
diff options
| author | Daniel Baumann <daniel.baumann@progress-linux.org> | 2023-05-08 16:27:08 +0000 |
|---|---|---|
| committer | Daniel Baumann <daniel.baumann@progress-linux.org> | 2023-05-08 16:27:08 +0000 |
| commit | 81581f9719bc56f01d5aa08952671d65fda9867a (patch) | |
| tree | 0f5c6b6138bf169c23c9d24b1fc0a3521385cb18 /docs/guides/monitor | |
| parent | Releasing debian version 1.38.1-1. (diff) | |
| download | netdata-81581f9719bc56f01d5aa08952671d65fda9867a.tar.xz netdata-81581f9719bc56f01d5aa08952671d65fda9867a.zip | |
Merging upstream version 1.39.0.
Signed-off-by: Daniel Baumann <daniel.baumann@progress-linux.org>
Diffstat (limited to 'docs/guides/monitor')
| -rw-r--r-- | docs/guides/monitor/anomaly-detection-python.md | 189 | ||||
| -rw-r--r-- | docs/guides/monitor/anomaly-detection.md | 19 | ||||
| -rw-r--r-- | docs/guides/monitor/dimension-templates.md | 181 | ||||
| -rw-r--r-- | docs/guides/monitor/kubernetes-k8s-netdata.md | 16 | ||||
| -rw-r--r-- | docs/guides/monitor/lamp-stack.md | 24 | ||||
| -rw-r--r-- | docs/guides/monitor/pi-hole-raspberry-pi.md | 36 | ||||
| -rw-r--r-- | docs/guides/monitor/process.md | 50 | ||||
| -rw-r--r-- | docs/guides/monitor/raspberry-pi-anomaly-detection.md | 37 | ||||
| -rw-r--r-- | docs/guides/monitor/statsd.md | 298 | ||||
| -rw-r--r-- | docs/guides/monitor/stop-notifications-alarms.md | 92 | ||||
| -rw-r--r-- | docs/guides/monitor/visualize-monitor-anomalies.md | 142 |
11 files changed, 38 insertions, 1046 deletions
diff --git a/docs/guides/monitor/anomaly-detection-python.md b/docs/guides/monitor/anomaly-detection-python.md deleted file mode 100644 index d6d27f4e5..000000000 --- a/docs/guides/monitor/anomaly-detection-python.md +++ /dev/null @@ -1,189 +0,0 @@ -<!-- -title: "Detect anomalies in systems and applications" -description: "Detect anomalies in any system, container, or application in your infrastructure with machine learning and the open-source Netdata Agent." -image: /img/seo/guides/monitor/anomaly-detection.png -author: "Joel Hans" -author_title: "Editorial Director, Technical & Educational Resources" -author_img: "/img/authors/joel-hans.jpg" -custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/guides/monitor/anomaly-detection-python.md ---> - -# Detect anomalies in systems and applications - -Beginning with v1.27, the [open-source Netdata Agent](https://github.com/netdata/netdata) is capable of unsupervised -[anomaly detection](https://en.wikipedia.org/wiki/Anomaly_detection) with machine learning (ML). As with all things -Netdata, the anomalies collector comes with preconfigured alarms and instant visualizations that require no query -languages or organizing metrics. You configure the collector to look at specific charts, and it handles the rest. - -Netdata's implementation uses a handful of functions in the [Python Outlier Detection (PyOD) -library](https://github.com/yzhao062/pyod/tree/master), which periodically runs a `train` function that learns what -"normal" looks like on your node and creates an ML model for each chart, then utilizes the -[`predict_proba()`](https://pyod.readthedocs.io/en/latest/api_cc.html#pyod.models.base.BaseDetector.predict_proba) and -[`predict()`](https://pyod.readthedocs.io/en/latest/api_cc.html#pyod.models.base.BaseDetector.predict) PyOD functions to -quantify how anomalous certain charts are. - -All these metrics and alarms are available for centralized monitoring in [Netdata Cloud](https://app.netdata.cloud). If -you choose to sign up for Netdata Cloud and [connect your nodes](https://github.com/netdata/netdata/blob/master/claim/README.md), you will have the ability to run -tailored anomaly detection on every node in your infrastructure, regardless of its purpose or workload. - -In this guide, you'll learn how to set up the anomalies collector to instantly detect anomalies in an Nginx web server -and/or the node that hosts it, which will give you the tools to configure parallel unsupervised monitors for any -application in your infrastructure. Let's get started. - -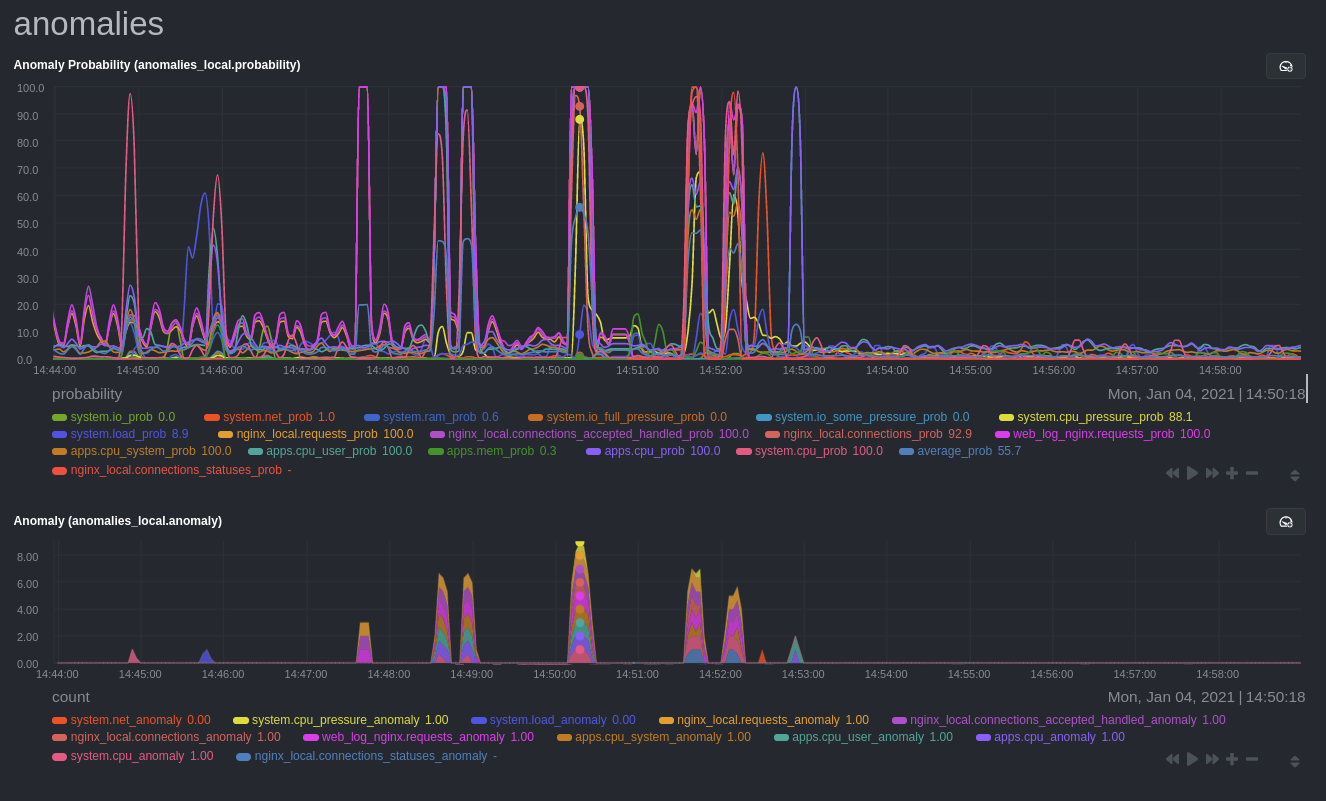 - -## Prerequisites - -- A node running the Netdata Agent. If you don't yet have that, [get Netdata](https://github.com/netdata/netdata/blob/master/docs/get-started.mdx). -- A Netdata Cloud account. [Sign up](https://app.netdata.cloud) if you don't have one already. -- Familiarity with configuring the Netdata Agent with [`edit-config`](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md). -- _Optional_: An Nginx web server running on the same node to follow the example configuration steps. - -## Install required Python packages - -The anomalies collector uses a few Python packages, available with `pip3`, to run ML training. It requires -[`numba`](http://numba.pydata.org/), [`scikit-learn`](https://scikit-learn.org/stable/), -[`pyod`](https://pyod.readthedocs.io/en/latest/), in addition to -[`netdata-pandas`](https://github.com/netdata/netdata-pandas), which is a package built by the Netdata team to pull data -from a Netdata Agent's API into a [Pandas](https://pandas.pydata.org/). Read more about `netdata-pandas` on its [package -repo](https://github.com/netdata/netdata-pandas) or in Netdata's [community -repo](https://github.com/netdata/community/tree/main/netdata-agent-api/netdata-pandas). - -```bash -# Become the netdata user -sudo su -s /bin/bash netdata - -# Install required packages for the netdata user -pip3 install --user netdata-pandas==0.0.38 numba==0.50.1 scikit-learn==0.23.2 pyod==0.8.3 -``` - -> If the `pip3` command fails, you need to install it. For example, on an Ubuntu system, use `sudo apt install -> python3-pip`. - -Use `exit` to become your normal user again. - -## Enable the anomalies collector - -Navigate to your [Netdata config directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md#the-netdata-config-directory) and use `edit-config` -to open the `python.d.conf` file. - -```bash -sudo ./edit-config python.d.conf -``` - -In `python.d.conf` file, search for the `anomalies` line. If the line exists, set the value to `yes`. Add the line -yourself if it doesn't already exist. Either way, the final result should look like: - -```conf -anomalies: yes -``` - -[Restart the Agent](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md) with `sudo systemctl restart netdata`, or the [appropriate -method](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md) for your system, to start up the anomalies collector. By default, the -model training process runs every 30 minutes, and uses the previous 4 hours of metrics to establish a baseline for -health and performance across the default included charts. - -> 💡 The anomaly collector may need 30-60 seconds to finish its initial training and have enough data to start -> generating anomaly scores. You may need to refresh your browser tab for the **Anomalies** section to appear in menus -> on both the local Agent dashboard or Netdata Cloud. - -## Configure the anomalies collector - -Open `python.d/anomalies.conf` with `edit-conf`. - -```bash -sudo ./edit-config python.d/anomalies.conf -``` - -The file contains many user-configurable settings with sane defaults. Here are some important settings that don't -involve tweaking the behavior of the ML training itself. - -- `charts_regex`: Which charts to train models for and run anomaly detection on, with each chart getting a separate - model. -- `charts_to_exclude`: Specific charts, selected by the regex in `charts_regex`, to exclude. -- `train_every_n`: How often to train the ML models. -- `train_n_secs`: The number of historical observations to train each model on. The default is 4 hours, but if your node - doesn't have historical metrics going back that far, consider [changing the metrics retention - policy](https://github.com/netdata/netdata/blob/master/docs/store/change-metrics-storage.md) or reducing this window. -- `custom_models`: A way to define custom models that you want anomaly probabilities for, including multi-node or - streaming setups. - -> ⚠️ Setting `charts_regex` with many charts or `train_n_secs` to a very large number will have an impact on the -> resources and time required to train a model for every chart. The actual performance implications depend on the -> resources available on your node. If you plan on changing these settings beyond the default, or what's mentioned in -> this guide, make incremental changes to observe the performance impact. Considering `train_max_n` to cap the number of -> observations actually used to train on. - -### Run anomaly detection on Nginx and log file metrics - -As mentioned above, this guide uses an Nginx web server to demonstrate how the anomalies collector works. You must -configure the collector to monitor charts from the -[Nginx](https://github.com/netdata/go.d.plugin/blob/master/modules/nginx/README.md) and [web -log](https://github.com/netdata/go.d.plugin/blob/master/modules/weblog/README.md) collectors. - -`charts_regex` allows for some basic regex, such as wildcards (`*`) to match all contexts with a certain pattern. For -example, `system\..*` matches with any chart with a context that begins with `system.`, and ends in any number of other -characters (`.*`). Note the escape character (`\`) around the first period to capture a period character exactly, and -not any character. - -Change `charts_regex` in `anomalies.conf` to the following: - -```conf - charts_regex: 'system\..