1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
|
<!--
title: "Anomaly Advisor"
description: "Quickly find anomalous metrics anywhere in your infrastructure."
custom_edit_url: "https://github.com/netdata/netdata/blob/master/docs/cloud/insights/anomaly-advisor.md"
sidebar_label: "Anomaly Advisor"
learn_status: "Published"
learn_topic_type: "Tasks"
learn_rel_path: "Operations"
-->
# Anomaly Advisor
import ReactPlayer from 'react-player'
The Anomaly Advisor feature lets you quickly surface potentially anomalous metrics and charts related to a particular highlight window of
interest.
<ReactPlayer playing true controls true url='https://user-images.githubusercontent.com/24860547/165943403-1acb9759-7446-4704-8955-c566d04ad7ab.mp4' />
## Getting Started
If you are running a Netdata version higher than `v1.35.0-29-nightly` you will be able to use the Anomaly Advisor out of the box with zero configuration. If you are on an earlier Netdata version you will need to first enable ML on your nodes by following the steps below.
To enable the Anomaly Advisor you must first enable ML on your nodes via a small config change in `netdata.conf`. Once the anomaly detection models have trained on the Agent (with default settings this takes a couple of hours until enough data has been seen to train the models) you will then be able to enable the Anomaly Advisor feature in Netdata Cloud.
### Enable ML on Netdata Agent
To enable ML on your Netdata Agent, you need to edit the `[ml]` section in your `netdata.conf` to look something like the following example.
```bash
[ml]
enabled = yes
```
At a minimum you just need to set `enabled = yes` to enable ML with default params. More details about configuration can be found in the [Netdata Agent ML docs](https://github.com/netdata/netdata/blob/master/src/ml/README.md#configuration).
When you have finished your configuration, restart Netdata with a command like `sudo systemctl restart netdata` for the config changes to take effect. You can find more info on restarting Netdata [here](https://github.com/netdata/netdata/blob/master/packaging/installer/README.md#maintaining-a-netdata-agent-installation).
After a brief delay, you should see the number of `trained` dimensions start to increase on the "dimensions" chart of the "Anomaly Detection" menu on the Overview page. By default the `minimum num samples to train = 3600` parameter means at least 1 hour of data is required to train initial models, but you could set this to `900` if you want to train initial models quicker but on less data. Over time, they will retrain on up to `maximum num samples to train = 14400` (4 hours by default), but you could increase this is you wanted to train on more data.
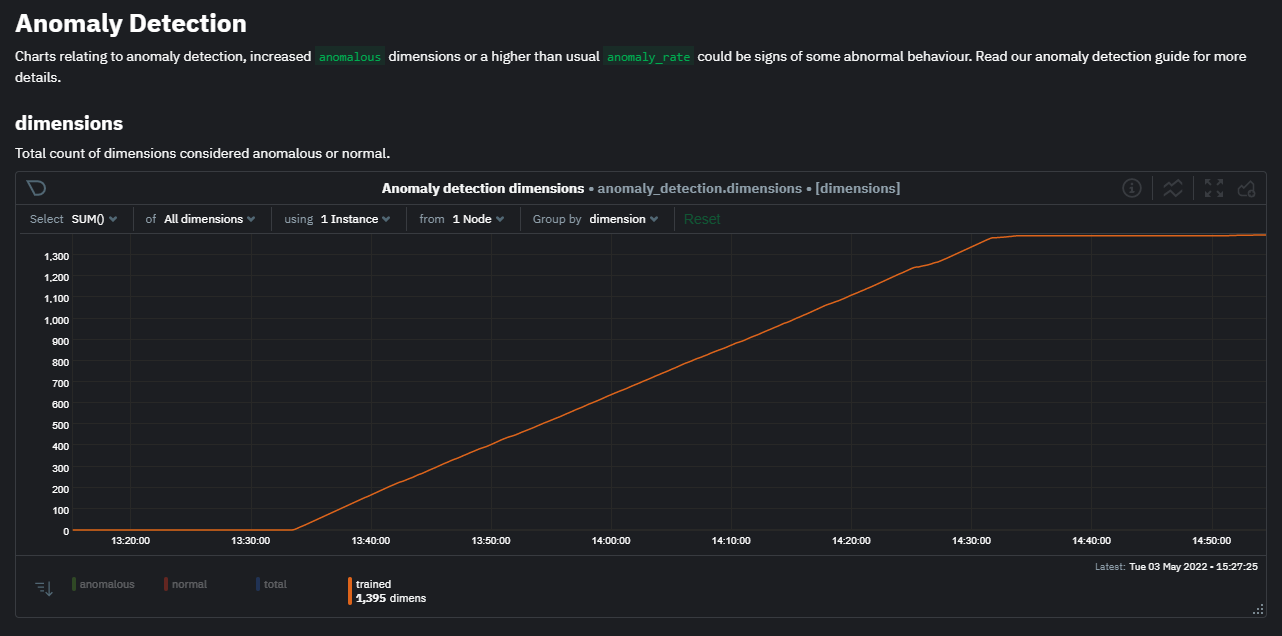
Once this line flattens out all configured metrics should have models trained and predicting anomaly scores each second, ready to be used by the new "anomalies" tab of the Anomaly Advisor.
