
diff options
| author | Daniel Baumann <daniel.baumann@progress-linux.org> | 2024-04-17 12:02:58 +0000 |
|---|---|---|
| committer | Daniel Baumann <daniel.baumann@progress-linux.org> | 2024-04-17 12:02:58 +0000 |
| commit | 698f8c2f01ea549d77d7dc3338a12e04c11057b9 (patch) | |
| tree | 173a775858bd501c378080a10dca74132f05bc50 /src/tools/rust-analyzer/docs | |
| parent | Initial commit. (diff) | |
| download | rustc-698f8c2f01ea549d77d7dc3338a12e04c11057b9.tar.xz rustc-698f8c2f01ea549d77d7dc3338a12e04c11057b9.zip | |
Adding upstream version 1.64.0+dfsg1.upstream/1.64.0+dfsg1
Signed-off-by: Daniel Baumann <daniel.baumann@progress-linux.org>
Diffstat (limited to 'src/tools/rust-analyzer/docs')
| -rw-r--r-- | src/tools/rust-analyzer/docs/dev/README.md | 266 | ||||
| -rw-r--r-- | src/tools/rust-analyzer/docs/dev/architecture.md | 497 | ||||
| -rw-r--r-- | src/tools/rust-analyzer/docs/dev/debugging.md | 99 | ||||
| -rw-r--r-- | src/tools/rust-analyzer/docs/dev/guide.md | 573 | ||||
| -rw-r--r-- | src/tools/rust-analyzer/docs/dev/lsp-extensions.md | 761 | ||||
| -rw-r--r-- | src/tools/rust-analyzer/docs/dev/style.md | 1172 | ||||
| -rw-r--r-- | src/tools/rust-analyzer/docs/dev/syntax.md | 534 | ||||
| -rw-r--r-- | src/tools/rust-analyzer/docs/user/generated_config.adoc | 620 | ||||
| -rw-r--r-- | src/tools/rust-analyzer/docs/user/manual.adoc | 863 |
9 files changed, 5385 insertions, 0 deletions
diff --git a/src/tools/rust-analyzer/docs/dev/README.md b/src/tools/rust-analyzer/docs/dev/README.md new file mode 100644 index 000000000..76bbd1e91 --- /dev/null +++ b/src/tools/rust-analyzer/docs/dev/README.md @@ -0,0 +1,266 @@ +# Contributing Quick Start + +rust-analyzer is an ordinary Rust project, which is organized as a Cargo workspace, builds on stable and doesn't depend on C libraries. +So, just + +``` +$ cargo test +``` + +should be enough to get you started! + +To learn more about how rust-analyzer works, see [./architecture.md](./architecture.md). +It also explains the high-level layout of the source code. +Do skim through that document. + +We also publish rustdoc docs to pages: https://rust-lang.github.io/rust-analyzer/ide/. +Note though, that the internal documentation is very incomplete. + +Various organizational and process issues are discussed in this document. + +# Getting in Touch + +rust-analyzer is a part of the [RLS-2.0 working +group](https://github.com/rust-lang/compiler-team/tree/6a769c13656c0a6959ebc09e7b1f7c09b86fb9c0/working-groups/rls-2.0). +Discussion happens in this Zulip stream: + +https://rust-lang.zulipchat.com/#narrow/stream/185405-t-compiler.2Frust-analyzer + +# Issue Labels + +* [good-first-issue](https://github.com/rust-lang/rust-analyzer/labels/good%20first%20issue) + are good issues to get into the project. +* [E-has-instructions](https://github.com/rust-lang/rust-analyzer/issues?q=is%3Aopen+is%3Aissue+label%3AE-has-instructions) + issues have links to the code in question and tests. +* [Broken Window](https://github.com/rust-lang/rust-analyzer/issues?q=is:issue+is:open+label:%22Broken+Window%22) + are issues which are not necessarily critical by themselves, but which should be fixed ASAP regardless, to avoid accumulation of technical debt. +* [E-easy](https://github.com/rust-lang/rust-analyzer/issues?q=is%3Aopen+is%3Aissue+label%3AE-easy), + [E-medium](https://github.com/rust-lang/rust-analyzer/issues?q=is%3Aopen+is%3Aissue+label%3AE-medium), + [E-hard](https://github.com/rust-lang/rust-analyzer/issues?q=is%3Aopen+is%3Aissue+label%3AE-hard), + [E-unknown](https://github.com/rust-lang/rust-analyzer/issues?q=is%3Aopen+is%3Aissue+label%3AE-unknown), + labels are *estimates* for how hard would be to write a fix. Each triaged issue should have one of these labels. +* [S-actionable](https://github.com/rust-lang/rust-analyzer/issues?q=is%3Aopen+is%3Aissue+label%3AS-actionable) and + [S-unactionable](https://github.com/rust-lang/rust-analyzer/issues?q=is%3Aopen+is%3Aissue+label%3AS-unactionable) + specify if there are concrete steps to resolve or advance an issue. Roughly, actionable issues need only work to be fixed, + while unactionable ones are blocked either on user feedback (providing a reproducible example), or on larger architectural + work or decisions. This classification is descriptive, not prescriptive, and might be wrong: Any unactionable issue might have a simple fix that we missed. + Each triaged issue should have one of these labels. +* [fun](https://github.com/rust-lang/rust-analyzer/issues?q=is%3Aopen+is%3Aissue+label%3Afun) + is for cool, but probably hard stuff. +* [Design](https://github.com/rust-lang/rust-analyzer/issues?q=is%3Aopen+is%3Aissue+label%Design) + is for moderate/large scale architecture discussion. + Also a kind of fun. + These issues should generally include a link to a Zulip discussion thread. + +# Code Style & Review Process + +Do see [./style.md](./style.md). + +# Cookbook + +## CI + +We use GitHub Actions for CI. +Most of the things, including formatting, are checked by `cargo test`. +If `cargo test` passes locally, that's a good sign that CI will be green as well. +The only exception is that some long-running tests are skipped locally by default. +Use `env RUN_SLOW_TESTS=1 cargo test` to run the full suite. + +We use bors to enforce the [not rocket science](https://graydon2.dreamwidth.org/1597.html) rule. + +## Launching rust-analyzer + +Debugging the language server can be tricky. +LSP is rather chatty, so driving it from the command line is not really feasible, driving it via VS Code requires interacting with two processes. + +For this reason, the best way to see how rust-analyzer works is to **find a relevant test and execute it**. +VS Code & Emacs include an action for running a single test. + +Launching a VS Code instance with a locally built language server is also possible. +There's **"Run Extension (Debug Build)"** launch configuration for this in VS Code. + +In general, I use one of the following workflows for fixing bugs and implementing features: + +If the problem concerns only internal parts of rust-analyzer (i.e. I don't need to touch the `rust-analyzer` crate or TypeScript code), there is a unit-test for it. +So, I use **Rust Analyzer: Run** action in VS Code to run this single test, and then just do printf-driven development/debugging. +As a sanity check after I'm done, I use `cargo xtask install --server` and **Reload Window** action in VS Code to verify that the thing works as I expect. + +If the problem concerns only the VS Code extension, I use **Run Installed Extension** launch configuration from `launch.json`. +Notably, this uses the usual `rust-analyzer` binary from `PATH`. +For this, it is important to have the following in your `settings.json` file: +```json +{ + "rust-analyzer.server.path": "rust-analyzer" +} +``` +After I am done with the fix, I use `cargo xtask install --client` to try the new extension for real. + +If I need to fix something in the `rust-analyzer` crate, I feel sad because it's on the boundary between the two processes, and working there is slow. +I usually just `cargo xtask install --server` and poke changes from my live environment. +Note that this uses `--release`, which is usually faster overall, because loading stdlib into debug version of rust-analyzer takes a lot of time. +To speed things up, sometimes I open a temporary hello-world project which has `"rust-analyzer.cargo.noSysroot": true` in `.code/settings.json`. +This flag causes rust-analyzer to skip loading the sysroot, which greatly reduces the amount of things rust-analyzer needs to do, and makes printf's more useful. +Note that you should only use the `eprint!` family of macros for debugging: stdout is used for LSP communication, and `print!` would break it. + +If I need to fix something simultaneously in the server and in the client, I feel even more sad. +I don't have a specific workflow for this case. + +Additionally, I use `cargo run --release -p rust-analyzer -- analysis-stats path/to/some/rust/crate` to run a batch analysis. +This is primarily useful for performance optimizations, or for bug minimization. + +## TypeScript Tests + +If you change files under `editors/code` and would like to run the tests and linter, install npm and run: + +```bash +cd editors/code +npm ci +npm run lint +``` +## How to ... + +* ... add an assist? [#7535](https://github.com/rust-lang/rust-analyzer/pull/7535) +* ... add a new protocol extension? [#4569](https://github.com/rust-lang/rust-analyzer/pull/4569) +* ... add a new configuration option? [#7451](https://github.com/rust-lang/rust-analyzer/pull/7451) +* ... add a new completion? [#6964](https://github.com/rust-lang/rust-analyzer/pull/6964) +* ... allow new syntax in the parser? [#7338](https://github.com/rust-lang/rust-analyzer/pull/7338) + +## Logging + +Logging is done by both rust-analyzer and VS Code, so it might be tricky to figure out where logs go. + +Inside rust-analyzer, we use the [`tracing`](https://docs.rs/tracing/) crate for logging, +and [`tracing-subscriber`](https://docs.rs/tracing-subscriber) for logging frontend. +By default, log goes to stderr, but the stderr itself is processed by VS Code. +`--log-file <PATH>` CLI argument allows logging to file. +Setting the `RA_LOG_FILE=<PATH>` environment variable will also log to file, it will also override `--log-file`. + +To see stderr in the running VS Code instance, go to the "Output" tab of the panel and select `rust-analyzer`. +This shows `eprintln!` as well. +Note that `stdout` is used for the actual protocol, so `println!` will break things. + +To log all communication between the server and the client, there are two choices: + +* You can log on the server side, by running something like + ``` + env RA_LOG=lsp_server=debug code . + ``` +* You can log on the client side, by enabling `"rust-analyzer.trace.server": "verbose"` workspace setting. + These logs are shown in a separate tab in the output and could be used with LSP inspector. + Kudos to [@DJMcNab](https://github.com/DJMcNab) for setting this awesome infra up! + + +There are also several VS Code commands which might be of interest: + +* `Rust Analyzer: Status` shows some memory-usage statistics. + +* `Rust Analyzer: Syntax Tree` shows syntax tree of the current file/selection. + +* `Rust Analyzer: View Hir` shows the HIR expressions within the function containing the cursor. + + You can hover over syntax nodes in the opened text file to see the appropriate + rust code that it refers to and the rust editor will also highlight the proper + text range. + + If you trigger Go to Definition in the inspected Rust source file, + the syntax tree read-only editor should scroll to and select the + appropriate syntax node token. + + 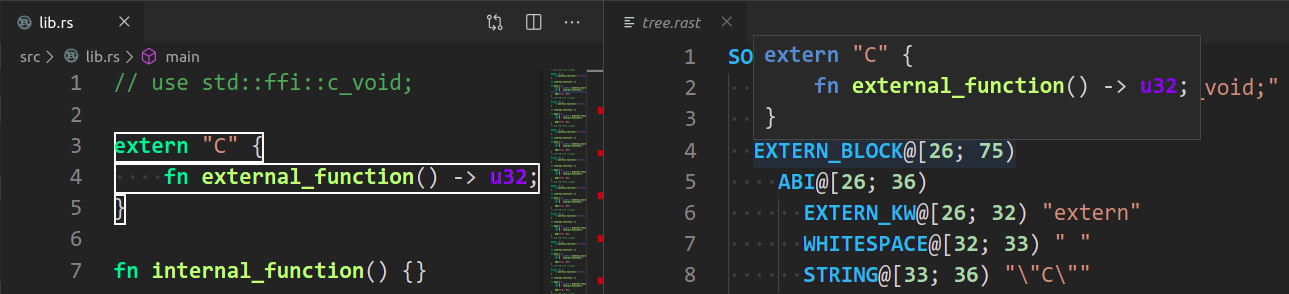 + +## Profiling + +We have a built-in hierarchical profiler, you can enable it by using `RA_PROFILE` env-var: + +``` +RA_PROFILE=* // dump everything +RA_PROFILE=foo|bar|baz // enabled only selected entries +RA_PROFILE=*@3>10 // dump everything, up to depth 3, if it takes more than 10 ms +``` + +In particular, I have `export RA_PROFILE='*>10'` in my shell profile. + +We also have a "counting" profiler which counts number of instances of popular structs. +It is enabled by `RA_COUNT=1`. + +To measure time for from-scratch analysis, use something like this: + +``` +$ cargo run --release -p rust-analyzer -- analysis-stats ../chalk/ +``` + +For measuring time of incremental analysis, use either of these: + +``` +$ cargo run --release -p rust-analyzer -- analysis-bench ../chalk/ --highlight ../chalk/chalk-engine/src/logic.rs +$ cargo run --release -p rust-analyzer -- analysis-bench ../chalk/ --complete ../chalk/chalk-engine/src/logic.rs:94:0 +``` + +Look for `fn benchmark_xxx` tests for a quick way to reproduce performance problems. + +## Release Process + +Release process is handled by `release`, `dist` and `promote` xtasks, `release` being the main one. + +`release` assumes that you have checkouts of `rust-analyzer`, `rust-analyzer.github.io`, and `rust-lang/rust` in the same directory: + +``` +./rust-analyzer +./rust-analyzer.github.io +./rust-rust-analyzer # Note the name! +``` + +The remote for `rust-analyzer` must be called `upstream` (I use `origin` to point to my fork). +In addition, for `xtask promote` (see below), `rust-rust-analyzer` must have a `rust-analyzer` remote pointing to this repository on GitHub. + +`release` calls the GitHub API calls to scrape pull request comments and categorize them in the changelog. +This step uses the `curl` and `jq` applications, which need to be available in `PATH`. +Finally, you need to obtain a GitHub personal access token and set the `GITHUB_TOKEN` environment variable. + +Release steps: + +1. Set the `GITHUB_TOKEN` environment variable. +2. Inside rust-analyzer, run `cargo xtask release`. This will: + * checkout the `release` branch + * reset it to `upstream/nightly` + * push it to `upstream`. This triggers GitHub Actions which: + * runs `cargo xtask dist` to package binaries and VS Code extension + * makes a GitHub release + * publishes the VS Code extension to the marketplace + * call the GitHub API for PR details + * create a new changelog in `rust-analyzer.github.io` +3. While the release is in progress, fill in the changelog +4. Commit & push the changelog +5. Tweet +6. Inside `rust-analyzer`, run `cargo xtask promote` -- this will create a PR to rust-lang/rust updating rust-analyzer's subtree. + Self-approve the PR. + +If the GitHub Actions release fails because of a transient problem like a timeout, you can re-run the job from the Actions console. +If it fails because of something that needs to be fixed, remove the release tag (if needed), fix the problem, then start over. +Make sure to remove the new changelog post created when running `cargo xtask release` a second time. + +We release "nightly" every night automatically and promote the latest nightly to "stable" manually, every week. + +We don't do "patch" releases, unless something truly egregious comes up. +To do a patch release, cherry-pick the fix on top of the current `release` branch and push the branch. +There's no need to write a changelog for a patch release, it's OK to include the notes about the fix into the next weekly one. +Note: we tag releases by dates, releasing a patch release on the same day should work (by overwriting a tag), but I am not 100% sure. + +## Permissions + +There are three sets of people with extra permissions: + +* rust-analyzer GitHub organization [**admins**](https://github.com/orgs/rust-analyzer/people?query=role:owner) (which include current t-compiler leads). + Admins have full access to the org. +* [**review**](https://github.com/orgs/rust-analyzer/teams/review) team in the organization. + Reviewers have `r+` access to all of organization's repositories and publish rights on crates.io. + They also have direct commit access, but all changes should via bors queue. + It's ok to self-approve if you think you know what you are doing! + bors should automatically sync the permissions. + Feel free to request a review or assign any PR to a reviewer with the relevant expertise to bring the work to their attention. + Don't feel pressured to review assigned PRs though. + If you don't feel like reviewing for whatever reason, someone else will pick the review up! +* [**triage**](https://github.com/orgs/rust-analyzer/teams/triage) team in the organization. + This team can label and close issues. + +Note that at the time being you need to be a member of the org yourself to view the links. diff --git a/src/tools/rust-analyzer/docs/dev/architecture.md b/src/tools/rust-analyzer/docs/dev/architecture.md new file mode 100644 index 000000000..ea4035baf --- /dev/null +++ b/src/tools/rust-analyzer/docs/dev/architecture.md @@ -0,0 +1,497 @@ +# Architecture + +This document describes the high-level architecture of rust-analyzer. +If you want to familiarize yourself with the code base, you are just in the right place! + +You might also enjoy ["Explaining Rust Analyzer"](https://www.youtube.com/playlist?list=PLhb66M_x9UmrqXhQuIpWC5VgTdrGxMx3y) series on YouTube. +It goes deeper than what is covered in this document, but will take some time to watch. + +See also these implementation-related blog posts: + +* https://rust-analyzer.github.io/blog/2019/11/13/find-usages.html +* https://rust-analyzer.github.io/blog/2020/07/20/three-architectures-for-responsive-ide.html +* https://rust-analyzer.github.io/blog/2020/09/16/challeging-LR-parsing.html +* https://rust-analyzer.github.io/blog/2020/09/28/how-to-make-a-light-bulb.html +* https://rust-analyzer.github.io/blog/2020/10/24/introducing-ungrammar.html + +For older, by now mostly outdated stuff, see the [guide](./guide.md) and [another playlist](https://www.youtube.com/playlist?list=PL85XCvVPmGQho7MZkdW-wtPtuJcFpzycE). + + +## Bird's Eye View + +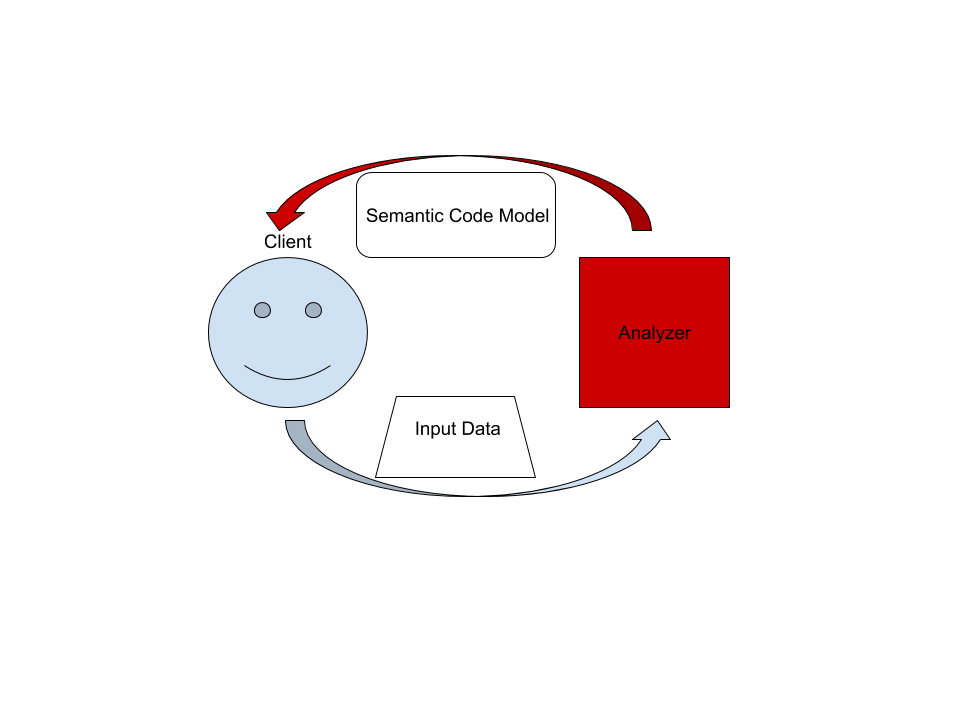 + +On the highest level, rust-analyzer is a thing which accepts input source code from the client and produces a structured semantic model of the code. + +More specifically, input data consists of a set of test files (`(PathBuf, String)` pairs) and information about project structure, captured in the so called `CrateGraph`. +The crate graph specifies which files are crate roots, which cfg flags are specified for each crate and what dependencies exist between the crates. +This is the input (ground) state. +The analyzer keeps all this input data in memory and never does any IO. +Because the input data is source code, which typically measures in tens of megabytes at most, keeping everything in memory is OK. + +A "structured semantic model" is basically an object-oriented representation of modules, functions and types which appear in the source code. +This representation is fully "resolved": all expressions have types, all references are bound to declarations, etc. +This is derived state. + +The client can submit a small delta of input data (typically, a change to a single file) and get a fresh code model which accounts for changes. + +The underlying engine makes sure that model is computed lazily (on-demand) and can be quickly updated for small modifications. + +## Entry Points + +`crates/rust-analyzer/src/bin/main.rs` contains the main function which spawns LSP. +This is *the* entry point, but it front-loads a lot of complexity, so it's fine to just skim through it. + +`crates/rust-analyzer/src/handlers.rs` implements all LSP requests and is a great place to start if you are already familiar with LSP. + +`Analysis` and `AnalysisHost` types define the main API for consumers of IDE services. + +## Code Map + +This section talks briefly about various important directories and data structures. +Pay attention to the **Architecture Invariant** sections. +They often talk about things which are deliberately absent in the source code. + +Note also which crates are **API Boundaries**. +Remember, [rules at the boundary are different](https://www.tedinski.com/2018/02/06/system-boundaries.html). + +### `xtask` + +This is rust-analyzer's "build system". +We use cargo to compile rust code, but there are also various other tasks, like release management or local installation. +They are handled by Rust code in the xtask directory. + +### `editors/code` + +VS Code plugin. + +### `lib/` + +rust-analyzer independent libraries which we publish to crates.io. +It's not heavily utilized at the moment. + +### `crates/parser` + +It is a hand-written recursive descent parser, which produces a sequence of events like "start node X", "finish node Y". +It works similarly to +[kotlin's parser](https://github.com/JetBrains/kotlin/blob/4d951de616b20feca92f3e9cc9679b2de9e65195/compiler/frontend/src/org/jetbrains/kotlin/parsing/KotlinParsing.java), +which is a good source of inspiration for dealing with syntax errors and incomplete input. +Original [libsyntax parser](https://github.com/rust-lang/rust/blob/6b99adeb11313197f409b4f7c4083c2ceca8a4fe/src/libsyntax/parse/parser.rs) is what we use for the definition of the Rust language. +`TreeSink` and `TokenSource` traits bridge the tree-agnostic parser from `grammar` with `rowan` trees. + +**Architecture Invariant:** the parser is independent of the particular tree structure and particular representation of the tokens. +It transforms one flat stream of events into another flat stream of events. +Token independence allows us to parse out both text-based source code and `tt`-based macro input. +Tree independence allows us to more easily vary the syntax tree implementation. +It should also unlock efficient light-parsing approaches. +For example, you can extract the set of names defined in a file (for typo correction) without building a syntax tree. + +**Architecture Invariant:** parsing never fails, the parser produces `(T, Vec<Error>)` rather than `Result<T, Error>`. + +### `crates/syntax` + +Rust syntax tree structure and parser. +See [RFC](https://github.com/rust-lang/rfcs/pull/2256) and [./syntax.md](./syntax.md) for some design notes. + +- [rowan](https://github.com/rust-analyzer/rowan) library is used for constructing syntax trees. +- `ast` provides a type safe API on top of the raw `rowan` tree. +- `ungrammar` description of the grammar, which is used to generate `syntax_kinds` and `ast` modules, using `cargo test -p xtask` command. + +Tests for ra_syntax are mostly data-driven. +`test_data/parser` contains subdirectories with a bunch of `.rs` (test vectors) and `.txt` files with corresponding syntax trees. +During testing, we check `.rs` against `.txt`. +If the `.txt` file is missing, it is created (this is how you update tests). +Additionally, running the xtask test suite with `cargo test -p xtask` will walk the grammar module and collect all `// test test_name` comments into files inside `test_data/parser/inline` directory. + +To update test data, run with `UPDATE_EXPECT` variable: + +```bash +env UPDATE_EXPECT=1 cargo qt +``` + +After adding a new inline test you need to run `cargo test -p xtask` and also update the test data as described above. + +Note [`api_walkthrough`](https://github.com/rust-lang/rust-analyzer/blob/2fb6af89eb794f775de60b82afe56b6f986c2a40/crates/ra_syntax/src/lib.rs#L190-L348) +in particular: it shows off various methods of working with syntax tree. + +See [#93](https://github.com/rust-lang/rust-analyzer/pull/93) for an example PR which fixes a bug in the grammar. + +**Architecture Invariant:** `syntax` crate is completely independent from the rest of rust-analyzer. It knows nothing about salsa or LSP. +This is important because it is possible to make useful tooling using only the syntax tree. +Without semantic information, you don't need to be able to _build_ code, which makes the tooling more robust. +See also https://web.stanford.edu/~mlfbrown/paper.pdf. +You can view the `syntax` crate as an entry point to rust-analyzer. +`syntax` crate is an **API Boundary**. + +**Architecture Invariant:** syntax tree is a value type. +The tree is fully determined by the contents of its syntax nodes, it doesn't need global context (like an interner) and doesn't store semantic info. +Using the tree as a store for semantic info is convenient in traditional compilers, but doesn't work nicely in the IDE. +Specifically, assists and refactors require transforming syntax trees, and that becomes awkward if you need to do something with the semantic info. + +**Architecture Invariant:** syntax tree is built for a single file. +This is to enable parallel parsing of all files. + +**Architecture Invariant:** Syntax trees are by design incomplete and do not enforce well-formedness. +If an AST method returns an `Option`, it *can* be `None` at runtime, even if this is forbidden by the grammar. + +### `crates/base_db` + +We use the [salsa](https://github.com/salsa-rs/salsa) crate for incremental and on-demand computation. +Roughly, you can think of salsa as a key-value store, but it can also compute derived values using specified functions. +The `base_db` crate provides basic infrastructure for interacting with salsa. +Crucially, it defines most of the "input" queries: facts supplied by the client of the analyzer. +Reading the docs of the `base_db::input` module should be useful: everything else is strictly derived from those inputs. + +**Architecture Invariant:** particularities of the build system are *not* the part of the ground state. +In particular, `base_db` knows nothing about cargo. +For example, `cfg` flags are a part of `base_db`, but `feature`s are not. +A `foo` feature is a Cargo-level concept, which is lowered by Cargo to `--cfg feature=foo` argument on the command line. +The `CrateGraph` structure is used to represent the dependencies between the crates abstractly. + +**Architecture Invariant:** `base_db` doesn't know about file system and file paths. +Files are represented with opaque `FileId`, there's no operation to get an `std::path::Path` out of the `FileId`. + +### `crates/hir_expand`, `crates/hir_def`, `crates/hir_ty` + +These crates are the *brain* of rust-analyzer. +This is the compiler part of the IDE. + +`hir_xxx` crates have a strong [ECS](https://en.wikipedia.org/wiki/Entity_component_system) flavor, in that they work with raw ids and directly query the database. +There's little abstraction here. +These crates integrate deeply with salsa and chalk. + +Name resolution, macro expansion and type inference all happen here. +These crates also define various intermediate representations of the core. + +`ItemTree` condenses a single `SyntaxTree` into a "summary" data structure, which is stable over modifications to function bodies. + +`DefMap` contains the module tree of a crate and stores module scopes. + +`Body` stores information about expressions. + +**Architecture Invariant:** these crates are not, and will never be, an api boundary. + +**Architecture Invariant:** these crates explicitly care about being incremental. +The core invariant we maintain is "typing inside a function's body never invalidates global derived data". +i.e., if you change the body of `foo`, all facts about `bar` should remain intact. + +**Architecture Invariant:** hir exists only in context of particular crate instance with specific CFG flags. +The same syntax may produce several instances of HIR if the crate participates in the crate graph more than once. + +### `crates/hir` + +The top-level `hir` crate is an **API