*|nginx_local\..*|web_log_nginx\..*|apps.cpu|apps.mem' -``` - -This value tells the anomaly collector to train against every `system.` chart, every `nginx_local` chart, every -`web_log_nginx` chart, and specifically the `apps.cpu` and `apps.mem` charts. - -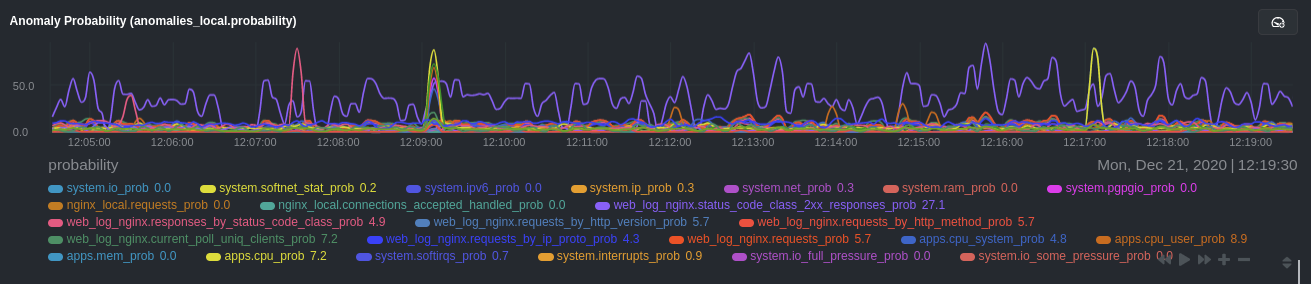 - -### Remove some metrics from anomaly detection - -As you can see in the above screenshot, this node is now looking for anomalies in many places. The result is a single -`anomalies_local.probability` chart with more than twenty dimensions, some of which the dashboard hides at the bottom of -a scrollable area. In addition, training and analyzing the anomaly collector on many charts might require more CPU -utilization that you're willing to give. - -First, explicitly declare which `system.` charts to monitor rather than of all of them using regex (`system\..*`). - -```conf - charts_regex: 'system\.cpu|system\.load|system\.io|system\.net|system\.ram|nginx_local\..*|web_log_nginx\..*|apps.cpu|apps.mem' -``` - -Next, remove some charts with the `charts_to_exclude` setting. For this example, using an Nginx web server, focus on the -volume of requests/responses, not, for example, which type of 4xx response a user might receive. - -```conf - charts_to_exclude: 'web_log_nginx.excluded_requests,web_log_nginx.responses_by_status_code_class,web_log_nginx.status_code_class_2xx_responses,web_log_nginx.status_code_class_4xx_responses,web_log_nginx.current_poll_uniq_clients,web_log_nginx.requests_by_http_method,web_log_nginx.requests_by_http_version,web_log_nginx.requests_by_ip_proto' -``` - -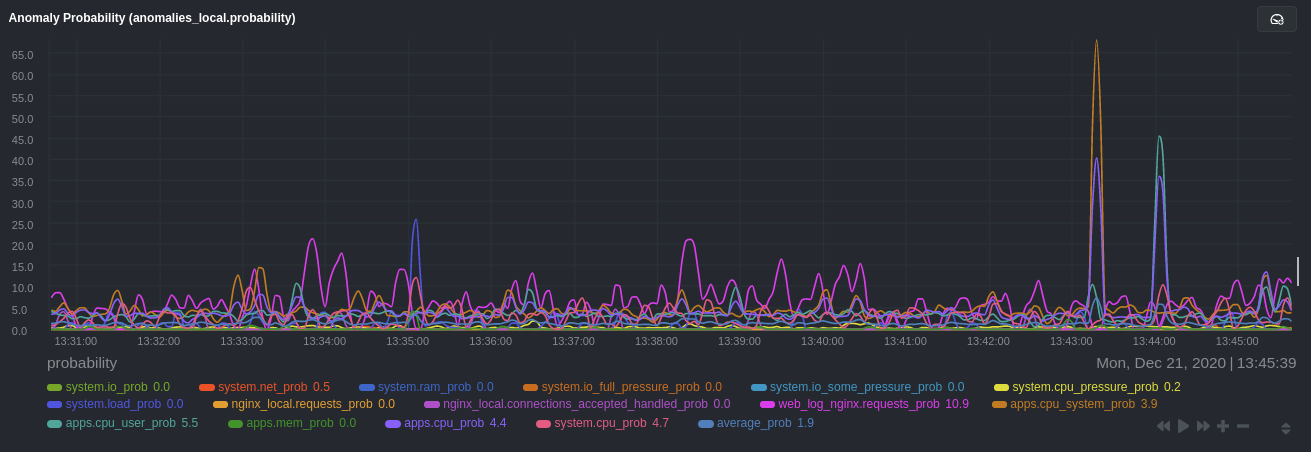 - -Apply the ideas behind the collector's regex and exclude settings to any other -[system](https://github.com/netdata/netdata/blob/master/docs/collect/system-metrics.md), [container](https://github.com/netdata/netdata/blob/master/docs/collect/container-metrics.md), or -[application](https://github.com/netdata/netdata/blob/master/docs/collect/application-metrics.md) metrics you want to detect anomalies for. - -## What's next? - -Now that you know how to set up unsupervised anomaly detection in the Netdata Agent, using an Nginx web server as an -example, it's time to apply that knowledge to other mission-critical parts of your infrastructure. If you're not sure -what to monitor next, check out our list of [collectors](https://github.com/netdata/netdata/blob/master/collectors/COLLECTORS.md) to see what kind of metrics Netdata -can collect from your systems, containers, and applications. - -Keep on moving to [part 2](https://github.com/netdata/netdata/blob/master/docs/guides/monitor/visualize-monitor-anomalies.md), which covers the charts and alarms -Netdata creates for unsupervised anomaly detection. - -For a different troubleshooting experience, try out the [Metric -Correlations](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/metric-correlations.md) feature in Netdata Cloud. Metric -Correlations helps you perform faster root cause analysis by narrowing a dashboard to only the charts most likely to be -related to an anomaly. - -### Related reference documentation - -- [Netdata Agent · Anomalies collector](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/anomalies/README.md) -- [Netdata Agent · Nginx collector](https://github.com/netdata/go.d.plugin/blob/master/modules/nginx/README.md) -- [Netdata Agent · web log collector](https://github.com/netdata/go.d.plugin/blob/master/modules/weblog/README.md) -- [Netdata Cloud · Metric Correlations](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/metric-correlations.md) diff --git a/docs/guides/monitor/anomaly-detection.md b/docs/guides/monitor/anomaly-detection.md index ce819d937..4552e7a72 100644 --- a/docs/guides/monitor/anomaly-detection.md +++ b/docs/guides/monitor/anomaly-detection.md @@ -1,13 +1,14 @@ <!-- title: "Machine learning (ML) powered anomaly detection" +sidebar_label: "Machine learning (ML) powered anomaly detection" description: "Detect anomalies in any system, container, or application in your infrastructure with machine learning and the open-source Netdata Agent." image: /img/seo/guides/monitor/anomaly-detection.png -author: "Andrew Maguire" -author_title: "Analytics & ML Lead" -author_img: "/img/authors/andy-maguire.jpg" custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/guides/monitor/anomaly-detection.md +learn_status: "Published" +learn_rel_path: "Operations" --> +# Machine learning (ML) powered anomaly detection ## Overview @@ -34,7 +35,7 @@ This guide will explain how to get started using these ML based anomaly detectio ## Anomaly Advisor -The [Anomaly Advisor](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/anomaly-advisor.mdx) is the flagship anomaly detection feature within Netdata. In the "Anomalies" tab of Netdata you will see an overall "Anomaly Rate" chart that aggregates node level anomaly rate for all nodes in a space. The aim of this chart is to make it easy to quickly spot periods of time where the overall "[node anomaly rate](https://github.com/netdata/netdata/blob/master/ml/README.md#node-anomaly-rate)" is elevated in some unusual way and for what node or nodes this relates to. +The [Anomaly Advisor](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/anomaly-advisor.md) is the flagship anomaly detection feature within Netdata. In the "Anomalies" tab of Netdata you will see an overall "Anomaly Rate" chart that aggregates node level anomaly rate for all nodes in a space. The aim of this chart is to make it easy to quickly spot periods of time where the overall "[node anomaly rate](https://github.com/netdata/netdata/blob/master/ml/README.md#node-anomaly-rate)" is elevated in some unusual way and for what node or nodes this relates to. 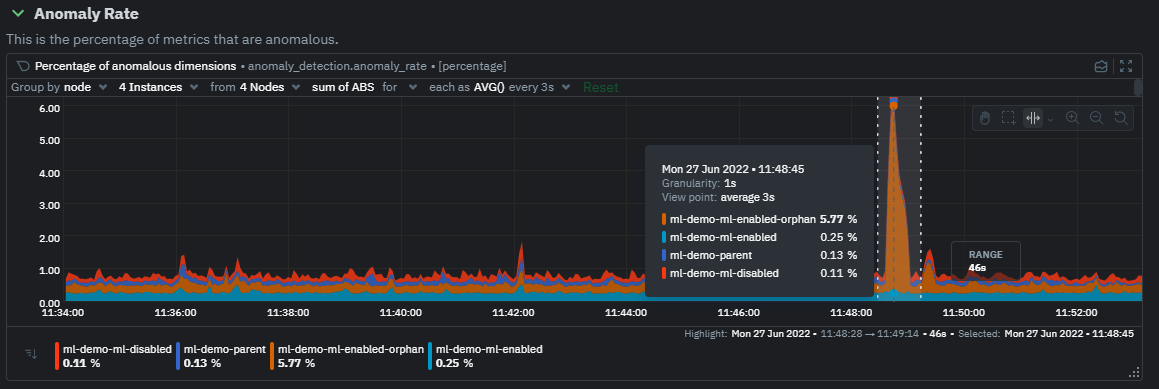 @@ -52,13 +53,13 @@ Pressing the anomalies icon (next to the information icon in the chart header) w ## Anomaly Rate Based Alerts -It is possible to use the `anomaly-bit` when defining traditional Alerts within netdata. The `anomaly-bit` is just another `options` parameter that can be passed as part of an [alarm line lookup](https://learn.netdata.cloud/docs/agent/health/reference#alarm-line-lookup). +It is possible to use the `anomaly-bit` when defining traditional Alerts within netdata. The `anomaly-bit` is just another `options` parameter that can be passed as part of an [alarm line lookup](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md#alarm-line-lookup). You can see some example ML based alert configurations below: -- [Anomaly rate based CPU dimensions alarm](https://learn.netdata.cloud/docs/agent/health/reference#example-8---anomaly-rate-based-cpu-dimensions-alarm) -- [Anomaly rate based CPU chart alarm](https://learn.netdata.cloud/docs/agent/health/reference#example-9---anomaly-rate-based-cpu-chart-alarm) -- [Anomaly rate based node level alarm](https://learn.netdata.cloud/docs/agent/health/reference#example-10---anomaly-rate-based-node-level-alarm) +- [Anomaly rate based CPU dimensions alarm](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md#example-8---anomaly-rate-based-cpu-dimensions-alarm) +- [Anomaly rate based CPU chart alarm](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md#example-9---anomaly-rate-based-cpu-chart-alarm) +- [Anomaly rate based node level alarm](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md#example-10---anomaly-rate-based-node-level-alarm) - More examples in the [`/health/health.d/ml.conf`](https://github.com/netdata/netdata/blob/master/health/health.d/ml.conf) file that ships with the agent. ## Learn More @@ -66,7 +67,7 @@ You can see some example ML based alert configurations below: Check out the resources below to learn more about how Netdata is approaching ML: - [Agent ML documentation](https://github.com/netdata/netdata/blob/master/ml/README.md). -- [Anomaly Advisor documentation](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/anomaly-advisor.mdx). +- [Anomaly Advisor documentation](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/anomaly-advisor.md). - [Metric Correlations documentation](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/metric-correlations.md). - Anomaly Advisor [launch blog post](https://www.netdata.cloud/blog/introducing-anomaly-advisor-unsupervised-anomaly-detection-in-netdata/). - Netdata Approach to ML [blog post](https://www.netdata.cloud/blog/our-approach-to-machine-learning/). diff --git a/docs/guides/monitor/dimension-templates.md b/docs/guides/monitor/dimension-templates.md deleted file mode 100644 index d2795a9c6..000000000 --- a/docs/guides/monitor/dimension-templates.md +++ /dev/null @@ -1,181 +0,0 @@ -<!