## Using Anomaly Advisor
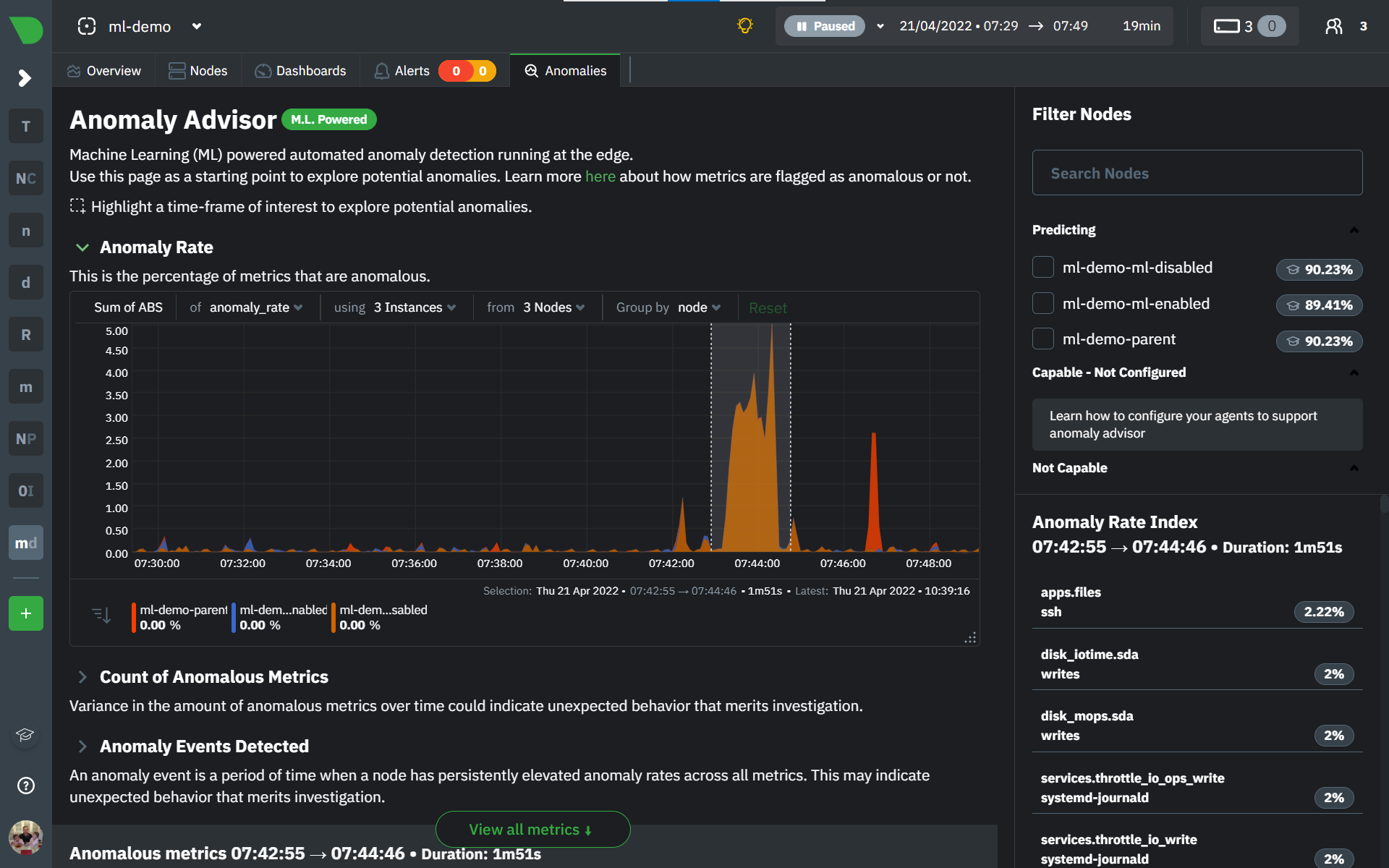
To use the Anomaly Advisor, go to the "anomalies" tab. Once you highlight a particular timeframe of interest, a selection of the most anomalous dimensions will appear below.