Boundary**. +If you think about "using rust-analyzer as a library", `hir` crate is most likely the façade you'll be talking to. + +It wraps ECS-style internal API into a more OO-flavored API (with an extra `db` argument for each call). + +**Architecture Invariant:** `hir` provides a static, fully resolved view of the code. +While internal `hir_*` crates _compute_ things, `hir`, from the outside, looks like an inert data structure. + +`hir` also handles the delicate task of going from syntax to the corresponding `hir`. +Remember that the mapping here is one-to-many. +See `Semantics` type and `source_to_def` module. + +Note in particular a curious recursive structure in `source_to_def`. +We first resolve the parent _syntax_ node to the parent _hir_ element. +Then we ask the _hir_ parent what _syntax_ children does it have. +Then we look for our node in the set of children. + +This is the heart of many IDE features, like goto definition, which start with figuring out the hir node at the cursor. +This is some kind of (yet unnamed) uber-IDE pattern, as it is present in Roslyn and Kotlin as well. + +### `crates/ide` + +The `ide` crate builds on top of `hir` semantic model to provide high-level IDE features like completion or goto definition. +It is an **API Boundary**. +If you want to use IDE parts of rust-analyzer via LSP, custom flatbuffers-based protocol or just as a library in your text editor, this is the right API. + +**Architecture Invariant:** `ide` crate's API is build out of POD types with public fields. +The API uses editor's terminology, it talks about offsets and string labels rather than in terms of definitions or types. +It is effectively the view in MVC and viewmodel in [MVVM](https://en.wikipedia.org/wiki/Model%E2%80%93view%E2%80%93viewmodel). +All arguments and return types are conceptually serializable. +In particular, syntax trees and hir types are generally absent from the API (but are used heavily in the implementation). +Shout outs to LSP developers for popularizing the idea that "UI" is a good place to draw a boundary at. + +`ide` is also the first crate which has the notion of change over time. +`AnalysisHost` is a state to which you can transactionally `apply_change`. +`Analysis` is an immutable snapshot of the state. + +Internally, `ide` is split across several crates. `ide_assists`, `ide_completion` and `ide_ssr` implement large isolated features. +`ide_db` implements common IDE functionality (notably, reference search is implemented here). +The `ide` contains a public API/façade, as well as implementation for a plethora of smaller features. + +**Architecture Invariant:** `ide` crate strives to provide a _perfect_ API. +Although at the moment it has only one consumer, the LSP server, LSP *does not* influence its API design. +Instead, we keep in mind a hypothetical _ideal_ client -- an IDE tailored specifically for rust, every nook and cranny of which is packed with Rust-specific goodies. + +### `crates/rust-analyzer` + +This crate defines the `rust-analyzer` binary, so it is the **entry point**. +It implements the language server. + +**Architecture Invariant:** `rust-analyzer` is the only crate that knows about LSP and JSON serialization. +If you want to expose a data structure `X` from ide to LSP, don't make it serializable. +Instead, create a serializable counterpart in `rust-analyzer` crate and manually convert between the two. + +`GlobalState` is the state of the server. +The `main_loop` defines the server event loop which accepts requests and sends responses. +Requests that modify the state or might block user's typing are handled on the main thread. +All other requests are processed in background. + +**Architecture Invariant:** the server is stateless, a-la HTTP. +Sometimes state needs to be preserved between requests. +For example, "what is the `edit` for the fifth completion item of the last completion edit?". +For this, the second request should include enough info to re-create the context from scratch. +This generally means including all the parameters of the original request. + +`reload` module contains the code that handles configuration and Cargo.toml changes. +This is a tricky business. + +**Architecture Invariant:** `rust-analyzer` should be partially available even when the build is broken. +Reloading process should not prevent IDE features from working. + +### `crates/toolchain`, `crates/project_model`, `crates/flycheck` + +These crates deal with invoking `cargo` to learn about project structure and get compiler errors for the "check on save" feature. + +They use `crates/path` heavily instead of `std::path`. +A single `rust-analyzer` process can serve many projects, so it is important that server's current directory does not leak. + +### `crates/mbe`, `crates/tt`, `crates/proc_macro_api`, `crates/proc_macro_srv` + +These crates implement macros as token tree -> token tree transforms. +They are independent from the rest of the code. + +`tt` crate defined `TokenTree`, a single token or a delimited sequence of token trees. +`mbe` crate contains tools for transforming between syntax trees and token tree. +And it also handles the actual parsing and expansion of declarative macro (a-la "Macros By Example" or mbe). + +For proc macros, the client-server model are used. +We pass an argument `--proc-macro` to `rust-analyzer` binary to start a separate process (`proc_macro_srv`). +And the client (`proc_macro_api`) provides an interface to talk to that server separately. + +And then token trees are passed from client, and the server will load the corresponding dynamic library (which built by `cargo`). +And due to the fact the api for getting result from proc macro are always unstable in `rustc`, +we maintain our own copy (and paste) of that part of code to allow us to build the whole thing in stable rust. + + **Architecture Invariant:** +Bad proc macros may panic or segfault accidentally. So we run it in another process and recover it from fatal error. +And they may be non-deterministic which conflict how `salsa` works, so special attention is required. + +### `crates/cfg` + +This crate is responsible for parsing, evaluation and general definition of `cfg` attributes. + +### `crates/vfs`, `crates/vfs-notify` + +These crates implement a virtual file system. +They provide consistent snapshots of the underlying file system and insulate messy OS paths. + +**Architecture Invariant:** vfs doesn't assume a single unified file system. +i.e., a single rust-analyzer process can act as a remote server for two different machines, where the same `/tmp/foo.rs` path points to different files. +For this reason, all path APIs generally take some existing path as a "file system witness". + +### `crates/stdx` + +This crate contains various non-rust-analyzer specific utils, which could have been in std, as well +as copies of unstable std items we would like to make use of already, like `std::str::split_once`. + +### `crates/profile` + +This crate contains utilities for CPU and memory profiling. + + +## Cross-Cutting Concerns + +This sections talks about the things which are everywhere and nowhere in particular. + +### Stability Guarantees + +One of the reasons rust-analyzer moves relatively fast is that we don't introduce new stability guarantees. +Instead, as much as possible we leverage existing ones. + +Examples: + +* The `ide` API of rust-analyzer are explicitly unstable, but the LSP interface is stable, and here we just implement a stable API managed by someone else. +* Rust language and Cargo are stable, and they are the primary inputs to rust-analyzer. +* The `rowan` library is published to crates.io, but it is deliberately kept under `1.0` and always makes semver-incompatible upgrades + +Another important example is that rust-analyzer isn't run on CI, so, unlike `rustc` and `clippy`, it is actually ok for us to change runtime behavior. + +At some point we might consider opening up APIs or allowing crates.io libraries to include rust-analyzer specific annotations, but that's going to be a big commitment on our side. + +Exceptions: + +* `rust-project.json` is a de-facto stable format for non-cargo build systems. + It is probably ok enough, but was definitely stabilized implicitly. + Lesson for the future: when designing API which could become a stability boundary, don't wait for the first users until you stabilize it. + By the time you have first users, it is already de-facto stable. + And the users will first use the thing, and *then* inform you that now you have users. + The sad thing is that stuff should be stable before someone uses it for the first time, or it should contain explicit opt-in. +* We ship some LSP extensions, and we try to keep those somewhat stable. + Here, we need to work with a finite set of editor maintainers, so not providing rock-solid guarantees works. + +### Code generation + +Some components in this repository are generated through automatic processes. +Generated code is updated automatically on `cargo test`. +Generated code is generally committed to the git repository. + +In particular, we generate: + +* API for working with syntax trees (`syntax::ast`, the [`ungrammar`](https://github.com/rust-analyzer/ungrammar) crate). +* Various sections of the manual: + + * features + * assists + * config + +* Documentation tests for assists + +See the `sourcegen` crate for details. + +**Architecture Invariant:** we avoid bootstrapping. +For codegen we need to parse Rust code. +Using rust-analyzer for that would work and would be fun, but it would also complicate the build process a lot. +For that reason, we use syn and manual string parsing. + +### Cancellation + +Let's say that the IDE is in the process of computing syntax highlighting, when the user types `foo`. +What should happen? +`rust-analyzer`s answer is that the highlighting process should be cancelled -- its results are now stale, and it also blocks modification of the inputs. + +The salsa database maintains a global revision counter. +When applying a change, salsa bumps this counter and waits until all other threads using salsa finish. +If a thread does salsa-based computation and notices that the counter is incremented, it panics with a special value (see `Canceled::throw`). +That is, rust-analyzer requires unwinding. + +`ide` is the boundary where the panic is caught and transformed into a `Result<T, Cancelled>`. + +### Testing + +Rust Analyzer has three interesting [system boundaries](https://www.tedinski.com/2018/04/10/making-tests-a-positive-influence-on-design.html) to concentrate tests on. + +The outermost boundary is the `rust-analyzer` crate, which defines an LSP interface in terms of stdio. +We do integration testing of this component, by feeding it with a stream of LSP requests and checking responses. +These tests are known as "heavy", because they interact with Cargo and read real files from disk. +For this reason, we try to avoid writing too many tests on this boundary: in a statically typed language, it's hard to make an error in the protocol itself if messages are themselves typed. +Heavy tests are only run when `RUN_SLOW_TESTS` env var is set. + +The middle, and most important, boundary is `ide`. +Unlike `rust-analyzer`, which exposes API, `ide` uses Rust API and is intended for use by various tools. +A typical test creates an `AnalysisHost`, calls some `Analysis` functions and compares the results against expectation. + +The innermost and most elaborate boundary is `hir`. +It has a much richer vocabulary of types than `ide`, but the basic testing setup is the same: we create a database, run some queries, assert result. + +For comparisons, we use the `expect` crate for snapshot testing. + +To test various analysis corner cases and avoid forgetting about old tests, we use so-called marks. +See the `marks` module in the `test_utils` crate for more. + +**Architecture Invariant:** rust-analyzer tests do not use libcore or libstd. +All required library code must be a part of the tests. +This ensures fast test execution. + +**Architecture Invariant:** tests are data driven and do not test the API. +Tests which directly call various API functions are a liability, because they make refactoring the API significantly more complicated. +So most of the tests look like this: + +```rust +#[track_caller] +fn check(input: &str, expect: expect_test::Expect) { + // The single place that actually exercises a particular API +} + +#[test] +fn foo() { + check("foo", expect![["bar"]]); +} + +#[test] +fn spam() { + check("spam", expect![["eggs"]]); +} +// ...and a hundred more tests that don't care about the specific API at all. +``` + +To specify input data, we use a single string literal in a special format, which can describe a set of rust files. +See the `Fixture` its module for fixture examples and documentation. + +**Architecture Invariant:** all code invariants are tested by `#[test]` tests. +There's no additional checks in CI, formatting and tidy tests are run with `cargo test`. + +**Architecture Invariant:** tests do not depend on any kind of external resources, they are perfectly reproducible. + + +### Performance Testing + +TBA, take a look at the `metrics` xtask and `#[test] fn benchmark_xxx()` functions. + +### Error Handling + +**Architecture Invariant:** core parts of rust-analyzer (`ide`/`hir`) don't interact with the outside world and thus can't fail. +Only parts touching LSP are allowed to do IO. + +Internals of rust-analyzer need to deal with broken code, but this is not an error condition. +rust-analyzer is robust: various analysis compute `(T, Vec<Error>)` rather than `Result<T, Error>`. + +rust-analyzer is a complex long-running process. +It will always have bugs and panics. +But a panic in an isolated feature should not bring down the whole process. +Each LSP-request is protected by a `catch_unwind`. +We use `always` and `never` macros instead of `assert` to gracefully recover from impossible conditions. + +### Observability + +rust-analyzer is a long-running process, so it is important to understand what's going on inside. +We have several instruments for that. + +The event loop that runs rust-analyzer is very explicit. +Rather than spawning futures or scheduling callbacks (open), the event loop accepts an `enum` of possible events (closed). +It's easy to see all the things that trigger rust-analyzer processing, together with their performance + +rust-analyzer includes a simple hierarchical profiler (`hprof`). +It is enabled with `RA_PROFILE='*>50'` env var (log all (`*`) actions which take more than `50` ms) and produces output like: + +``` +85ms - handle_completion + 68ms - import_on_the_fly + 67ms - import_assets::search_for_relative_paths + 0ms - crate_def_map:wait (804 calls) + 0ms - find_path (16 calls) + 2ms - find_similar_imports (1 calls) + 0ms - generic_params_query (334 calls) + 59ms - trait_solve_query (186 calls) + 0ms - Semantics::analyze_impl (1 calls) + 1ms - render_resolution (8 calls) + 0ms - Semantics::analyze_impl (5 calls) +``` + +This is cheap enough to enable in production. + + +Similarly, we save live object counting (`RA_COUNT=1`). +It is not cheap enough to enable in prod, and this is a bug which should be fixed. + +### Configurability + +rust-analyzer strives to be as configurable as possible while offering reasonable defaults where no configuration exists yet. +There will always be features that some people find more annoying than helpful, so giving the users the ability to tweak or disable these is a big part of offering a good user experience. +Mind the code--architecture gap: at the moment, we are using fewer feature flags than we really should. + +### Serialization + +In Rust, it is easy (often too easy) to add serialization to any type by adding `#[derive(Serialize)]`. +This easiness is misleading -- serializable types impose significant backwards compatability constraints. +If a type is serializable, then it is a part of some IPC boundary. +You often don't control the other side of this boundary, so changing serializable types is hard. + +For this reason, the types in `ide`, `base_db` and below are not serializable by design. +If such types need to cross an IPC boundary, then the client of rust-analyzer needs to provide custom, client-specific serialization format. +This isolates backwards compatibility and migration concerns to a specific client. + +For example, `rust-project.json` is it's own format -- it doesn't include `CrateGraph` as is. +Instead, it creates a `CrateGraph` by calling appropriate constructing functions. diff --git a/src/tools/rust-analyzer/docs/dev/debugging.md b/src/tools/rust-analyzer/docs/dev/debugging.md new file mode 100644 index 000000000..48caec1d8 --- /dev/null +++ b/src/tools/rust-analyzer/docs/dev/debugging.md @@ -0,0 +1,99 @@ +# Debugging VSCode plugin and the language server + +## Prerequisites + +- Install [LLDB](https://lldb.llvm.org/) and the [LLDB Extension](https://marketplace.visualstudio.com/items?itemName=vadimcn.vscode-lldb). +- Open the root folder in VSCode. Here you can access the preconfigured debug setups. + + <img height=150px src="https://user-images.githubusercontent.com/36276403/74611090-92ec5380-5101-11ea-8a41-598f51f3f3e3.png" alt="Debug options view"> + +- Install all TypeScript dependencies + ```bash + cd editors/code + npm ci + ``` + +## Common knowledge + +* All debug configurations open a new `[Extension Development Host]` VSCode instance +where **only** the `rust-analyzer` extension being debugged is enabled. +* To activate the extension you need to open any Rust project folder in `[Extension Development Host]`. + + +## Debug TypeScript VSCode extension + +- `Run Installed Extension` - runs the extension with the globally installed `rust-analyzer` binary. +- `Run Extension (Debug Build)` - runs extension with the locally built LSP server (`target/debug/rust-analyzer`). + +TypeScript debugging is configured to watch your source edits and recompile. +To apply changes to an already running debug process, press <kbd>Ctrl+Shift+P</kbd> and run the following command in your `[Extension Development Host]` + +``` +> Developer: Reload Window +``` + +## Debug Rust LSP server + +- When attaching a debugger to an already running `rust-analyzer` server on Linux you might need to enable `ptrace` for unrelated processes by running: + + ``` + echo 0 | sudo tee /proc/sys/kernel/yama/ptrace_scope + ``` + + +- By default, the LSP server is built without debug information. To enable it, you'll need to change `Cargo.toml`: + ```toml + [profile.dev] + debug = 2 + ``` + +- Select `Run Extension (Debug Build)` to run your locally built `target/debug/rust-analyzer`. + +- In the original VSCode window once again select the `Attach To Server` debug configuration. + +- A list of running processes should appear. Select the `rust-analyzer` from this repo. + +- Navigate to `crates/rust-analyzer/src/main_loop.rs` and add a breakpoint to the `on_request` function. + +- Go back to the `[Extension Development Host]` instance and hover over a Rust variable and your breakpoint should hit. + +If you need to debug the server from the very beginning, including its initialization code, you can use the `--wait-dbg` command line argument or `RA_WAIT_DBG` environment variable. The server will spin at the beginning of the `try_main` function (see `crates\rust-analyzer\src\bin\main.rs`) +```rust + let mut d = 4; + while d == 4 { // set a breakpoint here and change the value + d = 4; + } +``` + +However for this to work, you will need to enable debug_assertions in your build +```rust +RUSTFLAGS='--cfg debug_assertions' cargo build --release +``` + +## Demo + +- [Debugging TypeScript VScode extension](https://www.youtube.com/watch?v=T-hvpK6s4wM). +- [Debugging Rust LSP server](https://www.youtube.com/watch?v=EaNb5rg4E0M). + +## Troubleshooting + +### Can't find the `rust-analyzer` process + +It could be a case of just jumping the gun. + +The `rust-analyzer` is only started once the `onLanguage:rust` activation. + +Make sure you open a rust file in the `[Extension Development Host]` and try again. + +### Can't connect to `rust-analyzer` + +Make sure you have run `echo 0 | sudo tee /proc/sys/kernel/yama/ptrace_scope`. + +By default this should reset back to 1 every time you log in. + +### Breakpoints are never being hit + +Check your version of `lldb`. If it's version 6 and lower, use the `classic` adapter type. +It's `lldb.adapterType` in settings file. + +If you're running `lldb` version 7, change the lldb adapter type to `bundled` or `native`. diff --git a/src/tools/rust-analyzer/docs/dev/guide.md b/src/tools/rust-analyzer/docs/dev/guide.md new file mode 100644 index 000000000..47ae3f3e6 --- /dev/null +++ b/src/tools/rust-analyzer/docs/dev/guide.md @@ -0,0 +1,573 @@ +# Guide to rust-analyzer + +## About the guide + +This guide describes the current state of rust-analyzer as of 2019-01-20 (git +tag [guide-2019-01]). Its purpose is to document various problems and +architectural solutions related to the problem of building IDE-first compiler +for Rust. There is a video version of this guide as well: +https://youtu.be/ANKBNiSWyfc. + +[guide-2019-01]: https://github.com/rust-lang/rust-analyzer/tree/guide-2019-01 + +## The big picture + +On the highest possible level, rust-analyzer is a stateful component. A client may +apply changes to the analyzer (new contents of `foo.rs` file is "fn main() {}") +and it may ask semantic questions about the current state (what is the +definition of the identifier with offset 92 in file `bar.rs`?). Two important +properties hold: + +* Analyzer does not do any I/O. It starts in an empty state and all input data is + provided via `apply_change` API. + +* Only queries about the current state are supported. One can, of course, + simulate undo and redo by keeping a log of changes and inverse changes respectively. + +## IDE API + +To see the bigger picture of how the IDE features work, let's take a look at the [`AnalysisHost`] and +[`Analysis`] pair of types. `AnalysisHost` has three methods: + +* `default()` for creating an empty analysis instance +* `apply_change(&mut self)` to make changes (this is how you get from an empty + state to something interesting) +* `analysis(&self)` to get an instance of `Analysis` + +`Analysis` has a ton of methods for IDEs, like `goto_definition`, or +`completions`. Both inputs and outputs of `Analysis`' methods are formulated in +terms of files and offsets, and **not** in terms of Rust concepts like structs, +traits, etc. The "typed" API with Rust specific types is slightly lower in the +stack, we'll talk about it later. + +[`AnalysisHost`]: https://github.com/rust-lang/rust-analyzer/blob/guide-2019-01/crates/ide_api/src/lib.rs#L265-L284 +[`Analysis`]: https://github.com/rust-lang/rust-analyzer/blob/guide-2019-01/crates/ide_api/src/lib.rs#L291-L478 + +The reason for this separation of `Analysis` and `AnalysisHost` is that we want to apply +changes "uniquely", but we might also want to fork an `Analysis` and send it to +another thread for background processing. That is, there is only a single +`AnalysisHost`, but there may be several (equivalent) `Analysis`. + +Note that all of the `Analysis` API return `Cancellable<T>`. This is required to +be responsive in an IDE setting. Sometimes a long-running query is being computed +and the user types something in the editor and asks for completion. In this +case, we cancel the long-running computation (so it returns `Err(Cancelled)`), +apply the change and execute request for completion. We never use stale data to +answer requests. Under the cover, `AnalysisHost` "remembers" all outstanding +`Analysis` instances. The `AnalysisHost::apply_change` method cancels all +`Analysis`es, blocks until all of them are `Dropped` and then applies changes +in-place. This may be familiar to Rustaceans who use read-write locks for interior +mutability. + +Next, let's talk about what the inputs to the `Analysis` are, precisely. + +## Inputs + +Rust Analyzer never does any I/O itself, all inputs get passed explicitly via +the `AnalysisHost::apply_change` method, which accepts a single argument, a +`Change`. [`Change`] is a builder for a single change +"transaction", so it suffices to study its methods to understand all of the +input data. + +[`Change`]: https://github.com/rust-lang/rust-analyzer/blob/master/crates/base_db/src/change.rs#L14-L89 + +The `(add|change|remove)_file` methods control the set of the input files, where +each file has an integer id (`FileId`, picked by the client), text (`String`) +and a filesystem path. Paths are tricky; they'll be explained below, in source roots +section, together with the `add_root` method. The `add_library` method allows us to add a +group of files which are assumed to rarely change. It's mostly an optimization +and does not change the fundamental picture. + +The `set_crate_graph` method allows us to control how the input files are partitioned +into compilation units -- crates. It also controls (in theory, not implemented +yet) `cfg` flags. `CrateGraph` is a directed acyclic graph of crates. Each crate +has a root `FileId`, a set of active `cfg` flags and a set of dependencies. Each +dependency is a pair of a crate and a name. It is possible to have two crates +with the same root `FileId` but different `cfg`-flags/dependencies. This model +is lower than Cargo's model of packages: each Cargo package consists of several +targets, each of which is a separate crate (or several crates, if you try +different feature combinations). + +Procedural macros should become inputs as well, but currently they are not +supported. Procedural macro will be a black box `Box<dyn Fn(TokenStream) -> TokenStream>` +function, and will be inserted into the crate graph just like dependencies. + +Soon we'll talk how we build an LSP server on top of `Analysis`, but first, +let's deal with that paths issue. + +## Source roots (a.k.a. "Filesystems are horrible") + +This is a non-essential section, feel free to skip. + +The previous section said that the filesystem path is an attribute of a file, +but this is not the whole truth. Making it an absolute `PathBuf` will be bad for +several reasons. First, filesystems are full of (platform-dependent) edge cases: + +* It's hard (requires a syscall) to decide if two paths are equivalent. +* Some filesystems are case-sensitive (e.g. macOS). +* Paths are not necessarily UTF-8. +* Symlinks can form cycles. + +Second, this might hurt the reproducibility and hermeticity of builds. In theory, +moving a project from `/foo/bar/my-project` to `/spam/eggs/my-project` should +not change a bit in the output. However, if the absolute path is a part of the +input, it is at least in theory observable, and *could* affect the output. + +Yet another problem is that we really *really* want to avoid doing I/O, but with +Rust the set of "input" files is not necessarily known up-front. In theory, you +can have `#[path="/dev/random"] mod foo;`. + +To solve (or explicitly refuse to solve) these problems rust-analyzer uses the +concept of a "source root". Roughly speaking, source roots are the contents of a +directory on a file systems, like `/home/matklad/projects/rustraytracer/**.rs`. + +More precisely, all files (`FileId`s) are partitioned into disjoint +`SourceRoot`s. Each file has a relative UTF-8 path within the `SourceRoot`. +`SourceRoot` has an identity (integer ID). Crucially, the root path of the +source root itself is unknown to the analyzer: A client is supposed to maintain a +mapping between `SourceRoot` IDs (which are assigned by the client) and actual +`PathBuf`s. `SourceRoot`s give a sane tree model of the file system to the +analyzer. + +Note that `mod`, `#[path]` and `include!