queried. + +## Granularity of metrics + +The granularity of metrics (the frequency they are collected and stored, i.e. their resolution) is significantly +affecting retention. + +Lowering the granularity from per second to every two seconds, will double their retention and half the CPU requirements +of the Netdata Agent, without affecting disk space or memory requirements. + +## Long-term metrics storage with Netdata + +Any node running the Netdata Agent can store long-term metrics for any retention period, given you allocate the +appropriate amount of RAM and disk space. + +Read our document on changing [how long Netdata stores metrics](https://github.com/netdata/netdata/blob/master/docs/store/change-metrics-storage.md) on your nodes for +details. + +You can also stream between nodes using [streaming](https://github.com/netdata/netdata/blob/master/streaming/README.md), allowing to replicate databases and create +your own centralized data lake of metrics, if you choose to do so. + +While a distributed data architecture is the default when monitoring infrastructure with Netdata, you can also configure +its behavior based on your needs or the type of infrastructure you manage. + +To archive metrics to an external time-series database, such as InfluxDB, Graphite, OpenTSDB, Elasticsearch, +TimescaleDB, and many others, see details on [integrating Netdata via exporting](https://github.com/netdata/netdata/blob/master/docs/export/external-databases.md). + +When you use the database engine to store your metrics, you can always perform a quick backup of a node's +`/var/cache/netdata/dbengine/` folder using the tool of your choice. + +## Does Netdata Cloud store my metrics? + +Netdata Cloud does not store metric values. + +To enable certain features, such as [viewing active alerts](https://github.com/netdata/netdata/blob/master/docs/monitor/view-active-alerts.md) +or [filtering by hostname](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/node-filter.md), Netdata Cloud does +store configured alerts, their status, and a list of active collectors. + +Netdata does not and never will sell your personal data or data about your deployment. diff --git a/docs/visualize/overview-infrastructure.md b/docs/visualize/overview-infrastructure.md new file mode 100644 index 00000000..3b1f7fcc --- /dev/null +++ b/docs/visualize/overview-infrastructure.md @@ -0,0 +1,95 @@ +<!