-- -title: "Use dimension templates to create dynamic alarms" -custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/guides/monitor/dimension-templates.md ---> - -# Use dimension templates to create dynamic alarms - -Your ability to monitor the health of your systems and applications relies on your ability to create and maintain -the best set of alarms for your particular needs. - -In v1.18 of Netdata, we introduced **dimension templates** for alarms, which simplifies the process of -writing [alarm entities](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md#health-entity-reference) for -charts with many dimensions. - -Dimension templates can condense many individual entities into one—no more copy-pasting one entity and changing the -`alarm`/`template` and `lookup` lines for each dimension you'd like to monitor. - -They are, however, an advanced health monitoring feature. For more basic instructions on creating your first alarm, -check out our [health monitoring documentation](https://github.com/netdata/netdata/blob/master/health/README.md), which also includes -[examples](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md#example-alarms). - -## The fundamentals of `foreach` - -Our dimension templates update creates a new `foreach` parameter to the -existing [`lookup` line](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md#alarm-line-lookup). This -is where the magic happens. - -You use the `foreach` parameter to specify which dimensions you want to monitor with this single alarm. You can separate -them with a comma (`,`) or a pipe (`|`). You can also use -a [Netdata simple pattern](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md) to create -many alarms with a regex-like syntax. - -The `foreach` parameter _has_ to be the last parameter in your `lookup` line, and if you have both `of` and `foreach` in -the same `lookup` line, Netdata will ignore the `of` parameter and use `foreach` instead. - -Let's get into some examples so you can see how the new parameter works. - -> ⚠️ The following entities are examples to showcase the functionality and syntax of dimension templates. They are not -> meant to be run as-is on production systems. - -## Condensing entities with `foreach` - -Let's say you want to monitor the `system`, `user`, and `nice` dimensions in your system's overall CPU utilization. -Before dimension templates, you would need the following three entities: - -```yaml - alarm: cpu_system - on: system.cpu -lookup: average -10m percentage of system - every: 1m - warn: $this > 50 - crit: $this > 80 - - alarm: cpu_user - on: system.cpu -lookup: average -10m percentage of user - every: 1m - warn: $this > 50 - crit: $this > 80 - - alarm: cpu_nice - on: system.cpu -lookup: average -10m percentage of nice - every: 1m - warn: $this > 50 - crit: $this > 80 -``` - -With dimension templates, you can condense these into a single alarm. Take note of the `alarm` and `lookup` lines. - -```yaml - alarm: cpu_template - on: system.cpu -lookup: average -10m percentage foreach system,user,nice - every: 1m - warn: $this > 50 - crit: $this > 80 -``` - -The `alarm` line specifies the naming scheme Netdata will use. You can use whatever naming scheme you'd like, with `.` -and `_` being the only allowed symbols. - -The `lookup` line has changed from `of` to `foreach`, and we're now passing three dimensions. - -In this example, Netdata will create three alarms with the names `cpu_template_system`, `cpu_template_user`, and -`cpu_template_nice`. Every minute, each alarm will use the same database query to calculate the average CPU usage for -the `system`, `user`, and `nice` dimensions over the last 10 minutes and send out alarms if necessary. - -You can find these three alarms active by clicking on the **Alarms** button in the top navigation, and then clicking on -the **All** tab and scrolling to the **system - cpu** collapsible section. - -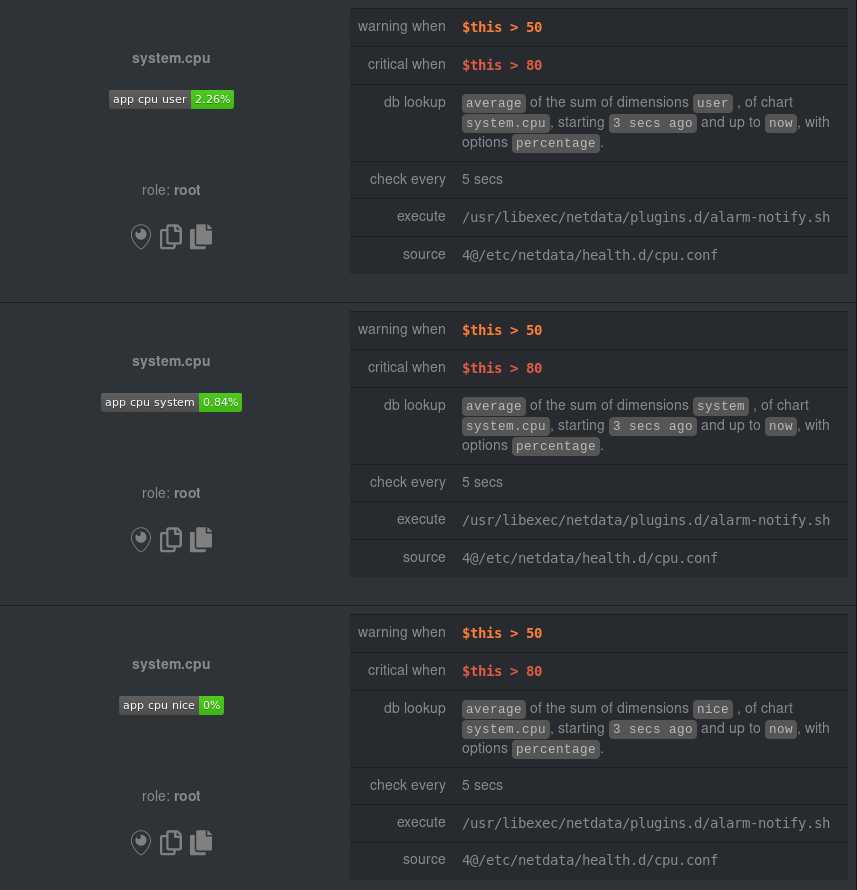 - -Let's look at some other examples of how `foreach` works so you can best apply it in your configurations. - -### Using a Netdata simple pattern in `foreach` - -In the last example, we used `foreach system,user,nice` to create three distinct alarms using dimension templates. But -what if you want to quickly create alarms for _all_ the dimensions of a given chart? - -Use a [simple pattern](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md)! One example of a simple pattern is a single wildcard -(`*`). - -Instead of monitoring system CPU usage, let's monitor per-application CPU usage using the `apps.cpu` chart. Passing a -wildcard as the simple pattern tells Netdata to create a separate alarm for _every_ process on your system: - -```yaml - alarm: app_cpu - on: apps.cpu -lookup: average -10m percentage foreach * - every: 1m - warn: $this > 50 - crit: $this > 80 -``` - -This entity will now create alarms for every dimension in the `apps.cpu` chart. Given that most `apps.cpu` charts have -10 or more dimensions, using the wildcard ensures you catch every CPU-hogging process. - -To learn more about how to use simple patterns with dimension templates, see -our [simple patterns documentation](https://github.com/netdata/netdata/blob/master/libnetdata/simple_pattern/README.md). - -## Using `foreach` with alarm templates - -Dimension templates also work -with [alarm templates](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md#alarm-line-alarm-or-template). -Alarm templates help you create alarms for all the charts with a given context—for example, all the cores of your -system's CPU. - -By combining the two, you can create dozens of individual alarms with a single template entity. Here's how you would -create alarms for the `system`, `user`, and `nice` dimensions for every chart in the `cpu.cpu` context—or, in other -words, every CPU core. - -```yaml -template: cpu_template - on: cpu.cpu - lookup: average -10m percentage foreach system,user,nice - every: 1m - warn: $this > 50 - crit: $this > 80 -``` - -On a system with a 6-core, 12-thread Ryzen 5 1600 CPU, this one entity creates alarms on the following charts and -dimensions: - -- `cpu.cpu0` - - `cpu_template_user` - - `cpu_template_system` - - `cpu_template_nice` -- `cpu.cpu1` - - `cpu_template_user` - - `cpu_template_system` - - `cpu_template_nice` -- `cpu.cpu2` - - `cpu_template_user` - - `cpu_template_system` - - `cpu_template_nice` -- ... -- `cpu.cpu11` - - `cpu_template_user` - - `cpu_template_system` - - `cpu_template_nice` - -And how just a few of those dimension template-generated alarms look like in the Netdata dashboard. - -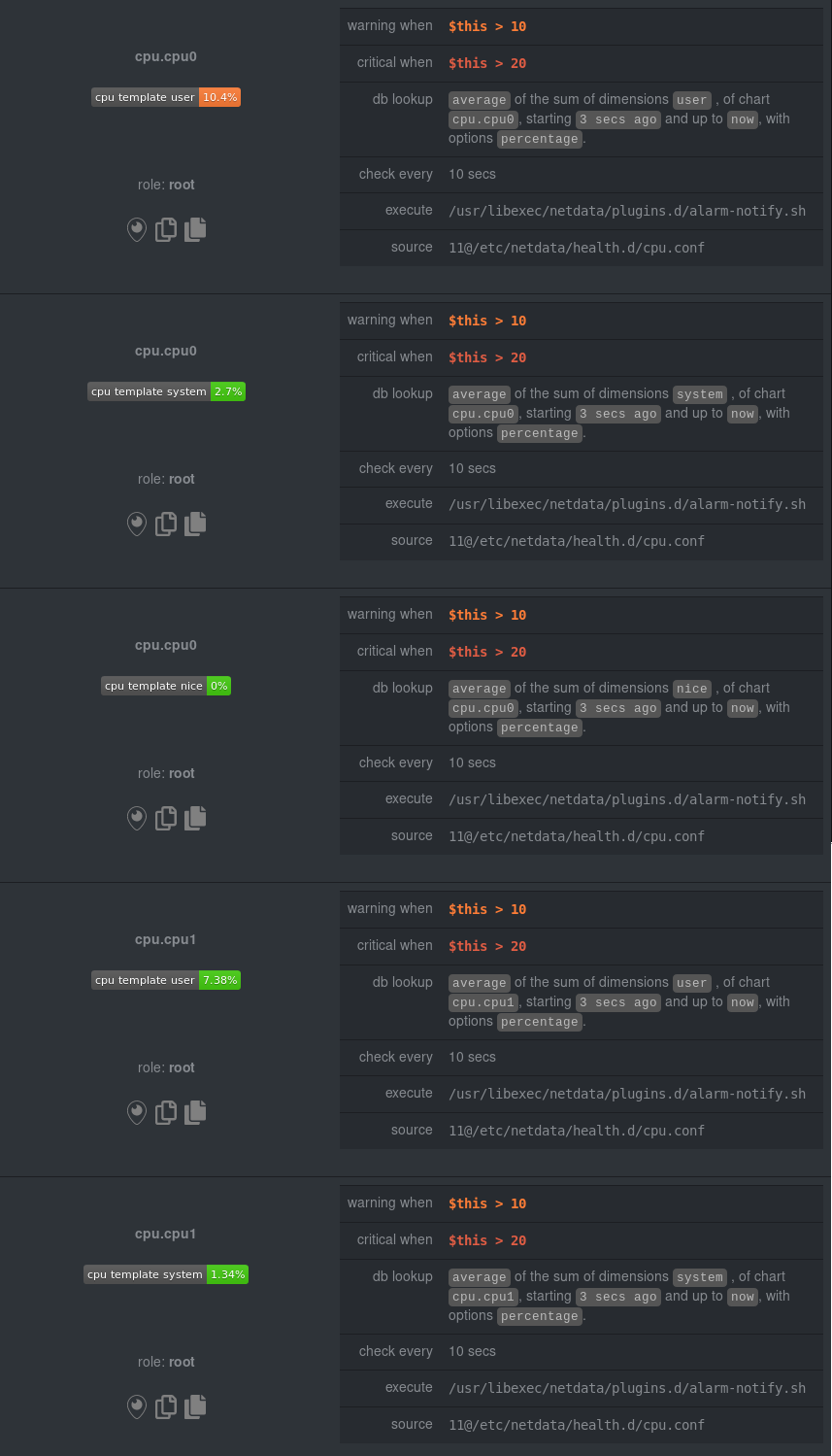 - -All in all, this single entity creates 36 individual alarms. Much easier than writing 36 separate entities in your -health configuration files! - -## What's next? - -We hope you're excited about the possibilities of using dimension templates! Maybe they'll inspire you to build new -alarms that will help you better monitor the health of your systems. - -Or, at the very least, simplify your configuration files. - -For information about other advanced features in Netdata's health monitoring toolkit, check out -our [health documentation](https://github.com/netdata/netdata/blob/master/health/README.md). And if you have some cool -alarms you built using dimension templates, - - diff --git a/docs/guides/monitor/kubernetes-k8s-netdata.md b/docs/guides/monitor/kubernetes-k8s-netdata.md index 5732fc96c..96d79935b 100644 --- a/docs/guides/monitor/kubernetes-k8s-netdata.md +++ b/docs/guides/monitor/kubernetes-k8s-netdata.md @@ -1,14 +1,6 @@ -<!-- -title: "Kubernetes monitoring with Netdata: Overview and visualizations" -description: "Learn how to navigate Netdata's Kubernetes monitoring features for visualizing the health and performance of a Kubernetes cluster with per-second granularity." -image: /img/seo/guides/monitor/kubernetes-k8s-netdata.png -author: "Joel Hans" -author_title: "Editorial Director, Technical & Educational Resources" -author_img: "/img/authors/joel-hans.jpg" -custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/guides/monitor/kubernetes-k8s-netdata.md ---> - -# Kubernetes monitoring with Netdata: Overview and visualizations +# Kubernetes monitoring with Netdata + +This document gives an overview of what visualizations Netdata provides on Kubernetes deployments. At Netdata, we've built Kubernetes monitoring tools that add visibility without complexity while also helping you actively troubleshoot anomalies or outages. This guide walks you through each of the visualizations and offers best @@ -140,7 +132,7 @@ visualizations](https://user-images.githubusercontent.com/1153921/109049195-349f ### Health map -The first visualization is the [health map](https://learn.netdata.cloud/docs/cloud/visualize/kubernetes#health-map), +The first visualization is the [health map](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/kubernetes.md#health-map), which places each container into its own box, then varies the intensity of their color to visualize the resource utilization. By default, the health map shows the **average CPU utilization as a percentage of the configured limit** for every container in your cluster. diff --git a/docs/guides/monitor/lamp-stack.md b/docs/guides/monitor/lamp-stack.md index 165888c4b..190ea87e8 100644 --- a/docs/guides/monitor/lamp-stack.md +++ b/docs/guides/monitor/lamp-stack.md @@ -1,15 +1,8 @@ -<!