The aim here is to surface the most anomalous metrics in the space or room for the highlighted window to try and cut down on the amount of manual searching required to get to the root cause of your issues.
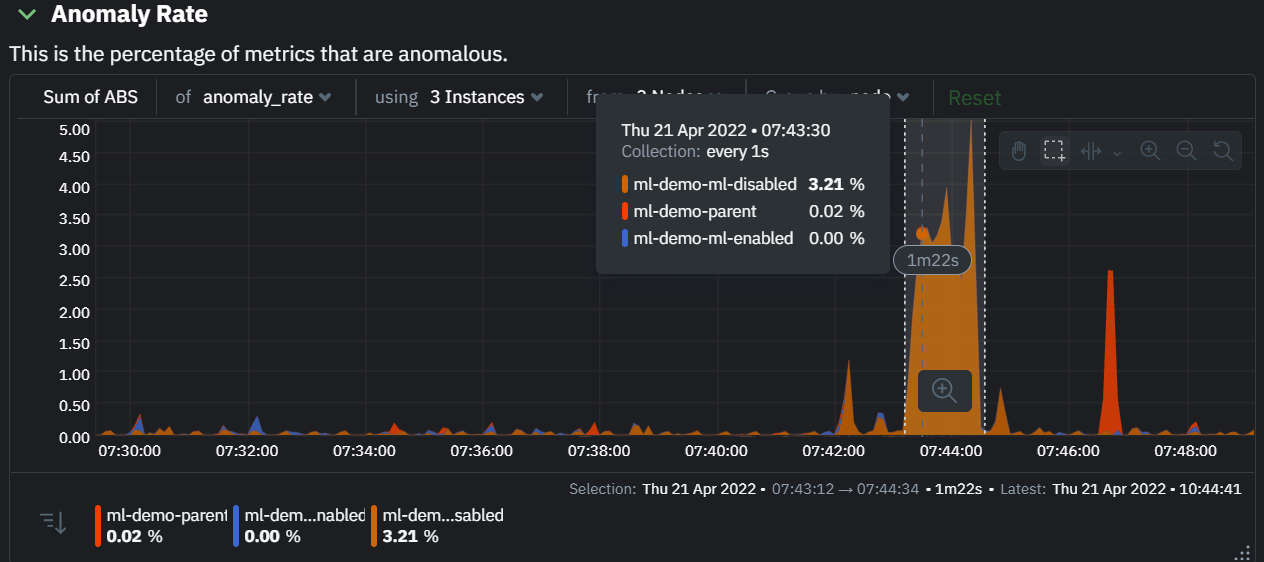
The "Anomaly Rate" chart shows the percentage of anomalous metrics over time per node. For example, in the following image, 3.21% of the metrics on the "ml-demo-ml-disabled" node were considered anomalous. This elevated anomaly rate could be a sign of something worth investigating.
**Note**: in this example the anomaly rates for this node are actually being calculated on the parent it streams to, you can run ml on the Agent itselt or on a parent the Agent stream to. Read more about the various configuration options in the [Agent docs](https://github.com/netdata/netdata/blob/master/src/ml/README.md).
The "Count of Anomalous Metrics" chart (collapsed by default) shows raw counts of anomalous metrics per node so may often be similar to the anomaly rate chart, apart from where nodes may have different numbers of metrics.