-- +title: "See an overview of your infrastructure" +description: "With Netdata Cloud's War Rooms, you can see real-time metrics, from any number of nodes in your infrastructure, in composite charts." +custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/visualize/overview-infrastructure.md +sidebar_label: "See an overview of your infrastructure" +learn_status: "Published" +learn_topic_type: "Tasks" +learn_rel_path: "Operations/Netdata Cloud Visualizations" +--> + +# See an overview of your infrastructure + +In Netdata Cloud, your nodes are organized into War Rooms. One of the two available views for a War Room is the +[**Overview**](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/overview.md), which uses composite charts to display +real-time, aggregated metrics from all the nodes (or a filtered selection) in a given War Room. + +With Overview's composite charts, you can see your infrastructure from a single pane of glass, discover trends or +anomalies, then drill down with filtering or single-node dashboards to see more. In the screenshot below, +each chart visualizes average or sum metrics values from across 5 distributed nodes. + +Netdata also supports robust Kubernetes monitoring using the Overview. Read our [deployment +doc](https://github.com/netdata/netdata/blob/master/packaging/installer/methods/kubernetes.md) for details on visualizing Kubernetes metrics in Netdata Cloud. + + + +## Using the Overview + +The Overview uses roughly the same interface as local Agent dashboards or single-node dashboards in Netdata Cloud. By +showing all available metrics from all your nodes in a single interface, Netdata Cloud helps you visualize the overall +health of your infrastructure. Best of all, you don't have to worry about creating your own dashboards just to get +started with infrastructure monitoring. + +Let's walk through some examples of using the Overview to monitor and troubleshoot your infrastructure. + +### Filter nodes and pick relevant times + +While not exclusive to Overview, you can use two important features, [node +filtering](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/node-filter.md) and the [time & date +picker](https://github.com/netdata/netdata/blob/master/docs/dashboard/visualization-date-and-time-controls.md), to widen or narrow your infrastructure +monitoring focus. + +By default, the Overview shows composite charts aggregated from every node in the War Room, but you can change that +behavior on an ad-hoc basis. The node filter allows you to create complex queries against your infrastructure based on +the name, OS, or services running on nodes. For example, use `(name contains aws AND os contains ubuntu) OR services == +apache` to show only nodes that have `aws` in the hostname and are Ubuntu-based, or any nodes that have an Apache +webserver running on them. + +The time & date picker helps you visualize both small and large timeframes depending on your goals, whether that's +establishing a baseline of infrastructure performance or targeted root cause analysis of a specific anomaly. + +For example, use the **Quick Selector** options to pick the 12-hour option first thing in the morning to check your +infrastructure for any odd behavior overnight. Use the 7-day option to observe trends between various days of the week. + +See the [War Rooms](https://github.com/netdata/netdata/blob/master/docs/cloud/manage/organize-your-infrastrucutre-invite-your-team.md#netdata-cloud-war-rooms) docs for more details on both features. + +### Configure composite charts to identify problems + +Let's say you notice a sharp decrease in available RAM for applications, as seen in the example screenshot below. In +this situation, you can see when the anomalous behavior began and that it affects the average available and committed +RAM across your infrastructure. However, when _grouped by dimension_, composite charts