
diff options
| author | Daniel Baumann <daniel.baumann@progress-linux.org> | 2019-10-13 08:36:33 +0000 |
|---|---|---|
| committer | Daniel Baumann <daniel.baumann@progress-linux.org> | 2019-10-13 08:36:33 +0000 |
| commit | a30a849b78fa4fe8552141b7b2802d1af1b18c09 (patch) | |
| tree | fab3c8bf29bf2d565595d4fa6a9413916ff02fee /docs | |
| parent | Adding upstream version 1.17.1. (diff) | |
| download | netdata-a30a849b78fa4fe8552141b7b2802d1af1b18c09.tar.xz netdata-a30a849b78fa4fe8552141b7b2802d1af1b18c09.zip | |
Adding upstream version 1.18.0.upstream/1.18.0
Signed-off-by: Daniel Baumann <daniel.baumann@progress-linux.org>
Diffstat (limited to 'docs')
| -rw-r--r-- | docs/Add-more-charts-to-netdata.md | 5 | ||||
| -rw-r--r-- | docs/GettingStarted.md | 182 | ||||
| -rw-r--r-- | docs/Running-behind-haproxy.md | 49 | ||||
| -rw-r--r-- | docs/configuration-guide.md | 2 | ||||
| -rw-r--r-- | docs/contributing/contributing-documentation.md | 137 | ||||
| -rwxr-xr-x | docs/generator/buildyaml.sh | 5 | ||||
| -rwxr-xr-x | docs/generator/checklinks.sh | 66 | ||||
| -rw-r--r-- | docs/generator/custom/themes/material/partials/header.html | 1 | ||||
| -rw-r--r-- | docs/getting-started.md | 233 | ||||
| -rw-r--r-- | docs/high-performance-netdata.md | 2 | ||||
| -rw-r--r-- | docs/netdata-security.md | 35 | ||||
| -rw-r--r-- | docs/tutorials/longer-metrics-storage.md | 155 | ||||
| -rw-r--r-- | docs/what-is-netdata.md | 12 |
13 files changed, 595 insertions, 289 deletions
diff --git a/docs/Add-more-charts-to-netdata.md b/docs/Add-more-charts-to-netdata.md index 3b1bb9626..fe0341ced 100644 --- a/docs/Add-more-charts-to-netdata.md +++ b/docs/Add-more-charts-to-netdata.md @@ -70,6 +70,7 @@ To control which plugins Netdata run, edit `netdata.conf` and check the `[plugin # apps = yes # xenstat = yes # perf = no + # slabinfo = no ``` The default for all plugins is the option `enable running new plugins`. So, setting this to `no` will disable all the plugins, except the ones specifically enabled. @@ -96,7 +97,7 @@ sudo su -s /bin/bash netdata ``` Similarly, you can use `charts.d.plugin` for BASH plugins and `node.d.plugin` for node.js plugins. -Other plugins (like `apps.plugin`, `freeipmi.plugin`, `fping.plugin`, `ioping.plugin`, `nfacct.plugin`, `xenstat.plugin`, `perf.plugin`) use the native Netdata plugin API and can be run directly. +Other plugins (like `apps.plugin`, `freeipmi.plugin`, `fping.plugin`, `ioping.plugin`, `nfacct.plugin`, `xenstat.plugin`, `perf.plugin`, `slabinfo.plugin`) use the native Netdata plugin API and can be run directly. If you need to configure a Netdata plugin or module, all user supplied configuration is kept at `/etc/netdata` while the stock versions of all files is at `/usr/lib/netdata/conf.d`. To copy a stock file and edit it, run `/etc/netdata/edit-config`. Running this command without an argument, will list the available stock files. @@ -126,6 +127,7 @@ This is a map of the all supported configuration options: | `proc.plugin`<br/>(internal plugin for monitoring Linux system resources)|`C`|`netdata.conf` section `[plugin:proc]`|one section for each module `[plugin:proc:MODULE]`. Each module may provide additional sections in the form of `[plugin:proc:MODULE:SUBSECTION]`.| | `python.d.plugin`<br/>(external plugin orchestrator for running python modules)|`python`<br/>v2 or v3<br/>both are supported|`python.d.conf`|a file for each module in `/etc/netdata/python.d/`.| | `statsd.plugin`<br/>(internal plugin for collecting statsd metrics)|`C`|`netdata.conf` section `[statsd]`|Synthetic statsd charts can be configured with files in `/etc/netdata/statsd.d/`.| +| `slabinfo.plugin`<br/>(external plugin for monitoring Kernel SLAB cache on Linux)|`C`|`netdata.conf` section `[plugin:slabinfo]`|N/A| | `tc.plugin`<br/>(internal plugin for collecting Linux traffic QoS)|`C`|`netdata.conf` section `[plugin:tc]`|The plugin runs an external helper called `tc-qos-helper.sh` to interface with the `tc` command. This helper supports a few additional options using `tc-qos-helper.conf`.| ## writing data collection modules @@ -316,6 +318,7 @@ These are all the data collection plugins currently available. | cpu_apps|BASH<br/>Shell Script|Collects the CPU utilization of select apps.<br/><br/>DEPRECATED IN FAVOR OF `apps.plugin`. It is still supplied only as an example module to shell scripting plugins.<br/> <br/>Netdata plugin: [charts.d.plugin](../collectors/charts.d.plugin#chartsdplugin)<br/>plugin module: [cpu_apps.chart.sh](../collectors/charts.d.plugin/cpu_apps)<br/>configuration file: [charts.d/cpu_apps.conf](../collectors/charts.d.plugin/cpu_apps)| | load_average|BASH<br/>Shell Script|Collects the current system load average.<br/><br/>DEPRECATED IN FAVOR OF THE NETDATA INTERNAL ONE. It is still supplied only as an example module to shell scripting plugins.<br/> <br/>Netdata plugin: [charts.d.plugin](../collectors/charts.d.plugin#chartsdplugin)<br/>plugin module: [load_average.chart.sh](../collectors/charts.d.plugin/load_average)<br/>configuration file: [charts.d/load_average.conf](../collectors/charts.d.plugin/load_average)| | mem_apps|BASH<br/>Shell Script|Collects the memory footprint of select applications.<br/><br/>DEPRECATED IN FAVOR OF `apps.plugin`. It is still supplied only as an example module to shell scripting plugins.<br/> <br/>Netdata plugin: [charts.d.plugin](../collectors/charts.d.plugin#chartsdplugin)<br/>plugin module: [mem_apps.chart.sh](../collectors/charts.d.plugin/mem_apps)<br/>configuration file: [charts.d/mem_apps.conf](../collectors/charts.d.plugin/mem_apps)| +| slabinfo|C|`slabinfo.plugin` collects Kernel SLAB cache metrics on Linux .<br/> <br/>[Documentation of `slabinfo.plugin`](../collectors/slabinfo.plugin/).<br/> <br/>Netdata plugin: [`slabinfo_plugin.c`](../collectors/slabinfo.plugin)| --- diff --git a/docs/GettingStarted.md b/docs/GettingStarted.md deleted file mode 100644 index 7fd7a5382..000000000 --- a/docs/GettingStarted.md +++ /dev/null @@ -1,182 +0,0 @@ -# Getting Started - -These are your first steps **after** you have installed Netdata. If you haven't installed it already, please check the [installation page](../packaging/installer). - -## Accessing the dashboard - -To access the Netdata dashboard, navigate with your browser to: - -``` -http://your.server.ip:19999/ -``` - -<details markdown="1"><summary>Click here, if it does not work.</summary> - -**Verify Netdata is running.** - -Open an ssh session to the server and execute `sudo ps -e | grep netdata`. It should respond with the PID of the Netdata daemon. If it prints nothing, Netdata is not running. Check the [installation page](../packaging/installer) to install it. - -**Verify Netdata responds to HTTP requests.** - -Using the same ssh session, execute `curl -Ss http://localhost:19999`. It should dump on your screen the `index.html` page of the dashboard. If it does not, check the [installation page](../packaging/installer) to install it. - -**Verify Netdata receives the HTTP requests.** - -On the same ssh session, execute `tail -f /var/log/netdata/access.log` (if you installed the static 64bit package, use: `tail -f /opt/netdata/var/log/netdata/access.log`). This command will print on your screen all HTTP requests Netdata receives. - -Next, try to access the dashboard using your web browser, using the URL posted above. If nothing is printed on your terminal, the HTTP request is not routed to your Netdata. - -If you are not sure about your server IP, run this for a hint: `ip route get 8.8.8.8 | grep -oP " src [0-9\.]+ "`. It should print the IP of your server. - -If still Netdata does not receive the requests, something is blocking them. A firewall possibly. Please check your network. - -</details> <br/> - -When you install multiple Netdata servers, all your servers will appear at the node menu at the top left of the dashboard. For this to work, you have to manually access just once, the dashboard of each of your Netdata servers. - -The node menu is more than just browser bookmarks. When switching Netdata servers from that menu, any settings of the current view are propagated to the other Netdata server: - -- the current charts panning (drag the charts left or right), -- the current charts zooming (`SHIFT` + mouse wheel over a chart), -- the highlighted time-frame (`ALT` + select an area on a chart), -- the scrolling position of the dashboard, -- the theme you use, -- etc. - -are all sent over to other Netdata server, to allow you troubleshoot cross-server performance issues easily. - -## Starting and stopping Netdata - -Netdata installer integrates Netdata to your init / systemd environment. - -To start/stop Netdata, depending on your environment, you should use: - -- `systemctl start netdata` and `systemctl stop netdata` -- `service netdata start` and `service netdata stop` -- `/etc/init.d/netdata start` and `/etc/init.d/netdata stop` - -Once Netdata is installed, the