()` can only reference files from the +same source root. It is of course possible to explicitly add extra files to +the source root, even `/dev/random`. + +## Language Server Protocol + +Now let's see how the `Analysis` API is exposed via the JSON RPC based language server protocol. The +hard part here is managing changes (which can come either from the file system +or from the editor) and concurrency (we want to spawn background jobs for things +like syntax highlighting). We use the event loop pattern to manage the zoo, and +the loop is the [`main_loop_inner`] function. The [`main_loop`] does a one-time +initialization and tearing down of the resources. + +[`main_loop`]: https://github.com/rust-lang/rust-analyzer/blob/guide-2019-01/crates/ra_lsp_server/src/main_loop.rs#L51-L110 +[`main_loop_inner`]: https://github.com/rust-lang/rust-analyzer/blob/guide-2019-01/crates/ra_lsp_server/src/main_loop.rs#L156-L258 + + +Let's walk through a typical analyzer session! + +First, we need to figure out what to analyze. To do this, we run `cargo +metadata` to learn about Cargo packages for current workspace and dependencies, +and we run `rustc --print sysroot` and scan the "sysroot" (the directory containing the current Rust toolchain's files) to learn about crates like +`std`. Currently we load this configuration once at the start of the server, but +it should be possible to dynamically reconfigure it later without restart. + +[main_loop.rs#L62-L70](https://github.com/rust-lang/rust-analyzer/blob/guide-2019-01/crates/ra_lsp_server/src/main_loop.rs#L62-L70) + +The [`ProjectModel`] we get after this step is very Cargo and sysroot specific, +it needs to be lowered to get the input in the form of `Change`. This +happens in [`ServerWorldState::new`] method. Specifically + +* Create a `SourceRoot` for each Cargo package and sysroot. +* Schedule a filesystem scan of the roots. +* Create an analyzer's `Crate` for each Cargo **target** and sysroot crate. +* Setup dependencies between the crates. + +[`ProjectModel`]: https://github.com/rust-lang/rust-analyzer/blob/guide-2019-01/crates/ra_lsp_server/src/project_model.rs#L16-L20 +[`ServerWorldState::new`]: https://github.com/rust-lang/rust-analyzer/blob/guide-2019-01/crates/ra_lsp_server/src/server_world.rs#L38-L160 + +The results of the scan (which may take a while) will be processed in the body +of the main loop, just like any other change. Here's where we handle: + +* [File system changes](https://github.com/rust-lang/rust-analyzer/blob/guide-2019-01/crates/ra_lsp_server/src/main_loop.rs#L194) +* [Changes from the editor](https://github.com/rust-lang/rust-analyzer/blob/guide-2019-01/crates/ra_lsp_server/src/main_loop.rs#L377) + +After a single loop's turn, we group the changes into one `Change` and +[apply] it. This always happens on the main thread and blocks the loop. + +[apply]: https://github.com/rust-lang/rust-analyzer/blob/guide-2019-01/crates/ra_lsp_server/src/server_world.rs#L216 + +To handle requests, like ["goto definition"], we create an instance of the +`Analysis` and [`schedule`] the task (which consumes `Analysis`) on the +threadpool. [The task] calls the corresponding `Analysis` method, while +massaging the types into the LSP representation. Keep in mind that if we are +executing "goto definition" on the threadpool and a new change comes in, the +task will be canceled as soon as the main loop calls `apply_change` on the +`AnalysisHost`. + +["goto definition"]: https://github.com/rust-lang/rust-analyzer/blob/guide-2019-01/crates/ra_lsp_server/src/server_world.rs#L216 +[`schedule`]: https://github.com/rust-lang/rust-analyzer/blob/guide-2019-01/crates/ra_lsp_server/src/main_loop.rs#L426-L455 +[The task]: https://github.com/rust-lang/rust-analyzer/blob/guide-2019-01/crates/ra_lsp_server/src/main_loop/handlers.rs#L205-L223 + +This concludes the overview of the analyzer's programing *interface*. Next, let's +dig into the implementation! + +## Salsa + +The most straightforward way to implement an "apply change, get analysis, repeat" +API would be to maintain the input state and to compute all possible analysis +information from scratch after every change. This works, but scales poorly with +the size of the project. To make this fast, we need to take advantage of the +fact that most of the changes are small, and that analysis results are unlikely +to change significantly between invocations. + +To do this we use [salsa]: a framework for incremental on-demand computation. +You can skip the rest of the section if you are familiar with `rustc`'s red-green +algorithm (which is used for incremental compilation). + +[salsa]: https://github.com/salsa-rs/salsa + +It's better to refer to salsa's docs to learn about it. Here's a small excerpt: + +The key idea of salsa is that you define your program as a set of queries. Every +query is used like a function `K -> V` that maps from some key of type `K` to a value +of type `V`. Queries come in two basic varieties: + +* **Inputs**: the base inputs to your system. You can change these whenever you + like. + +* **Functions**: pure functions (no side effects) that transform your inputs + into other values. The results of queries are memoized to avoid recomputing + them a lot. When you make changes to the inputs, we'll figure out (fairly + intelligently) when we can re-use these memoized values and when we have to + recompute them. + +For further discussion, its important to understand one bit of "fairly +intelligently". Suppose we have two functions, `f1` and `f2`, and one input, +`z`. We call `f1(X)` which in turn calls `f2(Y)` which inspects `i(Z)`. `i(Z)` +returns some value `V1`, `f2` uses that and returns `R1`, `f1` uses that and +returns `O`. Now, let's change `i` at `Z` to `V2` from `V1` and try to compute +`f1(X)` again. Because `f1(X)` (transitively) depends on `i(Z)`, we can't just +reuse its value as is. However, if `f2(Y)` is *still* equal to `R1` (despite +`i`'s change), we, in fact, *can* reuse `O` as result of `f1(X)`. And that's how +salsa works: it recomputes results in *reverse* order, starting from inputs and +progressing towards outputs, stopping as soon as it sees an intermediate value +that hasn't changed. If this sounds confusing to you, don't worry: it is +confusing. This illustration by @killercup might help: + +<img alt="step 1" src="https://user-images.githubusercontent.com/1711539/51460907-c5484780-1d6d-11e9-9cd2-d6f62bd746e0.png" width="50%"> + +<img alt="step 2" src="https://user-images.githubusercontent.com/1711539/51460915-c9746500-1d6d-11e9-9a77-27d33a0c51b5.png" width="50%"> + +<img alt="step 3" src="https://user-images.githubusercontent.com/1711539/51460920-cda08280-1d6d-11e9-8d96-a782aa57a4d4.png" width="50%"> + +<img alt="step 4" src="https://user-images.githubusercontent.com/1711539/51460927-d1340980-1d6d-11e9-851e-13c149d5c406.png" width="50%"> + +## Salsa Input Queries + +All analyzer information is stored in a salsa database. `Analysis` and +`AnalysisHost` types are newtype wrappers for [`RootDatabase`] -- a salsa +database. + +[`RootDatabase`]: https://github.com/rust-lang/rust-analyzer/blob/guide-2019-01/crates/ide_api/src/db.rs#L88-L134 + +Salsa input queries are defined in [`FilesDatabase`] (which is a part of +`RootDatabase`). They closely mirror the familiar `Change` structure: +indeed, what `apply_change` does is it sets the values of input queries. + +[`FilesDatabase`]: https://github.com/rust-lang/rust-analyzer/blob/guide-2019-01/crates/base_db/src/input.rs#L150-L174 + +## From text to semantic model + +The bulk of the rust-analyzer is transforming input text into a semantic model of +Rust code: a web of entities like modules, structs, functions and traits. + +An important fact to realize is that (unlike most other languages like C# or +Java) there is not a one-to-one mapping between the source code and the semantic model. A +single function definition in the source code might result in several semantic +functions: for example, the same source file might get included as a module in +several crates or a single crate might be present in the compilation DAG +several times, with different sets of `cfg`s enabled. The IDE-specific task of +mapping source code into a semantic model is inherently imprecise for +this reason and gets handled by the [`source_binder`]. + +[`source_binder`]: https://github.com/rust-lang/rust-analyzer/blob/guide-2019-01/crates/hir/src/source_binder.rs + +The semantic interface is declared in the [`code_model_api`] module. Each entity is +identified by an integer ID and has a bunch of methods which take a salsa database +as an argument and returns other entities (which are also IDs). Internally, these +methods invoke various queries on the database to build the model on demand. +Here's [the list of queries]. + +[`code_model_api`]: https://github.com/rust-lang/rust-analyzer/blob/guide-2019-01/crates/hir/src/code_model_api.rs +[the list of queries]: https://github.com/rust-lang/rust-analyzer/blob/7e84440e25e19529e4ff8a66e521d1b06349c6ec/crates/hir/src/db.rs#L20-L106 + +The first step of building the model is parsing the source code. + +## Syntax trees + +An important property of the Rust language is that each file can be parsed in +isolation. Unlike, say, `C++`, an `include` can't change the meaning of the +syntax. For this reason, rust-analyzer can build a syntax tree for each "source +file", which could then be reused by several semantic models if this file +happens to be a part of several crates. + +The representation of syntax trees that rust-analyzer uses is similar to that of `Roslyn` +and Swift's new [libsyntax]. Swift's docs give an excellent overview of the +approach, so I skip this part here and instead outline the main characteristics +of the syntax trees: + +* Syntax trees are fully lossless. Converting **any** text to a syntax tree and + back is a total identity function. All whitespace and comments are explicitly + represented in the tree. + +* Syntax nodes have generic `(next|previous)_sibling`, `parent`, + `(first|last)_child` functions. You can get from any one node to any other + node in the file using only these functions. + +* Syntax nodes know their range (start offset and length) in the file. + +* Syntax nodes share the ownership of their syntax tree: if you keep a reference + to a single function, the whole enclosing file is alive. + +* Syntax trees are immutable and the cost of replacing the subtree is + proportional to the depth of the subtree. Read Swift's docs to learn how + immutable + parent pointers + cheap modification is possible. + +* Syntax trees are build on best-effort basis. All accessor methods return + `Option`s. The tree for `fn foo` will contain a function declaration with + `None` for parameter list and body. + +* Syntax trees do not know the file they are built from, they only know about + the text. + +The implementation is based on the generic [rowan] crate on top of which a +[rust-specific] AST is generated. + +[libsyntax]: https://github.com/apple/swift/tree/5e2c815edfd758f9b1309ce07bfc01c4bc20ec23/lib/Syntax +[rowan]: https://github.com/rust-analyzer/rowan/tree/100a36dc820eb393b74abe0d20ddf99077b61f88 +[rust-specific]: https://github.com/rust-lang/rust-analyzer/blob/guide-2019-01/crates/ra_syntax/src/ast/generated.rs + +The next step in constructing the semantic model is ... + +## Building a Module Tree + +The algorithm for building a tree of modules is to start with a crate root +(remember, each `Crate` from a `CrateGraph` has a `FileId`), collect all `mod` +declarations and recursively process child modules. This is handled by the +[`module_tree_query`], with two slight variations. + +[`module_tree_query`]: https://github.com/rust-lang/rust-analyzer/blob/guide-2019-01/crates/hir/src/module_tree.rs#L116-L123 + +First, rust-analyzer builds a module tree for all crates in a source root +simultaneously. The main reason for this is historical (`module_tree` predates +`CrateGraph`), but this approach also enables accounting for files which are not +part of any crate. That is, if you create a file but do not include it as a +submodule anywhere, you still get semantic completion, and you get a warning +about a free-floating module (the actual warning is not implemented yet). + +The second difference is that `module_tree_query` does not *directly* depend on +the "parse" query (which is confusingly called `source_file`). Why would calling +the parse directly be bad? Suppose the user changes the file slightly, by adding +an insignificant whitespace. Adding whitespace changes the parse tree (because +it includes whitespace), and that means recomputing the whole module tree. + +We deal with this problem by introducing an intermediate [`submodules_query`]. +This query processes the syntax tree and extracts a set of declared submodule +names. Now, changing the whitespace results in `submodules_query` being +re-executed for a *single* module, but because the result of this query stays +the same, we don't have to re-execute [`module_tree_query`]. In fact, we only +need to re-execute it when we add/remove new files or when we change mod +declarations. + +[`submodules_query`]: https://github.com/rust-lang/rust-analyzer/blob/guide-2019-01/crates/hir/src/module_tree.rs#L41 + +We store the resulting modules in a `Vec`-based indexed arena. The indices in +the arena becomes module IDs. And this brings us to the next topic: +assigning IDs in the general case. + +## Location Interner pattern + +One way to assign IDs is how we've dealt with modules: Collect all items into a +single array in some specific order and use the index in the array as an ID. The +main drawback of this approach is that these IDs are not stable: Adding a new item can +shift the IDs of all other items. This works for modules, because adding a module is +a comparatively rare operation, but would be less convenient for, for example, +functions. + +Another solution here is positional IDs: We can identify a function as "the +function with name `foo` in a ModuleId(92) module". Such locations are stable: +adding a new function to the module (unless it is also named `foo`) does not +change the location. However, such "ID" types ceases to be a `Copy`able integer and in +general can become pretty large if we account for nesting (for example: "third parameter of +the `foo` function of the `bar` `impl` in the `baz` module"). + +[`LocationInterner`] allows us to combine the benefits of positional and numeric +IDs. It is a bidirectional append-only map between locations and consecutive +integers which can "intern" a location and return an integer ID back. The salsa +database we use includes a couple of [interners]. How to "garbage collect" +unused locations is an open question. + +[`LocationInterner`]: https://github.com/rust-lang/rust-analyzer/blob/guide-2019-01/crates/base_db/src/loc2id.rs#L65-L71 +[interners]: https://github.com/rust-lang/rust-analyzer/blob/guide-2019-01/crates/hir/src/db.rs#L22-L23 + +For example, we use `LocationInterner` to assign IDs to definitions of functions, +structs, enums, etc. The location, [`DefLoc`] contains two bits of information: + +* the ID of the module which contains the definition, +* the ID of the specific item in the modules source code. + +We "could" use a text offset for the location of a particular item, but that would play +badly with salsa: offsets change after edits. So, as a rule of thumb, we avoid +using offsets, text ranges or syntax trees as keys and values for queries. What +we do instead is we store "index" of the item among all of the items of a file +(so, a positional based ID, but localized to a single file). + +[`DefLoc`]: https://github.com/rust-lang/rust-analyzer/blob/guide-2019-01/crates/hir/src/ids.rs#L127-L139 + +One thing we've glossed over for the time being is support for macros. We have +only proof of concept handling of macros at the moment, but they are extremely +interesting from an "assigning IDs" perspective. + +## Macros and recursive locations + +The tricky bit about macros is that they effectively create new source files. +While we can use `FileId`s to refer to original files, we can't just assign them +willy-nilly to the pseudo files of macro expansion. Instead, we use a special +ID, [`HirFileId`] to refer to either a usual file or a macro-generated file: + +```rust +enum HirFileId { + FileId(FileId), + Macro(MacroCallId), +} +``` + +`MacroCallId` is an interned ID that specifies a particular macro invocation. +Its `MacroCallLoc` contains: + +* `ModuleId` of the containing module +* `HirFileId` of the containing file or pseudo file +* an index of this particular macro invocation in this file (positional id + again). + +Note how `HirFileId` is defined in terms of `MacroCallLoc` which is defined in +terms of `HirFileId`! This does not recur infinitely though: any chain of +`HirFileId`s bottoms out in `HirFileId::FileId`, that is, some source file +actually written by the user. + +[`HirFileId`]: https://github.com/rust-lang/rust-analyzer/blob/guide-2019-01/crates/hir/src/ids.rs#L18-L125 + +Now that we understand how to identify a definition, in a source or in a +macro-generated file, we can discuss name resolution a bit. + +## Name resolution + +Name resolution faces the same problem as the module tree: if we look at the +syntax tree directly, we'll have to recompute name resolution after every +modification. The solution to the problem is the same: We [lower] the source code of +each module into a position-independent representation which does not change if +we modify bodies of the items. After that we [loop] resolving all imports until +we've reached a fixed point. + +[lower]: https://github.com/rust-lang/rust-analyzer/blob/guide-2019-01/crates/hir/src/nameres/lower.rs#L113-L117 +[loop]: https://github.com/rust-lang/rust-analyzer/blob/guide-2019-01/crates/hir/src/nameres.rs#L186-L196 + +And, given all our preparation with IDs and a position-independent representation, +it is satisfying to [test] that typing inside function body does not invalidate +name resolution results. + +[test]: https://github.com/rust-lang/rust-analyzer/blob/guide-2019-01/crates/hir/src/nameres/tests.rs#L376 + +An interesting fact about name resolution is that it "erases" all of the +intermediate paths from the imports: in the end, we know which items are defined +and which items are imported in each module, but, if the import was `use +foo::bar::baz`, we deliberately forget what modules `foo` and `bar` resolve to. + +To serve "goto definition" requests on intermediate segments we need this info +in the IDE, however. Luckily, we need it only for a tiny fraction of imports, so we just ask +the module explicitly, "What does the path `foo::bar` resolve to?". This is a +general pattern: we try to compute the minimal possible amount of information +during analysis while allowing IDE to ask for additional specific bits. + +Name resolution is also a good place to introduce another salsa pattern used +throughout the analyzer: + +## Source Map pattern + +Due to an obscure edge case in completion, IDE needs to know the syntax node of +a use statement which imported the given completion candidate. We can't just +store the syntax node as a part of name resolution: this will break +incrementality, due to the fact that syntax changes after every file +modification. + +We solve this problem during the lowering step of name resolution. The lowering +query actually produces a *pair* of outputs: `LoweredModule` and [`SourceMap`]. +The `LoweredModule` module contains [imports], but in a position-independent form. +The `SourceMap` contains a mapping from position-independent imports to +(position-dependent) syntax nodes. + +The result of this basic lowering query changes after every modification. But +there's an intermediate [projection query] which returns only the first +position-independent part of the lowering. The result of this query is stable. +Naturally, name resolution [uses] this stable projection query. + +[imports]: https://github.com/rust-lang/rust-analyzer/blob/guide-2019-01/crates/hir/src/nameres/lower.rs#L52-L59 +[`SourceMap`]: https://github.com/rust-lang/rust-analyzer/blob/guide-2019-01/crates/hir/src/nameres/lower.rs#L52-L59 +[projection query]: https://github.com/rust-lang/rust-analyzer/blob/guide-2019-01/crates/hir/src/nameres/lower.rs#L97-L103 +[uses]: https://github.com/rust-lang/rust-analyzer/blob/guide-2019-01/crates/hir/src/query_definitions.rs#L49 + +## Type inference + +First of all, implementation of type inference in rust-analyzer was spearheaded +by [@flodiebold]. [#327] was an awesome Christmas present, thank you, Florian! + +Type inference runs on per-function granularity and uses the patterns we've +discussed previously. + +First, we [lower the AST] of a function body into a position-independent +representation. In this representation, each expression is assigned a +[positional ID]. Alongside the lowered expression, [a source map] is produced, +which maps between expression ids and original syntax. This lowering step also +deals with "incomplete" source trees by replacing missing expressions by an +explicit `Missing` expression. + +Given the lowered body of the function, we can now run [type inference] and +construct a mapping from `ExprId`s to types. + +[@flodiebold]: https://github.com/flodiebold +[#327]: https://github.com/rust-lang/rust-analyzer/pull/327 +[lower the AST]: https://github.com/rust-lang/rust-analyzer/blob/guide-2019-01/crates/hir/src/expr.rs +[positional ID]: https://github.com/rust-lang/rust-analyzer/blob/guide-2019-01/crates/hir/src/expr.rs#L13-L15 +[a source map]: https://github.com/rust-lang/rust-analyzer/blob/guide-2019-01/crates/hir/src/expr.rs#L41-L44 +[type inference]: https://github.com/rust-lang/rust-analyzer/blob/guide-2019-01/crates/hir/src/ty.rs#L1208-L1223 + +## Tying it all together: completion + +To conclude the overview of the rust-analyzer, let's trace the request for +(type-inference powered!) code completion! + +We start by [receiving a message] from the language client. We decode the +message as a request for completion and [schedule it on the threadpool]. This is +the place where we [catch] canceled errors if, immediately after completion, the +client sends some modification. + +In [the handler], we deserialize LSP requests into rust-analyzer specific data +types (by converting a file url into a numeric `FileId`), [ask analysis for +completion] and serialize results into the LSP. + +The [completion implementation] is finally the place where we start doing the actual +work. The first step is to collect the `CompletionContext` -- a struct which +describes the cursor position in terms of Rust syntax and semantics. For +example, `function_syntax: Option<&'a ast::FnDef>` stores a reference to +the enclosing function *syntax*, while `function: Option<hir::Function>` is the +`Def` for this function. + +To construct the context, we first do an ["IntelliJ Trick"]: we insert a dummy +identifier at the cursor's position and parse this modified file, to get a +reasonably looking syntax tree. Then we do a bunch of "classification" routines +to figure out the context. For example, we [find an ancestor `fn` node] and we get a +[semantic model] for it (using the lossy `source_binder` infrastructure). + +The second step is to run a [series of independent completion routines]. Let's +take a closer look at [`complete_dot`], which completes fields and methods in +`foo.bar|`. First we extract a semantic function and a syntactic receiver +expression out of the `Context`. Then we run type-inference for this single +function and map our syntactic expression to `ExprId`. Using the ID, we figure +out the type of the receiver expression. Then we add all fields & methods from +the type to completion. + +[receiving a message]: https://github.com/rust-lang/rust-analyzer/blob/guide-2019-01/crates/ra_lsp_server/src/main_loop.rs#L203 +[schedule it on the threadpool]: https://github.com/rust-lang/rust-analyzer/blob/guide-2019-01/crates/ra_lsp_server/src/main_loop.rs#L428 +[catch]: https://github.com/rust-lang/rust-analyzer/blob/guide-2019-01/crates/ra_lsp_server/src/main_loop.rs#L436-L442 +[the handler]: https://salsa.zulipchat.com/#narrow/stream/181542-rfcs.2Fsalsa-query-group/topic/design.20next.20steps +[ask analysis for completion]: https://github.com/rust-lang/rust-analyzer/blob/guide-2019-01/crates/ide_api/src/lib.rs#L439-L444 +[completion implementation]: https://github.com/rust-lang/rust-analyzer/blob/guide-2019-01/crates/ide_api/src/completion.rs#L46-L62 +[`CompletionContext`]: https://github.com/rust-lang/rust-analyzer/blob/guide-2019-01/crates/ide_api/src/completion/completion_context.rs#L14-L37 +["IntelliJ Trick"]: https://github.com/rust-lang/rust-analyzer/blob/guide-2019-01/crates/ide_api/src/completion/completion_context.rs#L72-L75 +[find an ancestor `fn` node]: https://github.com/rust-lang/rust-analyzer/blob/guide-2019-01/crates/ide_api/src/completion/completion_context.rs#L116-L120 +[semantic model]: https://github.com/rust-lang/rust-analyzer/blob/guide-2019-01/crates/ide_api/src/completion/completion_context.rs#L123 +[series of independent completion routines]: https://github.com/rust-lang/rust-analyzer/blob/guide-2019-01/crates/ide_api/src/completion.rs#L52-L59 +[`complete_dot`]: https://github.com/rust-lang/rust-analyzer/blob/guide-2019-01/crates/ide_api/src/completion/complete_dot.rs#L6-L22 diff --git a/src/tools/rust-analyzer/docs/dev/lsp-extensions.md b/src/tools/rust-analyzer/docs/dev/lsp-extensions.md new file mode 100644 index 000000000..5040643d3 --- /dev/null +++ b/src/tools/rust-analyzer/docs/dev/lsp-extensions.md @@ -0,0 +1,761 @@ +<!