cannot show whether an anomaly +affects a single node, a subset of nodes, or an entire infrastructure. + + + +Use [_group by node_](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/overview.md#group-by-dimension-or-node) to visualize +a single metric across all contributing nodes. If the composite chart has 5 contributing nodes, there will be 5 +lines/areas, one for the most relevant dimension from each node. + +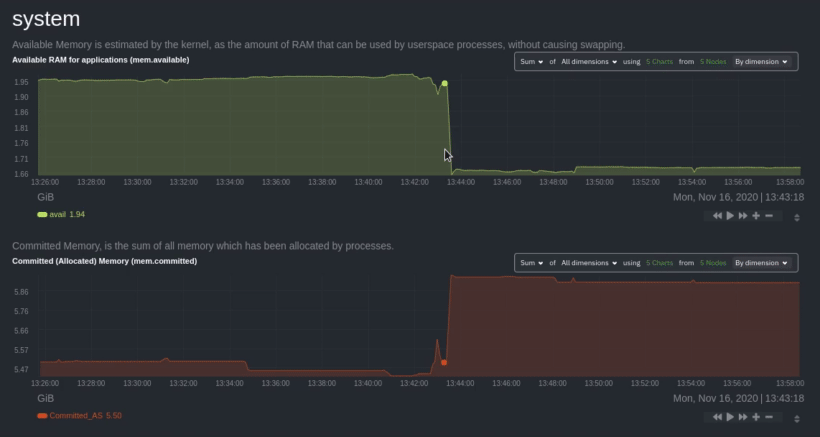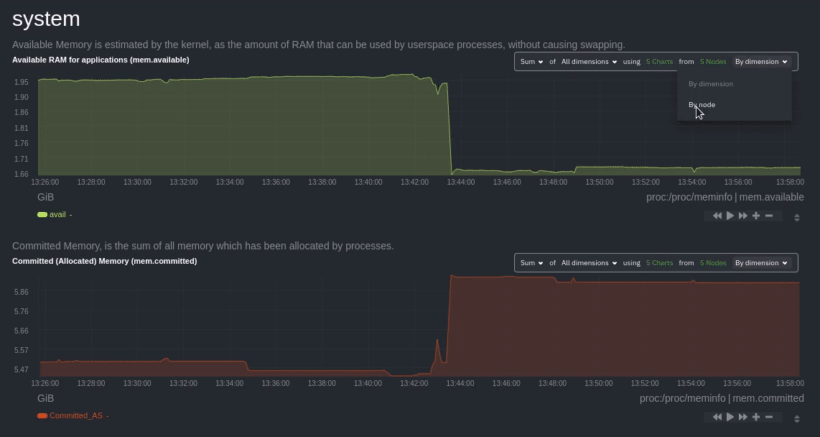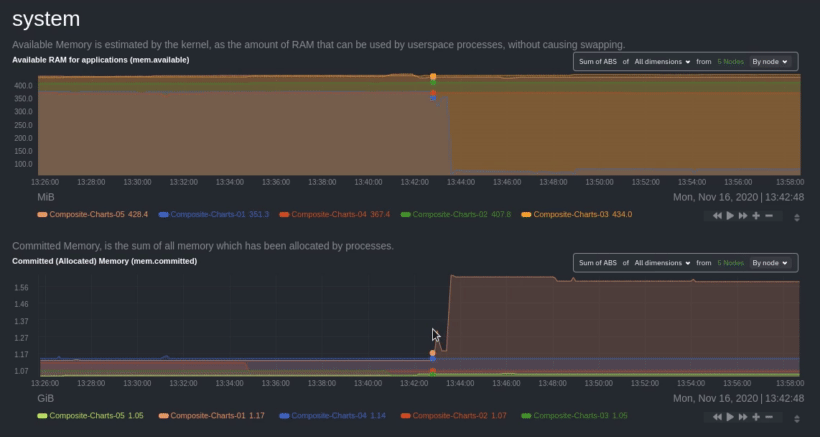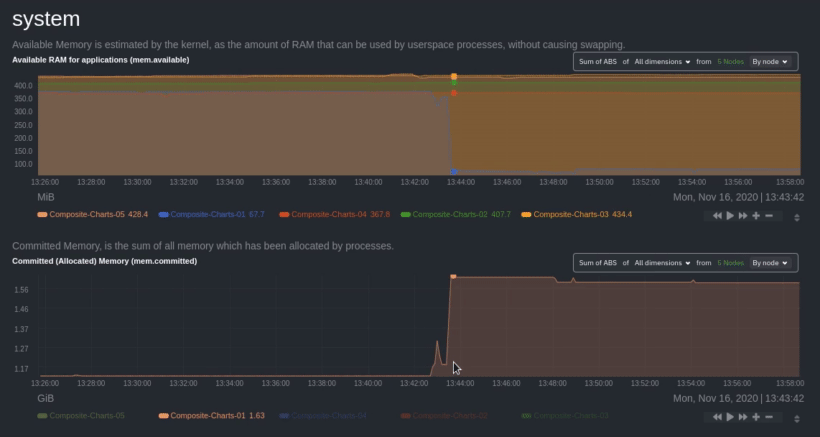 + +After grouping by node, it's clear that the `Composite-Charts-01` node is experiencing anomalous behavior and should be +investigated further by jumping to its [single-node dashboard](#drill-down-with-single-node-dashboards) in Netdata +Cloud. + +### Drill down with single-node dashboards + +Click on **X Charts** of any composite chart's definition bar to display a dropdown of contributing contexts and nodes +contributing. Click on the link icon <img class="img__inline img__inline--link" +src="https://user-images.githubusercontent.com/1153921/95762109-1d219300-0c62-11eb-8daa-9ba509a8e71c.png" /> next to a +given node to quickly _jump to the same chart in that node's single-node dashboard_ in Netdata Cloud. + +You can use single-node dashboards in Netdata Cloud to drill down on specific issues, scrub backward in time to +investigate historical data, and see like metrics presented meaningfully to help you troubleshoot performance problems. +All of the familiar [interactions](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/interact-new-charts.md) are available, as is adding any chart +to a [new dashboard](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/dashboards.md). + +## Nodes tab + +You can also use the **Nodes tab** to monitor the health status and user-configurable key metrics from multiple nodes +in a War Room. Read the [Nodes tab documentation](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/nodes.md) for details. + +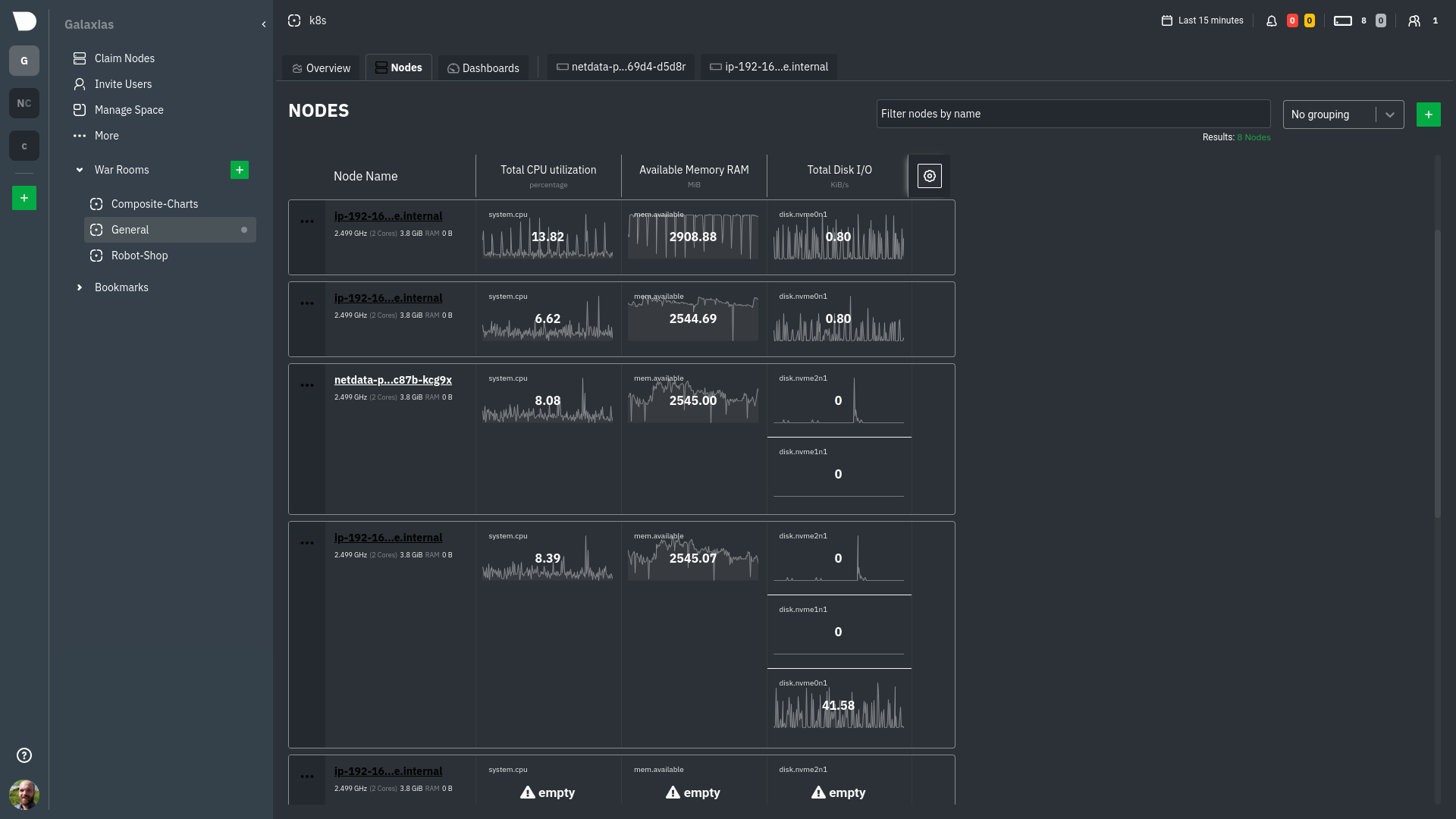 |
{kind=link}