-- -title: "LAMP stack monitoring (Linux, Apache, MySQL, PHP) with Netdata" -description: "Set up robust LAMP stack monitoring (Linux, Apache, MySQL, PHP) in just a few minutes using a free, open-source monitoring tool that collects metrics every second." -image: /img/seo/guides/monitor/lamp-stack.png -author: "Joel Hans" -author_title: "Editorial Director, Technical & Educational Resources" -author_img: "/img/authors/joel-hans.jpg" -custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/guides/monitor/lamp-stack.md ---> import { OneLineInstallWget } from '@site/src/components/OneLineInstall/' -# LAMP stack monitoring (Linux, Apache, MySQL, PHP) with Netdata +# LAMP stack monitoring with Netdata + +Set up robust LAMP stack monitoring (Linux, Apache, MySQL, PHP) in a few minutes using Netdata. The LAMP stack is the "hello world" for deploying dynamic web applications. It's fast, flexible, and reliable, which means a developer or sysadmin won't go far in their career without interacting with the stack and its services. @@ -58,7 +51,7 @@ To follow this tutorial, you need: ## Install the Netdata Agent If you don't have the free, open-source Netdata monitoring agent installed on your node yet, get started with a [single -kickstart command](https://github.com/netdata/netdata/blob/master/docs/get-started.mdx): +kickstart command](https://github.com/netdata/netdata/blob/master/packaging/installer/README.md): <OneLineInstallWget/> @@ -171,10 +164,9 @@ If the Netdata Agent isn't already open in your browser, open a new tab and navi Netdata automatically organizes all metrics and charts onto a single page for easy navigation. Peek at gauges to see overall system performance, then scroll down to see more. Click-and-drag with your mouse to pan _all_ charts back and forth through different time intervals, or hold `SHIFT` and use the scrollwheel (or two-finger scroll) to zoom in and -out. Check out our doc on [interacting with charts](https://github.com/netdata/netdata/blob/master/docs/visualize/interact-dashboards-charts.md) for all the details. +out. Check out our doc on [interacting with charts](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/interact-new-charts.md) for all the details. - + The **System Overview** section, which you can also see in the right-hand menu, contains key hardware monitoring charts, including CPU utilization, memory page faults, network monitoring, and much more. The **Applications** section shows you @@ -211,7 +203,7 @@ shows any alarms currently triggered, while the **All** tab displays a list of _ 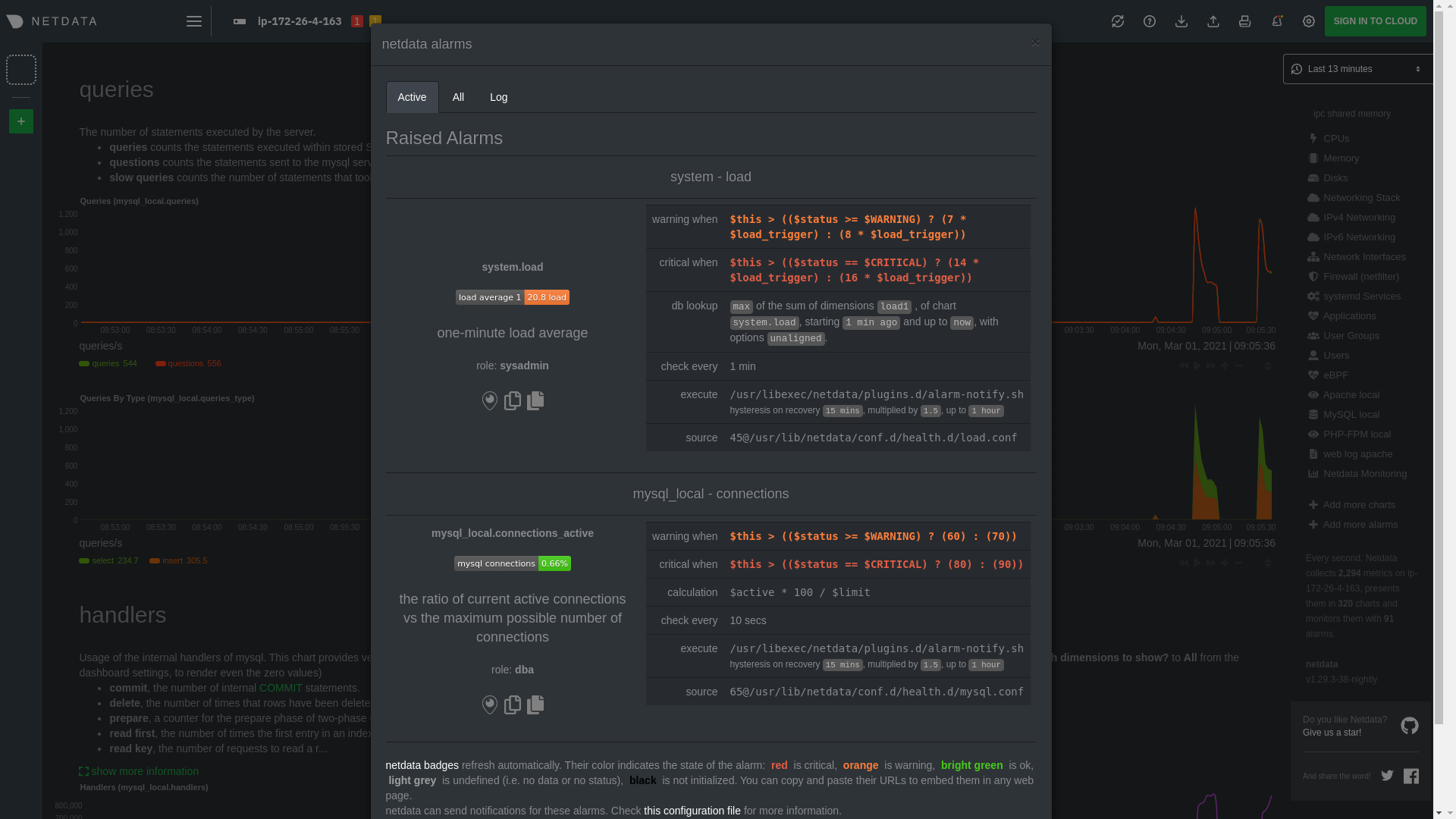 -[Tweak alarms](https://github.com/netdata/netdata/blob/master/docs/monitor/configure-alarms.md) based on your infrastructure monitoring needs, and to see these alarms +[Tweak alarms](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md) based on your infrastructure monitoring needs, and to see these alarms in other places, like your inbox or a Slack channel, [enable a notification method](https://github.com/netdata/netdata/blob/master/docs/monitor/enable-notifications.md). @@ -238,7 +230,7 @@ source of issues faster with [Metric Correlations](https://github.com/netdata/ne ### Related reference documentation -- [Netdata Agent · Get started](https://github.com/netdata/netdata/blob/master/docs/get-started.mdx) +- [Netdata Agent · Get started](https://github.com/netdata/netdata/blob/master/packaging/installer/README.md) - [Netdata Agent · Apache data collector](https://github.com/netdata/go.d.plugin/blob/master/modules/apache/README.md) - [Netdata Agent · Web log collector](https://github.com/netdata/go.d.plugin/blob/master/modules/weblog/README.md) - [Netdata Agent · MySQL data collector](https://github.com/netdata/go.d.plugin/blob/master/modules/mysql/README.md) diff --git a/docs/guides/monitor/pi-hole-raspberry-pi.md b/docs/guides/monitor/pi-hole-raspberry-pi.md index 5099d12b9..4f0ff4cd6 100644 --- a/docs/guides/monitor/pi-hole-raspberry-pi.md +++ b/docs/guides/monitor/pi-hole-raspberry-pi.md @@ -1,13 +1,17 @@ <!-- title: "Monitor Pi-hole (and a Raspberry Pi) with Netdata" +sidebar_label: "Monitor Pi-hole (and a Raspberry Pi) with Netdata" description: "Monitor Pi-hole metrics, plus Raspberry Pi system metrics, in minutes and completely for free with Netdata's open-source monitoring agent." image: /img/seo/guides/monitor/netdata-pi-hole-raspberry-pi.png custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/guides/monitor/pi-hole-raspberry-pi.md +learn_status: "Published" +learn_rel_path: "Miscellaneous" --> -import { OneLineInstallWget } from '@site/src/components/OneLineInstall/' # Monitor Pi-hole (and a Raspberry Pi) with Netdata +import { OneLineInstallWget } from '@site/src/components/OneLineInstall/' + Between intrusive ads, invasive trackers, and vicious malware, many techies and homelab enthusiasts are advancing their networks' security and speed with a tiny computer and a powerful piece of software: [Pi-hole](https://pi-hole.net/). @@ -61,9 +65,7 @@ populates its dashboard with more than 250 charts. Open your browser of choice and navigate to `http://NODE:19999/`, replacing `NODE` with the IP address of your Raspberry Pi. Not sure what that IP is? Try running `hostname -I | awk '{print $1}'` from the Pi itself. -You'll see Netdata's dashboard and a few hundred real-time, -[interactive](https://learn.netdata.cloud/guides/step-by-step/step-02#interact-with-charts) charts. Feel free to -explore, but let's turn our attention to installing Pi-hole. +You'll see Netdata's dashboard and a few hundred real-time, interactive charts. Feel free to explore, but let's turn our attention to installing Pi-hole. ## Install Pi-Hole @@ -98,8 +100,7 @@ part of your system might affect another.  -If you're completely new to Netdata, look at our [step-by-step guide](https://github.com/netdata/netdata/blob/master/docs/guides/step-by-step/step-00.md) for a -walkthrough of all its features. For a more expedited tour, see the [get started guide](https://github.com/netdata/netdata/blob/master/docs/get-started.mdx). +If you're completely new to Netdata, look at the [Introduction](https://github.com/netdata/netdata/blob/master/docs/getting-started/introduction.md) section for a walkthrough of all its features. For a more expedited tour, see the [get started documentation](https://github.com/netdata/netdata/blob/master/packaging/installer/README.md). ### Enable temperature sensor monitoring @@ -137,26 +138,5 @@ more than 256. Use our [database sizing calculator](https://github.com/netdata/netdata/blob/master/docs/store/change-metrics-storage.md#calculate-the-system-resources-ram-disk-space-needed-to-store-metrics) -and [guide on storing historical metrics](https://github.com/netdata/netdata/blob/master/docs/guides/longer-metrics-storage.md) to help you determine the right +and the [Database configuration documentation](https://github.com/netdata/netdata/blob/master/database/README.md) to help you determine the right setting for your Raspberry Pi. - -## What's next? - -Now that you're monitoring Pi-hole and your Raspberry Pi with Netdata, you can extend its capabilities even further, or -configure Netdata to more specific goals. - -Most importantly, you can always install additional services and instantly collect metrics from many of them with our -[300+ integrations](https://github.com/netdata/netdata/blob/master/collectors/COLLECTORS.md). - -- [Optimize performance](https://github.com/netdata/netdata/blob/master/docs/guides/configure/performance.md) using tweaks developed for IoT devices. -- [Stream Raspberry Pi metrics](https://github.com/netdata/netdata/blob/master/streaming/README.md) to a parent host for easy access or longer-term storage. -- [Tweak alarms](https://github.com/netdata/netdata/blob/master/health/QUICKSTART.md) for either Pi-hole or the health of your Raspberry Pi. -- [Export metrics to external databases](https://github.com/netdata/netdata/blob/master/exporting/README.md) with the exporting engine. - -Or, head over to [our guides](https://learn.netdata.cloud/guides/) for even more experiments and insights into -troubleshooting the health of your systems and services. - -If you have any questions about using Netdata to monitor your Raspberry Pi, Pi-hole, or any other applications, head on -over to our [community forum](https://community.netdata.cloud/). - - diff --git a/docs/guides/monitor/process.md b/docs/guides/monitor/process.md index 7cc327a01..9aa6911f1 100644 --- a/docs/guides/monitor/process.md +++ b/docs/guides/monitor/process.md @@ -1,8 +1,11 @@ <!-- title: Monitor any process in real-time with Netdata +sidebar_label: Monitor any process in real-time with Netdata description: "Tap into Netdata's powerful collectors, with per-second utilization metrics for every process, to troubleshoot faster and make data-informed decisions." image: /img/seo/guides/monitor/process.png custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/guides/monitor/process.md +learn_status: "Published" +learn_rel_path: "Operations" --> # Monitor any process in real-time with Netdata @@ -34,11 +37,7 @@ With Netdata's process monitoring, you can: ## Prerequisites -- One or more Linux nodes running [Netdata](https://github.com/netdata/netdata/blob/master/docs/get-started.mdx). If you - need more time to understand Netdata before - following this guide, see - the [infrastructure](https://github.com/netdata/netdata/blob/master/docs/quickstart/infrastructure.md) or - [single-node](https://github.com/netdata/netdata/blob/master/docs/quickstart/single-node.md) monitoring quickstarts. +- One or more Linux nodes running [Netdata](https://github.com/netdata/netdata/blob/master/packaging/installer/README.md) - A general understanding of how to [configure the Netdata Agent](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md) using `edit-config`. @@ -268,45 +267,4 @@ relevant data. `ebpf.plugin` visualizes additional eBPF metrics, which are system-wide and not per-process, under the **eBPF** section. -## What's next? - -Now that you have `apps_groups.conf` configured correctly, and know where to find per-process visualizations throughout -Netdata's ecosystem, you can