--- +lsp_ext.rs hash: 2a188defec26cc7c + +If you need to change the above hash to make the test pass, please check if you +need to adjust this doc as well and ping this issue: + + https://github.com/rust-lang/rust-analyzer/issues/4604 + +---> + +# LSP Extensions + +This document describes LSP extensions used by rust-analyzer. +It's a best effort document, when in doubt, consult the source (and send a PR with clarification ;-) ). +We aim to upstream all non Rust-specific extensions to the protocol, but this is not a top priority. +All capabilities are enabled via the `experimental` field of `ClientCapabilities` or `ServerCapabilities`. +Requests which we hope to upstream live under `experimental/` namespace. +Requests, which are likely to always remain specific to `rust-analyzer` are under `rust-analyzer/` namespace. + +If you want to be notified about the changes to this document, subscribe to [#4604](https://github.com/rust-lang/rust-analyzer/issues/4604). + +## UTF-8 offsets + +rust-analyzer supports clangd's extension for opting into UTF-8 as the coordinate space for offsets (by default, LSP uses UTF-16 offsets). + +https://clangd.llvm.org/extensions.html#utf-8-offsets + +## Configuration in `initializationOptions` + +**Upstream Issue:** https://github.com/microsoft/language-server-protocol/issues/567 + +The `initializationOptions` field of the `InitializeParams` of the initialization request should contain the `"rust-analyzer"` section of the configuration. + +`rust-analyzer` normally sends a `"workspace/configuration"` request with `{ "items": ["rust-analyzer"] }` payload. +However, the server can't do this during initialization. +At the same time some essential configuration parameters are needed early on, before servicing requests. +For this reason, we ask that `initializationOptions` contains the configuration, as if the server did make a `"workspace/configuration"` request. + +If a language client does not know about `rust-analyzer`'s configuration options it can get sensible defaults by doing any of the following: + * Not sending `initializationOptions` + * Sending `"initializationOptions": null` + * Sending `"initializationOptions": {}` + +## Snippet `TextEdit` + +**Upstream Issue:** https://github.com/microsoft/language-server-protocol/issues/724 + +**Experimental Client Capability:** `{ "snippetTextEdit": boolean }` + +If this capability is set, `WorkspaceEdit`s returned from `codeAction` requests and `TextEdit`s returned from `textDocument/onTypeFormatting` requests might contain `SnippetTextEdit`s instead of usual `TextEdit`s: + +```typescript +interface SnippetTextEdit extends TextEdit { + insertTextFormat?: InsertTextFormat; + annotationId?: ChangeAnnotationIdentifier; +} +``` + +```typescript +export interface TextDocumentEdit { + textDocument: OptionalVersionedTextDocumentIdentifier; + edits: (TextEdit | SnippetTextEdit)[]; +} +``` + +When applying such code action or text edit, the editor should insert snippet, with tab stops and placeholder. +At the moment, rust-analyzer guarantees that only a single edit will have `InsertTextFormat.Snippet`. + +### Example + +"Add `derive`" code action transforms `struct S;` into `#[derive($0)] struct S;` + +### Unresolved Questions + +* Where exactly are `SnippetTextEdit`s allowed (only in code actions at the moment)? +* Can snippets span multiple files (so far, no)? + +## `CodeAction` Groups + +**Upstream Issue:** https://github.com/microsoft/language-server-protocol/issues/994 + +**Experimental Client Capability:** `{ "codeActionGroup": boolean }` + +If this capability is set, `CodeAction`s returned from the server contain an additional field, `group`: + +```typescript +interface CodeAction { + title: string; + group?: string; + ... +} +``` + +All code-actions with the same `group` should be grouped under single (extendable) entry in lightbulb menu. +The set of actions `[ { title: "foo" }, { group: "frobnicate", title: "bar" }, { group: "frobnicate", title: "baz" }]` should be rendered as + +``` +💡 + +-------------+ + | foo | + +-------------+-----+ + | frobnicate >| bar | + +-------------+-----+ + | baz | + +-----+ +``` + +Alternatively, selecting `frobnicate` could present a user with an additional menu to choose between `bar` and `baz`. + +### Example + +```rust +fn main() { + let x: Entry/*cursor here*/ = todo!(); +} +``` + +Invoking code action at this position will yield two code actions for importing `Entry` from either `collections::HashMap` or `collection::BTreeMap`, grouped under a single "import" group. + +### Unresolved Questions + +* Is a fixed two-level structure enough? +* Should we devise a general way to encode custom interaction protocols for GUI refactorings? + +## Parent Module + +**Upstream Issue:** https://github.com/microsoft/language-server-protocol/issues/1002 + +**Experimental Server Capability:** `{ "parentModule": boolean }` + +This request is sent from client to server to handle "Goto Parent Module" editor action. + +**Method:** `experimental/parentModule` + +**Request:** `TextDocumentPositionParams` + +**Response:** `Location | Location[] | LocationLink[] | null` + + +### Example + +```rust +// src/main.rs +mod foo; +// src/foo.rs + +/* cursor here*/ +``` + +`experimental/parentModule` returns a single `Link` to the `mod foo;` declaration. + +### Unresolved Question + +* An alternative would be to use a more general "gotoSuper" request, which would work for super methods, super classes and super modules. + This is the approach IntelliJ Rust is taking. + However, experience shows that super module (which generally has a feeling of navigation between files) should be separate. + If you want super module, but the cursor happens to be inside an overridden function, the behavior with single "gotoSuper" request is surprising. + +## Join Lines + +**Upstream Issue:** https://github.com/microsoft/language-server-protocol/issues/992 + +**Experimental Server Capability:** `{ "joinLines": boolean }` + +This request is sent from client to server to handle "Join Lines" editor action. + +**Method:** `experimental/joinLines` + +**Request:** + +```typescript +interface JoinLinesParams { + textDocument: TextDocumentIdentifier, + /// Currently active selections/cursor offsets. + /// This is an array to support multiple cursors. + ranges: Range[], +} +``` + +**Response:** `TextEdit[]` + +### Example + +```rust +fn main() { + /*cursor here*/let x = { + 92 + }; +} +``` + +`experimental/joinLines` yields (curly braces are automagically removed) + +```rust +fn main() { + let x = 92; +} +``` + +### Unresolved Question + +* What is the position of the cursor after `joinLines`? + Currently, this is left to editor's discretion, but it might be useful to specify on the server via snippets. + However, it then becomes unclear how it works with multi cursor. + +## On Enter + +**Upstream Issue:** https://github.com/microsoft/language-server-protocol/issues/1001 + +**Experimental Server Capability:** `{ "onEnter": boolean }` + +This request is sent from client to server to handle the <kbd>Enter</kbd> key press. + +**Method:** `experimental/onEnter` + +**Request:**: `TextDocumentPositionParams` + +**Response:** + +```typescript +SnippetTextEdit[] +``` + +### Example + +```rust +fn main() { + // Some /*cursor here*/ docs + let x = 92; +} +``` + +`experimental/onEnter` returns the following snippet + +```rust +fn main() { + // Some + // $0 docs + let x = 92; +} +``` + +The primary goal of `onEnter` is to handle automatic indentation when opening a new line. +This is not yet implemented. +The secondary goal is to handle fixing up syntax, like continuing doc strings and comments, and escaping `\n` in string literals. + +As proper cursor positioning is raison-d'etat for `onEnter`, it uses `SnippetTextEdit`. + +### Unresolved Question + +* How to deal with synchronicity of the request? + One option is to require the client to block until the server returns the response. + Another option is to do a OT-style merging of edits from client and server. + A third option is to do a record-replay: client applies heuristic on enter immediately, then applies all user's keypresses. + When the server is ready with the response, the client rollbacks all the changes and applies the recorded actions on top of the correct response. +* How to deal with multiple carets? +* Should we extend this to arbitrary typed events and not just `onEnter`? + +## Structural Search Replace (SSR) + +**Experimental Server Capability:** `{ "ssr": boolean }` + +This request is sent from client to server to handle structural search replace -- automated syntax tree based transformation of the source. + +**Method:** `experimental/ssr` + +**Request:** + +```typescript +interface SsrParams { + /// Search query. + /// The specific syntax is specified outside of the protocol. + query: string, + /// If true, only check the syntax of the query and don't compute the actual edit. + parseOnly: boolean, + /// The current text document. This and `position` will be used to determine in what scope + /// paths in `query` should be resolved. + textDocument: TextDocumentIdentifier; + /// Position where SSR was invoked. + position: Position; + /// Current selections. Search/replace will be restricted to these if non-empty. + selections: Range[]; +} +``` + +**Response:** + +```typescript +WorkspaceEdit +``` + +### Example + +SSR with query `foo($a, $b) ==>> ($a).foo($b)` will transform, eg `foo(y + 5, z)` into `(y + 5).foo(z)`. + +### Unresolved Question + +* Probably needs search without replace mode +* Needs a way to limit the scope to certain files. + +## Matching Brace + +**Upstream Issue:** https://github.com/microsoft/language-server-protocol/issues/999 + +**Experimental Server Capability:** `{ "matchingBrace": boolean }` + +This request is sent from client to server to handle "Matching Brace" editor action. + +**Method:** `experimental/matchingBrace` + +**Request:** + +```typescript +interface MatchingBraceParams { + textDocument: TextDocumentIdentifier, + /// Position for each cursor + positions: Position[], +} +``` + +**Response:** + +```typescript +Position[] +``` + +### Example + +```rust +fn main() { + let x: Vec<()>/*cursor here*/ = vec![] +} +``` + +`experimental/matchingBrace` yields the position of `<`. +In many cases, matching braces can be handled by the editor. +However, some cases (like disambiguating between generics and comparison operations) need a real parser. +Moreover, it would be cool if editors didn't need to implement even basic language parsing + +### Unresolved Question + +* Should we return a nested brace structure, to allow paredit-like actions of jump *out* of the current brace pair? + This is how `SelectionRange` request works. +* Alternatively, should we perhaps flag certain `SelectionRange`s as being brace pairs? + +## Runnables + +**Upstream Issue:** https://github.com/microsoft/language-server-protocol/issues/944 + +**Experimental Server Capability:** `{ "runnables": { "kinds": string[] } }` + +This request is sent from client to server to get the list of things that can be run (tests, binaries, `cargo check -p`). + +**Method:** `experimental/runnables` + +**Request:** + +```typescript +interface RunnablesParams { + textDocument: TextDocumentIdentifier; + /// If null, compute runnables for the whole file. + position?: Position; +} +``` + +**Response:** `Runnable[]` + +```typescript +interface Runnable { + label: string; + /// If this Runnable is associated with a specific function/module, etc, the location of this item + location?: LocationLink; + /// Running things is necessary technology specific, `kind` needs to be advertised via server capabilities, + // the type of `args` is specific to `kind`. The actual running is handled by the client. + kind: string; + args: any; +} +``` + +rust-analyzer supports only one `kind`, `"cargo"`. The `args` for `"cargo"` look like this: + +```typescript +{ + workspaceRoot?: string; + cargoArgs: string[]; + cargoExtraArgs: string[]; + executableArgs: string[]; + expectTest?: boolean; + overrideCargo?: string; +} +``` + +## Open External Documentation + +This request is sent from client to server to get a URL to documentation for the symbol under the cursor, if available. + +**Method** `experimental/externalDocs` + +**Request:**: `TextDocumentPositionParams` + +**Response** `string | null` + + +## Analyzer Status + +**Method:** `rust-analyzer/analyzerStatus` + +**Request:** + +```typescript +interface AnalyzerStatusParams { + /// If specified, show dependencies of the current file. + textDocument?: TextDocumentIdentifier; +} +``` + +**Response:** `string` + +Returns internal status message, mostly for debugging purposes. + +## Reload Workspace + +**Method:** `rust-analyzer/reloadWorkspace` + +**Request:** `null` + +**Response:** `null` + +Reloads project information (that is, re-executes `cargo metadata`). + +## Server Status + +**Experimental Client Capability:** `{ "serverStatusNotification": boolean }` + +**Method:** `experimental/serverStatus` + +**Notification:** + +```typescript +interface ServerStatusParams { + /// `ok` means that the server is completely functional. + /// + /// `warning` means that the server is partially functional. + /// It can answer correctly to most requests, but some results + /// might be wrong due to, for example, some missing dependencies. + /// + /// `error` means that the server is not functional. For example, + /// there's a fatal build configuration problem. The server might + /// still give correct answers to simple requests, but most results + /// will be incomplete or wrong. + health: "ok" | "warning" | "error", + /// Is there any pending background work which might change the status? + /// For example, are dependencies being downloaded? + quiescent: boolean, + /// Explanatory message to show on hover. + message?: string, +} +``` + +This notification is sent from server to client. +The client can use it to display *persistent* status to the user (in modline). +It is similar to the `showMessage`, but is intended for stares rather than point-in-time events. + +Note that this functionality is intended primarily to inform the end user about the state of the server. +In particular, it's valid for the client to completely ignore this extension. +Clients are discouraged from but are allowed to use the `health` status to decide if it's worth sending a request to the server. + +## Syntax Tree + +**Method:** `rust-analyzer/syntaxTree` + +**Request:** + +```typescript +interface SyntaxTreeParams { + textDocument: TextDocumentIdentifier, + range?: Range, +} +``` + +**Response:** `string` + +Returns textual representation of a parse tree for the file/selected region. +Primarily for debugging, but very useful for all people working on rust-analyzer itself. + +## View Hir + +**Method:** `rust-analyzer/viewHir` + +**Request:** `TextDocumentPositionParams` + +**Response:** `string` + +Returns a textual representation of the HIR of the function containing the cursor. +For debugging or when working on rust-analyzer itself. + +## View File Text + +**Method:** `rust-analyzer/viewFileText` + +**Request:** `TextDocumentIdentifier` + +**Response:** `string` + +Returns the text of a file as seen by the server. +This is for debugging file sync problems. + +## View ItemTree + +**Method:** `rust-analyzer/viewItemTree` + +**Request:** + +```typescript +interface ViewItemTreeParams { + textDocument: TextDocumentIdentifier, +} +``` + +**Response:** `string` + +Returns a textual representation of the `ItemTree` of the currently open file, for debugging. + +## View Crate Graph + +**Method:** `rust-analyzer/viewCrateGraph` + +**Request:** + +```typescript +interface ViewCrateGraphParams { + full: boolean, +} +``` + +**Response:** `string` + +Renders rust-analyzer's crate graph as an SVG image. + +If `full` is `true`, the graph includes non-workspace crates (crates.io dependencies as well as sysroot crates). + +## Shuffle Crate Graph + +**Method:** `rust-analyzer/shuffleCrateGraph` + +**Request:** `null` + +Shuffles the crate IDs in the crate graph, for debugging purposes. + +## Expand Macro + +**Method:** `rust-analyzer/expandMacro` + +**Request:** + +```typescript +interface ExpandMacroParams { + textDocument: TextDocumentIdentifier, + position: Position, +} +``` + +**Response:** + +```typescript +interface ExpandedMacro { + name: string, + expansion: string, +} +``` + +Expands macro call at a given position. + +## Hover Actions + +**Experimental Client Capability:** `{ "hoverActions": boolean }` + +If this capability is set, `Hover` request returned from the server might contain an additional field, `actions`: + +```typescript +interface Hover { + ... + actions?: CommandLinkGroup[]; +} + +interface CommandLink extends Command { + /** + * A tooltip for the command, when represented in the UI. + */ + tooltip?: string; +} + +interface CommandLinkGroup { + title?: string; + commands: CommandLink[]; +} +``` + +Such actions on the client side are appended to a hover bottom as command links: +``` + +-----------------------------+ + | Hover content | + | | + +-----------------------------+ + | _Action1_ | _Action2_ | <- first group, no TITLE + +-----------------------------+ + | TITLE _Action1_ | _Action2_ | <- second group + +-----------------------------+ + ... +``` + +## Open Cargo.toml + +**Upstream Issue:** https://github.com/rust-lang/rust-analyzer/issues/6462 + +**Experimental Server Capability:** `{ "openCargoToml": boolean }` + +This request is sent from client to server to open the current project's Cargo.toml + +**Method:** `experimental/openCargoToml` + +**Request:** `OpenCargoTomlParams` + +**Response:** `Location | null` + + +### Example + +```rust +// Cargo.toml +[package] +// src/main.rs + +/* cursor here*/ +``` + +`experimental/openCargoToml` returns a single `Link` to the start of the `[package]` keyword. + +## Related tests + +This request is sent from client to server to get the list of tests for the specified position. + +**Method:** `rust-analyzer/relatedTests` + +**Request:** `TextDocumentPositionParams` + +**Response:** `TestInfo[]` + +```typescript +interface TestInfo { + runnable: Runnable; +} +``` + +## Hover Range + +**Upstream Issue:** https://github.com/microsoft/language-server-protocol/issues/377 + +**Experimental Server Capability:** { "hoverRange": boolean } + +This extension allows passing a `Range` as a `position` field of `HoverParams`. +The primary use-case is to use the hover request to show the type of the expression currently selected. + +```typescript +interface HoverParams extends WorkDoneProgressParams { + textDocument: TextDocumentIdentifier; + position: Range | Position; +} +``` +Whenever the client sends a `Range`, it is understood as the current selection and any hover included in the range will show the type of the expression if possible. + +### Example + +```rust +fn main() { + let expression = $01 + 2 * 3$0; +} +``` + +Triggering a hover inside the selection above will show a result of `i32`. + +## Move Item + +**Upstream Issue:** https://github.com/rust-lang/rust-analyzer/issues/6823 + +This request is sent from client to server to move item under cursor or selection in some direction. + +**Method:** `experimental/moveItem` + +**Request:** `MoveItemParams` + +**Response:** `SnippetTextEdit[]` + +```typescript +export interface MoveItemParams { + textDocument: TextDocumentIdentifier, + range: Range, + direction: Direction +} + +export const enum Direction { + Up = "Up", + Down = "Down" +} +``` + +## Workspace Symbols Filtering + +**Upstream Issue:** https://github.com/microsoft/language-server-protocol/issues/941 + +**Experimental Server Capability:** `{ "workspaceSymbolScopeKindFiltering": boolean }` + +Extends the existing `workspace/symbol` request with ability to filter symbols by broad scope and kind of symbol. +If this capability is set, `workspace/symbol` parameter gains two new optional fields: + + +```typescript +interface WorkspaceSymbolParams { + /** + * Return only the symbols defined in the specified scope. + */ + searchScope?: WorkspaceSymbolSearchScope; + /** + * Return only the symbols of specified kinds. + */ + searchKind?: WorkspaceSymbolSearchKind; + ... +} + +const enum WorkspaceSymbolSearchScope { + Workspace = "workspace", + WorkspaceAndDependencies = "workspaceAndDependencies" +} + +const enum WorkspaceSymbolSearchKind { + OnlyTypes = "onlyTypes", + AllSymbols = "allSymbols" +} +``` + +## Client Commands + +**Upstream Issue:** https://github.com/microsoft/language-server-protocol/issues/642 + +**Experimental Client Capability:** `{ "commands?": ClientCommandOptions }` + +Certain LSP types originating on the server, notably code lenses, embed commands. +Commands can be serviced either by the server or by the client. +However, the server doesn't know which commands are available on the client. + +This extensions allows the client to communicate this info. + + +```typescript +export interface ClientCommandOptions { + /** + * The commands to be executed on the client + */ + commands: string[]; +} +``` diff --git a/src/tools/rust-analyzer/docs/dev/style.md b/src/tools/rust-analyzer/docs/dev/style.md new file mode 100644 index 000000000..a80eebd63 --- /dev/null +++ b/src/tools/rust-analyzer/docs/dev/style.md @@ -0,0 +1,1172 @@ +Our approach to "clean code" is two-fold: + +* We generally don't block PRs on style changes. +* At the same time, all code in rust-analyzer is constantly refactored. + +It is explicitly OK for a reviewer to flag only some nits in the PR, and then send a follow-up cleanup PR for things which are easier to explain by example, cc-ing the original author. +Sending small cleanup PRs (like renaming a single local variable) is encouraged. + +When reviewing pull requests prefer extending this document to leaving +non-reusable comments on the pull request itself. + +# General + +## Scale of Changes + +Everyone knows that it's better to send small & focused pull requests. +The problem is, sometimes you *have* to, eg, rewrite the whole compiler, and that just doesn't fit into a set of isolated PRs. + +The main things to keep an eye on are the boundaries between various components. +There are three kinds of changes: + +1. Internals of a single component are changed. + Specifically, you don't change any `pub` items. + A good example here would be an addition of a new assist. + +2. API of a component is expanded. + Specifically, you add a new `pub` function which wasn't there before. + A good example here would be expansion of assist API, for example, to implement lazy assists or assists groups. + +3. A new dependency between components is introduced. + Specifically, you add a `pub use` reexport from another crate or you add a new line to the `[dependencies]` section of `Cargo.toml`. + A good example here would be adding reference search capability to the assists crates. + +For the first group, the change is generally merged as long as: + +* it works for the happy case, +* it has tests, +* it doesn't panic for the unhappy case. + +For the second group, the change would be subjected to quite a bit of scrutiny and iteration. +The new API needs to be right (or at least easy to change later). +The actual implementation doesn't matter that much. +It's very important to minimize the amount of changed lines of code for changes of the second kind. +Often, you start doing a change of the first kind, only to realize that you need to elevate to a change of the second kind. +In this case, we'll probably ask you to split API changes into a separate PR. + +Changes of the third group should be pretty rare, so we don't specify any specific process for them. +That said, adding an innocent-looking `pub use` is a very simple way to break encapsulation, keep an eye on it! + +Note: if you enjoyed this abstract hand-waving about boundaries, you might appreciate +https://www.tedinski.com/2018/02/06/system-boundaries.html + +## Crates.io Dependencies + +We try to be very conservative with usage of crates.io dependencies. +Don't use small "helper" crates (exception: `itertools` and `either` are allowed). +If there's some general reusable bit of code you need, consider adding it to the `stdx` crate. +A useful exercise is to read Cargo.lock and see if some *transitive* dependencies do not make sense for rust-analyzer. + +**Rationale:** keep compile times low, create ecosystem pressure for faster compiles, reduce the number of things which might break. + +## Commit Style + +We don't have specific rules around git history hygiene. +Maintaining clean git history is strongly encouraged, but not enforced. +Use rebase workflow, it's OK to rewrite history during PR review process. +After you are happy with the state of the code, please use [interactive rebase](https://git-scm.com/book/en/v2/Git-Tools-Rewriting-History) to squash fixup commits. + +Avoid @mentioning people in commit messages and pull request descriptions(they are added to commit message by bors). +Such messages create a lot of duplicate notification traffic during rebases. + +If possible, write Pull Request titles and descriptions from the user's perspective: + +``` +# GOOD +Make goto definition work inside macros + +# BAD +Use original span for FileId +``` + +This makes it easier to prepare a changelog. + +If the change adds a new user-visible functionality, consider recording a GIF with [peek](https://github.com/phw/peek) and pasting it into the PR description. + +To make writing the release notes easier, you can mark a pull request as a feature, fix, internal change, or minor. +Minor changes are excluded from the release notes, while the other types are distributed in their corresponding sections. +There are two ways to mark this: + +* use a `feat: `, `feature: `, `fix: `, `internal: ` or `minor: ` prefix in the PR title +* write `changelog [feature|fix|internal|skip] [description]` in a comment or in the PR description; the description is optional, and will replace the title if included. + +These comments don't have to be added by the PR author. +Editing a comment or the PR description or title is also fine, as long as it happens before the release. + +**Rationale:** clean history is potentially useful, but rarely used. +But many users read changelogs. +Including a description and GIF suitable for the changelog means less work for the maintainers on the release day. + +## Clippy + +We don't enforce Clippy. +A number of default lints have high false positive rate. +Selectively patching false-positives with `allow(clippy)` is considered worse than not using Clippy at all. +There's a `cargo lint` command which runs a subset of low-FPR lints. +Careful tweaking of `lint` is welcome. +Of course, applying Clippy suggestions is welcome as long as they indeed improve the code. + +**Rationale:** see [rust-lang/clippy#5537](https://github.com/rust-lang/rust-clippy/issues/5537). + +# Code + +## Minimal Tests + +Most tests in rust-analyzer start with a snippet of Rust code. +These snippets should be minimal -- if you copy-paste a snippet of real code into the tests, make sure to remove everything which could be removed. + +It also makes sense to format snippets more compactly (for example, by placing enum definitions like `enum E { Foo, Bar }` on a single line), +as long as they are still readable. + +When using multiline fixtures, use unindented raw string literals: + +```rust + #[test] + fn inline_field_shorthand() { + check_assist( + inline_local_variable, + r#" +struct S { foo: i32} +fn main() { + let $0foo = 92; + S { foo } +} +"#, + r#" +struct S { foo: i32} +fn main() { + S { foo: 92 } +} +"#, + ); + } +``` + +**Rationale:** + +There are many benefits to this: + +* less to read or to scroll past +* easier to understand what exactly is tested +* less stuff printed during printf-debugging +* less time to run test + +Formatting ensures that you can use your editor's "number of selected characters" feature to correlate offsets with test's source code. + +## Marked Tests + +Use +[`cov_mark::hit! / cov_mark::check!