The "Anomaly Events Detected" chart (collapsed by default) shows if the anomaly rate per node was sufficiently elevated to trigger a node level anomaly. Anomaly events will appear slightly after the anomaly rate starts to increase in the timeline, this is because a significant number of metrics in the node need to be anomalous before an anomaly event is triggered.
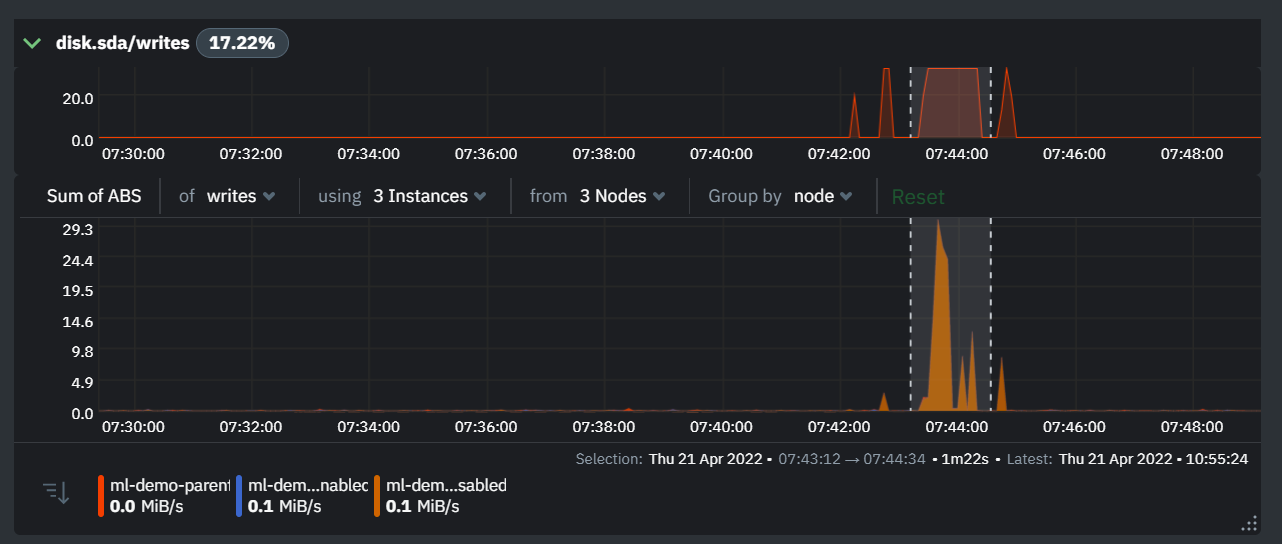
Once you have highlighted a window of interest, you should see an ordered list of anomaly rate sparklines in the "Anomalous metrics" section like below.
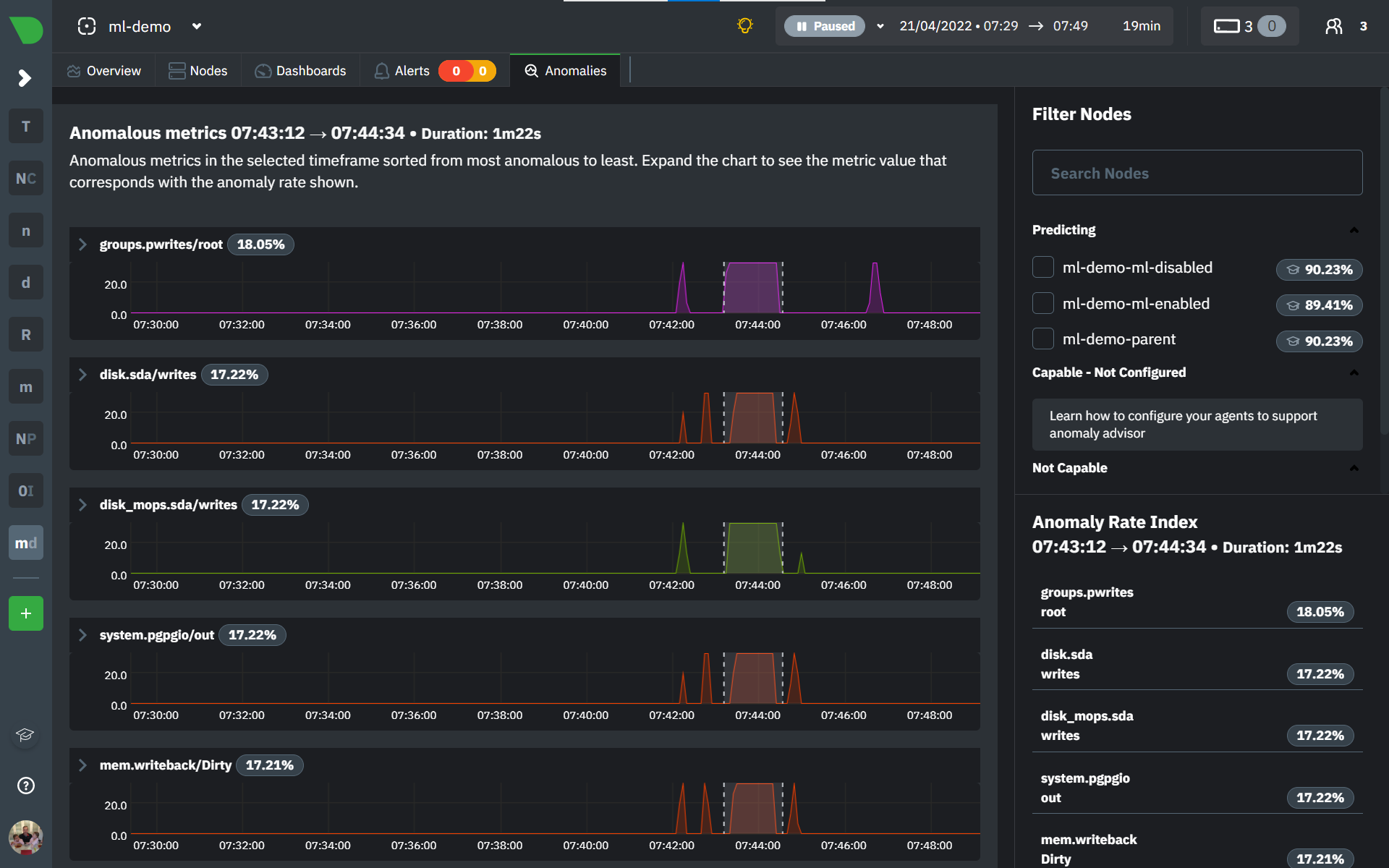
You can expand any sparkline chart to see the underlying raw data to see how it relates to the corresponding anomaly rate.
On the upper right hand side of the page you can select which nodes to filter on if you wish to do so. The ML training status of each node is also displayed.
On the lower right hand side of the page an index of anomaly rates is displayed for the highlighted timeline of interest. The index is sorted from most anomalous metric (highest anomaly rate) to least (lowest anomaly rate). Clicking on an entry in the index will scroll the rest of the page to the corresponding anomaly rate sparkline for that metric.
### Usage Tips
- If you are interested in a subset of specific nodes then filtering to just those nodes before highlighting tends to give better results. This is because when you highlight a region, Netdata Cloud will ask the Agents for a ranking over all metrics so if you can filter this early to just the subset of nodes you are interested in, less 'averaging' will occur and so you might be a less noisy ranking.
- Ideally try and highlight close to a spike or window of interest so that the resulting ranking can narrow in more easily on the timeline you are interested in.
You can read more detail on how anomaly detection in the Netdata Agent works in our [Agent docs](https://github.com/netdata/netdata/blob/master/src/ml/README.md).
🚧 **Note**: This functionality is still **under active development** and considered experimental. We dogfood it internally and among early adopters within the Netdata community to build the feature. If you would like to get involved and help us with feedback, you can reach us through any of the following channels:
- Email us at analytics-ml-team@netdata.cloud
- Comment on the [beta launch post](https://community.netdata.cloud/t/anomaly-advisor-beta-launch/2717) in the Netdata community
- Join us in the [🤖-ml-powered-monitoring](https://discord.gg/4eRSEUpJnc) channel of the Netdata discord.
- Or open a discussion in GitHub if that's more your thing
|