precisely monitor the health and performance of any process on your node using per-second -metrics. - -For even more in-depth troubleshooting, see our guide -on [monitoring and debugging applications with eBPF](https://github.com/netdata/netdata/blob/master/docs/guides/troubleshoot/monitor-debug-applications-ebpf.md). - -If the process you're monitoring also has -a [supported collector](https://github.com/netdata/netdata/blob/master/collectors/COLLECTORS.md), now is a great time to -set -that up if it wasn't autodetected. With both process utilization and application-specific metrics, you should have every -piece of data needed to discover the root cause of an incident. See -our [collector setup](https://github.com/netdata/netdata/blob/master/docs/collect/enable-configure.md) doc for details. - -[Create new dashboards](https://github.com/netdata/netdata/blob/master/docs/visualize/create-dashboards.md) in Netdata -Cloud using charts from `apps.plugin`, -`ebpf.plugin`, and application-specific collectors to build targeted dashboards for monitoring key processes across your -infrastructure. - -Try -running [Metric Correlations](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/metric-correlations.md) -on a node that's running the process(es) you're monitoring. Even if nothing is going wrong at the moment, Netdata -Cloud's embedded intelligence helps you better understand how a MySQL database, for example, might influence a system's -volume of memory page faults. And when an incident is afoot, use Metric Correlations to reduce mean time to resolution ( -MTTR) and cognitive load. - -If you want more specific metrics from your custom application, check out -Netdata's [statsd support](https://github.com/netdata/netdata/blob/master/collectors/statsd.plugin/README.md). With statd, you can send detailed metrics from your -application to Netdata and visualize them with per-second granularity. Netdata's statsd collector works with dozens of -[statsd server implementations](https://github.com/etsy/statsd/wiki#client-implementations), which work with most application -frameworks. - -### Related reference documentation - -- [Netdata Agent · `apps.plugin`](https://github.com/netdata/netdata/blob/master/collectors/apps.plugin/README.md) -- [Netdata Agent · `ebpf.plugin`](https://github.com/netdata/netdata/blob/master/collectors/ebpf.plugin/README.md) -- [Netdata Agent · Dashboards](https://github.com/netdata/netdata/blob/master/web/README.md#dimensions) -- [Netdata Agent · MySQL collector](https://github.com/netdata/go.d.plugin/blob/master/modules/mysql/README.md) - diff --git a/docs/guides/monitor/raspberry-pi-anomaly-detection.md b/docs/guides/monitor/raspberry-pi-anomaly-detection.md index 00b652bf2..935d0f6cf 100644 --- a/docs/guides/monitor/raspberry-pi-anomaly-detection.md +++ b/docs/guides/monitor/raspberry-pi-anomaly-detection.md @@ -1,12 +1,6 @@ ---- -title: "Unsupervised anomaly detection for Raspberry Pi monitoring" -description: "Use a low-overhead machine learning algorithm and an open-source monitoring tool to detect anomalous metrics on a Raspberry Pi." -image: /img/seo/guides/monitor/raspberry-pi-anomaly-detection.png -author: "Andy Maguire" -author_title: "Senior Machine Learning Engineer" -author_img: "/img/authors/andy-maguire.jpg" -custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/guides/monitor/raspberry-pi-anomaly-detection.md ---- +# Anomaly detection for RPi monitoring + +Learn how to use a low-overhead machine learning algorithm alongside Netdata to detect anomalous metrics on a Raspberry Pi. We love IoT and edge at Netdata, we also love machine learning. Even better if we can combine the two to ease the pain of monitoring increasingly complex systems. @@ -23,7 +17,7 @@ Read on to learn all the steps and enable unsupervised anomaly detection on your - A Raspberry Pi running Raspbian, which we'll call a _node_. - The [open-source Netdata](https://github.com/netdata/netdata) monitoring agent. If you don't have it installed on your - node yet, [get started now](https://github.com/netdata/netdata/blob/master/docs/get-started.mdx). + node yet, [get started now](https://github.com/netdata/netdata/blob/master/packaging/installer/README.md). ## Install dependencies @@ -63,7 +57,6 @@ Now you're ready to enable the collector and [restart Netdata](https://github.co ```bash sudo ./edit-config python.d.conf -# set `anomalies: no` to `anomalies: yes` # restart netdata sudo systemctl restart netdata @@ -100,26 +93,4 @@ during training. By default, the anomalies collector, along with all other runni 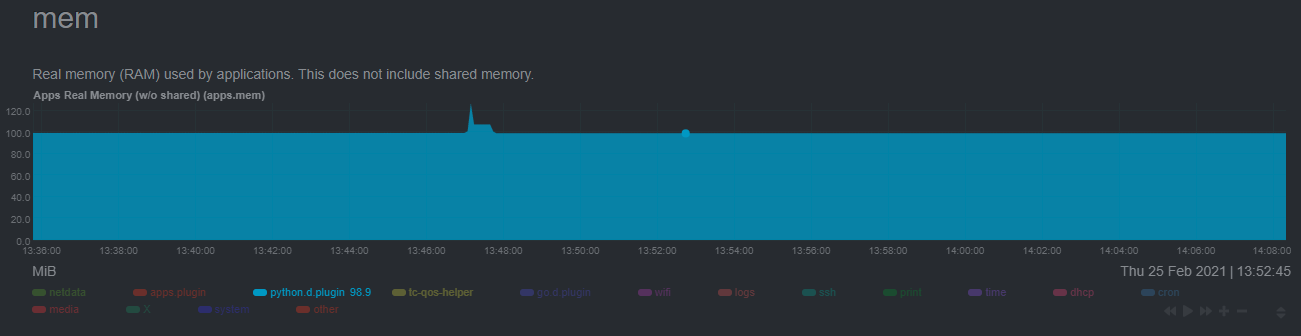 -## What's next? - -So, all in all, with a small little bit of extra set up and a small overhead on the Pi itself, the anomalies collector -looks like a potentially useful addition to enable unsupervised anomaly detection on your Pi. - -See our two-part guide series for a more complete picture of configuring the anomalies collector, plus some best -practices on using the charts it automatically generates: - -- [_Detect anomalies in systems and applications_](https://github.com/netdata/netdata/blob/master/docs/guides/monitor/anomaly-detection-python.md) -- [_Monitor and visualize anomalies with Netdata_](https://github.com/netdata/netdata/blob/master/docs/guides/monitor/visualize-monitor-anomalies.md) - -If you're using your Raspberry Pi for other purposes, like blocking ads/trackers with Pi-hole, check out our companions -Pi guide: [_Monitor Pi-hole (and a Raspberry Pi) with Netdata_](https://github.com/netdata/netdata/blob/master/docs/guides/monitor/pi-hole-raspberry-pi.md). - -Once you've had a chance to give unsupervised anomaly detection a go, share your use cases and let us know of any -feedback on our [community forum](https://community.netdata.cloud/t/anomalies-collector-feedback-megathread/767). - -### Related reference documentation - -- [Netdata Agent · Get Netdata](https://github.com/netdata/netdata/blob/master/docs/get-started.mdx) -- [Netdata Agent · Anomalies collector](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/anomalies/README.md) - diff --git a/docs/guides/monitor/statsd.md b/docs/guides/monitor/statsd.md deleted file mode 100644 index 848e2649c..000000000 --- a/docs/guides/monitor/statsd.md +++ /dev/null @@ -1,298 +0,0 @@ -<!-- -title: How to use any StatsD data source with Netdata -description: "Learn how to monitor any custom application instrumented with StatsD with per-second metrics and fully customizable, interactive charts." -image: /img/seo/guides/monitor/statsd.png -author: "Odysseas Lamtzidis" -author_title: "Developer Advocate" -author_img: "/img/authors/odysseas-lamtzidis.jpg" -custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/guides/monitor/statsd.md ---> - -# StatsD Guide - -StatsD is a protocol and server implementation, first introduced at Etsy, to aggregate and summarize application metrics. With StatsD, applications are instrumented by developers using the libraries that already exist for the language, without caring about managing the data. The StatsD server is in charge of receiving the metrics, performing some simple processing on them, and then pushing them to the time-series database (TSDB) for long-term storage and visualization. - -Netdata is a fully-functional StatsD server and TSDB implementation, so you can instantly visualize metrics by simply sending them to Netdata using the built-in StatsD server. - -In this guide, we'll go through a scenario of visualizing our data in Netdata in a matter of seconds using [k6](https://k6.io), an open-source tool for automating load testing that outputs metrics to the StatsD format. - -Although we'll use k6 as the use-case, the same principles can be applied to every application that supports the StatsD protocol. Simply enable the StatsD output and point it to the node that runs Netdata, which is `localhost` in this case. - -In general, the process for creating a StatsD collector can be summarized in 2 steps: - -- Run an experiment by sending StatsD metrics to Netdata, without any prior configuration. This will create a chart per metric (called private charts) and will help you verify that everything works as expected from the application side of things. - - Make sure to reload the dashboard tab **after** you start sending data to Netdata. -- Create a configuration file for your app using [edit-config](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md): `sudo ./edit-config - statsd.d/myapp.conf` - - Each app will have it's own section in the right-hand menu. - -Now, let's see the above process in detail. - -## Prerequisites - -- A node with the [Netdata](https://github.com/netdata/netdata/blob/master/docs/get-started.mdx) installed. -- An application to instrument. For this guide, that will be [k6](https://k6.io/docs/getting-started/installation). - -## Understanding the metrics - -The real in instrumenting an application with StatsD for you is to decide what metrics you want to visualize and how you want them grouped. In other words, you need decide which metrics will be grouped in the same charts and how the charts will be grouped on Netdata's dashboard. - -Start with documentation for the particular application that you want to monitor (or the technological stack that you are using). In our case, the [k6 documentation](https://k6.io/docs/using-k6/metrics/) has a whole page dedicated to the metrics output