installer configures it to start at boot and stop at shutdown. - -For more information about using these commands, consult your system documentation. - -## Sizing Netdata - -The default installation of Netdata is configured for a small round-robin database: just 1 hour of data. Depending on the memory your system has and the amount you can dedicate to Netdata, you should adapt this. On production systems with limited RAM, we suggest to set this to 3-4 hours. For best results you should set this to 24 or 48 hours. - -For every hour of data, Netdata needs about 25MB of RAM. If you can dedicate about 100MB of RAM to Netdata, you should set its database size to 4 hours. - -To do this, edit `/etc/netdata/netdata.conf` (or `/opt/netdata/etc/netdata/netdata.conf`) and set: - -``` -[global] - history = SECONDS -``` - -Make sure the `history` line is not commented (comment lines start with `#`). - -1 hour is 3600 seconds, so the number you need to set is the result of `HOURS * 3600`. - -!!! danger - Be careful when you set this on production systems. If you set it too high, your system may run out of memory. By default, Netdata is configured to be killed first when the system starves for memory, but better be careful to avoid issues. - -For more information about Netdata memory requirements, [check this page](../database). - -If your kernel supports KSM (most do), you can [enable KSM to half Netdata memory requirement](../database#ksm). - -## Service discovery and auto-detection - -Netdata supports auto-detection of data collection sources. It auto-detects almost everything: database servers, web servers, dns server, etc. - -This auto-detection process happens **only once**, when Netdata starts. To have Netdata re-discover data sources, you need to restart it. There are a few exceptions to this: - -- containers and VMs are auto-detected forever (when Netdata is running at the host). -- many data sources are collected but are silenced by default, until there is useful information to collect (for example network interface dropped packet, will appear after a packet has been dropped). -- services that are not optimal to collect on all systems, are disabled by default. -- services we received feedback from users that caused issues when monitored, are also disabled by default (for example, `chrony` is disabled by default, because CentOS ships a version of it that uses 100% CPU when queried for statistics). - -Once a data collection source is detected, Netdata will never quit trying to collect data from it, until Netdata is restarted. So, if you stop your web server, Netdata will pick it up automatically when it is started again. - -Since Netdata is installed on all your systems (even inside containers), auto-detection is limited to `localhost`. This simplifies significantly the security model of a Netdata monitored infrastructure, since most applications allow `localhost` access by default. - -A few well known data collection sources that commonly need to be configured are: - -- [systemd services utilization](../collectors/cgroups.plugin/#monitoring-systemd-services) are not exposed by default on most systems, so `systemd` has to be configured to expose those metrics. - -## Configuration quick start - -In Netdata we have: - -- **internal** data collection plugins (running inside the Netdata daemon) -- **external** data collection plugins (independent processes, sending data to Netdata over pipes) -- modular plugin **orchestrators** (external plugins that have multiple data collection modules) - -You can enable and disable plugins (internal and external) via `netdata.conf` at the section `[plugins]`. - -All plugins have dedicated sections in `netdata.conf`, like `[plugin:XXX]` for overwriting their default data collection frequency and providing additional command line options to them. - -All external plugins have their own `.conf` file. - -All modular plugin orchestrators have a directory in `/etc/netdata` with a `.conf` file for each of their modules. - -It is complex. So, let's see the whole configuration tree for the `nginx` module of `python.d.plugin`: - -In `netdata.conf` at the `[plugins]` section, `python.d.plugin` can be enabled or disabled: - -``` -[plugins] - python.d = yes -``` - -In `netdata.conf` at the `[plugin:python.d]` section, we can provide additional command line options for `python.d.plugin` and overwite its data collection frequency: - -``` -[plugin:python.d] - update every = 1 - command options = -``` - -`python.d.plugin` has its own configuration file for enabling and disabling its modules (here you can disable `nginx` for example): - -```bash -sudo /etc/netdata/edit-config python.d.conf -``` - -Then, `nginx` has its own configuration file for configuring its data collection jobs (most modules can collect data from multiple sources, so the `nginx` module can collect metrics from multiple, local or remote, `nginx` servers): - -```bash -sudo /etc/netdata/edit-config python.d/nginx.conf -``` - -## Health monitoring and alarms - -Netdata ships hundreds of health monitoring alarms for detecting anomalies. These are optimized for production servers. - -Many users install Netdata on workstations and are frustrated by the default alarms shipped with Netdata. On these cases, we suggest to disable health monitoring. - -To disable it, edit `/etc/netdata/netdata.conf` (or `/opt/netdata/etc/netdata/netdata.conf` if you installed the static 64bit package) and set: - -``` -[health] - enabled = no -``` - -The above will disable health monitoring entirely. - -If you want to keep health monitoring enabled for the dashboard, but you want to disable email notifications, run this: - -```bash -sudo /etc/netdata/edit-config health_alarm_notify.conf -``` - -and set `SEND_EMAIL="NO"`. - -(For static 64bit installations use `sudo /opt/netdata/etc/netdata/edit-config health_alarm_notify.conf`). - -## What is next? - -- Check [Data Collection](../collectors) for configuring data collection plugins. -- Check [Health Monitoring](../health) for configuring your own alarms, or setting up alarm notifications. -- Check [Streaming](../streaming) for centralizing Netdata metrics. -- Check [Backends](../backends) for long term archiving of Netdata metrics to time-series databases. - -[](<>) diff --git a/docs/Running-behind-haproxy.md b/docs/Running-behind-haproxy.md index cf95a491c..cf411b9f8 100644 --- a/docs/Running-behind-haproxy.md +++ b/docs/Running-behind-haproxy.md @@ -1,16 +1,21 @@ # Netdata via HAProxy -> HAProxy is a free, very fast and reliable solution offering high availability, load balancing, and proxying for TCP and HTTP-based applications. It is particularly suited for very high traffic web sites and powers quite a number of the world's most visited ones. +> HAProxy is a free, very fast and reliable solution offering high availability, load balancing, +> and proxying for TCP and HTTP-based applications. It is particularly suited for very high traffic web sites +> and powers quite a number of the world's most visited ones. -If Netdata is running on a host running HAProxy, rather than connecting to Netdata from a port number, a domain name can be pointed at HAProxy, and HAProxy can redirect connections to the Netdata port. This can make it possible to connect to Netdata at <https://example.com> or <https://example.com/netdata/>, which is a much nicer experience then <http://example.com:19999>. +If Netdata is running on a host running HAProxy, rather than connecting to Netdata from a port number, a domain name +can be pointed at HAProxy, and HAProxy can redirect connections to the Netdata port. This can make it possible to +connect to Netdata at <https://example.com> or <https://example.com/netdata/>, which is a much nicer experience then <http://example.com:19999>. -To proxy requests from [HAProxy](https://github.com/haproxy/haproxy) to Netdata, the following configuration can be used: +To proxy requests from [HAProxy](https://github.com/haproxy/haproxy) to Netdata, +the following configuration can be used: ## Default Configuration For all examples, set the mode to `http` -``` +```conf defaults mode http ``` @@ -23,7 +28,7 @@ A simple example where the base URL, say <http://example.com>, is used with no s Create a frontend to recieve the request. -``` +```conf frontend http_frontend ## HTTP ipv4 and ipv6 on all ips ## bind :::80 v4v6 @@ -35,7 +40,7 @@ frontend http_frontend Create the Netdata backend which will send requests to port `19999`. -``` +```conf backend netdata_backend option forwardfor server netdata_local 127.0.0.1:19999 @@ -54,7 +59,7 @@ A example where the base URL is used with a subpath `/netdata/`: To use a subpath, create an ACL, which will set a variable based on the subpath. -``` +```conf frontend http_frontend ## HTTP ipv4 and ipv6 on all ips ## bind :::80 v4v6 @@ -77,7 +82,7 @@ frontend http_frontend Same as simple example, expept remove `/netdata/` with regex. -``` +```conf backend netdata_backend option forwardfor server netdata_local 127.0.0.1:19999 @@ -92,13 +97,14 @@ backend netdata_backend ## Using TLS communication -TLS can be used by adding port `443` and a cert to the frontend. This example will only use Netdata if host matches example.com (replace with your domain). +TLS can be used by adding port `443` and a cert to the frontend. +This example will only use Netdata if host matches example.com (replace with your domain). ### Frontend This frontend uses a certificate list. -``` +```conf frontend https_frontend ## HTTP ## bind :::80 v4v6 @@ -123,14 +129,15 @@ In the cert list file place a mapping from a certificate file to the domain used `/etc/letsencrypt/certslist.txt`: -``` +```txt example.com /etc/letsencrypt/live/example.com/example.com.pem ``` -The file `/etc/letsencrypt/live/example.com/example.com.pem` should contain the key and certificate (in that order) concatenated into a `.pem` file.: +The file `/etc/letsencrypt/live/example.com/example.com.pem` should contain the key and +certificate (in that order) concatenated into a `.pem` file.: -``` -$ cat /etc/letsencrypt/live/example.com/fullchain.pem \ +```sh +cat /etc/letsencrypt/live/example.com/fullchain.pem \ /etc/letsencrypt/live/example.com/privkey.pem > \ /etc/letsencrypt/live/example.com/example.com.pem ``` @@ -139,7 +146,7 @@ $ cat /etc/letsencrypt/live/example.com/fullchain.pem \ Same as simple, except set protocol `https`. -``` +```conf backend netdata_backend option forwardfor server netdata_local 127.0.0.1:19999 @@ -155,7 +162,7 @@ backend netdata_backend To use basic HTTP Authentication, create a authentication list: -``` +```conf # HTTP Auth userlist basic-auth-list group is-admin @@ -165,20 +172,20 @@ userlist basic-auth-list You can create a hashed password using the `mkpassword` utility. -``` -$ printf "passwordhere" | mkpasswd --stdin --method=sha-256 +```sh + printf "passwordhere" | mkpasswd --stdin --method=sha-256 $5$l7Gk0VPIpKO$f5iEcxvjfdF11khw.utzSKqP7W.0oq8wX9nJwPLwzy1 ``` Replace `passwordhere` with hash: -``` +```conf user admin password $5$l7Gk0VPIpKO$f5iEcxvjfdF11khw.utzSKqP7W.0oq8wX9nJwPLwzy1 groups is-admin ``` Now add at the top of the backend: -``` +```conf acl devops-auth http_auth_group(basic-auth-list) is-admin http-request auth realm netdata_local unless devops-auth ``` @@ -187,7 +194,7 @@ http-request auth realm netdata_local unless devops-auth Full example configuration with HTTP auth over TLS with subpath: -``` +```conf global maxconn 20000 diff --git a/docs/configuration-guide.md b/docs/configuration-guide.md index c13347749..600848e2e 100644 --- a/docs/configuration-guide.md +++ b/docs/configuration-guide.md @@ -106,7 +106,7 @@ The page on [Netdata performance](Performance.md) has an excellent guide on how ##### Change when Netdata saves metrics to disk -[netdata.conf \[global\]](../daemon/config/#global-section-options) : `memory mode`</details> +[netdata.conf \[global\]](../daemon/config/#global-section-options) : `memory mode` ##### Prevent Netdata from getting immediately killed when my server runs out of memory diff --git a/docs/contributing/contributing-documentation.md b/docs/contributing/contributing-documentation.md index 7cf0d820f..6f94d5bf1 100644 --- a/docs/contributing/contributing-documentation.md +++ b/docs/contributing/contributing-documentation.md @@ -1,25 +1,38 @@ # Contributing to documentation -We welcome contributions to Netdata's already extensive documentation, which we host at [docs.netdata.cloud](https://docs.netdata.cloud/) and store inside of the [main repository](https://github.com/netdata/netdata) on GitHub. +We welcome contributions to Netdata's already extensive documentation, +which we host at [docs.netdata.cloud](https://docs.netdata.cloud/) +and store inside of the [main repository](https://github.com/netdata/netdata) on GitHub. -Like all contributing to all other aspects of Netdata, we ask that anyone who wants to help with documentation read and abide by the [Contributor Convenant Code of Conduct](https://docs.netdata.cloud/code_of_conduct/) and follow the instructions outlined in our [Contributing document](../../CONTRIBUTING.md). +Like all contributing to all other aspects of Netdata, we ask that anyone who wants to help with documentation +read and abide by the [Contributor Convenant Code of Conduct](https://docs.netdata.cloud/code_of_conduct/) +and follow the instructions outlined in our [Contributing document](../../CONTRIBUTING.md). -We also ask you to read our [documentation style guide](style-guide.md), which, while not complete, will give you some guidance on how we write and organize our documentation. +We also ask you to read our [documentation style guide](style-guide.md), which, while not complete, +will give you some guidance on how we write and organize our documentation. -All our documentation uses the Markdown syntax. If you're not familiar with how it works, please read the [Markdown introduction post](https://daringfireball.net/projects/markdown/) by its creator, followed by [Mastering Markdown](https://guides.github.com/features/mastering-markdown/) guide from GitHub. +All our documentation uses the Markdown syntax. If you're not familiar with how it works, +please read the [Markdown introduction post](https://daringfireball.net/projects/markdown/) by its creator, +followed by [Mastering Markdown](https://guides.github.com/features/mastering-markdown/) guide from GitHub. ## How contributing to the documentation works There are two ways to contribute to Netdata's documentation: -1. Edit documentation [directly in GitHub](#edit-documentation-directly-on-gitHub). +1. Edit documentation [directly in GitHub](#edit-documentation-directly-on-github). 2. Download the repository and [edit documentation locally](#edit-documentation-locally). -Editing in GitHub is a simpler process and is perfect for quick edits to a single document, such as fixing a typo or clarifying a confusing sentence. +Editing in GitHub is a simpler process and is perfect for quick edits to a single document, +such as fixing a typo or clarifying a confusing sentence. -Editing locally is more complex, as you need to download the Netdata repository and build the documentation using `mkdocs`, but allows you to better organize complex projects. By building documentation locally, you can preview your work using a local web server before you submit your PR. +Editing locally is more complex, as you need to download the Netdata repository +and build the documentation using `mkdocs`, but allows you to better organize complex projects. +By building documentation locally, you can preview your work using a local web server before you submit your PR. -In both cases, you'll finish by submitting a pull request (PR). Once you submit your PR, GitHub will initiate a number of jobs, including a Netlify preview. You can use this preview to view the documentation site with your changes applied, which might help you catch any lingering issues. +In both cases, you'll finish by submitting a pull request (PR). +Once you submit your PR, GitHub will initiate a number of jobs, including a Netlify preview. +You can use this preview to view the documentation site with your changes applied, +which might help you catch any lingering issues. To continue, follow one of the paths below: @@ -28,109 +41,149 @@ To continue, follow one of the paths below: ## Edit documentation directly on GitHub -Start editing documentation on GitHub by clicking the small pencil icon on any page on Netdata's [documentation site](https://docs.netdata.cloud/). You can find them at the top of every page. +Start editing documentation on GitHub by clicking the small pencil icon on any page on Netdata's [documentation site](https://docs.netdata.cloud/). +You can find them at the top of every page. -Clicking on this icon will take you to the associated page in the `netdata/netdata` repository. Then click the small pencil icon on any documentation file (those ending in the `.md` [Markdown] extension) in the `netdata/netdata` repository. +Clicking on this icon will take you to the associated page in the `netdata/netdata` repository. +Then click the small pencil icon on any documentation file (those ending in the `.md` Markdown extension) in the `netdata/netdata` repository.  -If you know where a file resides in the Netdata repository already, you can skip the step of beginning on the documentation site and go directly to GitHub. +If you know where a file resides in the Netdata repository already, +you can skip the step of beginning on the documentation site and go directly to GitHub. -Once you've clicked the pencil icon on GitHub, you'll see a full Markdown version of the file. Make changes as you see fit. You can use the `Preview changes` button to ensure your Markdown syntax is working properly. +Once you've clicked the pencil icon on GitHub, you'll see a full Markdown version of the file. +Make changes as you see fit. +You can use the `Preview changes` button to ensure your Markdown syntax is working properly. -Under the `Propose file change` header, write in a descriptive title for your requested change. Beneath that, add a concise descrition of what you've changed and why you think it's important. Then, click the `Propose file change` button. +Under the `Propose file change` header, write in a descriptive title for your requested change. +Beneath that, add a concise descrition of what you've changed and why you think it's important. Then, click the `Propose file change` button. -After you've hit that button, jump down to our instructions on [pull requests and cleanup](#pull-requests-and-final-steps) for your next steps. +After you've hit that button, +jump down to our instructions on [pull requests and cleanup](#pull-requests-and-final-steps) for your next steps. !!! note - This process will create a branch directly on the `netdata/netdata` repository, which then requires manual cleanup. If you're going to make significant documentation contributions, or contribute often, we recommend the local editing process just below. + This process will create a branch directly on the `netdata/netdata` repository, which then requires manual cleanup. + If you're going to make significant documentation contributions, or contribute often, + we recommend the local editing process just below. ## Edit documentation locally -Editing documentation locally is the preferred method for complex changes, PRs that span across multiple documents, or those that change the styling or underlying functionality of the documentation. +Editing documentation locally is the preferred method for complex changes, PRs that span across multiple documents, +or those that change the styling or underlying functionality of the documentation. -Here is the workflow for editing documentation locally. First, create a fork of the Netdata repository, if you don't have one already. Visit the [Netdata repository](https://github.com/netdata/netdata) and click on the `Fork` button in the upper-right corner of the window. +Here is the workflow for editing documentation locally. First, create a fork of the Netdata repository, +if you don't have one already. Visit the [Netdata repository](https://github.com/netdata/netdata) +and click on the `Fork` button in the upper-right corner of the window.  -GitHub will ask you where you want to clone the repository, and once finished you'll end up at the index of your forked Netdata repository. Clone your fork to your local machine: +GitHub will ask you where you want to clone the repository, +and once finished you'll end up at the index of your forked Netdata repository. +Clone your fork to your local machine: ```bash -$ git clone https://github.com/YOUR-GITHUB-USERNAME/netdata.git +git clone https://github.com/YOUR-GITHUB-USERNAME/netdata.git ``` You can now jump into the directory and explore Netdata's structure for yourself. ### Understanding the structure of Netdata's documentation -All of Netdata's documentation is stored within the repository itself, as close as possible to the code it corresponds to. Many sub-folders contain a `README.md` file, which is then used to populate the documentation about that feature/component of Netdata. +All of Netdata's documentation is stored within the repository itself, as close as possible to the code it +corresponds to. Many sub-folders contain a `README.md` file, +which is then used to populate the documentation about that feature/component of Netdata. -For example, the file at `packaging/installer/README.md` becomes `https://docs.netdata.cloud/packaging/installer/` and is our installation documentation. By co-locating it with quick-start installtion code, we ensure documentation is always tightly knit with the functions it describes. +For example, the file at `packaging/installer/README.md` becomes `https://docs.netdata.cloud/packaging/installer/` +and is our installation documentation. By co-locating it with quick-start installtion code, +we ensure documentation is always tightly knit with the functions it describes. -You might find other `.md` files within these directories. The `packaging/installer/` folder also contains `UPDATE.md` and `UNINSTALL.md`, which become `https://docs.netdata.cloud/packaging/installer/update/` and `https://docs.netdata.cloud/packaging/installer/uninstall/`, respectively. +You might find other `.md` files within these directories. The `packaging/installer/` folder also contains `UPDATE.md` +and `UNINSTALL.md`, which become `https://docs.netdata.cloud/packaging/installer/update/` +and `https://docs.netdata.cloud/packaging/installer/uninstall/`, respectively. -If the documentation you're working on has a direct correlation to some component of Netdata, place it into the correct folder and either name it `README.md` for generic documentation, or with another name for very specific instructions. +If the documentation you're working on has a direct correlation to some component of Netdata, place it into the correct +folder and either name it `README.md` for generic documentation, or with another name for very specific instructions. #### The `docs` folder -At the root of the Netdata repository is a `docs/` folder. Inside this folder we place documentation that does not have a direct relationship to a specific component of Netdata. It's where we house our [getting started guide](../GettingStarted.md), guides on [running Netdata behind Nginx](../Running-behind-nginx.md), and more. +At the root of the Netdata repository is a `docs/` folder. Inside this folder we place documentation that does not have +a direct relationship to a specific component of Netdata. It's where we house our [getting started +guide](../../docs/getting-started.md), guides on [running Netdata behind Nginx](../../docs/Running-behind-nginx.md), and +more. -If the documentation you're working on doesn't have a direct relaionship to a component of Netdata, it can be placed in this `docs/` folder. +If the documentation you're working on doesn't have a direct relaionship to a component of Netdata, +it can be placed in this `docs/` folder. ### Make your edits -Now that you're set up and understand where to find or create your `.md` file, you can now begin to make your edits. Just use your favorite editor and keep in mind our [style guide](style-guide.md) as you work. +Now that you're set up and understand where to find or create your `.md` file, you can now begin to make your edits. +Just use your favorite editor and keep in mind our [style guide](style-guide.md) as you work. -If you add a new file to the documentation, you may need to modify the `buildyaml.sh` file to ensure it's added to the site's navigation. This is true for any file added to the `docs/` folder. +If you add a new file to the documentation, you may need to modify the `buildyaml.sh` file to ensure +it's added to the site's navigation. This is true for any file added to the `docs/` folder. -Be sure to periodically add/commit your edits so that you don't lose your work! We use version control software for a reason. +Be sure to periodically add/commit your edits so that you don't lose your work! +We use version control software for a reason. ### Build the documentation -Building the documentation periodically gives you a glimpse into the final product, and is generally required if you're making changes to the table of contents. +Building the documentation periodically gives you a glimpse into the final product, and is generally required +if you're making changes to the table of contents. !!! attention "" - We have only tested the build process on Linux. Initial tests on OS X have been unsuccessful. Windows is fully untested at this point, but we would love to know if it works there as well! + We have only tested the build process on Linux. Initial tests on OS X have been unsuccessful. + Windows is fully untested at this point, but we would love to know if it works there as well! To build the documentation, you need `python`/`pip`, `mkdocs`, and `mkdocs-material` installed on your machine. Follow the [Python installation instructions](https://www.python.org/downloads/) for your machine. -Use `pip`, which was installed alongside Python, to install `mkdocs` and `mkdocs-material`. Your operating system might force you to use `pip2` or `pip3` instead, dependin on which version of Python you have installed. +Use `pip`, which was installed alongside Python, to install `mkdocs` and `mkdocs-material`. +Your operating system might force you to use `pip2` or `pip3` instead, +dependin on which version of Python you have installed. ```bash -$ pip install mkdocs mkdocs-material +pip install mkdocs mkdocs-material ``` ??? note "Troubleshooting" If you're having trouble with the installation of