`](https://github.com/matklad/cov-mark) +when testing specific conditions. +Do not place several marks into a single test or condition. +Do not reuse marks between several tests. + +**Rationale:** marks provide an easy way to find the canonical test for each bit of code. +This makes it much easier to understand. +More than one mark per test / code branch doesn't add significantly to understanding. + +## `#[should_panic]` + +Do not use `#[should_panic]` tests. +Instead, explicitly check for `None`, `Err`, etc. + +**Rationale:** `#[should_panic]` is a tool for library authors to make sure that the API does not fail silently when misused. +`rust-analyzer` is not a library, we don't need to test for API misuse, and we have to handle any user input without panics. +Panic messages in the logs from the `#[should_panic]` tests are confusing. + +## `#[ignore]` + +Do not `#[ignore]` tests. +If the test currently does not work, assert the wrong behavior and add a fixme explaining why it is wrong. + +**Rationale:** noticing when the behavior is fixed, making sure that even the wrong behavior is acceptable (ie, not a panic). + +## Function Preconditions + +Express function preconditions in types and force the caller to provide them (rather than checking in callee): + +```rust +// GOOD +fn frobnicate(walrus: Walrus) { + ... +} + +// BAD +fn frobnicate(walrus: Option<Walrus>) { + let walrus = match walrus { + Some(it) => it, + None => return, + }; + ... +} +``` + +**Rationale:** this makes control flow explicit at the call site. +Call-site has more context, it often happens that the precondition falls out naturally or can be bubbled up higher in the stack. + +Avoid splitting precondition check and precondition use across functions: + +```rust +// GOOD +fn main() { + let s: &str = ...; + if let Some(contents) = string_literal_contents(s) { + + } +} + +fn string_literal_contents(s: &str) -> Option<&str> { + if s.starts_with('"') && s.ends_with('"') { + Some(&s[1..s.len() - 1]) + } else { + None + } +} + +// BAD +fn main() { + let s: &str = ...; + if is_string_literal(s) { + let contents = &s[1..s.len() - 1]; + } +} + +fn is_string_literal(s: &str) -> bool { + s.starts_with('"') && s.ends_with('"') +} +``` + +In the "Not as good" version, the precondition that `1` is a valid char boundary is checked in `is_string_literal` and used in `foo`. +In the "Good" version, the precondition check and usage are checked in the same block, and then encoded in the types. + +**Rationale:** non-local code properties degrade under change. + +When checking a boolean precondition, prefer `if !invariant` to `if negated_invariant`: + +```rust +// GOOD +if !(idx < len) { + return None; +} + +// BAD +if idx >= len { + return None; +} +``` + +**Rationale:** it's useful to see the invariant relied upon by the rest of the function clearly spelled out. + +## Control Flow + +As a special case of the previous rule, do not hide control flow inside functions, push it to the caller: + +```rust +// GOOD +if cond { + f() +} + +// BAD +fn f() { + if !cond { + return; + } + ... +} +``` + +## Assertions + +Assert liberally. +Prefer [`stdx::never!`](https://docs.rs/always-assert/0.1.2/always_assert/macro.never.html) to standard `assert!`. + +**Rationale:** See [cross cutting concern: error handling](https://github.com/rust-lang/rust-analyzer/blob/master/docs/dev/architecture.md#error-handling). + +## Getters & Setters + +If a field can have any value without breaking invariants, make the field public. +Conversely, if there is an invariant, document it, enforce it in the "constructor" function, make the field private, and provide a getter. +Never provide setters. + +Getters should return borrowed data: + +```rust +struct Person { + // Invariant: never empty + first_name: String, + middle_name: Option<String> +} + +// GOOD +impl Person { + fn first_name(&self) -> &str { self.first_name.as_str() } + fn middle_name(&self) -> Option<&str> { self.middle_name.as_ref() } +} + +// BAD +impl Person { + fn first_name(&self) -> String { self.first_name.clone() } + fn middle_name(&self) -> &Option<String> { &self.middle_name } +} +``` + +**Rationale:** we don't provide public API, it's cheaper to refactor than to pay getters rent. +Non-local code properties degrade under change, privacy makes invariant local. +Borrowed owned types (`&String`) disclose irrelevant details about internal representation. +Irrelevant (neither right nor wrong) things obscure correctness. + +## Useless Types + +More generally, always prefer types on the left + +```rust +// GOOD BAD +&[T] &Vec<T> +&str &String +Option<&T> &Option<T> +&Path &PathBuf +``` + +**Rationale:** types on the left are strictly more general. +Even when generality is not required, consistency is important. + +## Constructors + +Prefer `Default` to zero-argument `new` function. + +```rust +// GOOD +#[derive(Default)] +struct Foo { + bar: Option<Bar> +} + +// BAD +struct Foo { + bar: Option<Bar> +} + +impl Foo { + fn new() -> Foo { + Foo { bar: None } + } +} +``` + +Prefer `Default` even if it has to be implemented manually. + +**Rationale:** less typing in the common case, uniformity. + +Use `Vec::new` rather than `vec![]`. + +**Rationale:** uniformity, strength reduction. + +Avoid using "dummy" states to implement a `Default`. +If a type doesn't have a sensible default, empty value, don't hide it. +Let the caller explicitly decide what the right initial state is. + +## Functions Over Objects + +Avoid creating "doer" objects. +That is, objects which are created only to execute a single action. + +```rust +// GOOD +do_thing(arg1, arg2); + +// BAD +ThingDoer::new(arg1, arg2).do(); +``` + +Note that this concerns only outward API. +When implementing `do_thing`, it might be very useful to create a context object. + +```rust +pub fn do_thing(arg1: Arg1, arg2: Arg2) -> Res { + let mut ctx = Ctx { arg1, arg2 }; + ctx.run() +} + +struct Ctx { + arg1: Arg1, arg2: Arg2 +} + +impl Ctx { + fn run(self) -> Res { + ... + } +} +``` + +The difference is that `Ctx` is an impl detail here. + +Sometimes a middle ground is acceptable if this can save some busywork: + +```rust +ThingDoer::do(arg1, arg2); + +pub struct ThingDoer { + arg1: Arg1, arg2: Arg2, +} + +impl ThingDoer { + pub fn do(arg1: Arg1, arg2: Arg2) -> Res { + ThingDoer { arg1, arg2 }.run() + } + fn run(self) -> Res { + ... + } +} +``` + +**Rationale:** not bothering the caller with irrelevant details, not mixing user API with implementor API. + +## Functions with many parameters + +Avoid creating functions with many optional or boolean parameters. +Introduce a `Config` struct instead. + +```rust +// GOOD +pub struct AnnotationConfig { + pub binary_target: bool, + pub annotate_runnables: bool, + pub annotate_impls: bool, +} + +pub fn annotations( + db: &RootDatabase, + file_id: FileId, + config: AnnotationConfig +) -> Vec<Annotation> { + ... +} + +// BAD +pub fn annotations( + db: &RootDatabase, + file_id: FileId, + binary_target: bool, + annotate_runnables: bool, + annotate_impls: bool, +) -> Vec<Annotation> { + ... +} +``` + +**Rationale:** reducing churn. +If the function has many parameters, they most likely change frequently. +By packing them into a struct we protect all intermediary functions from changes. + +Do not implement `Default` for the `Config` struct, the caller has more context to determine better defaults. +Do not store `Config` as a part of the `state`, pass it explicitly. +This gives more flexibility for the caller. + +If there is variation not only in the input parameters, but in the return type as well, consider introducing a `Command` type. + +```rust +// MAYBE GOOD +pub struct Query { + pub name: String, + pub case_sensitive: bool, +} + +impl Query { + pub fn all(self) -> Vec<Item> { ... } + pub fn first(self) -> Option<Item> { ... } +} + +// MAYBE BAD +fn query_all(name: String, case_sensitive: bool) -> Vec<Item> { ... } +fn query_first(name: String, case_sensitive: bool) -> Option<Item> { ... } +``` + +## Prefer Separate Functions Over Parameters + +If a function has a `bool` or an `Option` parameter, and it is always called with `true`, `false`, `Some` and `None` literals, split the function in two. + +```rust +// GOOD +fn caller_a() { + foo() +} + +fn caller_b() { + foo_with_bar(Bar::new()) +} + +fn foo() { ... } +fn foo_with_bar(bar: Bar) { ... } + +// BAD +fn caller_a() { + foo(None) +} + +fn caller_b() { + foo(Some(Bar::new())) +} + +fn foo(bar: Option<Bar>) { ... } +``` + +**Rationale:** more often than not, such functions display "`false sharing`" -- they have additional `if` branching inside for two different cases. +Splitting the two different control flows into two functions simplifies each path, and remove cross-dependencies between the two paths. +If there's common code between `foo` and `foo_with_bar`, extract *that* into a common helper. + +## Appropriate String Types + +When interfacing with OS APIs, use `OsString`, even if the original source of data is utf-8 encoded. +**Rationale:** cleanly delineates the boundary when the data goes into the OS-land. + +Use `AbsPathBuf` and `AbsPath` over `std::Path`. +**Rationale:** rust-analyzer is a long-lived process which handles several projects at the same time. +It is important not to leak cwd by accident. + +# Premature Pessimization + +## Avoid Allocations + +Avoid writing code which is slower than it needs to be. +Don't allocate a `Vec` where an iterator would do, don't allocate strings needlessly. + +```rust +// GOOD +use itertools::Itertools; + +let (first_word, second_word) = match text.split_ascii_whitespace().collect_tuple() { + Some(it) => it, + None => return, +} + +// BAD +let words = text.split_ascii_whitespace().collect::<Vec<_>>(); +if words.len() != 2 { + return +} +``` + +**Rationale:** not allocating is almost always faster. + +## Push Allocations to the Call Site + +If allocation is inevitable, let the caller allocate the resource: + +```rust +// GOOD +fn frobnicate(s: String) { + ... +} + +// BAD +fn frobnicate(s: &str) { + let s = s.to_string(); + ... +} +``` + +**Rationale:** reveals the costs. +It is also more efficient when the caller already owns the allocation. + +## Collection Types + +Prefer `rustc_hash::FxHashMap` and `rustc_hash::FxHashSet` instead of the ones in `std::collections`. + +**Rationale:** they use a hasher that's significantly faster and using them consistently will reduce code size by some small amount. + +## Avoid Intermediate Collections + +When writing a recursive function to compute a sets of things, use an accumulator parameter instead of returning a fresh collection. +Accumulator goes first in the list of arguments. + +```rust +// GOOD +pub fn reachable_nodes(node: Node) -> FxHashSet<Node> { + let mut res = FxHashSet::default(); + go(&mut res, node); + res +} +fn go(acc: &mut FxHashSet<Node>, node: Node) { + acc.insert(node); + for n in node.neighbors() { + go(acc, n); + } +} + +// BAD +pub fn reachable_nodes(node: Node) -> FxHashSet<Node> { + let mut res = FxHashSet::default(); + res.insert(node); + for n in node.neighbors() { + res.extend(reachable_nodes(n)); + } + res +} +``` + +**Rationale:** re-use allocations, accumulator style is more concise for complex cases. + +## Avoid Monomorphization + +Avoid making a lot of code type parametric, *especially* on the boundaries between crates. + +```rust +// GOOD +fn frobnicate(f: impl FnMut()) { + frobnicate_impl(&mut f) +} +fn frobnicate_impl(f: &mut dyn FnMut()) { + // lots of code +} + +// BAD +fn frobnicate(f: impl FnMut()) { + // lots of code +} +``` + +Avoid `AsRef` polymorphism, it pays back only for widely used libraries: + +```rust +// GOOD +fn frobnicate(f: &Path) { +} + +// BAD +fn frobnicate(f: impl AsRef<Path>) { +} +``` + +**Rationale:** Rust uses monomorphization to compile generic code, meaning that for each instantiation of a generic functions with concrete types, the function is compiled afresh, *per crate*. +This allows for exceptionally good performance, but leads to increased compile times. +Runtime performance obeys 80%/20% rule -- only a small fraction of code is hot. +Compile time **does not** obey this rule -- all code has to be compiled. + +# Style + +## Order of Imports + +Separate import groups with blank lines. +Use one `use` per crate. + +Module declarations come before the imports. +Order them in "suggested reading order" for a person new to the code base. + +```rust +mod x; +mod y; + +// First std. +use std::{ ... } + +// Second, external crates (both crates.io crates and other rust-analyzer crates). +use crate_foo::{ ... } +use crate_bar::{ ... } + +// Then current crate. +use crate::{} + +// Finally, parent and child modules, but prefer `use crate::`. +use super::{} + +// Re-exports are treated as item definitions rather than imports, so they go +// after imports and modules. Use them sparingly. +pub use crate::x::Z; +``` + +**Rationale:** consistency. +Reading order is important for new contributors. +Grouping by crate allows spotting unwanted dependencies easier. + +## Import Style + +Qualify items from `hir` and `ast`. + +```rust +// GOOD +use syntax::ast; + +fn frobnicate(func: hir::Function, strukt: ast::Struct) {} + +// BAD +use hir::Function; +use syntax::ast::Struct; + +fn frobnicate(func: Function, strukt: Struct) {} +``` + +**Rationale:** avoids name clashes, makes the layer clear at a glance. + +When implementing traits from `std::fmt` or `std::ops`, import the module: + +```rust +// GOOD +use std::fmt; + +impl fmt::Display for RenameError { + fn fmt(&self, f: &mut fmt::Formatter<'_>) -> fmt::Result { .. } +} + +// BAD +impl std::fmt::Display for RenameError { + fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result { .. } +} + +// BAD +use std::ops::Deref; + +impl Deref for Widget { + type Target = str; + fn deref(&self) -> &str { .. } +} +``` + +**Rationale:** overall, less typing. +Makes it clear that a trait is implemented, rather than used. + +Avoid local `use MyEnum::*` imports. +**Rationale:** consistency. + +Prefer `use crate::foo::bar` to `use super::bar` or `use self::bar::baz`. +**Rationale:** consistency, this is the style which works in all cases. + +By default, avoid re-exports. +**Rationale:** for non-library code, re-exports introduce two ways to use something and allow for inconsistency. + +## Order of Items + +Optimize for the reader who sees the file for the first time, and wants to get a general idea about what's going on. +People read things from top to bottom, so place most important things first. + +Specifically, if all items except one are private, always put the non-private item on top. + +```rust +// GOOD +pub(crate) fn frobnicate() { + Helper::act() +} + +#[derive(Default)] +struct Helper { stuff: i32 } + +impl Helper { + fn act(&self) { + + } +} + +// BAD +#[derive(Default)] +struct Helper { stuff: i32 } + +pub(crate) fn frobnicate() { + Helper::act() +} + +impl Helper { + fn act(&self) { + + } +} +``` + +If there's a mixture of private and public items, put public items first. + +Put `struct`s and `enum`s first, functions and impls last. Order type declarations in top-down manner. + +```rust +// GOOD +struct Parent { + children: Vec<Child> +} + +struct Child; + +impl Parent { +} + +impl Child { +} + +// BAD +struct Child; + +impl Child { +} + +struct Parent { + children: Vec<Child> +} + +impl Parent { +} +``` + +**Rationale:** easier to get the sense of the API by visually scanning the file. +If function bodies are folded in the editor, the source code should read as documentation for the public API. + +## Context Parameters + +Some parameters are threaded unchanged through many function calls. +They determine the "context" of the operation. +Pass such parameters first, not last. +If there are several context parameters, consider packing them into a `struct Ctx` and passing it as `&self`. + +```rust +// GOOD +fn dfs(graph: &Graph, v: Vertex) -> usize { + let mut visited = FxHashSet::default(); + return go(graph, &mut visited, v); + + fn go(graph: &Graph, visited: &mut FxHashSet<Vertex>, v: usize) -> usize { + ... + } +} + +// BAD +fn dfs(v: Vertex, graph: &Graph) -> usize { + fn go(v: usize, graph: &Graph, visited: &mut FxHashSet<Vertex>) -> usize { + ... + } + + let mut visited = FxHashSet::default(); + go(v, graph, &mut visited) +} +``` + +**Rationale:** consistency. +Context-first works better when non-context parameter is a lambda. + +## Variable Naming + +Use boring and long names for local variables ([yay code completion](https://github.com/rust-lang/rust-analyzer/pull/4162#discussion_r417130973)). +The default name is a lowercased name of the type: `global_state: GlobalState`. +Avoid ad-hoc acronyms and contractions, but use the ones that exist consistently (`db`, `ctx`, `acc`). +Prefer American spelling (color, behavior). + +Default names: + +* `res` -- "result of the function" local variable +* `it` -- I don't really care about the name +* `n_foos` -- number of foos (prefer this to `foo_count`) +* `foo_idx` -- index of `foo` + +Many names in rust-analyzer conflict with keywords. +We use mangled names instead of `r#ident` syntax: + +``` +crate -> krate +enum -> enum_ +fn -> func +impl -> imp +macro -> mac +mod -> module +struct -> strukt +trait -> trait_ +type -> ty +``` + +**Rationale:** consistency. + +## Early Returns + +Do use early returns + +```rust +// GOOD +fn foo() -> Option<Bar> { + if !condition() { + return None; + } + + Some(...) +} + +// BAD +fn foo() -> Option<Bar> { + if condition() { + Some(...) + } else { + None + } +} +``` + +**Rationale:** reduce cognitive stack usage. + +Use `return Err(err)` to throw an error: + +```rust +// GOOD +fn f() -> Result<(), ()> { + if condition { + return Err(()); + } + Ok(()) +} + +// BAD +fn f() -> Result<(), ()> { + if condition { + Err(())?; + } + Ok(()) +} +``` + +**Rationale:** `return` has type `!`, which allows the compiler to flag dead +code (`Err(...)?` is of unconstrained generic type `T`). + +## Comparisons + +When doing multiple comparisons use `<`/`<=`, avoid `>`/`>=`. + +```rust +// GOOD +assert!(lo <= x && x <= hi); +assert!(r1 < l2 || r2 < l1); +assert!(x < y); +assert!(0 < x); + +// BAD +assert!(x >= lo && x <= hi); +assert!(r1 < l2 || l1 > r2); +assert!(y > x); +assert!(x > 0); +``` + +**Rationale:** Less-then comparisons are more intuitive, they correspond spatially to [real line](https://en.wikipedia.org/wiki/Real_line). + +## If-let + +Avoid `if let ... { } else { }` construct, use `match` instead. + +```rust +// GOOD +match ctx.expected_type.as_ref() { + Some(expected_type) => completion_ty == expected_type && !expected_type.is_unit(), + None => false, +} + +// BAD +if let Some(expected_type) = ctx.expected_type.as_ref() { + completion_ty == expected_type && !expected_type.is_unit() +} else { + false +} +``` + +**Rationale:** `match` is almost always more compact. +The `else` branch can get a more precise pattern: `None` or `Err(_)` instead of `_`. + +## Match Ergonomics + +Don't use the `ref` keyword. + +**Rationale:** consistency & simplicity. +`ref` was required before [match ergonomics](https://github.com/rust-lang/rfcs/blob/master/text/2005-match-ergonomics.md). +Today, it is redundant. +Between `ref` and mach ergonomics, the latter is more ergonomic in most cases, and is simpler (does not require a keyword). + +## Empty Match Arms + +Use `=> (),` when a match arm is intentionally empty: + +```rust +// GOOD +match result { + Ok(_) => (), + Err(err) => error!("{}", err), +} + +// BAD +match result { + Ok(_) => {} + Err(err) => error!("{}", err), +} +``` + +**Rationale:** consistency. + +## Functional Combinators + +Use high order monadic combinators like `map`, `then` when they are a natural choice; don't bend the code to fit into some combinator. +If writing a chain of combinators creates friction, replace them with control flow constructs: `for`, `if`, `match`. +Mostly avoid `bool::then` and `Option::filter`. + +```rust +// GOOD +if !x.cond() { + return None; +} +Some(x) + +// BAD +Some(x).filter(|it| it.cond()) +``` + +This rule is more "soft" then others, and boils down mostly to taste. +The guiding principle behind this rule is that code should be dense in computation, and sparse in the number of expressions per line. +The second example contains *less* computation -- the `filter` function is an indirection for `if`, it doesn't do any useful work by itself. +At the same time, it is more crowded -- it takes more time to visually scan it. + +**Rationale:** consistency, playing to language's strengths. +Rust has first-class support for imperative control flow constructs like `for` and `if`, while functions are less first-class due to lack of universal function type, currying, and non-first-class effects (`?`, `.await`). + +## Turbofish + +Prefer type ascription over the turbofish. +When ascribing types, avoid `_` + +```rust +// GOOD +let mutable: Vec<T> = old.into_iter().map(|it| builder.make_mut(it)).collect(); + +// BAD +let mutable: Vec<_> = old.into_iter().map(|it| builder.make_mut(it)).collect(); + +// BAD +let mutable = old.into_iter().map(|it| builder.make_mut(it)).collect::<Vec<_>>(); +``` + +**Rationale:** consistency, readability. +If compiler struggles to infer the type, the human would as well. +Having the result type specified up-front helps with understanding what the chain of iterator methods is doing. + +## Helper Functions + +Avoid creating single-use helper functions: + +```rust +// GOOD +let buf = { + let mut buf = get_empty_buf(&mut arena); + buf.add_item(item); + buf +}; + +// BAD +let buf = prepare_buf(&mut arena, item); + +... + +fn prepare_buf(arena: &mut Arena, item: Item) -> ItemBuf { + let mut res = get_empty_buf(&mut arena); + res.add_item(item); + res +} +``` + +Exception: if you want to make use of `return` or `?`. + +**Rationale:** single-use functions change frequently, adding or removing parameters adds churn. +A block serves just as well to delineate a bit of logic, but has access to all the context. +Re-using originally single-purpose function often leads to bad coupling. + +## Local Helper Functions + +Put nested helper functions at the end of the enclosing functions +(this requires using return statement). +Don't nest more than one level deep. + +```rust +// GOOD +fn dfs(graph: &Graph, v: Vertex) -> usize { + let mut visited = FxHashSet::default(); + return go(graph, &mut visited, v); + + fn go(graph: &Graph, visited: &mut FxHashSet<Vertex>, v: usize) -> usize { + ... + } +} + +// BAD +fn dfs(graph: &Graph, v: Vertex) -> usize { + fn go(graph: &Graph, visited: &mut FxHashSet<Vertex>, v: usize) -> usize { + ... + } + + let mut visited = FxHashSet::default(); + go(graph, &mut visited, v) +} +``` + +**Rationale:** consistency, improved top-down readability. + +## Helper Variables + +Introduce helper variables freely, especially for multiline conditions: + +```rust +// GOOD +let rustfmt_not_installed = + captured_stderr.contains("not installed") || captured_stderr.contains("not available"); + +match output.status.code() { + Some(1) if !rustfmt_not_installed => Ok(None), + _ => Err(format_err!("rustfmt failed:\n{}", captured_stderr)), +}; + +// BAD +match output.status.code() { + Some(1) + if !captured_stderr.contains("not installed") + && !captured_stderr.contains("not available") => Ok(None), + _ => Err(format_err!