by k6, along with descriptions. - -If you are using StatsD to monitor an existing application, you don't have much control over these metrics. For example, k6 has a type called `trend`, which is identical to timers and histograms. Thus, _k6 is clearly dictating_ which metrics can be used as histograms and simple gauges. - -On the other hand, if you are instrumenting your own code, you will need to not only decide what are the "things" that you want to measure, but also decide which StatsD metric type is the appropriate for each. - -## Use private charts to see all available metrics - -In Netdata, every metric will receive its own chart, called a `private chart`. Although in the final implementation this is something that we will disable, since it can create considerable noise (imagine having 100s of metrics), it’s very handy while building the configuration file. - -You can get a quick visual representation of the metrics and their type (e.g it’s a gauge, a timer, etc.). - -An important thing to notice is that StatsD has different types of metrics, as illustrated in the [Netdata documentation](https://learn.netdata.cloud/docs/agent/collectors/statsd.plugin#metrics-supported-by-netdata). Histograms and timers support mathematical operations to be performed on top of the baseline metric, like reporting the `average` of the value. - -Here are some examples of default private charts. You can see that the histogram private charts will visualize all the available operations. - -**Gauge private chart** - - - -**Histogram private chart** - - - -## Create a new StatsD configuration file - -Start by creating a new configuration file under the `statsd.d/` folder in the [Netdata config directory](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md#the-netdata-config-directory). Use [`edit-config`](https://github.com/netdata/netdata/blob/master/docs/configure/nodes.md#use-edit-config-to-edit-configuration-files) to create a new file called `k6.conf`. - -```bash= -sudo ./edit-config statsd.d/k6.conf -``` - -Copy the following configuration into your file as a starting point. - -```conf -[app] - name = k6 - metrics = k6* - private charts = yes - gaps when not collected = no - memory mode = dbengine -``` - -Next, you need is to understand how to organize metrics in Netdata’s StatsD. - -### Synthetic charts - -Netdata lets you group the metrics exposed by your instrumented application with _synthetic charts_. - -First, create a `[dictionary]` section to transform the names of the metrics into human-readable equivalents. `http_req_blocked`, `http_req_connecting`, `http_req_receiving`, and `http_reqs` are all metrics exposed by k6. - -``` -[dictionary] - http_req_blocked = Blocked HTTP Requests - http_req_connecting = Connecting HTTP Requests - http_req_receiving = Receiving HTTP Requests - http_reqs = Total HTTP requests -``` - -Continue this dictionary process with any other metrics you want to collect with Netdata. - -### Families and context - -Families and context are additional ways to group metrics. Families control the submenu at right-hand menu and it's a subcategory of the section. Given the metrics given by K6, we are organizing them in 2 major groups, or `families`: `k6 native metrics` and `http metrics`. - -Context is a second way to group metrics, when the metrics are of the same nature but different origin. In our case, if we ran several different load testing experiments side-by-side, we could define the same app, but different context (e.g `http_requests.experiment1`, `http_requests.experiment2`). - -Find more details about family and context in our [documentation](https://github.com/netdata/netdata/blob/master/web/README.md#families). - -### Dimension - -Now, having decided on how we are going to group the charts, we need to define how we are going to group metrics into different charts. This is particularly important, since we decide: - -- What metrics **not** to show, since they are not useful for our use-case. -- What metrics to consolidate into the same charts, so as to reduce noise and increase visual correlation. - -The dimension option has this syntax: `dimension = [pattern] METRIC NAME TYPE MULTIPLIER DIVIDER OPTIONS` - -- **pattern**: A keyword that tells the StatsD server the `METRIC` string is actually a [simple pattern].(/libnetdata/simple_pattern/README.md). We don't simple patterns in the example, but if we wanted to visualize all the `http_req` metrics, we could have a single dimension: `dimension = pattern 'k6.http_req*' last 1 1`. Find detailed examples with patterns in our [documentation](https://github.com/netdata/netdata/blob/master/collectors/statsd.plugin/README.md#dimension-patterns). -- **METRIC** The id of the metric as it comes from the client. You can easily find this in the private charts above, for example: `k6.http_req_connecting`. -- **NAME**: The name of the dimension. You can use the dictionary to expand this to something more human-readable. -- **TYPE**: - - For all charts: - - `events`: The number of events (data points) received by the StatsD server - - `last`: The last value that the server received - - For histograms and timers: - - `min`, `max`, `sum`, `average`, `percentile`, `median`, `stddev`: This is helpful if you want to see different representations of the same value. You can find an example at the `[iteration_duration]` above. Note that the baseline `metric` is the same, but the `name` of the dimension is different, since we use the baseline, but we perform a computation on it, creating a different final metric for visualization(dimension). -- **MULTIPLIER DIVIDER**: Handy if you want to convert Kilobytes to Megabytes or you want to give negative value. The second is handy for better visualization of send/receive. You can find an example at the **packets** submenu of the **IPv4 Networking Section**. - -> ❕ If you define a chart, run Netdata to visualize metrics, and then add or remove a dimension from that chart, this will result in a new chart with the same name, confusing Netdata. If you change the dimensions of the chart, please make sure to also change the `name` of that chart, since it serves as the `id` of that chart in Netdata's storage. (e.g http_req --> http_req_1). - -### Finalize your StatsD configuration file - -It's time to assemble all the pieces together and create the synthetic charts that will consist our application dashboard in Netdata. We can do it in a few simple steps: - -- Decide which metrics we want to use (we have viewed all of them as private charts). For example, we want to use `k6.http_requests`, `k6.vus`, etc. -- Decide how we want organize them in different synthetic charts. For example, we want `k6.http_requests`, `k6.vus` on their own, but `k6.http_req_blocked` and `k6.http_req_connecting` on the same chart. -- For each synthetic chart, we define a **unique** name and a human readable title. -- We decide at which `family` (submenu section) we want each synthetic chart to belong to. For example, here we have defined 2 families: `http requests`, `k6_metrics`. -- If we have multiple instances of the same metric, we can define different contexts, (Optional). -- We define a dimension according to the syntax we highlighted above. -- We define a type for each synthetic chart (line, area, stacked) -- We define the units for each synthetic chart. - -Following the above steps, we append to the `k6.conf` that we defined above, the following configuration: - -``` -[http_req_total] - name = http_req_total - title = Total HTTP Requests - family = http requests - context = k6.http_requests - dimension = k6.http_reqs http_reqs last 1 1 sum - type = line - units = requests/s - -[vus] - name = vus - title = Virtual Active Users - family = k6_metrics - dimension = k6.vus vus last 1 1 - dimension = k6.vus_max vus_max last 1 1 - type = line - unit = vus - -[iteration_duration] - name = iteration_duration_2 - title = Iteration duration - family = k6_metrics - dimension = k6.iteration_duration iteration_duration last 1 1 - dimension = k6.iteration_duration iteration_duration_max max 1 1 - dimension = k6.iteration_duration iteration_duration_min min 1 1 - dimension = k6.iteration_duration iteration_duration_avg avg 1 1 - type = line - unit = s - -[dropped_iterations] - name = dropped_iterations - title = Dropped Iterations - family = k6_metrics - dimension = k6.dropped_iterations dropped_iterations last 1 1 - units = iterations - type = line - -[data] - name = data - title = K6 Data - family = k6_metrics - dimension = k6.data_received data_received last 1 1 - dimension = k6.data_sent data_sent last -1 1 - units = kb/s - type = area - -[http_req_status] - name = http_req_status - title = HTTP Requests Status - family = http requests - dimension = k6.http_req_blocked http_req_blocked last 1 1 - dimension = k6.http_req_connecting http_req_connecting last 1 1 - units = ms - type = line - -[http_req_duration] - name = http_req_duration - title = HTTP requests duration - family = http requests - dimension = k6.http_req_sending http_req_sending last 1 1 - dimension = k6.http_req_waiting http_req_waiting last 1 1 - dimension = k6.http_req_receiving http_req_receiving last 1 1 - units = ms - type = stacked -``` - -> Take note that Netdata will report the rate for metrics and counters, even if k6 or another application sends an _absolute_ number. For example, k6 sends absolute HTTP requests with `http_reqs`, but Netdat visualizes that in `requests/second`. - -To enable this StatsD configuration, [restart Netdata](https://github.com/netdata/netdata/blob/master/docs/configure/start-stop-restart.md). - -## Final touches - -At this point, you have used StatsD to gather metrics for k6, creating a whole new section in your Netdata dashboard in the process. Moreover, you can further customize the icon of the particular section, as well as the description for each chart. - -To edit the section, please follow the Netdata [documentation](https://learn.netdata.cloud/docs/agent/web/gui#customizing-the-local-dashboard). - -While the following configuration will be placed in a new file, as the documentation suggests, it is instructing to use `dashboard_info.js` as a template. Open the file and see how the rest of sections and collectors have been defined. - -```javascript= -netdataDashboard.menu = { - 'k6': { - title: 'K6 Load Testing', - icon: '<i class="fas fa-cogs"></i>', - info: 'k6 is an open-source load testing tool and cloud service providing the best developer experience for API performance testing.' - }, - . - . - . -``` - -We can then add a description for each chart. Simply find the following section in `dashboard_info.js` to understand how a chart definitions are used: - -```javascript= -netdataDashboard.context = { - 'system.cpu': { - info: function (os) { - void (os); - return 'Total CPU utilization (all cores). 100% here means there is no CPU idle time at all. You can get per core usage at the <a href="#menu_cpu">CPUs</a> section and per application usage at the <a href="#menu_apps">Applications Monitoring</a> section.' - + netdataDashboard.sparkline('<br/>Keep an eye on <b>iowait</b> ', 'system.cpu', 'iowait', '%', '. If it is constantly high, your disks are a bottleneck and they slow your system down.') - + netdataDashboard.sparkline('<br/>An important metric worth monitoring, is <b>softirq</b> ', 'system.cpu', 'softirq', '%', '. A constantly high percentage of softirq may indicate network driver issues.'); - }, - valueRange: "[0, 100]" - }, -``` - -Afterwards, you can open your `custom_dashboard_info.js`, as suggested in the documentation linked above, and add something like the following example: - -```javascript= -netdataDashboard.context = { - 'k6.http_req_duration': { - info: "Total time for the request. It's equal to http_req_sending + http_req_waiting + http_req_receiving (i.e. how long did the remote server take to process the request and respond, without the initial DNS lookup/connection times)" - }, - -``` -The chart is identified as ``<section_name>.<chart_name>``. - -These descriptions can greatly help the Netdata user who is monitoring your application in the midst of an incident. - -The `info` field supports `html`, embedding useful links and instructions in the description. - -## Vendoring a new collector - -While we learned how to visualize any data source in Netdata using the StatsD protocol, we have also created a new collector. - -As long as you use the same underlying collector, every new `myapp.conf` file will create a new data source and dashboard section for Netdata. Netdata loads all the configuration files by default, but it will **not** create dashboard sections or charts, unless it starts receiving data for that particular data source. This means that we can now share our collector with the rest of the Netdata community. - -If you want to contribute or you need any help in developing your collector, we have a whole [Forum Category](https://community.netdata.cloud/c/agent-development/9) dedicated to contributing to the Netdata Agent. - -### Making a PR to the netdata/netdata repository - -- Make sure you follow the contributing guide and read our Code of Conduct -- Fork the netdata/netdata repository -- Place the configuration file inside `netdata/collectors/statsd.plugin` -- Add a reference in `netdata/collectors/statsd.plugin/Makefile.am`. For example, if we contribute the `k6.conf` file: -```Makefile -dist_statsdconfig_DATA = \ - example.conf \ - k6.conf \ - $(NULL) -``` - -## What's next? - -In this tutorial, you learned how to monitor an application using Netdata's StatsD implementation. - -Netdata allows you easily visualize any StatsD metric without any configuration, since it creates a private metric per chart by default. But to make your implementation more robust, you also learned how to group metrics by family and context, and create multiple dimensions. With these tools, you can quickly instrument any application with StatsD to monitor its performance and availability with per-second metrics. - -### Related reference documentation - -- [Netdata Agent · StatsD](https://github.com/netdata/netdata/blob/master/collectors/statsd.plugin/README.md) - - diff --git a/docs/guides/monitor/stop-notifications-alarms.md b/docs/guides/monitor/stop-notifications-alarms.md deleted file mode 100644 index 3c026a89b..000000000 --- a/docs/guides/monitor/stop-notifications-alarms.md +++ /dev/null @@ -1,92 +0,0 @@ -<!-- -title: "Stop notifications for individual alarms" -custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/guides/monitor/stop-notifications-alarms.md ---> - -# Stop notifications for individual alarms - -In this short tutorial, you'll learn how to stop notifications for individual alarms in Netdata's health -monitoring system. We also refer to this process as _silencing_ the alarm. - -Why silence alarms? We designed Netdata's pre-configured alarms for production systems, so they might not be -relevant if you run Netdata on your laptop or a small virtual server. If they're not helpful, they can be a distraction -to real issues with health and performance. - -Silencing individual alarms is an excellent solution for situations where you're not interested in seeing a specific -alarm but don't want to disable a [notification system](https://github.com/netdata/netdata/blob/master/health/notifications/README.md) entirely. - -## Find the alarm configuration file - -To silence an alarm, you need to know where to find its configuration file. - -Let's use the `system.cpu` chart as an example. It's the first chart you'll see on most Netdata dashboards. - -To figure out which file you need to edit, open up Netdata's dashboard and, click the **Alarms** button at the top -of the dashboard, followed by clicking on the **All** tab. - -In this example, we're looking for the `system - cpu` entity, which, when opened, looks like this: - -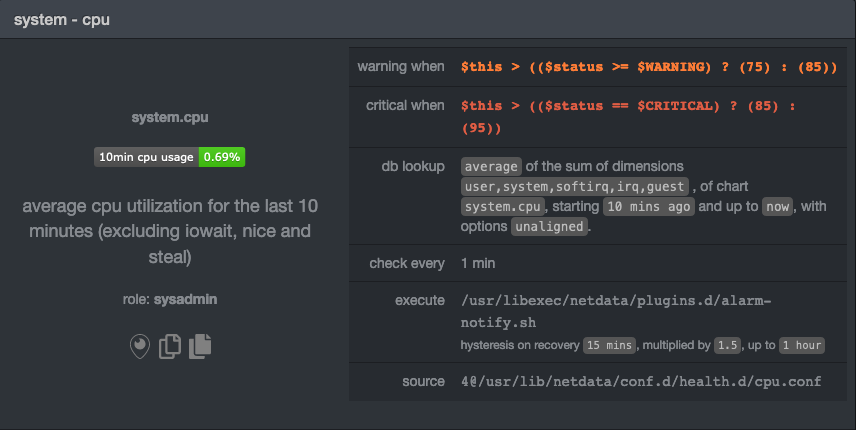 - -In the `source` row, you see that this chart is getting its configuration from -`4@/usr/lib/netdata/conf.d/health.d/cpu.conf`. The relevant part of begins at `health.d`: `health.d/cpu.conf`. That's -the file you need to edit if you want to silence this alarm. - -For more information about editing or referencing health configuration files on your system, see the [health -quickstart](https://github.com/netdata/netdata/blob/master/health/QUICKSTART.md#edit-health-configuration-files). - -## Edit the file to enable silencing - -To edit `health.d/cpu.conf`, use `edit-config` from inside of your Netdata configuration directory. - -```bash -cd /etc/netdata/ # Replace with your Netdata configuration directory, if not /etc/netdata/ -./edit-config health.d/cpu.conf -``` - -> You may need to use `sudo` or another method of elevating your privileges. - -The beginning of the file looks like this: - -```yaml -template: 10min_cpu_usage - on: system.cpu - os: linux - hosts: * - lookup: average -10m unaligned of user,system,softirq,irq,guest - units: % - every: 1m - warn: $this > (($status >= $WARNING) ? (75) : (85)) - crit: $this > (($status == $CRITICAL) ? (85) : (95)) - delay: down 15m multiplier 1.5 max 1h - info: average cpu utilization for the last 10 minutes (excluding iowait, nice and steal) - to: sysadmin -``` - -To silence this alarm, change `sysadmin` to `silent`. - -```yaml - to: silent -``` - -Use one of the available [methods](https://github.com/netdata/netdata/blob/master/health/QUICKSTART.md#reload-health-configuration) to reload your health configuration - and ensure you get no more notifications about that alarm**. - -You can add `to: silent` to any alarm you'd rather not bother you with notifications. - -## What's next? - -You should now know the fundamentals behind silencing any individual alarm in Netdata. - -To learn about _all_ of Netdata's health configuration possibilities, visit the [health reference -guide](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md), or check out other [tutorials on health monitoring](https://github.com/netdata/netdata/blob/master/health/README.md#guides). - -Or, take better control over how you get notified about alarms via the [notification -system](https://github.com/netdata/netdata/blob/master/health/notifications/README.md). - -You can also use Netdata's [Health Management API](https://github.com/netdata/netdata/blob/master/web/api/health/README.md#health-management-api) to control health -checks and notifications while Netdata runs. With this API, you can disable health checks during a maintenance window or -backup process, for example. - - diff --git a/docs/guides/monitor/visualize-monitor-anomalies.md b/docs/guides/monitor/visualize-monitor-anomalies.md deleted file mode 100644 index 90ce20a4b..000000000 --- a/docs/guides/monitor/visualize-monitor-anomalies.md +++ /dev/null @@ -1,142 +0,0 @@ ---- -title: "Monitor and visualize anomalies with Netdata (part 2)" -description: "Using unsupervised anomaly detection and machine learning, get notified " -image: /img/seo/guides/monitor/visualize-monitor-anomalies.png -author: "Joel Hans" -author_title: "Editorial Director, Technical & Educational Resources" -author_img: "/img/authors/joel-hans.jpg" -custom_edit_url: https://github.com/netdata/netdata/edit/master/docs/guides/monitor/visualize-monitor-anomalies.md ---- - -Welcome to part 2 of our series of guides on using _unsupervised anomaly detection_ to detect issues with your systems, -containers, and applications using the open-source Netdata Agent. For an introduction to detecting anomalies and -monitoring associated metrics, see [part 1](https://github.com/netdata/netdata/blob/master/docs/guides/monitor/anomaly-detection-python.md), which covers prerequisites and -configuration basics. - -With anomaly detection in the Netdata Agent set up, you will now want to visualize and monitor which charts have -anomalous data, when, and where to look next. - -> 💡 In certain cases, the anomalies collector doesn't start immediately after restarting the Netdata Agent. If this -> happens, you won't see the dashboard section or the relevant [charts](#visualize-anomalies-in-charts) right away. Wait -> a minute or two, refresh, and look again. If the anomalies charts and alarms are still not present, investigate the -> error log with `less /var/log/netdata/error.log | grep anomalies`. - -## Test anomaly detection - -Time to see the Netdata Agent's unsupervised anomaly detection in action. To trigger anomalies on the Nginx web server, -use `ab`, otherwise known as [Apache Bench](https://httpd.apache.org/docs/2.4/programs/ab.html). Despite its name, it -works just as well with Nginx web servers. Install it on Ubuntu/Debian systems with `sudo apt install apache2-utils`. - -> 💡 If you haven't followed the guide's example of using Nginx, an easy way to test anomaly detection on your node is -> to use the `stress-ng` command, which is available on most Linux distributions. Run `stress-ng --cpu 0` to create CPU -> stress or `stress-ng --vm 0` for RAM stress. Each test will cause some "collateral damage," in that you may see CPU -> utilization rise when running the RAM test, and vice versa. - -The following test creates a minimum of 10,000,000 requests for Nginx to handle, with a maximum of 10 at any given time, -with a run time of 60 seconds. If your system can handle those 10,000,000 in less than 60 seconds, `ab` will keep -sending requests until the timer runs out. - -```bash -ab -k -c 10 -t 60 -n 10000000 http://127.0.0.1/ -``` - -Let's see how Netdata detects this anomalous behavior and propagates information to you through preconfigured alarms and -dashboards that automatically organize anomaly detection metrics into meaningful charts to help you begin root cause -analysis (RCA). - -## Monitor anomalies with alarms - -The anomalies collector creates two "classes" of alarms for each chart captured by the `charts_regex` setting. All these -alarms are preconfigured based on your [configuration in -`anomalies.conf`](https://github.com/netdata/netdata/blob/master/docs/guides/monitor/anomaly-detection-python.md#configure-the-anomalies-collector). With the `charts_regex` -and `charts_to_exclude` settings from [part 1](https://github.com/netdata/netdata/blob/master/docs/guides/monitor/anomaly-detection-python.md) of this guide series, the -Netdata Agent creates 32 alarms driven by unsupervised anomaly detection. - -The first class triggers warning alarms when the average anomaly probability for a given chart has stayed above 50% for -at least the last two minutes. - -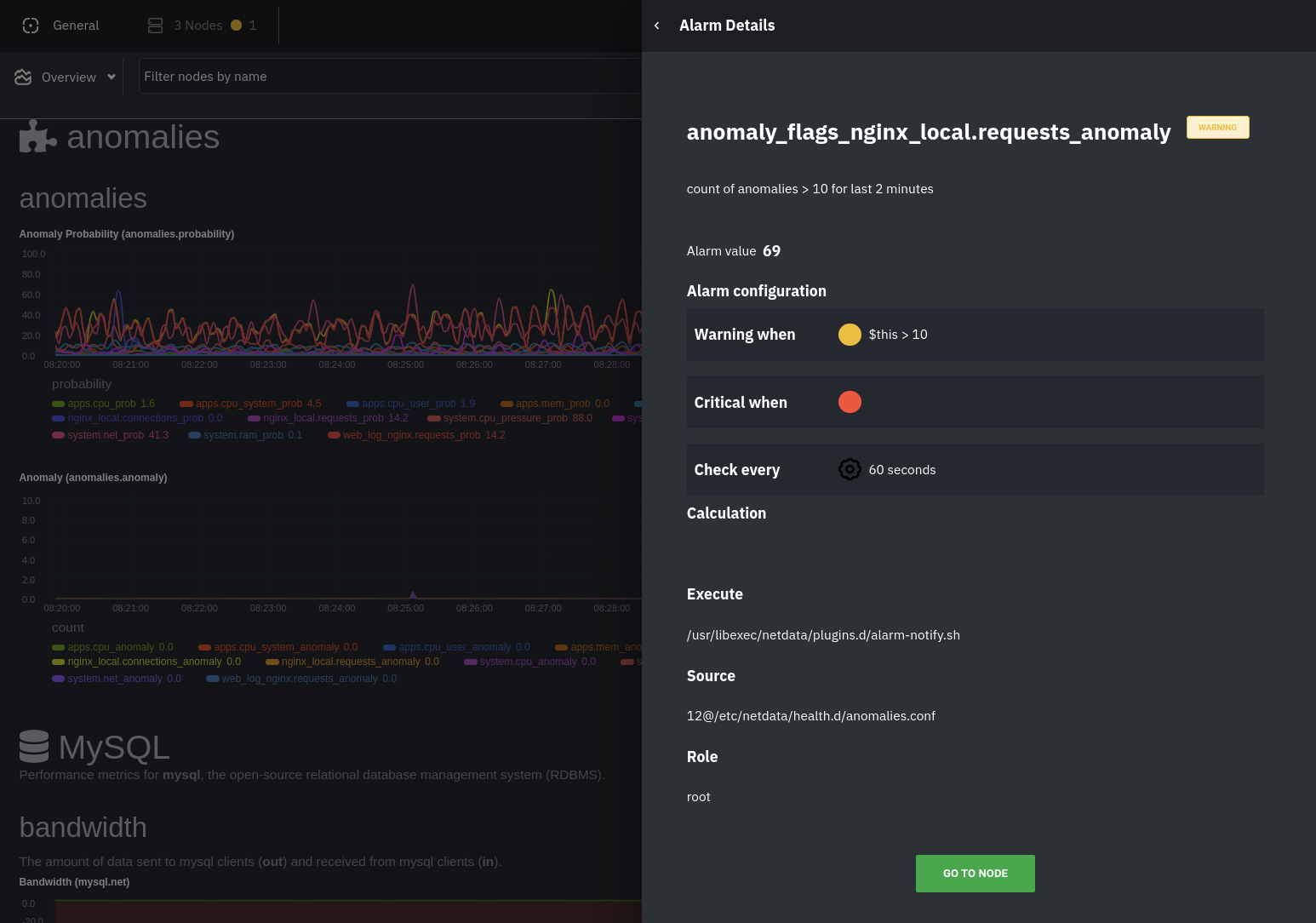 - -The second class triggers warning alarms when the number of anomalies in the last two minutes hits 10 or higher. - -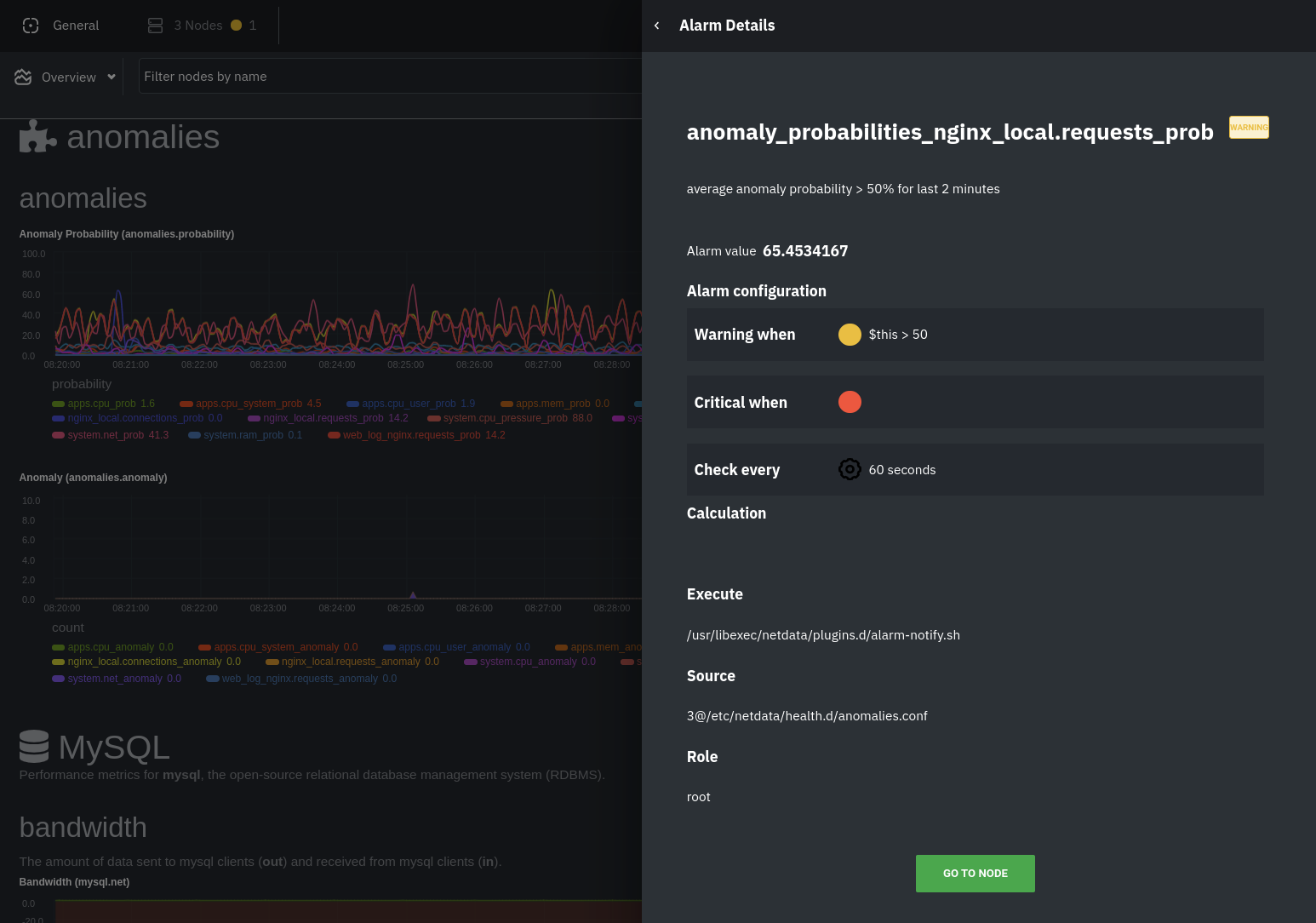 - -If you see either of these alarms in Netdata Cloud, the local Agent dashboard, or on your preferred notification -platform, it's a safe bet that the node's current metrics have deviated from normal. That doesn't necessarily mean -there's a full-blown incident, depending on what application/service you're using anomaly detection on, but it's worth -further investigation. - -As you use the anomalies collector, you may find that the default settings provide too many or too few genuine alarms. -In this case, [configure the alarm](https://github.com/netdata/netdata/blob/master/docs/monitor/configure-alarms.md) with `sudo ./edit-config -health.d/anomalies.conf`. Take a look at the `lookup` line syntax in the [health -reference](https://github.com/netdata/netdata/blob/master/health/REFERENCE.md#alarm-line-lookup) to understand how the anomalies collector automatically creates -alarms for any dimension on the `anomalies_local.probability` and `anomalies_local.anomaly` charts. - -## Visualize anomalies in charts - -In either [Netdata Cloud](https://app.netdata.cloud) or the local Agent dashboard at `http://NODE:19999`, click on the -**Anomalies** [section](https://github.com/netdata/netdata/blob/master/web/gui/README.md#sections) to see the pair of anomaly detection charts, which are -preconfigured to visualize per-second anomaly metrics based on your [configuration in -`anomalies.conf`](https://github.com/netdata/netdata/blob/master/docs/guides/monitor/anomaly-detection-python.md#configure-the-anomalies-collector). - -These charts have the contexts `anomalies.probability` and `anomalies.anomaly`. Together, these charts -create meaningful visualizations for immediately recognizing not only that something is going wrong on your node, but -give context as to where to look next. - -The `anomalies_local.probability` chart shows the probability that the latest observed data is anomalous, based on the -trained model. The `anomalies_local.anomaly` chart visualizes 0→1 predictions based on whether the latest observed -data is anomalous based on the trained model. Both charts share the same dimensions, which you configured via -`charts_regex` and `charts_to_exclude` in [part 1](https://github.com/netdata/netdata/blob/master/docs/guides/monitor/anomaly-detection-python.md). - -In other words, the `probability` chart shows the amplitude of the anomaly, whereas the `anomaly` chart provides quick -yes/no context. - -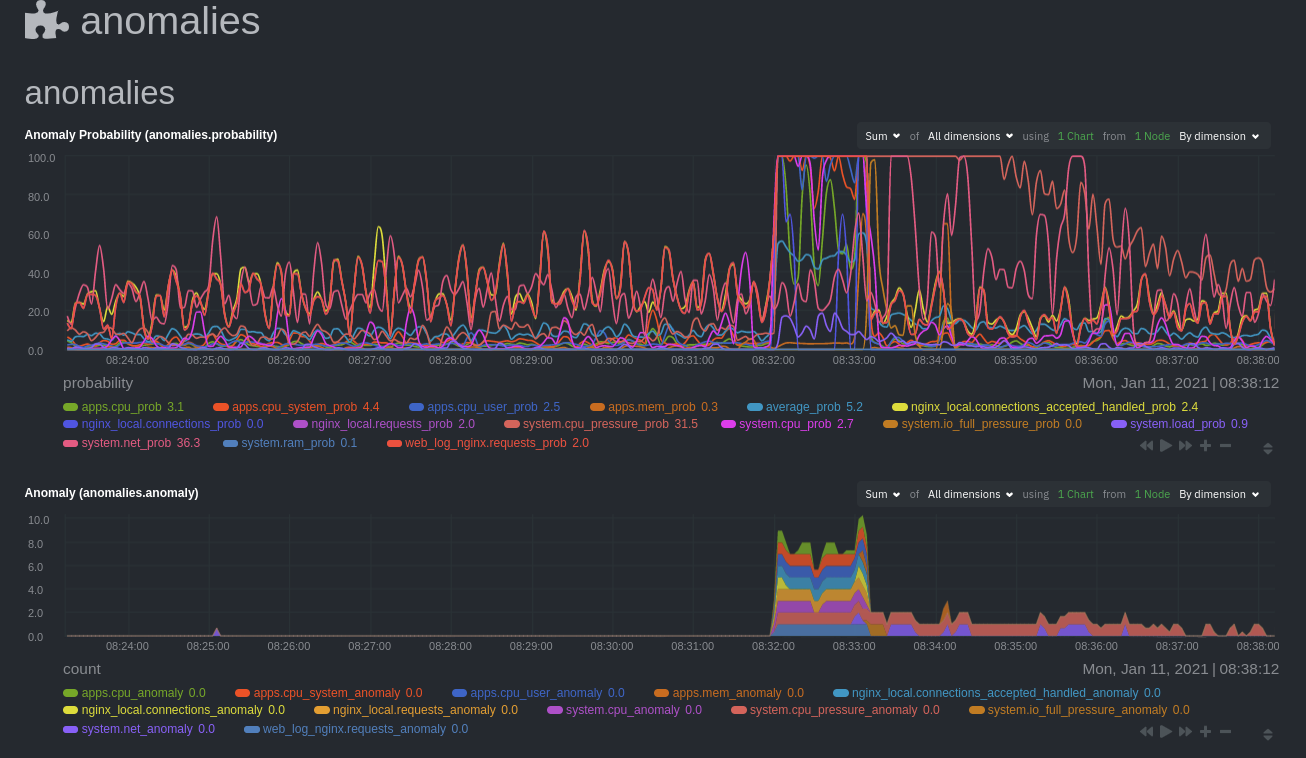 - -Before `08:32:00`, both charts show little in the way of verified anomalies. Based on the metrics the anomalies -collector has trained on, a certain percentage of anomaly probability score is normal, as seen in the -`web_log_nginx_requests_prob` dimension and a few others. What you're looking for is large deviations from the "noise" -in the `anomalies.probability` chart, or any increments to the `anomalies.anomaly` chart. - -Unsurprisingly, the stress test that began at `08:32:00` caused significant changes to these charts. The three -dimensions that immediately shot to 100% anomaly probability, and remained there during the test, were -`web_log_nginx.requests_prob`, `nginx_local.connections_accepted_handled_prob`, and `system.cpu_pressure_prob`. - -## Build an anomaly detection dashboard - -[Netdata Cloud](https://app.netdata.cloud) features a drag-and-drop [dashboard -editor](https://github.com/netdata/netdata/blob/master/docs/visualize/create-dashboards.md) that helps you create entirely new dashboards with charts targeted for -your specific applications. - -For example, here's a dashboard designed for visualizing anomalies present in an Nginx web server, including -documentation about why the dashboard exists and where to look next based on what you're seeing: - -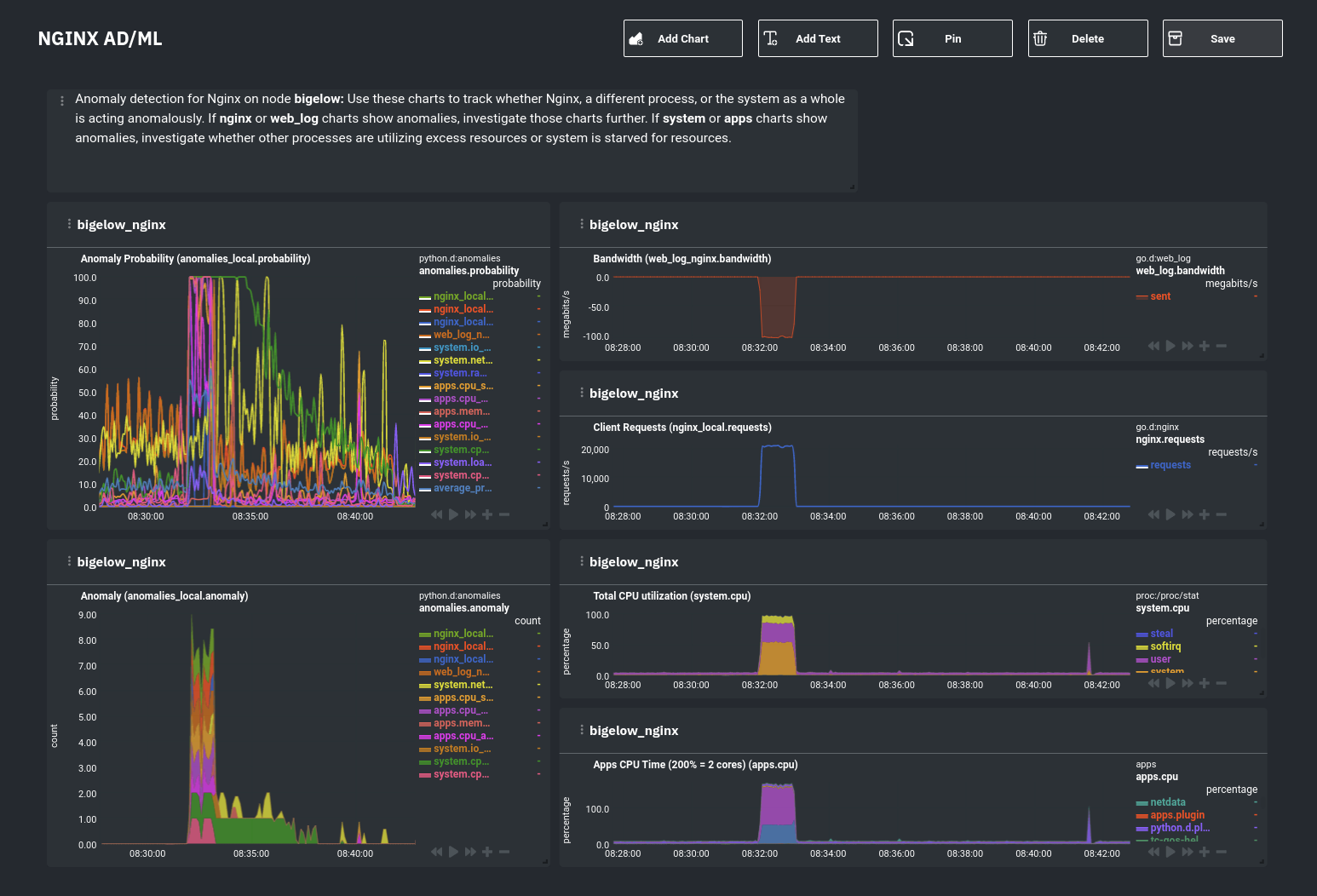 - -Use the anomaly charts for instant visual identification of potential anomalies, and then Nginx-specific charts, in the -right column, to validate whether the probability and anomaly counters are showing a valid incident worth further -investigation using [Metric Correlations](https://github.com/netdata/netdata/blob/master/docs/cloud/insights/metric-correlations.md) to narrow -the dashboard into only the charts relevant to what you're seeing from the anomalies collector. - -## What's next? - -Between this guide and [part 1](https://github.com/netdata/netdata/blob/master/docs/guides/monitor/anomaly-detection-python.md), which covered setup and configuration, you -now have a fundamental understanding of how unsupervised anomaly detection in Netdata works, from root cause to alarms -to preconfigured or custom dashboards. - -We'd love to hear your feedback on the anomalies collector. Hop over to the [community -forum](https://community.netdata.cloud/t/anomalies-collector-feedback-megathread/767), and let us know if you're already getting value from -unsupervised anomaly detection, or would like to see something added to it. You might even post a custom configuration -that works well for monitoring some other popular application, like MySQL, PostgreSQL, Redis, or anything else we -[support through collectors](https://github.com/netdata/netdata/blob/master/collectors/COLLECTORS.md). - -### Related reference documentation - -- [Netdata Agent · Anomalies collector](https://github.com/netdata/netdata/blob/master/collectors/python.d.plugin/anomalies/README.md) -- [Netdata Cloud · Build new dashboards](https://github.com/netdata/netdata/blob/master/docs/cloud/visualize/dashboards.md) - - |