Python, `mkdocs`, or `mkdocs-material`, try looking into the `mkdocs` [installation instructions](https://squidfunk.github.io/mkdocs-material/getting-started/#installation). -When `pip` is finished installing, navigate to the root directory of the Netdata repository and run the documentation generator script. +When `pip` is finished installing, navigate to the root directory of the Netdata repository +and run the documentation generator script. ```bash -$ sh docs/generator/buildhtml.sh +sh docs/generator/buildhtml.sh ``` This process will take some time. Once finished, the built documentation site will be located at `docs/generator/build/`. ### Run a local web server to test documentation -The best way to view the documentation site you just built is to run a simple web server from the `docs/generator/build/` directory. So, navigate there and run a Python-based web server: +The best way to view the documentation site you just built is to run a simple web server from the `docs/generator/build/` directory. +So, navigate there and run a Python-based web server: -``` -$ cd docs/generator/build/ -$ python3 -m http.server 20000 +```sh +cd docs/generator/build/ +python3 -m http.server 20000 ``` -Feel free to replace the port number you want this web server to listen on (port `20000` in this case [only one higher than the agent!]). +Feel free to replace the port number you want this web server to listen on (port `20000` in this case (only one higher +than the agent!)). -Open your web browser and navigate to `http://localhost:20000`. If you replaced the port earlier, change it here as well. You can now navigate through the documentation as you would on the live site! +Open your web browser and navigate to `http://localhost:20000`. +If you replaced the port earlier, change it here as well. +You can now navigate through the documentation as you would on the live site! ## Pull requests and final steps -When you're finished with your changes, add and commit them to your fork of the Netdata repository. Head over to GitHub to create your pull request (PR). +When you're finished with your changes, add and commit them to your fork of the Netdata repository. +Head over to GitHub to create your pull request (PR). -Once we receive your pull request (PR), we'll take time to read through it and assess it for correctness, conciseness, and overall quality. We may point to specific sections and ask for additional information or other fixes. +Once we receive your pull request (PR), we'll take time to read through it and assess it for correctness, conciseness, +and overall quality. +We may point to specific sections and ask for additional information or other fixes. ## What's next diff --git a/docs/generator/buildyaml.sh b/docs/generator/buildyaml.sh index 427f9d896..04d6098fc 100755 --- a/docs/generator/buildyaml.sh +++ b/docs/generator/buildyaml.sh @@ -149,7 +149,7 @@ echo -ne " - 'docs/what-is-netdata.md' - 'packaging/installer/UPDATE.md' - 'packaging/DISTRIBUTIONS.md' - 'packaging/installer/UNINSTALL.md' -- 'docs/GettingStarted.md' +- 'docs/getting-started.md' - Running Netdata: - 'daemon/README.md' - 'docs/configuration-guide.md' @@ -250,6 +250,7 @@ navpart 3 collectors/freeipmi.plugin navpart 3 collectors/nfacct.plugin navpart 3 collectors/xenstat.plugin navpart 3 collectors/perf.plugin +navpart 3 collectors/slabinfo.plugin echo -ne " - 'docs/Third-Party-Plugins.md' @@ -285,4 +286,4 @@ navpart 2 packaging/makeself "" "" 4 navpart 2 libnetdata "" "libnetdata" 4 navpart 2 contrib navpart 2 tests "" "" 2 -navpart 2 diagrams/data_structures
\ No newline at end of file +navpart 2 diagrams/data_structures diff --git a/docs/generator/checklinks.sh b/docs/generator/checklinks.sh index 6521ca9ad..a453d8ff2 100755 --- a/docs/generator/checklinks.sh +++ b/docs/generator/checklinks.sh @@ -31,16 +31,16 @@ printhelp () { fix () { if [ "$EXECUTE" -eq 0 ] ; then - echo "-- SHOULD EXECUTE: $1" + echo " - SHOULD EXECUTE: $1" else - dbg "-- EXECUTING: $1" + dbg " - EXECUTING: $1" eval "$1" fi } testURL () { if [ "$TESTURLS" -eq 0 ] ; then return 0 ; fi - dbg "-- Testing URL $1" + dbg " - Testing URL $1" curl -sS "$1" > /dev/null if [ $? -gt 0 ] ; then return 1 @@ -54,13 +54,13 @@ testinternal () { ifile=${2} ilnk=${3} header=${ilnk//-/} - dbg "-- Searching for \"$header\" in $ifile" + dbg " - Searching for \"$header\" in $ifile" tr -d '[],_.:? `'< "$ifile" | sed 's/-//g' | grep -i "^\\#*$header\$" >/dev/null if [ $? -eq 0 ] ; then - dbg "-- $ilnk found in $ifile" + dbg " - $ilnk found in $ifile" return 0 else - echo "-- ERROR: $ff - $ilnk header not found in file $ifile" + echo " - ERROR: $ff - $ilnk header not found in file $ifile" EXITCODE=1 return 1 fi @@ -71,10 +71,10 @@ testf () { tf=$2 if [ -f "$tf" ] ; then - dbg "-- $tf exists" + dbg " - $tf exists" return 0 else - echo "-- ERROR: $sf - $tf does not exist" + echo " - ERROR: $sf - $tf does not exist" EXITCODE=1 return 1 fi @@ -83,16 +83,16 @@ testf () { ck_netdata_relative () { f=${1} rlnk=${2} - dbg "-- Checking relative link $rlnk" + dbg " - Checking relative link $rlnk" fpath="." fname="$f" # First ensure that the link works in the repo, then try to fix it in htmldocs if [[ $f =~ ^(.*)/([^/]*)$ ]] ; then fpath="${BASH_REMATCH[1]}" fname="${BASH_REMATCH[2]}" - dbg "-- Current file is at $fpath" + dbg " - Current file is at $fpath" else - dbg "-- Current file is at root directory" + dbg " - Current file is at root directory" fi # Cases to handle: # (#somelink) @@ -109,11 +109,11 @@ ck_netdata_relative () { case "$rlnk" in \#* ) - dbg "-- # (#somelink)" + dbg " - # (#somelink)" testinternal "$f" "$f" "$rlnk" ;; */ ) - dbg "-- # (path/)" + dbg " - # (path/)" TRGT="$fpath/${rlnk}README.md" testf "$f" "$TRGT" if [ $? -eq 0 ] ; then @@ -121,11 +121,11 @@ ck_netdata_relative () { fi ;; */\#* ) - dbg "-- # (path/#somelink)" + dbg " - # (path/#somelink)" if [[ $rlnk =~ ^(.*)/#(.*)$ ]] ; then TRGT="$fpath/${BASH_REMATCH[1]}/README.md" LNK="#${BASH_REMATCH[2]}" - dbg "-- Look for $LNK in $TRGT" + dbg " - Look for $LNK in $TRGT" testf "$f" "$TRGT" if [ $? -eq 0 ] ; then testinternal "$f" "$TRGT" "$LNK" @@ -136,21 +136,21 @@ ck_netdata_relative () { fi ;; *.md ) - dbg "-- # (path/filename.md) -> htmldoc (path/filename/)" + dbg " - # (path/filename.md) -> htmldoc (path/filename/)" testf "$f" "$fpath/$rlnk" if [ $? -eq 0 ] ; then if [[ $rlnk =~ ^(.*)/(.*).md$ ]] ; then if [ "${BASH_REMATCH[2]}" = "README" ] ; then - s="../${BASH_REMATCH[1]}/" + s="${BASH_REMATCH[1]}/" else - s="../${BASH_REMATCH[1]}/${BASH_REMATCH[2]}/" + s="${BASH_REMATCH[1]}/${BASH_REMATCH[2]}/" fi if [ "$fname" != "README.md" ] ; then s="../$s"; fi fi fi ;; *.md\#* ) - dbg "-- # (path/filename.md#somelink) -> htmldoc (path/filename/#somelink)" + dbg " - # (path/filename.md#somelink) -> htmldoc (path/filename/#somelink)" if [[ $rlnk =~ ^(.*)#(.*)$ ]] ; then TRGT="$fpath/${BASH_REMATCH[1]}" LNK="#${BASH_REMATCH[2]}" @@ -160,9 +160,9 @@ ck_netdata_relative () { if [ $? -eq 0 ] ; then if [[ $lnk =~ ^(.*)/(.*).md#(.*)$ ]] ; then if [ "${BASH_REMATCH[2]}" = "README" ] ; then - s="../${BASH_REMATCH[1]}/#${BASH_REMATCH[3]}" + s="${BASH_REMATCH[1]}/#${BASH_REMATCH[3]}" else - s="../${BASH_REMATCH[1]}/${BASH_REMATCH[2]}/#${BASH_REMATCH[3]}" + s="${BASH_REMATCH[1]}/${BASH_REMATCH[2]}/#${BASH_REMATCH[3]}" fi if [ "$fname" != "README.md" ] ; then s="../$s"; fi fi @@ -171,7 +171,7 @@ ck_netdata_relative () { fi ;; *\#* ) - dbg "-- # (path#somelink) -> (path/#somelink)" + dbg " - # (path#somelink) -> (path/#somelink)" if [[ $rlnk =~ ^(.*)#(.*)$ ]] ; then TRGT="$fpath/${BASH_REMATCH[1]}/README.md" LNK="#${BASH_REMATCH[2]}" @@ -189,7 +189,7 @@ ck_netdata_relative () { ;; * ) if [ -d "$fpath/$rlnk" ] ; then - dbg "-- # (path) -> htmldoc (path/)" + dbg " - # (path) -> htmldoc (path/)" testf "$f" "$fpath/$rlnk/README.md" if [ $? -eq 0 ] ; then s="$rlnk/" @@ -198,14 +198,14 @@ ck_netdata_relative () { else cd - >/dev/null if [ -f "$fpath/$rlnk" ] ; then - dbg "-- # (path/someotherfile) $rlnk" + dbg " - # (path/someotherfile) $rlnk" if [ "$fpath" = "." ] ; then s="https://github.com/netdata/netdata/tree/master/$rlnk" else s="https://github.com/netdata/netdata/tree/master/$fpath/$rlnk" fi else - echo "-- ERROR: $f - $rlnk is neither a file or a directory. Giving up!" + echo " - ERROR: $f - $rlnk is neither a file or a directory. Giving up!" EXITCODE=1 fi cd $DOCS_DIR >/dev/null @@ -229,29 +229,29 @@ checklinks () { if [[ $word =~ .*\]\(([^\(\) ]*)\).* ]] ; then lnk=$(echo "${BASH_REMATCH[1]}" | tr -d '<>') if [ -z "$lnk" ] ; then continue ; fi - dbg "-$lnk" + dbg " $lnk" case "$lnk" in - mailto:* ) dbg "-- Mailto link, ignoring" ;; + mailto:* ) dbg " - Mailto link, ignoring" ;; https://github.com/netdata/netdata/wiki* ) - dbg "-- Wiki Link $lnk" - if [ "$CHKWIKI" -eq 1 ] ; then echo "-- WARNING: $f - $lnk points to the wiki. Please replace it manually" ; fi + dbg " - Wiki Link $lnk" + if [ "$CHKWIKI" -eq 1 ] ; then echo " - WARNING: $f - $lnk points to the wiki. Please replace it manually" ; fi ;; https://github.com/netdata/netdata/????