("rustfmt failed:\n{}", captured_stderr)), +}; +``` + +**Rationale:** Like blocks, single-use variables are a cognitively cheap abstraction, as they have access to all the context. +Extra variables help during debugging, they make it easy to print/view important intermediate results. +Giving a name to a condition inside an `if` expression often improves clarity and leads to nicely formatted code. + +## Token names + +Use `T![foo]` instead of `SyntaxKind::FOO_KW`. + +```rust +// GOOD +match p.current() { + T![true] | T![false] => true, + _ => false, +} + +// BAD + +match p.current() { + SyntaxKind::TRUE_KW | SyntaxKind::FALSE_KW => true, + _ => false, +} +``` + +**Rationale:** The macro uses the familiar Rust syntax, avoiding ambiguities like "is this a brace or bracket?". + +## Documentation + +Style inline code comments as proper sentences. +Start with a capital letter, end with a dot. + +```rust +// GOOD + +// Only simple single segment paths are allowed. +MergeBehavior::Last => { + tree.use_tree_list().is_none() && tree.path().map(path_len) <= Some(1) +} + +// BAD + +// only simple single segment paths are allowed +MergeBehavior::Last => { + tree.use_tree_list().is_none() && tree.path().map(path_len) <= Some(1) +} +``` + +**Rationale:** writing a sentence (or maybe even a paragraph) rather just "a comment" creates a more appropriate frame of mind. +It tricks you into writing down more of the context you keep in your head while coding. + +For `.md` and `.adoc` files, prefer a sentence-per-line format, don't wrap lines. +If the line is too long, you want to split the sentence in two :-) + +**Rationale:** much easier to edit the text and read the diff, see [this link](https://asciidoctor.org/docs/asciidoc-recommended-practices/#one-sentence-per-line). diff --git a/src/tools/rust-analyzer/docs/dev/syntax.md b/src/tools/rust-analyzer/docs/dev/syntax.md new file mode 100644 index 000000000..30e137013 --- /dev/null +++ b/src/tools/rust-analyzer/docs/dev/syntax.md @@ -0,0 +1,534 @@ +# Syntax in rust-analyzer + +## About the guide + +This guide describes the current state of syntax trees and parsing in rust-analyzer as of 2020-01-09 ([link to commit](https://github.com/rust-lang/rust-analyzer/tree/cf5bdf464cad7ceb9a67e07985a3f4d3799ec0b6)). + +## Source Code + +The things described are implemented in three places + +* [rowan](https://github.com/rust-analyzer/rowan/tree/v0.9.0) -- a generic library for rowan syntax trees. +* [ra_syntax](https://github.com/rust-lang/rust-analyzer/tree/cf5bdf464cad7ceb9a67e07985a3f4d3799ec0b6/crates/ra_syntax) crate inside rust-analyzer which wraps `rowan` into rust-analyzer specific API. + Nothing in rust-analyzer except this crate knows about `rowan`. +* [parser](https://github.com/rust-lang/rust-analyzer/tree/cf5bdf464cad7ceb9a67e07985a3f4d3799ec0b6/crates/parser) crate parses input tokens into an `ra_syntax` tree + +## Design Goals + +* Syntax trees are lossless, or full fidelity. All comments and whitespace get preserved. +* Syntax trees are semantic-less. They describe *strictly* the structure of a sequence of characters, they don't have hygiene, name resolution or type information attached. +* Syntax trees are simple value types. It is possible to create trees for a syntax without any external context. +* Syntax trees have intuitive traversal API (parent, children, siblings, etc). +* Parsing is lossless (even if the input is invalid, the tree produced by the parser represents it exactly). +* Parsing is resilient (even if the input is invalid, parser tries to see as much syntax tree fragments in the input as it can). +* Performance is important, it's OK to use `unsafe` if it means better memory/cpu usage. +* Keep the parser and the syntax tree isolated from each other, such that they can vary independently. + +## Trees + +### Overview + +The syntax tree consists of three layers: + +* GreenNodes +* SyntaxNodes (aka RedNode) +* AST + +Of these, only GreenNodes store the actual data, the other two layers are (non-trivial) views into green tree. +Red-green terminology comes from Roslyn ([link](https://ericlippert.com/2012/06/08/red-green-trees/)) and gives the name to the `rowan` library. Green and syntax nodes are defined in rowan, ast is defined in rust-analyzer. + +Syntax trees are a semi-transient data structure. +In general, frontend does not keep syntax trees for all files in memory. +Instead, it *lowers* syntax trees to more compact and rigid representation, which is not full-fidelity, but which can be mapped back to a syntax tree if so desired. + + +### GreenNode + +GreenNode is a purely-functional tree with arbitrary arity. Conceptually, it is equivalent to the following run of the mill struct: + +```rust +#[derive(PartialEq, Eq, Clone, Copy)] +struct SyntaxKind(u16); + +#[derive(PartialEq, Eq, Clone)] +struct Node { + kind: SyntaxKind, + text_len: usize, + children: Vec<Arc<Either<Node, Token>>>, +} + +#[derive(PartialEq, Eq, Clone)] +struct Token { + kind: SyntaxKind, + text: String, +} +``` + +All the difference between the above sketch and the real implementation are strictly due to optimizations. + +Points of note: +* The tree is untyped. Each node has a "type tag", `SyntaxKind`. +* Interior and leaf nodes are distinguished on the type level. +* Trivia and non-trivia tokens are not distinguished on the type level. +* Each token carries its full text. +* The original text can be recovered by concatenating the texts of all tokens in order. +* Accessing a child of particular type (for example, parameter list of a function) generally involves linearly traversing the children, looking for a specific `kind`. +* Modifying the tree is roughly `O(depth)`. + We don't make special efforts to guarantee that the depth is not linear, but, in practice, syntax trees are branchy and shallow. +* If mandatory (grammar wise) node is missing from the input, it's just missing from the tree. +* If an extra erroneous input is present, it is wrapped into a node with `ERROR` kind, and treated just like any other node. +* Parser errors are not a part of syntax tree. + +An input like `fn f() { 90 + 2 }` might be parsed as + +``` +FN@0..17 + FN_KW@0..2 "fn" + WHITESPACE@2..3 " " + NAME@3..4 + IDENT@3..4 "f" + PARAM_LIST@4..6 + L_PAREN@4..5 "(" + R_PAREN@5..6 ")" + WHITESPACE@6..7 " " + BLOCK_EXPR@7..17 + L_CURLY@7..8 "{" + WHITESPACE@8..9 " " + BIN_EXPR@9..15 + LITERAL@9..11 + INT_NUMBER@9..11 "90" + WHITESPACE@11..12 " " + PLUS@12..13 "+" + WHITESPACE@13..14 " " + LITERAL@14..15 + INT_NUMBER@14..15 "2" + WHITESPACE@15..16 " " + R_CURLY@16..17 "}" +``` + +#### Optimizations + +(significant amount of implementation work here was done by [CAD97](https://github.com/cad97)). + +To reduce the amount of allocations, the GreenNode is a [DST](https://doc.rust-lang.org/reference/dynamically-sized-types.html), which uses a single allocation for header and children. Thus, it is only usable behind a pointer. + +``` +*-----------+------+----------+------------+--------+--------+-----+--------* +| ref_count | kind | text_len | n_children | child1 | child2 | ... | childn | +*-----------+------+----------+------------+--------+--------+-----+--------* +``` + +To more compactly store the children, we box *both* interior nodes and tokens, and represent +`Either<Arc<Node>, Arc<Token>>` as a single pointer with a tag in the last bit. + +To avoid allocating EVERY SINGLE TOKEN on the heap, syntax trees use interning. +Because the tree is fully immutable, it's valid to structurally share subtrees. +For example, in `1 + 1`, there will be a *single* token for `1` with ref count 2; the same goes for the ` ` whitespace token. +Interior nodes are shared as well (for example in `(1 + 1) * (1 + 1)`). + +Note that, the result of the interning is an `Arc<Node>`. +That is, it's not an index into interning table, so you don't have to have the table around to do anything with the tree. +Each tree is fully self-contained (although different trees might share parts). +Currently, the interner is created per-file, but it will be easy to use a per-thread or per-some-contex one. + +We use a `TextSize`, a newtyped `u32`, to store the length of the text. + +We currently use `SmolStr`, a small object optimized string to store text. +This was mostly relevant *before* we implemented tree interning, to avoid allocating common keywords and identifiers. We should switch to storing text data alongside the interned tokens. + +#### Alternative designs + +##### Dealing with trivia + +In the above model, whitespace is not treated specially. +Another alternative (used by swift and roslyn) is to explicitly divide the set of tokens into trivia and non-trivia tokens, and represent non-trivia tokens as + +```rust +struct Token { + kind: NonTriviaTokenKind, + text: String, + leading_trivia: Vec<TriviaToken>, + trailing_trivia: Vec<TriviaToken>, +} +``` + +The tree then contains only non-trivia tokens. + +Another approach (from Dart) is to, in addition to a syntax tree, link all the tokens into a bidirectional link list. +That way, the tree again contains only non-trivia tokens. + +Explicit trivia nodes, like in `rowan`, are used by IntelliJ. + +##### Accessing Children + +As noted before, accessing a specific child in the node requires a linear traversal of the children (though we can skip tokens, because the tag is encoded in the pointer itself). +It is possible to recover O(1) access with another representation. +We explicitly store optional and missing (required by the grammar, but not present) nodes. +That is, we use `Option<Node>` for children. +We also remove trivia tokens from the tree. +This way, each child kind generally occupies a fixed position in a parent, and we can use index access to fetch it. +The cost is that we now need to allocate space for all not-present optional nodes. +So, `fn foo() {}` will have slots for visibility, unsafeness, attributes, abi and return type. + +IntelliJ uses linear traversal. +Roslyn and Swift do `O(1)` access. + +##### Mutable Trees + +IntelliJ uses mutable trees. +Overall, it creates a lot of additional complexity. +However, the API for *editing* syntax trees is nice. + +For example the assist to move generic bounds to where clause has this code: + +```kotlin + for typeBound in typeBounds { + typeBound.typeParamBounds?.delete() +} +``` + +Modeling this with immutable trees is possible, but annoying. + +### Syntax Nodes + +A function green tree is not super-convenient to use. +The biggest problem is accessing parents (there are no parent pointers!). +But there are also "identify" issues. +Let's say you want to write a code which builds a list of expressions in a file: `fn collect_expressions(file: GreenNode) -> HashSet<GreenNode>`. +For the input like + +```rust +fn main() { + let x = 90i8; + let x = x + 2; + let x = 90i64; + let x = x + 2; +} +``` + +both copies of the `x + 2` expression are representing by equal (and, with interning in mind, actually the same) green nodes. +Green trees just can't differentiate between the two. + +`SyntaxNode` adds parent pointers and identify semantics to green nodes. +They can be called cursors or [zippers](https://en.wikipedia.org/wiki/Zipper_(data_structure)) (fun fact: zipper is a derivative (as in ′) of a data structure). + +Conceptually, a `SyntaxNode` looks like this: + +```rust +type SyntaxNode = Arc<SyntaxData>; + +struct SyntaxData { + offset: usize, + parent: Option<SyntaxNode>, + green: Arc<GreenNode>, +} + +impl SyntaxNode { + fn new_root(root: Arc<GreenNode>) -> SyntaxNode { + Arc::new(SyntaxData { + offset: 0, + parent: None, + green: root, + }) + } + fn parent(&self) -> Option<SyntaxNode> { + self.parent.clone() + } + fn children(&self) -> impl Iterator<Item = SyntaxNode> { + let mut offset = self.offset; + self.green.children().map(|green_child| { + let child_offset = offset; + offset += green_child.text_len; + Arc::new(SyntaxData { + offset: child_offset, + parent: Some(Arc::clone(self)), + green: Arc::clone(green_child), + }) + }) + } +} + +impl PartialEq for SyntaxNode { + fn eq(&self, other: &SyntaxNode) -> bool { + self.offset == other.offset + && Arc::ptr_eq(&self.green, &other.green) + } +} +``` + +Points of note: + +* SyntaxNode remembers its parent node (and, transitively, the path to the root of the tree) +* SyntaxNode knows its *absolute* text offset in the whole file +* Equality is based on identity. Comparing nodes from different trees does not make sense. + +#### Optimization + +The reality is different though :-) +Traversal of trees is a common operation, and it makes sense to optimize it. +In particular, the above code allocates and does atomic operations during a traversal. + +To get rid of atomics, `rowan` uses non thread-safe `Rc`. +This is OK because trees traversals mostly (always, in case of rust-analyzer) run on a single thread. If you need to send a `SyntaxNode` to another thread, you can send a pair of **root**`GreenNode` (which is thread safe) and a `Range<usize>`. +The other thread can restore the `SyntaxNode` by traversing from the root green node and looking for a node with specified range. +You can also use the similar trick to store a `SyntaxNode`. +That is, a data structure that holds a `(GreenNode, Range<usize>)` will be `Sync`. +However, rust-analyzer goes even further. +It treats trees as semi-transient and instead of storing a `GreenNode`, it generally stores just the id of the file from which the tree originated: `(FileId, Range<usize>)`. +The `SyntaxNode` is the restored by reparsing the file and traversing it from root. +With this trick, rust-analyzer holds only a small amount of trees in memory at the same time, which reduces memory usage. + +Additionally, only the root `SyntaxNode` owns an `Arc` to the (root) `GreenNode`. +All other `SyntaxNode`s point to corresponding `GreenNode`s with a raw pointer. +They also point to the parent (and, consequently, to the root) with an owning `Rc`, so this is sound. +In other words, one needs *one* arc bump when initiating a traversal. + +To get rid of allocations, `rowan` takes advantage of `SyntaxNode: !Sync` and uses a thread-local free list of `SyntaxNode`s. +In a typical traversal, you only directly hold a few `SyntaxNode`s at a time (and their ancestors indirectly), so a free list proportional to the depth of the tree removes all allocations in a typical case. + +So, while traversal is not exactly incrementing a pointer, it's still pretty cheap: TLS + rc bump! + +Traversal also yields (cheap) owned nodes, which improves ergonomics quite a bit. + +#### Alternative Designs + +##### Memoized RedNodes + +C# and Swift follow the design where the red nodes are memoized, which would look roughly like this in Rust: + +```rust +type SyntaxNode = Arc<SyntaxData>; + +struct SyntaxData { + offset: usize, + parent: Option<SyntaxNode>, + green: Arc<GreenNode>, + children: Vec<OnceCell<SyntaxNode>>, +} +``` + +This allows using true pointer equality for comparison of identities of `SyntaxNodes`. +rust-analyzer used to have this design as well, but we've since switched to cursors. +The main problem with memoizing the red nodes is that it more than doubles the memory requirements for fully realized syntax trees. +In contrast, cursors generally retain only a path to the root. +C# combats increased memory usage by using weak references. + +### AST + +`GreenTree`s are untyped and homogeneous, because it makes accommodating error nodes, arbitrary whitespace and comments natural, and because it makes possible to write generic tree traversals. +However, when working with a specific node, like a function definition, one would want a strongly typed API. + +This is what is provided by the AST layer. AST nodes are transparent wrappers over untyped syntax nodes: + +```rust +pub trait AstNode { + fn cast(syntax: SyntaxNode) -> Option<Self> + where + Self: Sized; + + fn syntax(&self) -> &SyntaxNode; +} +``` + +Concrete nodes are generated (there are 117 of them), and look roughly like this: + +```rust +#[derive(Debug, Clone, PartialEq, Eq, Hash)] +pub struct FnDef { + syntax: SyntaxNode, +} + +impl AstNode for FnDef { + fn cast(syntax: SyntaxNode) -> Option<Self> { + match kind { + FN => Some(FnDef { syntax }), + _ => None, + } + } + fn syntax(&self) -> &SyntaxNode { + &self.syntax + } +} + +impl FnDef { + pub fn param_list(&self) -> Option<ParamList> { + self.syntax.children().find_map(ParamList::cast) + } + pub fn ret_type(&self) -> Option<RetType> { + self.syntax.children().find_map(RetType::cast) + } + pub fn body(&self) -> Option<BlockExpr> { + self.syntax.children().find_map(BlockExpr::cast) + } + // ... +} +``` + +Variants like expressions, patterns or items are modeled with `enum`s, which also implement `AstNode`: + +```rust +#[derive(Debug, Clone, PartialEq, Eq, Hash)] +pub enum AssocItem { + FnDef(FnDef), + TypeAliasDef(TypeAliasDef), + ConstDef(ConstDef), +} + +impl AstNode for AssocItem { + ... +} +``` + +Shared AST substructures are modeled via (object safe) traits: + +```rust +trait HasVisibility: AstNode { + fn visibility(&self) -> Option<Visibility>; +} + +impl HasVisibility for FnDef { + fn visibility(&self) -> Option<Visibility> { + self.syntax.children().find_map(Visibility::cast) + } +} +``` + +Points of note: + +* Like `SyntaxNode`s, AST nodes are cheap to clone pointer-sized owned values. +* All "fields" are optional, to accommodate incomplete and/or erroneous source code. +* It's always possible to go from an ast node to an untyped `SyntaxNode`. +* It's possible to go in the opposite direction with a checked cast. +* `enum`s allow modeling of arbitrary intersecting subsets of AST types. +* Most of rust-analyzer works with the ast layer, with notable exceptions of: + * macro expansion, which needs access to raw tokens and works with `SyntaxNode`s + * some IDE-specific features like syntax highlighting are more conveniently implemented over a homogeneous `SyntaxNode` tree + +#### Alternative Designs + +##### Semantic Full AST + +In IntelliJ the AST layer (dubbed **P**rogram **S**tructure **I**nterface) can have semantics attached, and is usually backed by either syntax tree, indices, or metadata from compiled libraries. +The backend for PSI can change dynamically. + +### Syntax Tree Recap + +At its core, the syntax tree is a purely functional n-ary tree, which stores text at the leaf nodes and node "kinds" at all nodes. +A cursor layer is added on top, which gives owned, cheap to clone nodes with identity semantics, parent links and absolute offsets. +An AST layer is added on top, which reifies each node `Kind` as a separate Rust type with the corresponding API. + +## Parsing + +The (green) tree is constructed by a DFS "traversal" of the desired tree structure: + +```rust +pub struct GreenNodeBuilder { ... } + +impl GreenNodeBuilder { + pub fn new() -> GreenNodeBuilder { ... } + + pub fn token(&mut self, kind: SyntaxKind, text: &str) { ... } + + pub fn start_node(&mut self, kind: SyntaxKind) { ... } + pub fn finish_node(&mut self) { ... } + + pub fn finish(self) -> GreenNode { ... } +} +``` + +The parser, ultimately, needs to invoke the `GreenNodeBuilder`. +There are two principal sources of inputs for the parser: + * source text, which contains trivia tokens (whitespace and comments) + * token trees from macros, which lack trivia + +Additionally, input tokens do not correspond 1-to-1 with output tokens. +For example, two consecutive `>` tokens might be glued, by the parser, into a single `>>`. + +For these reasons, the parser crate defines a callback interfaces for both input tokens and output trees. +The explicit glue layer then bridges various gaps. + +The parser interface looks like this: + +```rust +pub struct Token { + pub kind: SyntaxKind, + pub is_joined_to_next: bool, +} + +pub trait TokenSource { + fn current(&self) -> Token; + fn lookahead_nth(&self, n: usize) -> Token; + fn is_keyword(&self, kw: &str) -> bool; + + fn bump(&mut self); +} + +pub trait TreeSink { + fn token(&mut self, kind: SyntaxKind, n_tokens: u8); + + fn start_node(&mut self, kind: SyntaxKind); + fn finish_node(&mut self); + + fn error(&mut self, error: ParseError); +} + +pub fn parse( + token_source: &mut dyn TokenSource, + tree_sink: &mut dyn TreeSink, +) { ... } +``` + +Points of note: + +* The parser and the syntax tree are independent, they live in different crates neither of which depends on the other. +* The parser doesn't know anything about textual contents of the tokens, with an isolated hack for checking contextual keywords. +* For gluing tokens, the `TreeSink::token` might advance further than one atomic token ahead. + +### Reporting Syntax Errors + +Syntax errors are not stored directly in the tree. +The primary motivation for this is that syntax tree is not necessary produced by the parser, it may also be assembled manually from pieces (which happens all the time in refactorings). +Instead, parser reports errors to an error sink, which stores them in a `Vec`. +If possible, errors are not reported during parsing and are postponed for a separate validation step. +For example, parser accepts visibility modifiers on trait methods, but then a separate tree traversal flags all such visibilities as erroneous. + +### Macros + +The primary difficulty with macros is that individual tokens have identities, which need to be preserved in the syntax tree for hygiene purposes. +This is handled by the `TreeSink` layer. +Specifically, `TreeSink` constructs the tree in lockstep with draining the original token stream. +In the process, it records which tokens of the tree correspond to which tokens of the input, by using text ranges to identify syntax tokens. +The end result is that parsing an expanded code yields a syntax tree and a mapping of text-ranges of the tree to original tokens. + +To deal with precedence in cases like `$expr * 1`, we use special invisible parenthesis, which are explicitly handled by the parser + +### Whitespace & Comments + +Parser does not see whitespace nodes. +Instead, they are attached to the tree in the `TreeSink` layer. + +For example, in + +```rust +// non doc comment +fn foo() {} +``` + +the comment will be (heuristically) made a child of function node. + +### Incremental Reparse + +Green trees are cheap to modify, so incremental reparse works by patching a previous tree, without maintaining any additional state. +The reparse is based on heuristic: we try to contain a change to a single `{}` block, and reparse only this block. +To do this, we maintain the invariant that, even for invalid code, curly braces are always paired correctly. + +In practice, incremental reparsing doesn't actually matter much for IDE use-cases, parsing from scratch seems to be fast enough. + +### Parsing Algorithm + +We use a boring hand-crafted recursive descent + pratt combination, with a special effort of continuing the parsing if an error is detected. + +### Parser Recap + +Parser itself defines traits for token sequence input and syntax tree output. +It doesn't care about where the tokens come from, and how the resulting syntax tree looks like. diff --git a/src/tools/rust-analyzer/docs/user/generated_config.adoc b/src/tools/rust-analyzer/docs/user/generated_config.adoc new file mode 100644 index 000000000..b0f2f1614 --- /dev/null +++ b/src/tools/rust-analyzer/docs/user/generated_config.adoc @@ -0,0 +1,620 @@ +[[rust-analyzer.assist.expressionFillDefault]]rust-analyzer.assist.expressionFillDefault (default: `"todo"`):: ++ +-- +Placeholder expression to use for missing expressions in assists. +-- +[[rust-analyzer.cachePriming.enable]]rust-analyzer.cachePriming.enable (default: `true`):: ++ +-- +Warm up caches on project load. +-- +[[rust-analyzer.cachePriming.numThreads]]rust-analyzer.cachePriming.numThreads (default: `0`):: ++ +-- +How many worker threads to handle priming caches. The default `0` means to pick automatically. +-- +[[rust-analyzer.cargo.autoreload]]rust-analyzer.cargo.autoreload (default: `true`):: ++ +-- +Automatically refresh project info via `cargo metadata` on +`Cargo.toml` or `.cargo/config.toml` changes. +-- +[[rust-analyzer.cargo.buildScripts.enable]]rust-analyzer.cargo.buildScripts.enable (default: `true`):: ++ +-- +Run build scripts (`build.rs`) for more precise code analysis. +-- +[[rust-analyzer.cargo.buildScripts.overrideCommand]]rust-analyzer.cargo.buildScripts.overrideCommand (default: `null`):: ++ +-- +Override the command rust-analyzer uses to run build scripts and +build procedural macros. The command is required to output json +and should therefore include `--message-format=json` or a similar +option. + +By default, a cargo invocation will be constructed for the configured +targets and features, with the following base command line: + +```bash +cargo check --quiet --workspace --message-format=json --all-targets +``` +. +-- +[[rust-analyzer.cargo.buildScripts.useRustcWrapper]]rust-analyzer.cargo.buildScripts.useRustcWrapper (default: `true`):: ++ +-- +Use `RUSTC_WRAPPER=rust-analyzer` when running build scripts to +avoid checking unnecessary things. +-- +[[rust-analyzer.cargo.features]]rust-analyzer.cargo.features (default: `[]`):: ++ +-- +List of features to activate. + +Set this to `"all"` to pass `--all-features` to cargo. +-- +[[rust-analyzer.cargo.noDefaultFeatures]]rust-analyzer.cargo.noDefaultFeatures (default: `false`):: ++ +-- +Whether to pass `--no-default-features` to cargo. +-- +[[rust-analyzer.cargo.noSysroot]]rust-analyzer.cargo.noSysroot (default: `false`):: ++ +-- +Internal config for debugging, disables loading of sysroot crates. +-- +[[rust-analyzer.cargo.target]]rust-analyzer.cargo.target (default: `null`):: ++ +-- +Compilation target override (target triple). +-- +[[rust-analyzer.cargo.unsetTest]]rust-analyzer.cargo.unsetTest (default: `["core"]`):: ++ +-- +Unsets `#[cfg(test)]` for the specified crates. +-- +[[rust-analyzer.checkOnSave.allTargets]]rust-analyzer.checkOnSave.allTargets (default: `true`):: ++ +-- +Check all targets and tests (`--all-targets`). +-- +[[rust-analyzer.checkOnSave.command]]rust-analyzer.checkOnSave.command (default: `"check"`):: ++ +-- +Cargo command to use for `cargo check`. +-- +[[rust-analyzer.checkOnSave.enable]]rust-analyzer.checkOnSave.enable (default: `true`):: ++ +-- +Run specified `cargo check` command for diagnostics on save. +-- +[[rust-analyzer.checkOnSave.extraArgs]]rust-analyzer.checkOnSave.extraArgs (default: `[]`):: ++ +-- +Extra arguments for `cargo check`. +-- +[[rust-analyzer.checkOnSave.features]]rust-analyzer.checkOnSave.features (default: `null`):: ++ +-- +List of features to activate. Defaults to +`#rust-analyzer.cargo.features#`. + +Set to `"all"` to pass `--all-features` to Cargo. +-- +[[rust-analyzer.checkOnSave.noDefaultFeatures]]rust-analyzer.checkOnSave.noDefaultFeatures (default: `null`):: ++ +-- +Whether to pass `--no-default-features` to Cargo. Defaults to +`#rust-analyzer.cargo.noDefaultFeatures#`. +-- +[[rust-analyzer.checkOnSave.overrideCommand]]rust-analyzer.checkOnSave.overrideCommand (default: `null`):: ++ +-- +Override the command rust-analyzer uses instead of `cargo check` for +diagnostics on save. The command is required to output json and +should therefor include `--message-format=json` or a similar option. + +If you're