/master* ) - echo "-- ERROR: $f - $lnk is an absolute link to a Netdata file. Please convert to relative." + echo " - ERROR: $f - $lnk is an absolute link to a Netdata file. Please convert to relative." EXITCODE=1 ;; http* ) - dbg "-- External link $lnk" + dbg " - External link $lnk" if [ "$CHKEXTERNAL" -eq 1 ] ; then testURL "$lnk" if [ $? -eq 1 ] ; then - echo "-- ERROR: $f - $lnk is a broken link" + echo " - ERROR: $f - $lnk is a broken link" EXITCODE=1 fi fi ;; * ) - dbg "-- Relative link $lnk" + dbg " - Relative link $lnk" if [ "$CHKRELATIVE" -eq 1 ] ; then ck_netdata_relative "$f" "$lnk" ; fi ;; esac diff --git a/docs/generator/custom/themes/material/partials/header.html b/docs/generator/custom/themes/material/partials/header.html index 54086ecf5..85f874905 100644 --- a/docs/generator/custom/themes/material/partials/header.html +++ b/docs/generator/custom/themes/material/partials/header.html @@ -92,6 +92,7 @@ <select id="sel" onchange="setLanguage(this);" style="vertical-align: middle; background-color: #3f51b5; color: white; border: none;"> <option href="#" value='en'>English</option> <option href="#" value='zh'>中文</option> + <option href="#" value='pt'>Portugues-Brasil</option> </select> </div> diff --git a/docs/getting-started.md b/docs/getting-started.md new file mode 100644 index 000000000..ce3558192 --- /dev/null +++ b/docs/getting-started.md @@ -0,0 +1,233 @@ +# Getting started guide + +Thanks for trying Netdata! In this guide, we'll quickly walk you through the first steps you should take after getting +Netdata installed. + +Netdata can collect thousands of metrics in real-time without any configuration, but there are some valuable things to +know to get the most of out Netdata based on your needs. + +> If you haven't installed Netdata yet, visit the [installation instructions](../packaging/installer) for details, +> including our one-liner script, which automatically installs Netdata on almost all Linux distributions. + +## Access the dashboard + +Open up your web browser of choice and navigate to `http://YOUR-HOST:19999`. Welcome to Netdata! + + + +**What's next?**: + +- Read more about the [standard Netdata dashboard](../web/gui/). +- Learn all the specifics of [using charts](../web/README.md#using-charts) or the differences between [charts, + context, and families](../web/README.md#charts-contexts-families). + +## Configuration basics + +Netdata primarily uses the `netdata.conf` file for custom configurations. + +On most systems, you can find that file at `/etc/netdata/netdata.conf`. + +> Some operating systems will place your `netdata.conf` at `/opt/netdata/etc/netdata/netdata.conf`, so check there if +> you find nothing at `/etc/netdata/netdata.conf`. + +The `netdata.conf` file is broken up into various sections, such as `[global]`, `[web]`, `[registry]`, and more. By +default, most options are commented, so you'll have to uncomment them (remove the `#`) for Netdata to recognize your +change. + +Once you save your changes, [restart Netdata](#start-stop-and-restart-netdata) to load your new configuration. + +**What's next?**: + +- [Change how long Netdata stores metrics](#change-how-long-netdata-stores-metrics) by either increasing the `history` + option or switching to the database engine. +- Move Netdata's dashboard to a [different port](https://docs.netdata.cloud/web/server/) or enable TLS/HTTPS + encryption. +- See all the `netdata.conf` options in our [daemon configuration documentation](../daemon/config/). +- Run your own [registry](../registry/README.md#run-your-own-registry). + +## Collect data from more sources + +When Netdata _starts_, it auto-detects dozens of **data sources**, such as database servers, web servers, and more. To +auto-detect and collect metrics from a service or application you just installed, you need to [restart +Netdata](#start-stop-and-restart-netdata). + +> There is one exception: When Netdata is running on the host (as in not in a container itself), it will always +> auto-detect containers and VMs. + +However, auto-detection only works if you installed the source using its standard installation procedure. If Netdata +isn't collecting metrics after a restart, your source probably isn't configured correctly. Look at the [external plugin +documentation](../collectors/plugins.d/) to find the appropriate module for your source. Those pages will contain more +information about how to configure your source for auto-detection. + +Some modules, like `chrony`, are disabled by default and must be enabled manually for auto-detection to work. + +Once Netdata detects a valid source of data, it will continue trying to collect data from it. For example, if +Netdata is collecting data from an Nginx web server, and you shut Nginx down, Netdata will collect new data as soon as +you start the web server back up—no restart necessary. + +### Configuring plugins + +Even if Netdata auto-detects your service/application, you might want to configure what, or how often, Netdata is +collecting data. + +Netdata uses **internal** and **external** plugins to collect data. Internal plugins run within the Netdata dæmon, while +external plugins are independent processes that send metrics to Netdata over pipes. There are also plugin +**orchestrators**, which are external plugins with one or more data collection **modules**. + +You can configure both internal and external plugins, along with the individual modules. There are many ways to do so: + +- In `netdata.conf`, `[plugins]` section: Enable or disable internal or external plugins with `yes` or `no`. +- In `netdata.conf`, `[plugin:XXX]` sections: Each plugin has a section for changing collection frequency or passing + options to the plugin. +- In `.conf` files for each external plugin: For example, at `/etc/netdata/python.d.conf`. +- In `.conf` files for each module : For example, at `/etc/netdata/python.d/nginx.conf`. + +It's complex, so let's walk through an example of the various `.conf` files responsible for collecting data from an +Nginx web server using the `nginx` module and the `python.d` plugin orchestrator. + +First, you can enable or disable the `python.d` plugin entirely in `netdata.conf`. + +```conf +[plugins] + # Enabled + python.d = yes + # Disabled + python.d = no +``` + +You can also configure the entire `python.d` external plugin via the `[plugin:python.d]` section in `netdata.conf`. +Here, you can change how often Netdata uses `python.d` to collect metrics or pass other command options: + +```conf +[plugin:python.d] + update every = 1 + command options = +``` + +The `python.d` plugin has a separate configuration file at `/etc/netdata/python.d.conf` for enabling and disabling +modules. You can use the `edit-config` script to edit the file, or open it with your text editor of choice: + +```bash +sudo /etc/netdata/edit-config python.d.conf +``` + +Finally, the `nginx` module has a configuration file called `nginx.conf` in the `python.d` folder. Again, use +`edit-config` or your editor of choice: + +```bash +sudo /etc/netdata/edit-config python.d/nginx.conf +``` + +In the `nginx.conf` file, you'll find additional options. The default works in most situations, but you may need to make +changes based on your particular Nginx setup. + +**What's next?**: + +- Look at the [full list of data collection modules](Add-more-charts-to-netdata.md#available-data-collection-modules) + to configure your sources for auto-detection and monitoring. +- Improve the [performance](Performance.md) of Netdata on low-memory systems. +- Configure `systemd` to expose [systemd services + utilization](../collectors/cgroups.plugin/README.md#monitoring-systemd-services) metrics automatically. +- [Reconfigure individual charts](../daemon/config/README.md#per-chart-configuration) in `netdata.conf`. + +## Health monitoring and alarms + +Netdata comes with hundreds of health monitoring alarms for detecting anomalies on production servers. If you're running +Netdata on a workstation, you might want to disable Netdata's alarms. + +Edit your `/etc/netdata/netdata.conf` file and set the following: + +```conf +[health] + enabled = no +``` + +If you want to keep health monitoring enabled, but turn email notifications off, edit your `health_alarm_notify.conf` +file with `edit-config`, or with your the text editor of your choice: + +```bash +sudo /etc/netdata/edit-config health_alarm_notify.conf +``` + +Find the `SEND_EMAIL="YES"` line and change it to `SEND_EMAIL="NO"`. + +**What's next?**: + +- Write your own health alarm using the [examples](../health/README.md#examples). +- Add a new notification method, like [Slack](../health/notifications/slack/). + +## Change how long Netdata stores metrics + +By default, Netdata stores 1 hour of historical metrics and uses about 25MB of RAM. + +If that's not enough for you, Netdata is quite adaptable to long-term storage of your system's metrics. + +There are two quick ways to increase the depth of historical metrics: increase the `history` value for the round-robin +that's enabled by default, or switch to the database engine. + +We have a tutorial that walks you through both options: [**Changing how long Netdata stores +metrics**](../docs/tutorials/longer-metrics-storage.md). + +**What's next?**: + +- Learn more about the [memory requirements for the database engine](../database/engine/README.md#memory-requirements) + to understand how much RAM/disk space you should commit to storing historical metrics. +- Read up on the memory requirements of the [round-robin database](../database/), or figure out whether your system + has KSM enabled, which can [reduce the default database's memory usage](../database/README.md#ksm) by about 60%. + +## Monitoring multiple systems with Netdata + +If you have Netdata installed on multiple systems, you can have them all appear in the **My nodes** menu at the top-left +corner of the dashboard. + +To show all your servers in that menu, you need to [register for or sign in](../docs/netdata-cloud/signing-in.md) to +[Netdata Cloud](../docs/netdata-cloud/) from each system. Each system will then appear in the **My nodes** menu, which +you can use to navigate between your systems quickly. + +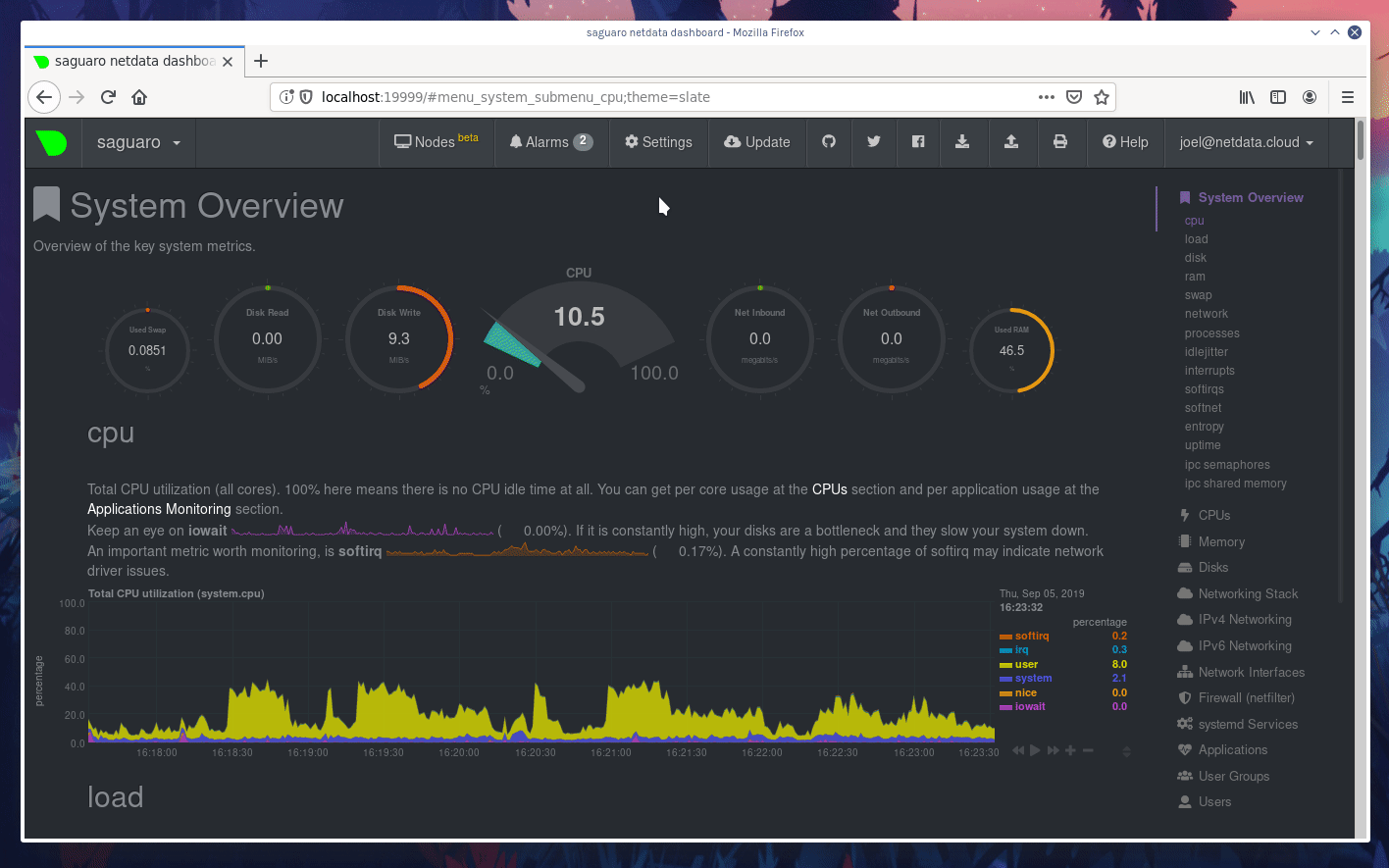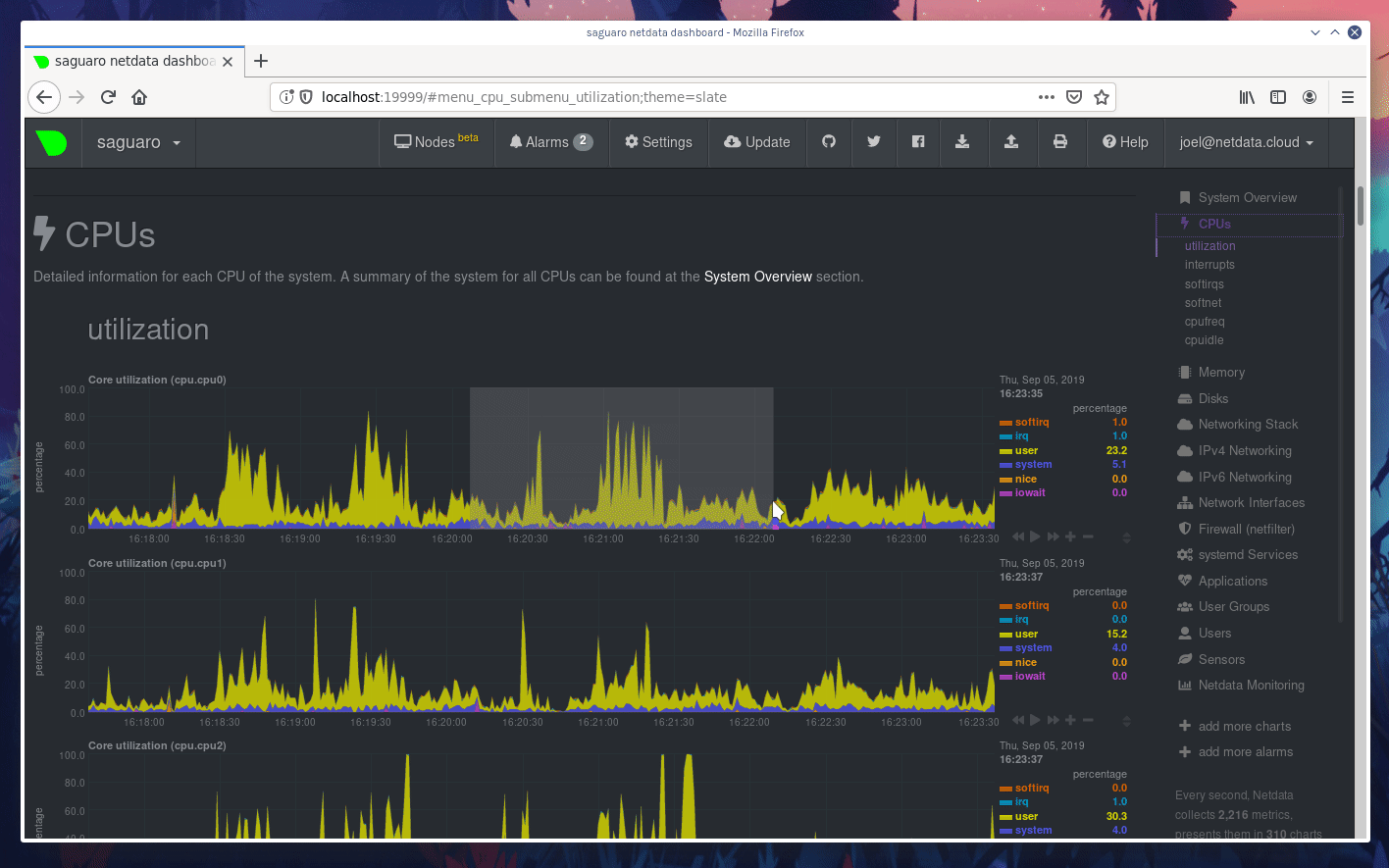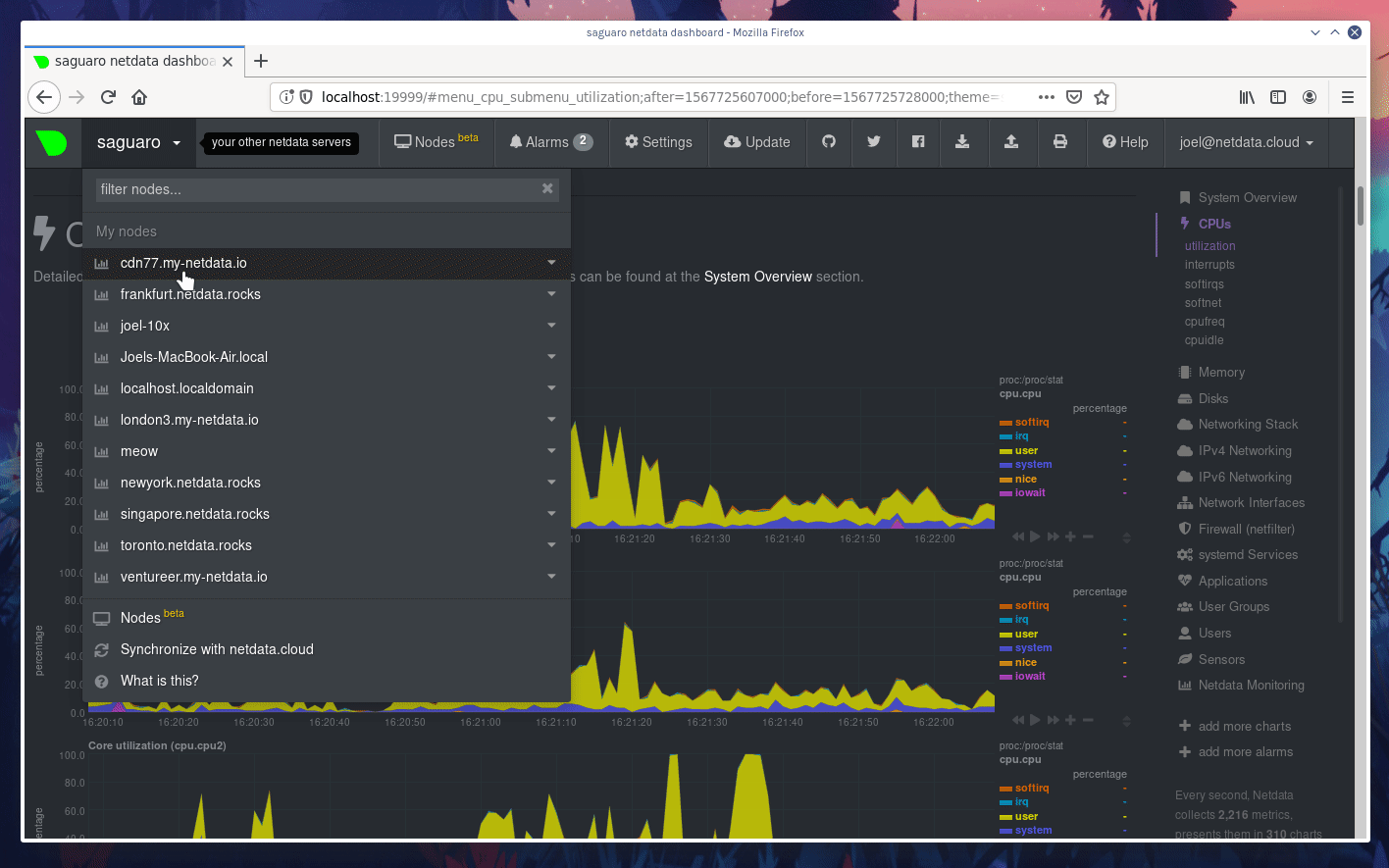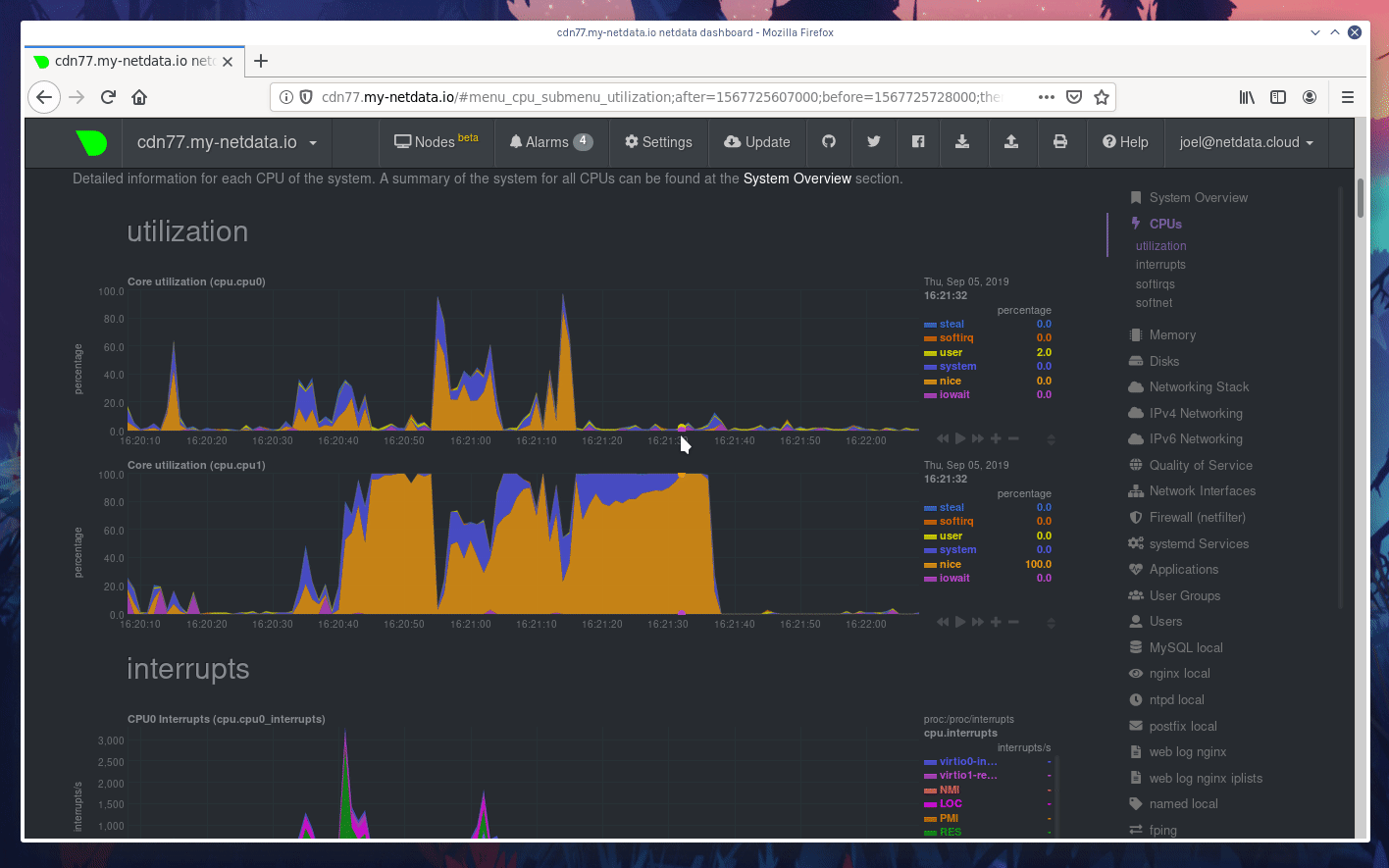 + +Whenever you pan, zoom, highlight, select, or pause a chart, Netdata will synchronize those settings with any other +agent you visit via the My nodes menu. Even your scroll position is synchronized, so you'll see the same charts and +respective data for easy comparisons or root cause analysis. + +You can now seamlessly track performance anomalies across your entire infrastructure! + +**What's next?**: + +- Read up on how the [Netdata Cloud registry works](../registry/), and what kind of data it stores and sends to your + web browser. +- Familiarize yourself with the [Nodes View](../docs/netdata-cloud/nodes-view.md) + +## Start, stop, and restart Netdata + +When you install Netdata, it's configured to start at boot, and stop and restart/shutdown. You shouldn't need to start +or stop Netdata manually, but you will probably need to restart Netdata at some point. + +- To **start** Netdata, open a terminal and run `service netdata start`. +- To **stop** Netdata, run `service netdata stop`. +- To **restart** Netdata, run `service netdata restart`. + +The `service` command is a wrapper script that tries to use your system's preferred method of starting or stopping +Netdata based on your system. But, if either of those commands fails, try using the equivalent commands for `systemd` +and `init.d`: + +- **systemd**: `systemctl start netdata`, `systemctl stop netdata`, `systemctl restart netdata` +- **init.d**: `/etc/init.d/netdata start`, `/etc/init.d/netdata stop`, `/etc/init.d/netdata restart` + +## What's next? + +Even after you've configured `netdata.conf`, tweaked alarms, learned the basics of performance troubleshooting, and +added all your systems to the **My nodes** menu, you've just gotten started with Netdata. + +Take a look at some more advanced features and configurations: + +- Centralize Netdata metrics from many systems with [streaming](../streaming) +- Enable long-term archiving of Netdata metrics via [backends](../backends) to time-series databases. +- Improve security by putting Netdata behind an [Nginx proxy with SSL](Running-behind-nginx.md). + +Or, learn more about how you can contribute to [Netdata core](../CONTRIBUTING.md) or our +[documentation](../docs/contributing/contributing-documentation.md)! + +[](<>) diff --git a/docs/high-performance-netdata.md b/docs/high-performance-netdata.md index 3611fee38..3b33c03f1 100644 --- a/docs/high-performance-netdata.md +++ b/docs/high-performance-netdata.md @@ -126,7 +126,7 @@ You can check limits with following commands: ```sh cat /proc/$(ps aux | grep "nginx: master process" | grep -v grep | awk '{print $2}')/limits | grep "Max open files" -cat /proc/$(ps aux | grep "netdata" | head -n1 | grep -v grep | awk '{print $2}')/limits | grep "Max open files" +cat /proc/$(ps aux | grep "\/[n]etdata " | head -n1 | grep -v grep | awk '{print $2}')/limits | grep "Max open files" ``` View of the files: diff --git a/docs/netdata-security.md b/docs/netdata-security.md index e3ce6d56c..59c1ae29b 100644 --- a/docs/netdata-security.md +++ b/docs/netdata-security.md @@ -86,6 +86,41 @@ In Netdata v1.9+ there is also access list support, like this: allow connections from = localhost 10.* 192.168.* ``` +#### Fine-grainined access control + +The access list support allows filtering of all incoming connections, by specific IP addresses, ranges +or validated DNS lookups. Only connections that match an entry on the list will be allowed: + +``` +[web] + allow connections from = localhost 192.168.* 1.2.3.4 homeip.net +``` + +Connections from the IP addresses are allowed if the connection IP matches one of the patterns given. +The alias localhost is alway checked against 127.0.0.1, any other symbolic names need to resolve in +both directions using DNS. In the above example the IP address of `homeip.net` must reverse DNS resolve +to the incoming IP address and a DNS lookup on `homeip.net` must return the incoming IP address as +one of the resolved addresses. + +More specific control of what each incoming connection can do can be specified through the access control +list settings: + +``` +[web] + allow connections from = 160.1.* + allow badges from = 160.1.1.2 + allow streaming from = 160.1.2.* + allow management from = control.subnet.ip + allow netdata.conf from = updates.subnet.ip + allow dashboard from = frontend.subnet.ip +``` + +In this example only connections from `160.1.x.x` are allowed, only the specific IP address `160.1.1.2` +can access badges, only IP addresses in the smaller range `160.1.2.x` can stream data. The three +hostnames shown can access specific features, this assumes that DNS is setup to resolve these names +to IP addresses within the `160.1.x.x` range and that reverse DNS is setup for these hosts. + + #### Use an authenticating web server in proxy mode Use one web server to provide authentication in front of **all your Netdata servers**. So, you will be accessing all your Netdata with URLs like `http://{HOST}/netdata/{NETDATA_HOSTNAME}/` and authentication will be shared among all of them (you will sign-in once for all your servers). Instructions are provided on how to set the proxy configuration to have Netdata run behind [nginx](Running-behind-nginx.md), [Apache](Running-behind-apache.md), [lighthttpd](Running-behind-lighttpd.md#netdata-via-lighttpd-v14x) and [Caddy](Running-behind-caddy.md#netdata-via-caddy). diff --git a/docs/tutorials/longer-metrics-storage.md b/docs/tutorials/longer-metrics-storage.md new file mode 100644 index 000000000..e227f5bda --- /dev/null +++ b/docs/tutorials/longer-metrics-storage.md @@ -0,0 +1,155 @@ +# Change how long Netdata stores metrics + +Netdata helps you collect thousands of system and application metrics every second, but what about storing them for the +long term? + +Many people think Netdata can only store about an hour's worth of real-time metrics, but that's just the default +configuration today. With the right settings, Netdata is quite capable of efficiently storing hours or days worth of +historical, per-second metrics without having to rely on a [backend](../../backends/). + +This tutorial gives two options for configuring Netdata to store more metrics. We recommend the [**database +engine**](#using-the-database-engine), as it will soon be the default configuration. However, you can stick with the +current default **round-robin database** if you prefer. + +Let's get started. + +## Using the database engine + +The database engine uses RAM to store recent metrics while also using a "spill to disk" feature that takes advantage of +available disk space for long-term metrics storage.This feature of the database engine allows you to store a much larger +dataset than your system's available RAM. + +The database engine will eventually become the default method of retaining metrics, but until then, you can switch to +the database engine by changing a single option. + +Edit your `netdata.conf` file and change the `memory mode` setting to `dbengine`: + +```conf +[global] + memory mode = dbengine +``` + +Next, restart Netdata. On Linux systems, we recommend running `sudo service netdata restart`. You're now using the +database engine! + +> Learn more about how we implemented the database engine, and our vision for its future, on our blog: [_How and why +> we're bringing long-term storage to