changing this because you're using some tool wrapping +Cargo, you might also want to change +`#rust-analyzer.cargo.buildScripts.overrideCommand#`. + +An example command would be: + +```bash +cargo check --workspace --message-format=json --all-targets +``` +. +-- +[[rust-analyzer.checkOnSave.target]]rust-analyzer.checkOnSave.target (default: `null`):: ++ +-- +Check for a specific target. Defaults to +`#rust-analyzer.cargo.target#`. +-- +[[rust-analyzer.completion.autoimport.enable]]rust-analyzer.completion.autoimport.enable (default: `true`):: ++ +-- +Toggles the additional completions that automatically add imports when completed. +Note that your client must specify the `additionalTextEdits` LSP client capability to truly have this feature enabled. +-- +[[rust-analyzer.completion.autoself.enable]]rust-analyzer.completion.autoself.enable (default: `true`):: ++ +-- +Toggles the additional completions that automatically show method calls and field accesses +with `self` prefixed to them when inside a method. +-- +[[rust-analyzer.completion.callable.snippets]]rust-analyzer.completion.callable.snippets (default: `"fill_arguments"`):: ++ +-- +Whether to add parenthesis and argument snippets when completing function. +-- +[[rust-analyzer.completion.postfix.enable]]rust-analyzer.completion.postfix.enable (default: `true`):: ++ +-- +Whether to show postfix snippets like `dbg`, `if`, `not`, etc. +-- +[[rust-analyzer.completion.privateEditable.enable]]rust-analyzer.completion.privateEditable.enable (default: `false`):: ++ +-- +Enables completions of private items and fields that are defined in the current workspace even if they are not visible at the current position. +-- +[[rust-analyzer.completion.snippets.custom]]rust-analyzer.completion.snippets.custom:: ++ +-- +Default: +---- +{ + "Arc::new": { + "postfix": "arc", + "body": "Arc::new(${receiver})", + "requires": "std::sync::Arc", + "description": "Put the expression into an `Arc`", + "scope": "expr" + }, + "Rc::new": { + "postfix": "rc", + "body": "Rc::new(${receiver})", + "requires": "std::rc::Rc", + "description": "Put the expression into an `Rc`", + "scope": "expr" + }, + "Box::pin": { + "postfix": "pinbox", + "body": "Box::pin(${receiver})", + "requires": "std::boxed::Box", + "description": "Put the expression into a pinned `Box`", + "scope": "expr" + }, + "Ok": { + "postfix": "ok", + "body": "Ok(${receiver})", + "description": "Wrap the expression in a `Result::Ok`", + "scope": "expr" + }, + "Err": { + "postfix": "err", + "body": "Err(${receiver})", + "description": "Wrap the expression in a `Result::Err`", + "scope": "expr" + }, + "Some": { + "postfix": "some", + "body": "Some(${receiver})", + "description": "Wrap the expression in an `Option::Some`", + "scope": "expr" + } + } +---- +Custom completion snippets. + +-- +[[rust-analyzer.diagnostics.disabled]]rust-analyzer.diagnostics.disabled (default: `[]`):: ++ +-- +List of rust-analyzer diagnostics to disable. +-- +[[rust-analyzer.diagnostics.enable]]rust-analyzer.diagnostics.enable (default: `true`):: ++ +-- +Whether to show native rust-analyzer diagnostics. +-- +[[rust-analyzer.diagnostics.experimental.enable]]rust-analyzer.diagnostics.experimental.enable (default: `false`):: ++ +-- +Whether to show experimental rust-analyzer diagnostics that might +have more false positives than usual. +-- +[[rust-analyzer.diagnostics.remapPrefix]]rust-analyzer.diagnostics.remapPrefix (default: `{}`):: ++ +-- +Map of prefixes to be substituted when parsing diagnostic file paths. +This should be the reverse mapping of what is passed to `rustc` as `--remap-path-prefix`. +-- +[[rust-analyzer.diagnostics.warningsAsHint]]rust-analyzer.diagnostics.warningsAsHint (default: `[]`):: ++ +-- +List of warnings that should be displayed with hint severity. + +The warnings will be indicated by faded text or three dots in code +and will not show up in the `Problems Panel`. +-- +[[rust-analyzer.diagnostics.warningsAsInfo]]rust-analyzer.diagnostics.warningsAsInfo (default: `[]`):: ++ +-- +List of warnings that should be displayed with info severity. + +The warnings will be indicated by a blue squiggly underline in code +and a blue icon in the `Problems Panel`. +-- +[[rust-analyzer.files.excludeDirs]]rust-analyzer.files.excludeDirs (default: `[]`):: ++ +-- +These directories will be ignored by rust-analyzer. They are +relative to the workspace root, and globs are not supported. You may +also need to add the folders to Code's `files.watcherExclude`. +-- +[[rust-analyzer.files.watcher]]rust-analyzer.files.watcher (default: `"client"`):: ++ +-- +Controls file watching implementation. +-- +[[rust-analyzer.highlightRelated.breakPoints.enable]]rust-analyzer.highlightRelated.breakPoints.enable (default: `true`):: ++ +-- +Enables highlighting of related references while the cursor is on `break`, `loop`, `while`, or `for` keywords. +-- +[[rust-analyzer.highlightRelated.exitPoints.enable]]rust-analyzer.highlightRelated.exitPoints.enable (default: `true`):: ++ +-- +Enables highlighting of all exit points while the cursor is on any `return`, `?`, `fn`, or return type arrow (`->`). +-- +[[rust-analyzer.highlightRelated.references.enable]]rust-analyzer.highlightRelated.references.enable (default: `true`):: ++ +-- +Enables highlighting of related references while the cursor is on any identifier. +-- +[[rust-analyzer.highlightRelated.yieldPoints.enable]]rust-analyzer.highlightRelated.yieldPoints.enable (default: `true`):: ++ +-- +Enables highlighting of all break points for a loop or block context while the cursor is on any `async` or `await` keywords. +-- +[[rust-analyzer.hover.actions.debug.enable]]rust-analyzer.hover.actions.debug.enable (default: `true`):: ++ +-- +Whether to show `Debug` action. Only applies when +`#rust-analyzer.hover.actions.enable#` is set. +-- +[[rust-analyzer.hover.actions.enable]]rust-analyzer.hover.actions.enable (default: `true`):: ++ +-- +Whether to show HoverActions in Rust files. +-- +[[rust-analyzer.hover.actions.gotoTypeDef.enable]]rust-analyzer.hover.actions.gotoTypeDef.enable (default: `true`):: ++ +-- +Whether to show `Go to Type Definition` action. Only applies when +`#rust-analyzer.hover.actions.enable#` is set. +-- +[[rust-analyzer.hover.actions.implementations.enable]]rust-analyzer.hover.actions.implementations.enable (default: `true`):: ++ +-- +Whether to show `Implementations` action. Only applies when +`#rust-analyzer.hover.actions.enable#` is set. +-- +[[rust-analyzer.hover.actions.references.enable]]rust-analyzer.hover.actions.references.enable (default: `false`):: ++ +-- +Whether to show `References` action. Only applies when +`#rust-analyzer.hover.actions.enable#` is set. +-- +[[rust-analyzer.hover.actions.run.enable]]rust-analyzer.hover.actions.run.enable (default: `true`):: ++ +-- +Whether to show `Run` action. Only applies when +`#rust-analyzer.hover.actions.enable#` is set. +-- +[[rust-analyzer.hover.documentation.enable]]rust-analyzer.hover.documentation.enable (default: `true`):: ++ +-- +Whether to show documentation on hover. +-- +[[rust-analyzer.hover.links.enable]]rust-analyzer.hover.links.enable (default: `true`):: ++ +-- +Use markdown syntax for links in hover. +-- +[[rust-analyzer.imports.granularity.enforce]]rust-analyzer.imports.granularity.enforce (default: `false`):: ++ +-- +Whether to enforce the import granularity setting for all files. If set to false rust-analyzer will try to keep import styles consistent per file. +-- +[[rust-analyzer.imports.granularity.group]]rust-analyzer.imports.granularity.group (default: `"crate"`):: ++ +-- +How imports should be grouped into use statements. +-- +[[rust-analyzer.imports.group.enable]]rust-analyzer.imports.group.enable (default: `true`):: ++ +-- +Group inserted imports by the https://rust-analyzer.github.io/manual.html#auto-import[following order]. Groups are separated by newlines. +-- +[[rust-analyzer.imports.merge.glob]]rust-analyzer.imports.merge.glob (default: `true`):: ++ +-- +Whether to allow import insertion to merge new imports into single path glob imports like `use std::fmt::*;`. +-- +[[rust-analyzer.imports.prefix]]rust-analyzer.imports.prefix (default: `"plain"`):: ++ +-- +The path structure for newly inserted paths to use. +-- +[[rust-analyzer.inlayHints.bindingModeHints.enable]]rust-analyzer.inlayHints.bindingModeHints.enable (default: `false`):: ++ +-- +Whether to show inlay type hints for binding modes. +-- +[[rust-analyzer.inlayHints.chainingHints.enable]]rust-analyzer.inlayHints.chainingHints.enable (default: `true`):: ++ +-- +Whether to show inlay type hints for method chains. +-- +[[rust-analyzer.inlayHints.closingBraceHints.enable]]rust-analyzer.inlayHints.closingBraceHints.enable (default: `true`):: ++ +-- +Whether to show inlay hints after a closing `}` to indicate what item it belongs to. +-- +[[rust-analyzer.inlayHints.closingBraceHints.minLines]]rust-analyzer.inlayHints.closingBraceHints.minLines (default: `25`):: ++ +-- +Minimum number of lines required before the `}` until the hint is shown (set to 0 or 1 +to always show them). +-- +[[rust-analyzer.inlayHints.closureReturnTypeHints.enable]]rust-analyzer.inlayHints.closureReturnTypeHints.enable (default: `"never"`):: ++ +-- +Whether to show inlay type hints for return types of closures. +-- +[[rust-analyzer.inlayHints.lifetimeElisionHints.enable]]rust-analyzer.inlayHints.lifetimeElisionHints.enable (default: `"never"`):: ++ +-- +Whether to show inlay type hints for elided lifetimes in function signatures. +-- +[[rust-analyzer.inlayHints.lifetimeElisionHints.useParameterNames]]rust-analyzer.inlayHints.lifetimeElisionHints.useParameterNames (default: `false`):: ++ +-- +Whether to prefer using parameter names as the name for elided lifetime hints if possible. +-- +[[rust-analyzer.inlayHints.maxLength]]rust-analyzer.inlayHints.maxLength (default: `25`):: ++ +-- +Maximum length for inlay hints. Set to null to have an unlimited length. +-- +[[rust-analyzer.inlayHints.parameterHints.enable]]rust-analyzer.inlayHints.parameterHints.enable (default: `true`):: ++ +-- +Whether to show function parameter name inlay hints at the call +site. +-- +[[rust-analyzer.inlayHints.reborrowHints.enable]]rust-analyzer.inlayHints.reborrowHints.enable (default: `"never"`):: ++ +-- +Whether to show inlay type hints for compiler inserted reborrows. +-- +[[rust-analyzer.inlayHints.renderColons]]rust-analyzer.inlayHints.renderColons (default: `true`):: ++ +-- +Whether to render leading colons for type hints, and trailing colons for parameter hints. +-- +[[rust-analyzer.inlayHints.typeHints.enable]]rust-analyzer.inlayHints.typeHints.enable (default: `true`):: ++ +-- +Whether to show inlay type hints for variables. +-- +[[rust-analyzer.inlayHints.typeHints.hideClosureInitialization]]rust-analyzer.inlayHints.typeHints.hideClosureInitialization (default: `false`):: ++ +-- +Whether to hide inlay type hints for `let` statements that initialize to a closure. +Only applies to closures with blocks, same as `#rust-analyzer.inlayHints.closureReturnTypeHints.enable#`. +-- +[[rust-analyzer.inlayHints.typeHints.hideNamedConstructor]]rust-analyzer.inlayHints.typeHints.hideNamedConstructor (default: `false`):: ++ +-- +Whether to hide inlay type hints for constructors. +-- +[[rust-analyzer.joinLines.joinAssignments]]rust-analyzer.joinLines.joinAssignments (default: `true`):: ++ +-- +Join lines merges consecutive declaration and initialization of an assignment. +-- +[[rust-analyzer.joinLines.joinElseIf]]rust-analyzer.joinLines.joinElseIf (default: `true`):: ++ +-- +Join lines inserts else between consecutive ifs. +-- +[[rust-analyzer.joinLines.removeTrailingComma]]rust-analyzer.joinLines.removeTrailingComma (default: `true`):: ++ +-- +Join lines removes trailing commas. +-- +[[rust-analyzer.joinLines.unwrapTrivialBlock]]rust-analyzer.joinLines.unwrapTrivialBlock (default: `true`):: ++ +-- +Join lines unwraps trivial blocks. +-- +[[rust-analyzer.lens.debug.enable]]rust-analyzer.lens.debug.enable (default: `true`):: ++ +-- +Whether to show `Debug` lens. Only applies when +`#rust-analyzer.lens.enable#` is set. +-- +[[rust-analyzer.lens.enable]]rust-analyzer.lens.enable (default: `true`):: ++ +-- +Whether to show CodeLens in Rust files. +-- +[[rust-analyzer.lens.forceCustomCommands]]rust-analyzer.lens.forceCustomCommands (default: `true`):: ++ +-- +Internal config: use custom client-side commands even when the +client doesn't set the corresponding capability. +-- +[[rust-analyzer.lens.implementations.enable]]rust-analyzer.lens.implementations.enable (default: `true`):: ++ +-- +Whether to show `Implementations` lens. Only applies when +`#rust-analyzer.lens.enable#` is set. +-- +[[rust-analyzer.lens.references.adt.enable]]rust-analyzer.lens.references.adt.enable (default: `false`):: ++ +-- +Whether to show `References` lens for Struct, Enum, and Union. +Only applies when `#rust-analyzer.lens.enable#` is set. +-- +[[rust-analyzer.lens.references.enumVariant.enable]]rust-analyzer.lens.references.enumVariant.enable (default: `false`):: ++ +-- +Whether to show `References` lens for Enum Variants. +Only applies when `#rust-analyzer.lens.enable#` is set. +-- +[[rust-analyzer.lens.references.method.enable]]rust-analyzer.lens.references.method.enable (default: `false`):: ++ +-- +Whether to show `Method References` lens. Only applies when +`#rust-analyzer.lens.enable#` is set. +-- +[[rust-analyzer.lens.references.trait.enable]]rust-analyzer.lens.references.trait.enable (default: `false`):: ++ +-- +Whether to show `References` lens for Trait. +Only applies when `#rust-analyzer.lens.enable#` is set. +-- +[[rust-analyzer.lens.run.enable]]rust-analyzer.lens.run.enable (default: `true`):: ++ +-- +Whether to show `Run` lens. Only applies when +`#rust-analyzer.lens.enable#` is set. +-- +[[rust-analyzer.linkedProjects]]rust-analyzer.linkedProjects (default: `[]`):: ++ +-- +Disable project auto-discovery in favor of explicitly specified set +of projects. + +Elements must be paths pointing to `Cargo.toml`, +`rust-project.json`, or JSON objects in `rust-project.json` format. +-- +[[rust-analyzer.lru.capacity]]rust-analyzer.lru.capacity (default: `null`):: ++ +-- +Number of syntax trees rust-analyzer keeps in memory. Defaults to 128. +-- +[[rust-analyzer.notifications.cargoTomlNotFound]]rust-analyzer.notifications.cargoTomlNotFound (default: `true`):: ++ +-- +Whether to show `can't find Cargo.toml` error message. +-- +[[rust-analyzer.procMacro.attributes.enable]]rust-analyzer.procMacro.attributes.enable (default: `true`):: ++ +-- +Expand attribute macros. Requires `#rust-analyzer.procMacro.enable#` to be set. +-- +[[rust-analyzer.procMacro.enable]]rust-analyzer.procMacro.enable (default: `true`):: ++ +-- +Enable support for procedural macros, implies `#rust-analyzer.cargo.buildScripts.enable#`. +-- +[[rust-analyzer.procMacro.ignored]]rust-analyzer.procMacro.ignored (default: `{}`):: ++ +-- +These proc-macros will be ignored when trying to expand them. + +This config takes a map of crate names with the exported proc-macro names to ignore as values. +-- +[[rust-analyzer.procMacro.server]]rust-analyzer.procMacro.server (default: `null`):: ++ +-- +Internal config, path to proc-macro server executable (typically, +this is rust-analyzer itself, but we override this in tests). +-- +[[rust-analyzer.runnables.command]]rust-analyzer.runnables.command (default: `null`):: ++ +-- +Command to be executed instead of 'cargo' for runnables. +-- +[[rust-analyzer.runnables.extraArgs]]rust-analyzer.runnables.extraArgs (default: `[]`):: ++ +-- +Additional arguments to be passed to cargo for runnables such as +tests or binaries. For example, it may be `--release`. +-- +[[rust-analyzer.rustc.source]]rust-analyzer.rustc.source (default: `null`):: ++ +-- +Path to the Cargo.toml of the rust compiler workspace, for usage in rustc_private +projects, or "discover" to try to automatically find it if the `rustc-dev` component +is installed. + +Any project which uses rust-analyzer with the rustcPrivate +crates must set `[package.metadata.rust-analyzer] rustc_private=true` to use it. + +This option does not take effect until rust-analyzer is restarted. +-- +[[rust-analyzer.rustfmt.extraArgs]]rust-analyzer.rustfmt.extraArgs (default: `[]`):: ++ +-- +Additional arguments to `rustfmt`. +-- +[[rust-analyzer.rustfmt.overrideCommand]]rust-analyzer.rustfmt.overrideCommand (default: `null`):: ++ +-- +Advanced option, fully override the command rust-analyzer uses for +formatting. +-- +[[rust-analyzer.rustfmt.rangeFormatting.enable]]rust-analyzer.rustfmt.rangeFormatting.enable (default: `false`):: ++ +-- +Enables the use of rustfmt's unstable range formatting command for the +`textDocument/rangeFormatting` request. The rustfmt option is unstable and only +available on a nightly build. +-- +[[rust-analyzer.semanticHighlighting.strings.enable]]rust-analyzer.semanticHighlighting.strings.enable (default: `true`):: ++ +-- +Use semantic tokens for strings. + +In some editors (e.g. vscode) semantic tokens override other highlighting grammars. +By disabling semantic tokens for strings, other grammars can be used to highlight +their contents. +-- +[[rust-analyzer.signatureInfo.detail]]rust-analyzer.signatureInfo.detail (default: `"full"`):: ++ +-- +Show full signature of the callable. Only shows parameters if disabled. +-- +[[rust-analyzer.signatureInfo.documentation.enable]]rust-analyzer.signatureInfo.documentation.enable (default: `true`):: ++ +-- +Show documentation. +-- +[[rust-analyzer.typing.autoClosingAngleBrackets.enable]]rust-analyzer.typing.autoClosingAngleBrackets.enable (default: `false`):: ++ +-- +Whether to insert closing angle brackets when typing an opening angle bracket of a generic argument list. +-- +[[rust-analyzer.workspace.symbol.search.kind]]rust-analyzer.workspace.symbol.search.kind (default: `"only_types"`):: ++ +-- +Workspace symbol search kind. +-- +[[rust-analyzer.workspace.symbol.search.limit]]rust-analyzer.workspace.symbol.search.limit (default: `128`):: ++ +-- +Limits the number of items returned from a workspace symbol search (Defaults to 128). +Some clients like vs-code issue new searches on result filtering and don't require all results to be returned in the initial search. +Other clients requires all results upfront and might require a higher limit. +-- +[[rust-analyzer.workspace.symbol.search.scope]]rust-analyzer.workspace.symbol.search.scope (default: `"workspace"`):: ++ +-- +Workspace symbol search scope. +-- diff --git a/src/tools/rust-analyzer/docs/user/manual.adoc b/src/tools/rust-analyzer/docs/user/manual.adoc new file mode 100644 index 000000000..999a6437a --- /dev/null +++ b/src/tools/rust-analyzer/docs/user/manual.adoc @@ -0,0 +1,863 @@ += User Manual +:toc: preamble +:sectanchors: +:page-layout: post +:icons: font +:source-highlighter: rouge +:experimental: + +//// +IMPORTANT: the master copy of this document lives in the https://github.com/rust-lang/rust-analyzer repository +//// + +At its core, rust-analyzer is a *library* for semantic analysis of Rust code as it changes over time. +This manual focuses on a specific usage of the library -- running it as part of a server that implements the +https://microsoft.github.io/language-server-protocol/[Language Server Protocol] (LSP). +The LSP allows various code editors, like VS Code, Emacs or Vim, to implement semantic features like completion or goto definition by talking to an external language server process. + +[TIP] +==== +[.lead] +To improve this document, send a pull request: + +https://github.com/rust-lang/rust-analyzer/blob/master/docs/user/manual.adoc[https://github.com/rust-analyzer/.../manual.adoc] + +The manual is written in https://asciidoc.org[AsciiDoc] and includes some extra files which are generated from the source code. Run `cargo test` and `cargo test -p xtask` to create these and then `asciidoctor manual.adoc` to create an HTML copy. +==== + +If you have questions about using rust-analyzer, please ask them in the https://users.rust-lang.org/c/ide/14["`IDEs and Editors`"] topic of Rust users forum. + +== Installation + +In theory, one should be able to just install the <<rust-analyzer-language-server-binary,`rust-analyzer` binary>> and have it automatically work with any editor. +We are not there yet, so some editor specific setup is required. + +Additionally, rust-analyzer needs the sources of the standard library. +If the source code is not present, rust-analyzer will attempt to install it automatically. + +To add the sources manually, run the following command: + +```bash +$ rustup component add rust-src +``` + +=== Toolchain + +Only the latest stable standard library source is officially supported for use with rust-analyzer. +If you are using an older toolchain or have an override set, rust-analyzer may fail to understand the Rust source. +You will either need to update your toolchain or use an older version of rust-analyzer that is compatible with your toolchain. + +If you are using an override in your project, you can still force rust-analyzer to use the stable toolchain via the environment variable `RUSTUP_TOOLCHAIN`. +For example, with VS Code or coc-rust-analyzer: + +[source,json] +---- +{ "rust-analyzer.server.extraEnv": { "RUSTUP_TOOLCHAIN": "stable" } } +---- + +=== VS Code + +This is the best supported editor at the moment. +The rust-analyzer plugin for VS Code is maintained +https://github.com/rust-lang/rust-analyzer/tree/master/editors/code[in tree]. + +You can install the latest release of the plugin from +https://marketplace.visualstudio.com/items?itemName=rust-lang.rust-analyzer[the marketplace]. + +Note that the plugin may cause conflicts with the +https://marketplace.visualstudio.com/items?itemName=rust-lang.rust[official Rust plugin]. +It is recommended to disable the Rust plugin when using the rust-analyzer extension. + +By default, the plugin will prompt you to download the matching version of the server as well: + +image::https://user-images.githubusercontent.com/9021944/75067008-17502500-54ba-11ea-835a-f92aac50e866.png[] + +[NOTE] +==== +To disable this notification put the following to `settings.json` + +[source,json] +---- +{ "rust-analyzer.updates.askBeforeDownload": false } +---- +==== + +The server binary is stored in the extension install directory, which starts with `rust-lang.rust-analyzer-` and is located under: + +* Linux: `~/.vscode/extensions` +* Linux (Remote, such as WSL): `~/.vscode-server/extensions` +* macOS: `~/.vscode/extensions` +* Windows: `%USERPROFILE%\.vscode\extensions` + +As an exception, on NixOS, the extension makes a copy of the server and stores it under `~/.config/Code/User/globalStorage/rust-lang.rust-analyzer`. + +Note that we only support the two most recent versions of VS Code. + +==== Updates + +The extension will be updated automatically as new versions become available. +It will ask your permission to download the matching language server version binary if needed. + +===== Nightly + +We ship nightly releases for VS Code. +To help us out by testing the newest code, you can enable pre-release versions in the Code extension page. + +==== Manual installation + +Alternatively, download a VSIX corresponding to your platform from the +https://github.com/rust-lang/rust-analyzer/releases[releases] page. + +Install the extension with the `Extensions: Install from VSIX` command within VS Code, or from the command line via: +[source] +---- +$ code --install-extension /path/to/rust-analyzer.vsix +---- + +If you are running an unsupported platform, you can install `rust-analyzer-no-server.vsix` and compile or obtain a server binary. +Copy the server anywhere, then add the path to your settings.json, for example: +[source,json] +---- +{ "rust-analyzer.server.path": "~/.local/bin/rust-analyzer-linux" } +---- + +==== Building From Source + +Both the server and the Code plugin can be installed from source: + +[source] +---- +$ git clone https://github.com/rust-lang/rust-analyzer.git && cd rust-analyzer +$ cargo xtask install +---- + +You'll need Cargo, nodejs (matching a supported version of VS Code) and npm for this. + +Note that installing via `xtask install` does not work for VS Code Remote, instead you'll need to install the `.vsix` manually. + +If you're not using Code, you can compile and install only the LSP server: + +[source] +---- +$ cargo xtask install --server +---- + +=== rust-analyzer Language Server Binary + +Other editors generally require the `rust-analyzer` binary to be in `$PATH`. +You can download pre-built binaries from the https://github.com/rust-lang/rust-analyzer/releases[releases] page. +You will need to uncompress and rename the binary for your platform, e.g. from `rust-analyzer-aarch64-apple-darwin.gz` on Mac OS to `rust-analyzer`, make it executable, then move it into a directory in your `$PATH`. + +On Linux to install the `rust-analyzer` binary into `~/.local/bin`, these commands should work: + +[source,bash] +---- +$ mkdir -p ~/.local/bin +$ curl -L https://github.com/rust-lang/rust-analyzer/releases/latest/download/rust-analyzer-x86_64-unknown-linux-gnu.gz | gunzip -c - > ~/.local/bin/rust-analyzer +$ chmod +x ~/.local/bin/rust-analyzer +---- + +Make sure that `~/.local/bin` is listed in the `$PATH` variable and use the appropriate URL if you're not on a `x86-64` system. + +You don't have to use `~/.local/bin`, any other path like `~/.cargo/bin` or `/usr/local/bin` will work just as well. + +Alternatively, you can install it from source using the command below. +You'll need the latest stable version of the Rust toolchain. + +[source,bash] +---- +$ git clone https://github.com/rust-lang/rust-analyzer.git && cd rust-analyzer +$ cargo xtask install --server +---- + +If your editor can't find the binary even though the binary is on your `$PATH`, the likely explanation is that it doesn't see the same `$PATH` as the shell, see https://github.com/rust-lang/rust-analyzer/issues/1811[this issue]. +On Unix, running the editor from a shell or changing the `.desktop` file to set the environment should help. + +==== `rustup` + +`rust-analyzer` is available in `rustup`, but only in the nightly toolchain: + +[source,bash] +---- +$ rustup +nightly component add rust-analyzer-preview +---- + +However, in contrast to `component add clippy` or `component add rustfmt`, this does not actually place a `rust-analyzer` binary in `~/.cargo/bin`, see https://github.com/rust-lang/rustup/issues/2411[this