Netdata_](https://blog.netdata.cloud/posts/db-engine/). + +What makes the database engine efficient? While it's structured like a traditional database, the database engine splits +data between RAM and disk. The database engine caches and indexes data on RAM to keep memory usage low, and then +compresses older metrics onto disk for long-term storage. + +When the Netdata dashboard queries for historical metrics, the database engine will use its cache, stored in RAM, to +return relevant metrics for visualization in charts. + +Now, given that the database engine uses _both_ RAM and disk, there are two other settings to consider: `page cache +size` and `dbengine disk space`. + +```conf +[global] + page cache size = 32 + dbengine disk space = 256 +``` + +`page cache size` sets the maximum amount of RAM (in MiB) the database engine will use for caching and indexing. +`dbengine disk space` sets the maximum disk space (again, in MiB) the database engine will use for storing compressed +metrics. + +Based on our testing, these default settings will retain about two day's worth of metrics when Netdata collects 2,000 +metrics every second. + +If you'd like to change these options, read more about the [database engine's memory +footprint](../../database/engine/README.md#memory-requirements). + +With the database engine active, you can back up your `/var/cache/netdata/dbengine/` folder to another location for +redundancy. + +Now that you know how to switch to the database engine, let's cover the default round-robin database for those who +aren't ready to make the move. + +## Using the round-robin database + +By default, Netdata uses a round-robin database to store 1 hour of per-second metrics. Here's the default setting for +`history` in the `netdata.conf` file that comes pre-installed with Netdata. + +```conf +[global] + history = 3600 +``` + +One hour has 3,600 seconds, hence the `3600` value! + +To increase your historical metrics, you can increase `history` to the number of seconds you'd like to store: + +```conf +[global] + # 2 hours = 2 * 60 * 60 = 7200 seconds + history = 7200 + # 4 hours = 4 * 60 * 60 = 14440 seconds + history = 14440 + # 24 hours = 24 * 60 * 60 = 86400 seconds + history = 86400 +``` + +And so on. + +Next, check to see how many metrics Netdata collects on your system, and how much RAM that uses. Visit the Netdata +dashboard and look at the bottom-right corner of the interface. You'll find a sentence similar to the following: + +> Every second, Netdata collects 1,938 metrics, presents them in 299 charts and monitors them with 81 alarms. Netdata is +> using 25 MB of memory on **netdata-linux** for 1 hour, 6 minutes and 36 seconds of real-time history. + +On this desktop system, using a Ryzen 5 1600 and 16GB of RAM, the round-robin databases uses 25 MB of RAM to store just +over an hour's worth of data for nearly 2,000 metrics. + +To increase the `history` option, you need to edit your `netdata.conf` file and increase the `history` setting. In most +installations, you'll find it at `/etc/netdata/netdata.conf`, but some operating systems place it at +`/opt/netdata/etc/netdata/netdata.conf`. + +Use `/etc/netdata/edit-config netdata.conf`, or your favorite text editor, to replace `3600` with the number of seconds +you'd like to store. + +You should base this number on two things: How much history you need for your use case, and how much RAM you're willing +to dedicate to Netdata. + +> Take care when you change the `history` option on production systems. Netdata is configured to stop its process if +> your system starts running out of RAM, but you can never be too careful. Out of memory situations are very bad. + +How much RAM will a longer history use? Let's use a little math. + +The round-robin database needs 4 bytes for every value Netdata collects. If Netdata collects metrics every second, +that's 4 bytes, per second, per metric. + +```text +4 bytes * X seconds * Y metrics = RAM usage in bytes +``` + +Let's assume your system collects 1,000 metrics per second. + +```text +4 bytes * 3600 seconds * 1,000 metrics = 14400000 bytes = 14.4 MB RAM +``` + +With that formula, you can calculate the RAM usage for much larger history settings. + +```conf +# 2 hours at 1,000 metrics per second +4 bytes * 7200 seconds * 1,000 metrics = 28800000 bytes = 28.8 MB RAM +# 2 hours at 2,000 metrics per second +4 bytes * 7200 seconds * 2,000 metrics = 57600000 bytes = 57.6 MB RAM +# 4 hours at 2,000 metrics per second +4 bytes * 14440 seconds * 2,000 metrics = 115520000 bytes = 115.52 MB RAM +# 24 hours at 1,000 metrics per second +4 bytes * 86400 seconds * 1,000 metrics = 345600000 bytes = 345.6 MB RAM +``` + +## What's next? + +Now that you have either configured database engine or round-robin database engine to store more metrics, you'll +probably want to see it in action! + +For more information about how to pan charts to view historical metrics, see our documentation on [using +charts](../../web/README.md#using-charts). + +And if you'd now like to reduce Netdata's resource usage, view our [performance guide](../../docs/Performance.md) for +our best practices on optimization. diff --git a/docs/what-is-netdata.md b/docs/what-is-netdata.md index b134dc2ca..e9b4d1598 100644 --- a/docs/what-is-netdata.md +++ b/docs/what-is-netdata.md @@ -43,7 +43,7 @@ We provide docker images for the most common architectures. These are statistics ### Registry -When you install multiple Netdata, they are integrated into **one distributed application**, via a [Netdata registry](../registry/#registry). This is a web browser feature and it allows us to count the number of unique users and unique Netdata servers installed. The following information comes from the global public Netdata registry we run: +When you install multiple Netdata, they are integrated into **one distributed application**, via a [Netdata registry](../registry/). This is a web browser feature and it allows us to count the number of unique users and unique Netdata servers installed. The following information comes from the global public Netdata registry we run: [](https://registry.my-netdata.io/#menu_netdata_submenu_registry) [](https://registry.my-netdata.io/#menu_netdata_submenu_registry) [](https://registry.my-netdata.io/#menu_netdata_submenu_registry) @@ -91,12 +91,12 @@ This is how it works: |Function|Description|Documentation| |:------:|:----------|:-----------:| -|**Collect**|Multiple independent data collection workers are collecting metrics from their sources using the optimal protocol for each application and push the metrics to the database. Each data collection worker has lockless write access to the metrics it collects.|[`collectors`](../collectors/#data-collection-plugins)| -|**Store**|Metrics are stored in RAM in a round robin database (ring buffer), using a custom made floating point number for minimal footprint.|[`database`](../database/#database)| -|**Check**|A lockless independent watchdog is evaluating **health checks** on the collected metrics, triggers alarms, maintains a health transaction log and dispatches alarm notifications.|[`health`](../health/#health-monitoring)| -|**Stream**|An lockless independent worker is streaming metrics, in full detail and in real-time, to remote Netdata servers, as soon as they are collected.|[`streaming`](../streaming/#streaming-and-replication)| +|**Collect**|Multiple independent data collection workers are collecting metrics from their sources using the optimal protocol for each application and push the metrics to the database. Each data collection worker has lockless write access to the metrics it collects.|[`collectors`](../collectors/)| +|**Store**|Metrics are stored in RAM in a round robin database (ring buffer), using a custom made floating point number for minimal footprint.|[`database`](../database/)| +|**Check**|A lockless independent watchdog is evaluating **health checks** on the collected metrics, triggers alarms, maintains a health transaction log and dispatches alarm notifications.|[`health`](../health/)| +|**Stream**|An lockless independent worker is streaming metrics, in full detail and in real-time, to remote Netdata servers, as soon as they are collected.|[`streaming`](../streaming/)| |**Archive**|A lockless independent worker is down-sampling the metrics and pushes them to **backend** time-series databases.|[`backends`](../backends/)| -|**Query**|Multiple independent workers are attached to the [internal web server](../web/server/#web-server), servicing API requests, including [data queries](../web/api/queries/#database-queries).|[`web/api`](../web/api/#api)| +|**Query**|Multiple independent workers are attached to the [internal web server](../web/server/), servicing API requests, including [data queries](../web/api/queries/README.md).|[`web/api`](../web/api/)| The result is a highly efficient, low latency system, supporting multiple readers and one writer on each metric. |