issue]. + +==== Arch Linux + +The `rust-analyzer` binary can be installed from the repos or AUR (Arch User Repository): + +- https://www.archlinux.org/packages/community/x86_64/rust-analyzer/[`rust-analyzer`] (built from latest tagged source) +- https://aur.archlinux.org/packages/rust-analyzer-git[`rust-analyzer-git`] (latest Git version) + +Install it with pacman, for example: + +[source,bash] +---- +$ pacman -S rust-analyzer +---- + +==== Gentoo Linux + +`rust-analyzer` is available in the GURU repository: + +- https://gitweb.gentoo.org/repo/proj/guru.git/tree/dev-util/rust-analyzer?id=9895cea62602cfe599bd48e0fb02127411ca6e81[`dev-util/rust-analyzer`] builds from source +- https://gitweb.gentoo.org/repo/proj/guru.git/tree/dev-util/rust-analyzer-bin?id=9895cea62602cfe599bd48e0fb02127411ca6e81[`dev-util/rust-analyzer-bin`] installs an official binary release + +If not already, GURU must be enabled (e.g. using `app-eselect/eselect-repository`) and sync'd before running `emerge`: + +[source,bash] +---- +$ eselect repository enable guru && emaint sync -r guru +$ emerge rust-analyzer-bin +---- + +==== macOS + +The `rust-analyzer` binary can be installed via https://brew.sh/[Homebrew]. + +[source,bash] +---- +$ brew install rust-analyzer +---- + +=== Emacs + +Note this excellent https://robert.kra.hn/posts/2021-02-07_rust-with-emacs/[guide] from https://github.com/rksm[@rksm]. + +Prerequisites: You have installed the <<rust-analyzer-language-server-binary,`rust-analyzer` binary>>. + +Emacs support is maintained as part of the https://github.com/emacs-lsp/lsp-mode[Emacs-LSP] package in https://github.com/emacs-lsp/lsp-mode/blob/master/lsp-rust.el[lsp-rust.el]. + +1. Install the most recent version of `emacs-lsp` package by following the https://github.com/emacs-lsp/lsp-mode[Emacs-LSP instructions]. +2. Set `lsp-rust-server` to `'rust-analyzer`. +3. Run `lsp` in a Rust buffer. +4. (Optionally) bind commands like `lsp-rust-analyzer-join-lines`, `lsp-extend-selection` and `lsp-rust-analyzer-expand-macro` to keys. + +=== Vim/NeoVim + +Prerequisites: You have installed the <<rust-analyzer-language-server-binary,`rust-analyzer` binary>>. +Not needed if the extension can install/update it on its own, coc-rust-analyzer is one example. + +There are several LSP client implementations for vim or neovim: + +==== coc-rust-analyzer + +1. Install coc.nvim by following the instructions at + https://github.com/neoclide/coc.nvim[coc.nvim] + (Node.js required) +2. Run `:CocInstall coc-rust-analyzer` to install + https://github.com/fannheyward/coc-rust-analyzer[coc-rust-analyzer], + this extension implements _most_ of the features supported in the VSCode extension: + * automatically install and upgrade stable/nightly releases + * same configurations as VSCode extension, `rust-analyzer.server.path`, `rust-analyzer.cargo.features` etc. + * same commands too, `rust-analyzer.analyzerStatus`, `rust-analyzer.ssr` etc. + * inlay hints for variables and method chaining, _Neovim Only_ + +Note: for code actions, use `coc-codeaction-cursor` and `coc-codeaction-selected`; `coc-codeaction` and `coc-codeaction-line` are unlikely to be useful. + +==== LanguageClient-neovim + +1. Install LanguageClient-neovim by following the instructions + https://github.com/autozimu/LanguageClient-neovim[here] + * The GitHub project wiki has extra tips on configuration + +2. Configure by adding this to your vim/neovim config file (replacing the existing Rust-specific line if it exists): ++ +[source,vim] +---- +let g:LanguageClient_serverCommands = { +\ 'rust': ['rust-analyzer'], +\ } +---- + +==== YouCompleteMe + +Install YouCompleteMe by following the instructions + https://github.com/ycm-core/YouCompleteMe#installation[here]. + +rust-analyzer is the default in ycm, it should work out of the box. + +==== ALE + +To use the LSP server in https://github.com/dense-analysis/ale[ale]: + +[source,vim] +---- +let g:ale_linters = {'rust': ['analyzer']} +---- + +==== nvim-lsp + +NeoVim 0.5 has built-in language server support. +For a quick start configuration of rust-analyzer, use https://github.com/neovim/nvim-lspconfig#rust_analyzer[neovim/nvim-lspconfig]. +Once `neovim/nvim-lspconfig` is installed, use `+lua require'lspconfig'.rust_analyzer.setup({})+` in your `init.vim`. + +You can also pass LSP settings to the server: + +[source,vim] +---- +lua << EOF +local nvim_lsp = require'lspconfig' + +local on_attach = function(client) + require'completion'.on_attach(client) +end + +nvim_lsp.rust_analyzer.setup({ + on_attach=on_attach, + settings = { + ["rust-analyzer"] = { + imports = { + granularity = { + group = "module", + }, + prefix = "self", + }, + cargo = { + buildScripts = { + enable = true, + }, + }, + procMacro = { + enable = true + }, + } + } +}) +EOF +---- + +See https://sharksforarms.dev/posts/neovim-rust/ for more tips on getting started. + +Check out https://github.com/simrat39/rust-tools.nvim for a batteries included rust-analyzer setup for neovim. + +==== vim-lsp + +vim-lsp is installed by following https://github.com/prabirshrestha/vim-lsp[the plugin instructions]. +It can be as simple as adding this line to your `.vimrc`: + +[source,vim] +---- +Plug 'prabirshrestha/vim-lsp' +---- + +Next you need to register the `rust-analyzer` binary. +If it is available in `$PATH`, you may want to add this to your `.vimrc`: + +[source,vim] +---- +if executable('rust-analyzer') + au User lsp_setup call lsp#register_server({ + \ 'name': 'Rust Language Server', + \ 'cmd': {server_info->['rust-analyzer']}, + \ 'whitelist': ['rust'], + \ }) +endif +---- + +There is no dedicated UI for the server configuration, so you would need to send any options as a value of the `initialization_options` field, as described in the <<_configuration,Configuration>> section. +Here is an example of how to enable the proc-macro support: + +[source,vim] +---- +if executable('rust-analyzer') + au User lsp_setup call lsp#register_server({ + \ 'name': 'Rust Language Server', + \ 'cmd': {server_info->['rust-analyzer']}, + \ 'whitelist': ['rust'], + \ 'initialization_options': { + \ 'cargo': { + \ 'buildScripts': { + \ 'enable': v:true, + \ }, + \ }, + \ 'procMacro': { + \ 'enable': v:true, + \ }, + \ }, + \ }) +endif +---- + +=== Sublime Text + +==== Sublime Text 4: +* Follow the instructions in link:https://github.com/sublimelsp/LSP-rust-analyzer[LSP-rust-analyzer]. + +NOTE: Install link:https://packagecontrol.io/packages/LSP-file-watcher-chokidar[LSP-file-watcher-chokidar] to enable file watching (`workspace/didChangeWatchedFiles`). + +==== Sublime Text 3: +* Install the <<rust-analyzer-language-server-binary,`rust-analyzer` binary>>. +* Install the link:https://packagecontrol.io/packages/LSP[LSP package]. +* From the command palette, run `LSP: Enable Language Server Globally` and select `rust-analyzer`. + +If it worked, you should see "rust-analyzer, Line X, Column Y" on the left side of the status bar, and after waiting a bit, functionalities like tooltips on hovering over variables should become available. + +If you get an error saying `No such file or directory: 'rust-analyzer'`, see the <<rust-analyzer-language-server-binary,`rust-analyzer` binary>> section on installing the language server binary. + +=== GNOME Builder + +GNOME Builder 3.37.1 and newer has native `rust-analyzer` support. +If the LSP binary is not available, GNOME Builder can install it when opening a Rust file. + + +=== Eclipse IDE + +Support for Rust development in the Eclipse IDE is provided by link:https://github.com/eclipse/corrosion[Eclipse Corrosion]. +If available in PATH or in some standard location, `rust-analyzer` is detected and powers editing of Rust files without further configuration. +If `rust-analyzer` is not detected, Corrosion will prompt you for configuration of your Rust toolchain and language server with a link to the __Window > Preferences > Rust__ preference page; from here a button allows to download and configure `rust-analyzer`, but you can also reference another installation. +You'll need to close and reopen all .rs and Cargo files, or to restart the IDE, for this change to take effect. + +=== Kate Text Editor + +Support for the language server protocol is built into Kate through the LSP plugin, which is included by default. +It is preconfigured to use rust-analyzer for Rust sources since Kate 21.12. + +Earlier versions allow you to use rust-analyzer through a simple settings change. +In the LSP Client settings of Kate, copy the content of the third tab "default parameters" to the second tab "server configuration". +Then in the configuration replace: +[source,json] +---- + "rust": { + "command": ["rls"], + "rootIndicationFileNames": ["Cargo.lock", "Cargo.toml"], + "url": "https://github.com/rust-lang/rls", + "highlightingModeRegex": "^Rust$" + }, +---- +With +[source,json] +---- + "rust": { + "command": ["rust-analyzer"], + "rootIndicationFileNames": ["Cargo.lock", "Cargo.toml"], + "url": "https://github.com/rust-lang/rust-analyzer", + "highlightingModeRegex": "^Rust$" + }, +---- +Then click on apply, and restart the LSP server for your rust project. + +=== juCi++ + +https://gitlab.com/cppit/jucipp[juCi++] has built-in support for the language server protocol, and since version 1.7.0 offers installation of both Rust and rust-analyzer when opening a Rust file. + +=== Kakoune + +https://kakoune.org/[Kakoune] supports LSP with the help of https://github.com/kak-lsp/kak-lsp[`kak-lsp`]. +Follow the https://github.com/kak-lsp/kak-lsp#installation[instructions] to install `kak-lsp`. +To configure `kak-lsp`, refer to the https://github.com/kak-lsp/kak-lsp#configuring-kak-lsp[configuration section] which is basically about copying the https://github.com/kak-lsp/kak-lsp/blob/master/kak-lsp.toml[configuration file] in the right place (latest versions should use `rust-analyzer` by default). + +Finally, you need to configure Kakoune to talk to `kak-lsp` (see https://github.com/kak-lsp/kak-lsp#usage[Usage section]). +A basic configuration will only get you LSP but you can also activate inlay diagnostics and auto-formatting on save. +The following might help you get all of this. + +[source,txt] +---- +eval %sh{kak-lsp --kakoune -s $kak_session} # Not needed if you load it with plug.kak. +hook global WinSetOption filetype=rust %{ + # Enable LSP + lsp-enable-window + + # Auto-formatting on save + hook window BufWritePre .* lsp-formatting-sync + + # Configure inlay hints (only on save) + hook window -group rust-inlay-hints BufWritePost .* rust-analyzer-inlay-hints + hook -once -always window WinSetOption filetype=.* %{ + remove-hooks window rust-inlay-hints + } +} +---- + +=== Helix + +https://docs.helix-editor.com/[Helix] supports LSP by default. +However, it won't install `rust-analyzer` automatically. +You can follow instructions for installing <<rust-analyzer-language-server-binary,`rust-analyzer` binary>>. + +== Troubleshooting + +Start with looking at the rust-analyzer version. +Try **Rust Analyzer: Show RA Version** in VS Code (using **Command Palette** feature typically activated by Ctrl+Shift+P) or `rust-analyzer --version` in the command line. +If the date is more than a week ago, it's better to update rust-analyzer version. + +The next thing to check would be panic messages in rust-analyzer's log. +Log messages are printed to stderr, in VS Code you can see then in the `Output > Rust Analyzer Language Server` tab of the panel. +To see more logs, set the `RA_LOG=info` environment variable, this can be done either by setting the environment variable manually or by using `rust-analyzer.server.extraEnv`, note that both of these approaches require the server to be restarted. + +To fully capture LSP messages between the editor and the server, set `"rust-analyzer.trace.server": "verbose"` config and check +`Output > Rust Analyzer Language Server Trace`. + +The root cause for many "`nothing works`" problems is that rust-analyzer fails to understand the project structure. +To debug that, first note the `rust-analyzer` section in the status bar. +If it has an error icon and red, that's the problem (hover will have somewhat helpful error message). +**Rust Analyzer: Status** prints dependency information for the current file. +Finally, `RA_LOG=project_model=debug` enables verbose logs during project loading. + +If rust-analyzer outright crashes, try running `rust-analyzer analysis-stats /path/to/project/directory/` on the command line. +This command type checks the whole project in batch mode bypassing LSP machinery. + +When filing issues, it is useful (but not necessary) to try to minimize examples. +An ideal bug reproduction looks like this: + +```bash +$ git clone https://github.com/username/repo.git && cd repo && git switch --detach commit-hash +$ rust-analyzer --version +rust-analyzer dd12184e4 2021-05-08 dev +$ rust-analyzer analysis-stats . +💀 💀 💀 +``` + +It is especially useful when the `repo` doesn't use external crates or the standard library. + +If you want to go as far as to modify the source code to debug the problem, be sure to take a look at the +https://github.com/rust-lang/rust-analyzer/tree/master/docs/dev[dev docs]! + +== Configuration + +**Source:** https://github.com/rust-lang/rust-analyzer/blob/master/crates/rust-analyzer/src/config.rs[config.rs] + +The <<_installation,Installation>> section contains details on configuration for some of the editors. +In general `rust-analyzer` is configured via LSP messages, which means that it's up to the editor to decide on the exact format and location of configuration files. + +Some clients, such as <<vs-code,VS Code>> or <<coc-rust-analyzer,COC plugin in Vim>> provide `rust-analyzer` specific configuration UIs. Others may require you to know a bit more about the interaction with `rust-analyzer`. + +For the later category, it might help to know that the initial configuration is specified as a value of the `initializationOptions` field of the https://microsoft.github.io/language-server-protocol/specifications/specification-current/#initialize[`InitializeParams` message, in the LSP protocol]. +The spec says that the field type is `any?`, but `rust-analyzer` is looking for a JSON object that is constructed using settings from the list below. +Name of the setting, ignoring the `rust-analyzer.` prefix, is used as a path, and value of the setting becomes the JSON property value. + +For example, a very common configuration is to enable proc-macro support, can be achieved by sending this JSON: + +[source,json] +---- +{ + "cargo": { + "buildScripts": { + "enable": true, + }, + }, + "procMacro": { + "enable": true, + } +} +---- + +Please consult your editor's documentation to learn more about how to configure https://microsoft.github.io/language-server-protocol/[LSP servers]. + +To verify which configuration is actually used by `rust-analyzer`, set `RA_LOG` environment variable to `rust_analyzer=info` and look for config-related messages. +Logs should show both the JSON that `rust-analyzer` sees as well as the updated config. + +This is the list of config options `rust-analyzer` supports: + +include::./generated_config.adoc[] + +== Non-Cargo Based Projects + +rust-analyzer does not require Cargo. +However, if you use some other build system, you'll have to describe the structure of your project for rust-analyzer in the `rust-project.json` format: + +[source,TypeScript] +---- +interface JsonProject { + /// Path to the directory with *source code* of + /// sysroot crates. + /// + /// It should point to the directory where std, + /// core, and friends can be found: + /// + /// https://github.com/rust-lang/rust/tree/master/library. + /// + /// If provided, rust-analyzer automatically adds + /// dependencies on sysroot crates. Conversely, + /// if you omit this path, you can specify sysroot + /// dependencies yourself and, for example, have + /// several different "sysroots" in one graph of + /// crates. + sysroot_src?: string; + /// The set of crates comprising the current + /// project. Must include all transitive + /// dependencies as well as sysroot crate (libstd, + /// libcore and such). + crates: Crate[]; +} + +interface Crate { + /// Optional crate name used for display purposes, + /// without affecting semantics. See the `deps` + /// key for semantically-significant crate names. + display_name?: string; + /// Path to the root module of the crate. + root_module: string; + /// Edition of the crate. + edition: "2015" | "2018" | "2021"; + /// Dependencies + deps: Dep[]; + /// Should this crate be treated as a member of + /// current "workspace". + /// + /// By default, inferred from the `root_module` + /// (members are the crates which reside inside + /// the directory opened in the editor). + /// + /// Set this to `false` for things like standard + /// library and 3rd party crates to enable + /// performance optimizations (rust-analyzer + /// assumes that non-member crates don't change). + is_workspace_member?: boolean; + /// Optionally specify the (super)set of `.rs` + /// files comprising this crate. + /// + /// By default, rust-analyzer assumes that only + /// files under `root_module.parent` can belong + /// to a crate. `include_dirs` are included + /// recursively, unless a subdirectory is in + /// `exclude_dirs`. + /// + /// Different crates can share the same `source`. + /// + /// If two crates share an `.rs` file in common, + /// they *must* have the same `source`. + /// rust-analyzer assumes that files from one + /// source can't refer to files in another source. + source?: { + include_dirs: string[], + exclude_dirs: string[], + }, + /// The set of cfgs activated for a given crate, like + /// `["unix", "feature=\"foo\"", "feature=\"bar\""]`. + cfg: string[]; + /// Target triple for this Crate. + /// + /// Used when running `rustc --print cfg` + /// to get target-specific cfgs. + target?: string; + /// Environment variables, used for + /// the `env!` macro + env: { [key: string]: string; }, + + /// Whether the crate is a proc-macro crate. + is_proc_macro: boolean; + /// For proc-macro crates, path to compiled + /// proc-macro (.so file). + proc_macro_dylib_path?: string; +} + +interface Dep { + /// Index of a crate in the `crates` array. + crate: number, + /// Name as should appear in the (implicit) + /// `extern crate name` declaration. + name: string, +} +---- + +This format is provisional and subject to change. +Specifically, the `roots` setup will be different eventually. + +There are three ways to feed `rust-project.json` to rust-analyzer: + +* Place `rust-project.json` file at the root of the project, and rust-analyzer will discover it. +* Specify `"rust-analyzer.linkedProjects": [ "path/to/rust-project.json" ]` in the settings (and make sure that your LSP client sends settings as a part of initialize request). +* Specify `"rust-analyzer.linkedProjects": [ { "roots": [...], "crates": [...] }]` inline. + +Relative paths are interpreted relative to `rust-project.json` file location or (for inline JSON) relative to `rootUri`. + +See https://github.com/rust-analyzer/rust-project.json-example for a small example. + +You can set the `RA_LOG` environment variable to `rust_analyzer=info` to inspect how rust-analyzer handles config and project loading. + +Note that calls to `cargo check` are disabled when using `rust-project.json` by default, so compilation errors and warnings will no longer be sent to your LSP client. To enable these compilation errors you will need to specify explicitly what command rust-analyzer should run to perform the checks using the `checkOnSave.overrideCommand` configuration. As an example, the following configuration explicitly sets `cargo check` as the `checkOnSave` command. + +[source,json] +---- +{ "rust-analyzer.checkOnSave.overrideCommand": ["cargo", "check", "--message-format=json"] } +---- + +The `checkOnSave.overrideCommand` requires the command specified to output json error messages for rust-analyzer to consume. The `--message-format=json` flag does this for `cargo check` so whichever command you use must also output errors in this format. See the <<Configuration>> section for more information. + +== Security + +At the moment, rust-analyzer assumes that all code is trusted. +Here is a **non-exhaustive** list of ways to make rust-analyzer execute arbitrary code: + +* proc macros and build scripts are executed by default +* `.cargo/config` can override `rustc` with an arbitrary executable +* `rust-toolchain.toml` can override `rustc` with an arbitrary executable +* VS Code plugin reads configuration from project directory, and that can be used to override paths to various executables, like `rustfmt` or `rust-analyzer` itself. +* rust-analyzer's syntax trees library uses a lot of `unsafe` and hasn't been properly audited for memory safety. + +== Privacy + +The LSP server performs no network access in itself, but runs `cargo metadata` which will update or download the crate registry and the source code of the project dependencies. +If enabled (the default), build scripts and procedural macros can do anything. + +The Code extension does not access the network. + +Any other editor plugins are not under the control of the `rust-analyzer` developers. For any privacy concerns, you should check with their respective developers. + +For `rust-analyzer` developers, `cargo xtask release` uses the GitHub API to put together the release notes. + +== Features + +include::./generated_features.adoc[] + +== Assists (Code Actions) + +Assists, or code actions, are small local refactorings, available in a particular context. +They are usually triggered by a shortcut or by clicking a light bulb icon in the editor. +Cursor position or selection is signified by `┃` character. + +include::./generated_assists.adoc[] + +== Diagnostics + +While most errors and warnings provided by rust-analyzer come from the `cargo check` integration, there's a growing number of diagnostics implemented using rust-analyzer's own analysis. +Some of these diagnostics don't respect `\#[allow]` or `\#[deny]` attributes yet, but can be turned off using the `rust-analyzer.diagnostics.enable`, `rust-analyzer.diagnostics.experimental.enable` or `rust-analyzer.diagnostics.disabled` settings. + +include::./generated_diagnostic.adoc[] + +== Editor Features +=== VS Code + +==== Color configurations + +It is possible to change the foreground/background color and font family/size of inlay hints. +Just add this to your `settings.json`: + +[source,jsonc] +---- +{ + "editor.inlayHints.fontFamily": "Courier New", + "editor.inlayHints.fontSize": 11, + + "workbench.colorCustomizations": { + // Name of the theme you are currently using + "[Default Dark+]": { + "editorInlayHint.foreground": "#868686f0", + "editorInlayHint.background": "#3d3d3d48", + + // Overrides for specific kinds of inlay hints + "editorInlayHint.typeForeground": "#fdb6fdf0", + "editorInlayHint.parameterForeground": "#fdb6fdf0", + } + } +} +---- + +==== Semantic style customizations + +You can customize the look of different semantic elements in the source code. +For example, mutable bindings are underlined by default and you can override this behavior by adding the following section to your `settings.json`: + +[source,jsonc] +---- +{ + "editor.semanticTokenColorCustomizations": { + "rules": { + "*.mutable": { + "fontStyle": "", // underline is the default + }, + } + }, +} +---- + +Most themes doesn't support styling unsafe operations differently yet. You can fix this by adding overrides for the rules `operator.unsafe`, `function.unsafe`, and `method.unsafe`: + +[source,jsonc] +---- +{ + "editor.semanticTokenColorCustomizations": { + "rules": { + "operator.unsafe": "#ff6600", + "function.unsafe": "#ff6600", + "method.unsafe": "#ff6600" + } + }, +} +---- + +In addition to the top-level rules you can specify overrides for specific themes. For example, if you wanted to use a darker text color on a specific light theme, you might write: + +[source,jsonc] +---- +{ + "editor.semanticTokenColorCustomizations": { + "rules": { + "operator.unsafe": "#ff6600" + }, + "[Ayu Light]": { + "rules": { + "operator.unsafe": "#572300" + } + } + }, +} +---- + +Make sure you include the brackets around the theme name. For example, use `"[Ayu Light]"` to customize the theme Ayu Light. + +==== Special `when` clause context for keybindings. +You may use `inRustProject` context to configure keybindings for rust projects only. +For example: + +[source,json] +---- +{ + "key": "ctrl+alt+d", + "command": "rust-analyzer.openDocs", + "when": "inRustProject" +} +---- +More about `when` clause contexts https://code.visualstudio.com/docs/getstarted/keybindings#_when-clause-contexts[here]. + +==== Setting runnable environment variables +You can use "rust-analyzer.runnableEnv" setting to define runnable environment-specific substitution variables. +The simplest way for all runnables in a bunch: +```jsonc +"rust-analyzer.runnableEnv": { + "RUN_SLOW_TESTS": "1" +} +``` + +Or it is possible to specify vars more granularly: +```jsonc +"rust-analyzer.runnableEnv": [ + { + // "mask": null, // null mask means that this rule will be applied for all runnables + env: { + "APP_ID": "1", + "APP_DATA": "asdf" + } + }, + { + "mask": "test_name", + "env": { + "APP_ID": "2", // overwrites only APP_ID + } + } +] +``` + +You can use any valid regular expression as a mask. +Also note that a full runnable name is something like *run bin_or_example_name*, *test some::mod::test_name* or *test-mod some::mod*, so it is possible to distinguish binaries, single tests, and test modules with this masks: `"^run"`, `"^test "` (the trailing space matters!), and `"^test-mod"` respectively. + +==== Compiler feedback from external commands + +Instead of relying on the built-in `cargo check`, you can configure Code to run a command in the background and use the `$rustc-watch` problem matcher to generate inline error markers from its output. + +To do this you need to create a new https://code.visualstudio.com/docs/editor/tasks[VS Code Task] and set `rust-analyzer.checkOnSave.enable: false` in preferences. + +For example, if you want to run https://crates.io/crates/cargo-watch[`cargo watch`] instead, you might add the following to `.vscode/tasks.json`: + +```json +{ + "label": "Watch", + "group": "build", + "type": "shell", + "command": "cargo watch", + "problemMatcher": "$rustc-watch", + "isBackground": true +} +``` |